基于BERT-BiGRU-CRF的医疗实体识别方法
2023-08-22张云华
胡 稳,张云华
(浙江理工大学信息科学与工程学院,浙江 杭州 310018)
0 引言
基于传统就医方式存在的就医排队时间长、获取问诊结果迟缓等问题,因此,智能医疗问答系统有了广泛的市场需求,而实体识别则可视为是问答系统中极为重要的一个组成部分。
命名实体识别一般认为是序列化标注任务,主要分为传统机器学习模型和深度神经网络模型两类。在传统机器学习领域,一般使用的模型有HMM[1](Hidden Markov Model)、CRF[2](conditional random field)、SVM[3](Support Vector Machine)等。然而传统机器学习方法仍然需要大量的人工参与特征的提取,识别效果并非特别理想。近些年来,深度学习技术快速发展,使得该技术被广泛应用到实体识别任务中。得益于长短期记忆网络的优秀序列化建模能力,Hammerton[4]才能够率先把神经网络中的LSTM(Long-Short Term Memory)应用到实体识别领域中,如李明浩等人[5]将该模型使用在中医临床症状识别上,该模型随后成为了命名实体识别的基础模型之一。张聪品等人[6]使用LSTM-CRF 模型识别医疗电子病历中的身体部位、疾病名称、检查、症状和治疗五类实体,准确率达到96.29%。2017 年Google 公司提出了基于注意力机制(Attention)的Transformer模型[7],提高了模型的并行效率,获得了非常好的实验效果。李博等人[8]构建了Transformer-CRF 神经网络模型用于识别医疗领域的命名实体,具有较好的识别性能。
本文使用医疗领域数据为研究对象,使用BERT模型(Bidirectional Encoder Representation from Transformers)对原始文本数据进行词向量嵌入表示,再输入到BiGRU(BidirectionalGatedRecurrentUnits)层中获得每个词向量在所有标签中的模型得分,最后使用CRF 进行纠正BiGRU 模型得到的非法结果从而生成最终的分类结果。
1 相关技术
1.1 BERT
BERT[9]是由Google 公司推出的基于变换器的双向编码器表示技术,性能十分强大,一经推出就取得了非常优秀的成绩。BERT 模型将自注意力机制融合进双向的Tansformer 编码器,从而使得关于语句上下文的语义信息能够被更深层次的从两个方向同时获取,达到获取更强的语义特征的目的。BERT 模型的基本结构如图1 所示,图中的Trm 表示Transformer模型,Ei表示第i个文本输入向量,Ti表示第i个输出的表示向量,通过使用多层双向堆叠的Transformer 模型使得整个模型的效果更好。
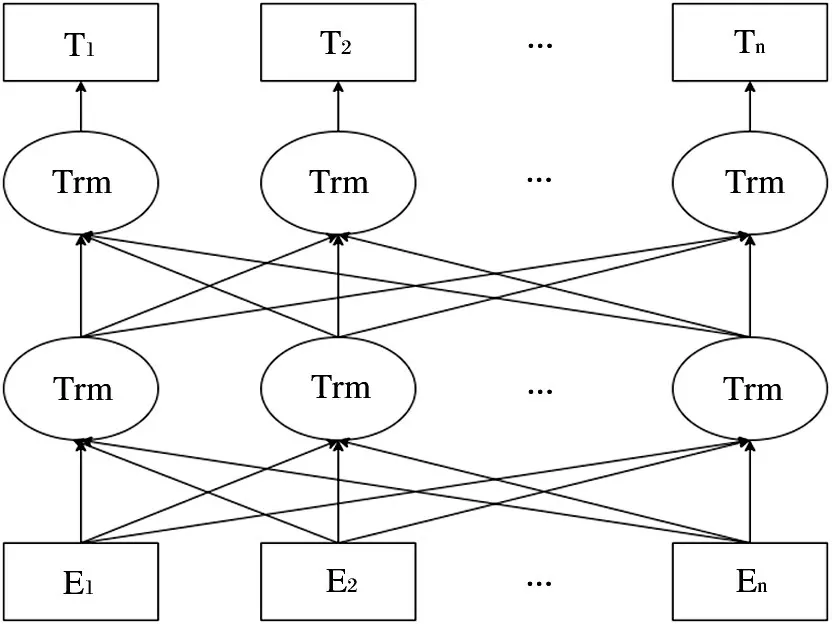
图1 BERT模型结构
BERT 模型除了使用上述模型结构之外,还提出基于Masked掩码语言模型以及下一句预测两个任务,针对一个语句分别从词语角度和语句角度进行模型训练。Masked 语言模型会随机遮住句子里的一些词语,让编码器来预测被遮住的原始单词。有80%的情况中奖单词使用Mask标记,10%的情况将其替换为其他单词,另10%的情况不变。这样做使得模型对于上下文语义信息获取的更为充分,如表1 所示。如果一个词语的一部分被Mask,这个词语其他部分也要被Mask,这种情况是全词Mask。下一句预测是指训练一个二分类模型,用这个模型来对当前两个句子是否为后继关系进行判断,即用于学习句子之间的关系。输入两个连续的句子,对该句子在句头插入[CLS]来标记,使用[SEP]标记语句结束。同时对BERT 模型进行训练,训练过程中这两个任务会一起进行,训练目标则是将他们的组合损失函数降到最低。

表1 Mask语言模型
1.2 BiGRU
在使用RNN(Recurrent Neural Network)模型时研究人员发现使用过程中可能会出现梯度消失,为了解决这一问题研究人员基于RNN 进行改进从而提出了LSTM[10]以及GRU 模型[11](Gate Recurrent Unit)。在LSTM 模型的使用过程中,通过三个门的设计来控制数据的流动。而GRU 模型是RNN 的另外一种改进方案,通过将LSTM 原有的三个门修改成两个门,合并了其中的两个门,GRU 单元如图2 所示。其中的ht−1表示前一时刻的输出,ht表示当前时刻的输出信息,xt表示当前时刻的输入信息,zt是一个更新门,用于控制信息流入下一个时刻,rt是一个重置门,用于控制信息丢失,zt和rt共同控制隐藏状态的输出。计算公式如式⑴~式⑷所示。
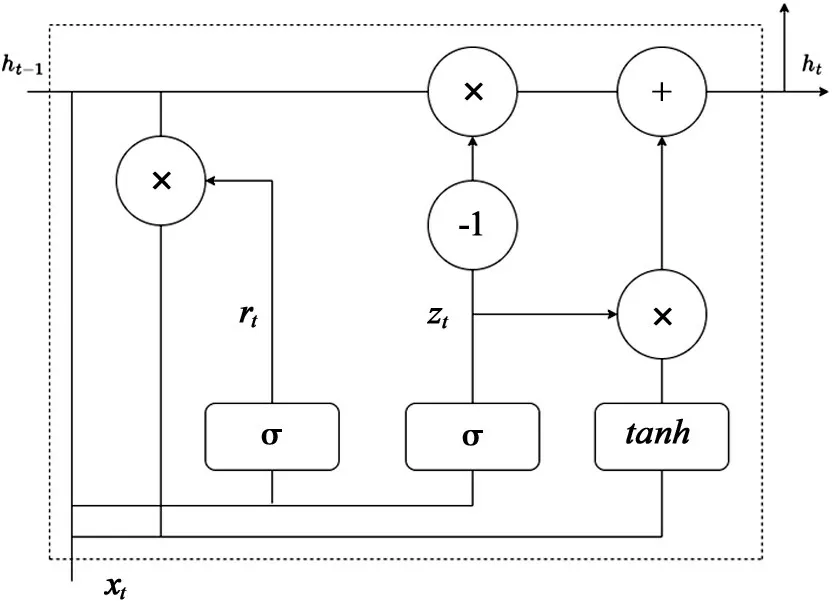
图2 GRU单元结构图
BiGRU 模型是在BiLSTM 和GRU 模型的基础上提出的一种改进模型,双向结构的GRU单元被使用来构成BiGRU 模型,这样做可以让模型同时从过去和未来两个角度获取句子特征。BiGRU 模型比原有基础模型的参数少,可以减少训练时间。
1.3 CRF
条件随机场CRF 模型是指提供任意数据时模型会给出对应的输出数据,而输出输出数据满足马尔科夫随机场定义。条件随机场结合了马尔科夫随机场和最大熵模型,主要应用于自然语言处理领域的标注问题中,其中最典型的是线性链,其形式一般如式⑸、式⑹所示。
2 模型设计
本文提出的算法模型主要由三个部分组成,分别是BERT 预训练模型、BiGRU 模型、CRF 模型。模型结构图如图3 所示。先将原始的问答数据被传入到BERT 模型中,对原始问答数据完成词向量的表示,词向量表示的数字矩阵被传入到BiGRU 模型进行获取语句的前后语义之间的特征。然而,BiGRU 模型在训练过程中考虑的是整体上下文信息,而针对标签和标签之间的依赖关系没有给予重视,所以会导致实验结果中标签前后语义出现问题。

图3 BERT-BiGRU-CRF模型结构图
根据BIO 标注法来说,B 表示当前单词为开头部分,I 表示当前单词为中间部分,O 表示无关的实体。如果对于某个疾病的标注符号为“dis”,对于症状的标注符号为“sym”,则针对这个实体识别得到的结果应该是“B-dis”、“I-dis”、“O”、“B-sym”、“I-sym”。然而对于BiGRU 模型来说,它并没有考虑标签之间的关系,而是单纯输出当前得分最高的标签。因此会出现“I-sym”、“I-dis”、“O”、“B-sym”、“I-sym”的输出,这种情况很明显不符合标注规则。因此本文在BiGRU模型的输出结果之后增加了CRF 模型来控制不合法的情况,即纠正错误。CRF 模型主要是在训练过程中根据标签之间的依赖关系学习到约束规则,从而纠正BiGRU层得到的非法标签输出。
3 实验与分析
本文使用了某医疗网站的数据作为数据集进行实验,一共8000 条数据,随机将数据进行打乱,按照80:10:10 的比值进行切分,分别用于模型的训练测试和验证,实验模型的初始化参数如表2所示。

表2 模型初始化参数
本文将随机选出的验证集数据与人工标注结果进行比照,人工标注的实体为正类,其他为负类,评估设置如表3所示。其评价指标的计算公式如下:

表3 评估设置
在对验证集进行的实验中我们可以看到,BiLSTM 模型的F1 值为69.37%,BiGRU 模型的F1 值为70.15%,BERT-BiLSTM-CRF 模型的F1 值为75.17%,BERT-BiGRU-CRF 模型的F1 值为76.39%。以上数据的具体Precision、Recall 和F1 值如表4 所示。在这一实验数据中我们可以看到,单模型的F1结果明显低于使用了BERT 模型和CRF 模型的两组模型,而其中使用BiGRU 模型在本数据集上的表现略好于BiLSTM 模型的结果。对比两组模型的训练时间,BERT-BiGRU-CRF 模型运行使用了4 小时31 分钟,而BERT-BiLSTM-CRF 模型足足使用了将近6 小时,BiGRU 模型更简单,从而,其运行速度也明显优于BiLSTM模型。
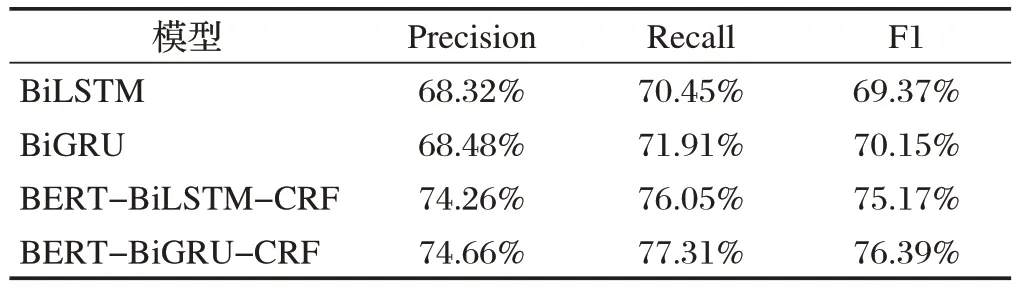
表4 实验结果
4 结束语
本文基于医疗领域数据集研究了实体识别任务,首先将原始的问答数据传入到BERT 模型中,对原始的问答数据完成词向量表示,词向量表示的数值矩阵被传入到BiGRU 模型进行获取语句的上下文特征,在完成以上操作后针对原BiGRU 模型针对标签问题的错误判定,使用CRF 模型进行修改。通过试验对比,模型最终得到的F1 值为76.39%,相比其他模型有所提升。针对实体识别任务,未来还需要做进一步实验,目前的数据来源不足,未来可以着眼于更加丰富的医疗数据来训练模型,提升模型表现。此外,BERT 模型使用的是通用语言模型,并没有使用医疗领域预训练数据,针对专用名词不能很好地识别。
