基于深度学习的声呐图像目标检测系统
2023-09-02罗逸豪
罗逸豪
(1.中国船舶集团有限公司第七一〇研究所,湖北 宜昌 443003;2.清江创新中心,湖北 武汉 430076)
0 引言
成像声呐通过发射和接收声信号进行成像,探测距离远,是目前水下探测的常用设备,被广泛应用于水下勘探、水下救援、敌对目标侦察等任务。声呐图像的自主目标识别(Autonomous Target Recognition,ATR)即目标检测(Object Detection),需定位图像中最可能包含目标的区域,并确定目标的类别[1]。传统目标检测算法通常先基于滑动窗口等筛选方法枚举出所有可能的目标外接矩形框,然后利用人工设计的边缘、纹理等特征进行分类,无法在复杂多变的水下环境中取得良好性能。
近年来,深度学习取得了突破性进展,以层次化的方式构建特征提取模块,逐层连接构成的深度神经网络(Deep Neural Network,DNN)通过数据驱动的方式自动学习图像特征,克服了人工特征模式单一、判别能力弱的局限。基于深度学习的目标检测算法实现了定位和分类任务的端到端共同优化,无论是处理可见光自然图像[2],还是应对前视声呐[3]、侧扫声呐[4]和合成孔径声呐图像[5],均能取得比传统方法更优的检测精度[6-7]。
然而声呐图像采集需要耗费大量的资源,且常因涉及到敏感信息而未公开[8],因此,基于深度学习的声呐图像目标检测系统性研究与应用仍然不足。实际工程应用不仅对检测算法的精度要求较高,还对软件系统质量属性、运行速度、部署环境等方面均具有一定要求。因此,本文利用深度学习模型数据驱动的优势设计了一种声呐图像目标检测系统,提高也不表明该系统在测试数据上和实际应用中均具有良好的性能。
1 基于深度学习的声呐图像目标检测系统
1.1 系统组成
所设计的基于深度学习的声呐图像目标检测系统包含数据集生成、算法模型训练与测试、模型部署应用3 个子系统,如图 1所示。各子系统的输入输出相互关联,且不存在强耦合关系,满足可移植性、可扩展性、易用性等软件系统质量属性。所设计的系统具备通用性,不依赖于某一项具体应用任务。
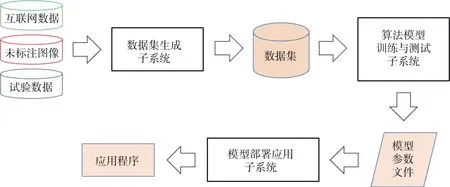
图1 声呐图像目标检测系统Fig.1 Sonar image object detection system
数据集生成子系统负责采集、标注、处理、生成和管理数据集,对外场试验的实时数据、已有的未标注图像和互联网数据进行标注,经过预处理和训练集测试集划分后生成数据集,并支持修改、合并等功能。
算法模型训练与测试子系统首先构建目标检测深度学习模型,然后读取训练集数据进行训练,并读取测试集数据对训练完成的模型进行测试,将满足算法精度、速度要求的模型参数文件输出。
模型部署应用子系统针对不同部署平台的软硬件环境要求,转换模型参数文件,并编写服务于实际任务的应用程序,然后部署于项目机,读取模型并进行前向计算。
1.2 数据集生成子系统
数据采集和标注功能分为离线和在线2种模式。离线模式指对已有的未标注声呐图像进行人工标注,数据来源通常为外场试验保存的历史数据,互联网下载的开源图像。采集数据后,可以采用labelImg、labelme、Vott、CVAT等开源的标注软件对声呐图像进行标注。在线模式指在试验现场使用相关显示软件实时解析声呐设备传输的原始数据,在生成声呐图像后直接手动标注并导出结果。由于现场试验时已知水下目标的布放位置,在线标注的类别信息通常比离线标注更加准确。
标注过程中,尽量不以狭长、极端长宽比的目标外界矩形框进行标注,且需要保持目标位于矩形框中央,减少无关的背景信息。标注格式也应保持一致。如图 2所示,P1为矩形框左上角顶点,P2为右下角顶点,P0为中心点,w,h表示矩形框的宽和高。通常以[x1,y1,w,h]或[x1,y1,x2,y2]的数据格式记录标注,YOLO系列算法[9]以图像的宽、高作为分母分别对坐标进行归一化,以归一化后的中心点坐标与矩形宽高记录。
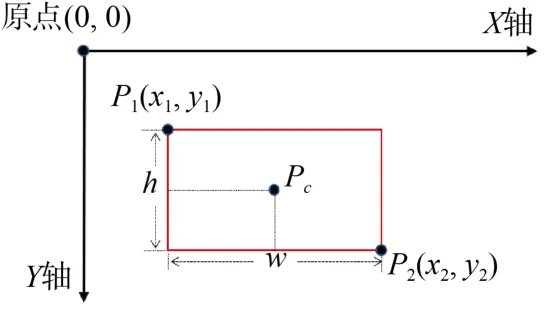
图2 标注坐标示例Fig.2 An example of annotation coordinate
传统检测方法通常使用滤波算法对声呐图像进行预处理,消除散斑噪声以提高检测精度[7]。深度学习以数据驱动来训练神经网络,使用噪声数据训练模型会提高算法鲁棒性和抗攻击能力[10]。因此,本系统不对数据集图像做滤波预处理操作。
由于声呐图像获取不易,训练图像通常数量较少,容易使得深度学习模型过拟合而缺乏泛化性。因此数据增强方法至关重要。基础的方法包括翻转、旋转、裁剪、变形、缩放等几何变换操作,不对图像本身内容进行修改,适用于声呐图像数据集生成阶段以增加图片数量。
更进一步的增强方法通常采用颜色空间变换,修改图像语义信息[11]。此类方法对训练结果造成的影响不能事先预知,因此常在模型训练阶段尝试。
对于不同类型、型号的声呐设备和在不同水域下采集的声呐图像数据集应分类归纳。常用的声呐设备有前视声呐、侧扫声呐、合成孔径声呐。不同种类的声呐图像风格不同,前视声呐对前方扇形区域进行扫描,图像分辨率低且对噪声敏感,侧扫声呐和合成孔径声呐图像分辨率高,但侧扫声呐图像精度较低[6]。此外,声呐图像数据分布还受到水质、水底环境等因素影响。不同分布的数据所包含的可学习信息不同,源域(Source Domain)和目标域(Target Domain)数据分布不同会影响深度学习模型的测试精度[12]。因此,对声呐图像数据集的归类需考虑影响数据分布的多方面因素。
1.3 算法模型训练与测试子系统
算法模型训练与测试子系统通常部署在配置NVIDIA GPU的服务器中。目前流行的深度学习框架有PyTorch[13]、TensorFlow[14]、PaddlePaddle等。而广泛使用的开源目标检测算法框架MMDetection[15]、Detectron2与YOLO系列模型[11]均基于PyTorch、Linux实现。因此,本系统基于上述框架定义了声呐图像目标检测深度学习模型构造和训练过程的关键模块:骨干网络(Backbone)。骨干网络是DNN提取图像特征的主要组成部分。目前有许多性能优越的卷积神经网络(Convolutional Neural Network,CNN),比如ResNet[16]、DenseNet[17]、ResNext[18]、Res2Net。通常而言,特征提取能力越强的CNN参数量越大,从而造成推理速度缓慢,因此轻量化CNN也常被用于高实时性任务。
为进一步提升特征丰富程度,颈部网络(Neck)通常采用以特征金字塔网络[19](Feature Pyramid Network,FPN)为代表的网络构造多尺度特征,以提高模型的小目标检测精度。在侧扫声呐和合成孔径声呐图像中,待检测目标往往只占据整幅图像的小部分,因此设计颈部网络至关重要。头部网络(Head)在提取的特征图上进行采样,然后计算分类和定位结果。目前常用的采样方式有两阶段(two stage)、一阶段(one stage)、无锚框(anchor-free)。其中一阶段方法直接将每个坐标点视作潜在目标,没有额外的候选框提取步骤,运行速度更快。数据增强是基于颜色空间变换的数据增强方法,常在训练过程中使用,比如CutOut、CutMix、MixUp。这些算法丰富了正样本目标的信息,能缓解声呐图像数据不足的问题,提高训练效率和测试精度。
声呐目标检测模型构建完成后,系统读取声呐图像数据集中的训练集进行训练,然后使用测试集进行性能评估。针对具体的任务,可以选择多个不同的声呐图像训练集进行组合,并在多个测试集上全面评估,将满足算法精度、速度要求的模型参数文件输出,文件后缀名通常为“.pt”。
与MS COCO[20]基准的评价指标类似,以预测框与真实框的面积交并比(Intersection over Union,IoU)反映单个预测结果的好坏。IoU数值和分类置信度均大于既定阈值的结果称为真阳性(True Positive,TP),即正确;否则为假阳性(False Positive,FP),即误检。由于算法不输出负样本背景框,因此不存在真阴性(True Negative,TN)。假阴性(False Negative,FN)则代表未被检测出的目标框,即漏检。以此计算精确率P(Precision)、召回率R(Recall)以及平均精度AP(Average Precision):
设置的IoU阈值和分类置信度越大,对于预测正确的标准就越严苛。通常在IoU阈值范围为[0.5,0.95]区间内每间隔0.05计算AP,求平均分作为综合评分。如果声呐图像分辨率高而待检测目标小,可以将IoU区间设置为[0.2, 0.65]。
1.4 模型部署应用子系统
模型部署应用子系统负责将训练好的声呐图像目标检测模型部署在特定的环境中运行。由于模型动态化、新增算子实现、框架兼容性等问题,当运行环境不同于模型训练环境时,模型参数文件通常无法直接被调用。可使用MMDeploy开源部署工具对算法模型训练与测试子系统输出的模型参数文件进行转换。MMDeploy支持多种算法库运行和多种格式的模型文件转换,支持Python、C++接口与Windows、Linux操作系统。
完成模型参数文件的转换后,编写应用程序进行读取运行。程序包含如下功能:
1)数据接收功能,以文件读取、网络传输协议、内存共享等方式从上游程序获取待处理的声呐图像数据。
2)目标检测功能:读取转换完成的模型参数文件,加载内存/显存,输入声呐图像进行计算,得到目标检测结果。根据实际应用效果可增加图像预处理和结果后处理算法。
3)结果发送功能:以文件存储、网络传输协议、内存共享等方式输出检测结果。
目标检测系统的应用程序独立运行,与上游程序和下游程序之间通过既定接口实现数据交互,满足解耦合原则。
2 水下可疑目标检测系统实现
本文将所设计的声呐图像目标检测系统应用于水下可疑目标探测任务,以验证应用效果。
系统使用某公司的合成孔径声呐设备,在一片固定水域进行湖上试验。首先,布置多个可疑目标外壳模型;然后,使用无人艇拖曳设备搭载声呐设备实施数据采集与标注。航行过程中远程控制无人艇从不同的方向驶入布雷区域,由于布雷位置事先已知,控制无人艇航行方向使得布放的可疑目标均能出现在声呐扫描范围内。声呐图像由合成孔径声呐设备进行渲染合成并通过行信号传输。采集的原始左声呐以及右声呐图像分辨率均为1 900×1 900。正样本标注仅有可疑目标一种类别,位置标注以归一化后的中心点坐标与矩形宽高记录。
采用缩放、裁剪、拼接、翻转等几何变换方式处理原始声呐图像,生成分辨率为640×640、1 024×1 024和3 800×1 900(左右声呐图像拼接)的数据集图像,共1 362张图像。生成的数据集具体划分和图像数量如表1所示。

表1 合成孔径声呐图像数据集Table 1 Synthetic aperture sonar image dataset
考虑到系统运行实时性要求,目标检测模型使用YOLOv5s网络。训练图像采用CutOut、MixUP、Mosaic方法进行数据增强。组合修改而成的新图像通过自适应缩放方式统一缩放至640×640分辨率,添加黑色边框而不改变原始信息的长宽比。输入图像经过骨干网络得到分辨率为80×80、40×40、20×20的多尺度特征,然后在基于FPN的颈部网络得到扩充、叠加、增强,输出通道数分别为128、256、512的3层特征。然后将多尺度特征输入头部网络,每个像素点得到18维通道数的预测结果(4维表示目标坐标,1维表示目标置信度,1维表示可疑目标类别结果,预设3个尺寸的anchor,所以6×3=18)。训练过程中分类损失和置信度损失均采用BCEWithLogitsLoss函数计算,坐标回归损失使用GIOU方法。多尺度特征图产生的损失进行加权融合,以提高小目标检测精度。训练参数均采用YOLOv5模型默认值。在测试阶段使用加权非极大值抑制剔除冗余预测框,筛选过程IoU阈值为0.6。
训练完成后,将满足算法精度要求的模型参数文件以“.pt”格式输出。由于水下可疑目标探测项目的软硬件环境约束,系统应用程序需基于C++编写,部署的项目计算机配置为Windows操作系统,Inter(R)Core(TM)i7-7700 CPU @ 3.60 GHz,内存16 GB,NVIDIA GeForce RTX 2080显卡。PyTorch提供基于C++的推理后端引擎LibTorch-Windows。因此系统使用模型参数转换工具将“.pt”格式文件转换为该引擎可用的“.torchscript.pt”格式。
系统应用程序调用LibTorch相关库函数完成对转换后模型文件参数的读取、加载、推理等功能。然后基于网络传输协议、声呐数据解析等链接库编写声呐数据接收功能,以及检测结果发送与保存功能。至此水下可疑目标检测系统实现完成。
3 实验结果
本章使用测试集包含的135张合成孔径声呐图像评估系统应用程序的检测性能,表2和表3分别展示了IoU阈值为0.5和0.2时的测试结果。
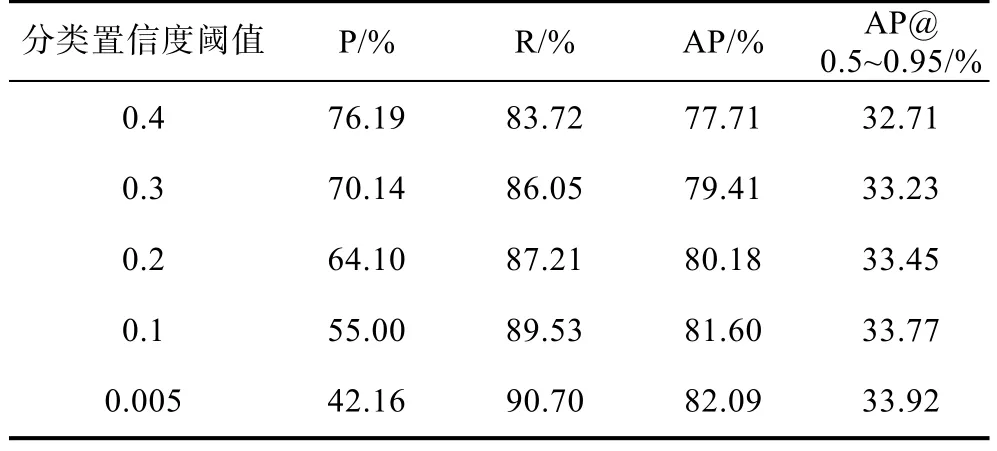
表2 IoU=0.5测试结果Table 2 Experimental results of IoU=0.5

表3 IoU=0.2测试结果Table 3 Experimental results of IoU=0.2
由表中数据可知,当IoU设置为0.2时,检测精度会明显上升,说明存在一定数量的预测框定位偏离了实际位置。合成孔径声呐图像中的水下可疑目标并不重叠、密集出现,因此具有一定偏离的预测结果并未定位错误。这也说明了目标检测算法的定位性能有进一步提升的空间。
当设置的分类置信度高时,精确率P高,此时较多的低置信度预测结果被剔除,减少了误检率(虚警率);但因为剔除了低置信度结果使得预测框数量下降,导致召回率R下降,即漏检率(漏警率)增加。当设置低分类置信度时,尽管平均精度AP和综合评分会提高,精确率P大幅下降,导致了高虚警率。在自然光学图像数据集MS COCO上通常将分类置信度设置为0.005以实现更高的平均精度。在本任务中,尽管将分类置信度设置为0.005时会得到最高的平均精度值82.09%(90.26%),但会导致虚警率过高,在实际应用中会造成指挥员经常性紧张和疲劳等问题。为了平衡虚警率和漏警率,本系统将分类置信度阈值设置为0.3。
图3在测试集中选择了4张图像展示了所设计的声呐图像目标检测系统的应用效果。可视化结果表明系统对于水下可疑目标具有较高的检测精度,对相似物(第3张图像)会产生虚警。
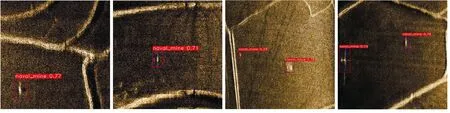
图3 合成孔径声呐图像测试集检测效果Fig.3 Detection effect of synthetic aperture sonar image test set
算法初始模型参数大小为13.7 MB,转换后为27.3 MB,系统在NVIDIA GeForce RTX 2080显卡上处理一张图像平均耗时18 ms,符合实时性要求。
4 结束语
本文设计了一种基于深度学习的声呐图像目标检测系统,通用性较高,满足可移植性、可扩展性、易用性等软件系统质量属性;将该系统应用于水下可疑目标探测任务,对合成孔径声呐图像的检测效果良好。实验表明,为了不造成过高的虚警率,分类置信度阈值不宜设置为较高或较低的值。未来将在更多的民事和军事任务中应用本系统。
