基于结构和语义的代码分类以及聚类方法
2023-08-10金岩磊秦冠军史志成
金岩磊 秦冠军 姜 凯 甘 迪 史志成 周 宇*
1(南京南瑞继保电气有限公司 江苏 南京 211106) 2(南京航空航天大学计算机科学与技术学院 江苏 南京 211106)
0 引 言
如何利用深度学习对代码进行高质量的特征提取是近几年研究的一个热点问题。代码语言与自然语言有很多相似的特征,都是由单词组成的,都可以生成AST的树形结构,二者最大的不同就是代码元素之间的依赖关系更强,且代码段的长度远远超过自然语句的长度,因此如何提取代码中的结构信息一直是软件工程领域研究的热点和难点。Tai等[1]提出了TreeLSTM模型,该模型的核心思想是通过将LSTM[2]的链状结构拓展为树状结构来提取自然语言的结构信息,软件工程领域内的很多模型将Tree-LSTM作为它们模型的一个子模块,例如Wei等[3]就将Tree-LSTM作为克隆检测模型CDLH的子模块来协助提取代码的结构信息,Wan等[4]则借助Tree-LSTM。Alon等[5-6]通过提取AST的路径,利用路径的中间节点提取代码的结构信息,路径的两端节点提取代码的语义信息,以此进行方法名生成、变量名预测工作。Ou等[7]、Allamanis等[8]则使用图网络对代码进行特征提取。
本文将基于卷积和循环神经网络生成高质量的代码向量完成代码分类以及聚类任务。该任务的主要目的是根据代码的结构和语义信息给出对应的代码标记。自动代码分类能够推动软件工程领域内众多任务的发展,如程序理解(program comprehension)[9]、概念定位(concept location)[10]、代码剽窃检测(code plagiarism detection)[11]、恶意软件检测(malware detection)等。代码分类的标签可以看作代码内部含义的一个总结,该标签能够协助后续代码模块化、分析、重用等工作的进行。当下代码分类的模型主要以深度学习模型为主,例如:Zhang等[12]设计的基于递归以及循环神经网络的ASTNN模型;Mou等[13]构建的基于自定义树卷积的TBCNN模型。除了借助AST提取代码信息之外,Ben-Num等[14]则借助LLVM获得代码的中间表示并结合循环神经网络对代码进行特征提取。通过中间表示可以生成代码的程序依赖图。然而中间表示一个明显的弊端就是无法获得变量最原始定义的标识符,这类模型在强化结构信息提取的同时却丢失了代码的语义信息。该领域使用最广泛的数据集就是Mou等[13]整理的104代码分类数据集,该数据集共有104个类,每个类别下有500条代码。当下在该数据集取得最高分类精度的就是ASTNN模型,分类的准确率达到98.2%。本文在后面的实验也将与ASTNN模型进行对比。
与很多学者的研究方法类似,本文也借助AST来提取代码的特征,通过对Zhang等提出的ASTNN模型以及Mou等提出的TBCNN模型进行结合,将ASTNN中的递归神经网络替换成TBCNN中自定义的速度更快的卷积网络,构建了一个基于卷积和循环神经网络的深度学习模型CVRNN,并基于该模型对代码分类展开研究。该模型在与ASTNN模型分类准确率十分接近的情况下,速度却是该模型的1.55倍。在我们之前相似代码搜索任务上[15]该模型也得到了成功的应用,此模型是原模型改进后的版本。
在使用分类训练好的CVRNN模型对代码进行编码,并将得到的代码向量进行降维打印后发现,代码功能越相似,对应代码向量之间的几何距离就越短。由于K-means的损失函数是样本与其所属类的中心之间的距离总和,具体距离的定义是欧氏距离的平方。因此,本文还基于CVRNN生成的代码向量利用K-means进行了聚类实验,聚类效果对比TBCNN有明显的优势,除了FMI指标与ASTNN持平,其他指标均高于ASTNN。
电力监控系统是整个电力系统运转的核心部分,为输电、变电、配电提供基础性的服务,若其因受到恶意代码攻击进而导致系统瘫痪将会造成巨大的经济损失。随着计算机技术的飞速进步,电力监控系统面临恶意代码攻击的问题愈发严峻。在该领域主要使用可信软件白名单对恶意代码进行防御[16],其中白名单维护所有可信软件的版本号、Hash指纹等相关的参数,通过比对这些参数是否匹配判断该软件是否是可信软件。很明显该方式是一个完全静态的方法,一方面,这个白名单很难进行实时维护,另一方面,将导致所有未记录在名单上的软件都给拦截掉。本文的工作是解决该问题的一个探索性工作,未来我们将试图将代码压缩成代码向量,首先使用白名单进行拦截,若在名单内,则可直接运行,否则通过计算代码向量之间的距离并设置一个阈值来判断该代码是否是恶意代码,使系统更加智能化,使得未在白名单中出现的非恶意代码也能够正常运行。矩阵的运算速度极快,经我们测试,即使一个千万级别的代码数据库,也能在毫秒级别完成计算,在保证系统正常运行的同时也保证系统的运行效率。
1 方法介绍
代码向量是本文进行分类和聚类任务的基石,代码向量具体的生成过程如图1所示。首先使用srcml工具生成代码的AST,然后通过先序遍历获得AST节点的展开序列,根据该序列应用Word2vec生成AST节点的词向量并存入到一个矩阵当中,训练得到的词向量能够将节点之间的某些潜藏关系编码进词向量中,如“if”“while”“for”表示程序的控制流关系,编码后得到的这三个词向量在向量空间上也是彼此邻近的。为了解决因AST规模过于庞大而引发的梯度消失问题,本文并没有简单地将完整的AST作为模型的输入,而是将AST切割成由循环以及条件子树构成的序列。图2给出了具体的切割样例,每个代码块都与一棵AST相对应,①号代码块将被切分成②③④⑤四个部分,其中②号代码块主要包含不属于条件判断以及循环执行的剩余代码,例如异常抛出语句没有包含在任何循环和条件判断的代码块中,因此将其放入到第一个代码块中,剩余代码块均属于条件判断或者循环执行,它们AST对应的根节点一定在{“if”,”while”,“for”}集合当中。由此可以得到一个子树序列,这个序列可以看作是源代码的控制流。通过之前得到的词向量矩阵,可以将这些子树节点由原先的字符串形式映射成词向量的形式,然后将该子树序列输入到我们设计的CVRNN(Convolutional and Recurrent Neural Network)模型中得到代码的向量表示。
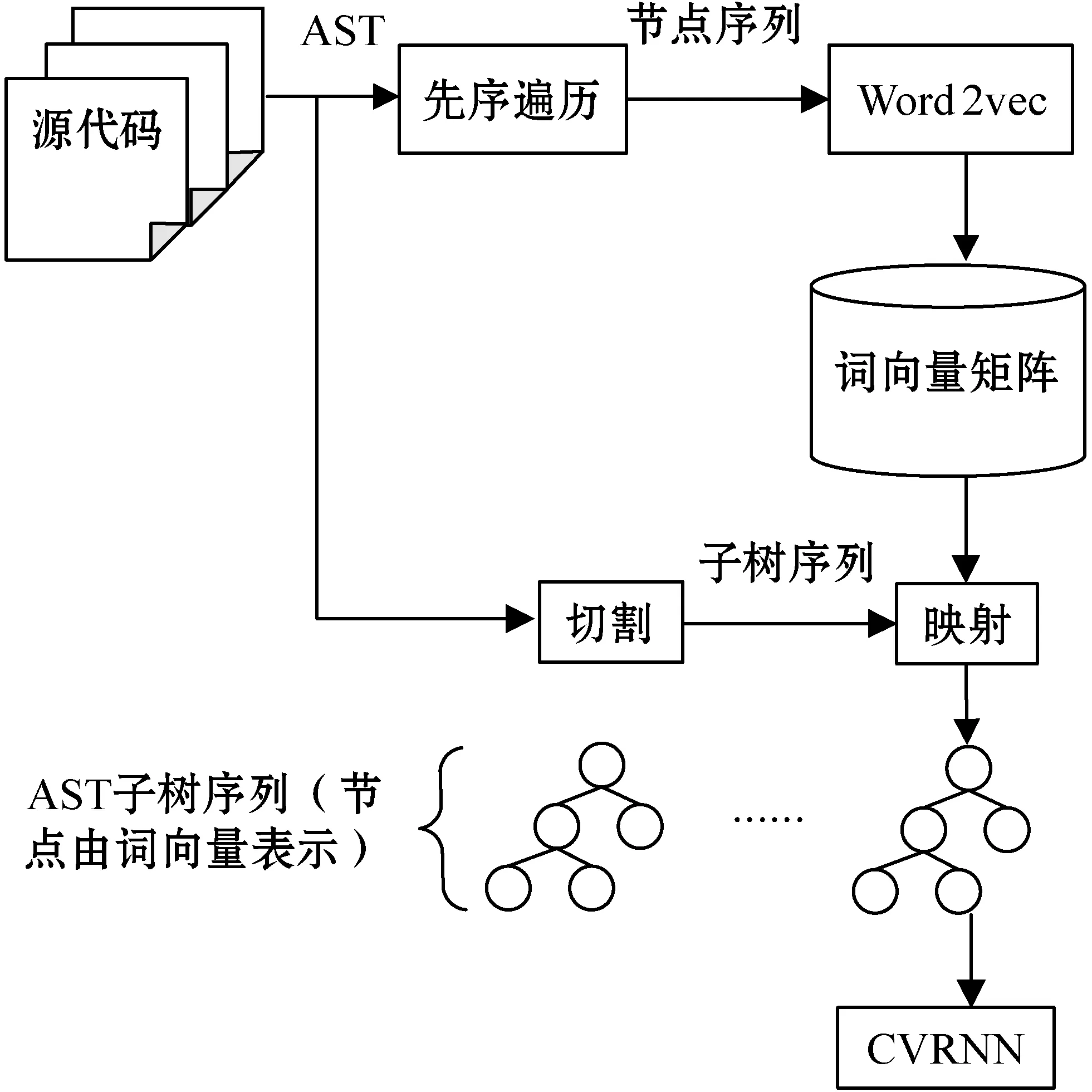
图1 生成代码向量流程

图2 切割样例
图3展示了CVRNN模型的执行过程,该模型使用TBCNN对输入到模型中的AST进行编码,得到每棵AST的向量表示。图4展示了TBCNN树卷积的过程。该模型设置了一个固定深度的滑动窗口,自上而下地遍历AST中的所有节点,图4中滑动窗口的深度是2,滑动窗口内的节点将被编码成一个向量,如图4左边①号三角形区域中的节点将被编码进右边所标注的①号向量,②号三角形区域同理。具体的编码公式如式(1)-式(5)所示。
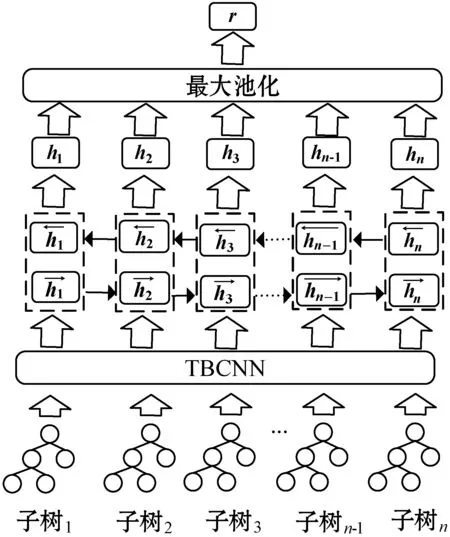
图3 CVRNN模型

图4 TBCNN树卷积


经过树卷积之后,原先AST中的特征将被提取到新生成的AST中,新AST中每个节点向量包含了一个区域内的节点信息,该AST与原AST有相同的结构,之后再经过动态池化[16]以及一层全连接神经网络将AST转化为一个固定长度的代码向量,因此子树序列将转化成一个向量序列[v1,v2,…,vn],在TBCNN之上再叠加一层双向循环神经网络(Bidirectional Recurrent Neural Network,BiRNN)以提取代码块之间的序列信息。与单向RNN不同的是,BiRNN将从过去和未来两个时间方向对当前时间步进行编码,因此会综合考虑代码上文和下文的信息。BiRNN内部神经元选取的是LSTM,相对于GRU[17],LSTM多了一个记忆单元,能够更好地保存过去的时间信息以缓解长期依赖导致的梯度消失问题,最终每个时间步的输出向量是两个时间方向隐层单元拼接得到的向量,例如时间步t最终的输出向量可以使用以下公式得出:
将每个时间步所生成的代码向量ht都存放到矩阵中,然后使用最大池化提取每个特征维度的最大值作为该维度上的值,将矩阵压缩成一个代码向量。最大池化可结合图5进行理解,其中有阴影的圆圈表示这个维度上的最大值,空白圆圈则表示非最大值,依次选取当前维度的最大值作为代码向量在该维度的值。
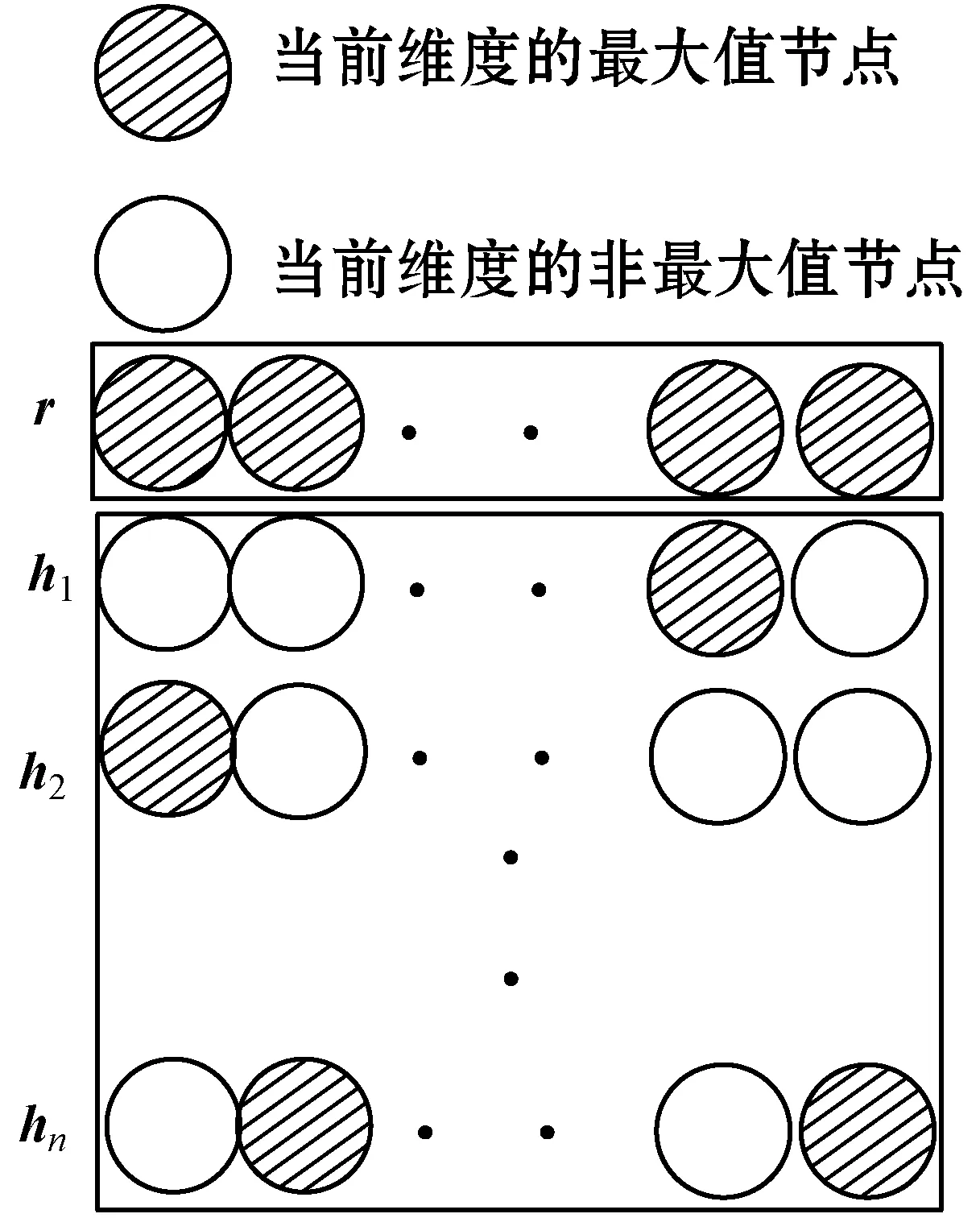
图5 最大池化
2 实验验证
2.1 数据集
代码分类以及聚类均使用的是Mou等[13]公开的104代码分类数据集。表1列出了使用叶子节点和不使用叶子节点的情况下,AST节点数目以及深度的最大值和平均值。从统计信息也可以看出原始的AST的结构十分庞大,若不对其进行切割而直接对整棵树进行提取必然会影响代码特征提取的效果。

表1 数据集统计信息
2.2 评估指标
2.2.1代码分类指标
Accuracy准确率,简称ACC:
式中:k表示代码类别的数目,在该任务中,值为104;nTP,i表示第i个类别被正确分类的数目;n表示样本总量。
2.2.2代码聚类度量指标
(1) Jaccard系数,简称JC:
(2) FM指数,简称FMI:
(3) ACC。计算公式与代码分类准确率公式相同。在计算该指标的时候,聚类标签要与真实标签相统一,因此实验过程中还增加了一个标签映射的过程,这里映射方法使用的是Kuhn-Munkres算法。
2.3 CVRNN参数设置以及实验平台
该模型核心配置参数如表2所示,使用叶子节点和不使用叶子节点在参数配置上唯一的不同就是词向量的维度。因为不使用叶子节点所需要训练的词汇表只有60,而使用叶子节点词汇表扩充至6 156。为了降低频词对模型的影响,具体的实验过程中只选取了词频大于等于5的单词纳入词汇表。在分类模型的训练过程中,以交叉熵作为训练的损失函数并选取Adam作为优化器。仿照Mou等[13]的工作,该模型同样没有设置正则化项来降低模型过拟合的风险。深度学习框架使用的是TensorFlow 1.14,操作系统是Ubuntu 16.04,GPU型号是RTX2060,CPU型号是AMD Ryzen 7 2700。

表2 模型参数
2.4 任 务
2.4.1代码分类
该实验将104数据集按3∶1∶1划分训练集、验证集和测试集,对比模型选取的是Ben-Num等[14]的inst2vec模型、Zhang等[12]的ASTNN模型,具体的实验结果如表3所示。因为inst2vec模型并没有使用AST,所以表3直接展示了原论文中的实验结果。ASTNN原文中使用的AST生成工具是javalang,为了对比的公平性,表3中展示的结果是使用srcml作为AST生成工具重新训练得到的实验结果。两个模型均训练了30轮,表3和表5分别展示了实验结果和训练时间。可以看出,ASTNN与CVRNN分类的准确率很接近,而CVRNN的运行速度大约是其的1.55倍,此外还进行了另一个与ASTNN的对比实验,不使用AST的叶子节点,仅使用srcml符号表中定义的节点对代码进行分类,表4和表5分别展示了实验结果和训练时间。CVRNN在速度和准确率上都要优于ASTNN模型。

表3 代码分类测试集准确率

表4 不使用叶子节点测试集代码分类的准确率

表5 30轮的训练时间
使用已训练的CVRNN对测试集中的代码进行编码生成代码向量(对应图3中的r向量)并使用TSNE进行降维打印,打印结果如图6所示,相同灰度的表示属于同一个类。可以看出,属于同种类别的代码形成一个簇,功能相近的代码经过CVRNN编码后得到的代码向量之间的几何距离也是彼此临近的。

图6 降维后测试集代码向量
2.4.2代码聚类
上面的代码分类任务中,尽管测试集中的代码与训练集样本不重叠,然而两个数据集代码的类别相同,在实际的代码分类场景下,测试集代码的类别大部分与训练集不同,为了探究CVRNN模型是否能够对训练过程中未出现过类别的代码进行正确分类,我们借助K-means设计了代码聚类实验,并根据代码的真实标签对聚类效果进行度量。
聚类模型整体架构如图7所示。首先将104个类别的代码数据库分为两部分,其中84个类别作为训练集,剩下的20个类别作为测试集。首先使用84个类别的代码数据库对CVRNN模型进行训练,然后应用训练好的CVRNN对20个类别构成的代码库进行编码得到的代码向量再使用TSNE进行降维,将降维后的代码向量输入到K-means中进行聚类,由此可以得到每个代码的预测标记。计算JC和FMI度量指标不需要预测标记和真实标记之间实现统一,因此可以直接计算出这两个度量指标的值。由于准确率ACC要统一真实标签和预测标签,例如得到的预测进行聚类,聚类的数目设为20。标签是(0,0,1,2,2,2,2,2),而真实标签是(1,1,2,0,0,0,2,0),就要将预测标签0映射为1,标签1映射为2,标签2映射为0,再计算准确率。这里使用的是Kuhn-Munkres算法完成标签的映射。具体的做法是将预测标签与真实标签进行组合得到一个矩阵,这里测试集共有20类,因此可以得到一个20×20的矩阵,矩阵中的每个值表示该标签组合情况下数据的重合数量,例如下面得到的标签混合矩阵:
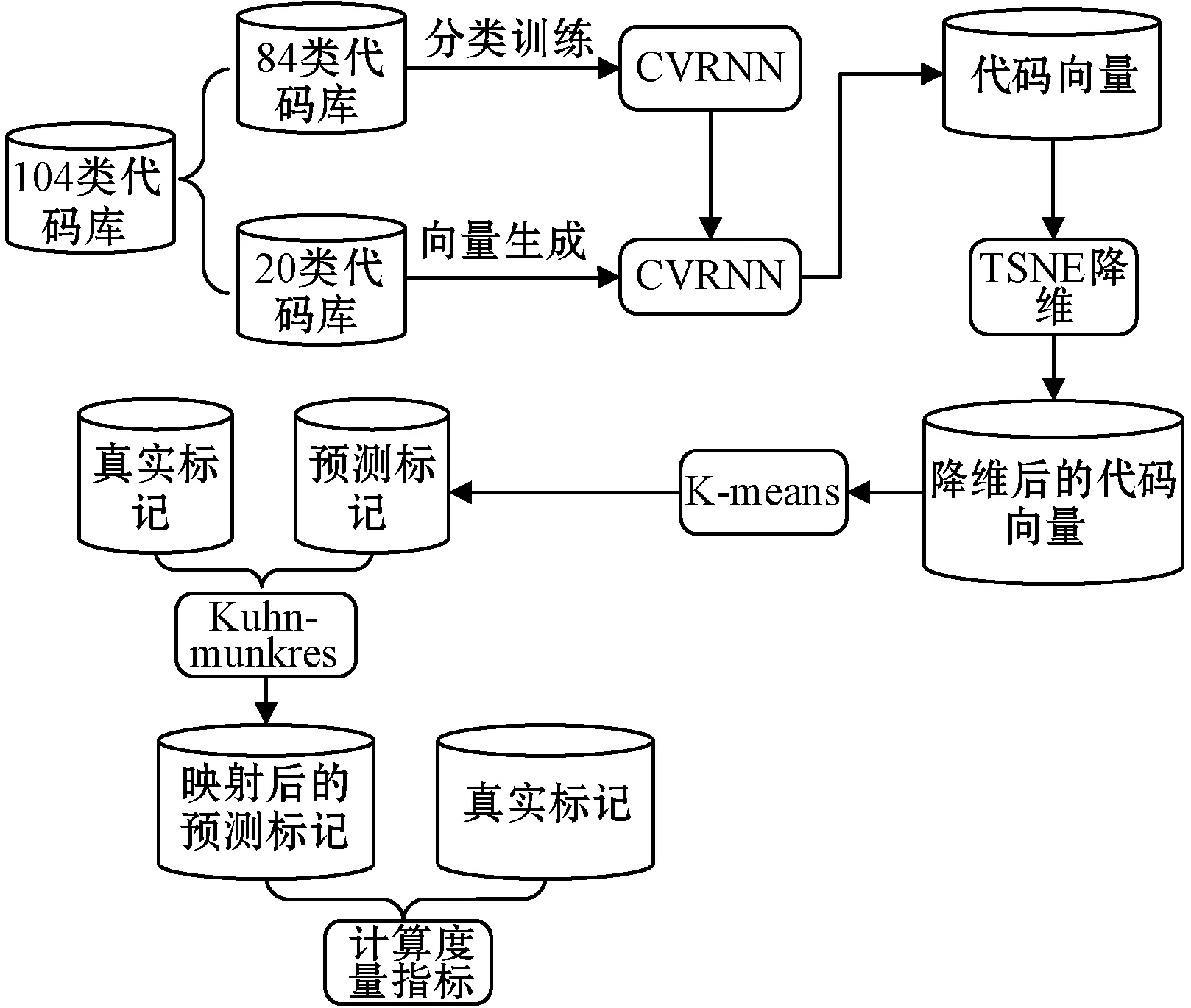
图7 聚类整体架构
第1行第2列数字为380,表示真实标签为1与预测标签为2的样本重合数为380,然后基于该矩阵计算最低代价的映射。将预测标签与真实标签实现统一之后,便可以计算准确率的值。对比模型选取的依然是TBCNN和ASTNN,因为K-means聚类度量指标可能会出现4到5百分点的波动,因此最终取10次实验结果的平均值来避免偶然性,结果如表6所示。可以看出CVRNN在3个模型的对比过程中各项度量指标均占有优势。图8给出了CVRNN模型聚类后的区域划分,同一灰度的点表示对应的代码向量属于同一个类。可以看出同一个区域下的点的灰度大致相同。

表6 聚类结果(%)

图8 CVRNN 聚类效果
3 结 语
本文通过卷积以及循环神经网络对代码的结构以及语义信息进行提取来获得高质量的代码向量并基于此对代码分类以及聚类展开研究,中间还应用Word2vec预训练AST节点的词向量来增强其初始语义。在代码分类以及聚类任务上对比当下最前沿的几个模型占有优势。实验选取的数据集是该领域内公开的标准数据集,代码也在GitHub上开源,方便后续工作的复现参考。因为该研究涉及的实验所采用的数据均来源于Mou等[13]提供的104代码分类数据集,然而该数据集经过精细化的人工预处理,数据集的噪声很少,而现实环境中很难有如此良好的数据集。因此在后面的工作中,我们还将对包含众多噪音的数据集展开研究,提高模型的鲁棒性。此外,该模型只在C/C++语言上进行了测试,未来还将在其他语言上进行尝试。当下不少的研究还制定了一系列启发式规则将AST由原来的树形结构转化成具有更强表达能力的图的结构,未来我们也将在这一方向进行深入的探索,根据AST的树形结构,进一步挖掘代码元素之间的依赖关系,将原来的树形结构拓展为图形结构,并设计构建图神经网络对代码的特征进行更深入的提取,将更多的代码特征编码进生成的代码向量中。
未来将对电力监控领域内的源代码以及常见的恶意代码进行分析,使得模型更适合该领域内代码的特征,生成能够提取该领域内代码特征的代码向量,在保证电力系统稳定运行的前提下,实现对损害电力系统的恶意代码进行有效拦截。
