基于主成分分析和Melkman 算法的选星策略
2023-09-06段吉蔚俞杭华刘会杰
段吉蔚,俞杭华,刘会杰
(1.中国科学院 微小卫星创新研究院,上海 201203;2.中国科学院大学,北京 100049;3.上海科技大学 信息科学与技术学院,上海 201210)
0 引言
随着北斗卫星导航系统(Beidou Navigation Satellite System,BDS)的全面运行,北斗、全球定位系统(Global Positioning System,GPS)、Galileo和Glonass 系统等4 大全球卫星导航系统(Global Navigation Satellite System,GNSS)在轨卫星数量共计已超过百颗[1]。与利用单系统导航定位的方式相比,多系统融合定位可以充分利用多系统的可见卫星,实时可见卫星数量更多、分布更好,有利于提高导航定位服务的精度和可用性。然而,如果将多系统所有可见卫星均用于导航定位计算,虽然理论上定位精度最优,但计算效率降低,对应用终端的资源需求大,且严重影响导航定位的实时性。合适的选星策略可以在保证定位精度的同时,降低计算复杂度,提高导航定位的实时性,增强大多数GNSS 应用。因此,对GNSS 多系统融合导航定位选星策略的研究具有重要的理论和实际意义。
目前,选星算法的研究方向主要有以下3 个方面。1)利用智能优化算法进行选星。文献[2]提出了一种基于灰狼优化(Grey Wolf Optimizer,GWO)算法的快速选星方法,该算法利用自适应收敛因子和信息反馈机制,在局部寻优与全局搜索之间实现平衡。文献[3]提出了一种基于NSGA-Ⅱ算法的多目标快速选星方法,该算法通过不断的选择不同的遗传算子和效用函数做实验,最终选取一组合适的遗传算子和效用函数做出最优的选星决策,并且不依赖于卫星的几何位置分布,可适用于有障碍或者遮挡的复杂情况。文献[4]提出了一种基于K-means++聚类算法的快速选星算法,该方法优先选择仰角最大的一颗卫星后,对剩余卫星进行K-means++聚类算法,然后在每个簇中选择一颗卫星,得到最终的选星组合。以上算法会导致较高的计算复杂度,增加选星所需要的时间,对实时性要求较高的应用场景可能不太适用。2)根据可见卫星的几何空间分布进行选星。文献[5]通过实验发现了可见星的空间分布规律,提出了一种基于卫星高度角和方位角进行分区筛选的快速选星算法。文献[6]根据最佳选星方案的卫星分布特性,通过利用卫星高度角和方位角信息进行区域划分,并引入代价函数筛选中仰角区域的卫星,从而得到最终的选星方案。文献[7]分析了几何精度因子(Geometric Dilution Precision,GDOP),与可见卫星布局的关系,确定各个卫星对GDOP 的贡献值,选择贡献值大的卫星作为最终用于定位解算的卫星组合。3)利用计算几何学中的凸包算法进行选星。文献[8]提出用三维凸包算法进行选星定位,虽然该算法考虑了卫星在三维空间中的分布,能够在选星过程中找到更有利于定位的卫星子集,但是三维凸包算法在计算时的复杂度较高,无法满足实时性的要求。因此为了提高实时性,文献[9]提出将三维卫星数据降为二维,然后利用二维凸包Graham 算法进行快速选星,但是该选星算法将三维卫星数据直接投影到站心坐标系下的水平平面,但可能会忽略高度方向上的影响,导致选择的卫星几何分布不够理想,从而影响定位精度。
综上所述,基于二维凸包算法的选星策略在处理三维卫星数据降维时,常忽略垂直方向的高度位置信息,为解决该问题,本文提出了一种融合主成分分析(Principal Component Analysis,PCA)与二维凸包Melkman 算法的选星策略。该策略利用PCA 技术在降维过程中最大限度地减小信息损失,确保生成的二维数据不仅保留了原始三维数据的水平信息,还包含了高度方向的信息。在后续选星计算中,能更准确地描述卫星的位置信息,其对于选星策略至关重要。此外,本文采用时间复杂度较低的Melkman 算法进行选星计算,以提高选星速度。
1 几何精度因子
GDOP 是卫星导航系统中一个重要指标,其代表卫星导航系统测距误差造成的接收机与空间卫星间的距离矢量放大因子[10]。导航卫星的定位误差的标准偏差δ定义如下:
式中:σUERE为伪距测量误差。
从式(1)可知,在伪距测量误差相同的情况下,导航定位精度完全由GDOP 决定,卫星几何分布越优,GDOP 越小,导航精度越高。GDOP 的推导过程如下:
式中:H为BDS/GPS/GLONASS 中某单一卫星系统观测矩 阵的前3 列;α为导航卫星的 仰角;β为导航卫星的方位角;N为单一系统参与定位解算的卫星的数量。
由于本文选取导航星座中的BDS、GPS 和GLONASS 这3 个系统卫星进行选星,因此这里只考虑BDS/GPS/GLONASS 组合导航系统的观测矩阵:
式中:1x、0x(x为BDS、GPS、GLONASS)分别为k×1 维的全1、全0 向量;k为当前系统x用于定位解算的卫星数量。
则GDOP 可以表示为[11]
GDOP 数值与定位精度的关系见表1[12]。

表1 GDOP 与定位精度的评价关系Tab.1 Evaluation relationship between the GDOP and positioning accuracy
2 基本原理
2.1 主成分分析的原理
PCA 方法的基本思想是通过将数据投影到最大方差的方向上,找到数据中最主要的模式和结构,并且保留尽可能多的信息[13]。利用PCA 算法将三维卫星数据降为二维时,通常需要经过以下步骤[14-16]:
1)对原始数据进行标准化。假设有n个卫星数据样本,每个样本有3 个特征(x,y,z),对于每个特征,计算其均值μ和标准差σ,然后将每个特征的值减去其均值,再除以其标准差,以使每个特征具有相同的权重,将标准化后的数据整理为一个n×3的矩阵Xstd。以特征x为例,标准化的过程可以用以下公式描述:
式中:μ为特征x的均值;σ为特征x的标准差。
2)计算标准化后的数据矩阵Xstd的协方差矩阵S。协方差矩阵可以用以下公式计算:
3)对协方差矩阵进行特征值分解,得到特征值和特征向量。特征值和特征向量可以用以下公式计算:
式中:vi为第i个特征向量;λi为第i个特征向量对应的特征值。
4)选择主成分。将特征值按降序排列,选取前k个最大特征值对应的特征向量作为数据降维后的新坐标系的基向量,组成新的特征向量矩阵Vk。在本文中,由于要将三维数据降为二维,因此k=2。
5)将原始数据投影到新的特征向量上,得到降维后的数据。新矩阵Y的每一行表示原始数据在新特征空间的坐标。
以上5 个步骤的流程如图1 所示。

图1 PCA 算法流程Fig.1 Flowchart of the PCA algorithm
通过遵循上述5 个步骤,可以使用PCA 算法将原始三维卫星数据有效地降至二维空间。由于该新的二维空间中的基向量是原始数据空间的线性组合,且相互正交,因此降维后的二维数据不仅保留了原始三维卫星数据的水平位置信息,还保留了高度位置信息,为后续选星计算提供了一个更精确地描述卫星位置信息的有效方式。
2.2 Melkman 算法原理
凸包的公式表达如下:在一个实数向量空间V中,对于给定集合X,所有包含X的凸集的交集CH(X)被称为X的凸包[17],即:
X的凸包CH(X)可以用X内所有点的线性组合来构造:
二维凸包是将平面上给定的点集用一个最小的凸多边形包围的形状。对于二维凸包的计算,可以使用不同的算法来实现,包括暴力、Graham 扫描、Jarvis 步 进、QuickHull 算 法、Melkman 算法等[18-21]。其中,Melkman 算法的时间复杂度为O(n),其比大多数其他算法(如Graham 扫描法、分治法和Andrew′s Monotone Chain Algorithm)的O(nlogn)时间复杂度更低[22],这意味着在处理二维凸包问题时,Melkman 算法可以更快地找到解决方案。因此本文采用Melkman 算法进行凸包计算。Melkman算法的核心思想是利用Deque 来维护凸包边界上的点。算法的具体步骤如下[23]:
1)对输入数据进行预判断,确保至少有3 个点。如果输入数据少于3 个点,则无法构成多边形,无需计算凸包。
2)初始化双端队列(Double-ended Queue,Deque)。在所有点中找出具有最小x值的点A,然后确定一个处理顺序,例如逆时针方向,计算剩余点与点A形成的向量与y轴负方向的夹角,再根据这些夹角将点集按从小到大的顺序进行排序,最后,将排序后的前两个点(点A和点B)加入Deque。
3)按顺序处理剩余的点,记当前处理的点为C。进行以下操作:①检查队列的头部。如果C与队列头部的前2 个点构成一个右拐(顺时针方向),则队列头部的第一个点出队。重复此操作,直到队列头部的2 个点与C构成一个左拐(逆时针方向)为止。② 检查队列的尾部。如果C与队列尾部的后2个点构成一个左拐(逆时针方向),则队列尾部的第1 个点出队。重复此操作,直到队列尾部的2 个点与C构成一个右拐(顺时针方向)为止。③将点C添加到队列的尾部。
值得注意的是:判断3 点之间的相对方向(左拐或右拐)可以通过计算向量积(Cross Product)来实现。例如,有3 个点A、B和C,那么如果向量AB与向量BC的向量积大于0,则表示点C在AB的逆时针方向(左拐);反之,如果向量积小于0,则表示点C在AB的顺时针方向(右拐)。
4)重复步骤3,直到所有点都被处理。
5)当所有点处理完毕后,Deque 中的点即为凸包上的顶点。从队列头部到尾部,按顺序连接这些顶点,就可以得到凸包的边界。Melkman 算法的流程如图2 所示。
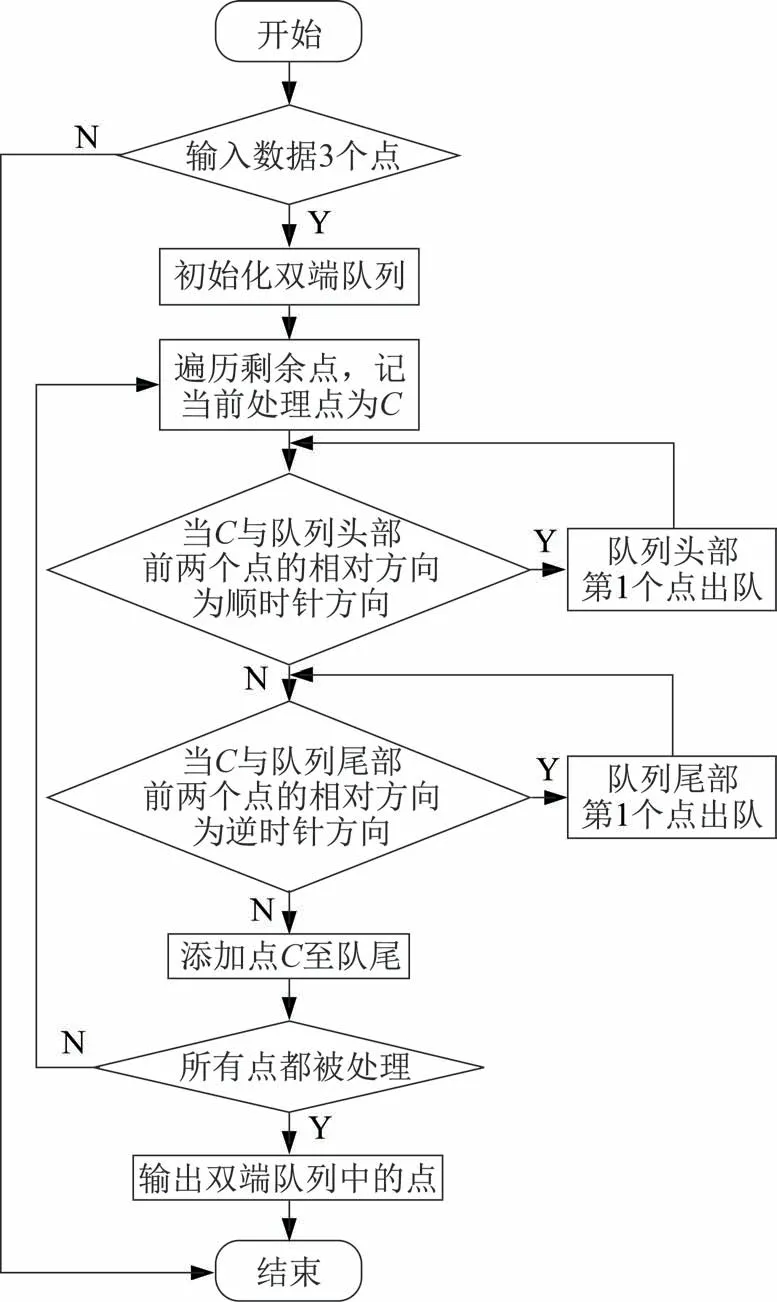
图2 Melkman 算法流程Fig.2 Flowchart of the Melkman algorithm
3 基于PCA 和Melkman 的选星算法
3.1 选星算法执行步骤
本文针对BDS/GPS/GLONASS 三模导航定位系统提出了一种基于PCA 和Melkman 的选星算法,具体实验步骤如下所述:
1)根据卫星广播星历信息,分别计算卫星在BDS、GPS、GLONASS 坐标系统下的坐标、仰角和方位角。虽然3 个导航系统的坐标系统不相同,但是其均为笛卡尔坐标系,可以根据文献[24]和文献[25]将3 个坐标系统一转换到GPS 系统的WGS-84坐标系下进行定位解算。
2)将卫星原始三维数据通过2.1 章分析的PCA 技术投影到新的二维坐标系下。
3)对二维平面的数据进行预处理,筛选掉不在凸包边界上的卫星数据。具体步骤如下:①找到x坐标、y坐标最小、最大的4 个点,分别记为Px-min(xmin,y1),Px-max(xmax,y2),Py-min(x1,ymin),Py-max(x2,ymax),显然,这4 个点都在凸包的边界上。② 将横坐标介于x1和x2之间,纵坐标介于y1和y2之间的点(图3 中的D 区域)从点集中剔除掉,因为D 区域的点不可能在凸包的边界上。

图3 数据预处理的卫星分类Fig.3 Satellite classification for data preprocessing
为了提高Melkman 算法在二维凸包扫描中的优化效果,首先分析了已有凸包扫描结果,发现当卫星位于图3 中的区域D 时,假设该点在凸包边界上,则该点与图3 中已知的4 个凸包边界上的点围成的“凸包”违反了凸包的性质:凸包上的任意2 点之间的线段都完全位于凸包内部或边界上,因此,该假设不成立,可以确定区域D 内的卫星一定不在二维凸包边界上。基于该发现,可以针对卫星数据进行预处理,减少后续Melkman 算法需要扫描的卫星数量,从而提高整体选星效率。
4)对新的二维数据预处理之后,基于2.2 章分析的Melkman 算法找到筛选后的点集的凸包。
5)凸包点即为最终选择用于用户定位解算的卫星,找到凸包点对应的卫星三维数据,计算选星后的GDOP 值。
3.2 选星算法仿真分析
为了验证本文提出选星算法的性能,本文用投影到站心坐标系XOY平面的二维凸包Melkman 选星算法与基于PCA 和Jarvis 步进法的选星算法作为对比实验,对上海市(121.47°E,31.23°N)位置进行选星实验,选取导航星座中的BDS、GPS 和GLONASS 系统的卫星,为保证实验准确性,卫星位置由星历计算得出,同时将卫星的高度截止角设定为5°,仿真实验的起始时间为UTC 时间2023 年2 月26 日00:00:00,持续时间为24 h,每1 h 进行一次采样,共计24 个采样点。选星算法的流程如图4所示。

图4 选星算法的流程Fig.4 Flowchart of the satellite selection algorithm
UTC 时间14:00:00 使用PCA 算法生成的新的二维平面如图5 所示。UTC 时间14:00:00 使 用PCA 算法将原始三维卫星数据投影至新的二维平面的分布如图6 所示。

图5 PCA 算法生成的新的二维平面Fig.5 New two-dimensional plane generated by the PCA algorithm

图6 二维PCA 平面散点Fig.6 Scatter plots in the two-dimensional PCA plane
预处理剔除的无关卫星数量变化如图7 所示。可以发现,无论是投影到XOY坐标系,还是PCA 投影生成的新坐标系下,在大多数时刻都会剔除较多的无关卫星数,在19:00 时刻甚至可以减少18 颗无关卫星数据,可为后续Melkman算法减少了大量的扫描卫星数,提高了整体算法扫描二维凸包的选星速度。
投影到站心坐标系XOY平面的二维凸包Melkman 选星算法和本文提出选星算法这2 种算法的选星数量如图8 所示。可以发现,在大部分时间里,本文所提算法的选星数量要多于投影到站心坐标系XOY平面的二维凸包Melkman 选星算法的选星数量,为后续定位解算提供了更多的观测数据,从而进一步提高定位精度。

图8 XOY-Melkman 与PCA-Melkman 算法的选星数量Fig.8 Numbers of selected satellites obtained by the XOYMelkman and PCA-Melkman algorithms
XOY-Melkman 与PCA-Melkman 这2 种选星算法GDOP 曲线和运行时间曲线,如图9 和图10 所示。PCA-Jarvis 与PCA-Melkman 选星算法运行时间曲线,如图11 所示。3 种选星算法的选星数、GDOP 和运行时间进行列表分析,见表2。如图9 所示,本文所提选星算法在60%的时间里实现了GDOP 小于2,而在其余40%的时间里GDOP 值介于2~3.5 之间,根据表1 中GDOP 与定位精度的关系,说明本文所提选星算法在一天中的60%时间能够达到优秀的定位精度,而在剩下的40%时间能够获得良好的定位精度。相对而言,投影到站心坐标系XOY平面的二维凸包Melkman选星算法仅有25%的时间达到优秀的定位精度。结合图10 和表2,可以发现本文所提选星算法的平均运行时间为0.002 0 s,投影到站心坐标系XOY平面的二维凸包Melkman 选星算法的平均运行时间为0.001 1 s,虽然运行效率降低,但是本文所提选星算法能够实现更优的GDOP 性能,即平均GDOP 性能可以提升0.384 0。结合图11 和表2,本文所提选星算法与PCA-Jarvis 选星算法获取的GDOP 性能一样,但是本文所提算法的平均运行时间却只有PCA-Jarvis 选星算法的三分之一。因此,从选星结果的角度来看,本文提出的选星算法是一种可行的选星策略,可以为实时定位、精确测量等领域提供高效可靠的解决方案。

图9 XOY-Melkman 与PCA-Melkman 选 星算 法GDOP 性能对比Fig.9 Comparison of the GDOP obtained by the XOYMelkman and PCA-Melkman satellite selection algorithms

图10 XOY-Melkman 与PCA-Melkman 选星算法运行时间对比Fig.10 Comparison of the running time obtained by the XOY-Melkman and PCA-Melkman satellite selection algorithms

图11 PCA-Jarvis与PCA-Melkman选星算法运行时间对比Fig.11 Comparison of the running time obtained by the PCA-Jarvis and PCA-Melkman satellite selection algorithms

表2 3 种选星算法卫星数、GDOP 与运行时间对比Tab.2 Comparison of the results of satellite number,GDOP,and running time obtained by three satellite selection algorithms
4 结束语
本文针对二维凸包选星算法在处理三维卫星数据降维过程中对高度位置信息的忽略,提出了一种基于PCA 和Melkman 算法的选星策略。该策略运用PCA 技术在降维时最大程度地减小信息损失,生成的二维数据不仅保留了原始三维数据的水平信息,还包含了高度方向的信息,从而在后续选星计算中能更准确地反映卫星位置。同时,该策略采用时间复杂度较低的Melkman 算法计算凸包,以提高选星速度。实验结果显示,相较于将数据投影到站心坐标系XOY平面的二维凸包 Melkman 选星算法,本文提出的选星算法实现了更优的GDOP 性能,平均GDOP性能提升了0.384 0;相较于PCA-Jarvis 选星算法,本文所提算法的平均运行时间仅有PCA-Jarvis 选星算法的三分之一。因此,本文所提出的选星策略在运行速度和定位精度方面具有明显优势。
