基于近红外光谱的烤烟香型分类模型研究
2023-08-13杨永锋刘向真赵森森刘茂林贾国涛牛洋洋张坤芳于建军彭桂新姬小明
付 博,杨永锋,刘向真,赵森森,刘茂林,贾国涛,牛洋洋,张坤芳,于建军,彭桂新,姬小明
(1.河南中烟工业有限责任公司技术中心,河南 郑州 450016;2.河南农业大学烟草学院,河南 郑州 450002)
烟草是我国重要的经济作物,烤烟在卷烟原料中占据重要地位。我国地域辽阔,各个种植气候与土壤条件形成了较为丰富的烤烟香气类型[1]。香气类型对烟叶原料的高效利用及卷烟配方开发具有举足轻重的作用。20 世纪50 年代,老一辈科学家根据烤烟香气特点,将其划分为浓香型、中间香型、清香型三大香型[2]。张建平等[3]以烟叶样品近红外光谱数据作为研究对象,通过建立烟叶生态区及风格特征的投影分析模型,将烤烟香型又细化为典型清、典型中、典型浓、清偏中、清透浓、中偏清、中偏浓、浓偏中、浓透清9 类。李章海等[4]建立了烟叶评判香型指数,将我国烤烟香型细分为清香型、清偏中型、中偏清型、中间型、中偏浓型、浓偏中型和浓香型7 个小类。罗登山等[5]在传统三大香型的基础上完成了全国烤烟烟叶风格区划体系的构建,将全国烤烟烟叶划分为西南高原生态区-清甜香型(Ⅰ)、黔桂山地生态区-蜜甜香型(Ⅱ)、武陵秦巴生态区-醇甜香型(Ⅲ)、黄淮平原生态区-焦甜焦香型(Ⅳ)、南岭丘陵生态区-焦甜醇甜香型(Ⅴ)、武夷丘陵生态区-清甜蜜甜香型(Ⅵ)、沂蒙丘陵生态区-蜜甜焦香型(Ⅶ)、东北平原生态区-木香蜜甜香型(Ⅷ)等八大香型。
八大香型的划分旨在满足中式卷烟对烟叶原料风格多样性需求[6],提高卷烟工业企业配方和原料利用水平,提升原料保障能力。以生态为基础、以香韵为依据、以化学成分和物质代谢为支撑确立了各香型典型产地及相邻香型边界,划分了香型稳定区和波动区[7]。卷烟产品设计及维护过程中需要对烟叶原料的香型进行判定,以满足卷烟产品设计目标和特征。烟叶香型的判定主要通过感官评吸的方式[8],但是感官评吸受人体嗅味觉、心理及评吸环境等多种因素影响,因此,建立高效便捷的烟叶香型判定方法尤为重要。
在烟叶香型快速判定方面已有较多研究,申钦鹏等[9]、许永等[10]利用烟叶化学成分与香型的关系建立香型判定模型,有效避免了人为主观因素影响,缩短了香型判定时间。张同琢等[11]利用热分析图谱结合机器学习,构建了八大香型判定模型,香型判定准确率为83.30%。王一丁等[12]建立了基于可见-近红外光谱判定烤烟香型的方法。近红外光谱技术由于快速、无损、操作简便、稳定性好等特点,经常被用于烟叶产地溯源及香型判定研究[13-15],但是目前还没有利用近红外光谱对八大香型进行快速判别的研究。因此,采用近红外光谱结合机器学习方法构建八大香型分类模型,以期进一步提高烤烟烟叶香型判定效率,为提高烟叶原料利用水平、卷烟配方设计及维护效率提供技术支撑。
1 材料和方法
1.1 试验材料
试验用样品选取来自云南、吉林、四川、广西、河南、湖南、福建、贵州、重庆、陕西、黑龙江、辽宁共12 个省(市、区)的烤烟烟叶,由河南中烟工业责任有限公司提供,烟叶采集年份在2016—2021 年,共计1 383份样品。
1.2 近红外光谱数据采集
将烟叶置于烘箱中45 ℃干燥30 min,研磨成粉后过0.42 mm 孔径筛网。将制备好的烟末放于石英测量杯中,并用压样器压实。利用傅立叶变换近红外光谱仪(Thermo Fisher)进行光谱采集,光谱采集范围:3 800~10 000 cm-1;光谱分辨率:8 cm-1;扫描次数:64次;样品杯方式:旋转。
1.3 近红外光谱数据预处理
选用一阶导数(D1)、二阶导数(D2)、移动平均平滑(MA)、均值归一化(MEAN)、多元散射校正(MSC)、极差归一化(MAXMIN)、SG 滤波一阶导数(SG1)、SG 滤波二阶导数(SG2)、标准正态变量变换(SNV)和小波变换(WAVE)等10 种预处理算法,按照无预处理、单种预处理、组合预处理等方法探讨预处理方法的优劣[16-17]。组合预处理方式分别采用2~4 种预处理方式叠加,通过随机组合形成93 种组合方式,包括组合顺序和预处理叠加个数。
1.4 数据降维
预处理后的数据分别利用主成分分析(Principal components analysis,PCA)、增量主成分分析(Incremental principal components analysis,IPCA)、核主成分分析(Kernel principal components analysis,KPCA)和因子分析(Factor analysis,FA)进行降维,以模型准确率为衡量标准,在主成分个数为1~50内筛选准确率最高的降维方式及主成分个数。
1.5 模型构建与评估
香型分类模型构建采用随机森林(RF)分类算法,随机森林是由多棵决策树组成的集成学习算法[18]。该算法首先Bootstrap 采样方法随机获得N个有差异的训练集,然后采用Bagging 机制生产含有N个决策树的随机森林,根据投票法判别样本的最终类别。根据随机森林运算原理,可知该算法有2 个关键参数,即评估器数量(N_estimators)和随机种子(Random_state),因此,模型构建时重点对这2 个参数进行优化。模型初始参数中,评估器数量为350、随机种子为12,参数优化范围分别为50~1000 和0~15。香型分类模型评价采用模型准确率(Accuracy)、精准率(Precision)、召回率(Recall)和宏观F1值(F1_macro)4项指标。
2 结果与分析
2.1 烟叶样品香型分布分析
根据八大香型区划结果对1 383 个烟叶样品进行香型归属分类,并依据香型边界定位确定样品属于香型稳定区(W)或者波动区(G),结果见表1。由表1 可知,清甜香型烟叶样品有486 份,其中云南的玉溪、昆明、曲靖、昭通、文山、楚雄及四川凉山等地为稳定区,共有302份样品,波动区主要包括云南保山、临沧、丽江及广西百色西部、贵州毕节西部的样品,共184份。贵州的中东部为蜜甜香型的稳定区,波动区主要包括贵州的黔西南、毕节及广西百色,该香型稳定区有88 份样品。焦甜焦香型的样品主要分布在稳定区,共有410 份样品。焦甜焦香型样品主要来自河南,清甜蜜甜香型全部来自福建。辽宁、吉林及黑龙江的样品全部划分为木香蜜甜香型稳定区,总计76份样品。采用各香型稳定区的烟叶样品(1 109 份)构建香型分类模型,以保证分类模型的准确性。
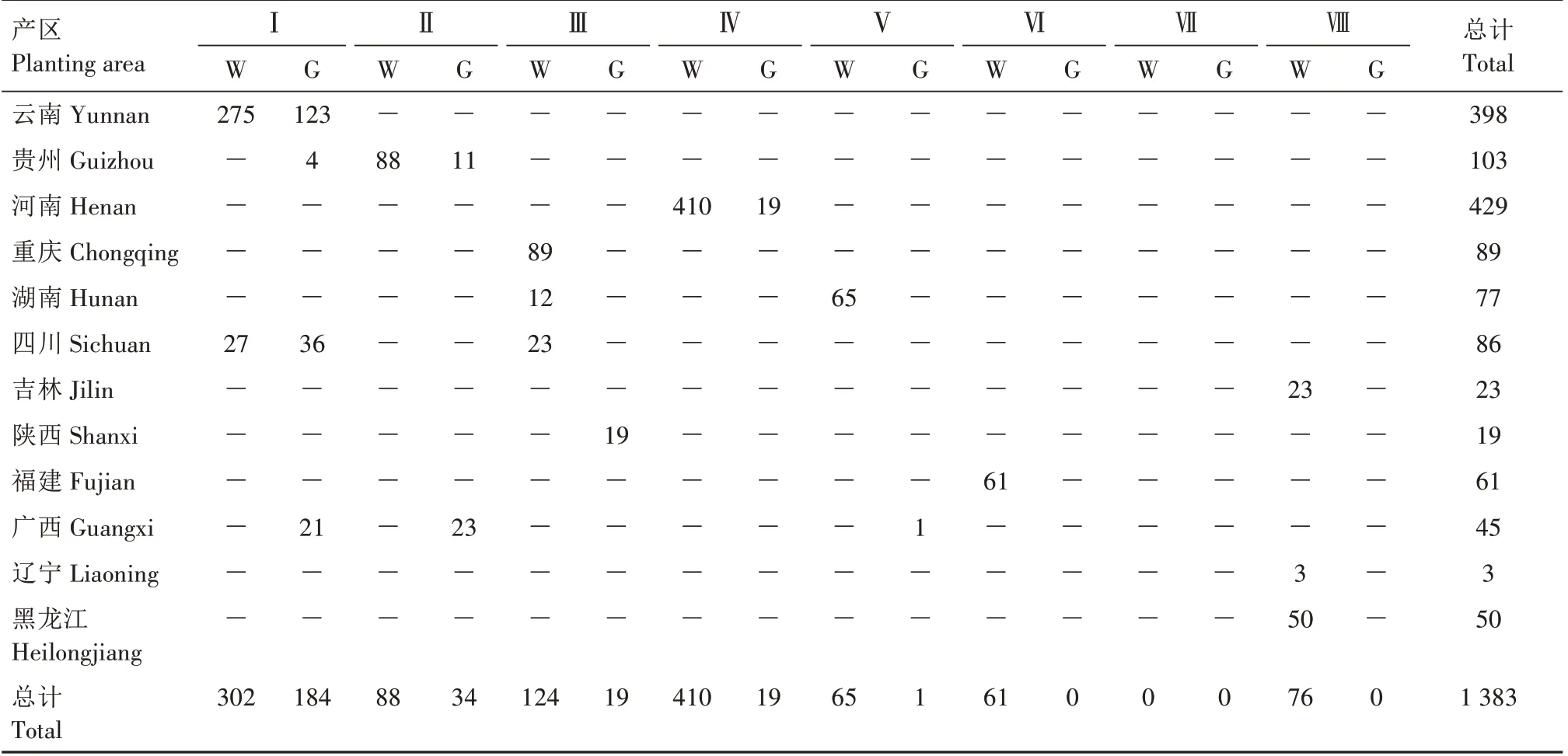
表1 烟叶样品产地来源及香型分布Tab.1 Table of origin and aroma type distribution of tobacco samples份
2.2 近红外光谱预处理方法对烤烟香型分类模型准确率的影响
利用近红外原始光谱构建香型随机森林分类模型,模型预测准确率(ACC)仅能达到48.64%(表2),观察近红外光谱曲线发现不同香型的光谱曲线在整个光谱区间均具有较大差异,说明原始光谱中存在较多的干扰因素(图1A)。近红外光谱经过小波变换(WAVE,ACC=0.50.00%)、极差归一化(MAXMIN,ACC=63.64%)和多元散射校正(MSC,ACC=66.82%)均能提高模型的预测准确率,但是正确率提升幅度有限。一阶导数(D1)处理后的模型预测准确率为72.27%,较原始光谱提高23.63 个百分点。SG 滤波一阶导数的准确率为73.64%,效果优于一阶导数。在不同预处理方法组合中,SG1+MSC 和SGZ+MSC 处理后构建的模型预测准确率最高,为78.18%,其次为MSC+D1+MA,准确率为77.73%,预处理方法组合顺序不同,会影响模型的准确率,D1+MA+MSC 处理后准确性为77.27%,略低于MSC+D1+MA。而D1+MA+MSC+WAVE 与D1+MA+MSC 预处理组合得到的模型预测准确率完全一致,说明光谱数据经过D1+MA+MSC 处理后进行小波变换对模型准确率没有提升作用。对比原始光谱、MSC、SG1 和SG1+MSC 等不同预处理光谱图发现,直观差异逐渐变小,干扰因素被逐步消除(图1)。
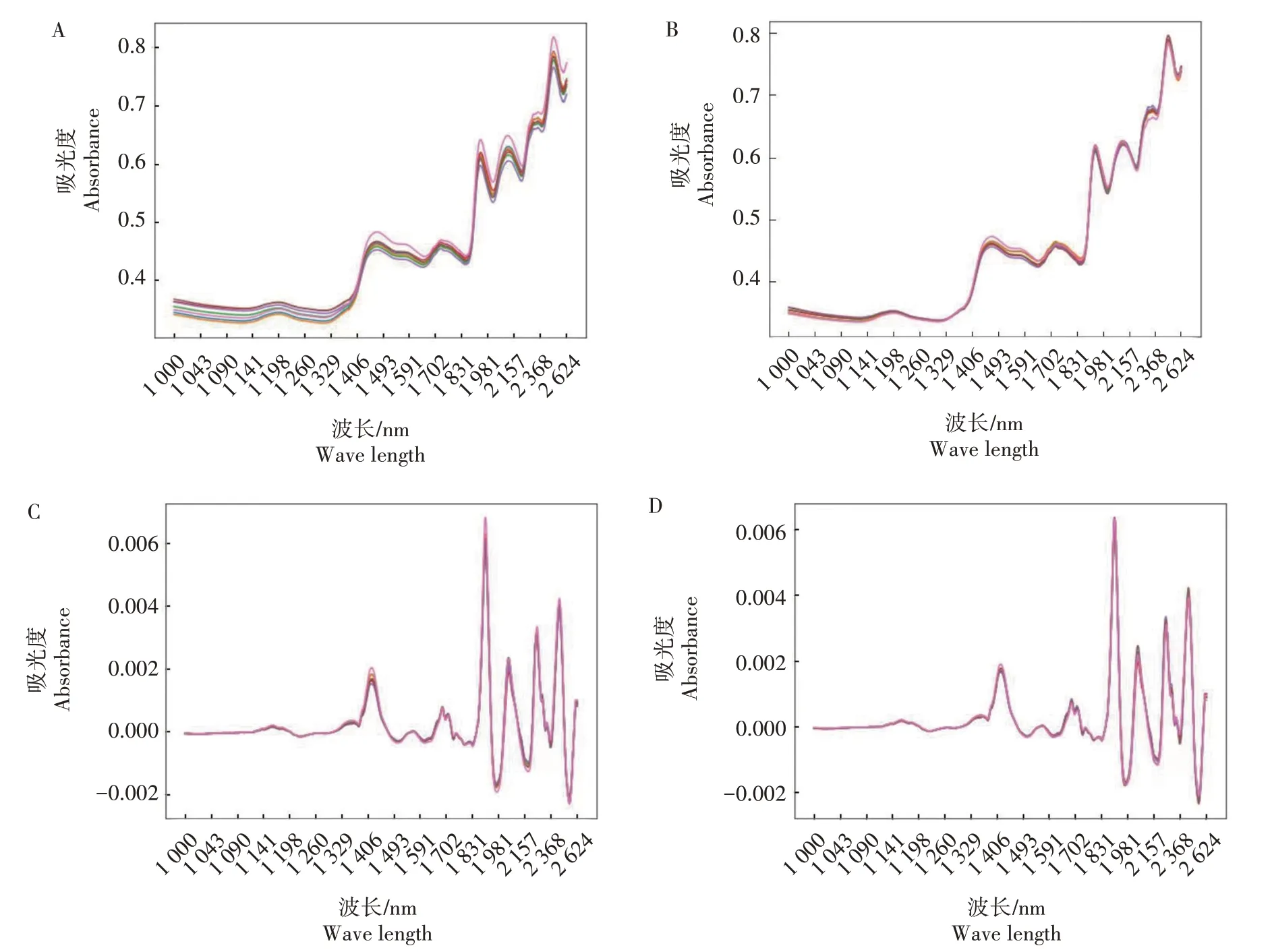
图1 不同预处理条件下的近红外光谱图Fig.1 Near infrared spectra of different pretreatments

表2 数据预处理对烤烟叶香型分类模型准确率的影响Tab.2 Influence of preprocessing methods on aroma type classification model accuracy of flue-cured tobacco %
2.3 近红外光谱数据降维方法对烤烟香型分类模型准确率的影响
选用PCA、IPCA、KPCA 和FA 等4 种数据降维方法对SG1+MSC 处理后的数据进行降维(表3),结果显示,利用PCA降维方法,主成分个数为26时,模型准确率为82.73%,较降维前模型准确率提高4.55个百分点。利用IPCA 降维后的数据集构建分类模型,模型准确率最高为82.27%。KPCA 降维后的分类模型准确率最高为83.18%,与PCA 和IPCA 相比准确率提高0.45 个百分点。FA 降维选取45 个主成分时,构建的随机森林分类模型准确率最高,为85.91%,与降维前相比,准确率提高7.73个百分点。
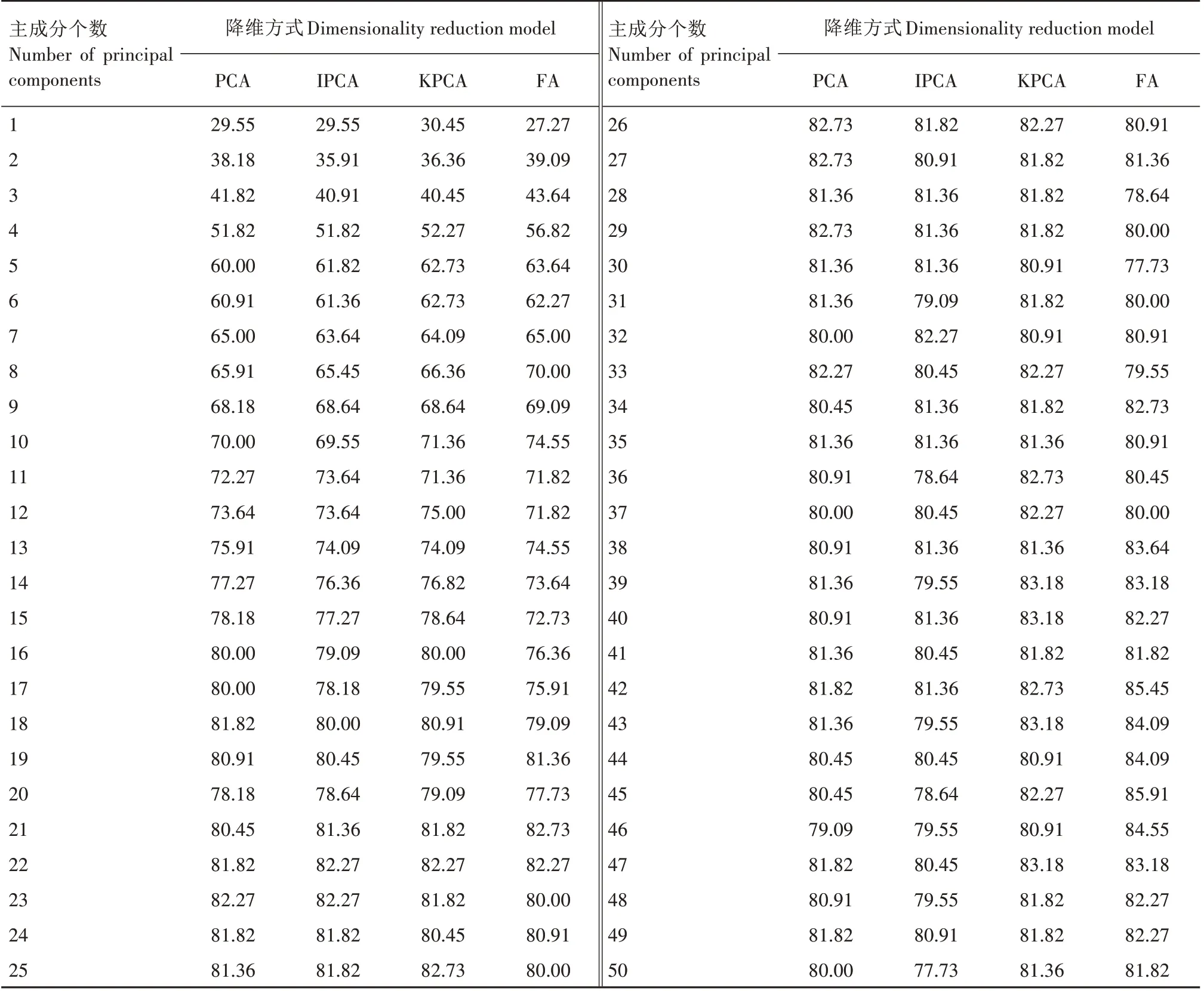
表3 降维方式对烤烟香型分类模型准确率的影响Tab.3 Effect of dimensionality reduction on aroma type classification model accuracy of flue-cured tobacco %
2.4 烤烟香型分类模型参数优化及预测效果评价
随机森林是非常具有代表性的装袋法(Bagging)集成算法,在模型构建过程中评估器数量(N_estimators)和随机种子(Random_state)是显著影响模型精度的参数。对评估器数量和随机种子2个参数优化结果显示,当评估器数量为500、随机种子为9 的时候,模型准确率最高为90.45%,与优化前相比准确率提高4.54 个百分点。利用优化后的香型分类模型对预测集进行分析,混沌矩阵结果(表4)显示,清甜香型55 份样品有1 份样品被错误分类到焦甜焦香型,召回率为98.18%。蜜甜香型样品召回率仅为66.67%,24 份样品中有7 份被错误分类到清甜香型,其中有5份为贵州毕节的样品,黔东南和遵义桐梓县的样品各1 份,毕节处于清甜香和醇甜香型交界处,不同年份气候条件的变化使得该地风格在2 种风格间波动。召回率同样为66.67%还有焦甜醇甜香型,15 份样品中有3 份被错误分类到焦甜焦香型,这3份样品均为湖南郴州的样品,而1 份衡阳的样品被分到了醇甜香型,另1 份常德的样品被错误分类到了清甜蜜甜香型。
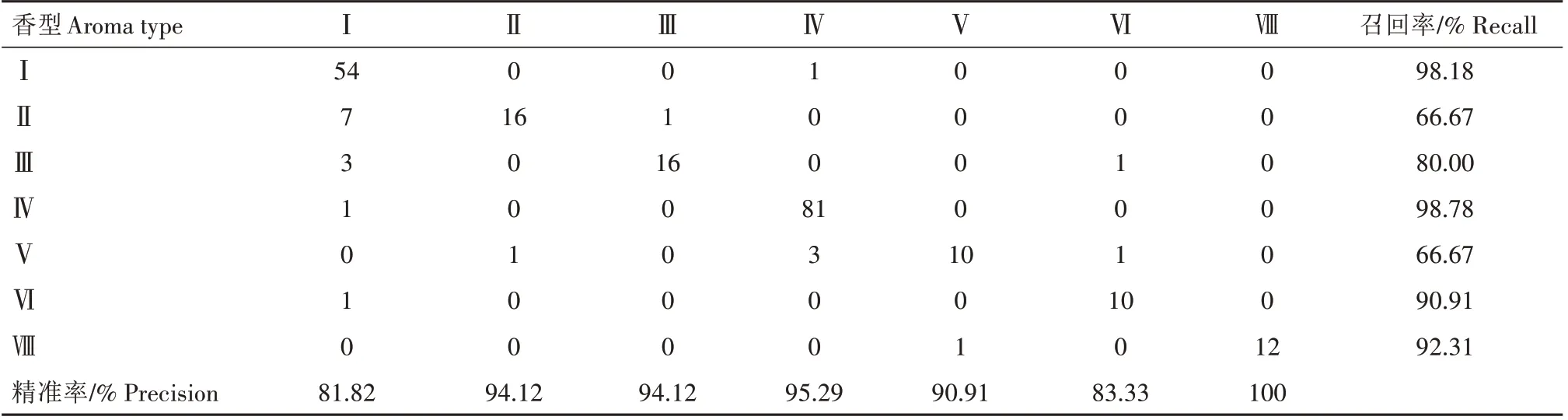
表4 参数优化后的烤烟香型分类模型混沌矩阵Tab.4 The chaotic matrix of the aroma type classification model of flue-cured tobacco after parameter optimization
3 结论与讨论
本研究基于八大香型区划结果对12 个省(市、区)的1 383 份烟叶样品进行香型分类,选用各香型稳定区的样品构建香型分类模型。近红外原始光谱数据首先经过SG 滤波一阶导数和多元散射校正预处理,然后利用因子分析降维处理(45 个因子),采用随机森林分类算法(N_estimators=500;Random_state=9)构建的模型准确率最高为90.45%,明显高于张同琢等[11]利用热分析图谱构建的香型判定模型准确率(83.30%)。该分类模型对清甜香型、焦甜焦香型、清甜蜜甜香型和木香蜜甜香型的召回率均达到90.00%以上,蜜甜香型和焦甜醇甜香型的召回率为66.67%。分析模型对蜜甜香型和焦甜醇甜香型预测准确率较低的原因发现,被错误分类的样品多位于香型分布区过渡地带,比如蜜甜香型被错误分类的7 份样品有5 份位于清甜香和醇甜香过渡地带,1 份位于醇甜香和蜜甜香过渡地带。而焦甜醇甜香型错误分类的5 份样品有3 份被分到了焦甜焦香型,1份被分到了醇甜香型,表现出了较强的香韵相似性,这也表明利用近红外光谱方法对烟草香韵的判别或许是可行的。
八大香型的划分主要依据烟叶产地生态条件、香韵组成及化学成分,其区划结果对烟叶原料配方应用具有重要指导意义。由于划分的香型类别较多,使八大香型数字化快速判定增加了难度、提高了挑战度。构建的近红外香型分类模型和热分析图谱香型判定模型均是在八大香型区划的前提下进行的香型数字化判定探索。另外,王文俊等[19]利用近红外和电子鼻融合数据对清香型、中间香型和浓香型3 种香型风格进行了判别,以及沙云菲等[20]利用近红外和中红外融合数据对3种香型构建判别模型,也为国产烟叶香型快速判别提供了新思路。单一的快速检测技术获得的数据很难全面地表征烟叶风格信息,利用多种检测技术能够提高模型的准确率,更为有效地指导烟叶原料利用。近红外光谱等方法具有绿色、快速、无损的优点[21],为烟叶原料有效利用及烟叶风格数字化评价提供了新思路和技术支撑。
