基于时间相关性注意力的行为识别
2023-08-16刘宽汪威申红婷候红涛郭明镇罗子江
刘宽, 汪威, 申红婷, 候红涛, 郭明镇, 罗子江*
(1.贵州财经大学 信息学院,贵州 贵阳550025;2.北京云迹科技股份有限公司 智能中台,北京 100089)
1 引言
图像是信息的载体,通过卷积神经网络对单张图片的空间信息进行特征提取,然后进行特征编码,可以识别图中包含的物体类别以及空间位置等信息,因而图像识别是计算机视觉领域的主要研究方向之一。然而单张图片所包含的信息往往是静态、非连续的,随着视频数据的暴增,视频中承载着更丰富和动态连续的行为信息,所以行为识别任务成为当前研究的重点。
与图像识别不同,行为识别不仅要分析目标体的空间信息,还要分析时间维度上的信息,如何更好地提取出时间-空间特征是问题的关键。传统的行为识别方法[1-4]融入大量的手工特征去提取视频帧之间的关系,虽然取得了不错的成绩但计算成本太高。使用单支卷积神经网络(Convolutional Neural Networks, CNN)[5-6]可以快速完成行为识别任务,但局限于视频帧之间的运动信息而表现弱于传统方法IDT[1]。为了提取运动信息,Simonyan等[7]对视频数据的空间和时间维度进行建模,并提出双流CNN进行行为识别。双流法包含两个通道,其中空间通道使用单张RGB图像作为输入用以提取行为动作信息,时间通道使用多帧相邻图像之间的光流作为输入用以提取行为时序信息,最后将时间和空间信息进行融合从而预测行为类别,并在多个行为数据集上表现优于IDT。双流法为提取时间和空间特征提供了一个新的思路,但是传统的双流网络大多使用2D卷积作为特征提取器,其缺点在于不能同时学习视频间的时空特征,因此文献[8-9]提出使用3D卷积神经网络同时在时间和空间维度上进行特征提取,有效学习到行为连续性,相较于文献[7]在UCF101数据集上获得88%的top-1准确率,I3D[9]带来10%的性能提升。除此之外,文献[10-15]旨在找到一种高效提取时空特征的方法,其共同点在于都使用光流作为网络输入。然而光流是一种手工设计的表示,这种方法不够智能,它的提取以及存储需要消耗大量的时间和空间导致效率不高。虽然Xu等[16]在双流结构中设计了一条新的分支去预测光流,使得网络训练时不用消耗额外的空间去存储光流从而提高了效率,但是这无疑增加了整个网络的计算量。文献[17-20]基于骨骼点特征并结合图卷积神经网络执行行为识别任务,该方法未使用到光流数据且网络输入为连续视频帧,但缺点在于不是端到端的训练。Feichtenhofer等[21]基于3D卷积同时提取时间-空间特征从而舍弃光流作为网络输入,并根据双流法提出了一个新的架构SlowFast。该架构通过FastPath和SlowPath分别从连续的RGB视频帧中提取不同的状态信息,随后进行特征融合。实验表明,SlowFast在Kinetics-400数据集上强于I3D,top-1提升了7.7%。
虽然基于双流的3D CNN在行为识别任务中获得了良好的性能,但是仍存在不足之处,例如三维卷积操作在特征提取过程中不能区分背景特征和人体动作特征,同时也不能捕获前后帧之间的相关性,使模型容易受到环境因素的影响,从而降低识别性能。
为解决上述缺陷,本文首先以SlowFast架构为基础,舍弃光流作为网络输入,通过设计不同帧采样率τ使分支自动采样,使网络直接接收视频而非图片序列,从而降低额外储存开销,加快模型推理速度。其次根据视频帧之间的时序关系构建时间相关性注意力机制(Time Correlation Attention Mechanism,TCAM),用于降低模型对背景环境变化的敏感性,增强模型对时序信息的建模能力。最后针对SlowFast架构在进行网络融合过程的不足之处进行改进,使用连续卷积操作进行降维,在保证网络感受野不变的情况下提取更完整的时序信息并且降低了参数量。分别在UCF101和HMDB51两个数据集上进行了实验,结果表明所提方法优于现有的行为识别算法。
2 架构
过去的行为识别架构在建模过程中忽略了动作和行为体状态变化的速度不同,例如人在握手时,手的变化速度通常比较快,而行为人的其他肢体部分则处于相对静止状态。根据这一现象,采用SlowFast分别构建SlowPath与FastPath来进行处理,其中SlowPath分析视频中的静态内容,FastPath处理动态信息。架构如图1所示,3D卷积维度可表示为{C,T,H,W},其中C表示通道数,T是时间维度,即视频帧的数量;H、W分别表示空间维度的宽和高。网络架构的输入是一段完整的视频数据,因两条路径拥有不同的帧采样率,所以各自的时间维度T不一致,T越大说明分辨率越高,时序性越连续,帧之间的相关性也就越强。故而输入SlowPath的数据往往不存在相关性,它们大多包含了行为人或物体的颜色、纹理、目标等相对静态的特征信息,这些信息更复杂、更难以提取,因此需要增加网络通道数量来获取更丰富的空间语义信息。FastPath不需要构建太多的网络通道,因为高分辨率的输入要求它必须有足够快的处理速度,因此在架构中将该路径的通道数设置为SlowPath的β倍。β<1使得网络更轻量、计算速度更快,其缺陷就是空间细节较少,然而如何在高分辨率的视频帧中捕获快速变化的运动信息才是FastPath的目标,这也是本文在设计网络时重点优化的方向。Slow-Fast通过横向连接的方式,将FastPath的特征图进行3D卷积匹配SlowPath特征维度之后,使用concat方式来融合。此外原始框架在使用3D卷积进行横向连接过程中,其步长设计不合理导致部分帧之间的相关性信息丢失,故设计了一种更高效的连接方式(文中第3.2节)。在架构的末尾,各分支分别执行全局平均池化,然后concat两个通道的特征执行全连接操作进行类别预测,再使用交叉熵损失函数(Cross Entropy Loss Function,CE Loss)评价预测是否正确,式(1)为损失函数计算公式:
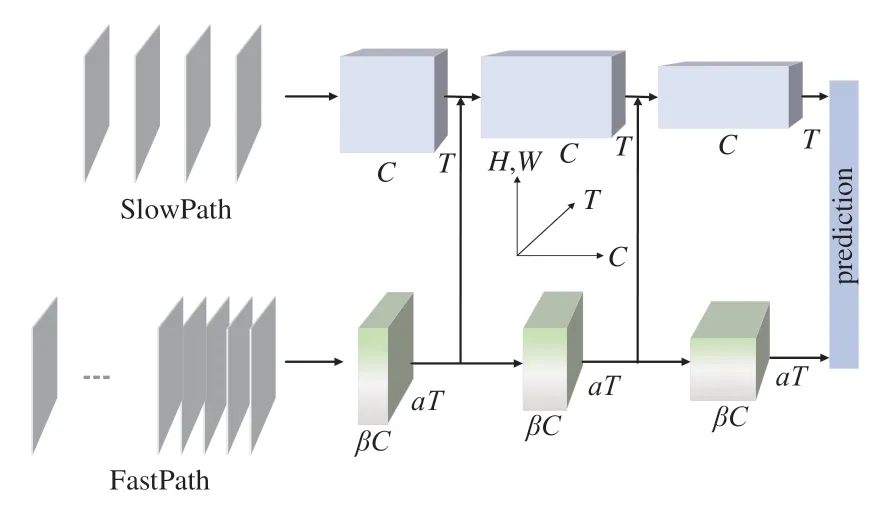
图1 SlowFast架构Fig.1 SlowFast architecture
其中:C代表类别数,pi为真实类别,qi为预测概率。在对C中的第j个类别进行预测时,若i=j,则pi=1,i≠j,pi=0,因此当i=j时,qi越大,CE就越小,表明模型预测错误率越低。
3 网络设计
如图2所示,t-1时刻行为人A做出踢球的动作从而导致t时刻足球改变运动状态。正是由于足球的运动状态发生改变,而使得行为人在t+1时刻作出了扑球动作,因此行为发生的动作之间是具有相关性的,行为识别任务中不仅要建立动作之间的时序关系还需要构建相关性。
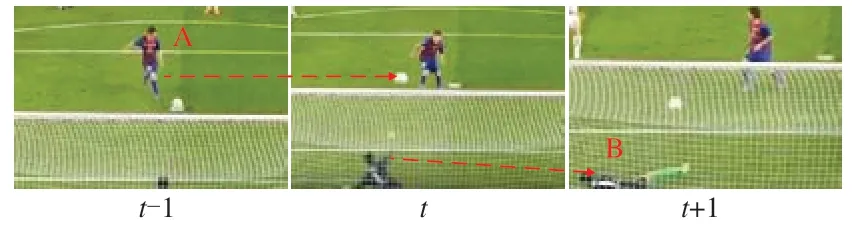
图2 动作相关性示例Fig.2 Example of action correlatio
3.1 时间相关性注意力机制
时间相关性注意力机制由两部分组成:相关性注意力机制、时间注意力机制。
3.1.1 相关性注意力机制
相关性注意力机制旨在找到视频帧之间的相互依赖关系,受文献[22]提出的三维时空注意力机制的启发,设计相关性注意力如图3所示。首先输入形状为{2C,T,H,W}的特征矩阵X,分别进行3次卷积核为{1,1,1}的三维卷积操作进行降维,得到维度为{C,T,H,W}的矩阵Matrix_1、Matrix_2、Matrix_3,随后将Matrix_1、Matrix_2分别Reshape成{T,CHW}和{CHW,T}的特征图Map_1、Map_2。图3中“Δ”被定义为一种利用矩阵相乘进行特征图融合的操作。不同于传统的矩阵乘法计算方式,它采用余弦相似性来获取相邻特征图之间的相关性关系,公式(2)给出了推导过程:
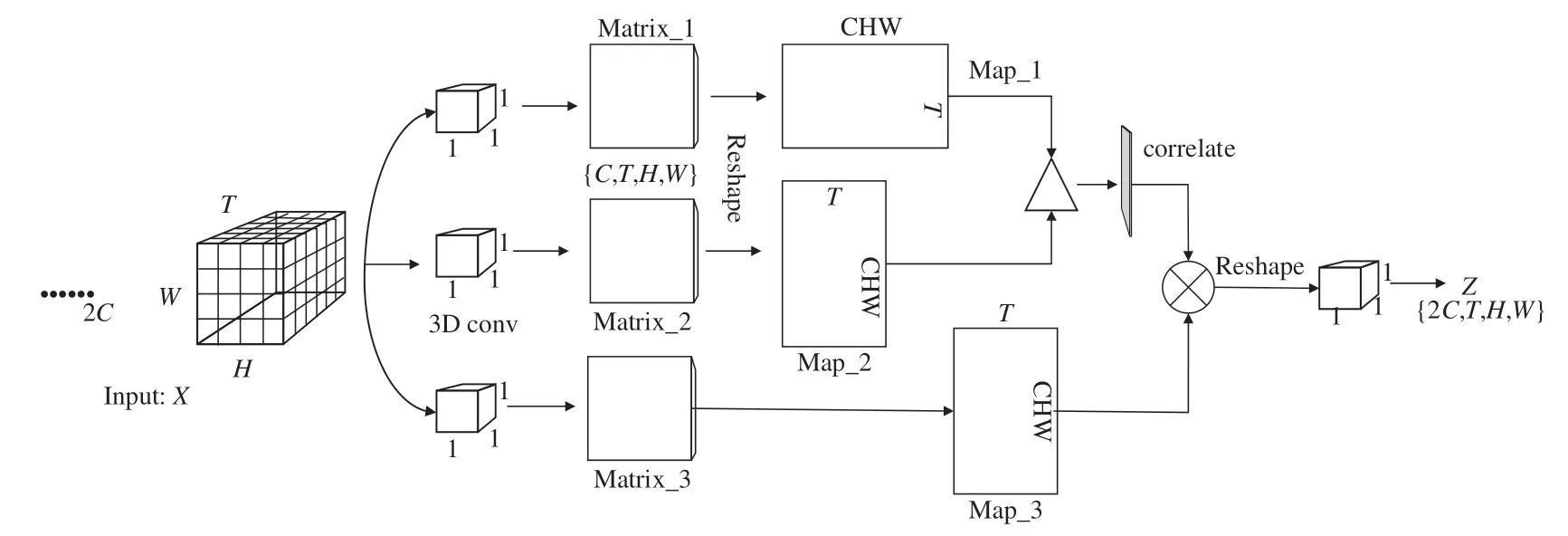
图3 相关性注意力机制Fig.3 Correlative attention mechanism
式中:Ti表示特征矩阵在时间维度上第i张特征图经过Reshape后的特征向量,Tix表示特征向量Ti的第x个特征值,其中{x|0≤x<C}。cos<Ti,Tj>越接近1表明特征图之间越相关,接近0则不相关性越强。相关性注意力机制可总结为公式(3)~(5),Map_1、2经过“Δ”得到T×T的相关性特征图M,随后利用该图的特征值计算每帧的相关性权重,计算方式见公式(4)。将得到的权重向量δ经过Sigmoid函数进行归一化后,通过Fscale(·,·)操作将归一化后的权重加权到每帧的特征上。
其中:Reshape(·)表示变换矩阵维度函数,Conv(·)为3D 卷积操作。
利用相关性注意力机制使卷积神经网不仅提取到行为时序特征,还建模了帧之间的依赖关系。然而在长视频序列中存在着许多不包含任何有效信息的序列,这些序列需要被忽略或者赋予其较低的权重让它变得不重要,通过构建时间注意力机制来实现这一目标。
3.1.2 时间注意力机制
图像处理任务常使用SENet[23]来建模通道之间的关系,以此矫正通道特征从而提升神经网络的表征能力。而在视频处理任务中更关注于时间维度之间的关系,传统的SENet不能提取该特征,因此将SENet进行移植,构建时间注意力机制,结构如图4所示。
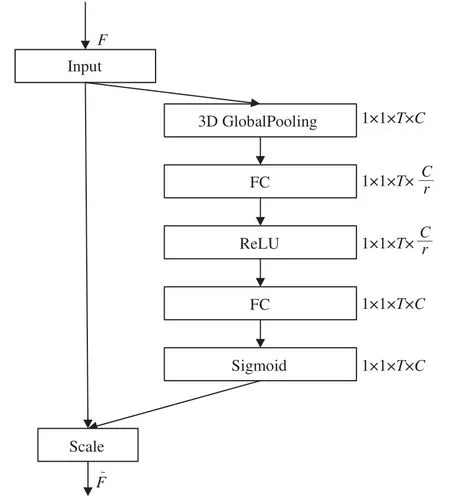
图4 时间注意力机制Fig.4 Temporal attention mechanism
对于输入u∈RC×T×W×H经过两条分支:SE通道和不做任何处理的快通道。其中SE通道分两步,首先是压缩(Squeeze),然后进行膨胀(Excitation)。Squeeze采用3D全局平局池化的方式,压缩每个时间维度的特征作为该维度的描述子,然后对每个时间维度里面的特征值求均值,得到2D时间注意力特征图At∈R1×1×T×C。Excitation用来捕捉时间维度之间的重要性,首先通过两个全连接层学习到每个时间维度的权重,激活函数依次选择ReLU和Sigmoid,然后输出特征图,图中每个元素对应时间维度的权重,输入特征矩阵u的每个时间维度最后会乘上对应的权重,因此无用维度会被忽略。时间注意力机制可总结为公式(6)~(8):
其中:ut(i,j)表示输入特征矩阵在时间维度t里面第i行j列的特征值,H、W分别表示特征图的宽和高,Wiz对应全连接操作,σ(·)、δ(·)分别对应Sigmoid和ReLU激活函数,Fscale(·,·)为矩阵乘法操作。
将相关性注意力机制与时间注意力机制进行融合可以使网络同时注意到行为之间的时间相关性,其网络结构如图5所示,⊕表示通道拼接操作。
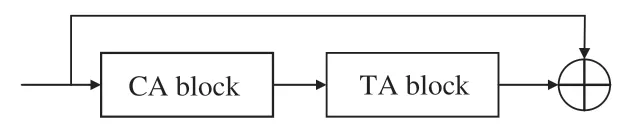
图5 时间相关性注意力机制Fig.5 Time-dependent attention mechanism
3.2 优化横向连接
行为类别判断需要同时了解该行为的动态信息以及静态信息。为此,模型将来自FastPath的特征信息通过横向连接送入到SlowPath进行信息融合,由于两条路径产生的特征图维度不一致,因此在融合之前需要先进行特征匹配。从图1可知,SlowPath的特征图维度为{T,S2,C},FastPath为{ɑT,S2,βC},S2表示特征图的H×W。SlowFast利用核大小为5×12,步长等于ɑ×12的滤波器对FastPath的特征图进行3D卷积之后送入SlowPath,然后利用concat操作实现数据的拼接。然而当ɑ>8时,由于滤波器在时间维度上的步长过大,会导致相邻帧之间的相关性丢失,因而使用3×12的卷积核,通过3×12的步长进行两次3D卷积来代替,在保证信息完整的同时降低了网络参数量,数学推导见公式(9)~(11)。横向连接过程中通道的输入数量为βC,输出数量为2βC,公式(9)是网络参数量的计算公式,其中kernelsize表示卷积核尺寸,indim、outdim分别表示网络通道的输入和输出数量,由此可计算出进行2次卷积核大小为3×12的卷积操作需要的参数量为7(βC)2,比1次5×12的参数量要减少30%。
3.3 网络结构
结合时间相关性注意力机制设计时间相关性残差块Res_TCAM,如图6所示。将TCAM放置该结构的最后位置,其目的在于使注意力机制每次都能对深层特征进行操作,抑制无用背景信息,增强特征表达能力。
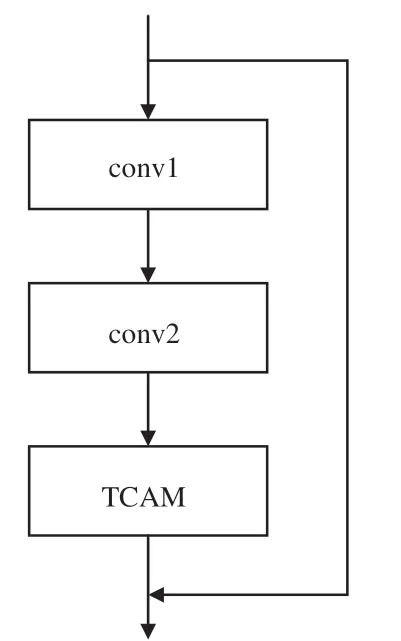
图6 残差块Res_TCAMFig.6 Risidual block of Res_TCAM
表1给出了网络结构参数,该网络在ResNet50的基础上,使用Res_TCAM替换传统的残差块结构。然而TCAM的加入会增加网络的计算量,表1中使用T×S2来表示时间和空间维度,步长用{时间步长,空间步长2}表示,同样卷积核尺寸也采用{时间卷积核,空间卷积核2}表示。网络中为了保证行为在时间上的连续性,不使用时间池化也不使用时间步长的卷积操作,直至分类之前使用全局平均池化。Res_TCAM在部分块中先后使用3×12、1×32的卷积核,这样可以在增强时间和空间维度上感受野的同时,减少参数量。
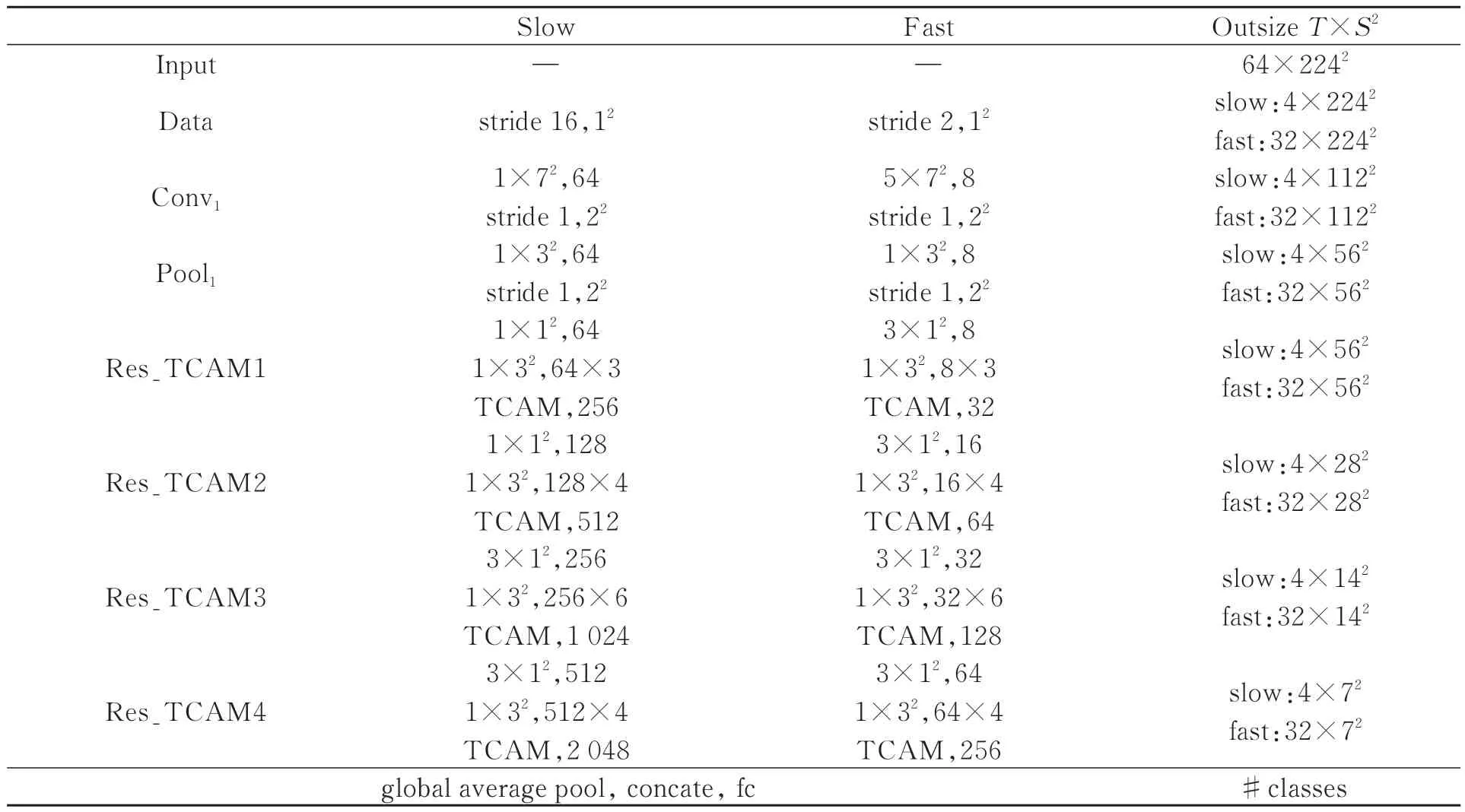
表1 网络结构参数Tab.1 Parameters of network structure
4 实验
实验运行环境基于Ubuntu18.0.4操作系统,CPU是Intel Core i5-10500,使用单张型号为GeForce GTX TITAN X的GPU进行训练,训练网络使用Python3.6,基于Pytorch框架搭建。
4.1 数据集介绍
UCF101[24]是目前行为识别任务中最常用的数据集之一,它来源于YouTube,数据集中包含了总时长约27 h的13 320个视频,收集了不同行为人在不同环境下的101个行为类别。这些类别可划分为5类:人与物体交互、单纯的肢体动作、人与人交互、演奏乐器和体育运动。HMDB51[25]提供的数据大多来源于YouTube等网络视频库,数据集包含6 849段样本共51类,类别主要包括:一般面部动作、面部操作与对象操作、一般的身体动作、与对象交互动作和人体动作。
4.2 实验训练过程
4.2.1 模型评价标准
为使实验结果与其他模型进行公平比较,采用通用的评价标准top-1 acc进行评价,公式(12)是计算公式。式中假设测试集样本数量为n,模型预测某个样本的类别为而该样本的实际类别是时,函数F(·)返回1,否则返回0。因此top-1越接近1,模型预测准确率越高。
4.2.2 自动帧采样方式
不同行为发生的动作频率不同。为了提高模型的通用性以及减少数据采样冗余,节省设备的存储开销,对UCF101的视频数据进行分析,分别提取各个类别中所有视频的平均值、最大值以及最小值。从图7可以分析出,多数行为平均发生时间在300帧以下,最短时间大多在50~100帧,因此在设计视频帧提取算法过程中以300为分界线,每个视频最多提取300帧数据,单个视频提取到的有效帧数少于γ帧时被丢掉。算法1对自动帧采样进行了描述。
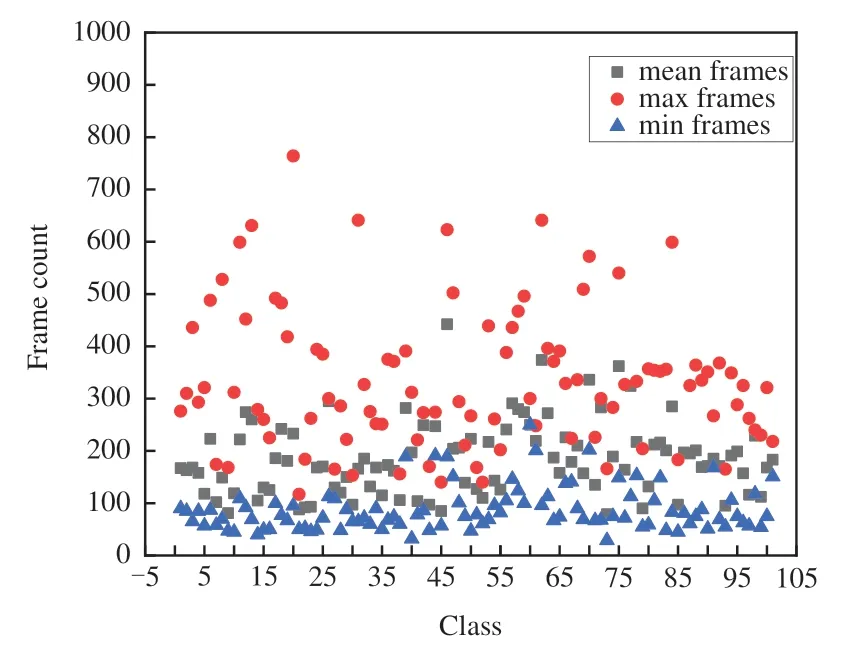
图7 UCF101视频帧数量统计图Fig.7 Statistics of the number of UCF101 video frames

首先根据输入获取原视频帧的数量,按照帧采样率r(每隔r帧采一次)计算单个视频能够被采样的帧数,如果该视频帧数超过300帧,则随机从300到frame_count之间取值,并设为结束采样索引(end_idx),开始采样索引(start_idx)为end_idx-300,否则令start_idx=0,end_idx=frame_count-1,然后进行帧采样,对采样后的数据缓存容器进行处理,若容器的缓存帧数量少于有效视频帧采样数量γ则丢弃,否则从DataBuffer中顺序抽取γ帧数据作为网络的输入。
4.2.3 模型训练细节
为使网络的训练过程是端到端,不需要预先提取视频帧,因此在网络训练时通过自动帧采样算法进行处理成γ帧224×224的图片序列。实验中参照文献[21]的实验结果,选择γ=64,然后设置SlowPath的帧采样率为16,FastPath为2。训练时设置的批处理大小为48,初始化学习率为10-2,采用随机梯度下降策略,动量为0.9,学习率优化器是Adam。最终模型在迭代100 Epochs时停止训练。图8是一个训练实例,训练数据集选择UCF101,骨干网络为ResNet50,仅在Fast-Path添加TCAM。模型在迭代了40个Epochs后,top-1 acc在97%上下浮动,在结束训练时最高达到98.16%,损失下降到0.06(±0.01)。
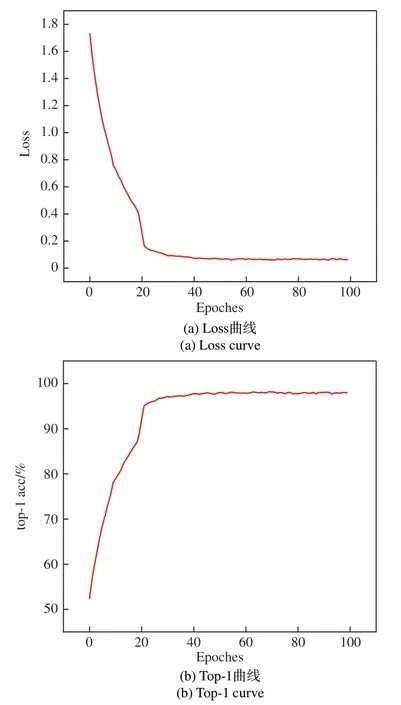
图8 UCF101上的训练结果Fig.8 Training results on UCF101
4.3 消融实验
4.3.1γ对模型的影响
在对原视频进行处理过程中,通过设置γ值来获取网络输入图片序列的帧数。在帧采样率r一致时,γ越大表明输入的时间跨度越长,网络所获取的信息越丰富,与之而来便是冗余信息的增加,因此选择合适的γ对模型的性能影响很大。在实验中固定SlowPath与FastPath的采样率为16和2,速度比α=8,骨干网络选择ResNet50,不进行预训练。从表2的结果可以看出,当γ从64增加到128时,SlowFast的top-1准确率增加了1.87%,SlowFast+TCAM增加了0.96%,然而它们的GFlops分别增加了2倍。此外当γ=64时,SlowFast+TCAM相比原模型的top-1增加了2.47%,而GFlops仅增加0.75。
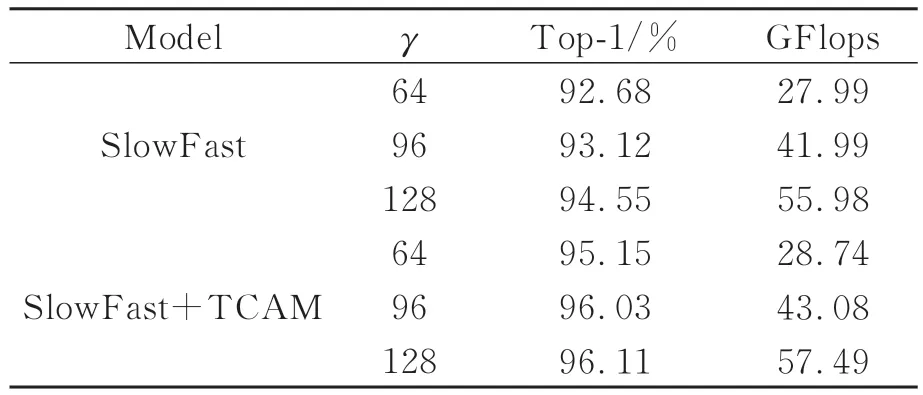
表2 γ对模型的影响Tab.2 Effect of γ on the model
4.3.2 不同帧采样率对模型的影响
固定γ=64,α=8,同样以ResNet50作为骨干网络添加TCAM,探究SlowPath与FastPath在不同帧采样率下对模型性能的影响。表3中T表示SlowPath采样的帧数,τ为帧采样率,通过速度比α可以推出FastPath的采样帧数为αT,采样率为τ/α。分析表3可以得出两个结果:(1)增加帧采样率τ可以提升模型的精度,然而由于Slow-Path在时间通道上的分辨率增加,使得模型的GFlops成倍增长,这将减慢模型的推理速度;(2)对比表2的实验结果,SlowFast在添加TCAM后,即使将τ降低1倍,top-1仍然比原模型提高0.21%,而每秒10亿次的浮点运算数(GFlops)约为原模型的50%。
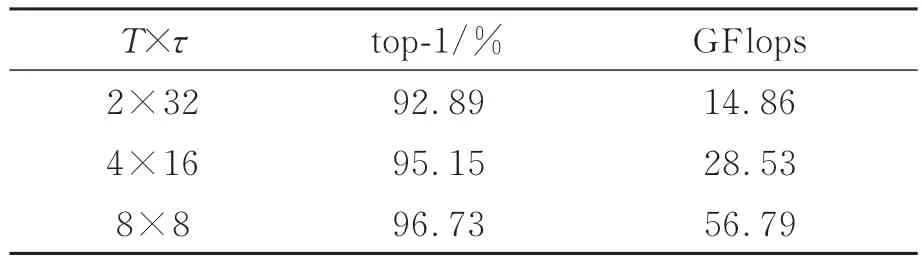
表3 不同帧采样率对模型的影响Tab.3 Effects of different frame sampling rates on the model
4.3.3 TCAM与横向连接对模型的影响
表4给出了所提方法和SlowFast在不同分支添加时间相关性注意力机制(TCAM),以及改进横向连接(Lateral)方法在UCF101上的实验结果。Backbone选择ResNet50,不进行预训练。SlowFast(b+)为比较基准,Slow Only与Fast Only分别仅在SlowPath与FastPath添加变量。为比较优化后的横向连接方式对行为识别准确率的影响,将lateral作为变量。从表4可以看出,模型使用lateral(Ours)比使用lateral的识别精度高1.11%。为探究TCAM在不同路径上的效果进行了3次实验,实验发现仅FastPath添加TCAM时的识别精度比基准高3.15%,表现最好。
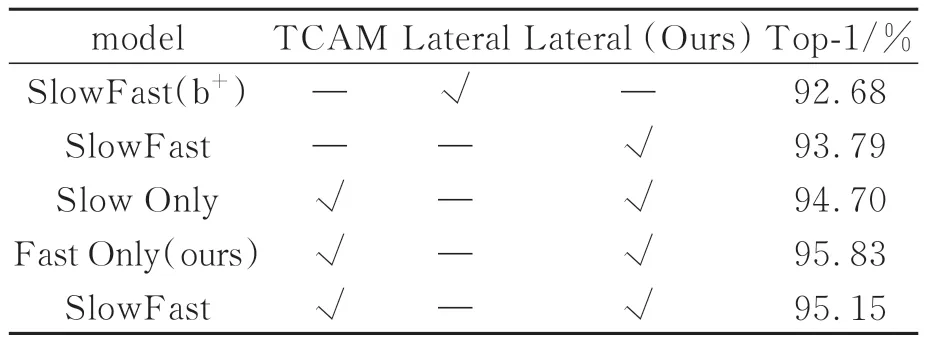
表4 时间相关性注意力与横向连接对实验结果的影响Tab.4 Effects of time-dependent attention and lateral connectivity on experimental results
4.4 与其他方法的比较
为判断所提方法在行为识别任务中是否具有先进性,分别与baseline、no-attention、attention这3种类型中的优秀算法进行了比较。其中baseline表示行为识别领域的基准,no-attention表示网络中没有加入注意力机制,attention表示网络中加入注意力机制。从表5的比较结果可以看出:(1)所提方法比IDT、Two-stream和C3D这3个基准模型的识别精度都有所提升。对比最好的基准模型Two-stream,TCAM在UCF101数据集上提升18.16%,HMDB51上提升了22.9%。分析原因可以得出,光流只能在一定程度上弥补2D卷积不能同时提取外观和运动信息的缺陷。(2)从数据上可以粗略得出,不带注意机制的模型在两个数据集上的表现同样良好,然而进行仔细分析可以发现两方面的差异,一方面TCAM(Kinetics)在UCF101和HMDB51上的错误率相较于Twostream-I3D (ImageNet+Kinetics)分别降低了8%和8.29%;另一方面Two-stream-I3D通过ImageNet+Kinetics预训练前后在UCF101上的精度相差4.6%,在HMDB51上更是相差14.3%,而TCAM仅在Kinetics上进行预训练前后得出的结果分别比Two-stream-I3D预训练前后的差异性降低了49.34%和56.64%。通过以上两个方面的分析可以得出,所提出的时间相关性注意力机制不仅可以降低模型在行为识别任务中的错误率,还能提升鲁棒性。(3)与AR3D进行比较,TCAM不经过预训练的模型在两个数据集上的识别精度均高于它。STA-LSTM是基于长短时记忆网络设计的时空注意力机制,它在HMDB51上的精度显著低于UCF101,说明HMDB51的训练集和测试集分布差异较大,对模型的鲁棒性能要求更高。而不经过预训练的TCAM在该数据集上的精度要比STA-LSTM在ImageNet上进行预训练的模型精度高16.7%,充分说明TCAM的鲁棒性强于STA-LSTM。可见,所提方法在现有行为识别任务的算法中无论是识别精度和模型鲁棒性均为最优,证明所提方法是具有先进性的。
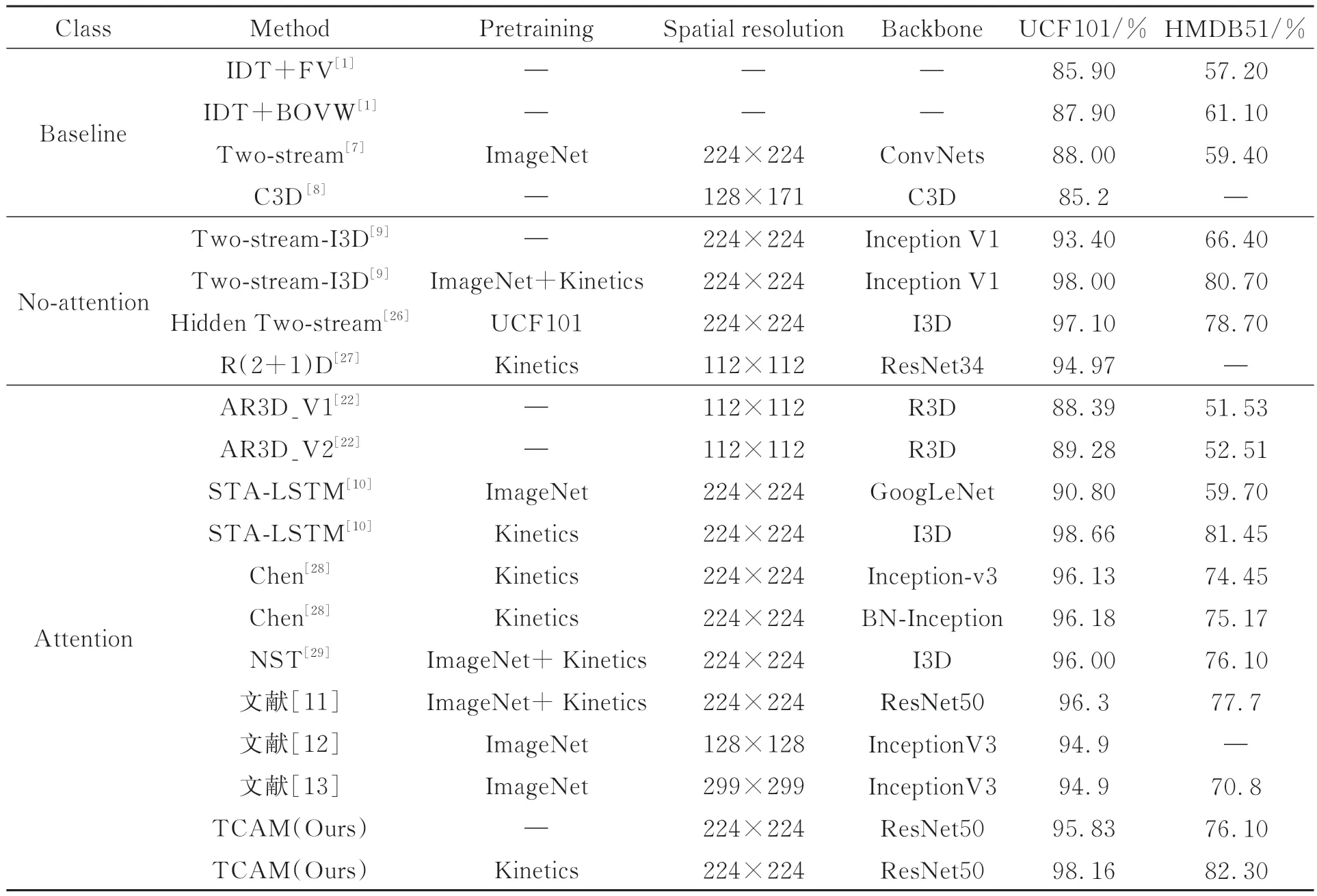
表5 TCAM与其他方法的识别精度的比较Tab.5 Comparison of recognition accuracy of TCAM with other methods
4.5 混淆矩阵
图9给出了UCF101和HMDB51数据集上的实验结果,通过混淆矩阵来展示。用i来对应类别序号。当模型预测标签predi与真实标签actuali一致时,在矩阵[i,i]位置进行计数,数值越高表明模型预测准确的次数越多,表现为该位置混淆点的颜色越深。从图中可以看出,模型对于每一类别的预测准确率,准确率越高,矩阵对角线颜色越深。从图9(a)可以看出,模型在UCF101数据集上的表现较优。图9(b)中除矩阵对角线外,在其他地方出现了颜色较浅的混淆点,表明模型在对应类别上的准率较低,出现误判,这也符合模型在HMDB51数据集上82.30%的top-1 acc的情况。
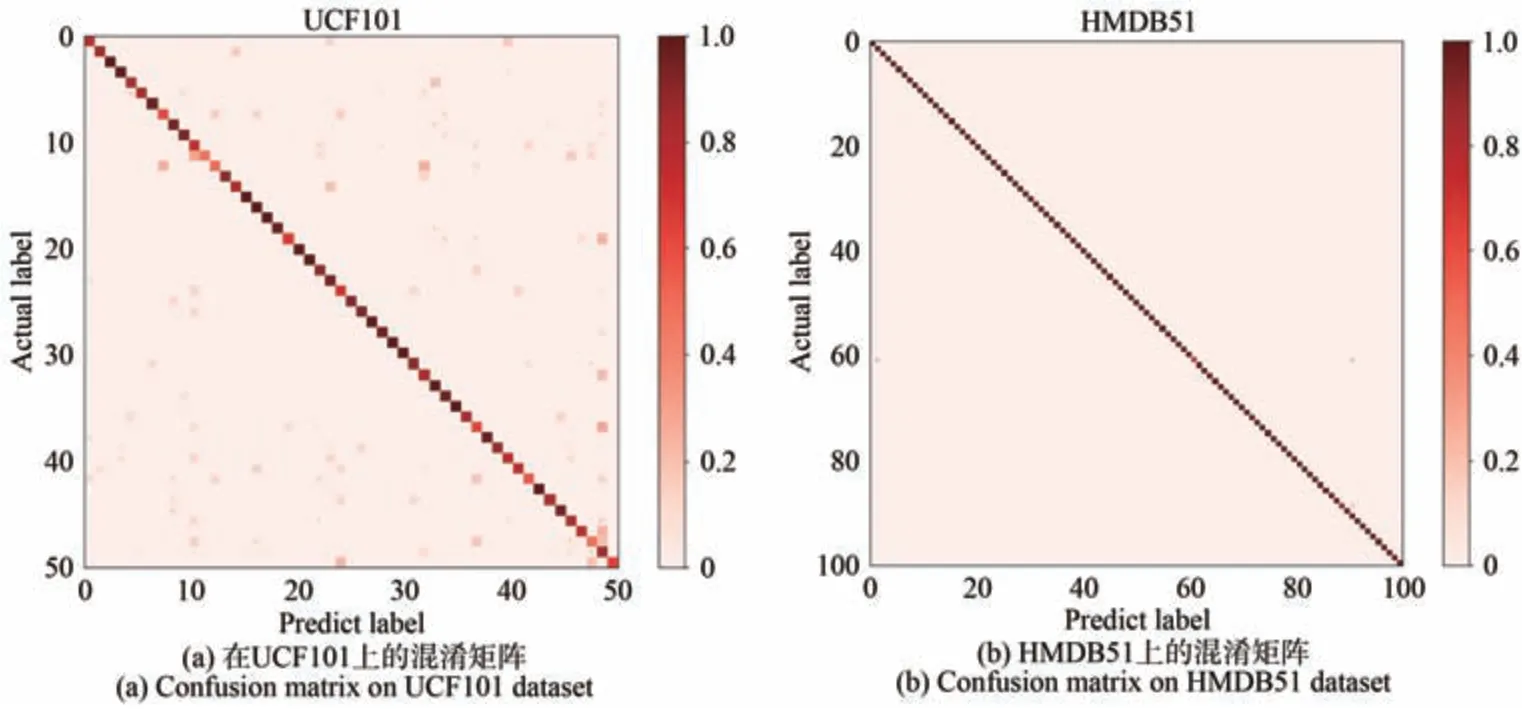
图9 混淆矩阵Fig.9 Confusion matrix
5 结论
本文提出了一种基于时间相关性注意力机制的行为识别网络,通过SlowFast框架设计快慢两条路径分别对行为的静态信息和动态信息进行建模,使用时间相关性注意力机制来提取特征之间的依赖关系并且抑制无用的特征信息,利用卷积核更小、步长更连续的3D卷积替代原有连接方式,在实现精度提升的同时减少模型参数量。最后在UCF101和HMDB51数据集上进行实验验证,TCAM的识别精度分别为98.16%和82.3%,比基准Two-Strean高18.16%和22.9%。相比于I3D和STA-LSTM,TCAM表现出了更强的鲁棒性,这也证明了所提方法的有效性。此外,还通过混淆矩阵展示了TCAM在两个数据集上的预测结果,矩阵混淆点的分布情况再一次证明了所提方法的优越性。
