基于对比学习的多肉植物分类识别方法研究
2023-08-13封雨欣梁少华
封雨欣,梁少华,童 浩
(长江大学计算机科学学院,湖北 荆州 434023)
据统计,目前有超过12 000 种多肉植物,隶属约80 科[1]。但在国内的多肉植物市场中,供人们欣赏的作为盆栽类的多肉植物种类只有百余种。多肉植物的外观特征很难准确评估和描述,种类间存在的差异很小,肉眼很难进行分辨,只有少数植物学家和多肉植物从业者能够完全识别它们。由于多肉植物种类繁多,类与类之间差异小,而类的内部由于生长周期、生长状态和环境的不同存在较大差异,这使得多肉植物的分类与其他分类任务相比更加复杂,属于细粒度分类问题。
深度学习技术为解决多肉植物图像分类问题带来了新思路,不仅大大节省了时间和精力,更是将人工智能和农业科学相结合促进了现代农业的发展。在多肉植物图像分类技术研究中,刘俨娇[2]提出的基于深度卷积网的多肉植物分类使用了包含10 个种类的多肉植物数据集和9 个种类的生石花细粒度数据集,通过微调AlexNet,多肉植物和生石花的分类准确率分别达到了96.1%和88.1%。黄嘉宝等[3]提出的基于卷积神经网络的多肉植物细粒度图像分类使用了包含20 个种类的多肉植物数据集,通过微调GoogLeNet,多肉植物的分类准确率达到了96.7%。上述多肉植物分类研究虽然能够有效提升分类准确率,但多肉植物数据集种类较少,只是简单对卷积网络进行微调,在多肉植物数据集种类扩充以及模型结构的改进方面仍有很大的进步空间。
随着人工智能技术的飞速发展,卷积神经网络近年来被广泛用于解决图像分类任务,它具有良好的特征提取和映射能力,通过迭代运算来提高模型的泛化能力。DYRMANN 等[4]设计了一个卷积神经网络,对22 种植物进行识别,识别准确率达到了86.2%。HU 等[5]提出了一种多尺度融合卷积神经网络(MSF-CNN),对MalayaKew Leaf[6]数据集中的99种植物叶片和LeafSnap[7]数据集中的184 种植物叶片进行识别。李立鹏等[8]使用迁移学习和残差网络对62 种野生植物进行识别,得到了85.6%的准确率。但是单纯的卷积神经网络在面对“类间差异小、类内差异大”这种细粒度分类时,往往很难捕捉到具有区分能力的关键局部信息。随着自监督学习领域中对比学习思想的提出,利用对比学习作为外部信息辅助细粒度图像分类也成为很多研究者的研究重点,涌现出了MoCo[9]、SimCLR[10]等一系列优秀的对比学习模型。MoCo 和SimCLR 都提出批大小设置的越大,越能获得更好的效果,这对计算机资源的需求很大,不利于实际应用。且在解决固定下游任务时,仍需要采用“预训练→微调迁移下游任务”两阶段训练过程,造成一定资源的浪费。鉴于此,扩充多肉植物数据集种类,参考卷积神经网络的结构设计,融合了对比学习思想,提出一种基于对比学习的CL_ConvNeXt 网络(ConvNeXt with contrastive learning),以提高多肉植物图像的分类准确率,从而有效识别更多种类的多肉植物。
1 材料和方法
1.1 试验材料
1.1.1 多肉植物数据集 数据集是自主采集的原创数据集,收集了网络上较为常见的190 种多肉植物的图片,每个种类包含60~180 张不等的图片,共有24 440 张图片,以8∶2 的比例划分训练集和验证集。部分种类多肉植物图像如图1所示。多肉植物种类多、数据量少,类内差异大、类间差异小等问题是多肉植物识别的主要难点。图2展示了多肉植物类内差异大、类间差异小的特点。

图1 部分种类多肉植物图像Fig.1 Images of some species of succulents

图2 多肉植物的识别难点Fig.2 Difficulties in identifying succulents
1.1.2 数据预处理 数据增强[11]可以有效解决数据不足引发的模型过拟合问题。数据增强可以让有限的数据产生更多的数据,增加训练样本的数量以及多样性,提升模型鲁棒性。常用的监督数据增强的方法包括裁剪、反转、对比度增强、平移、旋转、添加噪声等。所用数据集在使用普通数据增强的方法,比如中心裁剪、随机翻转、随机旋转、随机改变对比度之外,还增加了Cutout[12]和Mixup[13]2 种数据增强的方法。Cutout能更好地实现对遮挡数据的模拟,提高泛化能力。同时能够让卷积神经网络更好地利用图像的全局信息,而不是依赖于小部分特定的视觉特征。Mixup 作为常见的多样本数据增强方法,使用线性插值得到新样本数据,可以将不同类别之间的图像进行混合,从而扩充训练数据集。图3为多肉植物数据集的数据增强示例。

图3 多肉植物数据集的数据增强示例Fig.3 Example of data augmentation for the succulent dataset
1.2 试验方法
1.2.1 网络结构 CL_ConvNeXt 网络以ConvNeXt模型为主干网络。ConvNeXt[14]是2022 年提出的一款纯卷积神经网络。它以残差网络ResNet50[15]为基准模型,设计上参考了Transformer 和Swin-Transformer 的训练策略。在推理速度和准确率两方面都明显优于ResNet网络和Swin-Transformer[16]。CL_ConvNeXt 将卷积网络与对比学习相融合,利用ConvNeXt 模型的多路特征表示能力提取出不同抽象级别的特征,对比学习可以通过比较不同层之间的相似性和差异性,加强不同卷积层之间的交互,从而进一步提高模型的特征表示能力和性能。
一般来说,卷积神经网络的不同层倾向于学习不同层次的特征。通常,浅层学习诸如颜色和边缘等底层特征,而最后几层学习更多与任务相关的高级语义特征。对于细粒度图像分类任务来说,浅层网络学习到的特征同样需要关注。传统的卷积神经网络只对最后一层进行监督,然后将误差从最后一层传播到较浅的层,导致中间层优化困难,出现梯度消失的问题。对比学习作为一种表征学习方法,将其运用到网络中间层,学习数据增强的不变性,可以很好地对浅层网络特征进行提取,解决了传统深度卷积网络容易出现的梯度传播不稳定和收敛过慢的问题。同时还可以带来一定的计算优势,由于中间层的特征维度相对较小,因此在进行特征投影时所需计算的参数数量也较小,可以减少计算量和模型参数,加速模型的训练和推理过程。图4 为不同方法的基本结构对比,CL_ConvNeXt 网络模型的结构如图5所示。

图4 不同方法的基本结构对比Fig.4 The basic structure comparison of different methods

图5 CL_ConvNeXt网络模型结构Fig.5 CL_ConvNeXt network model structure
CL_ConvNeXt 在解决多肉植物种类多、类间差异小、类内差异大的问题时,首先,不需要数据集具有详细特征判别区域标签,简单的类别标签就可以获得不错的效果;其次,投影层(Projection head)的嵌入比较灵活,浅层嵌入如果效果好,就无需多层嵌入,避免资源浪费,也可以适应不同的任务需求;同时不需要复杂的网络结构,对不同卷积神经网络均有适用性。相较于SimCLR 和MoCo 需要先训练出通用大模型再进行fine-turn 训练出分类器的方法,在解决多肉植物图像分类这个特定领域问题时有着不可取代的优势。不仅可以提取浅层网络特征,对全局和局部特征进行融合,而且重新设计了损失函数的计算方法,可以实现单阶段模型训练。对计算机资源的要求不高,对后续在移动设备或嵌入网络系统中部署非常有利。
1.2.2 Projection head 结构 Projection head 通过将高维特征映射到低维向量空间来增强特征表示,这个低维的向量空间通常被称为嵌入空间(Embedding space),其中每个向量对应着1 个样本的表示。在这个空间中,相似的样本会被映射到相似的位置,不相似的样本会被映射到不同的位置。这种低维的表示可以帮助模型更好地学习数据的结构和特征,从而提高模型的性能。通过只保留相关信息并消除不相关信息,Projection head 有助于在不同任务中实现更好的泛化、高效的特征提取和稳定而健壮的模型性能。Projection head 中的每个神经元可以看作是1 个学到的特征。因此,可以通过分析每个神经元对应的权重来了解模型在学习哪些特征。对于多肉植物图像分类任务,可以通过分析投影层中的每个神经元对应的权重,来了解模型是否学习到了图像的纹理、形状、颜色等特征。Projection head 的结构对模型性能至关重要,常见的Projection head 主要结构是1 个包含隐藏层的多层感知机,一般添加在主干网络之后。
在本方法中将Projection head 作用于中间层,可以学习到浅层较为局部的特征,也可以学习到深层的全局特征,这些特征可以较好地融合全局和局部信息。为了使作用于中间层的Projection head 能够更好地对多个不同深浅层的特征进行特征提取,通过添加卷积层来增加Projection head 的复杂性,建立1个多层层级结构,使梯度传播过程更稳定、收敛速度更快。卷积层可以通过局部感受野、参数共享等特性,通过在输入图像上滑动1个滤波器,提取图像中的更加高级的语义信息,从而使得Projection head 可以学习到更加抽象和区分度更高的特征表示。并且通过参数共享可以大大减少网络参数数量,从而降低模型复杂度,避免过拟合。通过使用非线性激活函数(ReLU 函数),以增强模型的非线性表达能力。此外,加入Batch Normalization(BN)这种正则化手段,以进一步提高模型的泛化能力和鲁棒性。图6为Projection head结构图。

图6 Projection head结构Fig.6 Projection head structure
1.2.3 损失函数设计 对比学习[17]的核心思想是缩小正样本的距离,扩大负样本的距离,正、负样本的构造是计算对比损失的前提。本研究将1个批处理中的N个样本经过2 种数据增强得到2N个样本,对于1 个样本来说,其经过数据增强后得到的2 张图片互为1 对正样本,同批次中其余2N- 2 个样本均为负样本。使用余弦相似度计算2 个样本u、v之间的距离,公式如下:
以1 对正例图像为例,其对比损失函数[10]的计算公式如下:
式中,zi,zj为1对正样本,zi,zk互为负样本,τ是温度参数。
假设每对正样本位置相邻,对批处理中的每1对图像做上述损失函数计算,最后对所有损失函数之和求均值,即为最终的损失函数值,公式如下:
传统深度卷积网络[18]通常只需要对最后1 层计算损失然后向前反向传播,由于本研究在中间特征层引入了对比学习方法作为辅助分类器,所以对于损失函数需要重新设计。在每个特征提取阶段i,都要对辅助分类器Ci计算对比损失。因此,一共有n个分类器。中间层的辅助分类器采用上述对比损失函数LContra,最终层分类器Cn采用交叉熵[19]损失函数LCE,α是1 个超参数,用来平衡2 个损失项。所得损失函数公式如下:
1.2.4 训练策略优化 优化器选择AdamW(Adam with decoupled weight decay)[20]优化器是Adam(Adaptive moment estimation)[21]的改进版本。AdamW 是在Adam 的基础上加入L2正则,并且采用计算整体损失函数的梯度来进行更新。AdamW 优化器计算公式如下:
式(5)中,mt计算的是t时刻的一阶动量,gt表示时刻梯度,β1为一阶矩阵指数衰减率。式(6)中,vt计算的是t时刻的二阶动量,gt表示时刻梯度,β2为二阶矩阵指数衰减率。式(7)(8)中和分别是对一阶动量mt和二阶动量vt的校正。式(9)中,θ是要更新的参数,λ为权重衰减因子,α为学习率,ɛ是为了维持数值稳定性而添加的常数。
学习率优化时采用了学习率预热(Warmup)[22]和余弦下降(CosineAnnealingLR)[23]策略。由于神经网络刚开始训练时,模型的权重是随机初始化的,此时若选择一个较大的学习率,可能带来模型的振荡,选择学习率预热的训练方式,可以在开始训练的几个训练周期内设置较小学习率,在学习率预热阶段,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练。这种方法有助于减缓模型在初始阶段对小批量数据的提前过拟合现象,保持分布的平稳和模型深层的稳定性。当预热阶段结束后,选择采用余弦下降的方法来调整训练时的学习率。余弦下降调整学习率的原理公式如下:
2 结果与分析
2.1 试验环境及参数设置
GPU 显卡为NVIDIA GeForce RTX3060,软件环境为Windows10,深度学习框架是Pytorch1.10。各参数的初始设置如下:(1)对训练样本进行数据增强时,Mixup 的概率为0.2。(2)学习率预热阶段,学习率设为0.001,训练轮数设为20。(3)对整个模型进行微调训练的最大轮数设为300,批大小设为64,学习率为0.01,权重衰减为0.05,Dropout 概率为0.5。(4)数据增强对比试验采用的基础结构是ConvNeXt-tiny,其他试验均采用ConvNeXt-base。
2.2 数据增强对比试验
为了验证数据增强对多肉植物图像识别的影响,在没有对模型微调和优化的情况下,都采用ConvNeXt 网络结构,分别在没有数据增强只做了尺寸归一化处理的数据集上和经过Cutout、Mixup数据增强处理的数据集上进行140个轮次的训练。训练结果如图7所示。
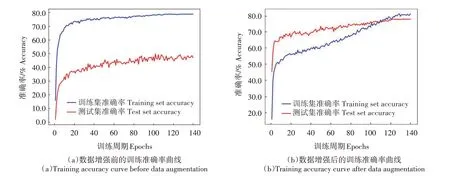
图7 数据增强前后的结果对比Fig.7 Comparison of results before and after data augmentation
从图7 可以看出,未做数据增强的数据集进行训练时存在明显的过拟合现象。数据增强后的训练集进行训练时,一定程度上缓解了模型过拟合的问题,使模型获得了更好的泛化能力。并且经过140 个轮次的训练,数据增强后模型的识别准确率仍然存在上升的趋势。相比原始数据集46.63%的识别准确率,数据增强后的训练效果显著提升,识别准确率提高了31.47 个百分点,达到了78.10%。说明数据增强能有效地提升多肉植物数据集的识别准确率。
为了进一步探究常见的几何变换、Cutout 和Mixup 3 种数据增强方式对多肉植物识别的影响,分别采用不同的数据增强方法,进行了多次消融试验,结果如表1 所示。从表1 可以看出,仅仅采用几何变换这种数据增强方式,虽然可以提升模型的识别准确率,解决模型过拟合的问题,但远没有任意2种数据增强组合的方式效果好。综合来看,将3 种数据增强方式组合起来使用,更适合多肉植物数据集的训练。

表1 不同数据增强方式的训练结果Tab.1 Training results of different data augmentation methods
2.3 不同方法对比试验
为了验证CL_ConvNeXt 在多肉植物数据集上的适用性,将目前热门网络结构,包括ResNet50、Vision-Transformer[24]、Swin-Transforme 和ConvNeXt,与CL_ConvNeXt 对比,均采用迁移学习[25]、选择AdamW 优化器、使用CosineAnnealingLR+Warmup的学习率优化策略、迭代300 次来进行训练。不同方法的训练结果如表2所示。具体识别准确率随迭代次数的变化情况如图8 所示。从表2 可以看出,CL_ConvNeXt 训练出的最终准确率分别比ResNet50、Vision-Transformer、Swin-Transformer 和ConvNeXt 高35.94、25.24、19.59、12.24 个百分点,损失函数值也是5 种方法中最小的。从图8 可以看出,CL_ConvNeXt 的收敛速度快于ResNet50、Vision-Transformer、Swin-Transformer。虽 然ConvNeXt 的收敛速度略快于CL_ConvNeXt,但CL_ConvNeXt 趋于稳定后的准确率更高。说明CL_ConvNeXt 在解决多肉植物分类问题时效果更好,更适合本研究所用多肉植物数据集的训练,进一步体现了将对比学习融入深度卷积网络的有效性。

表2 不同方法训练结果对比Tab.2 Comparison of training results of different methods

图8 不同方法的识别准确率曲线Fig.8 Recognition accuracy curve of different methods
为了验证CL_ConvNeXt 同经典对比学习模型相比的优势,将CL_ConvNeXt与MoCo、SimCLR进行对比试验,批大小均设置为64。最终试验结果如表3所示。
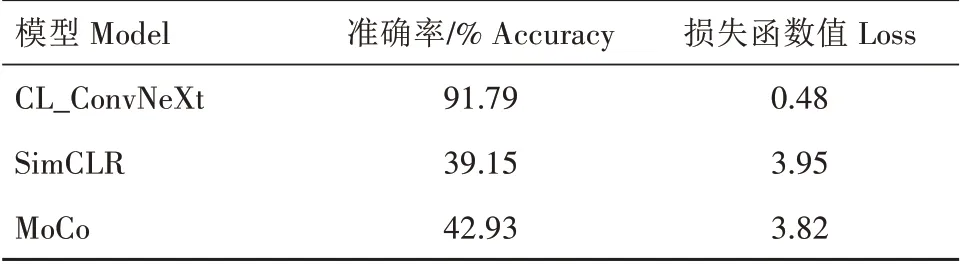
表3 不同对比学习方法训练结果对比Tab.3 Comparison of training results of different contrastive learning methods
从表3 可以看出,相比于SimCLR 和MoCo 这2种批大小设置越大效果越好的模型来说,在同样设置批大小为64 的情况下,CL_ConvNeXt 网络在识别准确率和损失函数值两方面都远远优于SimCLR 和MoCo。识别准确率比SimCLR 和MoCo 分别提升了52.64、48.86 个百分点。进一步说明CL_ConvNeXt能够降低对计算机资源的需求,更适合多肉植物图像的分类任务。
为了验证本研究所用方法在其他深度卷积网络是否同样适用,分别以ResNet50 和ResNet101 为主干网络,融入本研究提到的对比学习方法,构建了CL_ResNet50 和CL_ResNet101,训练策略同上,最终结果如表4所示。具体识别准确率随迭代次数的变化情况如图9所示。

表4 不同模型训练结果对比Tab.4 Comparison of training results of different models

图9 不同模型的识别准确率曲线Fig.9 Recognition accuracy curves of different models
从表4 可以看出,相比于原始的ResNet50 网络,CL_ResNet50 识别准确率提高了28.98 个百分点,说明本研究的方法解决多肉植物图像分类问题的效果比较明显,在深度卷积网络中有一定的适用性。采用CL_ConvNeXt 训练出来的最终准确率在CL_ResNet50 的基础上提升了6.96 个百分点,在CL_ResNet101 的基础上提升了6.15 个百分点,最终的损失函数值也比CL_ResNet101低了0.14。从图9可以看出,CL_ConvNeXt的收敛速度最快,且稳定后的准确率也是最高的,由此可见,CL_ConvNeXt训练出来的效果仍优于其他模型。
2.4 不同优化策略对比试验
对不同数据集针对性地进行训练策略优化可以在一定程度上提高模型的训练精度,得到最优模型。为了验证不同优化策略对多肉植物图像识别的影响,以CL_ConvNeXt 网络为基准模型,对网络细节进行多方面优化,比如尝试增加Dropout 模块[26]、更改优化器、更改学习率策略等。每次训练周期均为300,以验证集准确率的最大值为判断依据,得到的对比结果如表5所示。

表5 不同优化策略训练结果对比Tab.5 Comparison of training results of different optimization strategies
从表5 可以看出,在增加了Dropout 模块后,识别准确率提升了0.58 个百分点。将优化器从Adam换成AdamW 后,无论是准确率还是损失函数值都较之前有了明显的进步,说明AdamW 优化器在模型的泛化能力上优于Adam。在学习率优化策略的选择上可以看出,CosineAnnealingLR+Warmup 的效果是最优的,最终模型的识别准确率达到了91.79%。增加Dropout 模块,以AdamW 为优化器,学习率策略更新为CosineAnnealingLR+Warmup,这种组合的训练策略更适合于本模型的训练。
3 结论与讨论
本研究提出一种基于对比学习的ConvNeXt 网络CL_ConvNeXt,用于多肉植物图像的分类识别。研究了多种数据增强方法、网络结构、优化策略对模型最终结果的影响。最终CL_ConvNeXt 对190种多肉植物分类识别准确率可达91.79%。表明对比学习和卷积网络相融合的方法在解决多肉植物图像的分类识别问题时效果较好;3 种数据增强方法组合使用能够减小模型的过拟合问题;增加Dropout模块、选择AdamW 优化器、使用CosineAnnealingLR+Warmup 的学习率优化策略都能在一定程度上提升模型性能。在未来的研究中,考虑引入注意力机制来优化模型结构,提高模型处理任务的效率和准确率;考虑将CL_ConvNeXt 在其他细粒度图像分类数据集(如Oxford flower[27]、CUB200[28]、Stanford Dog[29])上进行试验,验证其在解决图像分类识别任务时是否具有通用性。
