基于自适应特征感知的轻量化人体姿态估计
2023-08-16毋宁王鹏李晓艳吕志刚孙梦宇
毋宁, 王鹏, 李晓艳, 吕志刚, 孙梦宇
(1.西安工业大学 兵器科学与技术学院, 陕西 西安 710021;2.西安工业大学 发展规划处, 陕西 西安 710021;3.西安工业大学 电子信息工程学院, 陕西 西安 710021;4.西安工业大学 光电工程学院, 陕西 西安 710021)
1 引言
随着计算机视觉领域的不断发展,人体姿态估计逐渐进入人们视野。人体姿态估计主要是对图片或视频中的人体骨骼关键点进行精确定位识别[1-2]。目前人体姿态估计算法已被广泛应用到人机交互、动作识别、3D姿态研究、智能武器、智能视频监控等众多领域[3-6]。但随着人体姿态估计算法检测精度的提升,模型复杂度也在剧增,造成模型参数量和计算量的大幅增加,导致现有的人体姿态估计算法难以满足实际应用中对检测效率的需求。低内存和低计算能力下的姿态估计问题不仅具有挑战性,目前还很少受到研究界的关注[7-10],因此进行人体姿态估计模型的轻量化研究十分必要。在确保模型检测精度的同时,降低网络模型的体积与运算量、提高检测速率变得刻不容缓。
基于深度学习的人体姿态估计可分为两种:一种是自下向上框架,其直接定位人体骨骼关键点,再通过聚类等方法将关键点匹配到相应的人[11-12];另一种是自顶向下框架,先对人体进行检测,再通过直接回归或热图回归的方法对关键点进行定位识别[13]。Fang[14]等人提出基于自上向下框架的多人姿态估计网络(Regional Multi-Person Pose Estimation,RMPE),结合对称空间变换网络有效提高了关键点检测效果,但其存在网络复杂度高、算法运行时间长的问题。Chen[15]等人提出的级联金字塔网络(Cascaded Pyramid Network,CPN)采用在线难例挖掘有效缓解了困难关键点定位问题,但仍存在精度低、时耗长的缺点。Sun[16]等人提出深度高分辨率网络(High Resolution Network,HRNet),高分辨率网络有效改善了关键点定位精度,但在网络中始终保持高分辨率极大增加了网络负荷,导致模型参数量急剧增加。Cheng[17]等人融入多尺度模块改善高分辨率网络的多尺度特征提取能力,但更加深了模型的复杂度。Yu[18]等人提出轻量级高分辨率网络(Lite-High Resolution Network,Lite-HRNet),引入条件信道加权单元取代昂贵的点态卷积,并结合通道混洗有效减少了网络的复杂度,但也造成了精度的极大损失。
针对人体姿态估计模型在准确度与速度之间难以平衡的问题[19],本文展开了人体姿态估计算法的轻量化研究,主要从卷积模块轻量化、注意力机制轻量化及损失函数3个角度进行改进,使模型在保证检测精度的同时减少了网络参数量与运算量,压缩了模型体积,从而改善了实际应用中人体姿态估计模型的检测效率。实验结果证明,最终得到的轻量级人体姿态估计模型有效提高了多人复杂场景下的关键点检测性能,实现了人体姿态估计模型的轻量化。
2 RMPE算法原理
图1是一种经典多人姿态估计网络RMPE(Regional Multi-person Pose Estimation)的结构图,主要由人体检测、空间变换网络(Spatial transformation network,STN)、姿态估计网络SPPE、空间反变换网络(Spatial de-transform network,SDTN)以及姿态非极大值抑制Pose-NMS 5部分组成。RMPE算法先通过目标检测算法进行人体检测,然后将检测到的人体送入姿态估计网络SPPE中,对每一个人的关键点分析定位,再通过姿态非极大值抑制对冗余的人体检测结果进行消除,得到最终的人体姿态估计检测结果。
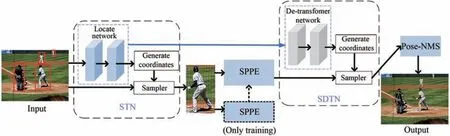
图1 多人姿态估计网络RMPEFig.1 Multi-person pose estimation network RMPE
RMPE网络为自顶向下的多人姿态估计网络,其在追求高精度关键点检测的同时会涉及大量的运算量,加深了模型复杂度,且随着输入图片中人数的增多,关键点的数量也在成倍增加,导致检测效率大幅降低,实际应用效果差。故如何在保证模型检测精度的同时,有效减少网络的参数量和计算量,提高人体姿态估计网络的检测效率十分必要。为了提升人体姿态估计算法在实际应用中的检测效率,本文将对RMPE算法展开轻量化研究。
3 本文算法
3.1 改进的RMPE-tiny网络结构
RMPE网络作为多人姿态估计模型具有较好的检测效果,但在实际应用中由于网络较复杂、参数量多,导致模型庞大,检测速率慢。本文为降低多人姿态估计网络RMPE的复杂度,提高模型的实时检测效率,改进并得到了如图2所示的轻量化人体姿态估计模型RMPE-tiny。
本文算法首先针对模型参数量大的情况,结合Ghost卷积[20]构建G-Bottleneck模块,实现特征提取网络的轻量化重构,所构建的G-Bottleneck模块如图2所示。其次由于特征提取网络参数量减少会导致网络缺少部分特征信息,因此融合了多个改进的轻量级自适应特征感知注意力机制Sa-ECA,增强通道间的信息交流以得到更丰富的语义信息。最后采用指数平方损失函数Huber Loss[21]来优化损失回归,加速模型收敛,提升模型对异常点的检测效果。
最终通过改进得到了一个轻量级、高精度、强鲁棒性的轻量级人体姿态估计模型RMPE-tiny,可以有效降低网络参数量,压缩模型体积,充分融合通道间交互信息并增强人体关键点的定位效果,显著提高了人体姿态估计模型检测效率,实现了人体姿态估计网络的轻量化。
3.2 基于Ghost模块的特征提取网络重构
为降低多人姿态估计RMPE网络的复杂度,本文首先进行了基于Ghost模块的特征提取网络轻量化重构。RMPE姿态估计模型采用Resnet50骨干网络进行特征提取,该网络在提高性能的同时也带来了更多的计算量。由于卷积神经网络的语义信息中包含众多冗余特征,普通卷积操作含浪费大量的参数量和算力来提取冗余特征,限制了模型的运行效率,而Ghost卷积采用廉价线性操作映射生成冗余特征,极大地减少了卷积运算。故本文结合Ghost卷积,构建了轻量级特征提取模块G-Bottleneck,以减少提取冗余特征造成的算力浪费。
在进行常规卷积运算时,当输入数据为X∈Rc×h×w,则会产生n个特征映射,常规卷积运算公式如式(1)所示:
式中:Y∈Rh'×w'×n表示n个通道的输出特征映射,h和w为输入图像高和宽;*表示卷积运算,f∈Rc×k×k×n为该层卷积核,c为输入通道数,k×k为卷积滤波器f的核大小,b为偏置项。故常规卷积运算所需计算量为n·h'·w'·c·k·k,其中h'和w'分别为输出图像的高和宽。由于滤波器的数量n和通道数c通常非常大,故模型的浮点运算量通常非常高。
对比图3(a)常规卷积和图3(b)Ghost卷积可以发现,通过常规卷积直接提取全部特征时,生成的全部特征图中往往包含众多冗余特征,使用常规卷积直接生成这些冗余特征会造成极大算力浪费;Ghost卷积则通过线性映射提取冗余信息,避免了采用常规卷积提取冗余特征带来的大量算力浪费。Ghost卷积首先通过少量常规卷积生成内在特征,再通过廉价线性变化φ生成冗余特征Ghost feature来增强特征,增加信道,用恒等映射Identity生成内在特征Intrinsic feature,线性变化和恒等映射并行,最终融合得到丰富的输出特征。廉价线性操作的计算公式如式(2)所示:
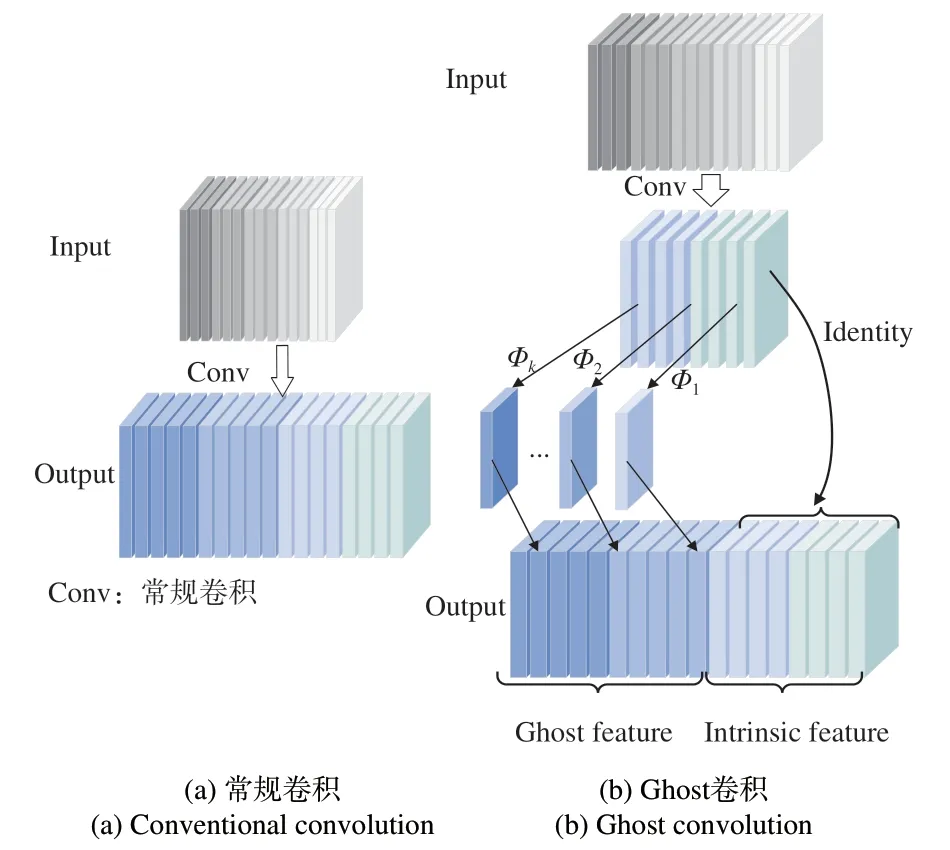
图3 常规卷积和Ghost卷积Fig.3 Conventional convolution and Ghost convolution
式中:∀i=1,…,m,j=1,…,s,yi'是Y'中的第i个固有特征映射,φ是生成第j个Ghost特征yij的第j个线性操作,yi'可以有一个或多个Ghost特征映射,最后一个φi,s保留固有特征映射内的自身映射。利用公式(2)可获得n=m·s个特征映射作为Ghost模块的输出,线性操作φ在每个信道上的计算成本远小于普通卷积。
Ghost卷积模块包含恒等映射与线性操作,线性操作卷积核大小是d×d,Ghost卷积一般采用相同大小的线性操作。理论上,Ghost卷积改进常规卷积的模型压缩比Rs如公式(3)所示:
当卷积核与大小相似时,这种理想情况的模型压缩比Rc如式(4)所示。
3.3 轻量级自适应特征感知注意力机制
为增强人体姿态估计网络的跨通道信息交互,有效融合局部与全局信息,本文改进了高效注意力模块(Efficient Channel Attention,ECA)[22],得到了轻量级自适应特征感知模块(Sa-ECA)。通过在人体姿态估计网络中融入多个Sa-ECA模块,实现了更加高效的语义信息提取与交互。RMPE网络使用注意力机制(Squeeze and Excitation,SE)[23]增强语义信息提取,但SE模块采用涉及降维操作的全连接层FC捕获所有通道间的交互信息,造成了信息的极大损失,并极大增加了网络负荷。而ECA注意力机制虽可减少网络负荷,但其通过设定固定卷积核来聚合特征信息,导致该操作不能有效地结合语义信息实现特征聚合。本文采用自适应全局平均池化来完成特征聚合,实现特征信息的有效聚合,改进后的轻量级自适应特征感知模块Sa-ECA可使模型在参数量减少的情况下实现通道信息的有效获取。
轻量级自适应特征感知模块Sa-ECA如图4所示,图中卷积块的输入为χ∈RW×H×C,其中W、H和C分别为输入的宽度、高度和通道尺寸。自适应注意力机制将高分辨率特征与卷积后特征融合,保证了特征信息的有效融合。自适应全局平均池化(Adaptive Global Average Pooling,Adaptive GAP)不涉及降维操作可有效获得聚合特征,使通道和权重之间直接联系,避免了降维带来的信息损失,保证了信息的有效获取。
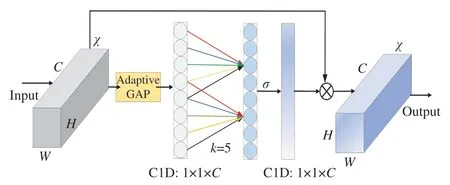
图4 轻量级自适应特征感知模块Fig.4 Lightweight adaptive feature perception module
自适应全局平均池化通过对每个输出通道的所有像素计算平均值,根据输入参数自适应地调节控制输出大小,学习自适应和可判别性的特征图以汇总特征,同时丢弃无用信息特征,极大地保留目标的大量细节。通过快速一维卷积C1D实现通道间信息交互,捕获跨通道交互信息,如公式(5)所示:
式中:k为自适应卷积核的大小,表示局部跨通道交互的范围,是由通道数C的映射自适应地确定的;σ是Sigmoid函数;C1D是一维卷积,即1×k的卷积,它只涉及k个参数,可有效减少注意力机制带来的大量参数。
3.4 损失函数
为加快轻量化之后模型训练的收敛速度,本文对训练所采用的损失函数进行改进。原算法采用平方损失函数(Mean Square Loss,MSE Loss)训练网络,虽梯度会随损失值接近最小值时不断减小,但其对离群点兼容性不够好,降低了模型鲁棒性。本文结合指数平方损失函数Huber Loss训练模型,该损失函数围绕训练中的最小值减小梯度并降低网络对异常点惩罚程度,同时可加快模型收敛,相比于平方损失函数有更好的鲁棒性。Huber Loss可更好地拟合数据分布,Huber损失函数公式如(6)所示:
式中:yi和f(xi)分别表示第i个样本的真实值及其对应的预测值,δ为超参数。从定义可以看出Huber Loss处处可导。当预测误差大于δ时,采用均方绝对误差损失函数(Mean Absolute Loss,MAE Loss);当预测值误差小于δ时,则采用MSE Loss。
采用MAE损失训练网络时,其梯度始终很大,不利于模型学习,而且在使用梯度下降训练模型时易忽略较小值;而采用MSE训练网络时,梯度会随损失值接近最小值时不断减小,但其对离群点的兼容性不够好。Huber Loss同时包含MAE Loss与MSE Loss两者的优点,对于异常点有较好的拟合效果,可有效避免梯度爆炸的问题。随着训练误差的减小,梯度也在减小,这可加快收敛速度,使模型较快收敛到最小值。最终本文结合Huber Loss损失函数进行训练,加快了模型的收敛速度,提高了模型的鲁棒性。
4 实验与结果
4.1 实验环境及数据集
本文使用Pytorch深度学习框架来实现人体姿态估计算法,实验操作系统为Ubuntu16.04,显卡为NVIDIA Quadro M6000。在本实验中选用Adam优化器对模型进行优化,训练批量Batch size为32,学习率(LR)为1e-3,训练周期为200 epoch。所有实验均在以上环境中进行。
本文使用MSCOCO 2017数据集验证模型的有效性,该数据集共定义17个人体关键点,其具体表示如图5所示。按需将其划分为训练集、验证集及测试集,其中64 115张训练集图片作为训练样本,5 000张验证集作为验证样本。
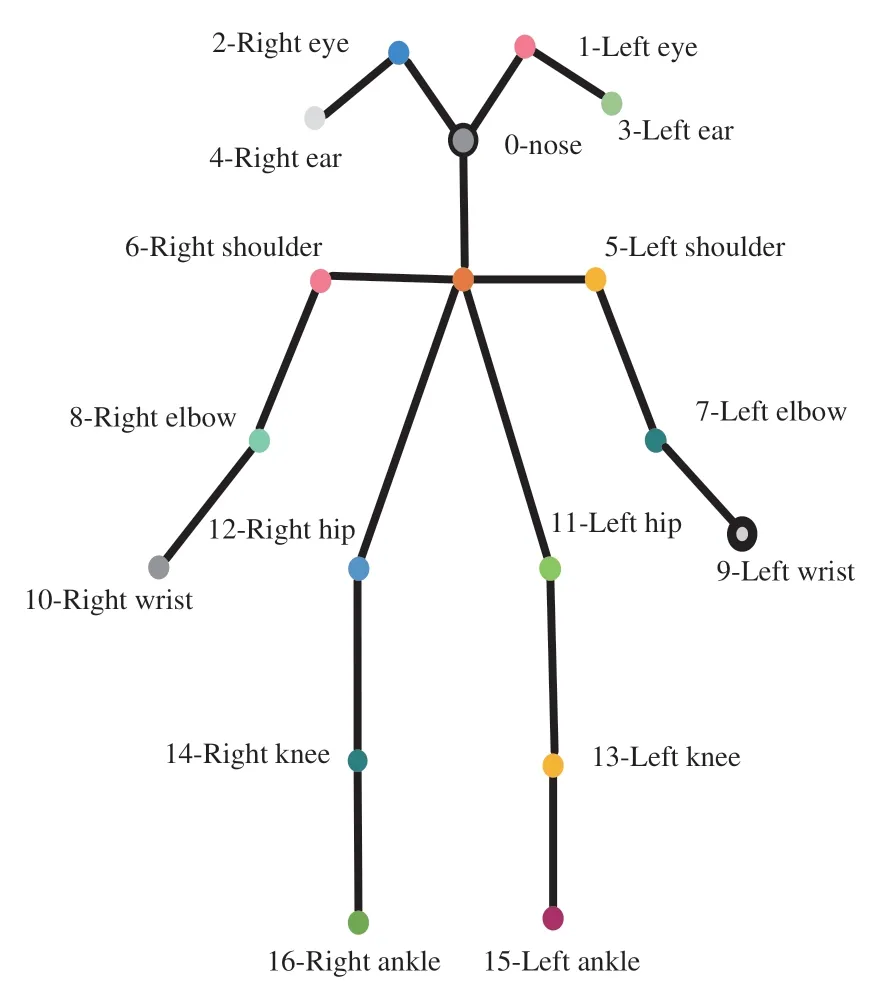
图5 人体关键点示意图Fig.5 Schematic diagram of key points of the human body
4.2 评估指标
本文采用COCO数据集的主要评估指标AP、AP50、AP75、APM、APL来评估模型的精度。其中AP表示在10个OKS阈值(OKS=0.50,0.55,0.60,…,0.95)处的平均精度,AP50表示OKS=0.50时的检测精度,AP75表示OKS=0.75时的检测精度,APM表示中等物体的检测精度,APL表示大型物体的检测精度。OKS(Object Keypoint Similarity)表示关键点相似度,其值在(0,1)之间分布,OKS的值越接近1则预测结果越好,OKS计算公式如式(7)所示:
式中:di表示每个预测关键点与真实关键点之间的欧几里得距离,vi表示关键点可视,s表示物体尺度,ki表示控制衰减常数。
对模型轻量化程度评价时,通常选取的评价指标是参数量(Params)、浮点运算数(GFLOPs)及模型大小。参数量是指网络模型中需要训练的参数总量,直接决定模型的大小。浮点运算数是网络实际运行过程中计算量的大小,即算力,其用来衡量算法或模型的复杂度,计算公式如式(8)所示:
式中:K为卷积核,H、W为输入图像的高与宽,输入通道数是Cin,输出通道数是Cout。文中所用GFLOPs指10亿次浮点运算数,其中1GFLOPs=109FLOPs。
4.3 模型训练损失对比分析
模型训练损失曲线对比如图6所示。使用MAE Loss训练模型时,损失曲线变化如蓝色曲线所示,可以看出损失曲线收敛慢,损失值较高。使用MSE Loss训练时,损失曲线变化如灰色曲线所示,可以看出模型收敛速度相对较慢,损失值最终收敛在3.5e-4左右,对异常值的处理效果不佳。结合Huber Loss训练模型时,损失变化如红色曲线所示,该损失曲线相对较平滑,训练过程中对异常值的处理优于使用其他两者训练时的效果。使用Huber Loss训练时,模型在训练到约160批次开始收敛,收敛速度较快,收敛后的曲线较平稳,最终损失值收敛在3.1e-4左右。
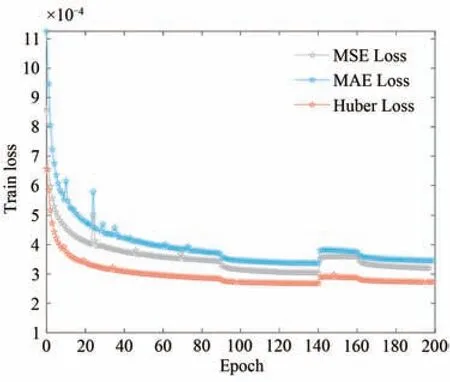
图6 网络训练损失对比Fig.6 Comparison of network training losses
损失函数是评价模型的预测值与真实值之间的不一致程度,损失函数越小,模型的鲁棒性越好。合适的损失函数会加快模型的收敛速度,提高模型的检测精度。可以看出,改进模型损失函数,结合Huber Loss训练模型可加快模型收敛,模型收敛值更优,而且该损失函数对异常值的处理效果更好,增强了模型的鲁棒性。
4.4 实验结果及分析
为验证算法的有效性,本文主要从模型的参数量、算力以及检测精度等方面对模型进行对比分析。不同人体姿态估计方法性能对比如表1所示。CPN模型采用堆叠金字塔进行多人姿态估计,检测精度低,这是其对深层语义信息的提取不够充分导致的;SimpleBaseline-101[24]模型简单的反卷积结构使精度提升至71.4%,但同时由于网络较深也造成了模型参数量剧增;HRNet网络始终保持高分辨率使检测精度可达73.4%,但始终保持高分辨率造成了模型体积高达116.2 MB;HigherHRNet为改善多尺度场景检测效果导致模型算力剧增。从对比实验结果可以看出,本文提出的RMPE-tiny模型相比于基准模型RMPE,参数量减少了约56.1%;算力减少了约32.0%;模型体积压缩至72.1 MB,减少了约57.0%;模型检测精度为72.8%,提升了约0.5%。故可以得出,本文改进后的模型检测效率更高。
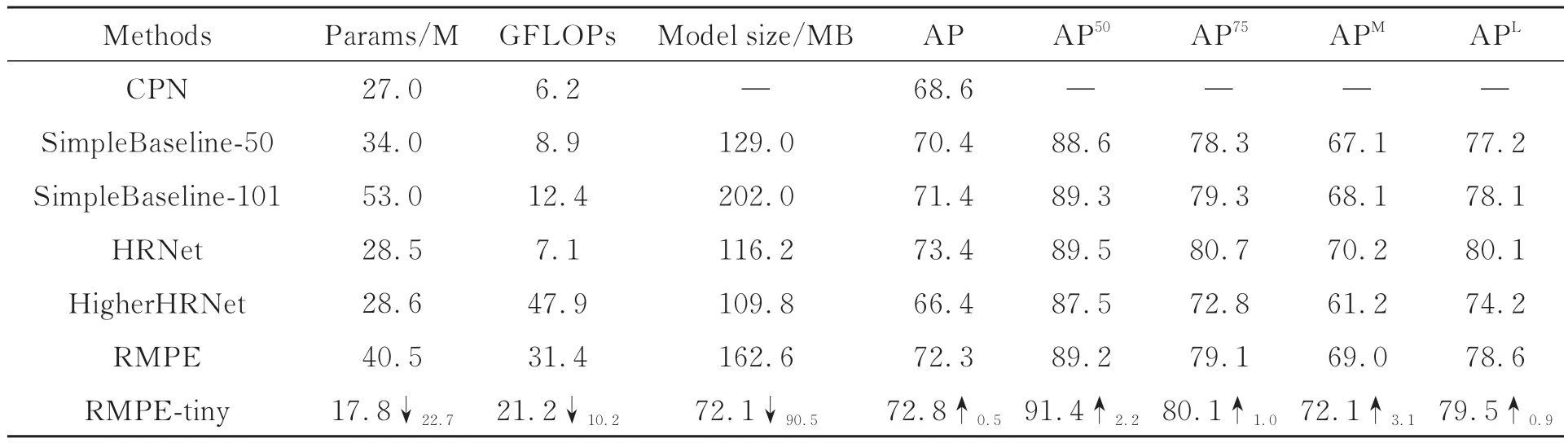
表1 不同人体姿态估计方法的性能对比Tab.1 Performance comparison of different human posture estimation methods
4.5 消融实验
表2为改进的人体姿态估计算法的消融实验对比分析,主要对比分析了本文所做各个改进的实验结果。实验结果表明,进行基于Ghost模块的特征提取网络轻量化重构后,模型参数量由原来的40.5 M下降至29.0 M,与RMPE网络相比减少了约25.0%,算力减少了约32.5%,模型体积减少了约28.1%。可以看出,Ghost卷积可显著降低网络的参数和运算量,但会导致精度AP有所损失。当采用轻量级注意力模块ECA恢复精度时,模型参数量明显下降,但模型AP值降至71.5%,检测精度有所降低,模型性能有所损失。为进一步恢复损失精度,本文融入多个改进的轻量级自适应特征感知模块Sa-ECA,此时模型体积减少为原来的约57.0%,检测精度提升为72.6%。故Sa-ECA模块可使网络充分获取关键点语义信息,在降低网络参数量的同时增强模型检测精度,性能更好。最后改进训练损失函数,结合Huber Loss训练模型时检测精度提高了约0.2%,进一步增强了模型的鲁棒性。最终通过本文优化改进得到了一个体积小、精度高、鲁棒性强的人体姿态估计模型。
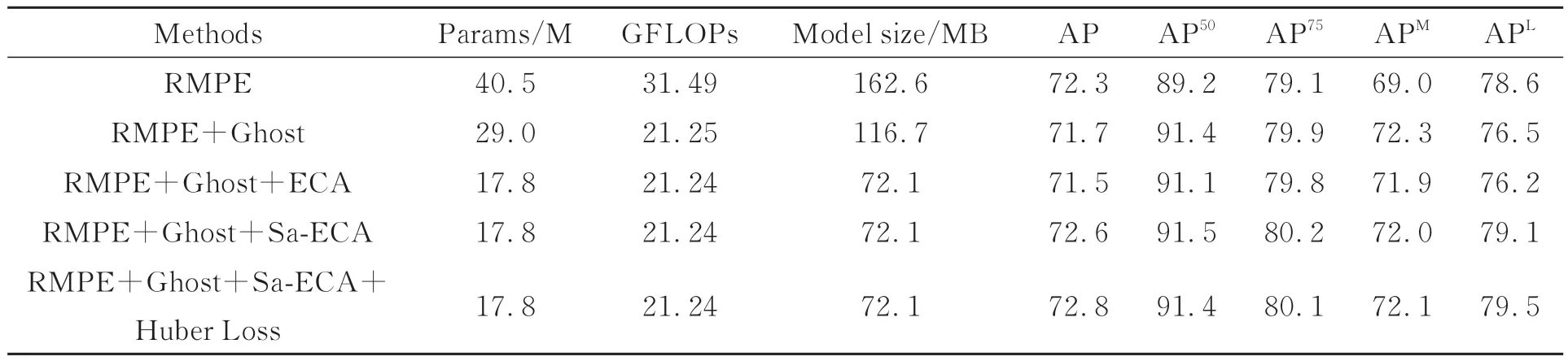
表2 消融实验的对比分析Tab.2 Comparative analysis of ablation experiments
表3为本文改进前后的模型性能对比。从表3可以看出,对RMPE多人姿态估计网络进行一系列轻量化改进后,本文模型RMPE-tiny与基准模型RMPE相比,模型检测精度提升约0.5%,模型检测速率提高了约2.1倍。本文改进后的模型在显著压缩模型体积、减少运算量的同时,有效改善了模型的检测速率,提升了人体姿态估计模型的检测效率。
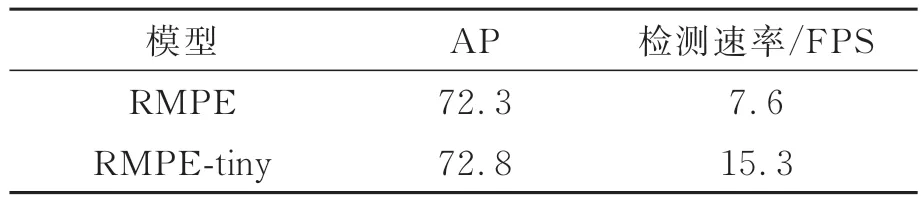
表3 模型性能对比Tab.3 Model performance comparison
4.6 关键点热图可视化分析
图7为模型改进前后的关键点定位热图可视化分析。从图7可以看出,注意力机制改进前后的关键点检测效果有着显著区别。热图是对COCO数据集中定义的17个人体关键点进行预测的中间过程展示。由于关键点为细粒度的像素级目标,故关键点热图的范围相对较小。使用注意力机制ECA时,不能很好地检测到Right ear和Right eye,检测结果存在一定误差。这是因为ECA模块聚合通道间的交互信息具有一定的局限性,导致关键点定位效果不理想。
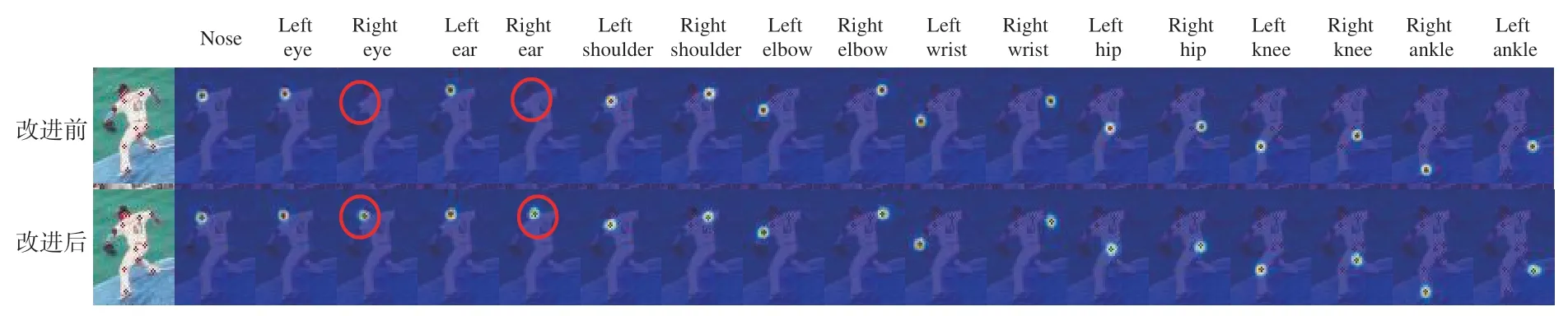
图7 热图可视化分析Fig.7 Heatmap visualization analysis
本文改进后的算法RMPE-tiny通过融入轻量级自适应特征感知模块Sa-ECA来实现通道信息有效聚合。Sa-ECA模块只涉及少量参数,通过自适应全局平均池化更加有效地获取与聚合局部跨通道交互信息,模型检测效率更高。从图7可以看出,融入轻量级自适应特征感知模块的检测效果更为理想,它能从特征图中获取更加充分的关键点信息。Sa-ECA模块在提升模型检测精度的同时,降低了模型参数量,压缩了模型体积,故本文有效地实现关键点热图定位。
4.7 可视化结果
本文方法的可视化效果如图8所示。图8(a)为遮挡检测结果,是针对不同遮挡情况下的检测结果。当人体某一关节被物体或自身遮挡时,本文模型可获取充分的上下文语义信息完成关键点位置判断,从而定位到遮挡关节的大致逻辑位置。图8(b)为复杂姿态检测效果。当人体做出复杂动作时,关键点极易发生多尺度变化。当场景中人体相对较小时,本文模型依旧可精确定位。图8(c)为多人场景检测效果。当输入图像中的人数较多时,会存在各种遮挡场景及多尺度情况,本文模型依旧可在此类情况下进行高效检测,准确定位到多人场景下的人体关键点,实现高效的人体关键点定位。图8(d)为本文算法模型在实际拍摄场景下的检测结果。当背景复杂且人物较小有遮挡时,由于本文模型有着较好的泛化能力与鲁棒性,依旧可进行高效的关键点检测。因此,从可视化结果可以得出,本文提出的RMPE-tiny算法具有较强的鲁棒性且泛化能力更优。该算法在显著降低网络复杂度的同时,依旧可以保持较好的关键点检测效果。

图8 可视化结果Fig.8 Visualization results
5 结论
本文针对一般多人姿态估计算法存在的参数量多、计算量大、检测速率低,模型检测速度与检测精度之间难以平衡的问题,提出了一种改进的轻量级多人姿态估计算法RMPE-tiny。该算法首先结合Ghost模块轻量化重构特征提取网络,压缩模型体积;其次融合自适应特征感知模块Sa-ECA,在增强检测精度的同时降低模型复杂度;最后结合Huber Loss损失函数加快模型收敛,进一步提高模型鲁棒性。实验结果表明,本文算法RMPE-tiny的检测效果优于原算法RMPE,改进后模型的检测精度可达约72.8%,模型的参数量为17.8 M,模型体积为72.1 MB,检测速率可达约15.3 FPS,模型的轻量化程度达约57.0%。轻量级人体姿态估计算法RMPE-tiny以更少的参数和计算成本达到了更优的检测效果,有效改善了人体姿态估计模型在多人复杂场景中的检测性能,提升了模型的检测精度与检测速率,实现了高效的人体姿态估计。
