威胁情报提取与知识图谱构建技术研究
2023-09-07史慧洋魏靖烜蔡兴业高随祥张玉清
史慧洋,魏靖烜,蔡兴业,王 鹤,高随祥,张玉清,,6
(1.中国科学院大学 计算机科学与技术学院,北京 101408;2.中国科学院大学 国家计算机网络入侵防范中心,北京 101408;3.中国科学院大学 沈阳计算技术研究所,辽宁 沈阳 110168;4.西安电子科技大学 网络与信息安全学院,陕西 西安 710071;5.中国科学院大学 数学科学学院,北京 101408;6.中关村实验室,北京 100094)
1 引 言
当今网络攻击手段日趋成熟,两方博弈中,如何快速利用威胁情报分析对手的攻击行为,从而弥补自身的不足,由被动防御转为主动进攻。如何从海量的数据中快速提取有效的威胁情报,如何对离散分布的各类威胁情报进行有效收集并有效利用,如何将威胁情报融合分析发挥整体威力,已成为学术界关注的热点。威胁情报经过聚合和标准化、去重去伪,使用混合策略纳什均衡来评估时间威胁等级,从而预测攻击行为[1]。
威胁情报主要包括以下几种标准格式:结构化威胁信息表达(Structured Threat Information eXpression,STIX)、可信任的指标信息自动变换(Trusted Automated eXchange of Indicator Information,TAXII)、网络可观察表达(Cyber Observable eXpression,CybOX)和恶意软件属性举和描述(Malware Attribute Enumeration and Characterization,MAEC)。文中采用STIX标准格式,STIX 可以使用对象和描述性关系来表达可疑、攻陷和溯源的所有方面的内容;通过关系连接多个对象可以简化或复杂地表示网络空间威胁情报。其优势在于类型丰富,适用于各类场景,能够获取更为广泛的网络威胁信息,且更加标准化和结构化。
随着人工智能以及自然语言处理(Natural Language Processing,NLP)技术的发展,出现大量信息抽取工具,如自然语言处理的Stanford NLP工具和NLTK(Natural Language ToolKit)工具包,还有THUTag清华关键词抽取工具包等,在这些工具的基础上,结合第三方词库进行数据标记,采用数据库匹配、启发式规则和安全词集3种方式对文本数据进行标记,记录BIO(Begin,Inside,Outside)标签[2]。因此,文中使用BIO标签作为特征提取方法,使用神经网络进行非结构化文本中安全信息的提取。
本体是同一领域中不同主体之间的交流和联系的语义基础[3]。文中参考威胁情报数据标准STIX格式提出本体构建,并作为图数据库模式。本体构建的过程是首先将实体和提取的关系构建成知识网络,然后将数据转换为知识,并将知识与应用相结合。通过本体构建可以促进知识的融合,从而发挥数据的实用价值。
知识图谱由谷歌提出,作为搜索引擎的辅助存储知识库。知识图谱主要是以多种不同形式分发的信息通过关联融合,形成了统一的高质量知识。文献[4]根据现有知识推理,挖掘潜在知识,同时,产生新知识。目前,在威胁情报领域中知识图谱的研究和应用还处于起步阶段。
文中技术研究的贡献如下:
(1) 提出了一种基于Bert+BiSLTM+CRF(Conditional Random Fields)的失陷指标(Indicator Of Compromise,IOC) 识别抽取方法。通过对非结构化文本信息的分析处理,并将其与正则匹配方法相结合,从中抽取出需要的IOC信息并进行标准化输出,得到STIX标准格式的数据。
(2) 构建威胁情报的知识图谱框架,包括情报搜集、信息抽取、本体构建和知识推理4个过程。
(3) 基于STIX构建威胁情报本体模型,以知识图谱的形式表示重要指标和威胁情报实体间的关系,设计出威胁情报检索系统。结合ATT&CK描述攻击行为,挖掘出威胁情报潜在关联信息和攻击主体。
2 相关工作
失陷指标指在网络或操作系统中观察到的伪像,指示计算机入侵行为并在早期检测到网络攻击,因此,它们在网络安全领域中发挥着重要作用。但是IOC检测系统严重依赖具有网络安全知识的专家的判断结果,因此研究需要大规模的手动注释语料库来训练IOC分类器。
何志鹏等[5]总结概述了国际上部分国家(组织)在网络威胁情报领域开展的标准化工作。孙铭鸿等[6]介绍了情报、威胁溯源对国家层面的影响。在威胁情报识别抽取技术中,基于web爬虫和邮件解析的技术具有构造方便、模型简单的优点,缺点在于精度很低,对于复杂的场景不能做出很好的处理。随着人工智能和NLP 技术的发展,徐留杰等[7]提出了一种多源网络安全威胁情报采集与封装技术,首先针对不同来源的威胁情报进行搜集处理,最后生成JSON 格式的标准化情报库。HUANG 等[8]提出了一种基于双向长短期记忆的序列标记模型用于命名实体识别(Named Entity Recognition,NER)任务。LONG等[9]提出了利用基于神经的序列标签从网络安全文章的非结构化文本抽取IOC 模型。该模型引入了多头注意力机制和上下文特征,显著提高了IOC 识别的性能。LAMPLE等[10]提出了将LSTM 编码器与word embedding和神经序列标记模型相结合的方法,在命名实体识别任务和词性标记任务上取得了显著的效果。
LANDAUER等[11]从原始日志中提取网络威胁情报,所提方法还利用数据异常检测来揭示可疑日志事件,这些事件用于迭代聚类、模式识别和优化。KUROGOME等[12]提出了枚举和优化勒索软件的枚举和推断家族典型示例(Enumerating and Inferring Genealogical Exemplars of Ransomware,EIGER) 的方法,通过恶意软件的跟踪自动提取生成可靠的IOC。该方法首先利用TextRank 生成文章的摘要,然后按文章的时间戳对摘要和实体进行排序,生成安全事件链的网络威胁情报(Cyber Threat Intelligence,CTI)。胡代旺等[13]使用轻量级预训框架ALBERT、图卷积网络和负样本学习三元组损失,提出了一种新的实体关系抽取算法。郭渊博等[14]使用BiLSTM融合Focal loss和字符特征就行实体抽取,验证了其有效性。程顺航等[15]融合自举法与语义角色标注,利用少量样本构建语义实体之间的关系。
通过相关研究分析,文中采用从安全文章中提取IOC的方式来获得标准化威胁情报。虽然其获取过程需要更多的工作,但其优势在于可自定义抓取所需时间段内的文本数据,因此时效性较高。此外,安全文章通常是经过专业安全人员审核发表,IOC信息可对应到文章所提到的具体事件,其可信度更高,具有更高的数据价值。在抽取技术方面,现有的研究工作表明,使用深度学习相关的技术会有更好的效果。因此,文中在模型的构建上采用了NER命名实体识别技术。
关于威胁情报的实体有如下信息:pattern_type(模式类型)、valid_from(有效期)、pattern_version(模式版本)、name(威胁情报名称)、indicator_types(指标类型)、created(创建时间)、pattern(攻击模式)、labels(情报标签)、spec_version(情报规格版本)、modified(情报修改时间)、type(情报类型)、id(情报编号)、is_family(威胁情报是否相关)、description(情报描述)、ip(攻击网络地址)、domain(域名)等。文中设计的实体之间具有松耦合性,为本体的扩充留下了充足的空间。与此同时,在本体关系及约束规则下,本体之间关联融合,从而丰富和完善了威胁情报领域知识图谱。
知识图谱首先通过不同形式分发的信息,关联融合后形成统一的高质量知识。然后根据现有知识推理,挖掘潜在知识,同时产生新知识。因此,设计威胁情报的知识图谱,目的是将知识映射技术引入威胁情报领域。最后,针对开源威胁情报的输入,采用Kill-Chain 模型、钻石模型或异构信息网络模型,结合现有的开源威胁情报和实时数据,对威胁情报进行深入关联、碰撞和分析,找到潜在的攻击行为,并通过推理挖掘揭示隐藏的攻击链和其他威胁信息。石波等[16]验证了基于知识图谱的安全威胁感知方法更适用于对高强度安全威胁的感知。
在知识图谱构建的相关研究中,董聪等[17]提出情报知识图谱构建的框架和关键技术。包括信息抽取、本体构建和知识推理等。WU等[18]提出了一种创新的基于本体和基于图的方法来进行安全评估,该方法利用本体模型的推理能力生成攻击图和评估网络安全性。刘强等[19]采用了联合学习的方法,说明了该端到端威胁情报知识图谱构建方法的有效性。对于在线社交网络用户,GONG等[20]提出了新的隐私攻击来推断属性,文中的攻击是利用在线社交网络上公开提供的看似无害的用户信息来推断目标用户的缺失属性。GASCON等[21]介绍了一种威胁情报平台,可通过基于属性图的新型类型不可知相似性算法,对不同标准进行统一分析,并对威胁数据进行关联,提高组织的防御能力。XU等[22]提出了一个新的模型,用于解决二进制代码分析的问题。
3 知识图谱构建框架作
威胁情报知识图谱构建的目的是借助知识图谱技术将分散的威胁情报集成在一起,建立和完善威胁情报评估机制[23]。通用知识图谱的构建基于知识的广度,目的是建立一个覆盖所有领域的通用搜索辅助知识库,而威胁情报知识图则需要实现深度知识系统的构建,从而达到使知识系统适应实际应用的目的。因此,威胁情报知识图谱的构建不同于一般知识图谱的构建。文中在前人对知识图谱研究的基础上,提出了知识图谱构建流程图,如图1所示。
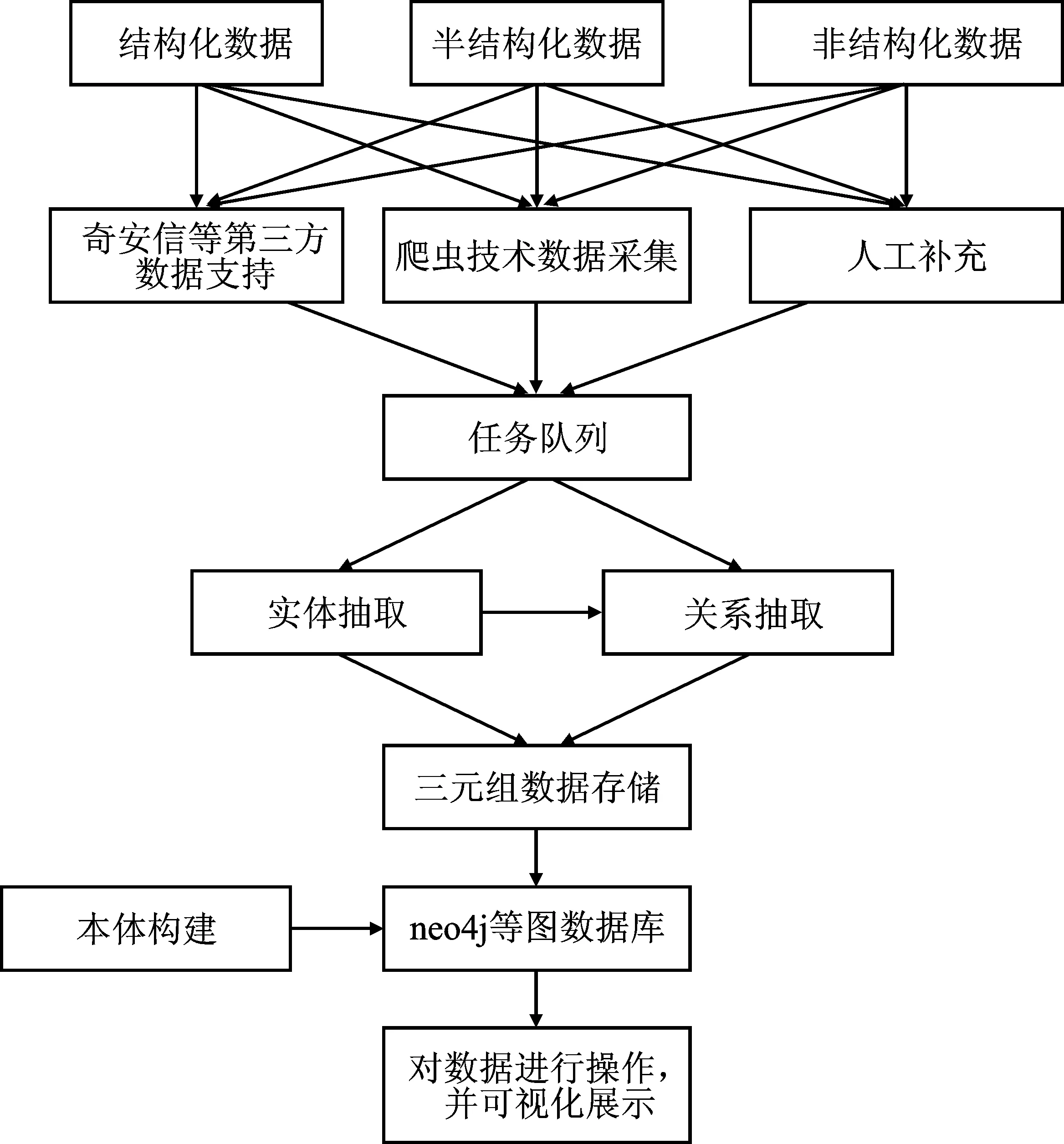
图1 知识图谱构建流程图
图1中数据采集的任务是通过分布式爬虫等方式从网络中威胁情报开放网站获取情报信息。知识抽取包括通过第三方开源包如jieba分词工具对实体进行抽取,然后利用深度学习方式抽取出威胁情报实体及其关系,从而获得有用信息。实体指安全活动中的主体信息,例如漏洞病毒、事件等;关系是指安全实体间存在的关联关系,如攻击者与漏洞的关系,病毒和恶意行为的关系等;本体构建过程是在标准威胁情报表达式STIX格式的基础上,结合获取信息的实际情况,进行图的本体构建。对抽取出的知识进行存储,主要是将获取的知识存入图数据库[24]。文中采用neo4j数据库形成情报知识图谱后,便于知识的增删查询及数据的可视化展示。
3.1 情报搜集
数据采集的任务是通过分布式爬虫等方式从网络中威胁情报开放网站获取情报信息,威胁情报信息分为无结构化数据、半结构化数据和结构化数据。从6个安全平台爬取了总计1 172 条安全博客高级持续性威胁(Advanced Persistent Threat,APT)攻击报告,情报来源既有国内知名情报厂商,也有访问度较高的情报共享开源平台,包括Feebuf、GreenSnow、blocklist、奇安信、VirusTotal和360等。爬取过程如下:首先设置反爬虫机制,添加Cookie用来伪装身份ID;在各个安全网站中自定义搜索中输入APT 攻击报告,采用广度优先搜索的方式,遍历查询列表,通过检查定位资源,使用爬虫的方式获取文章的统一资源定位符(Uniform Resource Location,URL),再通过URL获取文章内容信息。
通过对文章内容进行人工审查发现,部分报告对于攻击行动的描述过于简单,关于攻击模式、攻击过程等信息的记录不充分。为避免模型训练受到数据的影响并且获取更多的有价值信息,可从文章篇幅、规范程度、描述细节等几个标准进行筛选,尽量选择篇幅较长且具体的介绍了整个攻击流程的文章。最终挑选了爬取的745 篇,提取出其正文文本信息,作为本实验的原始数据集,如表1所示。

表1 原始安全报告信息
3.2 识别抽取
通过攻击报告发现,报告在正文内容中描述了攻击策略技术、恶意软件和恶意IP等,这些IOC信息在报告中通常以固定的格式标准出现。例如,在沙箱环境中监控恶意软件等动态分析方法,使用Snort等网络安全工具来监控网络流量。由此可见,IOC信息提取是一项非常重要的任务,可以帮助安全专家更好了解网络攻击的策略、目标和工具,以及加强系统防御。但是采用正则匹配会存在非恶意IP等信息被误提取和IOC信息被漏报。因此,文中首先考虑利用神经网络建模的方法,引入上下文特征,然后采用正则匹配和命名实体识别相结合的办法识别抽取。
3.2.1 识 别
首先对文本信息进行向量化操作,将其映射为数字向量。文中采用Google公司推出的基于Transformer的 Bert 模型将文本信息处理为词向量。在输入时,Bert的编码方式与Transformer的相同。以固定长度的字符串作为输入,数据从下到上传输,每层都采用自我注意的方式,可表示为
(1)
多头自注意机可表示为
(2)

输出是每个位置返回的隐藏层大小向量,定义为Bert(x)。与传统的词向量词word2vec相比,Bert模型的优点是引入上下文特征,可以有效地捕捉上下文的依赖关系,使向量空间中上下文相似的语料库距离非常近,因此可以产生更准确的特征表示,对IOC的识别、提取和判断是否为恶意信息非常有效。
该神经网络模型是基于循环神经网络(Recurrent Neural Network,RNN)的变体 BiLSTM 模型。BiLSTM作为RNN的变体,在处理此类数据上具有更为优秀的表现。BiLSTM由前向LSTM和后向LSTM组成。当输入词向量为 [w1,w2,w3,…,wn] 时,前向LSTM将得到n个词向量[hr1,hr2,hr3,…,hRn];当输入词向量为 [wn,wn-1,wn-2,…,w1] 时,后向LSTM将得到n个词向量[hln,wl3,wl2,…,wl1]。将前向和后向量拼接在一起后,可以得到[H0,H1,… ,Hn]。该向量包含向后信息,即也包含上下文特征,对顺序文本信息的处理有很好的影响。由于该模型采用了Bert预训练模型来获得单词向量,因此,BiLSTM层的输入是上一层的Bert层的输出,可表示为
BiLSTM(w)=S[LstmL(w),LstmR(w)] ,
(3)
其中,S[L,R] 表示l和r拼接的输出,w表示上面Bert层的输出Bert(x)。
在命名实体识别任务中,词向量通过神经网络模型即可输出标签分值,即每个标注词的概率,可以选择一个分值最大的标签作为该字符的标签,但是无法保证概率最大的就是正确的预测结果。因此,在命名实体模型中,在神经网络模型输出后增加一个条件随机场(Conditional Radom Field,CRF)层,CRF 在假定随机变量构成马尔科夫随机场的前提下,预测一组随机变量的条件分布。
一代青年有一代青年的成长,一代青年有一代青年的使命,成长各异,使命相同。党的十九大报告描绘了“两个一百年”的宏伟蓝图。中国石化提出了“两个三年、两个十年”的发展战略。在这一跨越近30年的历史进程中,石化青年生逢其时,成长期、奋斗期与民族复兴、企业奋进的目标同向同行,将完整经历实现新时代目标的伟大进程,成为强国梦、强企梦的亲历者和见证者、追梦者和圆梦人。
在该模型中,在 CRF 层充分的引入了文本与标签的对应关系和文本的上下文标注关系,通过对输出标签二元组进行建模,使用动态规划算法找出得分最高的路径作为最优路径进行序列标注。避免出现得到的文本标签出现前后冲突的情况,在最后输出时为最后的预测结果添加一个限制标签,以此来控制提高输出结果的正确性,并预测最有可能的标签序列,即
(4)
其中,score(y)为BiLSTM层的输出,对应于条件下标签y的概率;T矩阵包含两个相邻实体标签的转移概率,表示标签为后标签项的概率。该功能是为了避免文本标签之间的冲突,并在预测结果中添加一个限制标签,以控制和提高输出结果的精度。
3.2.2 模型融合
通过以上的描述,可得到最终的模型结构的文本表达为
Result=Re(BiLSTM(Bert(x))+score(y)) 。
(5)
首先,引入了正则性来提取可能的识别结果集。在词向量层中,使用Bert预训练模型进行编码;然后将其输入到BiLSTM层得到特征和预测结果,并将该层的结果输入到CRF得到最优解,Re(x)表示一个常规的输出限制。
3.2.3 提 取
采用Bert+BiLSTM+CRF的方法进行实体和关系抽取。首先对原始数据进行数据清洗预处理,然后按照以下两个流程进行抽取:一种是定义正则表达式,抽取出文章中的IOC 匹配数据;另一种是对标注好的数据进行词向量生成,构建神经网络模型。之后获取模型的抽取结果,将两种结果进行匹配。将正则匹配结果中出现在模型输出结果中的信息直接输出;对于未出现在模型输出结果中的信息将其上下文标注为疑似IOC,重新输入到模型中,用于二次识别抽取,再输出抽取结果,以此来更加准确地抽取出文章中的IOC 信息。算法流程如图2所示。

图2 IOC抽取算法流程图
以“蔓灵花攻击行动(简报)”为测试样本举例说明抽取流程。首先将测试样本进行数据清洗后,通过定义正则表达式,抽取候选集合:{RequirementList.doc,…,C:ProgramDataMicrosoftDeviceSynctemp.txt }作为正则匹配候选集;将样本输入到训练好的Bert-BiLSTM-CRF模型中,与正则匹配候选集进行匹配验证,最终输出得到“蔓灵花攻击行动(简报)”抽取结果(为表达直观,采用< >框选实体部分)。
蔓灵花攻击行动(简报)标注结果:研究人员发现,该组织经常使用<鱼叉邮件>攻击的手法,<鱼叉邮件>中包含
…
程序首先尝试在
…
3.3 本体构建
本体构建过程是在标准威胁情报表达式STIX 格式的基础上[25],结合获取信息的实际情况,进行图的本体构建。对抽取出的知识进行存储主要是将获取的知识存入图数据库。文中采用neo4j数据库形成情报知识图谱,便于知识的增删改查操作以及数据的可视化展示。
入侵集合是攻击活动的组合,由单个威胁源发起;特征指标即威胁情报指标,在攻击过程中产生,常见的IOC 指标通常包括:HASH、URL、域名和IP值;身份归属于威胁源,与其一一对应;防御策略是针对攻击模式所制定的策略,保护组织应对攻击[26]。
通过对威胁情报的原子构建最终实现图谱的架构。以攻击模式和漏洞为例,攻击模式是组织快速理解攻击强弱的途径,从攻击方法来说,分为DDOS攻击、web入侵、数据库入侵、系统入侵和病毒植入。其中,web 入侵有远程入侵和隐秘通道入侵两种方式,系统入侵包括系统提权和Webshell;攻击过程分为远程漏洞利用、Web暴力破解登录、本地漏洞利用、XSS攻击、数据库注入、欺骗和flood攻击;漏洞从技术类型来说,划分为内存破坏类、逻辑错误类、输入验证类、设计错误类和配置错误。
3.4 情报推理
Adversarial Tactics,Techniques,and Common Knowledge (ATT&CK)以攻击者的视角来描述攻击中各阶段用到的技术。通过将已知攻击者行为转换为结构化列表,以矩阵和结构化威胁信息表达式(STIX)、指标信息的可信自动化交换(TAXII)来表示攻击战术和技术。ATT&CK 在kill chain 模型的基础上提出,关注攻击过程的上下文,构建共享的知识模型和框架,解决了分析检测以IOC 为主的行为标记和攻击描述缺乏规范化两大问题。文中提出的抽取模型从多个来源获取威胁情报数据后,首先根据ATT&CK模型将攻击者行为转化为标准化结构,使用知识图谱清晰描绘出攻击行为,并且进行威胁情报融合分析,然后进行关联分析[27],帮助还原攻击事件的量化指标,通过理解上下文进行态势感知,为威胁响应团队提供及时、相关、完整和准确的情报。关联分析可以应对不断增加的数据及数据复杂性,常用的关联分析方法有内部溯源和外部溯源。外部溯源通过给攻击者描绘画像信息,如个人信息、攻击用网络资产、工具、目标和事件发生位置等进行分析。在APT攻击中,恶意软件通常以家族形式演化。
因此,对于追踪攻击的来源和了解新的恶意软件可以使用建立恶意软件家族图的方式。当攻击对象知道某类攻击名称,其所属的类型后,以及类型中所包含的攻击病毒家族后[28],可以判断出某一类关系是否合法,从而对于威胁情报进行有效评估。同理,知道第1、2、4、5、6类的关系,能够推理出第3类关系,从而更能广泛挖掘出数据之间存在的深度关联,发掘出潜在的攻击行为,从而更好地发现威胁情报信息。
4 实验评估
4.1 数据源
数据来源是结构化信息标准促进组织(oasis)公布的威胁情报数据,将爬取得到的非结构化数据进行简单的预处理,包括数据清洗、停用词过滤后,选择文章的正文内容作为数据集。将报告按照8∶1∶1的比例,从中随机抽取出74篇进行人工IOC标注,标记出文章中涉及到的恶意IP,URL等,作为测试集。再随机选出74篇作为验证集,剩下的部分为训练集。采用的标注工具为Colabeler,标注过程如图3所示。
图3 标注过程
4.2 识别抽取实验结果
在生成词向量阶段,直接调用Bert模型生成。在训练神经网络模型时,采用随机梯度下降的方法。为了防止出现过拟合的现象,模型引入Dropout正则化处理,设置最大epoch个数为100,经过调参发现当Embedding_dim值为100、Hidden_dim值为129、Dropout_rate为0.5、Batch_size为32、学习率为0.001的情况下最优。训练过程如图4所示。
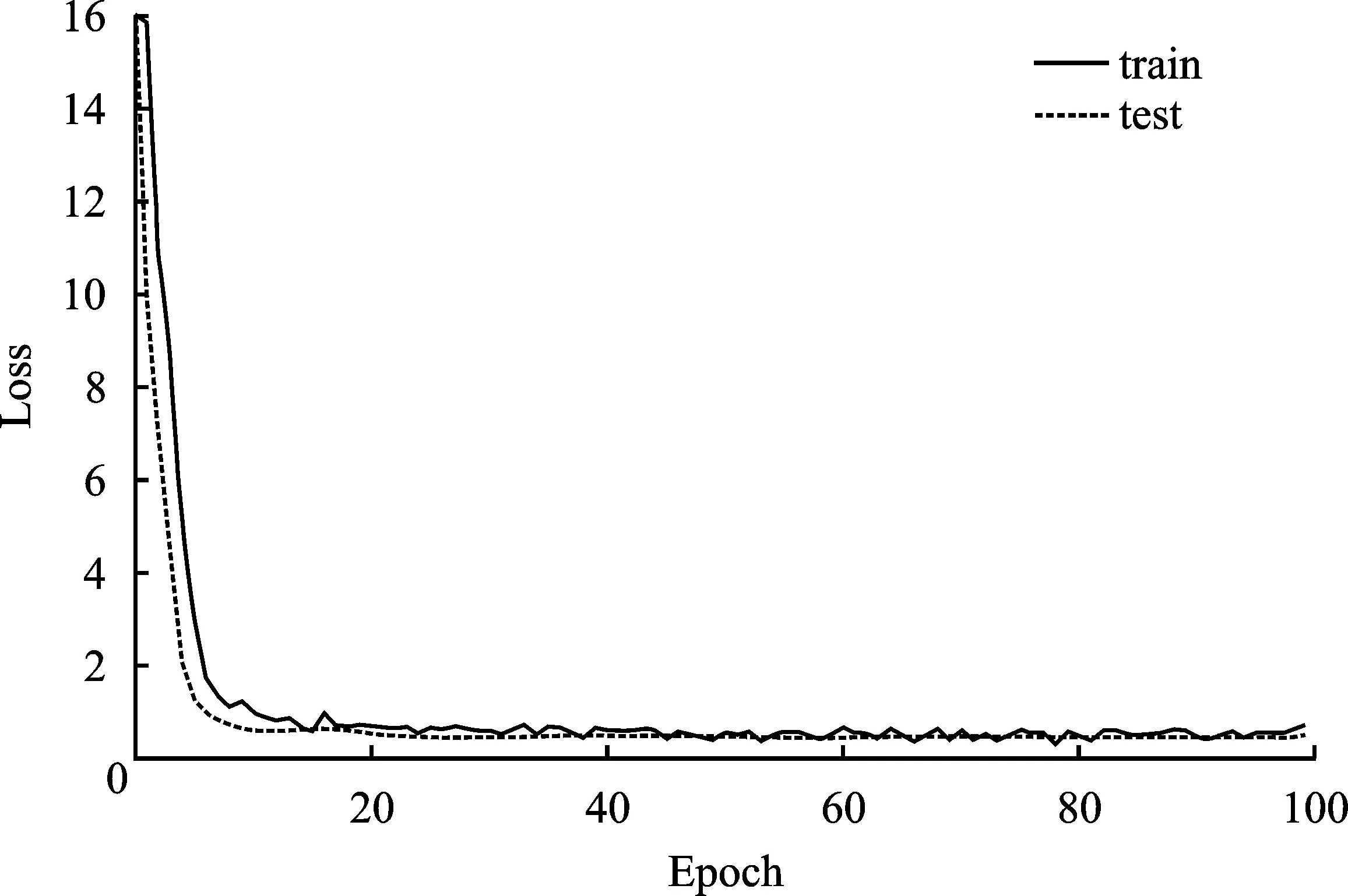
图4 训练过程
文中采用常用的NER评价指标值:精确率P(Precision)、召回率R(Recall)和F1(F-measure) 来衡量实验结果。根据评估标准,模型对比如表2所示。
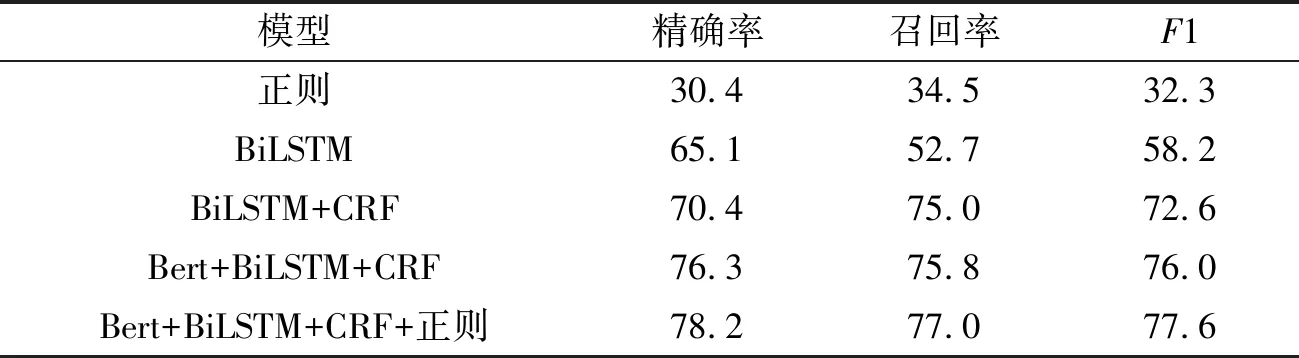
表2 神经网络抽取模型改进
当单独使用正则匹配时,模型的识别率非常低,原因在于非恶意IOC的错误识别和非标注格式IOC的漏报,当使用神经网络BiLSTM时,相比于正则匹配性能有了非常显著的提升;当对BiLSTM的输出加以CRF限制时,识别性能也相对提高。可见CRF 对标签限制输出在命名实体识别任务中的必要性。采用Bert模型进行词向量的生成也提高了模型的识别准确率,Bert和CRF的引入可以看出引入上下文特征在文本信息处理任务上具有非常好的效果; 最后,文中添加了正则匹配,将正则匹配结果进行二次识别。实验

表3 各抽取模型对比
结果表明,这一方法对模型优化也存在一定帮助。
同时将该法与其他抽取模型对比,文中所使用的模型评分明显高于基准线。对比结果如表3所示。
4.3 实 现
ATT&CK的应用之一是威胁情报,通过将报告转化为结构化格式,把依赖IOC转变为基于TTPs和行为的攻击检测。文中首先使用ATT&CK Navigator工具进行分析,Dicovery战术中使用5种技术,Collection阶段使用两种技术:Automated Collection和Data from Local System,然后通过构建知识图谱描述攻击行为和过程。
对APT1 建立知识图谱进行分析,攻击手段通常为鱼叉攻击,通过寻找易受攻击的web 服务器,然后上传webshell,达到访问目标内部网络的目的。攻击周期包括初步侦察、建立立足点、特权提升、内部侦察和横向移动5个阶段。数据格式为JSON格式,图谱中包含实体200个,关系133个,关系类别包括uses、mitigates、indicates、targets和attributed_to。将威胁情报对象和对应的值输入查询系统时,可以根据cypher语句从图数据中查询到相应的点及关系,从而返回页面中。本次分析采用标准的STIX格式数据,需要创建本体及原子本体。其中,图谱中共有7类本体,分别为入侵集合、威胁源、特征指标、恶意代码、身份、攻击工具和攻击模式,图谱中本体关系如图5所示。
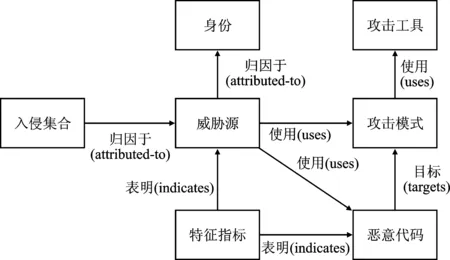
图5 本体关系
各个本体下的原子本体是实例化的实体,是本体中最小的不可分割的概念。具体的数据即为图谱中的一个实体。依据本体关系建立实体关联,从图谱中任一实体出发,可根据关系查询出与之相关的所有信息。如图6所示,通过特征指标indicator--8da68996-f175-4ae0-bd74-aad4913873b8指示恶意软件malware--4de25c38-5826-4ee7-b84d-878064de87ad具有攻击性,其威胁源来自于campaign--752c225d-d6f6-4456-9130-d9580fd4007b,通过分析协助用户快速找到威胁源,从而有效处置。
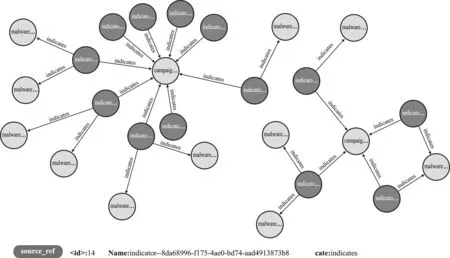
图6 APT1实体关系图谱
从图6中也可以看出,根据边颜色的不同进行实体间关系的划分[29],更加直观地了解攻击事件中本体及原子本体以及其之间的关系。通过知识图谱的情报搜索,可以更加充分挖掘数据之间潜在关系,对于威胁情报的精准可视化具有重要意义。
4.4 工程应用
4.4.1 数据可视化
可视化是知识图的一个典型应用。对于各种类型的威胁情报,可以使用模式匹配的原则来查询特定的节点和关系并可视化显示。例如,与攻击事件相关的所有节点的信息、相同攻击模式的所有节点等,可以帮助专业人员进行推理分析。
4.4.2 知识推理
这部分使用了知识图的推理函数。虽然neo4j的存储方法不如RDF稳健,具有较强的语义能力,但基于弱语义的推理仍被广泛应用。知识推理可以被理解为基于一般的规则和结论来获取新的知识。它应用于威胁情报领域,可以推断出各种潜在的威胁。例如,当多个攻击者在同一攻击模式下攻击某一特定公司时,可以假设该公司对这种攻击模式的防御能力较差。还可以推断出在这种攻击模式下的其他攻击者也受到了威胁。此外,它还包含了一些基于知识推理的错误检查和分类等功能。
5 结束语
文中介绍了知识图谱的相关构建技术,包括数据获取、识别抽取、本体构建及情报推理。使用了一种基于Bert+BiLSTM+CRF的命名实体识别模型,加以正则匹配机制进行输出限制,用于从文本信息中识别抽取IOC信息,并输出为STIX标准化格式数据的方法。Bert模型和条件随机场的引入充分利用了上下文特征,从而获得了比前人更好的性能,提高了IOC抽取的准确度。实验结果对比表明,文中模型相比于其他模型在识别准确度上有提升,在中文数据集上有较为良好的表现。最后提出一个KGCP系统,该系统使用ATT&CK技术对威胁情报进行格式转换完成情报推理。基于本体建立了本体与原子本体知识图谱,通过知识图谱关联分析数据之间潜在关联,发现具有相似性和相关性的威胁,完成攻击行为的查询与分析预测。
未来,将首先构建一个平台,该平台能够收集不同数据格式的威胁情报并对其进行关联;然后引入相似度算法进行相似性分析,来表示不同粒度级别威胁之间的关系,将相似性分析整合到平台中,设计出高效的情报检索,提高组织的防御能力。云托管的应用程序容易受到 APT 攻击、Sybil 攻击和 DDOS 攻击,针对这一攻击特点,需要提出新的有针对性的威胁情报共享平台,可以快速检测出混淆的数据以防御上述攻击,提高 CTI 共享平台的有效性和可靠性。
