一种面向法律文书的命名实体识别方法
2023-09-04万玉晴
王 霄 万玉晴
(太极计算机股份有限公司 北京 100102)
0 引 言
近年来,深度神经网络在人工智能多个应用领域表现出了优越的性能,作为自然语言处理重要任务之一的命名实体识别(Named Entity Recognition,NER),也出现很多基于深度学习的研究成果,与传统的基于规则的方法或者基于统计机器学习的方法相比,深度神经网络模型具有更好的泛化性、更少的人工特征依赖等优点,在各领域命名实体识别中得到了广泛的应用。
目前法院对所积累的海量电子卷宗具有结构化、知识化的迫切需求,法律文书命名实体主要包含人名、地名和机构名等通用实体,以及案件名、案由和法律条文等领域实体。法律文书命名实体识别的主要问题在于:1) 不同命名实体之间长度差别大,使得语言表示的语义粒度对模型训练效果影响较大,造成不同命名实体的识别性能差异大的问题。2) 在不同案件类型的卷宗文书中,命名实体的上下文特征具有显著差异,造成模型应用在不同类型案件卷宗上的鲁棒性较差。3) 当前法律文书的标注语料不充足。
针对前两点问题,本文从输入模型的语言表示入手,对不同尺度的嵌入表示,以及结合方式的有效性进行了研究验证,形成涵盖字向量、词向量和主题向量三个语义粒度的语言表示。对于标注语料匮乏问题,文本从模型训练入手,使用一种辅助优化的训练方式,减少模型对人工标注语料的依赖。基于以上研究内容,训练了适用于法律文书的命名实体识别模型。
1 相关工作
命名实体识别是实现信息抽取的主要技术手段,其研究方法种类很多,当前获取很好性能及研究热情的方法是基于深度学习命名实体识别方法。例如:Hammerto[1]使用一种序列自组织图模型SARDNET训练单词表示向量,输入LSTM模型进行命名实体识别。Collobertd等[2]通过训练词向量来完成多个序列标注任务,提出了窗口和句子两种方法,在后者的模型中加入了一层卷积神经网络以获取全局特征。Ma等[3]预训练了词向量和单词的字符级表示,组合了CNN,BiLSTM和CRF进行命名实体识别。Kuru等[4]提出的CHarNER模型,是使用字符级的语义单元输入双向LSTM的技术方案。Huang等[5]系统研究了序列标注任务在多种基于LSTM模型的性能,证明了BiLSTM-CRF模型的健壮性。Chiu等[6]提出了BiLSTM-CNNs的模型架构进行命名实体识别,其中CNNs用来获取字符级的语义特征向量,并与原有的词向量结合,BiLSTM用于NER预测。Lample等[7]提出两种模型用于命名实体识别,第一种是BiLSTM结合CRF的模型结构,另一种是基于转换的分块模型。上述模型均在各种领域命名实体识别的应用中得到过验证,例如:Liu等[8]使用KNN结合CRF的模型在推特文本中进行命名实体识别;李丽双等[9]通过结合深度神经网络构建CNN-BILSTM-CRF模型对生物医学命名实体进行识别;梁立荣等[10]构建层叠条件随即场模型CCRF,用于医院电子病历文本信息抽取获取了较为理想的效果;龚启文等[11]结合循环神经网络设计了BiRNN-CRF算法模型来提取法院命名实体。
基于深度学习的命名实体识别模型通常接受的是数学化的语言表示,即通过Word2vec[12]、GloVe[13]和BERT[14]等方法训练得到的字、词和句等不同语义单元粒度的嵌入向量,向量中包含的语义特征对模型识别性能具有非常关键的影响。因此,一些学者的研究工作是如何获取具有更好语义特征的向量表示,例如:Alexandrescu等[15]提出了一种新型的神经概率语言模型,学习从单词和显式单词因子到连续空间的映射关系,将其用于单词预测。Luong等[16]提出结合RNN与NLM的模型,在学习形态感知的单词表示时,同时考虑其上下文信息。Huang等[17]提出一种新的神经网络架构,通过结合局部和全局文档上下文来学习词嵌入,并通过学习每个单词的多个嵌入,以得到不同语义下的词向量表示。Li等[18]提出了两种组件增强的汉字嵌入模型及其双字扩展,通过对词相似性和文本分类的评估验证了模型的有效性。Chen等[19]提出一种中文字符增强型词嵌入模型(CWE),通过结合词内部信息,解决字符歧义和非组成词的问题。可以看出,大多相关研究关注的重点在于,如何结合外部信息来丰富词向量蕴含的语义特征,但对不同粒度语义单元如何有效结合上关注较少。
2 数据采集与标注
目前针对司法领域命名实体识别任务,还没有数量充分的标注语料集,本文的语料数据主要来源于中国裁判文书网,共计2 200份案件判决书,其中包含民事、刑事和执行三种类型的案件。在实体标注上,本文面向司法领域需求,设定5类命名实体:人名(Nr)、地名(Ns)、机构名(Nt)、案件名(Nc)和法律条文(Nl),采用BIOES方式进行标注,对语料分别进行字标注和词标注,如图1所示。在词标注中使用HanLP开发工具进行分词。

原告/O:/O万∗娟/S-Nr,/O女/O,/O1979/O年/O∗月/O∗日/O出生/O,/O汉族/O,/O户籍地/O浙江省/B-Ns丽水市/I-Ns莲∗区/I-Ns黄∗村/I-Ns ∗∗号/E-Ns,/O 现/O 住/O 陕西省西安市甘亭街道办事处/B-Ns ∗∗村/I-Ns ∗/I-Ns 组/I-Ns ∗/I-Ns 街/I-Ns ∗∗∗号/E-Ns。/O 委托/O 诉讼/O 代理人/O:/O 陈∗/B-Nr 进/E-Nr,/O 浙江∗∗律师事务所律师/S-Nt。/O
在标注方式上,本文采用人工标注和自动标注两种方式,人工标注语料集中包含200份裁判文书,经过人工标注和检验,获取高质量标注语料集。对于另2 000份文书,根据法律文书中一些半结构化特点和关键词典,使用正则表达式和词性标注工具定义了相应启发式规则,例如:当事人姓名和机构名前通常会有“原告”“被告”这样的诉讼地位;地名前通常会有“住址”“籍贯”等词出现;案件名通常由当事人名称和案由名称组合而成;法律条文更是具有典型的结构化特征。基于这些启发式规则开发了相应命名实体的自动标注工具,可以快速获取标注语料集,但其标注质量,尤其在召回率上与人工标注语料相比有一定差距。
3 基于多粒度语义的法律文书NER模型及训练方法
目前被广泛使用NER模型是基于BiLSTM-CRF[5]的网络结构,并在各领域应用中得到验证。本文面向法律文书命名实体识别的3个主要问题,有针对性地对BiLSTM-CRF模型进行改进,并以该模型作为实验对比的基准方法。
3.1 多粒度语义单元的结合方式
本文采集了一个包含400多万份裁判文书的中文语料集,采用Word2vec的Skip-gram模型,分别训练得到司法领域词向量和字向量模型,向量维度均为200维。
根据基准方法BiLSTM-CRF模型在标注语料上的表现来看,使用字向量对较短的命名实体(例如人名)具有更好的识别效果,而对于法律文书中地名、机构名较长的特点,采用词向量效果更好一些。分析主要原因在于:词向量忽略了词内字的语义信息,另外,分词质量对采用词向量的识别结果有很大影响,但另一方面,以单字作为语义单元的歧义性较大,可见词向量和字向量各有优劣,两种语义单元相结合可以包含更全面的信息表示。
另外,不同案件类型的裁判文书中,命名实体的上下文具有显著差异,这种差异特征无法在细粒度语义单元中得到很好的表示,需要结合更大粒度的语义信息。目前句向量的构造通常基于词向量,即句子粒度在语义上和词的作用相近,而且不同类型案件的文书中,大多数句子间的类型差异并不明显,因此从案件类型语义差异上考虑,篇章级的主题信息比句子粒度的语义信息具有更好的补充作用。本文使用LDA[20](Latent Dirichlet Allocation)模型的统计推理过程分别基于中文词和字构建主题模型。
1) 基于LDA模型的主题向量模型,如图2所示。
LDA模型的训练语料是根据设定的主题,从Word2vec训练语料集中筛选出的子集,本文只选取了民事、刑事、执行三类案件的裁判文书,再根据案件审理阶段分为一审、非一审两种情况,设定主题个数为6。Word2vec模型是通过语料中上下文对词或字的语义表示,而LDA模型是针对所选定的主题及对应语料,获取主题在词或字上的语义表示。以词为例,按图2所示构建基于词的主题模型,首先做出以下设定:
θ~Dir(α)
(1)
φ~Dir(β)
(2)
Z~P(θ)
(3)
W~P(Z,φ)
(4)
Dir=f(x1,x2,…,xK;α1,α2,…,αK)=
(5)
式中:θ是裁判文书中主题的概率分布,该分布是服从参数为α的Dirichlet分布的变量,如式(5)所示,α为K维向量,即对于任一篇裁判文书d,其主题分布为:θd=Dirichlet(α);同样设定φ是主题中词的概率分布,该分布是服从参数为β的Dirichlet分布的变量,β为V维向量,V表示文书语料集的词典长度,即对于任一主题z,其词分布为φz=Dirichlet(β);Z是服从θ分布的主题变量,对文档d中的第n个词,可以从θd中得到主题编号zdn的分布:zdn=multi(θd),zdn∈{1,2,…,K};W是服从Z和φ分布的词变量,可以得到词wdn的概率分布:wdn=multi(φzdn),本文设定K=6。基于以上设定,可以得到如式(6)所示的联合概率关系。
P(W,Z,θ,φ;α,β)=
(6)
式中:K为主题数;M为裁判文书数;N为文书中的词数,W是唯一可以观察到的量,Z、θ、φ是中间隐含变量,α、β是需要确定的超参数。对式(6)进一步处理:
(7)
(8)
本文要计算的就是超参α、β的极大似然估计值:
(9)
通过以上方法分别得到了字、词和篇章三种粒度上的语义信息表示,对此,本文提出以下两种结合方式分别获取词向量和字向量。
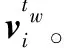
(10)
(11)
式中:i是指词在句子中的位置;j是指字在词中的位置;n是指词的字数。
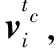
(12)
3.2 BiLSTM-Attention-CRF模型
以上过程确定了模型的输入向量,在模型的结构上,本文在基准模型BiLSTM-CRF中增加了Attention[21-22]机制。BiLSTM可以预测出每个语义单元属于不同标签的概率,但无法感知标签之间的关联性,在BiLSTM上接入CRF,使得模型在计算最优标签序列时,考虑到标签组合的合理性,这种合理性体现在CRF的转移矩阵中。在BiLSTM和CRF之间加入Attention机制,可以在语义单元特征中加入全局注意力信息,为CRF计算最优路径时突出关键词的影响。
(13)
(14)
(15)
得到双向LSTM提取的特征状态值,进入全连接层,该层在基于辅助优化的训练中,具有融合辅助特征到统一维度的作用。
(16)
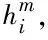
ha=dense(hm)=φ(θahm+ba)
(17)
α=softmax(ha)
(18)
(19)
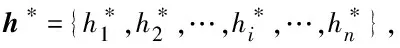
(20)
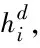
(21)
式中:A为CRF的转移矩阵,P为BiLSTM-Attention输出的标注概率矩阵。可以计算把输入句子x标记为序列y的概率为:
(22)
式中:Yx是句子x所有可能的标注序列集合。根据式(22)得到如下对数似然函数:
(23)
CRF在预测中使用Viterbi算法来求解最优路径,即得到概率最大的一组标注序列:
(24)
3.3 基于辅助优化的模型训练方式
针对司法标注语料匮乏问题,文本采用辅助优化[24-25]的训练方式,借助快速获取的自动标注语料集提高模型性能,减少模型对人工标注语料的依赖。训练过程如图3所示。
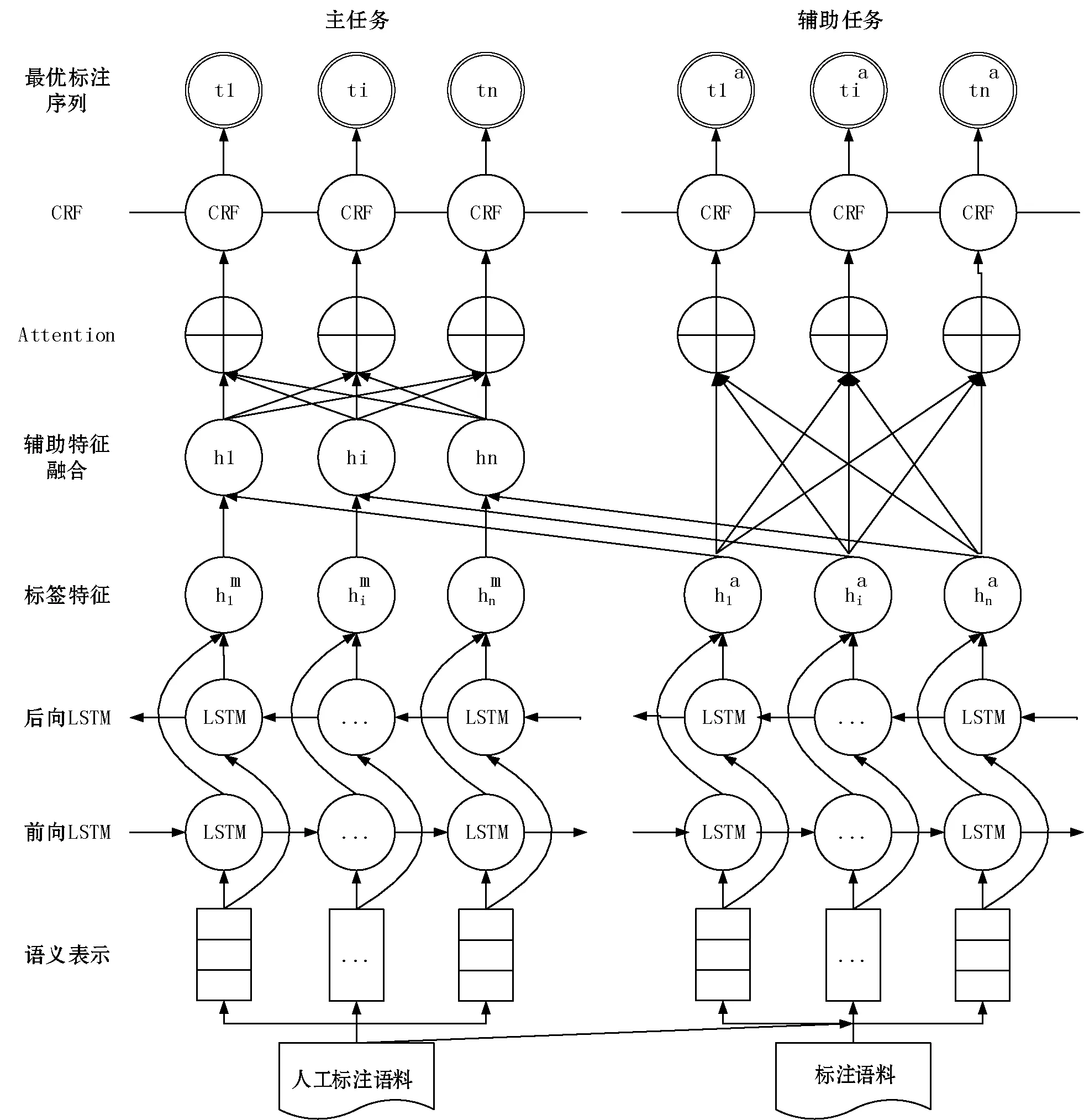
图3 基于辅助优化的模型训练方式
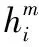
hi,main=BiLSTMmain(xi)
(25)
hi,aux=BiLSTMaux(xi)
(26)
(27)
当输入的句子是自动标注语料时,只执行辅助任务,当输入来自人工标注语料集时,会同时执行主任务和辅助任务,因此训练依据的损失函数是两者损失函数的加权组合,λ是一个可调控的组合系数。对λ在[0,1]区间取值,通过实验对比发现,当λ取值0.65时,本文模型获取最高的F1值,因此设λ=0.65。
lossauxopt=λlossmain+(1-λ)lossaux
(28)
4 实验与结果分析
本文从人工标注语料集中随机选取150份裁判文书作为NER主任务的训练语料,剩余50份用于测试,自动标注语料集中全部2 000份文书用于辅助任务训练。另外,根据句长分布情况,无论以词还是字作为语义单元,模型接收的句子长度设为200。数据集情况如表1所示。
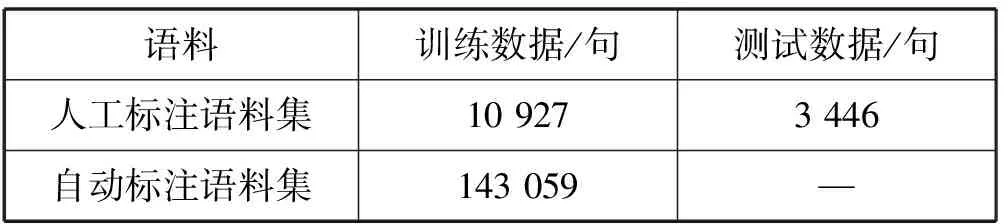
表1 数据集情况
4.1 实验设置
为了验证本文方法的识别效果,实验模型时采用相同数据集,以及相同参数设置,如表2所示。评测采用在NER任务上广泛使用的指标:Precision、Recall和F1。
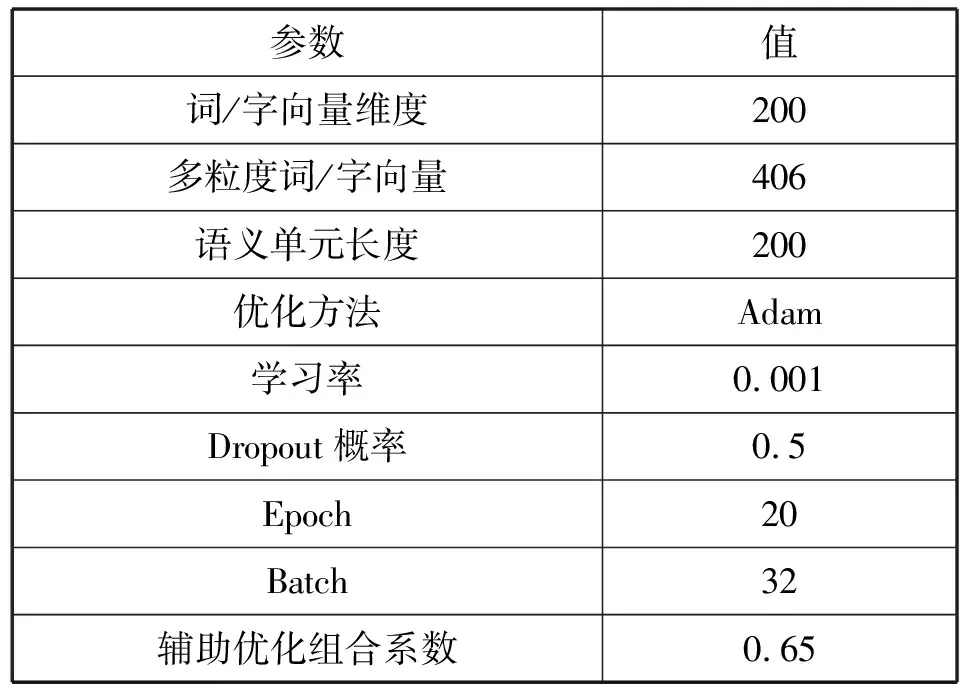
表2 模型参数设置
4.2 结果分析
本文以BiLSTM-CRF为基准方法,对比测试BiLSTM-Attention-CRF网络结构增加辅助优化训练前后的识别效果,分别采用词向量、结合字及主题信息的词向量、结合词及主题信息的字向量,三种语义表示进行测试,结果如表3所示,其中指标是对所有实体识别结果的统计。
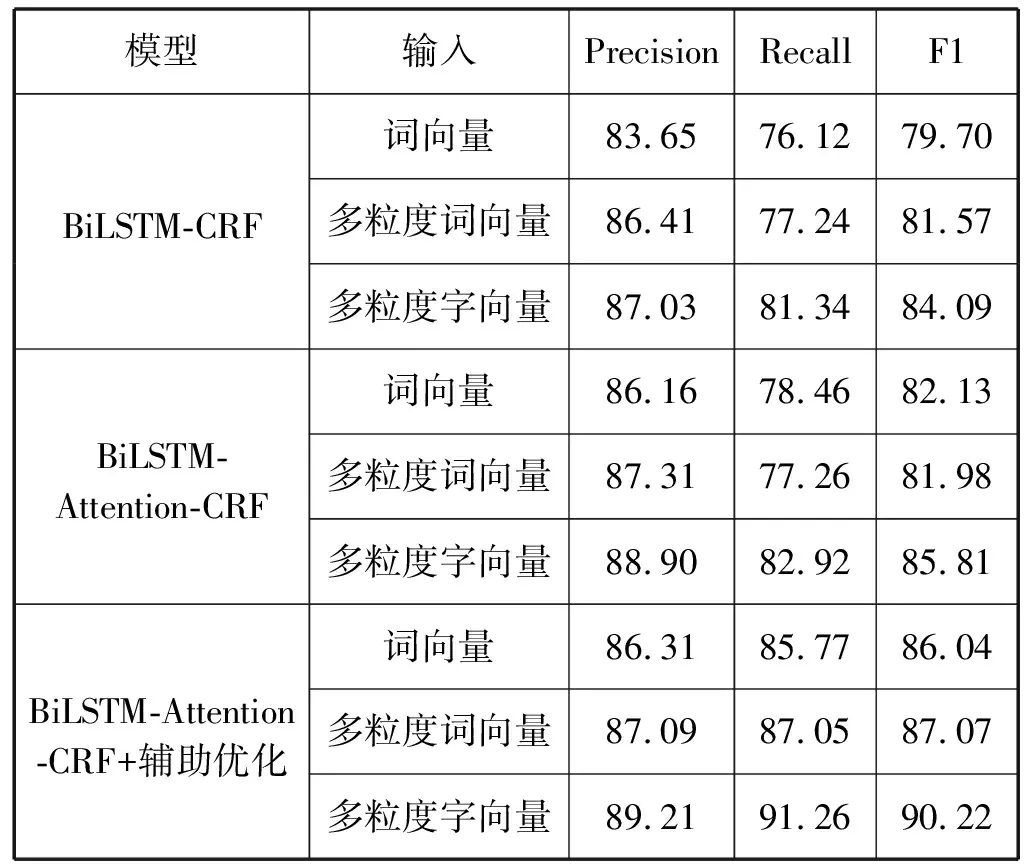
表3 模型结果对比(%)
可以看出,与基准方法相比,增加了Attention机制的模型实验效果更好,根据模型分析,CRF学到的是标签之间的转移概率,而Attention机制在每个语义单元特征中加入全局注意力信息,为CRF计算最优路径时突出句中关键词的作用,弱化非关键词的影响。以表4中的标注语料为例,基准模型对当事人现住地址识别为:“陕西省西安市甘亭街道办事处/B-Ns **村/E-Ns */O 组/O */O 街/O ***号/O”,而增加Attention的模型识别结果与标注语料一致,对比结果分析:语料中存在较多以某村为结尾的地名,使得学习到的基准模型没有标注完整,但Attention机制对后半段地址的强化作用起到了修正的效果。
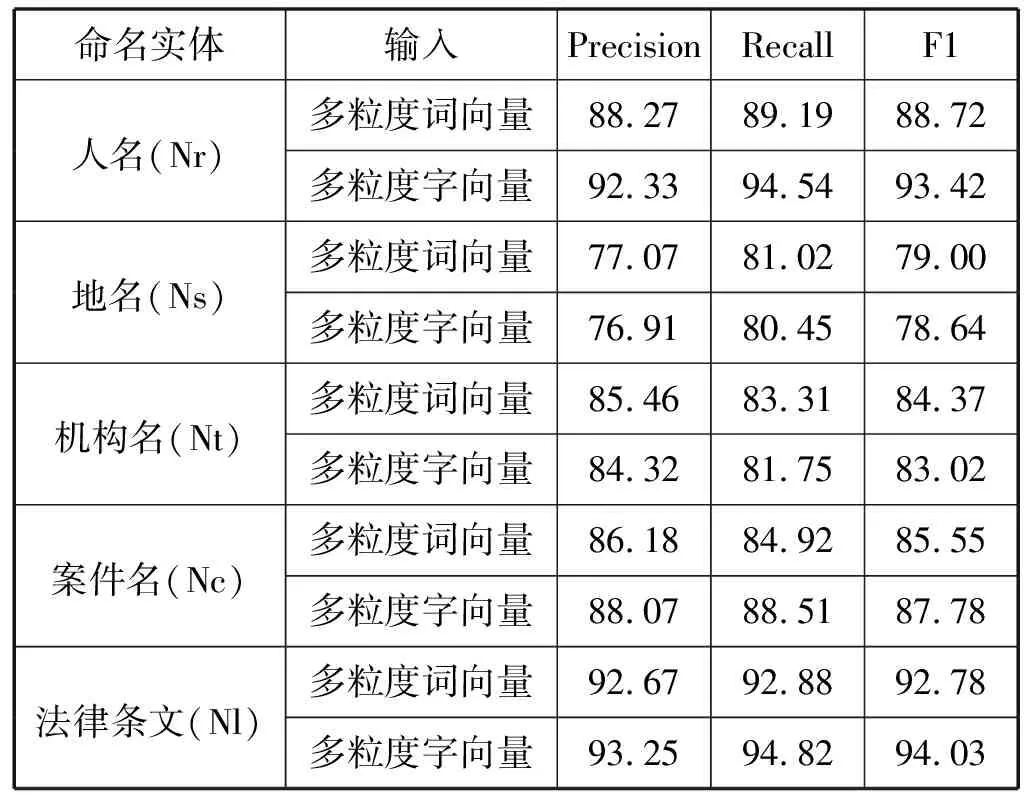
表4 各实体结果对比(%)
另外,从结果可以看出,使用本文提出的结合多粒度语义单元信息的表示方式,实验结果明显由于词本身的向量表示,证明了多个粒度上的语义信息对NER任务的有效性。对本文提出的两种结合方式比较,结合词及主题信息的字向量比结合字及主题信息的词向量具有更好的效果,为了更好地分析原因,采用BiLSTM-Attention-CRF+辅助优化的方式,对本文设定的5种实体类型分别统计指标值进行对比,如表4所示。
从各实体识别结果分析,使用字向量优于词向量的原因主要有三方面:一是法律文书中人名实体较多,这种短实体更适用于字向量,例如基于词向量会把表4中的一处人名标注为“委托/O 诉讼/O 代理人/O:/O 陈*/S-Nr 进O”,而基于字向量得到正确结果;二是在同样规模的语料中,字相比于词具有更短的词典,可以得到更充分的训练;三是分词结果并非完全准确。
5 结 语
本文深入探究了法律文书命名实体识别的主要问题,并针对具体问题提出相应的解决方法。对于识别模型在不同案件类型的文书中鲁棒性差的问题,采用LDA模型获取主题向量,提供篇章级粒度的语义信息。对于语义表示涵盖信息片面的问题,提出了两种多粒度语义单元结合方式:结合字及主题信息的词向量、结合词及主题信息的字向量,为模型输入提供了更全面的语义表示。对于法律文书命名实体识别标注语料不充足的问题,采用基于辅助优化的模型训练方式,减少模型对人工标注语料的依赖。在模型上采用BiLSTM-Attention-CRF网络结构,通过增加Attention机制,为每个语义单元特征中加入全局注意力信息,从而强化了句中关键词对当前标签判断的作用。最后通过实验证明,本文提出的各种优化方法都是有效的,在现有分词工具的性能基础上,采用结合词及主题信息的字向量作为BiLSTM-Attention-CRF模型的输入语义表示,可以获取最好的识别效果。
虽然本文在模型结构、输入表示、训练方式进行了优化研究,但在具体参数上还可以进一步通过细化实验,对最优方案进行深入研究,比如在多粒度语义单元的结合方式上,本文采用的是浅层结合的方式,可以尝试如CNN和RNN这类深层结合方式进行对比测试。另外,辅助优化语料数量对主任务影响的关系,也需要进行更深入的研究。
