基于PCA与深度学习的表情识别算法
2023-08-10冯开平罗立宏
区 健 冯开平 罗立宏
1(广东工业大学计算机学院 广东 广州 510006)2(广东工业大学艺术与设计学院 广东 广州 510090)
0 引 言
今天,由于技术的进步和无处不在的传播,我们大部分时间都花在了与计算机和手机的交互上。它们在我们的生活中起着至关重要的作用,并且现有的大量软件接口都是非语言的、原始的和简洁的。通过人脸表情识别期望用户的感受和情感状态可以大大改善人机交互(HCI)体验[1-2]。
在面部表情识别中,表情一般分为7类[3],包括生气、厌恶、害怕、高兴、悲伤、惊讶和中性。现在的表情识别任务集中在图像预处理、特征提取和分类三大块,从原始数据中抽离特征用于分类这一步骤有着至关重要的作用,它直接影响了表情识别的性能。传统的特征提取方法主要有局部特征二值模式(Local Binary Patterns)、主成分分析(Principal Component Analysis)、尺度不变特征变换(Scale-invarialt Feature Transform)等。Ma等[4]提出了一种基于块LGBP,以接收过完备字典。通过稀疏表示,从每个最小子块中的残差值中获取类别残差向量。通过残差向量类别中的大量最小残值来测试表情类别。蔡则苏等[5]提出了一种基于PCA的特征提取算法,通过PCA提取人脸特征并将特征加入哈希表中进行分类,对复杂数据集进行降维并揭示了数据集中某些潜在的隐含信息。传统方法大多采用手工提取,虽然具有较高的准确率,但是过程中会包含对分类没有作用的特征,或者忽略了对分类具有重大作用的特征。随着近些年来深度学习的不断发展,将卷积神经网络应用到表情识别分类的问题引发了众多学者的研究和探讨。深度学习方法与传统方法最大的不同就是深度学习将特征提取和分类两大块结合在了一起,这极大地减少了因人工干预而导致的误差,并且通过局部感知的方法提取特征可以细化提取出人工提取难以提取到的关键点和特征。Szegedy等[6]提出了GoogLeNet架构,卷积神经网络结构深度高达27层,是ILSVRC2014分类挑战赛冠军,将Top5的错误率降低至6.67%。He等[7]提出了ResNet架构,在ILSVRC2015中获得优胜,ResNet在其内部残差块使用了内部跳跃连接,缓解了在深度网络中增加深度带来的梯度消失问题。深度学习的方法取得了比传统方法更高的识别率,但也带来了一些无法忽视的问题:图像预处理过于耗时、网络深度和宽度过高导致计算复杂度过大、梯度弥散(梯度越到后面越容易消失),难以优化模型、训练数据集有限容易产生过拟合。
针对以上问题,本文提出了一种以主成分分析特征图作为输入的改进的轻量卷积神经网络结构。首先通过主成分分析方法对图像进行降维重构,摒弃了自然采集图像下出现的许多与面部表情无关的冗余信息,降低预处理成本;然后本文设计了一种轻量卷积网络结构,降低由于网络深度宽度导致的高计算成本和梯度弥散问题;最后与现有的人脸表情识别方法进行对比,在与现实环境相符合的FER2013公开数据集上进行实验。结果表明,本文方法有效地提高了人脸表情的识别率。
1 基本理论
1.1 主成分分析法
PCA通过线性变换将训练图像变为一组各维度都线性无关的数据,使得这一组数据尽可能多地反映训练图像的信息[8-9]。PCA的目标是找到数据中最主要的信息,去除噪声和冗余,并将复杂的数据降维,发掘出隐藏在复杂数据背后的简易结构。训练图像可看作一个复杂的高维数据矩阵,可用PCA对该图像进行降维重构,得出降维后的样本图像。
PCA的处理步骤如下:
1) 把每幅图像看作一个矩阵X,表达式如下:
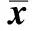
2) 求取图像样本矩阵的协方差矩阵S,如下:
3) 求协方差矩阵的特征值和特征向量:解特征方程|λ-Sr|=0或采用SVD方法(本文采用SVD),求特征值λ1≥λ2≥…≥λl以及对应的特征向量a1,a2,…,al,其中l表示特征向量的个数,协方差矩阵的特征向量表示为A=(a1,a2,…,an)。
4) 将协方差矩阵的特征向量按特征值的大小进行排列组合,并取前k个向量作为投影到k维空间的投影矩阵。
5) 投影矩阵与图像样本矩阵的点积生成最终的主成分矩阵,训练图像的主成分矩阵为ATX。
1.2 卷积神经网络
前馈式网络(Feedforward Neural Work,FNN)是一种简单的神经网络,神经元按照各层分布排列,各层神经元只和前一层的神经元相连。单通道且各层间没有反馈,是目前发展最快、应用最广的神经网络之一。卷积神经网络(Convolutional Neural Network,CNN)是一种特殊的前馈式网络,它具有深度结构并包含卷积计算,是深度学习的代表算法之一,它包含了卷积层、池化层、全连接层、输出层等多个结构。卷积神经网络通过端对端的方式,对图像进行特征提取和分类,极大减少了人工干预,适用于大规模的数据训练。以下是卷积神经网络结构详解。
1.2.1卷积层
卷积层由若干个卷积单元组成,卷积单元通过反向传播算法得到最佳化参数,用于提取特征图。将用可训练的卷积核应用到上一层的表情特征图的所有点上,通过将卷积核在输入特征图上滑动,生成经过滤波处理的特征图,并经过激活函数激活后输出给下一层。表情特征图的处理公式为:
Ci=f(Ci-1*Ki+bi)
(3)
式中:Ci为第i层输出的特征图;f为激活函数;Ki为第i层与第i-1层对应的卷积核;bi为偏置向量。
1.2.2池化层
池化层主要是对参数进行压缩,是图像的下采样层[10]。池化层一方面能对特征图进行降维,减少网络计算量,另一方面可以提取主要特征,放弃次要特征,防止网络过拟合,提高模型泛化能力。本文采用最大池化与平均池化两种方式,最大池化是选择池化区域中最大的数作为该池化区域的输出,平均池化则是对池化区域的所有数求和取平均值。池化公式为:
Ci=f(down(p(Ci-1)+bi))
(4)
式中:Ci为第i层输出的特征图;f为激活函数;p为池化方式;down为下采样函数;bi为偏置向量。
1.2.3全连接层
全连接层将自身的每一个神经元与上一层的神经元进行连接,将所有特征排列成一个向量,作为神经网络的“分类器”。基于这个特性,全连接层的参数是整个卷积神经网络最多的一层,占比高达80%以上。其计算公式为:
xout=f(xin*K+b)
(5)
式中:xin为输入的元素,xout为输出元素;f为激活函数;K为全连接层的卷积核;b为偏置向量。
1.2.4输出层
本文采用SoftMax函数进行输出层的表情分类,SoftMax函数,又称归一化函数。它是逻辑二分类器sigmoid函数的扩展,适用于多分类问题。SoftMax函数接收全连接层输出的向量作为输入,把每一维的数转换为(0,1)区间的某一实数,进行分类。对于输入图像x,其是类别i的概率公式为:
式中:p表示x是类别i的概率;w表示权重值;k表示总的类别数,k∈{0,1,2,3,4,5,6}。
2 算法描述
2.1 图像预处理
人脸表情图像在采集的过程中,会存在采光过高、背景复杂、无用冗余信息过多等问题。因为在用卷积神经网络训练之前,需要对图像进行补光、人脸定位等预处理。
2.1.1 FER2013数据集
FER2013人脸表情数据集由35 886幅人脸表情图片组成,其中,测试图包含了28 708幅图片,验证图和测试图各为3 589幅。每幅图的尺寸固定为48×48像素,且均为灰度图像。共有7种表情,分别对应0-6的数字标签,具体表情对应的标签如下:0,生气;1,厌恶;2,害怕;3,高兴;4,悲伤;5,惊讶;6,中性。该数据集的图像具有不同的角度、光照、姿势、遮挡物,并且分辨率较低,使得FER2013对比其他公开数据集数据更加齐全,同时也更加符合生活场景。图1为FER2013数据集中的7种表情图像例子。

图1 FER2013数据集的7种表情类别图例
2.1.2 JAFEE数据集
JAFEE数据集包含213幅图像,是十位日本女性的7种面部表情(与FER20213数据集中的表情标签相同),每个人每种表情大约有3到4幅图像[10]。图像源自于实验室采集,是像素为256×256的静态灰度图。图2为JAFEE数据集中的7种表情图像样例。
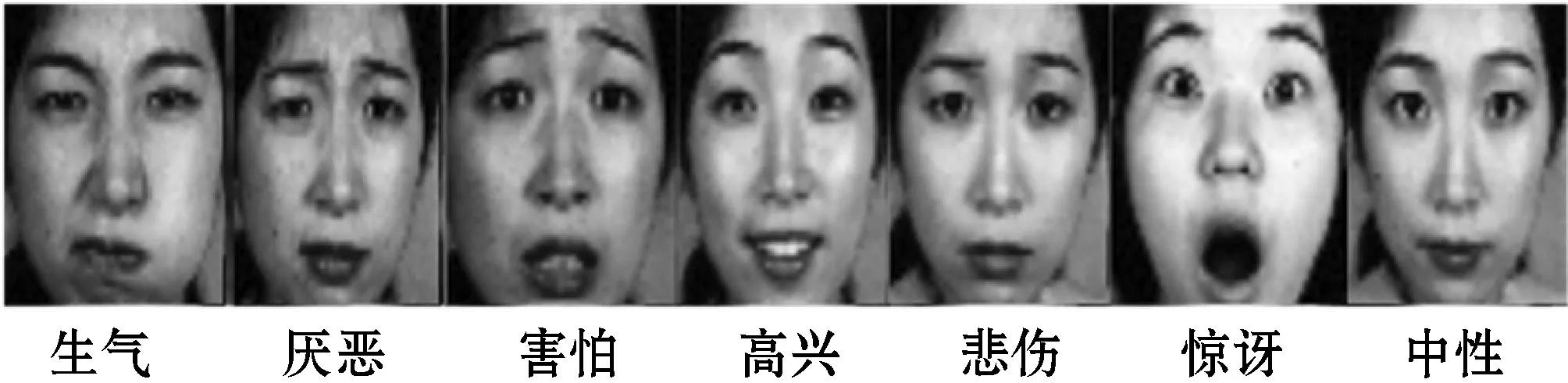
图2 JAFEE数据集的7种表情类别图例
在数据集中的预处理如下:
1) 将数据集的原始图像进行PCA降维重构,获取表情识别的关键部分:鼻子、眼睛、嘴巴。忽略掉与表情识别无关的面部区域,去除多余信息,降低模型训练成本。效果如图3所示。

图3 PCA降维重构图像
2) 数据增强。为了保证训练模型的精度,防止神经网络过拟合,加强神经网络的泛化能力,需要对数据进行数据增强处理。本文采用的数据增强方式是旋转变换、上下左右移动、随机水平翻转、倾斜、缩放的方式,将数据集图片扩充到近十倍,具体参数如表1所示。
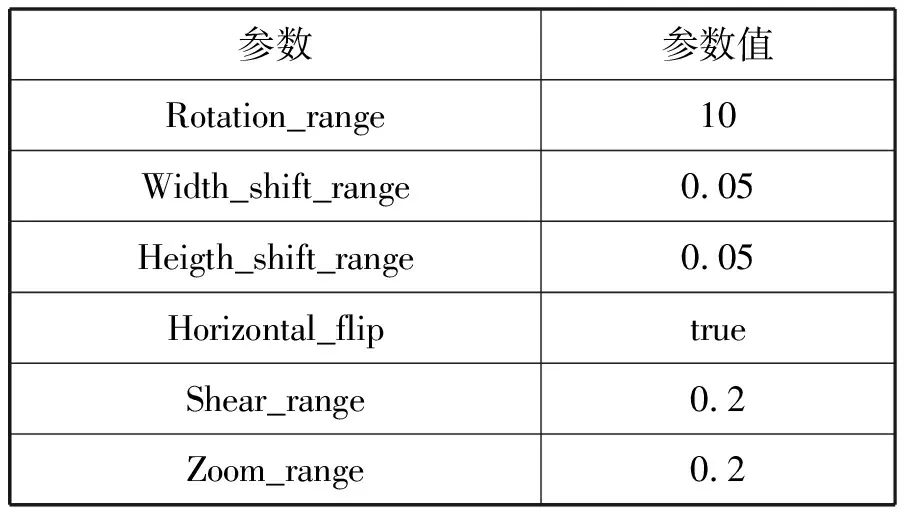
表1 数据增强参数
2.2 改进的轻量卷积神经网络架构
卢官明等[11]设计的7层CNN模型在用于人脸表情识别上要优于一般的传统方法,但识别率与其他深层的卷积模型相比依然达不到一个理想的效果,而在GoogLeNet与VGG16等分别具有27层与16层,在数据量小的数据集中会导致特征图分辨率降低,出现梯度弥散、学习特征不够鲁棒等问题,而且深度过高导致计算成本过大,实时性不足。
为此,本文提出了一种改进的轻量卷积神经模型:
1) 在输入层加一层步长为1的1×1卷积。
2) Conv2-1层和Conv2-2层的卷积核为64个,Conv2-1和Conv2-2层的卷积核尺寸为5×5;Conv3-1层和Conv3-2层的卷积核为64个,Conv3-1层和Conv3-2层层的卷积核尺寸为5×5。
3) 池化层不包含学习参数,P4层采用最大值池化(MaxPooling2D),P7层采用平均池化(AveragePooling2D),池化核大小均为(2,2),池化步长为2。
4) 在每个卷积层的后边均加入PReLU激活函数[12]。全连接层Fc1和Fc2后均添加Dropout函数,参数设置为0.5。
轻量神经网络结构如图4所示。

图4 轻量神经网络结构示意图
该网络结构一共含有9层,包括5层卷积层、2层池化层和2层全连接层,受文献[13]的启发,网络在输入层中加入一层1×1的卷积层增加非线性表示,增加网络深度,提高模型特征表达能力;该模型在初始层较大的堆叠卷积层使用5×5卷积核,在后两层堆叠卷积层使用3×3卷积核,可有效降低参数量并保证模型空间特征信息的提取能力;在堆叠卷积层中加入PReLU函数,在ReLU激活函数的基础上加入参数,参数由模型训练得出,可提高网络的非线性表征,解决梯度弥散问题,加快模型收敛速度。对最后一层卷积得出的深度卷积采用平均全局池化操作(Golbal Average Pooling),最大程度保留局部信息,替代一层1×4 096的全连接层,减少参数量,降低计算成本;剩余两层连接层神经元个数分别为2 048、1 024。全连接层中加入一层参数为0.5的Dropout层[13]。全连接层神经元经过dropout之后,一半的神经元个数置0,可有效防止过拟合现象,加快训练速度,增强神经网络模型的泛化能力,最后输入到输出层,实现人脸表情的分类。
该网络结构参数设置如表2所示。

表2 卷积神经网络结构参数
3 实验与结果
3.1 实验环境
本文方法使用硬件信息如下:GPU是NVIDA GeForce GTX960,CPU为Intel(R)Core(TM) i5-2300@2.80Hz,内存为8 GB;实验基于Python3.6.5下的TensorFlow2.0深度学习框架来进行,操作系统为Windows 10。为了保证实验的严谨性,实验采用的是十折交叉验证法,将经过扩充的公开数据集分为10份,9组作为训练集,1组作为测试集,进行10次实验,将10次实验结果取平均值。这样既保证了实验结果的有效性,也可以让每份样本都可以作为测试集和训练集,避免某些数据噪声过大而影响最终的识别效果。作为CNN中的超参数设置如表3所示。

表3 CNN超参数
3.2 实验结果与分析
经过200个epoch的训练后,计算十折交叉验证后,FER2013数据集上的准确率为69.07%,得到的识别率曲线图5所示,JAFFE数据集上的准确率为98.23%,得到的识别率曲线如图6所示。
图5 FER2013数据集的准确率曲线图

图6 JAFFE数据集的准确率曲线图
由图5、图6可以看出,经过大概40个epoch之后,模型就达到了一个比较好的识别效果。经过200个epoch之后,识别率保持一个稳定的状态,不再发生太大的波动,说明此时模型得到了充分的收敛。由图中改进CNN与轻量CNN的曲线对比可知,经过结构改进的CNN识别率上优于轻量CNN。而经过PCA和数据增强的预处理之后,本文方法识别率要高于改进的纯轻量CNN方法。
为了比较本文所提出的方法性能,与其他现有的主流模型和方法进行了对比实验。FER2013数据集的对比结果如表4所示。
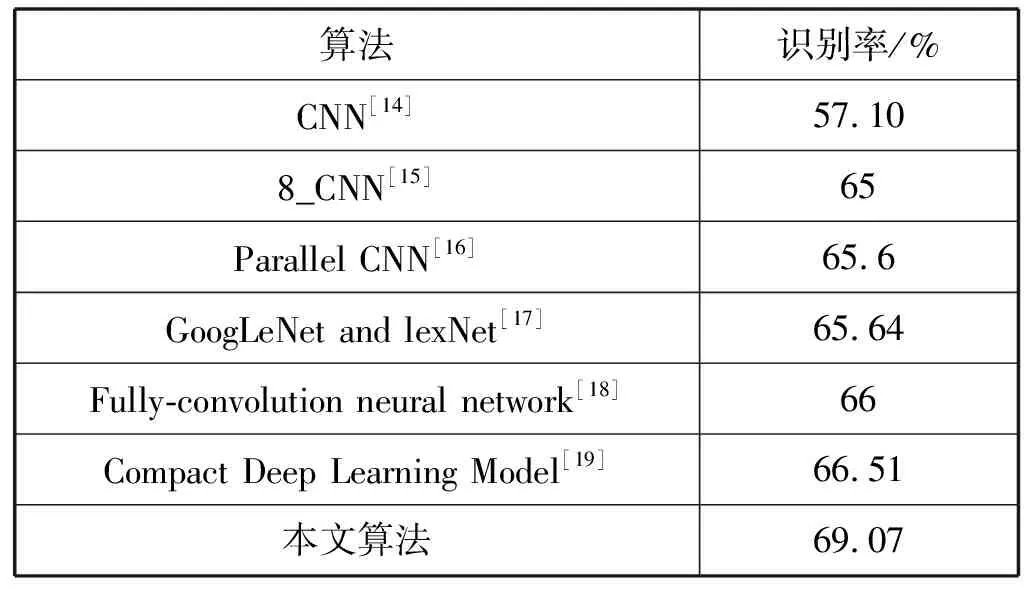
表4 不同算法在FER2013数据集的识别率结果对比
在FER2013数据集中,文献[14]采用的是类VGG结构网络,通过不断堆叠卷积层和池化层构建深度网络,但因其结构只有10层,未达到VGG-16的深度和宽度,导致难以精确地提取人脸表情特征,识别率较低。文献[15]是采用了8×8的卷积核的深度网络结构,达到了肉眼识别65±5%[20]的效果,但选用的卷积核过大导致提取空间特征信息能力下降,识别率不够理想。文献[16-18]采用的均是多网络融合的深度网络框架,与单网络相比,性能并没有提升。说明针对FER2013数据集,多网络融合并不是一个很好的选择,使用单网络反而能取得较好的识别率。文献[19]提出了一种紧凑型的深度学习框架,使用了更少的参数情况下达到了较好的识别效果,达到66.51%。
为了进一步验证模型的有效性和泛化能力,本文给出了JAFEE数据集中与其他现有模型的对比,如表5所示。

表5 不同算法在JAFFE数据集的识别率结果对比
在JAFFE数据集中,主流方法文献中大多采用的是特征融合的深度网络结构,文献[22]采用的是多分辨率特征融合的方法,文献[23]采用的是局部特征融合的方法,文献[24]采用的是LBP特征与CNN卷积层融合的方法,文献[23]和文献[24]的方法原理上相似,均为通过摈弃与表情特征无关的一些特征向量以达到提高表情识别率的目的,而通过调整分辨率的方法则无法去除这些冗余的信息,因此文献[23]和文献[24]的识别率提升明显,达到了97%。从表4、表5的识别率对比可以看出,本文提出的通过PCA降维重构获得主成分特征图像作为输入,并通过轻量CNN训练实现特征提取与分类的表情识别算法,具有更好的表情识别能力,一定程度上提高了表情识别率,在FER2013数据集和JAFFE数据集上达到了69.07%和98.23%的识别率。表6、表7分别为本文方法在FER2013数据集和JAFFE数据集上的混淆矩阵。
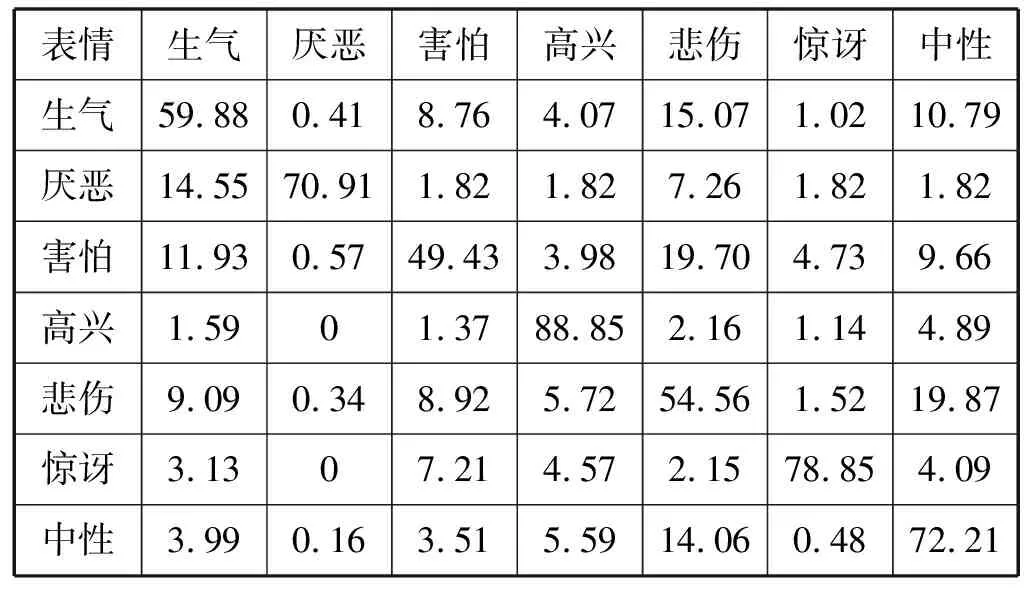
表6 FER2013数据集混淆矩阵

表7 JAFFE数据集混淆矩阵
表6、表7的混淆矩阵显示了害怕、生气、悲伤这三类表情的识别率明显比其他四类表情低。轻微的生气脸部会有轻微变动,无表情易于中性混淆;过分的生气则会伴随嘴巴张大、眉毛紧锁和鼻子皱起等现象,与害怕和悲伤产生混淆。而害怕与悲伤最容易混淆,亦是两表情中具有相同的眉毛特性、嘴角向两边拉伸以及眼睛紧紧闭起等特征。高兴和惊讶最具识别率是因为它们各自具有独特的标识:高兴表情大部分嘴角翘起,眼睑收缩;惊讶表情则会眼睛睁大,嘴巴张开。由于JAFFE数据集是在实验室的环境中进行,所以高兴、惊讶这两类非常具有辨识度的表情达到了最高识别率,而FER2013数据集是竞赛数据集,数据来源复杂,并不能达到实验数据集的精度,而且数据集中一些复杂的表情图像亦带来了一些混淆,如惊讶般的高兴、害怕般的厌恶等,增大了表情识别的难度。
4 结 语
本文方法在图像预处理上采用了PCA降维重构法,去除与表情无关的冗余特征,降低了深度模型在特征提取上的预处理时间成本,并用数据增强的方法扩充了数据集,加强了模型的泛化能力并防止过拟合。设计了改进的轻量级神经网络,降低深度模型的深度和宽度,在FER2013、JAFEE公开数据集上进行了实验,分别取得了69.07%和98.23%的识别率,一定程度上提高了表情识别率,并与其他主流方法进行对比,证明了其有效性。后续将用本方法在不同数据集中应用,并进一步调整网络的内部框架和参数,提高神经网络的泛化能力。
