基于图模型和注意力机制的车辆轨迹预测方法
2023-08-08连静丁荣琪李琳辉王雪成周雅夫
连静, 丁荣琪, 李琳辉, 王雪成, 周雅夫
(1.大连理工大学 工业装备结构分析国家重点实验室, 辽宁 大连 116024; 2.大连理工大学 汽车工程学院, 辽宁 大连 116024)
0 引言
由于交通环境中的复杂交互行为,导致车辆未来轨迹具有高动态性、随机性的特点,使得轨迹预测问题充满挑战。轨迹预测作为自动驾驶系统中承上启下的重要环节,对车辆合理决策、安全行驶具有重要意义。因此,车辆轨迹预测方法研究成为自动驾驶领域探索的一个重要方向[1]。预测方法通常由场景建模、特征提取融合和轨迹估计三部分组成,其中场景建模和特征提取融合对于提高预测轨迹精度具有重要作用[2]。
场景建模方法可以分为两类:一类将地图语义信息渲染成栅格化地图,如CoverNet[3]和MultiPath[4]等方法,将道路元素和车辆观测轨迹分别渲染成不同颜色和形状的掩膜,使图片同时包含环境信息和车辆交互信息。这类方法极大地降低了场景建模的复杂度,但存在栅格化过程中部分有效信息丢失和栅格图感受野有限等问题[5]。另一类是基于图论的场景建模方法,例如LaneRCNN[6]和LaneGCN[7]等方法,将有向无环图用于表示高精度地图中的车道连接关系[8],增强网络对复杂拓扑特征的提取能力。此外,Trajectron++[9]还将图模型拓展到车辆交互,实现了动态场景的图模型表示。这类方法能实现部分场景的准确建模,可有效扩展地图感受野,实现对数据长距离依赖关系的高效提取。但上述方法均是从单一角度对场景建模,未同时涵盖动态和静态特征。为实现交通场景的完整描述,本文方法分别利用车道图和车交互图对交通场景建模,从数据角度确保场景特征的完整。
对应于上述两种场景建模方法,代表性特征提取融合方法分别是图像卷积和注意力机制。对于图像卷积,常被用来隐式提取车道拓扑结构和车辆间交互。栅格化建模方法MultiPath[4]和HOME[10]利用卷积神经网络完成车辆-环境特征交互融合。这种方式可以显著减少参数量和计算量,且由于其参数共享的特性,对特征有一定的记忆性[11],但作为一种隐式的特征提取方法,缺乏可解释性。对于注意力机制[12],则被用来显式完成中间特征的交互融合。Mercat等[13]将多头注意力中的多头用来表示场景中多种可能的交互方式;曾伟良等[14]将时空图注意力应用于交叉路口的车辆轨迹预测。但这些方法仅使用了一种注意力机制,为充分发挥其优势,本文除利用多头交叉注意力[13]模拟环境-车辆特征的多种交互可能外,还在车辆交互提取阶段利用自注意力机制,根据信息重要程度为特征分配不同注意力权重,以有效克服循环神经网络的部分缺点,提高特征质量,增加模型可解释性。
基于以上分析,本文从场景建模和特征融合两个角度入手,提出一种基于图模型和注意力机制的多模态轨迹预测方法。与现有工作相比,本文的主要贡献包括:1)采用基于图模型的场景建模方法,同时对交通场景静态环境和动态交互进行建模,实现场景信息的完整表达;2)采用多种注意力机制完成车辆交互特征的提取和交通场景中静态信息与动态信息的高效融合,增加模型的可解释性。在Argoverse轨迹预测数据集上进行测试,实验结果表明,相比于当前主流方法,预测指标有不同程度的提高。
1 预测模型构建
1.1 轨迹预测问题描述
车辆轨迹预测,即根据被预测车辆观测信息和环境信息来估计未来一段时间内的轨迹。输入包括过去时间段L内,车辆的观测轨迹Pobs={(xt-L,yt-L),…,(xt,yt)}和观测状态Sobs={(vt-L,at-L,ht-L),…,(vt,at,ht)},其中(x,y)表示俯视图中车辆中心坐标,(v,a,h)分别表示车辆的速度、加速度和朝向角度,下标表示车辆的观测时刻。此外,地图信息对实现精确的轨迹预测同样重要[4-5]。道路的拓扑结构决定着车辆未来的可能行驶方向,车道的走向和红绿灯信息影响着车辆的未来轨迹分布。因此,轨迹预测输入还包括高精度地图信息,其中包含由车道拓扑关系、中心线坐标序列组成的几何信息和由红绿灯状态、车道类型等组成的语义信息。

1.2 轨迹预测模型
图1为本文预测模型,按照编码-交互-解码结构设计,分为三部分:特征提取、特征融合和轨迹生成。模型输入包括包含地图信息的车道图和包含观测轨迹及车辆间交互关系的车交互图;通过车道图卷积操作提取地图特征,通对车交互图节点进行累加获得聚合特征,并由聚合特征进行自注意力加权获取车辆交互信息;然后利用堆叠的注意力模块,即车辆交互信息对地图特征进行注意力加权(车辆对车道注意力,Vehicle to Lane Attention,V2L),再由加权的地图特征对车辆交互信息进行注意力筛选(车道对车辆注意力,Lane to Vehicle Attention,L2V),得出融合地图信息与交互信息的编码特征;最终通过轨迹生成模块实现对交互特征的解码,生成预测轨迹及对应置信度评分。

图1 预测模型总体结构
2 交通场景建模
2.1 车道图构建
所用地图数据包含多组车道及对应的连接关系。每条车道由多个分段对应中心线组成,中心线是俯视图车道中心的位置坐标序列。对于车道连接关系,车辆不违反交通规则能够直接到达的车道分段则视为相互连通。
类似于LaneGCN[7],采用车道图来表示地图数据,如图2左下图所示,圆点表示图节点,箭头代表车道分段的连接关系。组成一条车道的每个分段看作一个图节点。对预测场景,首先获得与预测车辆相关的车道,即以当前时刻车辆位置为中心,沿车道方向划定矩形边界框,对框内与被预测车辆当前所处车道相互连通的车道进行采集,以减少计算量,提高预测速度。综合考虑预测时长和轨迹长度,边界框长宽均取100 m。

图2 车道图及车交互图构建示意图
将采集到的车道转换成有向图G(v,{pre,suc,left,right}),其中v表示车道段,即图中节点;道路的拓扑结构通过不同边的连接关系来表示,分别是前续(pre)、后继(suc)、左邻(left)和右邻(right),车道节点间邻接关系代表类型的边。此后,将使用车道节点来替代车道段的说法。每个车道节点嵌入信息包含语义信息和几何信息,语义信息由独热向量表示,代表该段车道是否为转弯车道,当前是否由红灯控制;几何信息包括该段车道的中心序列。
2.2 车交互图构建
将当前的交通场景中车辆交互关系抽象成一个时空图G(V,E),其中,节点V表示不同车辆,图边E表示不同车辆之间的交互行为,如图2右下图所示,圆点表示车辆节点,箭头表示车辆之间的交互行为。判断车辆之间是否会有交互行为,依据是当前时刻两车之间的欧式距离,若距离小于某一阈值d(本文取d=40 m),则认为车辆之间会有交互行为产生,在图中表现为边连接。每个节点嵌入信息包含观测轨迹信息Pobs和状态信息Sobs。此处采用有向图来对交通场景进行建模,相比于无向图[15-16],有向图更能够体现出交通场景中车辆之间不对称的影响[9]。
3 网络结构设计
3.1 特征提取
对车道图采用车道卷积操作[7]进行地图特征提取。当车道图给定时,首先对节点信息进行编码。考虑到节点的形状特性(大小和方向)和位置特性(中心坐标),通过下式进行特征提取,得到表征该节点的特征向量为
(1)

(2)
式中:F0和Fr分别表示预测车辆当前所处车道节点及其邻接节点特征,r表示节点之间的邻接关系;W0表示可训练的权重矩阵;A表示节点邻接矩阵;c为超参数,表示膨胀大小。当r∈{pre,suc}时c∈{1,2,4,16,32},当r∈{left,right}时取c=1;即膨胀卷积操作只对当前节点的前续和后继节点,因为车道的长距离依赖通常只是沿车道方向发生。
车道图特征提取模块基于上述车道图卷积操作。由车道图卷积层和线性连接层组成的残差块,经过4次堆叠,输出特征通道数为128的车道图特征向量Fveh。
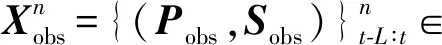
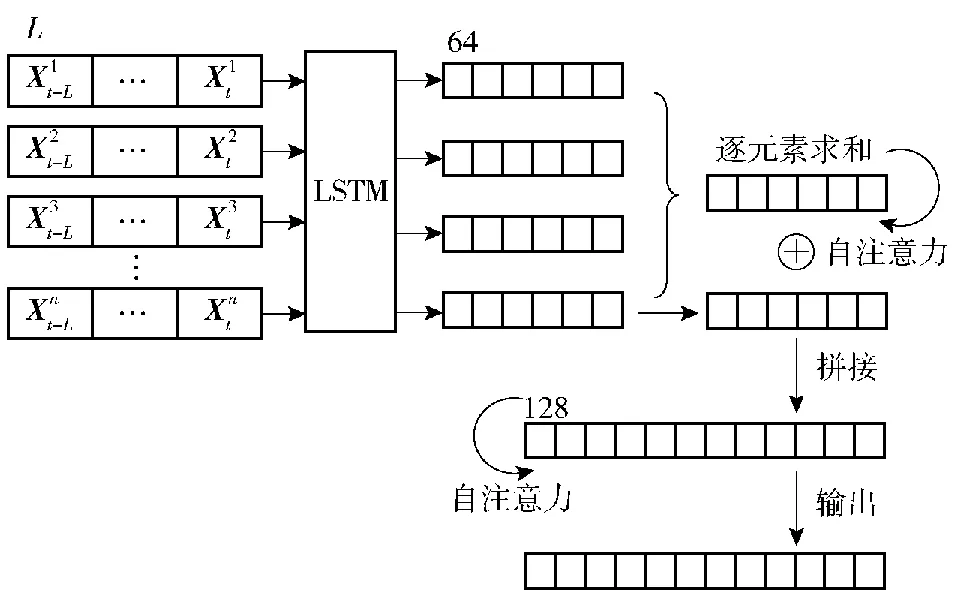
图3 车辆交互特征融合结构示意图
(3)
按照节点间连接关系,将所有节点特征向量进行逐元素的叠加求和,得到节点聚合特征Hn。特征聚合方式选择叠加求和而不是拼接[5],是为了利用确定的网络结构来处理图中节点数量随场景不同而变化的问题,而且能够保存节点数量信息[17-18]。由于自注意力机制能减少对外部信息的依赖,擅长捕捉数据内部相关性[19-20],将聚合特征由如下自注意力网络进行交互建模,得到表征车辆相互影响的特征。
(4)
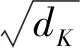
3.2 特征融合
在轨迹预测任务中,输入信息包含了时变的车辆状态轨迹信息以及结构复杂的地图信息,此处采用堆叠的多头注意力机制,使生成预测轨迹的特征向量能够专注于最重要的特征[21]。该模块受人类驾驶习惯启发:当车辆在道路中行驶时,驾驶员首先关注的是道路的拓扑结构,因为这决定着驾驶员可能的行驶方向,然后根据周围交通环境,如与周围车辆的交互,确定具体的路径。
模块中车辆对车道注意力通过车交互图特征对车道图特征进行注意力筛选,将交通信息引入道路特征;车道对车辆注意力通过隐含交通信息的车道图向量对车交互图特征进行注意力编码,完成地图信息与车辆交互信息的融合。两部分拥有相同的结构,但不共享参数。每个部分均包含两个残差块,每块中包含一个多头注意力层、一个全连接层和一个残差连接,结构如图4所示。

图4 车辆对车道注意力部分(V2L)结构示意图
以车辆对车道注意力为例,输入包括车辆交互特征向量Fveh和车道图特征向量Flane。为实现车辆对车道注意力,即车交互图特征对车道图特征进行注意力加权编码,将车辆信息引入道路特征;参照式(4)使用Fveh计算Qi,使用Flane计算Ki、Vi。特征编码过程如式(5)所示。
(5)
式中:Hi表示第i个头所表示的车道图特征;F′lane表示经全连接融合后的车道图特征向量。由于F′lane中包含了观测轨迹、状态和环境等多种信息,需要足够的维度来表示,参考文献[13]将特征方向上的通道数定为128。再与Flane做残差连接并归一化,得出筛选后的车道图特征。
3.3 轨迹生成
车辆未来轨迹天然就是多模态的[1],首先,车辆行驶的意图会有多种可能,表现为多个可能的目的地;其次,即使同一目的地也会有不同的到达路径。对于给出的多条预测轨迹,根据置信度评分获取最大概率预测轨迹。预测轨迹生成模块以特征融合模块的输出,即车交互图特征向量I作为输入,得到k条(本文k=6)多模态预测轨迹及其对应置信度评分。该模块一共两个分支,回归分支负责生成k条多模态预测轨迹,分类分支产生每条轨迹对应的置信度评分。
对于回归分支,融合模块输出向量I通过一个带有残差模块的三层全连接网络,得到预测轨迹
(6)
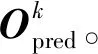
(7)
(8)
3.4 损失函数
对车道图与车交互图建模完成后,后续整个网络中的模块均是可微的,因此实验采用下面的损失函数来端到端地训练整个网络。损失函数对应于上述两条预测分支
Ltotal=aLreg+Lcls
(9)
式中:Ltotal表示全部损失;Lreg表示回归损失;Lcls表示分类损失;α为超参数,用于平衡网络的回归和分类权重,此处α=1。
对于回归损失,为防止模式崩溃,且希望预测轨迹终点能够准确命中真实驾驶意图,使得预测轨迹与真实轨迹相近,对于被预测车辆的k条预测轨迹,选择其中具有最小最终距离误差的预测轨迹P用以计算回归损失,采用平滑L1损失对每个预测时间点进行计算:
(10)
(11)
式中:T为预测时长;pt为第t时刻最小最终位移误差预测轨迹的坐标;为第t时刻真实轨迹的坐标;xi表示x中的第i个元素,x为预测轨迹与真实轨迹之间的偏移误差。平滑L1损失定义如下式:
(12)
对于分类损失,为生成多样的预测结果和增强预测轨迹的可信度,在试验了多种损失函数(负对数似然损失、交叉熵损失和最大间隔损失)之后,最终选择对P的置信度评分Opred做最大间隔损失,得出分类损失:
(13)
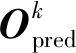
4 实验结果及分析
4.1 数据集
采用Argoverse轨迹预测数据集[22]对本文方法进行评估。数据集包含340k+条从迈阿密和匹兹堡收集的真实驾驶数据。每条数据时长为5 s(50帧),包含车辆的标签及位置序列等信息,前2 s数据用作模型输入,后3 s真实轨迹用于训练预测模型及验证模型预测效果。整个数据集分为三个部分:205k+条训练数据、39k+条验证数据和78k+条测试数据,其中测试数据只包含前2 s信息。除车辆的轨迹序列外,数据集还提供矢量化的高精度地图,包括精确的车道信息及中心线连接信息、栅格化的可行驶区域信息和道路高度信息。
4.2 参数设置
实验运行在安装有Ubuntu 18.04 LTS操作系统的服务器上,主要硬件配置包括CPU Intel Xeon E5-2620、GPU NVIDIA Titan X和32G RAM,使用Pytorch1.4.0深度学习框架。首先对数据集数据进行预处理,将交通场景中车辆轨迹数据和高精地图转化成相应的车交互图和车道图,然后对整个模型进行训练。训练批次大小设置为72,共36个轮次。
采用数据集基准中提供的基本预测参数与评价指标。基本预测参数包括多模态数量为k=1和k=6,预测轨迹时长3 s;评价指标包括最小平均位移误差(minADEk)、最小最终位移误差(minFDEk)和漏失率(MRk),这些评价指标同时适用于单模态(k=1)和多模态(k=6)轨迹预测,分别表示如下:
(14)
(15)

(16)

(17)

4.3 实验结果
使用数据集中测试集数据进行轨迹预测,将得到的结果与数据集提供的基准预测方法和另外4种主流模型进行对比,结果如表1所示。对比模型分别为采用恒定速度的基准方法、采用加权最邻近回归的基准方法、采用多头注意力的轨迹预测方法(Jean)、由终点驱动的轨迹预测(TNT)方法和图注意力方法(WIMP)。评价指标越小,表示模型预测结果与真实轨迹之间偏移越小,预测越准确。

表1 预测结果对比
从表1中可以看出,本文提出方法在平均位移误差和终点位移误差上均优于目前主流方法。其中,相较于采用恒定速度的基准预测方法,本文方法在单模态指标上分别提升41.2%、42.8%、25.9%,在多模态指标上分别提升63.2%、75.1%、78.2%;相较于采用加权最邻近回归的基准预测方法,在单模态指标上分别提升49.5%、50.6%、31.0%,在多模态指标上分别提升49.7%、58.8%、72.2%。基准方法由于只考虑轨迹数据,完全忽略车辆所处的交通环境和场景交互信息,且所用预测方法较为简单,因此在整个轨迹预测任务中精度最低。相比于Jean方法,本文方法在单模态指标上分别提升0%、8%、13%,在多模态指标上分别提升14%、5%、-15%。 本文方法考虑了交通环境对预测轨迹的影响,并将其与车辆间交互特征进行综合考虑,说明多头注意力机制能够充分考虑交通场景的环境特征和交互特征,提高轨迹预测精度。相比于TNT方法,本文方法在单模态指标上分别提升2%、1%、-1%,在多模态指标上分别提升8%、12%、-15%;相比于WIMP方法,在单模态指标上分别提升4%、3%、4%,在多模态指标上分别提升4%、5%、11%。上述两种方法仅使用单独的图方法对场景建模,进一步证明了本文方法使用车道图和车交互图对交通场景建模的有效性,可有效提高预测轨迹的准确性。
为了更加直观地分析预测结果,将预测结果进行可视化,图5展示了部分预测结果。

图5 预测结果可视化
如图5所示,真实轨迹总是与某条预测轨迹重合,表明本文方法能够准确预测车辆轨迹。如图5(a)、图5(b)和图5(c)所示,模型能够根据车辆自身状态(历史轨迹、速度和所在位置)和地图信息,给出合理多样的预测轨迹,从而体现出意图的多样性。同时,模型对于车辆的速度也能够准确进行预测,如图5(d)所示,当车辆以较高速度通过弯道时,预测轨迹较为集中,一致沿当前或临近车道呈现不同的速度分布,而低速时则会如图5(a)中呈现出多种可能的方向。如图5(e)所示,为起步加速过程,模型预测轨迹与真实轨迹一致。如图5(f)所示,当车辆沿车道持续斜向行驶时,模型也能够识别到车辆换道意图,从而给出恰当的预测。
4.4 消融实验
为了观察各个模块在整个模型中所发挥的作用,本文通过消融实验对模型进行研究。实验以包含车辆观测轨迹和状态信息的车交互图为基础,然后逐步加入车道图和特征融合模型组件,在验证集数据上进行轨迹预测,预测结果如表2所示。

表2 消融实验预测结果
由表2可知,以仅含车交互图的模型所获得的评价指标为准,随着V2L模型组件和L2V模型组件的逐步添加,所有评价指标均在不断减小,表明所有模块均有助于提升模型预测准确率,验证了所有模型组件的有效性。当特征融合模块仅包含V2L时,评价指标相较于只有车交互图的模型分别提升15.0%、7.5%、11.9%、18.0%;当特征融合模块仅包含L2V时,相较于只有车交互图的模型分别提升23.8%、18.4%、18.8%、27.1%,表明仅利用车交互图所包含的信息,不足以实现准确的轨迹预测,而车道图为轨迹预测提供的环境信息,对提高预测精度有极大的帮助,且前者较后者提升幅度更大,表明L2V部分在特征融合模块中发挥着更重要的作用。当特征融合模块同时包含V2L和L2V两部分之后,预测精度达到最优,表明特征融合是双向的,任何一部分的缺失都会导致预测效果的下降。因此,本文充分考虑交通场景的静态特性和动态交互,并实现高效融合,用于车辆轨迹预测,取得领先于主流方法的优秀效果。
为探究不同多模态轨迹数量k和不同预测时长对预测结果的影响,本文还对验证集预测轨迹进行了统计研究,结果分别如图6和图7所示。

图6 多模态预测轨迹数量对预测结果的影响

图7 预测时长对预测结果的影响
图6为3 s预测时长下不同多模态预测轨迹数量k对预测结果的影响。由图6可知,k与预测指标minADE和minFDE均呈负相关趋势,即k越大,预测指标数值越小。在对预测轨迹进行评价时,由评价指标定义可知,k值越大,表明单个预测智能体被纳入评价的轨迹越多,有更大可能统计到更准确的预测轨迹,因此使k与评价指标呈负相关趋势。
图7为不同预测时长对预测结果的影响。由图7可知,随着预测时间的增长,各预测指标数值均呈现不同程度的增长,表明预测时长越长,模型的预测准确度越差。这是因为当预测时长较短,如1 s左右时,车辆状态更多由动力学因素决定,会有更大概率保持原有的运动状态行进,因此更容易被模型所预测;当预测时长更长,如3 s甚至更长时,影响车辆未来轨迹的因素更多是车辆之间的交互、车道的拓扑关系和走向等,这类特征建模对模型有更高的要求,使长时的轨迹更不容易被准确预测。
5 结论
本文提出了一种基于有向图模型和注意力机制的轨迹预测方法。通过场景建模、特征提取融合和预测轨迹解码实现了结构化道路场景中车辆多模态轨迹的预测,并对模型开展了消融研究。得出主要结论如下:
1)通过将高精度地图和车辆间交互转化为有向图,能够实现交通场景静态特征和动态交互特征的准确建模,以及场景信息的完整描述;
2)多种注意力机制的使用,可高效完成特征提取和融合,增加模型的可解释性;
3)实验结果表明,本文方法能够有效预测各场景下的车辆未来轨迹,且具有较高的准确度及泛化能力。
但本文预测方法交互图建模时,只考虑车辆之间的交互,且依赖高精度地图对交通场景建模,因此适用于有高精度地图覆盖的结构化道路场景。未来研究中,在本文方法基础上,可考虑面向包含行人、骑行者和车辆的混杂交通场景,开展算法拓展研究。同时,对于无高精度地图覆盖场景,探索接入基于车载传感器生成的局部矢量地图,可以提升算法对更多场景的适应性。
