基于改进YOLOv7的口罩佩戴检测
2023-08-16付惠琛高军伟车鲁阳
付惠琛, 高军伟*, 车鲁阳
(1.青岛大学 自动化学院, 山东 青岛 266071;2.山东省工业控制技术重点实验室, 山东 青岛 266071)
1 引言
新冠疫情爆发以来,我国坚持动态清零政策,保证了极低的感染率、病亡率,而居民外出佩戴好口罩,仍是预防疫情反扑的重要方法[1]。但随着时间的推移以及国家正确政策下社会有条不紊运行的情况,让许多居民心存侥幸,麻痹大意,出现了不规范佩戴口罩的情况,例如口罩未覆盖口鼻、口罩戴在下巴上甚至会有不佩戴口罩的情况出现[2]。因此,在人流密集的公共场合进行口罩佩戴检测,对疫情防控有着重要的作用。传统的口罩检测只是检测了人脸和口罩这两个目标,只能判断出目标人物是否佩戴口罩而无法检测出目标人物的佩戴情况是否有误,针对侧面和遮挡等情况的识别效果也不尽如人意。
随着社会的需要和深度学习[3]的发展,出现了不少目标检测算法,如Fast-RCNN算法[4]、SSD算法和YOLO系列算法[5]等。文献[6]在YOLO算法中引入了MobileNetv2网络对口罩的佩戴情况进行分类,提高了动态检测的速度;文献[7]在YOLOv4算法的基础上增加了路径聚合网络,并使用标签平滑来降低损失函数,但只是简单地分了是否佩戴口罩这两个类别,没有考虑佩戴错误的情况。YOLO系列算法的检测速度快,精度较高,但考虑到某些具体的检测目标有特征复杂、背景多样等特点,必须对网络结构进行相应的改进。文献[8]通过引入数据增广的方法,提高了细胞信息的利用率。随着检测算法精度和速度的提升,出现了不少能完成实时检测任务的算法。文献[9]通过模板匹配与LSTM相结合,提升了模型检测准确率且能够实现目标实时检测。在实际的检测场景中,多目标检测逐渐成为主流。文献[10]中基于热力图的Top-down和Bottom-up方法可以有效地完成多目标检测任务。随着网络复杂性的提高,网络模型的泛化能力十分重要。文献[11]通过设计随机扩散器的方法,提高了网络的泛化能力。
本文将居民佩戴口罩时常见的3种情况(没有佩戴口罩、正确佩戴口罩、错误佩戴口罩)设为检测目标,对YOLOv7算法进行改进。在Head区域加入了卷积注意力机制(CBAM),从通道和空间两方面入手,使得网络更加关注于目标的重要特征,提高了网络对口罩佩戴目标的学习能力。在主干网络(Backbone)区引入了改进后的ConvNeXT,对原有的SPPCSPC进行改进,在原有池化层的结构上增加了串行连接,在不降低识别精度的同时加快了收敛速度和识别速度。
2 YOLOv7算法
YOLOv7算法在2022年由Alexey Bochkovskiy团队提出,在检测精度和速度两方面均优于YOLOv5。YOLOv7的整体结构由输入层、主干网络(Backbone)、Head和预测端4部分组成,其模型结构如图1所示。其中输入层对数据的部分预处理方法延用YOLOv5,如Mosaic数据增强、自适应锚框计算和图片自适应缩放等。
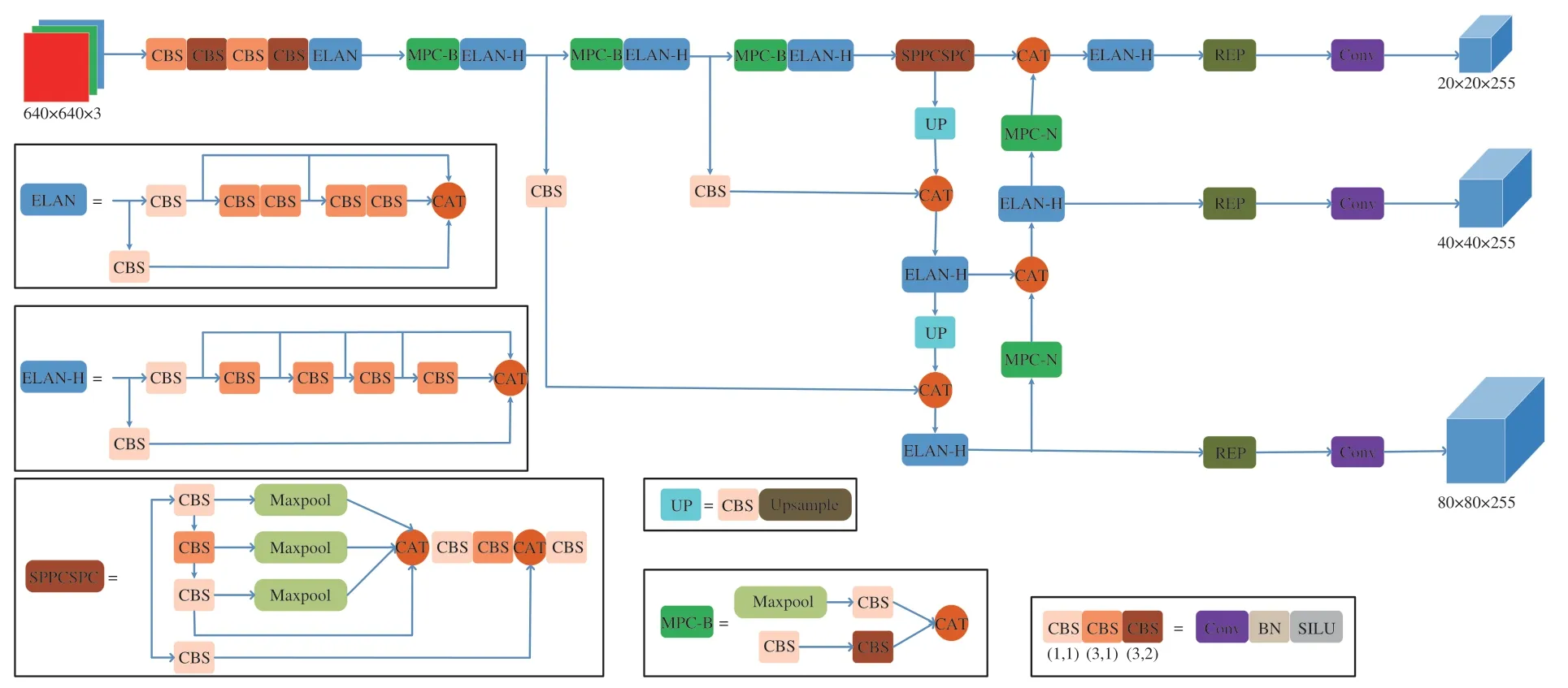
图1 YOLOv7模型结构图Fig.1 YOLOv7 model structure
Mosaic数据增强通过对图片进行随机的缩放、裁剪、排布来充实检测目标的背景变相地对batch_size进行提高。自适应锚框计算会在网络模型训练的初始状态设定好锚框,随后输出一个预测框,将锚框跟真实框进行对照,再多次计算误差并进行反馈,通过不断的计算和补偿来选取适应度最好的锚框,从而产生最后的预测框[12]。图片自适应缩放通过获取较小的放缩系数减少图片放缩后增添的黑边,在推理时减少信息冗余,大幅减少计算量以及提高检测的速度[13]。
YOLOv7对Mosaic数据增强方法进行了优化。传统的Mosaic方法会选取4张图片进行增强,而YOLOv7则会根据函数的随机生成值与超参数值进行比较,当随机值过小时会关闭Mosaic数据增强功能,当随机值适中时会抽取4张图片进行增强,而随机值过大时则会选取9张图片进行增强,从而更加灵活地增加了数据的多样性。
主干网络Backbone由CBS模块、ELAN模块和MPC-B模块组成。其中CBS模块包含了卷积(Conv)、批正则化层(BN)和SiLU激活函数这三部分。MPC-B模块由1个池化层和3个CBS组成,作用是下采样,同时通过卷积和池化层的结合可以获取局部小区域所有值的信息,避免了池化层只获取最大值的弊端。ELAN模块由多个CBS组成,是一个高效聚合的网络结构,删除了1×1的卷积,提高了GPU计算效率,大幅降低了访问内存的消耗,并采用了梯度分割的思想,在卷积网络的输出和输入层直接添加了较短的连接,使得梯度流在不同的网络结构中传播,解决了输入以及梯度信息的过度膨胀,同时能控制最短和最长的梯度路径,使得网络能提取更多的特征,使训练更加高效和精确。
Head层主要由SPPCSPC模块、ELAN-H模块、MPC-N模块、UPSample模块和RepConv模块组成。SPPCSPC是一种空间金字塔池化改进模块[14],内部由多个CBS模块和池化层组成,通过最大池化来得到不同的感受野,在使得算法能适应不同分辨率的图片的同时,能防止图像在剪裁和放缩过程中出发生失真,还能避免卷积对图像的特征重复提取,降低计算量,加速预选框的生成。ELAN-H模块与ELAN模块在功能和结构上高度类似,区别于ELAN模块在第二条分支将3个输出进行相加,ELAN-H则将5个CBS的结果取和。MPC-N模块则是在MPC-B模块的基础上增加了与前向输出层的链接。UPSample模块的作用是上采样,采用最近邻插值的方法[15]能减少网络的计算量。RepConv模块是一个结构重参数化模块,能将训练中结构的改变转变为推理过程时参数的变化,将结构的等价替换转变为参数的等价替换,从而达到提高性能、节省空间的目的。
最后的预测端包括了损失函数计算以及边界框预测。总体损失函数由定位损失、目标置信度损失和分类损失3部分组成,其中目标置信度和分类损失采用了BCEWithLogitsLoss算法,坐标损失采用CIoU算法。
3 改进的YOLOv7
3.1 卷积注意力机制(CBAM)
除了网络结构的深度、宽度以及网络的基数这3个重要因素外,注意力机制也能提高卷积网络的性能[16]。注意力机制的添加能帮助卷积神经网络更重视目标重要的特征以及忽略不必要的特征。卷积注意力机制(CBAM)结构如图2所示。
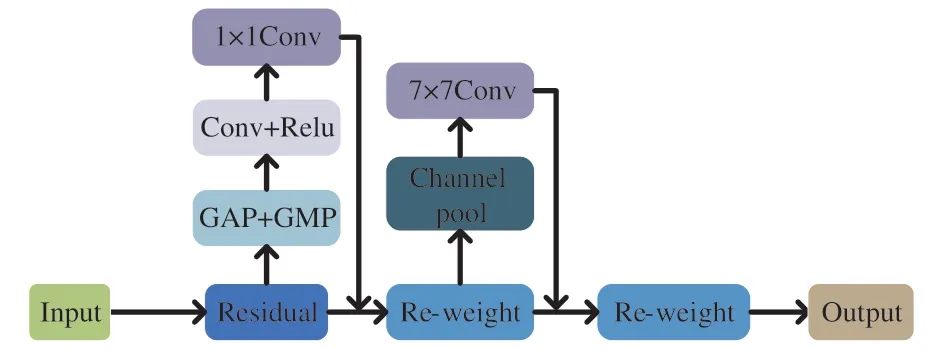
图2 卷积注意力结构图Fig.2 Convolutional attention structure diagram
卷积运算基于通道和空间两种信息来综合提取信息特征。卷积注意力机制(CBAM)从这两个方面入手,融合了通道注意模块(CAM)和空间注意模块(SAM)来提高卷积神经网络的学习能力。
通道注意力Mc来关注特征的通道信息,从而确定图像中由主要特征的目标及通道。通道注意力Mc的计算如公式(1)所示:
式中:σ为sigmoid函数,W0∈RC/r×C,W1∈RC×C/r,当σ在W0前时为ReLU激活函数。空间注意模块(SAM)也使用了平均池化(AP)和最大池化(MP)的方法,采用了特征空间的关系来产生空间注意力Ms从而确定空间内包含主要特征信息的位置。Ms的计算如公式(2)所示。式中σ为sigmoid函数,f7×7是大小为7的卷积核。
3.2 网络改进ConvNeXt
近几年来,Transformer[17]网络以其模态融合能力和全局特性被大量研究和应用,但是因其计算效率低下,局部信息获取的能力较弱且顶层梯度会被归一化部分阻断等问题,使Transformer的应用不如卷积神经网络广泛。ConvNeXt在ResNet50卷积网络的基础上引入了Transformer的优点,在保留卷积网络结构简洁的同时提高了性能[18]。ResNet50网络使用的卷积核尺寸为3,而ConvNeXt借鉴了Transformer将卷积核尺寸上调为7,同时将ResNet50中常用的ReLU激活函数替换为Transformer网络中常用的GeLU激活函数,并从Transformer网络中获得启发,减少了激活函数和正则化函数的使用,从而减少了计算量。本文通过自身数据的特点对ConvNeXt进行改进,将正则化函数中的层正则化(Layer Normalization)替换成批正则化(Batch Normalization)。进一步提高了模型的鲁棒性。改进后的ConvNeXt的结构如图3所示。

图3 ConvNeXt改进结构图Fig.3 Improved ConvNeXt structure diagram
3.3 空间金字塔池化改进
空间金字塔池化的功能主要是使图像可以以任意大小和像素宽高比输入,其输入端可以接纳任意大小的图片[19]。本文对原有的SPPCSPC结构进行改进,将原有的3个并行的池化层添加上串行结构,在不改变原有结构感受野的情况下,提升检测速度同时能帮助网络收敛和抑制过拟合。改进前后的结构如图4所示。具体实现过程为:
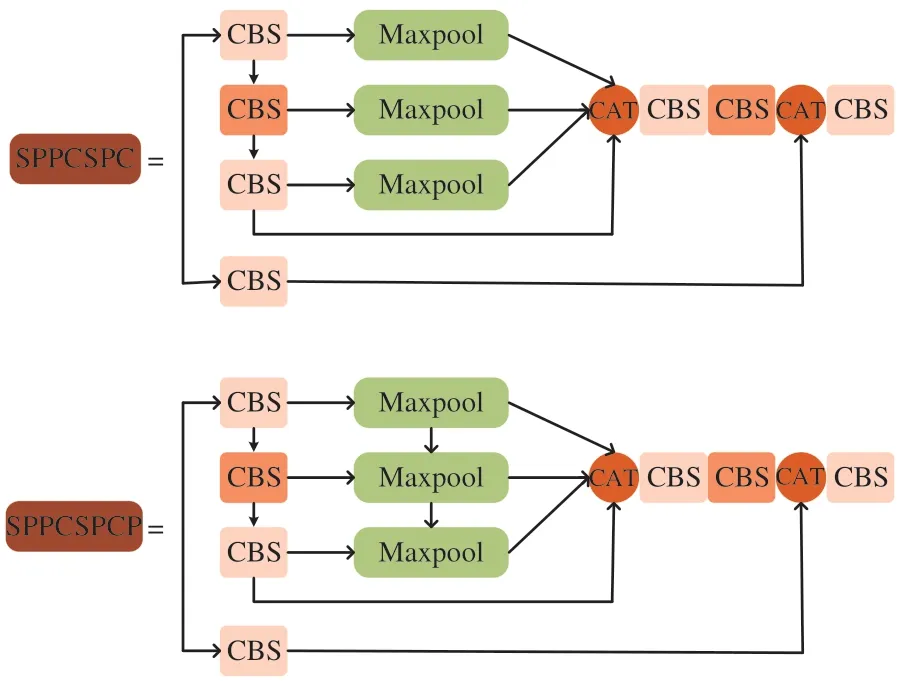
图4 空间金字塔池化结构改进图Fig.4 Diagram of improved space pyramid pool structure
(1)对Backbone主干网络中ELAN-H模块的特征输出进行CBS卷积操作,即分别经过卷积操作、批正则化和SiLU激活函数处理。
(2)对第一步中进行过一次CBS卷积操作的特征再进行两次CBS卷积操作,并在每个卷积操作后进行一次最大池化处理,随后将3次最大池化后的特征进行串并行连接,并进行特征层融合。
(3)将第二步中的结果经过两次CBS卷积处理后与第一步中的结果融合,再最后进行一次CBS处理,即可得到最终输出特征层。
4 实验与结果分析
4.1 实验环境
本文的算法在Pycharm集成软件中实现,采用的编程语言为Python3.9,使用Pytorch 1.12.1作为深度学习框架,并使用了CUDA11.3硬件加速工具。实验平台使用了NVIDIA RTX3080 GPU,Intel(R)Core(TM)i7-12700KF @ 3.60 GHz处理器,操作系统为Win10,设备内存为32.0 GB。
4.2 数据集的准备
由于目前网络上公开的口罩佩戴情况数据集较少,而且很少有不正确佩戴口罩的数据集,因此本文通过在互联网查找和组织同学拍摄共计9 000余张图片,采用LabelImg软件自行标注制作了口罩佩戴数据集。数据集包括了各种不同的场景,其中有不佩戴口罩、正确佩戴口罩和错误佩戴口罩3种情况,包含了正脸、左侧脸、右侧脸3种角度及不同的背景、光线和遮挡等情形,如图5所示。

图5 数据集图片示例Fig.5 Example of dataset images
数据分类包括没有佩戴口罩、正确佩戴口罩和不正确佩戴口罩3种,并将训练集、测试集以及验证集按照8∶1∶1的比例进行分割,训练批次为16,学习率0.005,模型迭代150次。
表1展示了数据集中各类情况的数量。
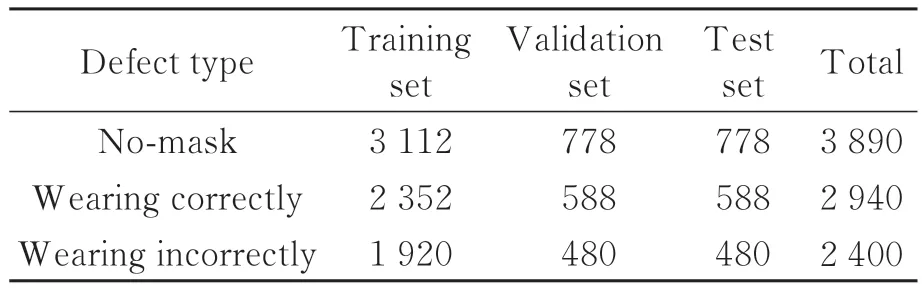
表1 数据集中的目标分类及数量Tab.1 Classification and number of targets in the data set
4.3 模型评估指标
本文采用精度(P)、召回率(R)、均值平均精度(mAP)作为评价指标检验模型的效果。精度和召回率的表达式为:
以本文检测中没有佩戴口罩类别No-mask为例,TP为训练完成的模型将没有佩戴口罩的图片目标检测为No-mask类别的数量,FP为模型将正确佩戴口罩以及错误佩戴口罩的图片目标检测为No-mask类别的数量,FN为模型将没有佩戴口罩的图片目标检测为正确佩戴口罩(Wearing correctly)和不正确佩戴口罩(Wearing incorrectly)类别的数量。精度(P)描述了模型对该类别分类的精确情况,召回率(R)描述了模型对该分类的漏检情况,平均精度(AP)是P-R曲线与横纵坐标正半轴所围成的面积,从精度(P)和召回率(R)两个方面评估模型在该类别上的检测效果。均值平均精度(mAP)是模型中所有分类的平均精度(AP)的均值,能有效评估该模型对所有分类的检测情况。平均精度(AP)和均值平均精度(mAP)的计算公式如式(5)和式(6)所示:
4.4 实验设计
为了验证改进后的算法对口罩佩戴检测的效果,本文采用了两组对照实验,第一组将改进后的算法模型与和原始的YOLOv7算法以及不同改进部分的算法模型进行对照,第二组将改进后的算法与Faster-RCNN算法进行比较。
4.4.1 损失函数收敛对比
改进前后的YOLOv7 在训练过程中验证集的损失函数变化如图6所示,图中曲线A为原始YOLOv7损失函数,曲线B为改进后的损失函数。损失函数曲线在初始阶段下降较快且波动很大。随着训练轮数的增加,在训练50个Epoch之后,波动起伏开始变小,损失函数逐渐降低,曲线趋于平稳。在训练约100个Epoch时,损失函数逐渐稳定,模型逐渐收敛。由图6可见改进后的算法损失函数更低且收敛更快。
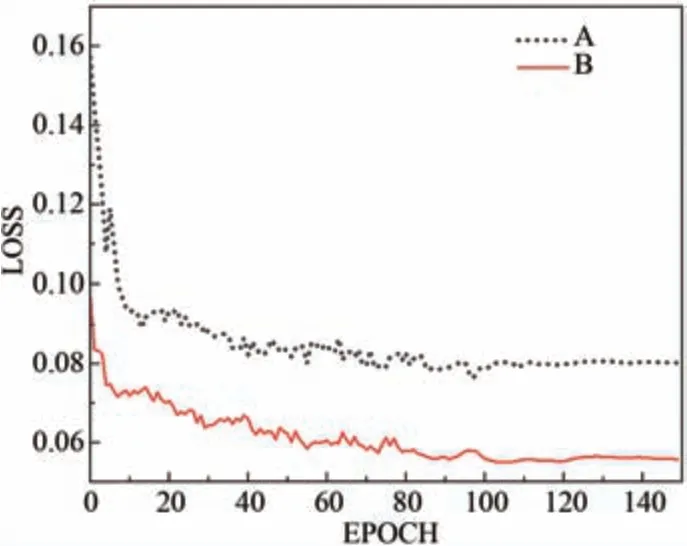
图6 损失函数对比Fig.6 Example of dataset images
4.4.2 改进方法对模型性能的影响
本文通过对不同改进方法的检测指标进行对照实验,分析不同改进部分对网络性能提升情况,表2为不同改进方法对模型性能的改进结果。由表2中数据对比可见,YOLOv7-A在Head层引入卷积注意力(CABM)使得原始模型的精度提升3.2%,mAP值提升0.7%。YOLOv7-B在YOLOv7-A的基础上在Backbone层中引入了改进的ConNeXt网络结构,使得原始模型的精度提升2.7%,mAP值提升1.7%。YOLOv7-C在YOLOv7-B的基础上在Head层中对SPPCSPC进行优化,使得原始模型的损失函数显著下降,精度提升2.2%,mAP值提升3.6%。

表2 不同改进方法的性能指标Tab.2 Performance index of different improvement methods
4.4.3 改进前后与主流检测模型的性能对比
模型训练完成后,采用多次检测抽样的统计方法,将验证集中的数据进行测试,并与改进前的YOLOv7以及Fast-RCNN进行对比,验证集中包含了单人、多人及侧面等不同情况,部分对比结果如图7所示。由图7(a)、图7(b)和图7(c)对比可以看出,从侧面角度检测时,改进后的算法置信度比Fast-RCNN和原始YOLOv7算法均有提升;由图7(d)、图7(e)和图7(f)对比可以看出,目标错误佩戴口罩时,改进后的算法置信度比Fast-RCNN和原始YOLOv7算法均有提升;由正面和侧面对比可以得出,侧面的识别置信度要低于正面的识别置信度;由图7(g)、图7(h)和图7(i)对比可以看出,在3种类别中,改进后的算法的置信度比其他两种算法高,同时图7(g)中Fast-RCNN算法发生错检情况且3种类别的置信度均较低,图7(h)中改进前的算法将错误佩戴口罩的情况误检为正确佩戴口罩,而图7(f)中改进后算法则进行了正确的分类。从3种算法的检测情况对比可以得出,改进后的YOLOv7算法检测结果最好,尤其在侧面和多人的检测情况下,效果提升更多。

图7 Fast-RCNN、YOLOv7与改进YOLOv7的检测结果对比。Fig.7 Comparison of Fast-RCNN, YOLOv7 and improved YOLOv7 detection results.
将本文算法与其他的检测算法的检测指标进行对比,结果如表3所示。改进后的YOLOv7的mAP值比其他算法有所提升,比Fast-RCNN高21.4%,比YOLOv7_A、YOLOv7_B以及原始YOLOv7分别高1.9%、2.9%、3.6%。相较于原始YOLOv7,各个类别的检测精度均有提升,没佩戴口罩类别的AP值提升6.8%,正确佩戴口罩类别的AP值提升2.1%,不正确佩戴口罩类别的AP值提升1.7%。通过数据对比可以得出结论,改进后的YOLOv7的检测指标要优于其他算法。
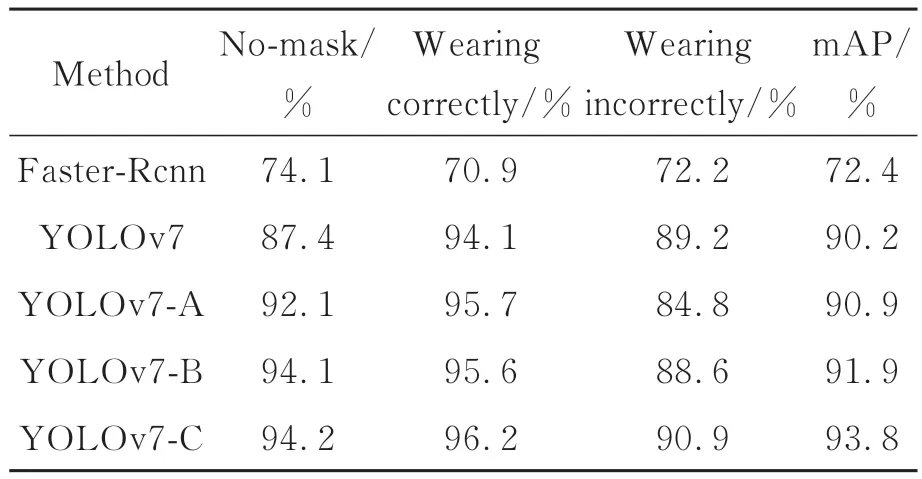
表3 不同检测算法的性能指标对比Tab.3 Comparison of performance indicators of different detection algorithms
5 结论
针对目前部分居民口罩佩戴不正确等问题,本文提出了一种改进YOLOv7的口罩佩戴检测算法。通过自行拍摄和网上搜集,丰富了口罩佩戴错误类别以及侧面遮挡等情况的数据集。通过在Head层引入卷积注意力机制,加强了网络结构在空间和通道上对有效特征的重视,提高了网络对口罩佩戴目标的学习能力。在Backbone层引入ConvNeXt网络结构,提高了网络结构的性能和鲁棒性。对Head层SPPCSPC模块进行优化,有效减少了损失函数,将平均精度从90.2%提高到93.8%。同时各个类别的检测精度均有提升,没佩戴口罩、正确佩戴口罩、不正确佩戴口罩类别的精度提升分别提升6.8%、2.1%、1.7%;并且减少了漏检和错检的情况,提高了系统的鲁棒性。
