中国知网文献共被引方法及实证研究
2023-08-31冉从敬李旺谢真强
冉从敬 李旺 谢真强

关键词: 中国知网; 共被引分析; 智慧医疗; CiteSpace
DOI:10.3969 / j.issn.1008-0821.2023.09.013
〔中图分类号〕G250.2 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 09-0154-11
1973 年, 美国情报学家Small H[1] 首次提出了文献共被引(Co-citation) 的概念, 作为测度文献间关系程度的一种研究方法。而后随着研究的逐渐深入, White H D 等[2] 在1981 年将文献共被引拓展至作者与期刊层面, 形成了作者共被引分析(AuthorCo-citation Analysis, ACA)与期刊共被引分析(Jour?nal Co-citation Analysis)的研究方法。随着科学知识图谱的兴起, 其一直是科学计量学、知识计量学领域的一种重要的研究方法与研究手段, 基于学者的不断摸索, 共被引分析与科学知识图谱相结合,分析结果逐渐被可视化的展示出来。科学知识图谱是以知识域(Knowledge Domain)为对象, 显示科学知识发展进程与结构关系的一种图像[3] 。科学知识图谱这一概念在2003 年美国国家科学院举行的研讨会中被第一次提出, 而后随着科学技术的发展,学者将科学知识图谱这一概念与技术相融合, 从而衍生了各类知识图谱绘制工具。在众多可视化软件中, 由美国Drexel 大学陈超美研发的CiteSpace 由于其绘制图譜信息量大, 图谱美观, 可以从多个层面为学者提供研究视角而广受欢迎。随着CiteSpace工具的普及, 国内外产生了许多关于应用CiteSpace及其知识图谱的学术论文。国外学者如Jayantha WM 等[4] 通过Scopus 数据库检索了1970—2019 年关于享乐价格模型的相关文献, 而后使用CiteSpace软件对数据进行分析和可视化; Rawat K S 等[5] 运用CiteSpace 分析了2011—2020 年在教育领域使用ICT 发表的文献的科学计量特征; Widziewicz-RzońcaK 等[6] 通过WOS 数据库检索了1996—2018 年关于PM 结合水研究领域的相关文献, 并使用CiteSpace软件可以确定测量气溶胶结合水的过去趋势和未来可能的方向。国内学者如陈晓玲等[7] 以WOS 数据库中SCI-E、SSCI、CPSI 三大核心数据库收录为数据来源, 运用CiteSpace 分析了2012—2016 年东北三省的研究热点和学科趋势; 花龙雪等[8] 以中国知网收录的“过程挖掘” 领域相关文献为样本, 运用VOSviewer 和CiteSpace 两款软件对文献特征、热点主题和前沿趋势进行分析; 李灵芝等[9] 运用CiteSpace 针对WOS 数据库中基础设施韧性评估核心文献展开文献分布、共现分析、共被引分析等计量分析并得出结论。
分析已有研究发现, 国内外多数学者均运用CiteSpace 对WOS 数据库与CSSCI 等数据库的论文进行共被引分析, 而针对中国知网CNKI 数据库时仅仅是进行了关键词分析, 较少运用CiteSpace 针对CNKI 数据库文献进行文献共被引分析、作者共被引分析与期刊共被引分析。即便现有的极少数学者进行了相关研究, 也是通过手动下载参考文献并导入对应文章的方式来实现[10-11] 。通过下载最新版CiteSpace6.2.3 并分析发现, 当前版本可以对WOS 数据库与CSSCI 等数据库下载的文献数据进行共被引分析、关键词共现分析、作者耦合与机构耦合分析等, 帮助相关研究者探究某一研究领域的研究热点、研究前沿、知识基础、主要作者和机构等, 预测某一研究领域的未来发展走向。但是将CNKI 数据库导出的文献数据导入CiteSpace 中进行分析时, 只能进行关键词共现分析、作者共现分析与机构共现分析等, 无法进行文献共被引分析, 从而导致相关学者无法在CNKI 的海量文献资源中找到高被引论文、高被引期刊与高被引作者, 一定程度上阻碍了相关学者鉴别领域学科共同体, 不利于学者归纳相关领域的学科范式。针对上述情况, 本文通过分析发现, CNKI 数据库导出的题录数据不包含参考文献, 进而无法对其进行共被引分析, 这导致研究者在进行中文文献共被引分析时只能基于CSSCI 数据库来完成。对于一些自然科学学科来说, CSSCI 数据库所包含的数据量有限, 检索逻辑较为单一, 数据导出流程较为繁琐, 这不仅降低了研究效率, 还无法得出更加精准的研究结果。基于此, 为了提升相关研究者的研究效率, 探索共被引分析的新渠道, 更加广泛地剖析学科知识领域的研究热点、前沿与趋势, 本文尝试提出一种基于CiteSpace 的CNKI 文献共被引分析方法, 旨在实现对CNKI 数据库的文献共被引分析、作者共被引分析与期刊共被引分析, 为相关研究者提供新的共被引分析思路。本研究不仅将扩宽学者的研究渠道,还有助于提升相关学者的研究效率, 因而具有一定现实意义。
1研究设计
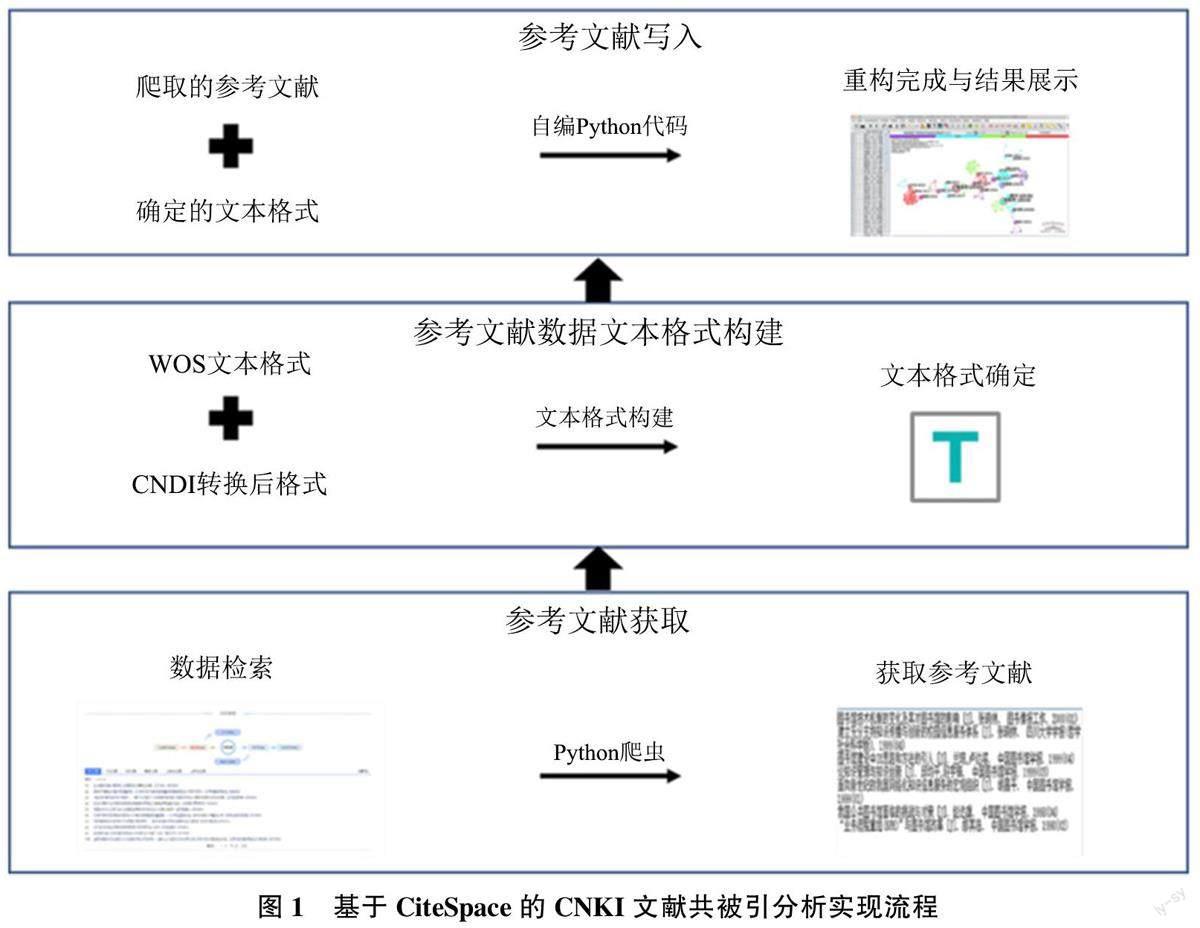
通过前期CiteSpace 的使用经验并阅读相关文献资料, 可获知当运用CiteSpace 对CNKI 文献数据进行关键词分析时, 通用步骤是在CNKI 中检索文献,导出Refworks 格式, 而后将数据导入到CiteSpace中将其转换为与从WOS 文献数据库中下载到的“全纪录与参考文献” 一致的纯文本形式。由此可见, CiteSpace 在进行分析时并不对数据库进行限制, 而是对数据文本格式有特定限制。因此, 只要文献数据格式符合软件要求, 那么就可以对CNKI数据库文本进行共被引分析。为了实现这一设想,本文需要解决如下问题: CNKI 参考文献获取、参考文献的数据文本格式构建与参考文献写入方式构建。本文所使用编程语言为Python, 具体研究步骤如图1 所示。
1.1参考文献获取
当使用CNKI 检索文献时, 在确定检索条件后开始检索, 随后便会显示检索条件下的所有文献;当点开文献后, 可以看到该论文的标题、摘要等信息。而在引文网络中, 便可以看到参考文献的详细信息。当点击该篇文章时, 可以获取参考文献所属文章的URL, 通过对URL 进行解析, 可获取参考文献的基本信息。由于CNKI 数据库中少量文献存在参考文献缺失和无法显示的现象, 所以需要通过引文网络中的“期刊” 字段来确定该文献是否有参考文献, 返回结果为True 则爬取参考文献信息,返回结果为False 则循环结束。由于CNKI 的参考文献只显示10 条, 所以本文使用Len()函数来判断是否存在下一页参考文献, 如不存在则终止循环, 如存在则读取下一页的参考文献信息。最后,结合URL 解析出的参考文献标题、文献类型标志、作者、所属期刊, 以及期刊的年、卷、期、页等信息, 爬取特定主题下论文的参考文献, 将其储存在Text 文档中。
1.2参考文献数据文本构建
通过阅读文献可知, 国内外相关领域学者多使用WOS 数据库来进行文献共被引分析, 其重要因素为WOS 数据库可以导出“全纪录与参考文献”的纯文本形式, 该文本格式主要包含的因素如图2 所示。
由图2 可知, WOS 数据库“全纪录与参考文献” 纯文本格式主要包含PT(出版物类型)、AU(文献作者)、AF(作者全名)、TI(文献标题)、SO(出版物名称)、DT(文献类型)、AB(摘要)、C1(作者地址)与CR(参考文献)等关键信息。正因为有了这些信息, CiteSpace 才可以对相关文献数据进行关键词分析、共被引分析等操作。当使用CiteSpace 对CNKI 数据库文献进行分析时, 最基本的操作是在CNKI 数据库中选中文献并导出Ref?works 格式。由于CiteSpace 对文献数据名称有特殊要求, 所以需要将导出的文献数据命名为download_XX 的形式才可以被CiteSpace 所识别, 而后通过Data>Import/ Export→CNKI→Format Conversion 等操作对CNKI 数据进行转换。转换后的文本格式如图3 所示。
由图3可知, CNKI 数据库下载的数据经过CiteSpace 转换后的格式与WOS 的“全纪录与参考文献” 纯文本数据格式基本相同, 唯一的差别是CNKI 转换后文本的CR 为空值。产生这一现象的原因是CNKI 数据库尚未开放参考文献导出权限,这也就解释了CiteSpace 无法对CNKI 数据库导出的数据进行文献共被引分析的原因。由此笔者断定, 只要将CNKI 转换后数据文本中的CR 字段按照WOS 中CR 字段的文本格式进行补全, 那么CiteSpace 便可以识别CNKI 数据文本的CR 字段,从而完成对CNKI 文本数据的共被引分析。
通过观察WOS “全纪录与参考文献” 纯文本格式中的CR 字段本文可以得知, 其参考文献的基本格式为“作者、发文年份、期刊、v、p、DOI”等字段, 并且每个字段后均有1 个空格与半角符号的逗号, 而CR 字段后的参考文献第一作者处空1个空格, 其他参考文献作者处均空3 个空格。同时,通过使用CiteSpace 发现, 数据可视化主要展示的是对应参考文献的作者、发文年份与期刊信息, 而后面的v、p、DOI 可以忽略不计。但为了保证CiteSpace 可以顺利读取本文添加后的数据文本格式, 本文把v、p、DOI 3 个数据设定1 个固定的内容, 即: “V6, DOI 10.1186/ s40168-018-0470-z”,CR 的最终格式确定为“作者, 发文年份, 期刊,V6, DOI 10.1186/ s40168 -018 -0470 -z”。因此,在写入参考文献时, 按照上述格式写入即可。
1.3参考文献写入
通过前文的分析, 本文确定了参考文献写入的基本格式。由于每篇论文都有多条参考文献, 并且在进行共被引分析时所需数据量巨大, 如果采取手动写入方式, 则需要耗费大量的时间, 因而本文借助Python 自编代码完成参考文献的重写与写入。
1.3.1参考文献重写
在将参考文献写入CNKI 并转换为文档之前,需要对前期获取的特定主题下相关论文的参考文献进行拆分重写。本文将从CNKI 上获取的参考文献格式设置为“[序号] 文献主要责任者.文献题名[文献类型标志].连续出版物题名(其他题名信息),年,卷(期):页码.”, 而在进行参考文献重写时需要作者、期刊、年份这3 个字段。同时, 本文观察发现上述3 个字段均以符号“.” 进行分割,因此将“作者” 定义为“Name”, 则Name 的提取方式为“Name =ref.split(‘.)[1].split(‘,)[0].strip()”; 将“年份” 定义为Year, 则Year 的提取方式为“Year = ref.split(‘.) [-1].split(‘( )[0].strip( )”; 将“期刊” 定义为“Article”, 则Article 的提取方式为“Article = ref.split(‘.)[2].strip()”。在完成上述数据的提取后, 分别获得了文献的“Name” “Year” 与“Article” 字段数据。最后结合前文确定的CR 格式“作者, 发文年份,期刊, V6, DOI 10.1186/ s40168-018-0470-z”, 运用“ef1=‘name+,‘+year+,‘+Article+,V6,DOI10.1186/ s40168-018-0470-z” 完成字符串拼接,從而实现Python 参考文献自动重写[12] 。
1.3.2参考文献写入
通过前文准备工作, 本文通过爬虫程序获取了特定主题下相关论文的参考文献, 确定了参考文献重写格式并通过Python 代码进行实现。参考文献重写后, 本文以文献标题为文件名, 文件内容为参考文献的所有参考文献重写后的内容, 而后通过下列代码来读取所有参考文献重写后的文献信息并返回字典结果:
完成文本写入后, 会生成WOS 格式的数据文本“download.CNKI”。此处需要强调的是, 该文本已经是系统可以识别的文档, 无需再通过data-im?port-WOS-Remove Duplicates 进行文本转换。如果进行该操作就会造成数据缺失, 从而导致实验失败, 所以只需将“download.CNKI” 存放到CiteSpace的data 中直接进行文献共被引分析即可。
2中国知网文献共被引方法实证
2.1数据来源与预处理
随着智慧城市、智慧社区相关概念与技术的普及, 智慧医疗一词也逐渐走入了大众的视野。而早在2009 年, 国际商业机器公司(IBM) 就提出了“智慧地球” (Smart Planet)战略概念, 智慧医疗成为其战略下的六大领域之一。随着IBM 大中华区软件集团与IBM 中国开发中心CDL 共同宣布成立“IBM 医疗行业解决方案实验室”, “智慧医疗” 在中国落地有了切实可行的方案和实践。自2009 年以来, 中国智慧医疗建设投资规模也逐年递增, 且随着医养护一体进程不断加快, 构建旨在打造健康档案区域医疗信息共享平台的智慧医疗, 对传统医疗生态圈在国家宏观政策、行业信息化战略、微观技术变革、资源创新融合等方面都有着重要意义[13] 。智慧医疗作为一个与“互联网+医疗健康”正加速相关的创新服务模式, 不仅仅关注于解决医改难题, 更在一定程度上决定着“智慧城市” “健康中国” 的战略实施。
智慧医疗的主要实现方式为通过打造全社区健康档案的医疗信息平台, 利用先进的物联网技术,实现患者与医疗设备、医疗机构、医务人员之间的互动交流, 从而逐步实现信息化资源共享, 达成更加智能的服务体系。当前, 随着人工智能、传感技术等高科技技术在医疗领域的广泛应用, 国内外智慧医疗的建设水平已经逐步加深, 并在一定程度上实现了医疗服务智能化[14] , 并有望在不久的将来达到医疗服务智慧化水平, 从而从根本上解决“看病难、看病贵” 等关键问题, 做到真正的“人人健康, 健康人人”。新冠肺炎疫情是中华人民共和国成立以来传播速度最快、感染范围最广、防控难度最大的重大突发公共卫生事件。在疫情发生的过程中, 随着感染人数的剧增, 部分地区医疗系统几近崩溃, 医疗资源不足、寻医问药困难、检测诊断治疗滞后等问题频繁发生, 给医疗机构带来前所未有的压力。在传统医疗服务模式难以满足患者和大众在疫情期间医疗需求的同时, 以5G 网络、区域联合平台、大数据AI 技术、互联网医院等为代表的新兴科技先后落地到疫情防控之中, 发挥了新科技优势, 贡献了前所未有的力量[15-17] , 这也导致了学者对“智慧医疗” 领域兴趣倍增, 相关研究呈现井喷式发展。图4 为2010—2020 年智慧医疗领域研究文献增长图。分析图4 可知, 2010—2020年相关学者在“智慧医疗” 领域发文数量总体呈现上升趋势, 说明在近5 年相关学者对该领域的关注度有增无减。尤其是新冠疫情期间, 发文量呈现直线上升趋势, 并且研究愈发深入, 这表明当前及今后智慧医疗的相关研究结论对该领域的深入探讨具有一定借鉴意义。
作为一项被管理部门和社会公众普遍重视的议题, “智慧医疗” 在学界也拥有着一定的相关研究文献。然而, 笔者通過文献调研发现, 国内相关学者较少对智慧医疗领域的相关文献进行文献计量研究, 而对智慧医疗领域的相关文献进行共被引分析则是少之又少。为了验证本研究方法的实用性, 厘清智慧医疗领域的近五年的共被引情况, 本研究结合前文的研究思路, 选取CNKI 数据库中“智慧医疗” 领域相关文献作为实证数据, 对其进行文献共被引分析, 厘清该领域下文献共被引、作者共被引与期刊共被引情况, 帮助相关学者鉴别领域学科共同体与归纳相关领域的学科范式, 从而为后疫情时代的常态化疫情防控提供实现路径的参考。
本研究选择CNKI 期刊数据库作为数据来源,跨库来源选择“期刊、硕士、博士”, 将检索主题设置为“智慧医疗”, 检索时间设置为2010 年1 月1 日—2020 年12 月31 日。通过上述检索条件, 合计检索到2 528条文献数据, 其中学术期刊文献数据2 242条, 硕士论文文献数据272 条, 博士论文文献数据14 条。将上述文献导出为Refworks 文本格式,并使用本文提出的参考文献重写与写入方法对上述数据进行预处理, 最终得到本文的研究数据。
2.2国内智慧医疗领域文献共被引分析
图5 显示了CNKI 数据库下“智慧医疗” 的文献共被引网络, 表1 列出了被引频次大于20 的文献信息。从图5 与表1 可以得知, 在“智慧医疗”领域的研究文献中, 相关作者更倾向于引用综述“智慧医疗” 领域理论沿革、厘清“智慧医疗” 领域发展路径与剖析“智慧医疗” 领域发展现状的相关论文来进行理论综述。如学者项高悦等[18] 撰写的《我国智慧医疗建设的现状及发展趋势探究》一文被相关学者广泛引用, 该文总结了近几年的“智慧医疗” 领域文献及相关研究成果, 阐述智慧医疗的概念、发展现状, 分析智慧医疗的发展前景及存在问题, 并提出相关建议, 为智慧医疗的进一步研究提供参考。再如学者宫芳芳等[19] 撰写的《我国智慧医疗建设初探》一文就智慧医疗的概念、主要内容、发展动态进行系统的研究探讨, 指出智慧医疗建设中应注意的问题, 并对我国全面推进智慧医疗建设提出建议, 该研究也在一定程度上促进了相关领域理论研究的进一步深化。此外, 图5 与表1 也显示被引频次较高的文献多集中于2013—2016 年, 产生这一现象的原因是此时“智慧医疗”领域相关研究处于理论研究向实践研究转型的阶段, 论文发表数量快速增长。同时, 由于前期相关理论研究已经相当充实, 其中不乏有研究视野相当前沿的论文产生, 研究视角不局限于理论研究, 慢慢向“智慧医疗大数据” “人工智能与智慧医疗”等方向迈进, 从而促使高被引现象的产生。由此可见, 2013—2016 年的相关研究为“智慧医疗” 领域的蓬勃发展提供了强大的理论基础。
2.3国内智慧医疗领域作者共被引分析
2.4国内智慧医疗领域期刊共被引分析
学术期刊是学术传播的重要纽带与载体, 也是学术研究的基础, 是发文质量的象征[23] 。图7 显示了CNKI 数据库下“智慧医疗” 的期刊共被引网络, 表3 列出了被引频次大于50 的期刊信息。由图7 可知, 收录“智慧医疗” 相关研究的期刊主要集中在医学信息、医院管理等相关领域, 可见在此期间, “智慧医疗” 相关研究的学科交叉现象还不是很明显, 但是该领域的相关研究已经和计算机、信息管理与数字化领域有了交叉趋势。节点大小代表该期刊共被引次数[24] , 图7 显示节点最大的是《医学信息学杂志》, 其出现频次为191 次。这表明相比于其他医学期刊, 《医学信息学杂志》刊出的论文阅读受众面更广, 更受广大学者所青睐, 从侧面也反映出该期刊比较倾向于收录“智慧医疗” 领域相关文献, 使得该期刊逐步形成了“智慧医疗” 领域研究集聚效应。如果有学者想对“智慧医疗” 领域进行纵深探索或者有兴趣了解“智慧医疗” 领域前沿动态, 可优先阅读该期刊文献。与此同时, 《中国数字医学》《中国医院管理》《中国卫生信息管理杂志》《中国全科医学》与《中国医院》这5 本期刊的被引频次均超过100,且其中介中心性相对较高, 也可作为读者或学者了解“智慧医疗” 领域的优质期刊。
2.5实证研究结论
综上所述, 2010—2020 年, 相关学者在“智慧医疗” 领域发文数量总体呈现上升趋势, 可见国内对“智慧医疗” 的学术探索由理论研究逐步向实践探索深化。通过运用本文提出的方法对中国知网“智慧医疗” 领域进行文献共被引分析可获得如下结论:
1) 通过文献共被引分析可以发现, “智慧医疗” 领域文献对理论探索论文引用频次相对较高,且引用的论文发文年度多集中于2013—2016 年。可见, 国内针对“智慧医疗” 的研究仍旧处于起步阶段, 且研究较多聚焦于理论探索, 针对实践应用方面的研究有待加强。
2) 通过作者共被引分析可以发现, 聚焦于“智慧医疗” 相关研究多为医学领域学者, 计算机领域学者也略有涉猎, 但是占比较低。如果可以促进医学领域学者与计算机、大数据、人工智能等领域研究者深度合作, 那么该领域研究层次将会实现质的飞跃。
3) 通过期刊共被引分析可以发现, “智慧医疗” 领域研究者在文献阅读时更倾向于阅读和“智慧医疗” 研究相关的医学类期刊, 而对与“智慧医疗” 相关的技术类期刊、管理类期刊等关注度较低。这也侧面反映发表在医学类期刊上的“智慧医疗” 相关文献研究层次更深、研究视角更广、研究成果更加前沿, 从而吸引了大量学者阅读与引用, 进一步促进了领域的深度发展。
通过上述的实证分析表明, 本文所提出的中国知网文献共被引分析的方法, 不仅可以实现对中国知网文献数据进行共被引分析, 厘清中国知网数据库中某领域的高被引论文、高被引作者与高被引期刊, 而且也可剖析出文献之间的联系是否密切, 从而为相关研究者开展学术研究提供参考与借鉴。与此同时, 该方法的提出也拓宽了国内学者进行共被引分析的渠道, 创新了文献共被引分析的研究方法, 为相关研究者提供了新的共被引分析思路。本文所研究设计的方法在提升相关研究者的研究效率、探索共被引分析的新渠道, 对更加广泛地剖析学科知识领域发展及其研究热点、前沿与趋势等方面具有一定现实意义。
3总结与展望
当前, 由于CNKI 数据库题录数据并未包含参考文献, 导致无法借助CiteSpace 对CNKI 文献进行文献共被引分析、作者共被引分析与期刊共被引分析, 一定程度上影响了基于CNKI 数据库文献开展文献计量分析的效率和深度。本文从文献共被引分析的角度出发, 对中国知网文献共被引分析进行了探索, 创新性地通过修改数据文本格式来实现中国知网文献的共被引分析。針对数据获取与文献清洗的复杂性工作, 本文采用Python 代码实现参考文献数据格式重写和写入的快速处理, 极大提高了研究效率, 为学者基于共被引分析剖析其他学术领域研究现状提供了新思路。该方法核心步骤包括:
①运用Python 自编爬虫程序自动获取了中国知网“智慧医疗” 领域文献的参考文献, 并将其写入text 文档中; ②通过将WOS 数据库与中国知网数据库下载的数据文本格式进行对比, 提取文本特征, 构建CiteSpace 可识别的参考文献格式; ③通过自编Python 代码对中国知网下载的数据进行批量重写, 并将重写后的数据批量写入到通过CiteSpace 转换后的Refwork 格式文档中, 实现了基于CiteSpace 的中国知网文献共被引分析。以国内“智慧医疗” 领域文献数据的实证分析验证了本文所提出方法的适用性, 提供了基于CNKI 文献数据开展文献共被引分析的渠道。
需要说明的是, 由于CNKI 数据库存在反爬机制, 导致采用本方法获取参考文献时需要使用手动更新URL, 与从CSSCI 数据库与WOS 数据库快速实现数据导出相比具有一定的工作量要求, 数据搜集的效率仍然有待提高。同时, 由于CNKI 中某些文献的引文网络中没有参考文献字段, 导致无法基于自编程序获取该文献的参考文献, 从而使得该文献无法进行分析, 存在数据缺失现象。后续研究将优化数据获取算法, 提高数据搜集效率, 思考更加自动化的获取参考文献方式, 从而提高研究效率;同时探索更加合理的参考文献获取方式, 避免数据缺失的现象发生。
