模拟初级视觉皮层增强CNN神经网络结构的稳定性
2023-08-29张丽娟胡梦达张紫薇姜雨彤李东明
张丽娟, 胡梦达, 张紫薇, 姜雨彤, 李东明
(1.无锡学院 物联网工程学院,江苏 无锡 214105;2.长春工业大学 计算机科学与工程学院,吉林 长春 130012;3.中国北方车辆研究所,北京100072)
1 引 言
自20世纪中叶机器学习理论被提出以来,随着相关研究的不断深入和计算机算力的不断提升,机器学习的应用越来越广泛,图像识别就是机器学习在计算机视觉领域上的主要应用之一。1998年,Lecun[1]等提出了卷积神经网络(Convolutional Neural Network, CNN),并通过LeNet-5网络结构成功实现了手写数字的图像识别。自此,以CNN为基础的深度学习概念受到了相关领域大量研究人员的关注和研究,各种新型的网络结构模型和训练方法被提出。2012年,Krizhevsky等[2]提出了AlexNet,在ImageNet图像识别竞赛中凭借优秀准确率夺得了分类比赛的冠军。2015年,He[3]等提出的ResNet网络结构在ImageNet分类任务比赛中获得第一名,ResNet50和ResNet101网络结构成为许多深度学习方法的基础,如Inecption网络结构[4]以及DenseNet结构[5]等。随着神经网络准确率的不断提高,CNN在搜索引擎、智能家居、生物医疗等多个领域都得到了广泛的应用,同时随着研究的深入,神经网络稳定性不足的缺陷也逐渐显现。
稳定性通常指神经网络模型接收到异常输入仍能够输出正确结果的能力。2014年,Szegedy等[6]提出的对抗样本表明,所有的神经网络都有着稳定性不足的缺陷。神经网络是探索人脑神经元结构和功能并通过计算机对其模拟、相互连结而构建的,以此实现人工智能。目前,神经网络算法已经能够在一定程度上模拟人类的识别、记忆、运算等功能,但Szegedy等[6]发现,通过在图像上加入人类无法识别的噪声干扰,神经网络模型会产生错误的判断。这种缺陷是神经网络自身局限性导致的,依赖于神经网络的图像识别是通过认知图像信息中必要的信息[7],而必要信息的维数往往远小于输入数据的总维数,大量不被人类视觉所认知的冗余信息也会影响神经网络的准确率,即神经网络往往优先学习图像中的高频纹理特征,这种认知方式与人类认知信息的方式间存在分歧。
提高神经网络稳定性的主要方法有两种[8]:一是通过图像压缩[9]、去噪自编码器[10]等降噪手段,或是通过对比降噪前后样本[11]等方法直接筛查出对抗样本,以减轻网络受到对抗样本的攻击性,进而降低对抗样本对结果的干扰性;二是通过对抗训练[12-13]或生物启发模型等形式,直接增强模型自身的稳定性。前者往往防御能力有限,在会降低网络自身性能的同时也无法有效地抵抗高强度的干扰[14]。提高网络稳定性效果最好的方法是数据增强,但训练成本较高,还可能导致模型过拟合和网络层次过深、结构过于臃肿等问题。相比之下,人类视觉往往比神经网络模型具有更高的稳定性,更能分辨局部的图像特征[15]。
1962年,Hubel和Wiesel[16]提出了视觉皮层的概念,对视觉系统中简单细胞和复杂细胞的反应功能做出描述以来,对于初级视觉皮层(V1)反应的建模始终是研究的主要领域之一。近年来,一些学者重新从类脑视觉的角度出发[17-21],研究人类视觉模型对神经网络的改进。Reddy等[22]在网络结构中引入了模拟人体视网膜和视觉皮层注视点的结构。Kim等[23]建立了一种模拟视网膜的模型。
本文从模拟生物视觉神经结构的角度出发,以Joel Dapello[24]等提出的VOneNet结构为基础,设计出VVNet混合CNN视觉模型。该模型延续了VOneNet模型基于经典的神经科学的线性-非线性-泊松(LNP)模型的结构,增加了非线性层的层数,并插入瓶颈层,进一步模仿生物视觉,以增强网络稳定性。在Cifar10数据集上进行训练,VVNet结构在保持原网络模型性能的同时,有效地提高了模型在面对常见图像损坏和噪声时的稳定性。本文提出的网络可以作为输入层扩展模块接入其他CNN,具有良好的可迁移性和可复现性。
2 VVNet的构成及工作原理
2.1 对初级视觉皮层(V1)进行模拟建模
早期研究者们通过调整Gabor滤波器实现了简单细胞[25]和复杂细胞[26]的反应预测,并通过引入两个连续的线性-非线性结构来模拟V1的行为[27]。依据神经生理学的研究,人体的视觉系统中的初级视觉皮层中存在简单细胞和复杂细胞两种主要的感受器[16]。二者能分别对不同特定方向的线条或边缘产生反应,背外侧膝状核(LGN)中两种细胞互相合作,对接收到的图像信息中的轮廓、细节和运动等信息进行识别,并将得到的信息形成高级的视觉信息传递到脑部进行进一步的处理,在面部识别、运动感知中起到了重要的作用。
部分CNN在预测V1行为时胜过Gabor滤波器组[28],这表明需要多个线性-非线性层来实现V1的复杂行为。但CNN的结构导致其会依赖于一些灵长类视觉系统不使用的一部分视觉特征作为判断基础。Joel等[24]等通过使用基于偏最小平方回归(PLS)[29-30]的标准神经预测方法,评估每个模型诱发的单个V1神经元反应的解释程度,来对AlexNet,DenseNet,VGG,ResNet等神经网络进行训练分析,发现在白盒对抗性攻击下的模型准确率与V1解释方差呈现明显的正相关关系。以此为基础,本文提出的VVNet,其最大特征是对生物视觉系统中视网膜到V1前端的部分做了进一步的模拟。每个VVNet由VVBlock和一个由对应基础CNN改编的后端网络组成,VVBlock具有多个非线性层(见图1),分别模拟灵长类动物视觉神经系统V1区域中简单细胞和复杂细胞对图像信息的处理。最终,用VVBlock和一个特定的过渡层来替换原本CNN中的第一个模块(一般为一个卷积层、归一化层、非线性层和池化层的一个堆叠)。VVBlock与被替换的模块相比虽空间图尺寸相同,但具有更多的通道数,而过渡层中一般有一个1×1的卷积作为瓶颈,将更多的通道数压缩到原模型的深层。VVBlock的构成遵循LNP模型,包括卷积层、非线性层和随机发生器三个连续的处理阶段,并且在通道都有一定数量的神经单元包含有简单细胞和复杂细胞两种不同的神经元类型。
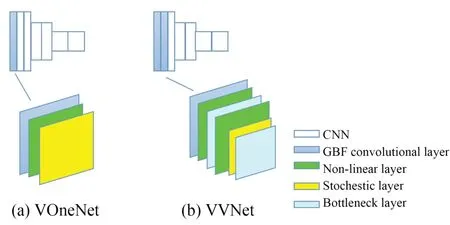
图1 VVBLock结构示意图Fig.1 Schematic diagram of VVBLock
2.2 生物约束的Gabor滤波器组的卷积层构建
VVBlock中第一层是一个数学参数化的GFB,其参数被调整为近似灵长类V1神经反应数据。它用多方向、多尺度及多空间频率的Gabor滤波器对RGB输入图像进行融合。将GFB的跨度设置为4,产生一个56×56的激活空间图。由于大多数CNN第一次卷积中的通道数量相对较少(在适应的架构中为64个),在VVBlock中将通道的数量设成较大的数值,以便GFB能覆盖更大的范围并更好地接近灵长类的V1。将主要的VOneNet模型设置为512个通道,在简单和复杂细胞间平均分配。GFB中的每个通道都对输入图像中的一个颜色通道进行卷积。
Gabor函数由一个具有高斯包络的二维光栅组成,定义为:
其中:xrot和yrot分别为相对于光栅的正交和平行方向,θ是光栅方向的角度,f是光栅的空间频率,φ是光栅相对于高斯包络的相位,σx和σy分别是正交和平行于光栅的高斯包络的标准偏差,可以定义为光栅周期(频率的倒数)的倍数(nx和ny)。
尽管GFB大大减少了定义V1神经元线性空间成分所需要的参数数量,但它每个通道仍然有5个参数。幸运的是,在神经生理学方面有大量文献对灵长类动物的V1反应特性进行了详细的描述,可以用来约束这些参数。为了实例化一个带有CV1通道的VVBlock,这里根据经验上的约束分布对每个参数的CV1值进行采样。根据输入图像的分辨率,限定空间频率(f<5.6 c/d)和周期数(n>0.1)的范围。
2.3 简单细胞和复杂细胞
简单细胞曾被认为是计算复杂细胞反应的一个中间步骤,它们现在已形成了对V2的大部分下游投射[31]。基于Hubel和Wiesel[16]提出的视觉功能柱中具有多个独立的简单和复杂细胞层的设想,VVBlock设计成具有两个不同的非线性层,根据其对应的细胞类型应用于各自的通道中,模拟简单细胞的整流线性变换,以及复杂细胞的正交相位对的频谱功率,即:
其中:Sl和Snl分别为简单神经元的线性和非线性响应,Cl和Cnl对于复杂神经元来说也是相同的。
2.4 随机性层和瓶颈层
神经元反应的一个决定性属性是它们的随机性对一个神经元进行重复测量,以应对名义上相同的视觉输入,结果是不同的尖峰序列。对于清醒的猴子,平均尖峰计数(多次重复的平均值)取决于呈现的图像,在同一组实验中,尖峰序列近似呈泊松分布,即尖峰计数方差基本等于平均值[32]。为了逼近神经元反应,本文向VVBlock的每个单元添加独立的高斯噪声,其方差等于激活度。最终,使用现有的经验分布来约束GFB模型,生成一个近似于灵长类V1的神经元空间。同时,在每个非线性层后加入一个1×1的卷积作为瓶颈层,模拟视觉系统中对输出维度的约束[33],并将更多的通道数压缩到原模型的深层。
3 消融实验与结果
实验环境如下:NVIDIA A100 SXM4 40 GB显卡的运行内存为80 GB,采用Pytorch1.13.1深度学习框架和Python3.8的服务器。本文使用的数据集为CIFAR-10(图2),它由Alex Krizhevsky, Vinod Nair和Geoffrey Hinton收集完成。CIFAR-10数据集包含60 000张32×32的彩色图像,分为10类,每类6 000张图片,其中50 000张作为训练图像,10 000张作为测试图像。

图2 CIFAR-10数据集图像示例Fig.2 Example images of CIFAR-10 dataset
为验证本文提出网络模型的性能,实验选择在CIFAR-10数据集上使用常用图像识别算法与本文提出的算法在同一数据集上进行训练。为验证本文提出网络结构的稳定性,使用imagecorruptions对图像进行破坏(见图3),模拟噪声干扰的情况,并进行对比实验。

图3 人为加入噪声的图像Fig.3 Images with artificial insertion of noise
3.1 VVNet的适用性和可移植性测试
为验证VVNet网络的可行性,本文以AlexNet[2],DenseNet121[5]和VGG19[34]3种基本网络架构为基础来构建VVNet,如图4所示。选择标准Top1图像分类准确率作为评价指标,通过对比3种网络在使用VVNet,VOneNet和原本网络结构方法下训练50轮的分类准确率,来检验插入VVBlock模块对算法准确率的影响。
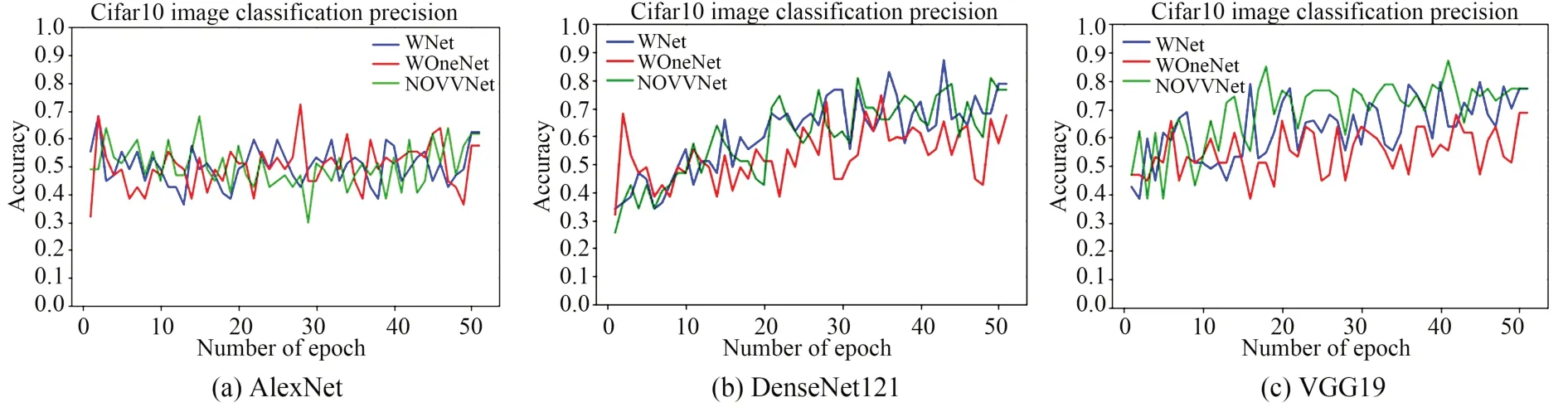
图4 在Cifar10数据集上对3种常见网络架构的原网络和VVNet重构后网络的准确率对比Fig.4 Accuracy comparison of original network and reconstructed network of VVNet on dataset Cifar10 for three common networks
从图4可以看出,与原网络相比,移植了VVNet结构的神经网络的图像分类识别准确率几乎没有变化,这证明了该方法对不同CNN网络的适应性和通用性。相比之下,套用VOneNet结构的网络准确率会下降5%~10%,VVNet结构对于不同网络的适用性比VOneNet更好,准确率变化波动小,能够在不对原网络产生负面影响的情况下进行优化。
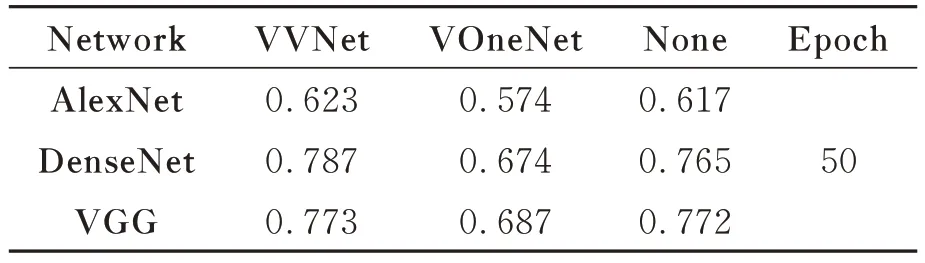
表1 三种网络不同架构在数据集Cifar10上的准确率Tab.1 Accuracy for three network in different architectures on dataset Cifar10
3.2 模型稳定性测试
为了评估VVNet在噪声干扰下的稳定性,本文对数据集Cifar10的图像进行破坏处理,形成点状噪声、模糊、泼溅遮挡和饱和曝光4类图像,使用的网络模型为在普通的训练集上训练完成的一般模型,在噪音破坏过的测试集上进行分类识别,通过对比准确率验证VVNet结构对神经网络模型稳定性的影响。
从图5可以看出,不论哪种噪声,随着破坏程度的加重,网络模型的准确率都有了明显的下降,与原网络准确率骤降的情况相比,不论是具有VVNet结构还是具有VOneNet结构网络都能够保持一个更平缓的下降趋势。从实验结果可以看出,VVNet相比VOneNet,曲线更平滑,在破坏程度最高等级的情况下,分类准确率也能提高10%左右。特别是在饱和度破坏的情况下,本文提出的方法能够有效地减少图像破坏对网络模型准确率的影响。
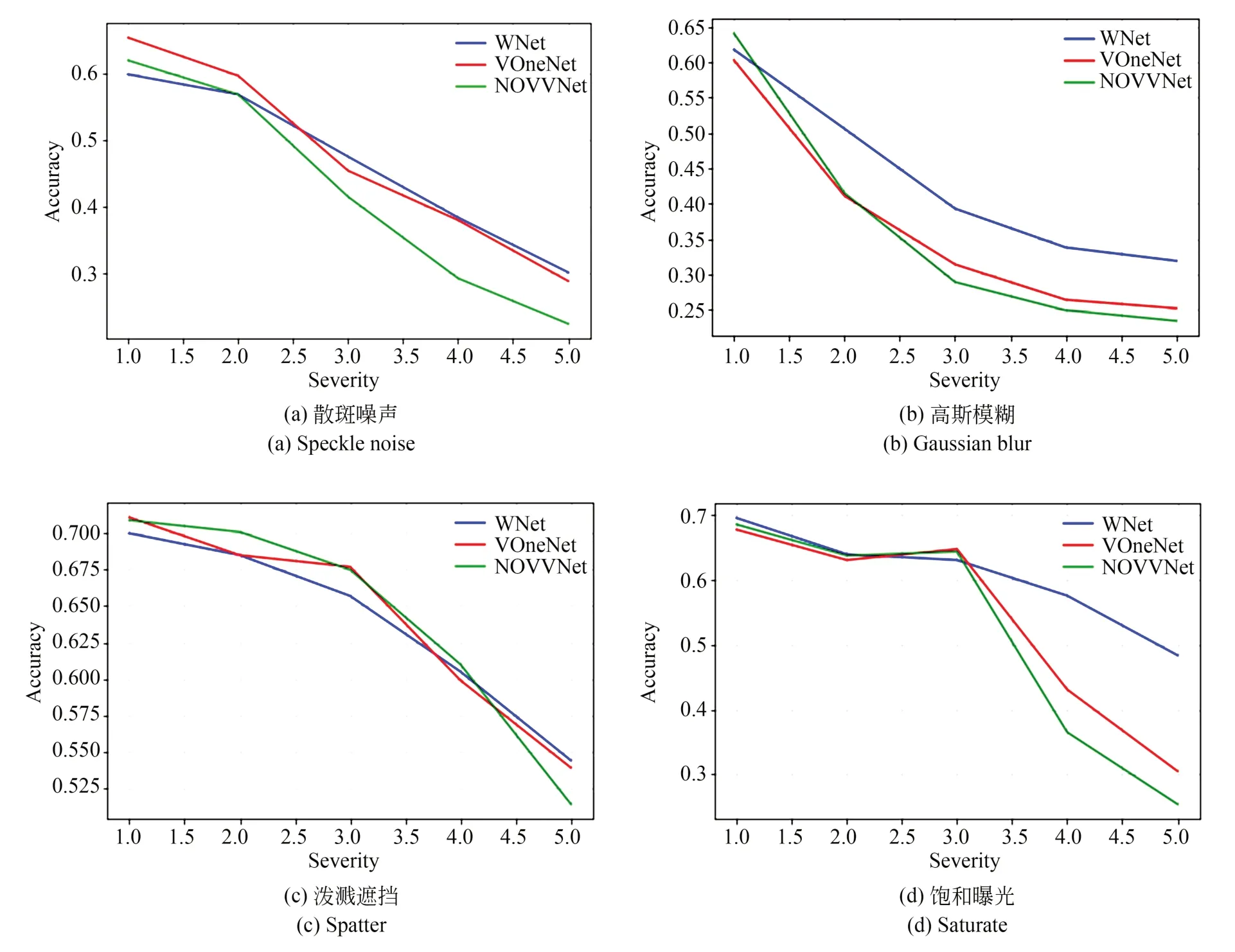
图5 使用VVNet,VOneNet和原始的网络模型DenseNet121对4类噪声图像的分类准确率对比Fig.5 Comparison of image classification accuracy for four types of noise images using VVNet network, VOneNet network, and original network model
在CIFAR-10数据集上进行多组对抗性测试,结果表明,使用VVNet结构的神经网络模型能在不进行对抗训练的情况下确实有效地提高网络的稳定性。
4 结 论
本文提出了一种基于人体视觉神经系统生物特征的CNN结构改进方法,通过将模拟初级视觉皮层结构的VVBlock作为CNN前端输入模块来优化原本的网络性能,能够在不增加网络层数并保持原准确率的情况下提高深度学习算法的稳定性。实验结果表明,与原网络模型相比,使用VVNet方法的网络模型的准确率提升了5%~10%,对于增强神经网络的稳定性具有积极影响。同时,VVNet具有良好的可迁移性,通过实验验证,与原网络VOneNet相比,VVnet网络在不同的CNN结构(AlexNet[2]、DenseNet121[5]和VGG19[34])间可以顺利移植,并且不会对原网络模型的准确率造成较大的影响。但VVNet作为一种生物启发模型的探索仍有许多不足,优化效果还不如对抗训练,今后的研究工作会尝试进一步优化结构和实验方法,以提高图像分类的稳定性。
