基于NLP的虚拟人自动对话系统关键技术研究
2023-09-04魏娜娣段再超
魏娜娣,段再超
(河北师范大学汇华学院,河北 石家庄 050091)
1 引言
随着数字孪生、元宇宙等新概念的不断完善和普及,数字人或者虚拟人技术逐渐成为动画、影视行业研究的一个热点[1]。普遍认为:一个体态、面容、行为、语言等各方面都与真人真假难辨的虚拟人形象,会极大的提升电视节目、电影和电子游戏的临场体验感,以及内容的互动性和娱乐性。因此,如何创建逼真的虚拟角色形象,以及如何利用图形学、计算机视觉、人工智能等技术,为虚拟人赋予视觉、听觉、语音和行动上的独立特色,成为开发者和研究者的主要课题。如何针对不同用户的语言或者文字输入,为虚拟人生成合适的应答语音,并通过面部和口型动画呈现出来,这也是重要研究内容[2]。
传统的语音生成和口型动画制作[2],需要大量的人工介入。熟练的美术人员为虚拟角色制作面部模型,并设置多个不同的面部变形体(Blendshape)。每个Blendshape对应了角色的某个标准发音口型,例如:汉语拼音的元音a,o,e,i,u,ü,辅音b,p,m等。在实际应用中,美术或者动画制作人员根据当前配音的时间线,将多个Blendshape按照权重混合在一起,产生一个混合了多种口型的新面部模型,即角色在当前的面部动画状态。该方法可以制作非常准确的虚拟人面部表情和口型动画[2],但是,其制作过程非常繁琐,需要多名美术人员配合,并且很容易人为出错。
提出一种新的方法:首先,由用户交互式地输入文字或者语音;系统自动将它转换到统一的文字并进行自然语言处理(Natural Language, Processing,即NLP)[6];经过NLP分词之后的文字被输入到人工智能处理系统,转换得到合适的回答语;然后,该回答语言文字被同步转换到语音和拼音,和预置口型匹配;最后,接入到图形前端,构成虚拟人的回答语和口型动画。整个过程不需要他人操作,整个系统的响应速度可以维持在2-3秒内,与正常人说话的频率相当。
2 自动对话系统整体架构设计
2.1 自动对话系统的组成
1)虚拟角色管理和渲染:建立虚拟角色模型,绑定骨骼蒙皮以及口型变形体(Blendshape),输入到实时系统中显示和交互控制。
2)真人语音输入和识别:识别用户从麦克风等设备的音频输入,尝试将它转换为中文文字的形式。
3)语音转换为文字并分词处理:将转换后的文字进行分词处理,区分出主语、谓语、宾语,从句结构等,并输入到后续的智能回复模块处理。
4)识别分词结果并智能回复:根据训练模型以及分词的结果数据,自动生成文字并进行恰当的回复。
5)将回复的文字转换为口型:将回复的汉语文字转换为拼音的形式,并从中获取适当的元音和辅音,映射到对应的Blendshape口型变形体,从而形成连续的口型动画。
6)将回复的文字转换为语音:将回复的汉语文字转换为语音的形式,并保存为音频数据,音频时间线需要和口型动画时间线同步。
7)将口型和语音与虚拟角色结合:将口型动画赋予角色模型,同步播放语音音频,从而形成虚拟角色开口说话的效果。
根据用户的具体需求不同,系统还可能存在运动捕捉和回放,或者静态场景渲染等功能需求。不过这些已并非自动对话系统的核心组成部分,因此,不再赘述。
2.2 自动对话系统的执行流程
基于虚拟人的自动对话系统主要执行流程是:用户外部语音输入,识别语音并输出文字,将文字进行NLP分词处理,根据分词结果输出应答文字,将应答文字输出为语音,将应答文字输出位拼音,根据拼音产生口型变形动画序列,匹配口型到虚拟角色并播放语音。如图1所示。
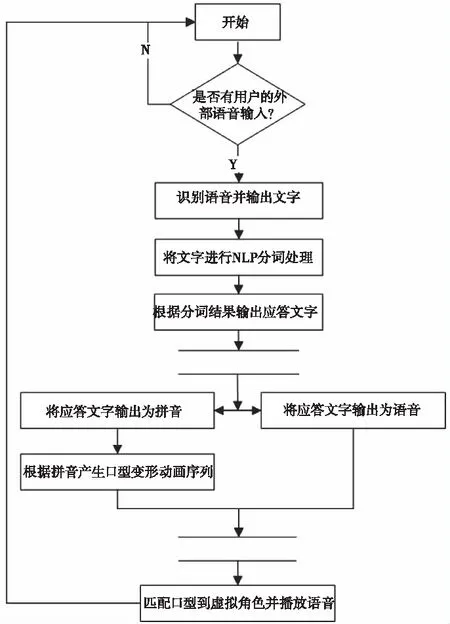
图1 自动对话系统执行流程
2.3 虚拟人角色素材管理
自动对话系统的虚拟角色可以采用3dsmax,blender等多种建模软件进行开发,在设置角色模型、纹理、骨骼、蒙皮等属性的同时,为角色添加多个不同的面部变形体模型,分别对应角色不同的口型设置。汉语口型的变形体,可以考虑元音口型,例如:元音a对应张大嘴发音,元音i则是扁嘴发音,元音u发音的时候嘴唇向外鼓起。在美术人员制作变形体时,根据常识口型形状来修改模型即可,如图2所示。

图2 元音a对应的口型变形体
但是,汉语中并非所有的口型都是来自元音发音的结果,一些典型的辅音也会产生强烈的口型变化,例如:p,m发音时有明显的上下嘴唇触碰和摩擦,而d,t会产生舌头与上排牙齿的弹击。此外,汉语元音是可以进行组合扩展的,例如:ai,ao,ang等,虽然都是从元音a衍生而来,但其发音特点与a有着明显的不同。如果全部忽视这些因素,则口型模拟的结果也会不理想;但是,全部包含的话,需要制作的Blendshape数量过多,对美术人员又是繁重的工作。
为此,设计了一个能够囊括大部分口型情况的Blendshape列表,经测试表明,它对汉语语言的模拟有较好的效果,见表1。

表1 口型变形体类型
当多个Blendshape同时起作用时,可以表达更为复杂的拼音口型动画。对于不在表1中的元音/辅音,选择相近的发音口型即可。
3 自动对话系统功能研究与实现
3.1 角色的语音输入识别
实现中文和英文等语言的语音输入和文字识别的基本工作原理是通过高斯混合模型(GMM)-隐马尔可夫模型(HMM)的方式,将声音特征序列识别为另一类序列(例如语言文本序列)。通过音素(Phoneme)来表达某一种语言中的基本音节符号,每个音素都可以用一个HMM的状态来描述。因为,正常人说话时经常会把多个音节连接到一起,因此,HMM状态可能不止是常见的一些拼音符号,而是多种不同符号组合的形态。对于这些状态数据的管理和控制,也就是针对某种语言训练得到的声学模型。
在实际计算过程中,通过计算声音当前帧的梅尔频率倒谱系数(即MFCC系数)和GMM混合模型分类器,得到当前帧对应的HMM状态,进而得到整个状态数据序列。这一过程也可以通过基于神经网络的分类器来完成。得到HMM状态序列之后,将它与已知的声学模型进行比对,判断某个音节与序列中某一帧的匹配概率情况。如果概率超过阈值,则将音节与序列帧进行匹配。最终得到该序列对应的音节数据,如图3所示。
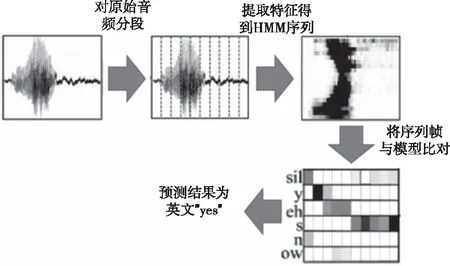
图3 HMM序列的生成和匹配过程
音节数据通过类似于声学模型的文字模型来进行比对,得到的就是文字结果,该过程与上述匹配过程类似。
3.2 基于自然语言识别的文字识别流程
自动对话系统并不希望能够接收用户的任意语句输入并进行反馈,并且已经有科大讯飞等公司做了大量相关的工作,以实现类似自动聊天机器人的功能。本系统的研究目的,更多的时候是为了响应用户的特定需求,并且形成自动化的虚拟角色响应流程。因此,本系统的关键功能在于:分解用户输入的文字内容,然后与系统内置的功能组件关键字进行匹配,最后输出响应结果。
自然语言识别(NLP)分词的关键技术在于,如何对一个完整的句子进行切分,并给切分结果序列的每一项赋予不同的标签。为此,定义了一套可以适用于大部分中文语境的分词标签,并且根据该标签实现了对应的分词词典,如表2所示。
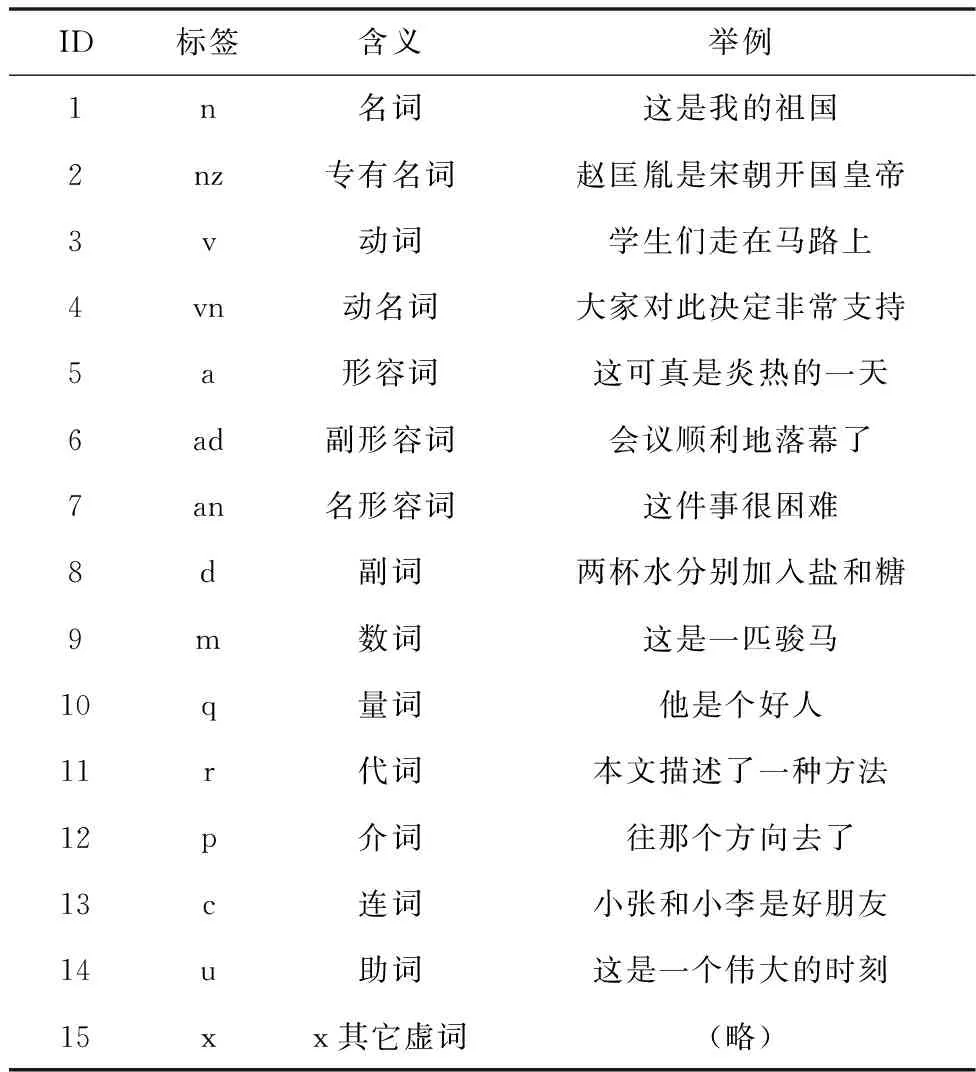
表2 NLP分词标签表
通过HMM特征的提取和比对,可以得到一个句子中每个字或者词语对应的标签类型,如果发现了某个新出现的名词无法被正确切分的时候,也可以直接在词典当中进行添加来补全数据。
3.3 文字回复和语音合成输出
目前,使用了较为简单的词典来做自动回复的规则。例如,如果分词结果中存在“什么(r)是(v)xxx(n)”或者“查找(v)xxx(n)”的句式,则回复“我来查找”并随后返回在线查找结果;如果无法理解分词后的结果或者识别到的文本内容,则回复“我不知道”。该规则可以不断扩展和完善,以便用在更多复杂的环境中。
文字到语音的合成(Text To Speech,TTS)过程与语音识别和输出文字的过程类似。首先,对回复文字同样进行NLP分词,将结果字词序列与之前的声学模型库中的数据进行比对,得到对应的HMM特征,并反向输出梅尔频率系数。最后,通过声码器的步骤,将低维的声学特征数据映射到高维的语音波形。这一过程通过已有的开源TTS引擎ekho进行实现。
3. 4 文字到角色口型的转换和同步
回复文字同样需要输出到角色模型和BLendshape,转换为对应的口型动画数据并且和合成后的语音同步播放。通过之前的声学模型数据,已经可以将文字和音素数据一一对应起来。并且可以将输出的语音按照每一帧的音素来切分,从而得到每帧音频对应的口型形状。在播放音频的同时,将口型Blendshape的数值传递给虚拟角色,从而实现同时开口说话和声音播放,就如同是虚拟角色和用户进行实际的交流一样。整个过程不需要程序和美术人员再介入,可以完全自动完成,互动性和实时性都比较理想,并且可以根据具体行业需求做深度的功能扩展。
4 应用实例
使用Unity引擎作为主要的应用测试平台;所用的虚拟角色使用Blender引擎制作,并按照之前表1制作了大部分的口型变形体。变形体数据可以自动导入到Unity中,并实时进行手动或者程序调节,如图4所示。
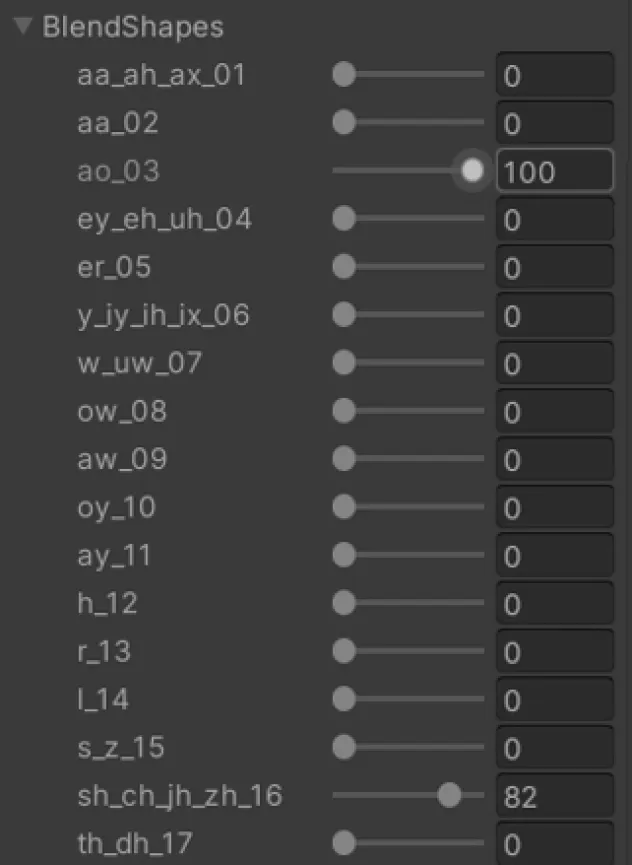
图4 Unity中的口型变形体设置
当用户通过麦克风与角色交流,并说出类似“什么是自动对话系统”的句式时,本系统经过短暂的计算后即通过虚拟人的口型动画回答“好的,我来查找”。之后“自动对话系统”作为关键字传递给系统后台,可以通过其它搜索引擎进行搜索并进一步反馈,如图5所示。

图5 虚拟角色回答用户问题
如果用户的语音识别结果经过分词后无法匹配现有词典,或者无法正确识别或者分词,则系统自动调用内部的默认回答语,即“我不知道”,并传递给虚拟角色通过语音合成进行表达,如图6所示。

图6 虚拟角色的默认回答
经过多次测试,本系统可以识别多种类型的用户提问,并自动进行分析和语音回答,同时伴有虚拟角色的口型动画。系统执行过程中,具体的识别情况和运行速度如表3所示。

表3 系统运行时的对话情况
5 结语
本文提出了一种虚拟角色交互对话系统,并研究了其中涉及的关键技术,包括语音输入的识别的文字转换,自然语言分词和结果输出[6],文字转换为语音,以及将语音转换到虚拟角色口型变形体的方法。通过GMM-HMM系统将输入的声音波形进行分割,再提取每个分段中的特征信息,转换为HMM状态数据,
与声学模型库进行比对,得到对应的文字序列[3]。之后,将文字序列合成为整段自然句,并进行NLP分词识别,根据分词的结果生成回应文字;然后,再通过同一个声学模型库的逆比对,得到新的文字段对应的声音HMM状态,最终输出新的波形数据,并同步将文字输出为虚拟角色的口型动画。整个流程可以通过程序自动完成,不需要人工干预操作,因此,大大简化了虚拟人角色和内容的制作周期,可以用于电视电影,游戏娱乐,直播和VR等领域的需求,具有较高的实用价值[1]。
所提出的方法还有较大的完善空间,尤其是自动产生回应文字的部分,目前采用了较为原始的从词典中匹配和提取的手段,因此,较多的用户提问都会被转换到“我不知道”这一默认答案。后续的研究过程中,会尝试引入神经网络的方法,来完善虚拟角色的回应机制,从而进一步提升整个系统的实用价值。
