多网络和多头注意力融合的场景文本识别算法
2023-08-22贾小云翁佳顺刘颜荦
贾小云,翁佳顺,刘颜荦
(陕西科技大学电子信息与人工智能学院,陕西 西安 710021)
0 引言
如今大量的文字/文本内容被保存在图片或视频中。因此需要运用计算机技术检测和识别图片或视频中的文字/文本内容。例如证件识别[1]、车牌识别[2]以及视频检索[3,4]中,都需检测其中的文字/文本内容。
自然场景中的文本大都以序列的形式出现,可以将其理解为序列识别问题。SHI 等人[5]基于CNN 和RNN 提出一种识别图像中序列对象的卷积循环神经网络模型CRNN,该模型主要采用多层双向长短期记忆网络结构[6]BiLSTM 学习特征序列的双向依赖关系,提取文本序列的上下文关系特征,并融合上下文关系特征与文本特征进行识别。由于自然场景图像中的文本存在大量的不规则、残缺、模糊和扭曲变形文本,因此自然场景文本识别依旧具有挑战。Sheng 等人[7]提出的场景文本识别模型,基于Vision Transformer设计了一个特征图转换块,将二维的特征图像转换为一维的特征序列。Qiao 等人[8]提出场景文本识别模型,在图像编码识别的模块中对序列解码时应用注意力机制,为每一时刻的解码序列赋予不用的权重,提取到更丰富的上下文特征。
综上所述,当前场景文本识别算法大多忽略了图像文本的全局的语义特征和文本间的位置特征,而且很少使用多种特征之间的相互联系来辅助文本识别,以至于用来编码的特征之间缺乏相互联系,导致文本识别内容不准确。为了解决上述问题,本文提出多网络和多头注意力融合的自然场景文本识别(multi-network convergence and multi-head attention scene text recognition,MCMASTR)算法以增强自然场景下文本内容的识别,从而实现对文本内容的更加准确的识别。
1 多网络和多头注意力融合的场景文本识别算法
本文提出了一种基于多网络融合和多头注意力机制的场景文本识别模型,它是一个端到端训练的网络模型,包括特征提取模块MNC、多头注意力模块MHA、损失函数CTC[9]。
本文设计的MCMASTR 模型如图1 所示。首先对于不规则输入图片进行预处理,将输入图片统一处理为192×32 大小,然后使用一种多网络融合结构的特征提取模块,从文本图像中大量提取视觉特征;其次在多头注意力模块对输入的视觉特征进行划分,包括嵌入层、编码层、分类层,嵌入模块将视觉特征按49个patch划分后,将每个patch通过线性映射,映射到一维向量,然后在每个向量中叠加字符类别特征和位置编码,将50个调整好的特征向量输入到编码模块中进行编码,将编码后的向量传入分类模块中,生成50 个对齐的一维序列特征,每个特征对应文本中的一个字符,输出50个预测字符;最终,通过CTC算法根据多头注意模块预测的字符获取图像中的文本内容。
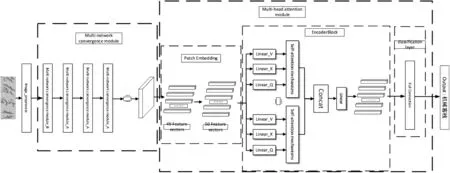
图1 多网络和多头注意力融合的场景文本识别模型
1.1 特征提取模块
基于多网络融合结构的特征提取阶段,在每一个卷积层都进行两个以上的网络并行融合操作,使得多个网络融合为更加鲁棒的模型,这些操作旨在不增加网络深度的情况下提升模型泛化性,表征能力和感受野信息,从而提取更丰富的视觉特征。特征提取模块是以改进的VGG-16作为骨干网络。多网络融合结构如图2所示,将输入特征图分成两个分支,分别用不同尺度的卷积核进行卷积,融合卷积后的两张特征图,再将其输入到三分支的网络中,使用不同尺度的卷积核进行卷积,再融合卷积后的三张特征图,最终生成一张特征图。这样网络可以通过多网络的融合获取不同的感受野,为后续处理提供了丰富的特征信息。

图2 多网络融合结构
1.2 多头注意力模块
图3 详细展示了多头注意力模块的处理流程,它集成了多个独立运行的自注意力机制,而且为每个patch 添加位置编码信息,使得模型可以在不同的patch子空间中学习到相关信息,针对这些相关信息实现并行编码。自注意力机制针对当前patch 的位置的信息编码时,会将注意力集中到自己所处的位置上并针对重要的信息特征进行学习,快速地提取局部特征之间的内部关系。
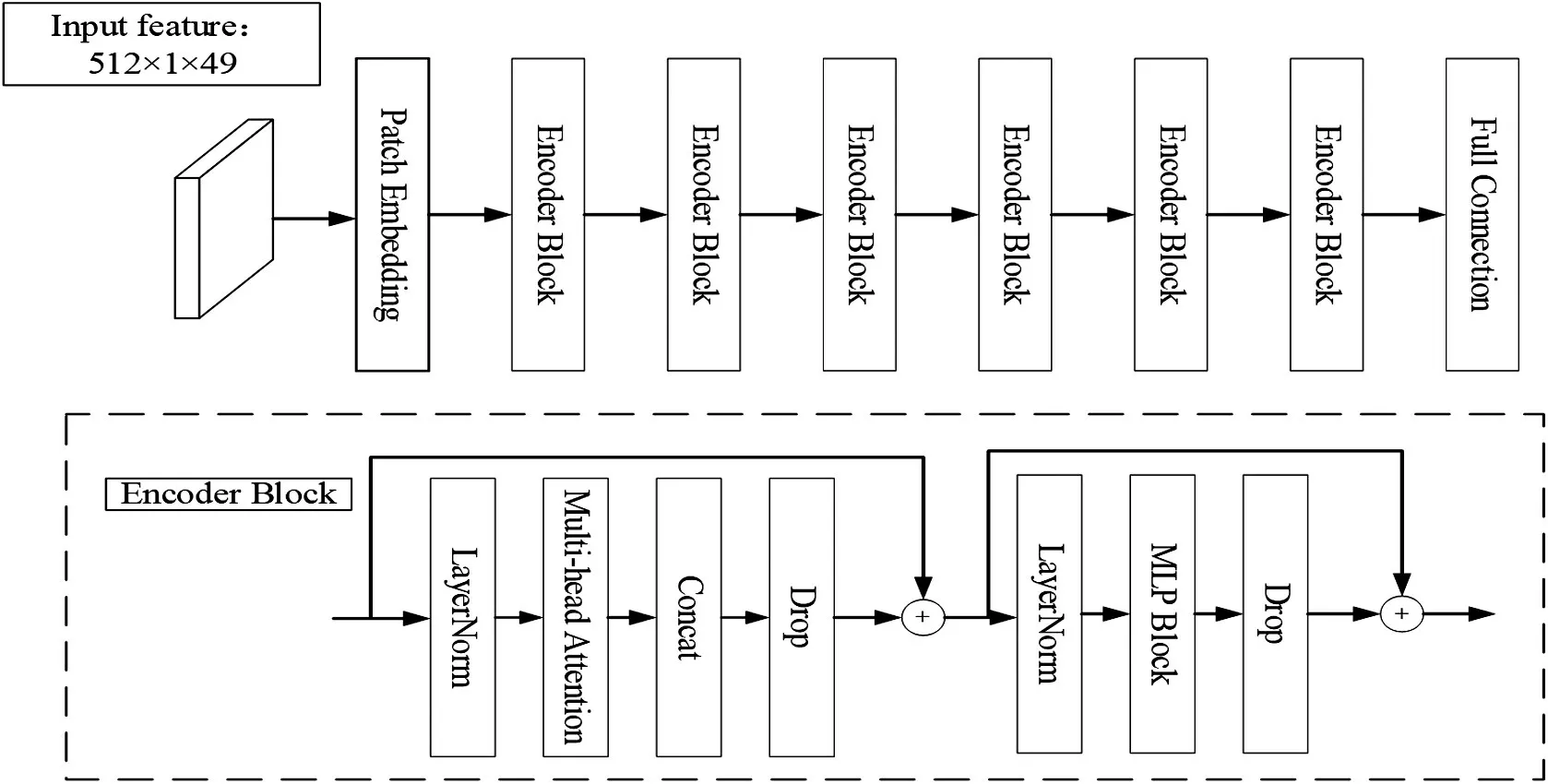
图3 多头注意力模块结构图
图4表示了多头注意力机制,其计算流程如下。
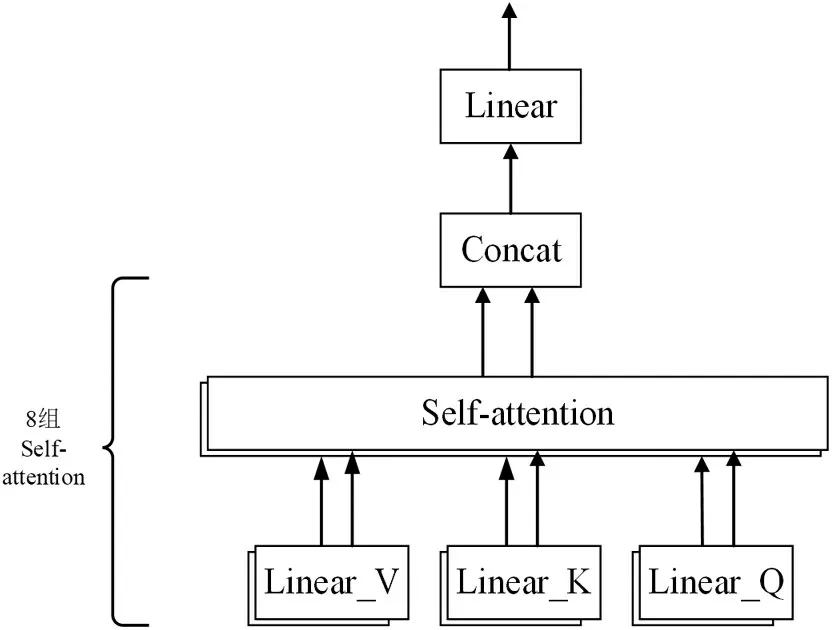
图4 多头注意力机制
⑴计算出每个注意力头对应,对多头注意力模型中的8个头分别使用自注意力机制的运算过程得到对应的结果,其计算公式如下:
其中,Q 代表字符查询向量;K 代表字符匹配向量;V代表字符值向量。从输入向量中提取得到向量的Q和K 匹配过程中得到的值越大对应的V 的权重越高;dK代表了Q和K的维度,维度越大对应的dK越大。
⑵使用Concat 操作在channel 维度上进行拼接,将拼接的结果通过WO参数进行融合,得到最终的结果,其计算公式如下:
其中,head 表示多头注意力模块的第i 个自注意力机制,Concat表示拼接操作,num为拼接向量的数量。
1.2.1 嵌入层
多头注意力模块处理的是包含位置信息与分类信息的二维矩阵向量序列,而特征提取模块输入的特征图是三维矩阵,需要将三维矩阵转化为二维向量,再添加对应的位置信息与分类信息,然后输入到编码层,其逻辑结构如图5 所示,其中左边部分为位置信息,最后一条为分类信息。嵌入层输出的特征向量是由图像块输入特征、类别向量和位置编码构成嵌入输入向量z0,其公式如下:
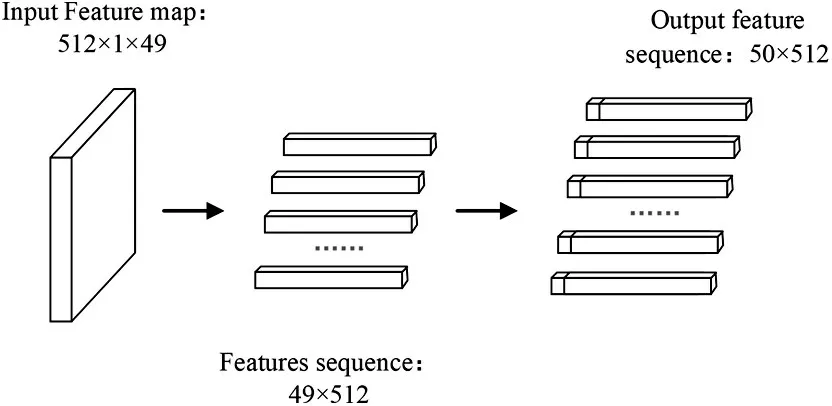
图5 特征图转为序列特征
1.2.2 编码层
编码层是重复堆叠多头注意力和多层感知机块。首先将嵌入层的输出特征传入归一化层(Layer Normalization,简称LN),经过LN后将其传入多头注意力模块,然后经过Dropout层,进行残差连接,残差之后经过LN,多层感知机块,Dropout之后完成一次编码。
多层感知机块(MLP Block)是由两个全连接、GELU激活函数和两个Dropout组成。
编码块输出的特征向量,其计算流程如下。
⑴计算出多头注意力部分的输出特征:由多头注意力机制、层归一化和跳跃连接构成,其计算公式为:
⑵计算出多层感知机部分的输出特征,由前馈网络、层归一化和跳跃连接构成,其计算公式为:
其中,Zi表示多头注意力模块的第i 个特征向量,MLP表示多层感知机,LN表示层归一化。
1.3 损失函数
本文的损失函数使用CTC Loss(Connectionist Temporal Class)来定义标签序列的概率,即通过CTC 将字符进行转录达到预测文本序列的目的。CTC 的输入为多头注意力模块输出的预测序列Y=y1,y2,…,yi,i表示输入序列的全部长度。
每个序列在L上的概率分布用表示,用“-”来代表空白字符标签,表示所有经过变换后生成标签为的所有路径的集合;然后映射函数过滤掉空白和重复的标签,如“--s-s-t---rraw-berry”映射之后变成strawberry,其条件概率表达式如下:
损失函数表达式如下:
其中,x 表示全部训练样本,li代表数据集中真实标签序列,yi代表多头注意力模块解码后预测得到的序列。
2 实验结果与分析
2.1 实验设置
实验所使用的CPU 型号为E5-2666v3,内存为128G,使用的图形处理器型号为NVIDIA Tesla P40,操作系统为Ubuntu,Python 版本为3.9,机器学习框架为Pytorch 1.12。模型在360 万中文数据集和ICPR MTWI 2018数据集上进行了预训练,所有图像大小归一化为32×192,图像批处理尺寸为16,初始学习率设置为0.001,使用adam 优化器在训练过程中对模型参数进行更新。
2.1.1 数据集
本次实验所采用的预训练集为360万中文数据集和ICPR MTWI 2018数据集。360万中文数据集其中有364 万张图片,数据集按照99:1 划分为训练集和验证集两部分。其图片是通过对语料库中的字体、大小、灰度、模糊、透视、拉伸等变化随机生成的。ICPR WTMI2018 是中英文混合数据集,其中有20000 张图片,数据集按照1:1 划分为训练集和验证集两部分。其中图片全部来自网络图片,文本内容主要为水平、倾斜、模糊和残缺文本,而且字体种类较多。
2.1.2 评价指标
自然场景文本识别的评价指标一般有两种,一种是字符识别准确率(Character recognition accuracy,简称CRA),一种是文本识别准确率(Text recognition accuracy,简称TRA)[10]。字符识别准确率一般表示字符识别正确的个数占总字符的比例,评价指标比较直观[10],其表达式为:
其中,W 表示为识别正确的字符数量,A 表示所有的字符数量。
文本识别准确率一般使用编辑距离,当一个字符需要转换成另一个字符所需要的步骤数(包括删除、插入和替换)就称之为编辑距离[10],其表达式为:
其中,其中S 表示总字符的数量,D、I、R 分别表示删除、插入、替换的步骤数[10]。
2.2 结果分析
2.2.1 消融实验
为了验证本文识别算法的性能,实验选取VGG+BiLSTM为基础模型,在规则数据集(360万中文、SVT)和不规则数据集(ICPR MTWI 2018、ICDAR 2015)共四个数据集上进行消融实验,其结果如表1所示。
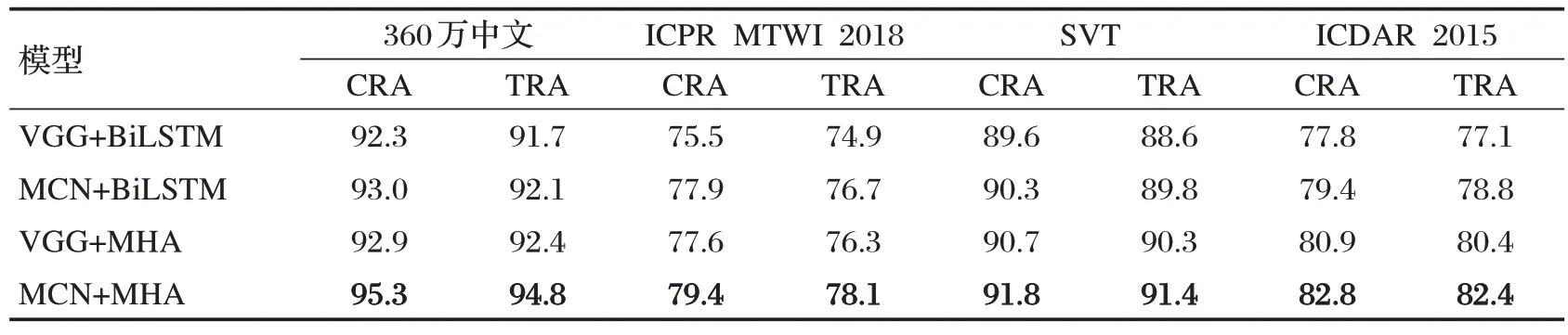
表1 规则与不规则文本数据集消融实验
由表1 中的数据可得,添加了多网络融合结构的特征提取模块(MCN)后,MCMASTR 与基础模型在规则文本和不规则文本上的平均字符准确率分别提升了0.7%、2.0%,平均文本准确率分别提升了0.6%、1.7%,证明了多网融合的可行性,它能提升文本特征提取的效果。而在使用本文提出的多头注意力模块(MHA)替换掉基础模型中的BiLSTM 后与基础模型相比,MCMASTR 在规则文本和不规则文本上的平均字符准确率分别提升了0.85%、2.0%,平均文本准确率分别提升了2.6%、2.3%,证明了多头注意力模块比BiLSTM 在字符解码方面有更好的优越性。而在使用多头注意力模块替换掉基础模型中的BiLSTM 后同样使用多网络融合结构为基础模型,与基础模型相比,MCMASTR 分别提升了1.9%、2.1%的字符准确率和2.45%、2.5%文本准确率,证明了多网络融合与多头注意力在字符识别方面有更好的表现。
图6 可以得出,实验中不断地增加多头注意力模块数量,本文的模型在规则与不规则数据集上的准确率在稳定提升,但是当模块的数量达到六个时模型整体表现最佳,而超过六个模块后训练时长增加,但是训练速度、准确率都会下降,也说明单纯的增加网络深度与模块数量不一定取得优异的结果,由于深层网络中含有大量非线性变化,每次变化相当于丢失了特征的一些原始信息,从而导致层数越深退化现象越严重,所以如何提高模型的设计思路、改进训练技巧也将成为研究的重点。

图6 多头注意力模块数量对比实验
2.2.2 对比试验
由表2 可知,本文提出的算法在超过一半的标准数据集上取得了不错的效果。本文算法在规则文本数据集SVT 上准确率能达91.4%,在不规则文本数据集ICDAR2015 和SVTP 上准确率分别能达82.4 和82.7%,均优于2019 年Yang M 等人提出的ScRN 算法[14]与2020 年Qiao Z 等人提出的SEED 算法[8]。本文算法在数据集ICDAR2013、IIT5k、CUTE80 三个数据集上准确率分别为93.1%、92.3%、84.2%与部分主流算法之间存在一定差距,但是相比于其他算法具有较强的竞争性。

表2 本文算法与近几年的主流算法的对比实验
图7 直观展示了本文方法的识别效果,可以看出在模糊情况、残缺情况、扭曲变形情况和曝光条件下均能正确识别,而CRNN算法[7]和RARE算法[11]在图片模糊、粘连、残缺等情况下无法准确的预测和识别图中的文本内容,这证明了多网络融合与多头注意力在字符识别方面有更好的表现。

图7 文本识别效果展示
3 结束语
本文提出的算法在规则文本与不规则文本数据集上都取得了不错的效果,而且能有效识别模糊、残缺、扭曲和过度曝光文本,与一般文本识别算法相比,本文方法在自然场景中的实用性更强。
本文主要研究了自然场景的中英文文本识别,而对于提高模型准确率、识别速度以及硬件移植将成为未来研究的重点。
