基于谱聚类的多维数据集异常子群挖掘方法
2023-09-04康耀龙冯丽露张景安
康耀龙,冯丽露,张景安
(1. 山西大同大学计算机与网络工程学院,山西 大同 037009;2. 山西大同大学,山西 大同 037009;3. 山西大同大学计算机网络中心,山西 大同 037009)
1 引言
多维数据集中的异常数据深度挖掘,是实现数据集中数据有效利用的基础,多维数据集是一种结构,包含多种维度和度量值,前者是实现多维数据结构的定义,后者则是将数值或者数据提供给感兴趣的用户。所有的多维数据集均有自己的结构,该结构是一种多种数据表集合,位于传统数据仓库中[1]。异常子群指的是符合特定条件下的子群,即为在多维数据集切片内存在的部分频繁项集,其可能不是整个结构的频繁项集[2]。分析多维数据集时,以用户需求为依据,确定上述异常子群,但是在确定过程中,由于数据集的维度存在变化性,处于不断增加状态,导致异常子群的获取难度增加。谱聚类是以谱图理论为基础的一种聚类算法,其在解决多形状样本空间聚类方面具备显著优势,可完成全局收敛,获取最佳聚类结果[3]。
异常子群挖掘方法在挖掘过程中,受到多维结构的影响,导致挖掘结果均存在局限性,甚至无法完成高维度目标的挖掘。肖文[4]等人提出了基于数据集稀疏度的挖掘方法,丁建立[5]等人提出了基于时间序列的挖掘方法,各自通过对差异度进行度量和异常聚类实现目标挖掘,但是,两者均在挖掘深度上存在相对不足,导致挖掘结果存在一定的差异性。因此,本文研究基于谱聚类的多维数据集异常子群挖掘方法,依据用户指定的参数,完成多维数据集中的异常子群准确挖掘。
2 基于谱聚类的多维数据集异常子群挖掘
基于谱聚类的多维数据集异常子群挖掘由两部分完成,第一部分是预处理,通过对数据进行脱机计算,获取数据集中存在的部分候选子群;第二部分是异常子集挖掘,基于L1范数的约束谱聚类算法挖掘候选子群,获取挖掘结果。
2.1 多维数据集预处理
设D表示多维数据集,其为给定状态;C和Z均表示阈值,依次分别对应覆盖率和支持度;A表示属性集,属于用户输入,以其为依据,将D中的所有子群返回[6]。
在C中的显著子群即为构成异常模式的子群,S表示特定的显著子群;|tidset|和tidset分别表示编号的数量和集合;S的覆盖率用cou(S)表示,则结合C的概念得出:|tidset(S)|=cou(S)×|D|;所以,新生成的S是否为显著子群的判断,可通过|tidset(S)|≥mincoou×|D|完成。
基本选择器ei生成:ad表示离散属性,其属性值则用υd表示;则ei为(ad=υd)。连续属性用ac表示,由于无法对ac中形成的各个属性均生成一个(ad=υd),所以,需使其形成离散化区间,其通过划分手段完成,且划分的总数量用L表示,即{[l0,l1),[l1,l2),…,[lL-2,lL-1),[lL-1,lL)},在此基础上,完成相应的ei生成,同时构建ei对应的tidset;|tidset(ei)|≥mincoou×|D|,使ei完成一阶子群的形成,且Si=ei标准;基于此可得:|tidset(Si)|=|tidset(ei)|≥mincoou×|D|,此时D中所有的一阶显著子群即为生成的同阶子群。
为保证可靠获取显著子群,采用属性集子组元组概念建立显著子群索引;该概念存储于k阶子群文件中,其包含两部分,分别为属性集相同的子群和该属性集自身[7],且前者属于相同k阶。k阶子群文件中的各个索引均由k阶属性显著子集ASk和各属性集子组构成,且后者的属性集需为ASk;在此基础上,获取所有子群。基于上述分析可知,各个属性即表示各个维度,其只可具备一个属性值[8]。如果ω表示ei的属性数量,则0≤k≤ω。
设Imn表示新形成的项集,|tidset(Imn)|的计算通过diffset完成,其公式为
diffset(Imn)=diffset(In)-diffset(Im)
(1)
|tidset(Imn)|=|tidset(Im)|-diffset(Im)-diffset(In)
(2)
式中:In和Im均为项集,两者前k-1个项为相同项,Imn=Im∪In。
新形成的子群Smn与Imn可完成相同属性以及属性值的共享,则tidset(Smn)=tidset(Imn);由于tidset是diffset计算的依据,可得diffset(Smn)=diffset(Imn)。基于此,Smn是否是显著子群的判断,可依据diffset完成,求解|tidset(Smn)|的公式为
diffset(Smn)=diffset(Sn)-diffset(Sm)
(3)
|tidset(Smn)|=|tidset(Sm)|-diffset(Sm)-diffset(Sn)
(4)
通过上述方法获取每个生成的显著子群Smn后,以其ad和υd为依据,完成编号(sid(Smn))的形成,在此基础上,完成索引diffset(Smn)和|tidset(Smn)|的建立,同时,通过迭代获取上一层子群的diffset和|tidset|,由此获取D中存在的部分候选子群Si。
2.2 异常子群挖掘
2.2.1 算法原理
本文采用属于半监督谱聚类算法的基于L1范数的约束谱聚类算法完成异常子群挖掘。
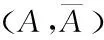
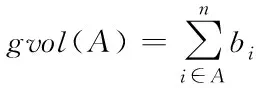
(5)
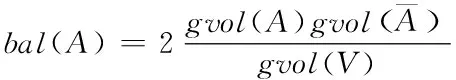
(6)

设式(6)为划分准则,即
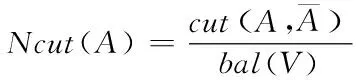
(7)
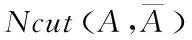
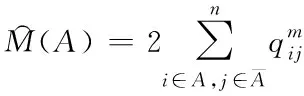
(8)
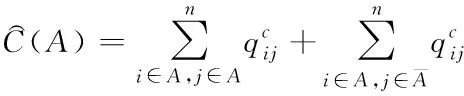
(9)
为获取软约束归一化划分函数,结合式(7)、(8)、(9)完成,得到
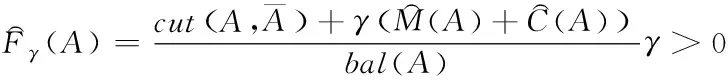
(10)

(11)
参数γ可通过自身大小的调整用于权重的控制,且该权重属于归一化划分和冲突约束[10]。为保证划分结果为最佳结果,采用连续放松代替式(10),则约束冲突代价计算公式为
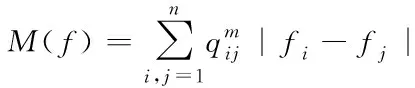
(12)
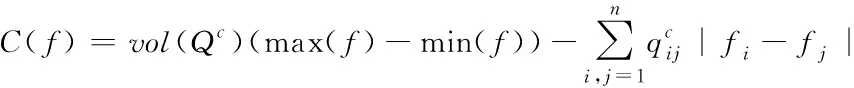
(13)
式中:指示向量用f表示,用于划分,其最大和最小值分别用max(f)和min(f)表示。最优划分结果可通过式(12)(13)获取。
对归一化划分进行约束的代价函数计算公式为


(14)
式中,对角矩阵用B表示。
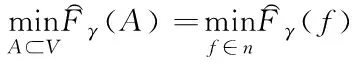
(15)
设

(16)
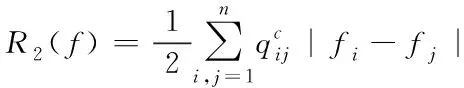
(17)
则可获取代价函数的计算公式为
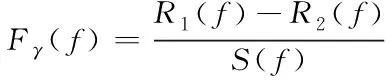
(18)
通过式(18)即可获取Fγ(f)的结果,该结果即为挖掘最优解。
2.2.2 多维数据集异常子群挖掘流程
结合候选子群的类别多样化特征,对异常子集的挖掘,也可看作是对多类别的候选子群进行聚类。为保证挖掘效果,实现不同类别候选子群的最佳聚类,将该聚类采用多类别的归一化图划分替代。在该过程中,采用整合方式对正约束点进行处理,并对顶点的度和边进行重现定义,以此保证全部的正约束和划分不会发生冲突,实现约化图的形成,完成候选子群的挖掘,即完成异常子群挖掘。
1)输入:候选子群Si(i=1,2,…,n)、其类别数量k、正负约束。
2)对相似度矩阵进行求解。
3)求解矩阵B。
4)为生成约化图,对正约束顶点进行合并处理。
5)对步骤2)、3)进行更新处理。
6)采用二分类对全部的簇进行划分处理。
7)求解代价函数,为经过划分的多类划分。
8)在多类划分函数中,采用划分手段对其中最小的函数进行处理。
9)对形成的簇进行判断,如果为K个,则直接输出结果;反之回转步骤6)。
10)输出聚类簇。
3 测试分析
为分析本文方法在多维数据集异常子群挖掘中的应用性能和效果,选取Wine数据集为测试对象,该对象内共有三类样本数据(采用1、2、3进行编号),数据集中共有样本数量178个,各类样本数量依次分别为59个、71个和48个;十三种特征,其中各个特征均表示相对应的成分含量。测试采用Matlab2016b仿真软件完成。
3.1 最佳阈值确定
候选子群的选择,需确定支持度最佳阈值,以候选子群选择过程中所需的计算开销作为衡量标准,选取开销最小的阈值为最佳阈值,结果用图1描述。

图1 最佳阈值测试结果
对图1测试进行分析后可得:在不同阈值取值情况下,所需开销呈现变化状态,当阈值取值为0.5时,开销最小,仅为0.27s。因此本文最佳支持度阈值设定为0.5,并用于后续所有测试。
3.2 挖掘性能和效果测试
采用挖掘准确率、标准化互信息作为衡量本文方法的指标,前者用于衡量方法的效果,后者则用于衡量方法的性能,其取值范围为[0,1],越接近1表明性能越好。两者公式分别为
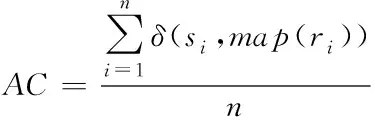
(19)
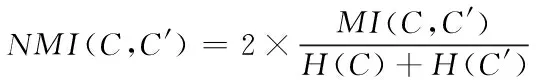
(20)
式中:准确率用AC表示;si和ri均表示标签,分别对应真实结果和计算结果;C和C′均表示标签集合,分别对应实际结果和计算结果;C和C′的互信息用NMI(C,C′)表示;C和C′的信息熵分别用H(C)和H(C′)表示。
为分析本文方法的挖掘性能,以式(19)、(20)为依据,测试本文方法在约束数量变化情况下准确率、标准化互信息的变化情况,结果用图2描述。

图2 测试结果
对图2进行分析后可得:监督约束数量的增加,本文方法的准确率和标准化互信息随之增加,监督约束数量越多,本文方法的性能越佳,越可保证异常子群挖掘的效果,因此,为保证本文方法的挖掘效果,需保证其监督性能较好,约束数量设定在320以上。
为直观衡量本文方法的优劣,将基于数据集稀疏度的方法(文献[4]方法)和基于时间序列的方法(文献[5]方法)作为本文方法的对比方法,完成对此测试。
为分析本文方法的优劣,根据式(19)、(20)测试三种方法在不同近邻点数量下的准确率、标准化互信息的测试结果,用表1描述。
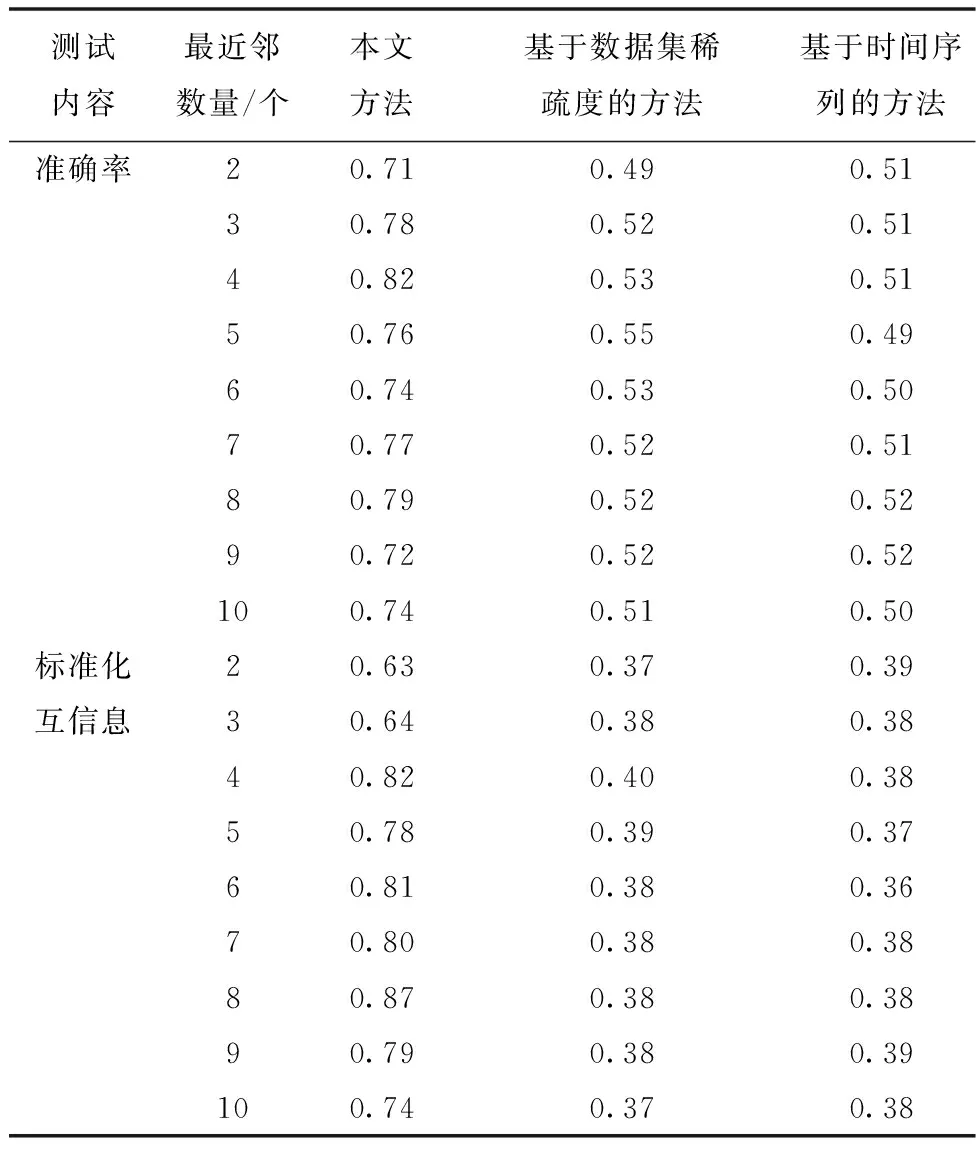
表1 三种方法测试结果
对表1进行分析后可得:在不同最近邻数量本文方法的准确率、标准化互信息值均为最佳,表明本文方法的效果和性能均优于两种对比方法,可保证在良好的性能下实现多维数据集异常子群的准确挖掘,这是由于本文方法可直接对多维数据集内的显著子群进行计算并建立候选子群,使挖掘性能显著提升。
本文以第2类数据作指定需求数据,采用三种方法分别对目标对象进行挖掘,统计三种方法的挖掘效果,以此定量分析三种方法的挖掘效果,用图3描述。

图3 三种方法的对比结果
对图3进行分析可得:三种方法在对多维数据集进行挖掘中,挖掘数据量增加,表示数据集的维度在增加,在此情况下,文本方法的挖掘性能稳定,维度的增加对方法的挖掘效果并没造成影响;但是两种对比方法则在维度的增加下,挖掘效果逐渐降低,当样本数量超过121时,两种方法则无法继续深度挖掘。
表明本文方法具备更佳的多维数据集异常子群的挖掘效果,可实现数据深度挖掘,且稳定性较好。
4 结论
由于多维数据集的多维特征,导致用户想对其内的信息数据进行调取或者查看时,无法实现数据的深度挖掘,影响数据调取或者使用情况,因此,当在用户确定数据类别或者指定的情况下,其所需的目标数据即可用异常子集描述,为了完成该类数据子集的挖掘,本文提出基于谱聚类的多维数据集异常子群挖掘方法,该方法以候选子群的选取为基础,通过谱聚类方法完成特定情况下的异常数据子群挖掘。并通过相关测试表明:本文方法具备良好的异常子群挖掘性能以及效果,在标准化互信息值较高的情况下,实现指定的情况的异常数据子群挖掘。
