基于风险轨迹的开源软件安全性缺陷定位方法
2023-09-04周金宇金超武
王 强,周金宇, 金超武
(1. 金陵科技学院信息化建设与管理中心,江苏 南京 211169;2. 金陵科技学院机电学院,江苏 南京 211169;3. 南京航空航天大学机电学院,江苏 南京 210016)
1 引言
精准的缺陷定位可以帮助工作人员及时发现和修复问题,在一定程度上降低系统维修的费用。目前对于缺陷定位最常用的两种算法是静态和动态缺陷定位法。静态缺陷定位法仅分析软件程序中缺陷报告和源代码,即可对缺陷定位;动态缺陷定位法则是监控程序执行过程中每一个轨迹,分析每一个轨迹的数据点和断点,找出潜在风险位置。
文献[1]利用方法级别细粒度对软件缺陷进行静态定位,将词向量和TF-IDF算法结合在一起,将缺陷报告中的源代码以向量的形式展现出来;再计算源代码中方法体间的相似度,实现对向量的拓展;经过拓展后,根据余弦距离对方法体和缺陷报告排序,确定缺陷可能存在的位置;文献[2]凭借条件分类可执行切片算法实现对软件中缺陷的有效动态定位,在CESS-MFL中选取不同的谓词条件,并划分为若干个不同的类别;利用相关执行切片对每个类别建立相应的特征集,再为每个特征集选取合适的分类执行切片谱;计算每个切片谱的可疑度,得到可疑度报告,实现对软件缺陷的定位。
但上述两种方法面对不同类型开源软件时,缺陷定位结果误差较大,为此,本文提出一种基于风险轨迹的开源软件安全性缺陷定位方法。
2 开源软件缺陷报告问题描述
将开源软件的程序集[3]定义为P={s1,s2,…,sm},T={t1,t2,…,tn}表示测试用例集,tn表示程序中的第n个测试用例。测试用例由输入项di和预期结果oi两部分组成,即tn=(di,oi)(1≤i≤n)。在P中运行一次tn得到的结果为oi′=P(di),当oi′=oi时,说明测试用例通过程序的验证,将该用例称为通过的测试用例;当oi′≠oi时,说明测试用例没有通过程序的验证,称其为未通过的测试用例。P运行一次tn,可用执行轨迹trn来表示。当P执行完所有的tn后,得到执行用例集T和执行轨迹集Tr,两个集合中的元素存在相互对应的关系。
根据P的执行结果,可以将T分为两个无关联的集合Tp和Tf,二者分别表示通过和未通过的执行测试用例集合。同样地,Tr也被分为集合Trp和Trf,分别表示测试用例通过和未通过执行所构成的执行轨迹集。将上述四个集合用式(1)进行描述
Tp={tn≥|P(di)=oi}
Tf={tn≥|P(di)≠oi}
Trp={trn|tn∈Tp}
Trf={trn|tn∈Tf}
(1)
运行在程序中的任意一个语句块[4]都有可能存在缺陷,因此在软件试运行阶段,开发人员和用户会根据试用情况提交缺陷报告,对这些缺陷报告进行分析,帮助后期更快地实现缺陷定位。本文从Eclipse3.1整理了部分缺陷报告,如表1所示。
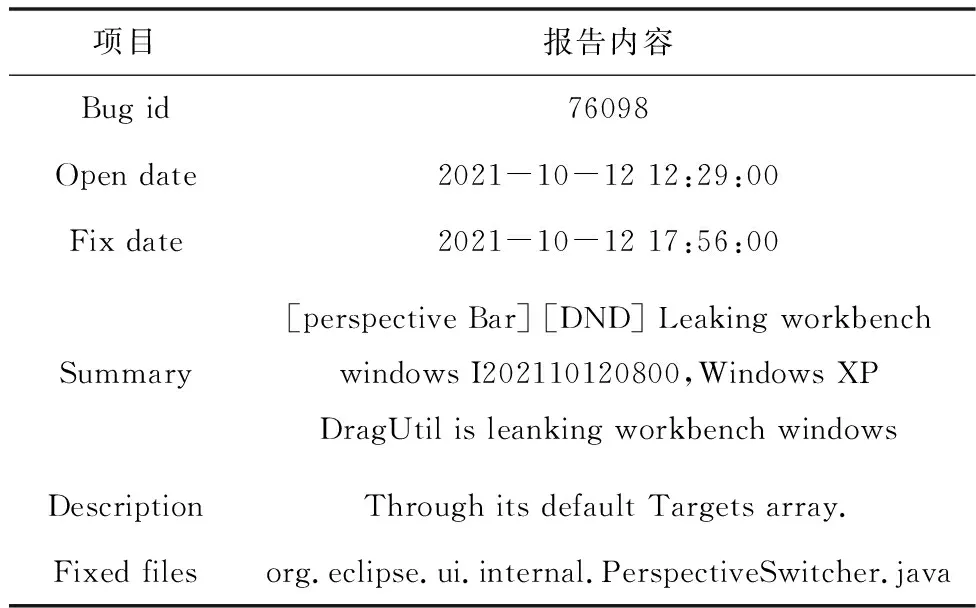
表1 开源软件部分缺陷报告
表1中,Bug id代表的是缺陷报告的名称信息;Open date表示缺陷报告最终提交的日期;Fix date代表了缺陷报告最后一次修改的时间;Summary中描述了缺陷报告的大体内容和展现形式;Description描述了缺陷报告中的具体内容;Fixed files表示软件缺陷定位模板[5]。通过分析Summary和Description二个部分,得到Fixed files,进而确定软件中缺陷所在的位置。
3 获取程序风险轨迹
3.1 获取函数调用序列
函数调用序列(FCS)指的是特定输入环境下,程序调用函数关系的所有信息。本文主要对FCS中3个主要部分进行分析:函数之间的调用关系、函数之间的调用次数以及函数之间的调用时间先后顺序。
分析函数之间的调用关系,定义FC=a→b[calls="count"],其中,a、b分别表示主调函数和被调函数[6],a→b表示a调用b,calls="count"表示a调用bcount次。函数调用序列过程如图1所示。
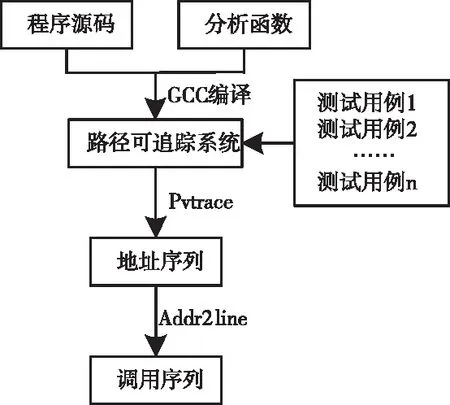
图1 函数调用序列动态过程
3.2 提取风险轨迹
在P上运行T={t1,t2,…,tn},将预期输出结果定义为on,实际输出结果定义为pn,tn是否通过P的执行作为判定目标序列[7]和可疑序列的条件。
1)目标序列:当on=pn时,说明P执行tn通过,得到目标序列Scorrect。
2)可疑序列:当on≠pn时,说明P执行tn未通过,得到可疑序列Sdoubt。
3)风险轨迹:将Scorrect和Sdoubt进行对比,选取目标不一致的序列,构成集合为风险轨迹集Trisk。
通过对比Scorrect和Sdoubt找出程序中的风险轨迹,提取其中的特征信息,即可构建可疑函数集[8],再对其进行检测,就可定位到软件中缺陷的准确位置。在后续进行回归测试时,将多个包含缺陷的软件来执行同一个测试用例,如果出现一个软件版本成功、其它软件版本失败的情况,以成功的软件版本程序内函数调用序列作为目标序列。
3.3 风险轨迹分析
针对软件中缺陷的风险轨迹,本文深入分析函数之间的调用关系、调用次数和调用时间顺序三个方面。举个例子,当Scorrect、Sdoubt二者在调用关系上存在不同时,则说明软件模块的主调函数极有可能出现了缺陷;当Scorrect、Sdoubt二者之间的调用时间顺序不相同时,说明软件模块的调用序列可能出现了缺陷;当Scorrect、Sdoubt在上述三种关系都出现了不同时,不考虑调用时间顺序的影响,直接对调用关系和调用次数进行分析,软件模块也很大可能是由于二者不一致而导致缺陷的出现。
当对软件模块测试后,得到Scorrect和Sdoubt,凭借Linux文本比对促使diff找出软件中缺陷的风险轨迹,diff通过找出Scorrect和Sdoubt二者之间的不一致序列,然后标记,标记的情况通常分为三种:①将Scorrect和Sdoubt之间不一致的序列标记为“|”;②将Scorrect和Sdoubt之间不一致的序列标记为“<”或“>”;③没有标记。
在软件模块调用序列中提取可疑函数fsuspect,并根据其位置的不同进行排序,得到可疑函数候选集Tsuspect={fsuspect1,fsuspect2,…,fsuspectn|n≥1}。依次对候选集中的数据进行检测,确定软件的缺陷函数[9]。
4 开源软件安全性缺陷定位
在综合考虑了开源软件中序列风险轨迹类型和调用关系,本文选取TPA方法作为实现方法。TPA方法分为风险度传播和标签传播两部分,从历史缺陷报告中获取已经成功修复的缺陷,构成初始标签矩阵L0,再对标签矩阵构建初始风险度向量R0,据此两个条件,设计风险度传播图(SG-SC和CG),通过对图中传播模块的风险度进行分析,得到风险度向量R。最后确定缺陷报告标签L,对标签值进行分析,即可实现开源软件缺陷的准确定位。
4.1 风险度传播计算
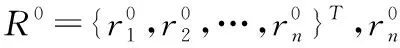
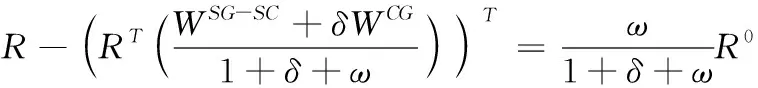
(2)
式中,δ和ω均表示正则项。
为了使式(2)达到最小值,对其进行求导计算[13-15],如式(3)所示
ω(R-R0)=0
(3)
对δ和ω进行代换,得到
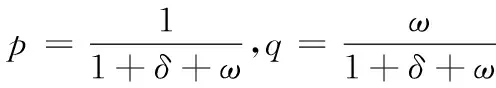
(4)
对式(2)进行收敛,得到:
RT=(1-p-q)(M-pWSG-SC-qWCG)-1R0T
(5)
式中,M表示单位矩阵。
计算每一轮的风险度传播公式,如式(6)所示
Ri+1=(pWSG-SC+qWCG)RiT+(1-p-q)R0
=(p+q)W′RiT+(1-p-q)R0
(6)
4.2 标签传播及安全缺陷定位


(7)
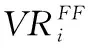
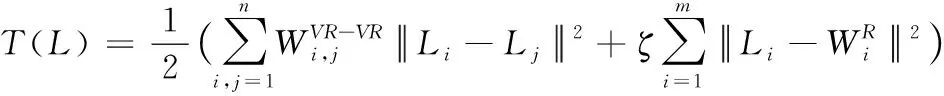
(8)
式中,ζ表示正则项。
对式(8)做最小化处理,得到
Ln+1=(1-η)WVR-VRL+ηWR
(9)
通过上述计算,得到开源软件标签分布情况,根据其在模块中的位置对其进行排列,当标签值越大时,该模块中存在缺陷的概率就越大,以此实现缺陷的精准定位。
5 实验分析
5.1 实验环境和实验数据
为了验证本文方法在开源软件缺陷定位中的有效性,与引言中提到的细粒度和条件分类可执行切片算法展开对比实验。实验在开源软件Linux上实现,系统内存大小为8GB,CPU频率为2.7GHz。实验中用到的数据集为Eclipse3.1、AspectJ1.5和SWT3.1,介绍如表2所示。

表2 数据集信息
5.2 算法评价指标
为了验证三种算法在缺陷定位方面的有效性,实验中选取了前N排名(top N rank)、平均准确率(MAP)以及平均倒数排名(MRR)三个指标作为算法有效性的评价指标。
1)前N排名(top N rank)
该指标表示缺陷报告中缺陷的定位方法,在返回结果的前N(N=1,5,10)位中所占的数量比例。在使用该项指标评判缺陷定位效果时,对于给定的缺陷报告,如果在前N个结果中含有1个缺陷定位的方法体,那么就认为算法成功定位到缺陷。top N rank的值越大,说明算法的缺陷定位方法越精准。
2)平均准确率(MAP)
该指标指的是对开源软件中缺陷部位实现定位后,得到准确率的平均值。对于软件中单独一个缺陷,通过式(10)计算其平均精度AvgP
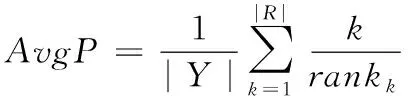
(10)
式中,Y表示算法对软件中的缺陷进行定位后,构成的源代码方法体集合,|Y|表示共获得的源代码方法体总数,rankk表示第k个正确定位的源代码方法体在总数中的排名。MAP公式为
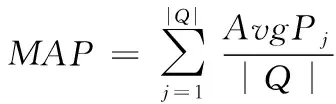
(11)
式中,Q表示开源软件的缺陷报告集,|Q|表示Q中含有缺陷报告的个数,AvgPj表示第j个缺陷报告的平均精度值。
3)平均倒数排名(MRR)
该指标指的是正确定位缺陷的方法体位置倒数平均值。当MRR的值越大时,说明算法的定位精度就越高。计算过程如式(12)所示
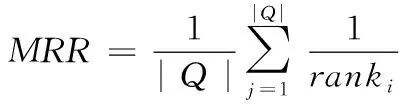
(12)
式中,ranki表示算法定位到的缺陷与第i个缺陷报告中的方法体最靠前排名的位置。
5.3 三种算法有效性对比
首先,对于前N排名指标,对比本文方法与细粒度和条件分类可执行切片算法的有效性。选取TOP1、TOP5和TOP10的平均准确率,实验结果如图2所示。
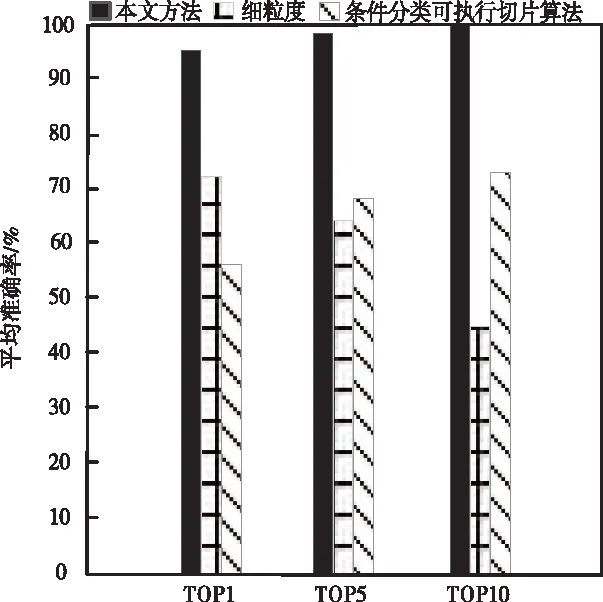
图2 三种算法前N排名平均准确率对比
从图2中可以看出,三种算法中本文方法的平均准确率最高,在TOP10准确率达到了100%,而其它两种方法最高准确率仅为70%。由此说明本文方法在缺陷定位方面具有较高的准确率。
接下来利用平均倒数排名指标对三种算法的有效性展开分析,实验结果如图3所示。
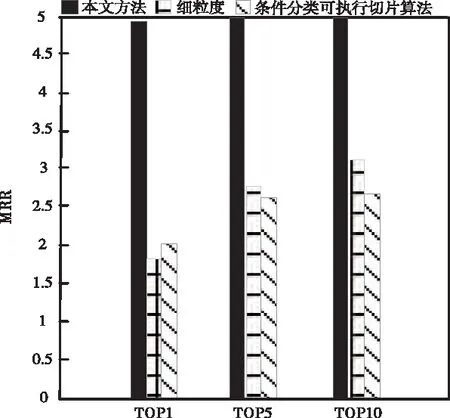
图3 三种算法平均倒数排名对比
从图3中可以看出,不论在哪个排名中,利用本文方法得到的缺陷定位MRR值都是最高的,而其它两种方法的MRR值相对较低。说明通过本文方法定位到的软件缺陷,与实际位置拟合程度最高。
最后针对不同的数据集,利用三种算法进行缺陷定位的对比,实验结果如图4所示。

图4 不同算法在三个数据集上缺陷定位对比
通过观察图4可以看出,无论在哪个数据集上,利用本文方法对软件缺陷定位的概率值始终都是最高的,说明本文方法可以得到更精准的缺陷位置,实现精准定位
6 结论
由于开源软件各个模块之间存在着复杂的关系,传统方法在对其进行缺陷定位时,常常出现较大的误差。因此,本文利用风险轨迹,提出一种安全性缺陷定位方法。在综合考虑了软件模块间的相似度和风险度之后,构建风险度传播模块,根据风险度向量值确定缺陷报告标签,通过对比标签值,实现软件缺陷的精准定位。
