基于XLNet 的农业命名实体识别方法
2023-08-17陈明,顾凡
陈 明,顾 凡
(1.上海海洋大学 信息学院,上海 201306;2.农业部渔业信息重点实验室,上海 201306)
随着我国农业经济的持续发展,农业信息化近年来发展迅速,农技咨询服务成为农户与领域专家的重要交流渠道,农户通过线上描述农作物情况及问题,及时获得专业解答。面对海量的非结构化农业文本数据,如何快速定位关键词,挖掘深层语义关系,及时解决基层农户的问题,成为了农业信息化的关键问题。
命名实体识别(Named Entity Recognition,NER)是自然语言处理(Nature Language Processing,NLP)中的1 项基本技术,农业命名实体识别的准确性对于快速智能识别信息中的专有名词有重要作用,它决定了下游任务的效果,是下游任务的基础,例如农业关系提取[1],知识图谱构建[2],问题意图识别[3]等。
但是,在农业命名实体识别领域仍存在许多挑战。主要体现在农业领域实体构词复杂多样,缺乏标准化的农业词典,也没有公开的数据语料库,在使用分词工具对农业语料库进行分词时会存在分词错误的问题,影响模型性能[4]。在非结构化农业文本中,存在许多由专有名词和混合名词组成的混合复杂实体,例如“戊唑·吡虫啉”“苯醚·咯·噻虫”,将多个实体嵌套在1 个实体中,增加了对模型捕捉长距离特征的依赖性;“藏青3000”“C 两优农39”实体由字母、数字、汉字混合组成,汉语词语的无边界性,以及实体的复杂性和长度上的差异[5],这给农业命名实体识别增加了挑战。
农业领域命名实体识别的研究发展过程中,李想等[6]将CRF 应用在中文农业领域,对于农作物、病虫害以及农药进行了识别,王春雨等[7]基于CRF对于农业实体进行了识别,选取标注特征模板并比较了BIO 和BMES 2 种实体标注方式的效果。
随着深度学习的发展,应用深度学习神经网络模型充分识别各个领域的命名实体已成为1种趋势。出现了越来越多的预训练模型,进一步提高了命名实体识别整体的性能。其中较为重要的是Devlin 等[8]提出的BERT 模型,在农业领域,赵鹏飞[9]等提出了基于BERT 多特征融合的农业命名实体识别,证明了BERT 模型在农业领域的有效性和适用性。但是农业命名实体识别领域对于预训练模型的应用研究较少,可以在此基础上进行研究发展。
为解决以上问题,本文提出1 种基于预训练语言模型XLNet 的农业命名实体识别模型XLNet-IDCNNCRF,并构建针对农业领域的数据语料库,利用该模型对语料数据集中预定义的农作物、病虫害、农药和肥料4 类实体进行识别,通过使用预训练语言模型构建词嵌入,利用文本的多维度语义信息快速准确地识别实体,有效提高了农业命名实体识别的效果。
1 数据材料与方法
1.1 XLNet-IDCNN-CRF 命名实体识别模型
该模型由嵌入层XLNet、编码层IDCNN 和输出层CRF 构成。首先在嵌入层XLNet 中输入文本,通过预训练模型,获得低维的字向量特征,并得到序列化的文本输入,将其拼接后作为IDCNN 层输入,用于抽取句子的特征,接收语义信息后输入CRF 层,由转移概率矩阵输出概率最大的序列标签,XLNet-IDCNN-CRF 模型如图1 所示。

图1 XLNet-IDCNN-CRF 命名实体识别模型Fig.1 XLNet-IDCNN-CRF named entity recognition model
1.2 XLNet
XLNet 是由Yang 等[10]提出的1 种广义自回归预训练方法,在以往预训练模型的基础上做了改进,主要采用了3 种机制:排列语言模型(Permutation Language Model,PLM)、双流自注意力机制以及Transformer-XL 结构。
PLM 是XLNet 为了实现获取双向语义信息提出的重要方法,XLNet 为平衡自回归(AR)和自编码(AE)语言方法,在Transformer 内部通过Attention mask 矩阵来对语句进行重排列,并同时保持自回归模型的单向模式。这个过程中每一个嵌入向量和相对位置编码是保持不变的,序列不会发生变化,因此不会像掩码机制一样造成信息缺失。
因目标位置信息缺失造成的问题通过双流自注意力机制来解决。当模型没有目标位置信息时,对于有部分排列下的模型组合,预测不同目标词的概率是相同的。例如输入是[种植小麦],当有2 种排列为z=[1,2,3,4]和z=[1,2,4,3]时P(小|种植)=P(麦|种植),显然这2 个字出现在种植后面的概率是不同的,为此引入了双流自注意力机制。公式(1)、(2)如下:
其中m=1,…,M为自注意力层,hZt为内容表达式hθ(xz≤t)的简写,代表内容流主要为查询流提供其他词的内容向量,包括位置向量和内容信息;gZt为查询表达式gθ(xz<t)的简写,代表不包含预测目标的上下文语境;Q,K,V分别代表Query,Key 和Value。
XLNet 还使用Transformer-XL[11]来解决超长句子的问题。现有的大多数预训练语言模型使用的Transformer 架构对长文本编码没有很好的效果,因为无法对超过固定长度的依赖关系完成建模[12]。在Transformer 结构基础上,Transformer-XL 引入了相对位置编码以及循环机制。通过循环机制将每一个片段单独投入计算自我注意力,每一层输出作为隐藏状态存储在片段之间的Memory 存储单元中,作为预测下一个片段的额外输入,使模型可以捕获更长距离的依赖关系。具体运作方式如图2 所示,虚线区域代表前一片段的注意力层的信息,前面片段的语义信息可用于预测下一片段,通过这种方式实现了长距离依赖关系的捕捉。
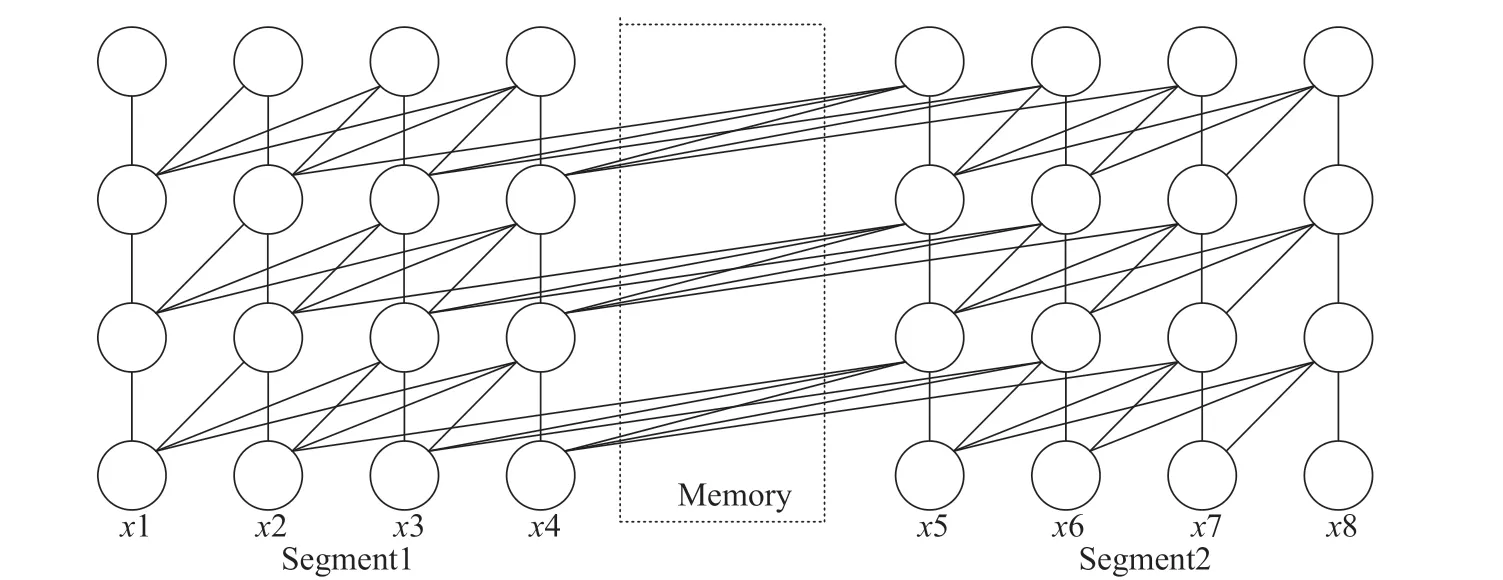
图2 Transformer-XL 循环机制Fig.2 Transformer-XL loop mechanism
XLNet 能够充分获得上下文语义信息,并且能够更灵活地捕捉长距离依赖关系,克服了AR 和AE语言模型的不足,得到更精确的词向量表示。
1.3 迭代膨胀卷积网络(IDCNN)层
卷积神经网络(CNN)在标注序列方面有一些缺陷,对于CNN 来说要获取整个句子中的全部输入信息需要加入大量的卷积层,导致参数越来越多的同时计算及其复杂,整个模型复杂度上升导致难以训练。
为了解决这个问题,Yu 等[13]提出了膨胀卷积神经网络(DCNN),使一次卷积能够获得更大感受野,获得更多的上下文信息,并且不改变卷积核窗口大小。在普通的CNN 卷积核中,增加了1 个膨胀距离,卷积操作作用在输入矩阵的时候,会跳过膨胀距离中间的输入数据,而卷积核的大小保持不变,这样能获取到更广阔输入矩阵上的数据。具体示意图如图3 所示,膨胀距离会随着层数的增加而指数增加,图3(a)是正常卷积操作,大小为3×3;图3(b)经过步长为2 的膨胀距离,3×3 的感受野扩大成7×7;图3(c)膨胀距离为4,感受野扩大成15×15。

图3 膨胀卷积示意图Fig.3 Schematic diagram of dilated convolution
迭代膨胀卷积(IDCNN)[14]则是在膨胀卷积的基础上,将4 个大小相同的膨胀卷积模型叠加在一起,每个膨胀卷积块内膨胀距离为1,1,2。反复利用单位膨胀卷积,使每一次输出的结果作为下一次膨胀卷积的输入。参数线性增加的同时感受野呈指数增加,随着层数增加很快覆盖到全部输入序列。IDCNN 与BiLSTM 模型在计算词的标签概率上非常相似,但是IDCNN 在处理速度上可以充分利用GPU 并行计算的优势,快于BiLSTM,减少训练时间。对于XLNet 层输入的向量,经过IDCNN 层提取特征,输出到下一层标签解码。
1.4 条件随机场(CRF)层
理论上IDCNN 层输出的结果包含了每个标签的分数值,可以直接输出概率最大的标签,但是标签之间有很强的依赖性,这种依赖关系可以理解成需要1 种约束条件,以确保输出序列的标签是合法的。
Lafferty 等[15]提出了CRF 模型可以对输出标签进行联合建模。对于输入句子X=(X1,X2,…,Xn),设定P为IDCNN 网络输出的分数矩阵。P的大小为n×k,其中n表示输入句子包含字的数量,k为不同标签的数量,Pi,j对应于句子中第i个单词的第j个标签的分数。对于输出的标签序列预测y=(y1,y2,…,yn),它的得分定义为
其中A是转移分数的矩阵,Ai,j表示从标签i到标签j的转移分数。y0和yn是句子开始和结束的标记。在所有可能的标签序列上,通过Softmax 函数得到标签序列y的条件概率为
YX代表句子X的所有可能的标记序列。最后通过Viterbi 算法确定最优标签序列y*作为模型的最终标记结果。如式(5)所示
2 实验及结果分析
2.1 实验数据
2.1.1 语料采集与处理 由于农业领域的命名实体识别研究较少,并且缺乏公开的语料库,本文通过数据收集、清洗、注释,建立了农业领域的实体识别语料库。本文主要运用爬虫框架来进行实验数据的采集,抓取中国农业信息网(http://www.agri.gov.cn/)、技E 网(http://www.ctex.cn/)、中国作物种植信息网(http://www.cgris.net/)等农业网站,主要内容包括农作物信息、病虫害、农药、施肥等相关的内容、评论及描述信息。
由于通过爬虫抓取的网页信息中带有大量冗余无关的类如网页标签、特殊字符等非文本结构数据,增加数据标注的难度,本研究通过Python 正则表达式、人工删除噪声文本等初步清洗的处理方式,保证数据可靠性,将文本数据处理成规范化的农业语料库。
2.1.2 数据标注 由于农业领域缺乏公开的数据语料库,也没有广泛使用的标注规范,对于通过清洗的标准化语料库,结合农业领域特点,通过人工标注方法进行标记语料库,其中,农作物实体包括植物名称及品种名称,如水稻和‘汕优63’,农药实体也包括产品名称和化学品名称,如敌敌畏和甲基异柳磷。不同类型的实体标注符号与示例如表1所示。

表1 语料库实体标注符号与示例Table 1 Corpus entity labeling symbols and examples
本文采用YEDDA 标注工具对整个语料库进行标注。标注过程使用BIO 编码标注方式。在该编码方式中,实体的开端用B 表示,实体的中间和结尾部分用I 表示,与实体无关的标签用O 表示。语料库共包含实体20 835 个,其中包括7 267 个农作物名称,6 645 个病虫害名称,3 420 个农药名称,3 503个肥料名称,语料库统计信息如表2 所示。
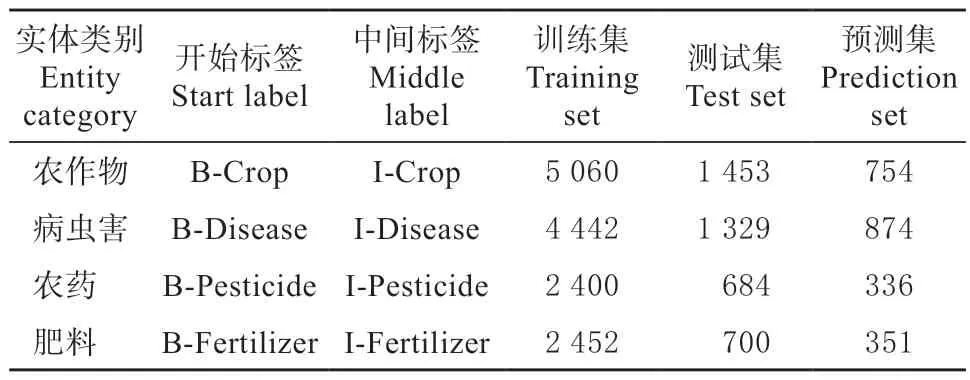
表2 语料库统计信息Table 2 Corpus Statistics
为验证XLNet-IDCNN-CRF 模型有效性,基于构建的自标注数据集来验证模型的识别性能,将语料库按7∶2∶1 的比例划分为训练集、测试集、验证集。验证集用于验证模型的训练情况,测试集的实验结果可作为模型实体识别性能的评价指标。
2.2 实验环境与参数设置
本文实验的命名实体识别模型基于Pytorch 框架,具体实验环境设置见表3 所示。

表3 实验环境设置Table 3 Experimental environment settings
实验参数具体设置:选取Adam 优化算法,学习率设置为1e-5,IDCNN 层卷积核个数为100 个,大小为3×3,膨胀距离为1,1,2,卷积层数为4 层。选取Relu 作为激活函数,Dropout 率设置为0.1,模型序列最大长度为128,批次大小为32,最大迭代次数为50。
2.3 评价指标
命名实体识别实验通常采用准确率(P),召回率(R),F1值来评价模型的性能优劣,其计算公式为
其中TP表示模型正确识别的标签总数,FP表示模型将错误的识别成正确的标签总数,FN表示模型将正确的识别成错误的标签总数。
2.4 实验结果与分析
2.4.1 编码层性能对比 为了验证编码层IDCNN模型和BiLSTM 模型的性能,将数据集在2 种编码层模型中进行实验。模型初始的参数为由Word2vec[16]训练得到的100 维预训练字符向量。识别结果如表4 所示。
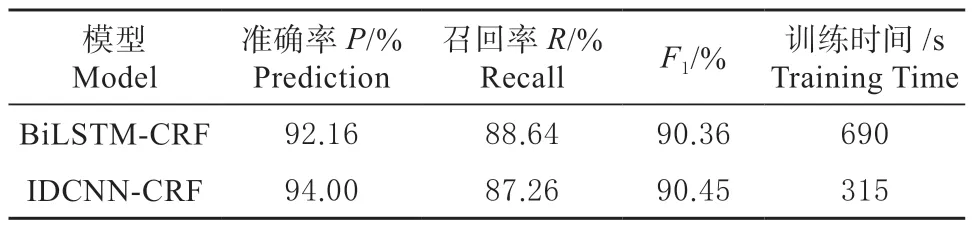
表4 不同编码层识别结果Table 4 Identification results of different coding layers
IDCNN-CRF 与BiLSTM-CRF 模型在精度差距极小的情况下,由于IDCNN 继承了CNN 的特点,充分利用GPU 并行计算与BiLSTM-CRF 模型相比,训练时间减少了375 s。在没有明显精度损失的情况下,应充分发挥IDCNN 的速度优势,提高模型响应速度。
2.4.2 不同预训练模型性能对比 为验证XLNet-IDCNN-CRF 的性能,本文在自构建的语料数据集上进行了XLNet 与其他不同的预训练语言模型的对比,包括BERT 模型、ELMo[17]模型以及作为基线的使用Word2vec 根据原始文件的设置生成字符级嵌入的IDCNN-CRF 模型。编码层与输出层统一使用IDCNN 和CRF 模型,对比结果如图4 所示。

图4 预训练语言模型实验结果对比图Fig.4 Comparison of experimental results of pre-trained language models
XLNet 在预训练模型中取得了最好的效果,在准确率、召回率以及F1值上都超过了其他预训练模型。农业领域中通常存在一词多义现象,例如“李”即可以代表水果“李”,也在很多情况下是某人的姓氏,无法消除歧义会对实体识别的结果带来一定误差。IDCNN-CRF 模型使用传统的Word2Vec 获取的词向量,该模型生成的字向量是静态的,表征单一,无法获取同一词汇的多种含义,只在句子的表面提取特征,无法融入内部特征,因此在对比中效果最差;ELMo 能够实现动态获取词向量,将词向量由静态更改为随语境改变的上下文学习函数,因此能部分解决一词多义问题,但是模型无法从上下文不同方向进行预测,因而无法获取进一步丰富的语义信息,在F1值上略高于基线1.67%;BERT 在之前预训练模型功能的基础上,运用了Mask 掩码机制以及自编码语言模型,更好地获取上下文信息,得到更准确的语义表示,F1值进一步提升了0.77%;而XLNet 则在BERT 的基础上,弥补了BERT 在微调和预训练出现的差异,增强了捕捉长距离依赖关系的能力,模型的语义表征能力更强,因此在准确率、召回率和F1 值上都分别超过了BERT 1.30、1.19、1.22 个百分点,实现了识别效果的提升。
2.4.3 不同实体结果分析 在效果最好的XLNet-IDCNN-CRF 模型上,各不同种类的实体具体数值如图5 所示。

图5 XLNet-IDCNN-CRF 模型不同实体对比图Fig.5 Comparison of different entities in the XLNet-IDCNN-CRF model
从图5 可见,农作物、病虫害的F1值普遍比农药和肥料要高。通过分析,农药和肥料的实体名称大多是“过磷酸钙”、“马拉硫磷”等化学物质,词语构成复杂,混合嵌套实体较多,易造成实体判定混淆,并且命名规律性较差,而很多农作物和病虫害实体构成结构简单,有着明确的边界特征,例如“菜”“虫”“病”等,增加了模型对于该类实体的识别准确性。造成召回率和F1 值差异的主要原因还有数据集中农药和肥料的数据量相比农作物和病虫害要小很多,由于数据有限,识别准确的难度比起实体丰富的另外2 类要大。进一步改进应该从丰富农业领域数据语料库入手,获取更多数据支撑农业领域的实体识别研究。
3 结论
本文提出了XLNet-IDCNN-CRF 的农业命名实体识别模型。通过XLNet 预训练生成含有上下文信息的动态字向量,更好地传递语义之间的上下文信息,更准确地捕获长距离依赖关系,通过IDCNN网络提升了训练速度。在自构建的农业领域标注语料库上实验结果可以达到93.91%的F1值,相较于其他主流模型有了进一步的提升,能较好地完成农业命名实体识别,对农业领域的下游任务应用具有一定的参考价值。
