基于集成学习方法的耕地质量评价研究
2023-09-04程桂芳王钰鑫申会诗
程桂芳,王钰鑫,申会诗
(郑州大学数学与统计学院,河南 郑州 450001)
耕地对人类来说具有举足轻重的作用,它是人类生存以及社会发展的必要条件[1-4]。根据土地变更调查数据显示,截止2022年底我国耕地面积约为12 760.1 万hm²,总土地面积在世界上排第3 位[5]。因为我国的人口数量众多,平均每人拥有的土地面积却仅为全球平均水平的1∕3,部分土地损毁污染严重、人多地少、耕地质量水平偏低等问题意味着提升与保护耕地质量的重要性。耕地质量评价是了解区域耕地质量水平、进行耕地资源管理的重要基础。早在1999 年我国就开展了耕地质量定级的工作,耕地质量等级成果的更新工作也在2014年展开,2016年发布的《耕地质量等级》逐渐成为判别耕地质量水平的重要依据[6]。进行耕地质量等级的调查评价工作,摸清耕地地力的变化以及土壤的情况,对指导种植业结构调整、降低生产成本、科学合理施肥具有重要的现实意义[7-8]。
长期以来,国内外学者在耕地质量评价领域采用较广的方法是层次分析法、综合指数法、回归分析法、模糊评价法等[9-15],此类方法具有模型简单、适用性强等特点,但同时也存在评价过程繁琐、主观性较强的问题。在现今这个大数据时代,机器学习技术的出现使得许多传统工作变得更加精准、高效。近年来,部分学者将SVM、BP 神经网络等机器学习技术应用到耕地质量评价领域[16-18]。但当前耕地质量评价工作还存在数据利用化程度不高、相关采集数据筛选不充分、建模应用领域不足等问题。鉴于此,引入特征工程、机器学习[19-20]等方法,建立模型对三门峡市陕州区的耕地质量进行评价,并将评价结果与历史结果进行对比分析,以探究出最优评价模型,为耕地质量评价及更新工作提供些许参考,推动评价更加精准、更加科学。
1 材料和方法
1.1 研究区概况
陕州区位于河南省三门峡市西部,地处黄土高原东部,地势由东峻西坦,南高北低,海拔高度范围在252~1 884 m,气候类型为暖温带大陆性季风气候,日照量丰富,历年平均日照时数为2 354.4 h,气候温和,全年平均气温为13.9 ℃,历年平均降水量为523.8 mm,但是年内分布并不均衡,一般正常年度降雨量基本能满足庄稼生长发育的需要。
1.2 研究流程
针对耕地质量评价属于多分类的情况,且需要满足高精度的要求,Bagging 算法[21-22]的并行集成策略能大大提高模型分类的精度。因此将机器学习算法与Bagging 思想结合,将集成学习Bagging 算法作为耕地质量评价模型的基本框架,采用人工神经网络(ANN)、XGBoost、LightGBM 等算法作为基学习器进行集成,利用投票算法确定最终的预测结果。首先对耕地质量数据集进行处理,包括缺失值删除或填充、数据归一化处理、数值型数据分箱、分类型数据One-hot 编码等,得到能够使机器学习算法使用的入模变量,对于耕地质量评价数据集类别比例不平衡的问题,选择对少数类样本进行过采样的方法降低样本类别的不平衡度,将处理好后的数据分别用ANN、XGBoost、LightGBM 等模型进行训练处理,并利用以ANN、XGBoost、LightGBM 等为基学习器的Bagging 集成耕地质量评价模型进行训练,比较不同模型表现。研究流程如图1所示。

图1 基于集成学习方法的耕地质量评价研究流程Fig.1 Research process of cultivated land quality evaluation based on ensemble learning method
1.3 研究方法
1.3.1 集成学习 集成学习也被称作多分类器系统,其基本的模型框架是先产生多个个体学习器,再依据某种策略方法将所产生的多个个体学习器组合起来,利用组合后的模型来完成学习任务。本研究所用的Bagging 算法是由BREIMA 提出的并行式集成学习算法[23-26],其主要通过尽可能选择相对独立同质的且并行训练的基学习器,利用投票或加权平均等方法输出运行结果。Bagging 算法的基学习器通常倾向于选择使用低偏差和高方差的个体学习器,其降低分类算法的泛化误差方式主要通过减少基学习器方差。
如图2 所示,Bagging 算法是基于Boostrapping的思想,主要从原始数据集上进行T次的随机有放回采样得到T个子集,也就是产生了T个不同的训练集,再利用所产生的训练集分别训练产生T个基学习器,利用投票、加权平均等法则产生最终结果。通过集成并行的策略可以降低模型的方差,因此Bagging 算法的预测精度通常显著高于单个的学习器。基学习器的预测能力决定了它的整体性能,随机采样的过程中抽中每个样本的概率是相同的,因此Bagging 算法具有较强的抗噪声能力。选用ANN、XGBoost 和LightGBM 作为基学习器,通过Bagging思想投票的方法建立集成模型。
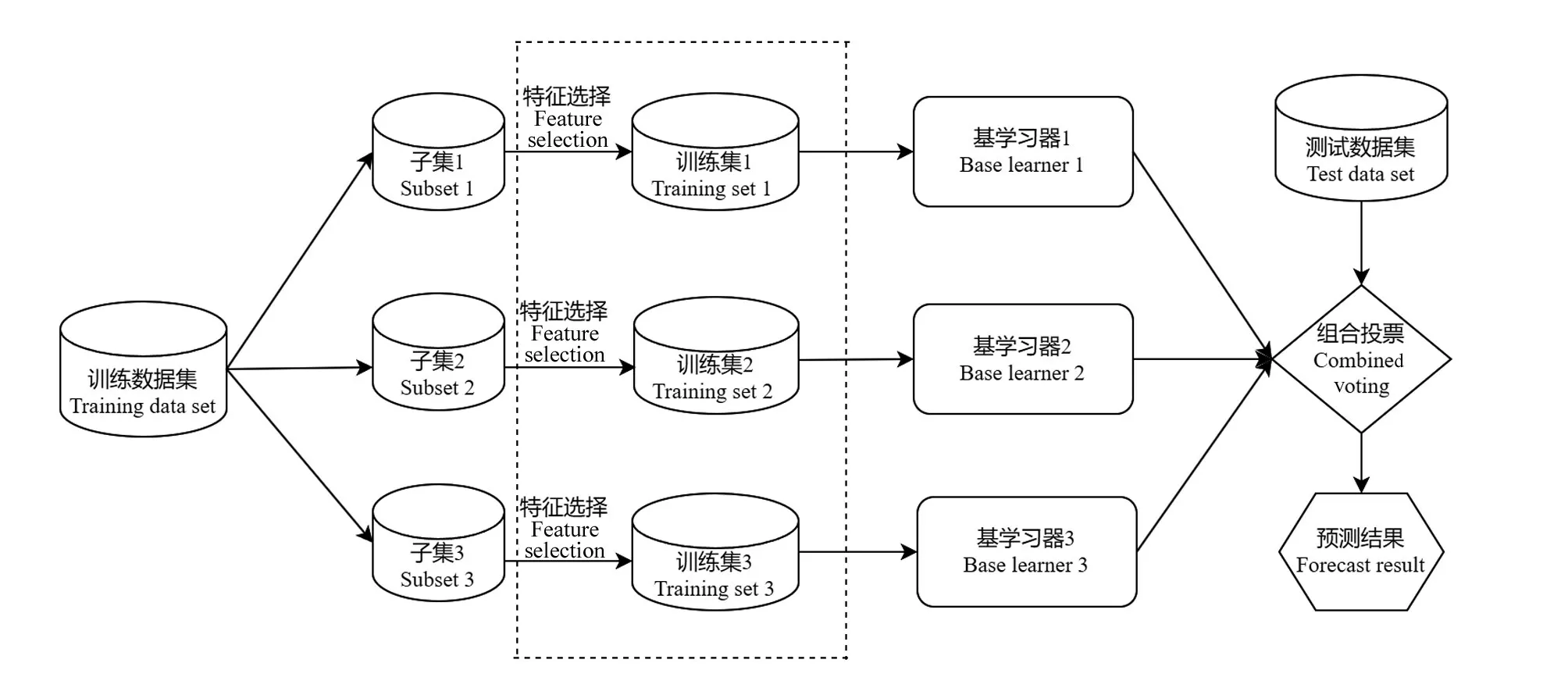
图2 Bagging算法结构图Fig.2 Bagging algorithm structure diagram
1.3.2 ANN ANN 是基于网络拓扑的原理,通过仿真人类大脑的构造和机能,利用神经网络来完成对复杂信息的处理。人工神经网络结构由3个部分组成,分别为输入层、隐藏层和输出层,其中隐藏层既能够是单层也能够是多层。在实际中结合具体问题,神经网络模型的复杂程度也不同,如节点的个数、隐藏层的个数[27]。本研究采用了4 层神经网络模型,其中输入节点数为16,隐藏层共2 层,节点数分别为50、20,输出层节点数为6。
1.3.3 XGBoost XGBoost 算法是先利用均值拟合预测值,计算出残差,训练决策树对计算出的残差进行拟合,得出新残差,重复上述操作,直到残差拟合到设定的精度为止,将训练的决策树模型相加就得到最终的XGBoost 模型,LightGBM 模型也是对XGBoost的优化加强[28]。
1.3.4 数据处理 数据由河南省现代农业研究院提供,查看数据特征,发现特征变量类型主要是int、object 和float 型3 种,其中float 浮点型有5 个,int 型有4 个,object 型有9 个,数据的具体分布如表1所示。

表1 陕州区耕地特征数据变量分布Tab.1 Distribution of data variables of cultivated land characteristics in Shanzhou District
由表1 可知,陕州区耕地特征数据主要包含数值型数据和分类型数据2 种,其中数值型数据有海拔、有效土层厚、土壤容重、pH值、有机质、有效磷和速效钾含量7 种,分类型数据有耕层质地、地形部位、灌溉能力、质地构型、生物多样性、障碍因素、清洁程度、排水能力、农田林网化以及作为目标变量的质量等级共10 种。将数值型数据采取卡方分箱处理,分类型数据采取one-hot编码处理。
数据分箱是特征工程中经常用到的方法,它的作用是减少数据变量的复杂程度,减小噪声对系统的干扰,减小算法的过度拟合,增加了自变量与因变量之间的关联性,从而保证了模型的稳定性。卡方分箱是数据离散化方法基于自下而上的合并区间思想。在该过程中,依据卡方检验的思想把相邻2 个计算所得卡方值最小的区间进行合并,直到满足提前设定的停止准则结束。其基本思想是:针对精确要求的数据分箱,在同一区间内相对类别的频率应完全一致。因此,若2 个相邻的区间类的分布非常相似,那么可以对2 个区间进行合并;否则,它们应该不进行合并,保持分开。而它们之间具有相似类的特征就是低卡方值。
对于数值型的7 个变量,采用卡方分箱(P值为0.05)的方法进行处理。对于分类型变量机器学习中一般采用one-hot 独热编码进行编码处理,其编码方法是对N个状态利用N位的状态寄存器进行编码,每个状态都拥有它对应独立的寄存器位,并且在任意时间,其中只有一位的状态是有效的。因此,对灌溉能力、地形部位、耕层质地等分类变量作one-hot 编码处理,对于上述分箱后的数值型数据,也根据其分箱结果采取one-hot 编码处理,而对质量等级等顺序型变量才用顺序1、2、3…来做编码处理。编码的结果如图3所示。

图3 数据处理后的编码结果Fig.3 Coding results after data processing
由表2 可以看出,其中目标变量耕地质量等级4、5、6数量相对较多,分别为3 548、2 726、13 534个,约占总数量的97.159%,等级3、7、8 数量相对较少,分别为111、404、64 个,约占总数量的2.841%。表示样本数据存在比较严重的不平衡现象,还需要对数据采取进一步处理,否则模型会偏向于预测数目较多的类别,这样即使模型预测准确率较高,但却不具备什么实际意义。

表2 陕州区耕地质量等级分布Tab.2 Quality grade distribution of cultivated land in Shanzhou District
因此,采用合成少数类过采样技术(SMOTE)合成新的少数类样本,结果显示,通过SMOTE 方法合成后的耕地质量等级3、4、5、6、7、8 等均含有13 534个样本,样本数据达到平衡,能够有效地避免在下一步的模型训练和预测中,因为样本不平衡而造成的对于类别数目较少的样本预测评价不准确的现象,提高模型的鲁棒性以及评价的准确率。
1.3.5 评价指标 选用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1 分数(F1-score)4个评价指标,其中,准确率表示预测正确的正例和负例占全部样本的比例,精确率表示正确分类的正类样本数占实际预测为正类样本数的比例,召回率表示正确分类的正类样本数占实际正类样本数的比例,F1分数是精确率和召回率的调和平均。具体计算如公式(1)—(4)所示:
式中:TP表示预测为正类,实际也为正类的数量;FP表示预测为正类,实际为负类的数量;FN表示预测为负类,实际为正类的数量;TN表示预测为负类,实际也为负类的数量。
2 结果与分析
按照7∶3的比例将上述处理过的数据划分为训练集和测试集,分别使用ANN、XGBoost、LightGBM等模型及基于XGBoost-LightGBM-ANN 的融合模型将训练集数据代入并训练模型,然后利用测试集来检验模型的效果,将准确率、精确率、召回率和F1分数等4个指标作为评估指标。
2.1 未采样的模型预测
从表3 可以看出,经过处理后的数据在耕地质量评价单一以及组合模型预测中各指标值均达到了0.97 以上,表明机器学习模型应用到耕地质量评价中产生了良好的效果。单一模型ANN、LightGBM、XGBoost对应的各指标值是递增的趋势,另外基于XGBoost-LightGBM-ANN 集成学习算法得到的各指标值高于其他3 个单一模型,对应的准确率、精确率、召回率和F1 分数值分别为0.997 2、0.983 4、0.989 4、0.986 3。

表3 未采样各模型评价指标值Tab.3 The values of each model evaluation index before SMOTE treatment
2.2 采样后的模型预测
从表4 可以看出,经过采样后的数据在模型预测中产生了明显的效果,单一以及组合模型预测中各指标值均达到了0.99 以上,尤其是XGBoost 以及经过模型融合后的XGBoost-LightGBM-ANN 组合模型预测结果,对应的准确率、精确率、召回率和F1分数值均达到了0.998 3。通过采样后对不平衡数据的处理,使得模型对类别数目较少的样本预测更为精准,提高了模型的泛化能力及预测的准确性,也使得模型的应用价值更加广泛。

表4 采样后各模型评价指标值Tab.4 The values of each model evaluation index after SMOTE treatment
将原始数据带入上述融合后的模型,查看此模型下的混淆矩阵,如表5 所示。由表5 可知,经过模型融合后的XGBoost-LightGBM-ANN 组合模型在评价划分各个耕地质量等级时均较为准确,误差相对较小,且绝大多数的误差都在相邻类别,如4等地被划分为3 等地和5 等地、5 等地被划分为6 等地、7等地被划分为6 等地和8 等地等。这些误差产生的原因可能是模型训练样本数量较少,对一些特殊特征变量覆盖不够导致的,未来可通过增加各类训练样本数量来加以改善。基于Bagging 融合的模型对于耕地质量评价有较好的分类效果,通过采样的方法处理耕地质量评价数据集的样本不平衡现象,可以对分类预测效果带来更好的提升。上述结果显示,陕州区的耕地质量等级分布在3~8等,依照我国耕地质量划分标准[29],1~3 等地为高等地,4~6 等地为中等地,7~10 等地为低等地,计算得出陕州区0.54%的评价单元的耕地为高等地,97.16%的评价单元的耕地为中等地,2.30%的评价单元的耕地为低等地,整体耕地质量以中等地为主。

表5 基于XGBoost-LightGBM-ANN模型的混淆矩阵Tab.5 Confusion matrix based on XGBoost-LightGBM-ANN model
3 结论与讨论
本研究以三门峡市陕州区耕地为研究对象,采用基于Bagging 集成学习的耕地质量评价方法,利用历史已有的评价结果,通过对原始数据进行特征处理,将处理好的数据进行训练,构建高精度且适宜的单一以及组合评价模型。将所需评价的耕地质量数据代入到评价模型中,评价结果显示,陕州区评价单元内整体耕地质量以中等地为主,占比达97.16%,高等地和低等地分别占比0.54%、2.30%。
为了避免数据变量受主观因素的影响,本研究采用特征工程的方法处理耕地特征数据。针对分类型数据采用one-hot 编码的形式,针对连续数值型数据采用卡方分箱的方法离散化处理,并编码赋值。针对样本数据量较大、数据存在不平衡,构建的模型更容易倾向于预测数据较多的类别,实际应用价值较低等问题,本研究采用SMOTE方法合成少数类别的样本,使模型评价更为准确,更具普适性。
考虑到耕地质量评价工作需要达到高精确度的要求,本研究引入机器学习中ANN、XGBoost、LightGBM 等方法,并根据评价结果,通过Voting 投票机制选择ANN、XGBoost、LightGBM等模型进行模型融合建立耕地质量评价Bagging 集成模型,并将预测结果对比分析。对于耕地质量评价数据,将经过卡方分箱、分类数据编码处理后的数据带入模型均产生了良好的效果,尤其是基于Bagging 算法的XGBoost-LightGBM-ANN 组合模型评价效果均优于其他单一模型,这对未来的耕地质量评价模型构建有一定的参考意义。
传统的评价方法适用性强,操作简便,但评价过程较为主观、繁琐,且需要耗费较长时间。采用基于Bagging 组合模型的评价方法只需根据已有数据,通过调整相应参数获得高精度的评价模型,将评价单元代入模型中即可得到耕地等级划分结果。耗费时长较短,且减少了传统方法中层次分析法、特尔斐法等评价方法个人主观因素的影响。基于Bagging 集成学习评价方法在数据量较大的情况下评价结果较为准确,在数据量小的情况下,数据存在一些细微偏差,可以通过调节相应参数获得最合适的模型,或将其运用到地区的耕地质量等级更新中,则能取得更好的效果。
