注入图情领域知识的命名实体识别模型*
2023-08-08王志红曹树金
王 娟,王志红,曹树金
0 引言
人工智能正逐渐走向数据和知识双驱动的认知智能[1]。命名实体作为基本信息元素,是正确理解文本的基础,也是实现认知智能的知识引擎[2]。此外,随着通用领域和特定领域网络信息资源的丰富,从海量、非结构化的文本中识别出相应的命名实体,对网络信息资源的序化和有效利用具有重要价值。相比于通用命名实体,领域命名实体的数据来源更偏向于垂直领域,语料的构建也更加严密,这为实体识别带来两个挑战。首先,领域命名实体的名称、指代内容及对应的类别等会随着技术的快速更新而不断变化,很难快速有效地根据特定领域或任务场景设计相应特征;其次,面向垂直领域的实体识别需要具有一定领域知识的人员进行语料标注,增加了语料构建的难度和成本。图情领域具有高度跨学科性[3],面向图情领域的实体识别具有较好的代表性以及较大的难度。因此,为满足在领域数据量小、人工标注成本高的情况下提升实体识别效果的要求,本文提出基于ERNIE(Enhanced Representation through Knowledge Integration,知识增强的语义表示)[4]的LISERNIE模型,以及面向命名实体识别的LISERNIE+BiGRU(Bi-directional Gated Recurrent Unit,双向门控循环单元)+CRF(Conditional Random Fields,条件随机场)模型。提出的LISERNIE 模型通过在ERNIE预训练阶段注入图情领域知识,增强模型对领域文本的语义理解能力,从而解决通用预训练模型因缺乏下游特定领域知识而效果不佳的问题[5]。在命名实体识别和开放域关系抽取对比实验中,本文提出的LISERNIE+BiGRU+CRF模型的实验性能均优于对比模型,验证了该模型的有效性和可行性,也为下游任务如知识图谱构建、语义检索、问答系统等提供可借鉴的思路。
1 相关研究
不同研究对实体的定义不同,主要体现在实体类型的粒度上,如医疗领域对疾病、药品、治疗方法等的识别[6-7],军事领域对军职军衔、军事装备、军用物资等的识别[8-9]。在图情领域,现有研究[10-13]主要针对可公开获取的文摘或论文全文数据集上的情报分析方法和情报学研究方法等单一类别实体的识别;也有文献[14-15]面向中文古籍构建历史事件实体的识别任务。实际上,图情领域实体复杂多样,图书馆、情报机构配置或使用的设备、不同角色的人才组成、各种会议等都是很有价值的实体类别。因此,根据图情领域的特点,合理划分命名实体的类别,并基于开源数据构建标注语料,是实现图情领域命名实体识别的关键步骤,也为进一步构建知识图谱等提供数据支撑。
由于中文命名实体结构复杂、形式多样,有效的实体识别方法仍然非常重要且具有挑战性。随着深度学习的兴起,无需复杂特征工程的深度学习方法成为命名实体识别研究的主流。Huang等[16]提出将人工设计的拼写特征和BiLSTM(Bidirectional Long Short-Term Memory,双向长短期记忆网络)与CRF 融合起来进行实体识别;李丽双等[17]利用CNN(Convolutional Neural Network,卷积神经网络)训练得到字符级向量,并输入到BiLSTM+CRF 模型中进行生物医学命名实体识别;杨培等[18]结合注意力机制、BiLSTM 和CRF 来识别化学药物命名实体。然而,这些方法主要采用传统的Word2Vec[19-20]静态词向量来表示模型,对不同语境的适应能力较差。2018 年Google 推出BERT 模型(Bidirectional Encoder Representations from Transformer,基于Transformer的双向编码器表示),随后出现越来越多的动态预训练语言模型(Pretrained Language Models,PLM),并逐渐得到广泛应用。这种动态PLM利用大规模无标注的文本语料进行预训练以获得通用特征表示,再通过微调将学习到的语义关系传递到下游任务中。但由于学习到的通用特征表示太泛化,导致模型往往在垂直领域表现不佳,尤其当训练的源任务领域文本和目标任务领域文本所对应的领域不同时,模型效果下降非常明显[21]。为增强PLM在垂直领域的应用效果,研究人员开始对如何使用领域知识来增强PLM进行探索[22-25]。结果表明,这种在预训练阶段注入知识来提升PLM性能的方法具有有效性。
目前图情领域语料还十分稀少,因此如何为PLM注入领域知识,增强模型在垂直领域的应用效果是本文的研究重点。本文将根据图情领域特征,对其实体分类、识别和应用展开一些基础性研究,旨在通过同时利用知识、数据、算法和算力4个要素来构造更强大的人工智能[26]。
2 图情领域实体分类
不同领域文本具有不同的文本特征。为比较图情领域文本和其他领域文本的差异性,本文选取3个特定领域语料库,分别是医疗、司法和金融领域的预训练数据集,如表1所示。图情领域数据集是通过自主采集图情领域相关的百科、新闻网、高校网、协会网以及博客整理得到的,其他3个领域的数据集均为网上公开的实体识别数据集。
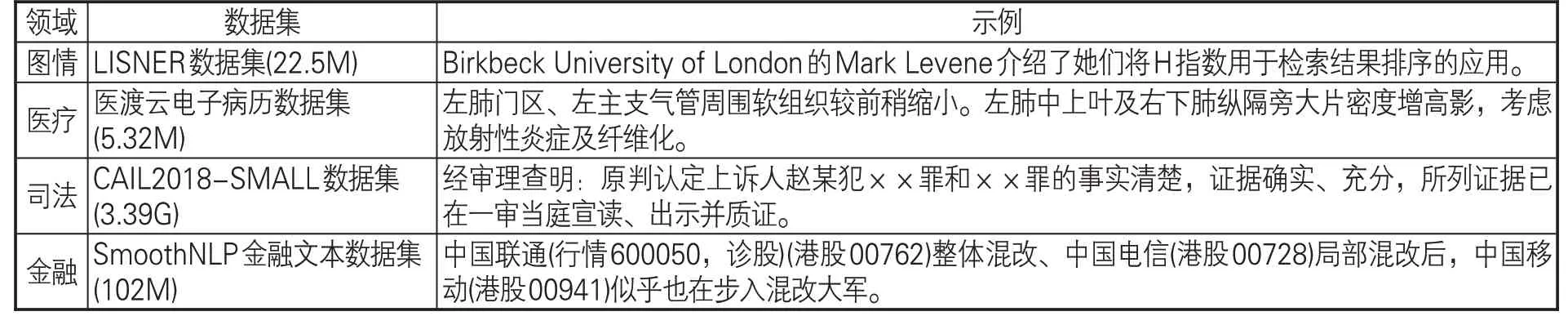
表1 4个特定领域文本数据集说明
本文对这4个领域做了词汇重叠度分析[21]:随机抽取4个领域各1,000条数据,使用Python的jieba库对数据进行分词处理,并过滤掉停用词,对各领域剩下的词统计前500个高频词,然后进行重合比对分析。从图1可看出,图情领域文本和其他3个领域的文本重合度不高,与医疗文本的领域相似度最低,只有0.033,与金融领域相似度稍高,达到0.26,这主要是因为图情和金融领域文本中都有一些比较通用的词汇,如“公司”“传统”“共同”“保障”。不同领域词分布的不同会导致语言模型在相应领域语料中获取到的语言表征不同,因此,针对不同领域特点需要设计不同的命名实体分类和识别方法。
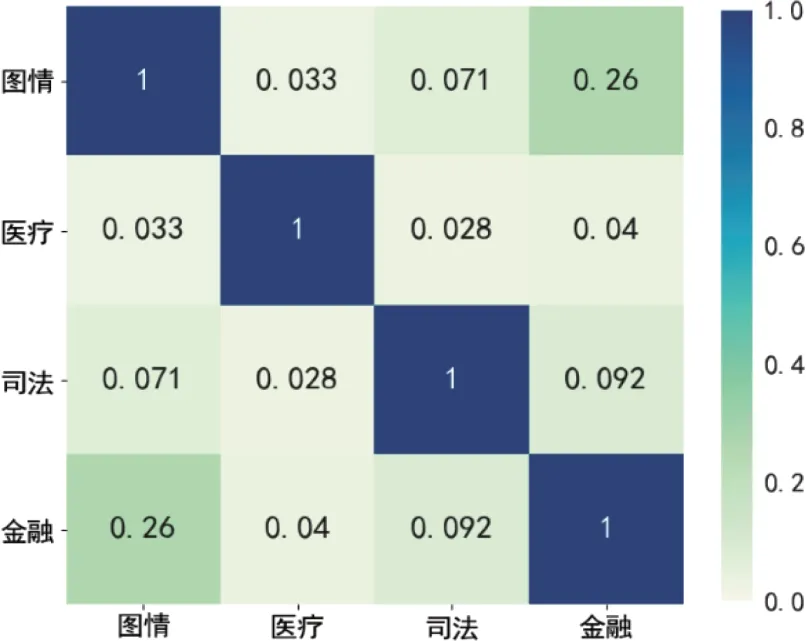
图1 不同领域间的词汇重叠度
领域命名实体的分类一般是利用标注数据集中实体内部的结构特征[27]或者知识库定义来描述类别[28-29]。对第一种方法,有学者[30]认为实体的类别往往会以短词的方式直接出现在实体的末尾,但本文通过统计清华大学推出的通用知识图谱XLORE[31]中出现的图情领域相关实体,发现这种依靠实体结构特征来获取实体类别的方法并不可行。如表2所示,在1,602个实体中,只有17.8%的实体内部包含类别指示词。据此,本文采用第二种方法,即基于知识图谱定义的类别描述方法。具体而言,利用XLORE中高质量的结构化数据来扩展图情领域的命名实体类别。通过解析XLORE发现,其层级结构关系中主要包含实体和类目两类节点,以及类目之间的上下位关系subclass-of 和实体、类目之间的从属关系instance-of。由于一个节点可以包含多个上位节点和下位节点,使得这个类别层级结构不是严格意义的树形结构。为了把XLORE中图情领域相关的实体节点及其对应的类目节点一一联系起来,本文借鉴广度优先遍历算法(Breadth First Search,BFS)的思想,指定类目节点“图书资讯科学”作为类别路径[32]的起始位置,并标记为已访问;然后从该节点出发,沿着subclass-of和instance-of 这两类关系,访问下位节点c1,c2,……和实体节点e1,e2,……,并均标记为已访问;再按c1,c2,……的次序,访问这些类目节点的所有未被访问的下位节点和实例节点;如此循环,直到所有与(其他)节点有路径相通的节点均被访问为止。至此,一个没有多余路径和回路的类别层级结构形成。该层级结构共10层,包含75 个类目节点和1,584 个实体节点,部分示例见图2[1]。
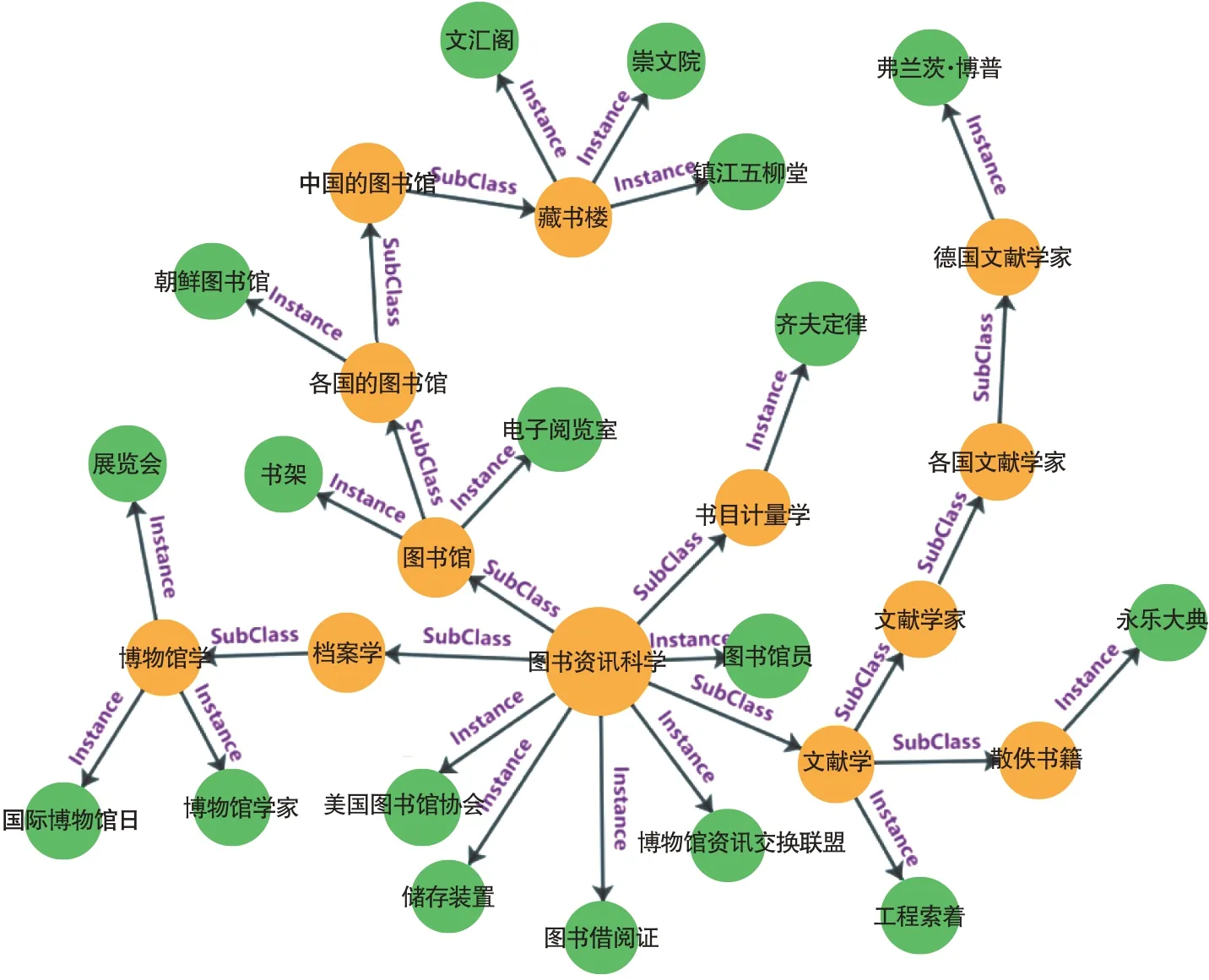
图2 类别路径示例(部分)
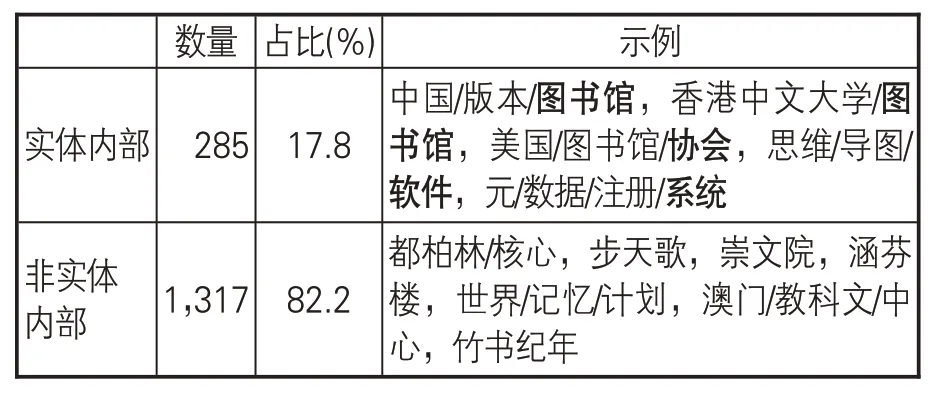
表2 样本数据中类别指示词的统计结果
在类别路径构建过程中,笔者发现部分实体和其上位词的语义关系较弱。比如,实体“图书馆员”“储存装置”“博物馆资讯交换联盟”的上位词是“图书资讯科学”,“国际博物馆日”的上位词是“博物馆学”,这些实体和其上位词之间都没有遵从严格的上下位语义关系,无法从中获得实体所属类别的有效信息。为了弥补在构建严格意义的类别层级结构时可能误删掉的与实体节点更相关的类目节点,对类别路径上的1,584个实体找出其在XLORE中所有的直接上位词,共计3,005个。部分实体及其所有直接上位词如表3所示。分析表3发现,相对于类目“图书资讯科学”和“博物馆学”,类目“职业”与实体“图书馆员”、类目“国际纪念活动”与实体“国际博物馆日”更具有语义相关性。这样,通过对3,005个类目进行人工修改无效类目、合并相似类目,最终形成9大类图情领域命名实体,分别是:人(Person,Per)、组织(Organization,Org)、图书馆(Library,Lib)、技术(Technology,Tec)、设备(Device,Dev)、文档(Document,Doc)、职位(Job)、事件(Event,Eve)以及地点(Location,Loc)。这些实体类别在本文LISNER数据集的标注如图3所示。

图3 图情领域命名实体类别示例
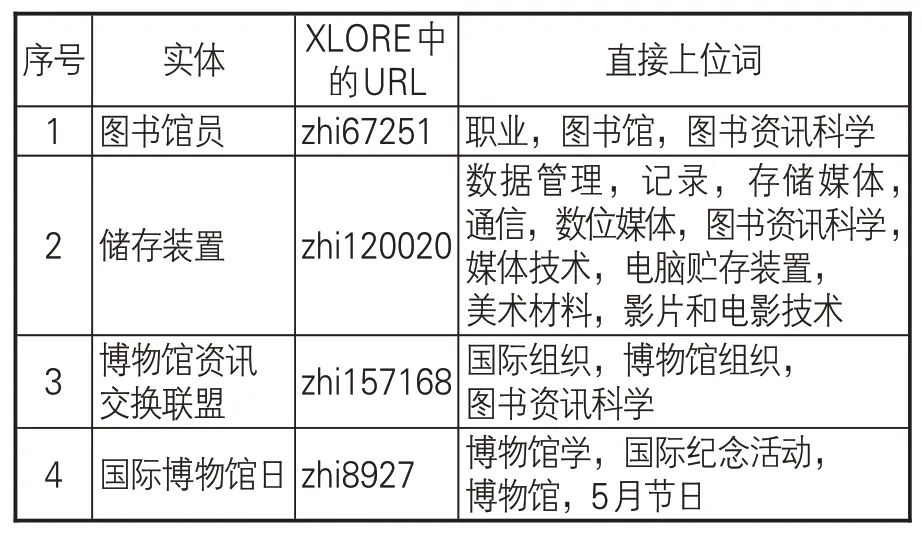
表3 实体节点及其直接上位词(部分)
3 基于LISERNIE的命名实体识别模型
动态PLM一般被划分为两阶段:第一阶段的预训练过程主要包含遮蔽语言建模(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction,NSP)两个基本任务;第二阶段使用微调处理下游任务。ERNIE预训练的语料集主要来自中文百科类网站,这种基于通用语料上的预训练并不能很好地适配特定领域的NLP任务。为此,本文提出基于LISERNIE的命名实体识别模型,通过在ERNIE预训练阶段注入图情领域知识,来提升ERNIE对图情领域文本的语义理解能力。
3.1 LISERNIE预训练模型
总结已有模型在知识注入时所用策略,发现大部分模型或多或少修改了传统PLM 的结构。例如,K-BERT[22]在BERT 嵌入层增加可视层;ERNIE-THU[26]使用K-Encoder 模块将字嵌入和来自知识图谱的实体嵌入进行融合。与上述模型不同,本文提出的LISERNIE模型不需要改变ERNIE原有结构,仅在预训练和微调之间引入一个中间阶段,以便使用领域知识对ERNIE进行继续预训练。如图4所示,PLM“预训练+微调”两阶段被调整为“基于通用语料的预训练+基于图情领域知识的预训练+在命名实体识别任务上的微调”三阶段。第一阶段使用大量无标注的通用文本语料进行预训练,训练任务为MLM和NSP。第二阶段直接加载第一阶段预训练好的模型,基于图情领域知识进行无监督训练,训练任务仍为MLM和NSP。第三阶段利用自建的小规模标注领域文本集,针对命名实体识别任务进行微调。两阶段流程被调整为三阶段流程,需要消耗一定的预训练资源,但获得的知识是全局性的[33],能让预训练模型更好地应用于语义理解任务。
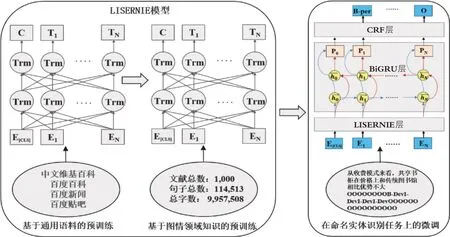
图4 基于LISERNIE的命名实体识别模型
预训练模型主要从非结构化的文本信息中获取知识,然而目前主流的知识注入方法是将知识图谱信息注入PLM中。相对于非结构化的文本信息,形如三元组或有向图的知识图谱所蕴含的是结构化的信息,需要对其进行转换以融入预训练模型中。如果无法进行良好的融合,所融入的知识图谱信息不仅不会提升性能,反而会降低预训练模型的效果。基于此,本文选择从CNKI下载图情相关的期刊论文作为第二阶段使用的图情领域知识来源。学术期刊是科学知识的主要载体之一,蕴含着大量专业知识且比较新颖,将特定领域文献作为语料引入到预训练过程中也是最近的一个研究方向。SCIBERT的预训练语料来自Semantic Scholar上的110万篇文章[34],BioBERT则在PubMed摘要和PubMed Central全文文章上进行预训练[5]。因此,本文使用易获取的图情相关文献来进行后续预训练。首先,在CNKI中检索2007-2021年与“图书情报”主题相关的中文期刊论文,并对结果中含有“HTML阅读”的7,329篇论文的文本内容进行采集。然后,将作者、摘要、关键词、参考文献等信息剔除,只保留题名和全文文本内容。考虑到训练代价大,本文仅随机选取1,000篇进行分句处理,共切分出114,513个句子组成二次预训练的数据集。由于注入的是与ERNIE训练数据形式相同的同构知识,不需要考虑外部知识与原有的非结构化文本信息融合的问题,使用起来比较便捷。
3.2 面向命名实体识别任务的三层模型
本文将实体识别作为一个序列标注任务,模型输入字序列X={x1,x2…xn},其中n代表句子中包含的字数,xn表示第n个字,输出为对应的实体标签序列Y={y1,y2…yn}。整个命名实体识别模型由输入表示层、上下文编码层和输出解码层3 个模块组成。字序列的输入向量如图5 所示,由字嵌入、句嵌入和位置嵌入3部分求和而成。
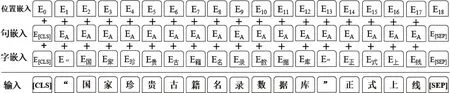
图5 模型输入示例
将相加后得到的嵌入表示E={e1,e2…en}输入到LISERNIE层。LISERNIE层中最重要的结构单元就是Transformer(Trm)编码器。通过Trm编码器计算得到的字的表征,既蕴含字本身的含义,也蕴含该字与其他字的关系,更具全局表达能力。为了进一步提取文本的语义特征,可以在LISERNIE 层后接入RNN(Recurrent Neural Network,循环神经网络)或者LSTM(Long Short-Term Memory,长短期记忆网络)、GRU(Gated Recurrent Unit,门控循环单元)等RNN改进模型。与LSTM相比,GRU具有更低的模型复杂度和更高的训练效率。因此,本文采用由前向和后向GRU组合得到的BiGRU获取范围更广的上下文依赖特征。
对于序列标注问题,需要在获取文本特征后预测当前输入序列的标签。虽然BiGRU层也能预测当前序列的标签,但它只考虑字词自身特征,忽略了标签之间的约束关系。因此,本文在BiGRU的输出后面接入CRF层,以有效约束预测标签之间的依赖关系,对标签序列进行建模,从而获取全局最优序列。
4 实验和结果分析
4.1 小规模标注数据集
本文标注数据来自自建的LISNER数据集中的228篇文档,共7,537个句子。采用半自动化标注方法,首先通过文本标注工具BRAT进行标注。由于本文采用BIO标记法,对于每个实体,首个字标记为“B-实体类别”,中间字或结尾字标记为“I-实体类别”,其他非实体标记为“O”,所以预处理标注后的数据就被分成9 类实体19 种标签。然后,通过人工审查并修正标注结果,生成实验用的小规模标注数据集,部分数据展示见表4。将数据集按“6∶2∶2”拆分成训练集、测试集和验证集,这些实体在评测数据上的分布见表5。

表4 图情领域的小规模标注数据集
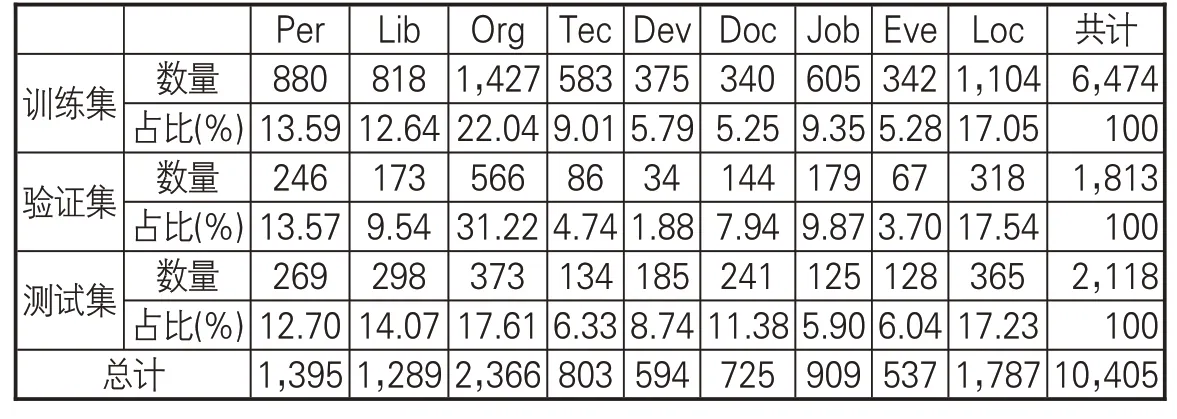
表5 实体在评测数据中的分布
4.2 模型搭建和参数设置
实验采用Tesla V100 的GPU,32GB 的Video Mem,实验语言为Python3.7,实验模型采用PaddlePaddle2.1.2搭建。预训练阶段,模型超参设置如下:LISERNIE隐藏层维度为768维,batch size为64,学习率采用自定义算法,范围为[1×10-5,1×10-4],dropout设置为0.1,优化算法使用AdamW[35]。微调阶段,BiGRU隐藏层维度为256维,模型由15个Epoch进行训练,学习率范围设置为[6×10-5,1×10-4],其余参数的设置与预训练阶段保持一致。
4.3 评价指标
本文使用实体级别的准确率(Precision,P)、召回率(Recall,R)及其调和平均数F1来评价模型效果,具体计算公式如下:
4.4 实验设计与分析
为了验证基于LISERNIE的图情领域命名实体识别模型的有效性,本文设计了4组实验。第一组为使用不同PLM 的实体识别效果对比实验,用来检验注入领域知识的PLM相比其他PLM 是否取得更好的性能;第二组为不同类别的实体在不同规模数据集上的识别效果对比实验,用来检验本文模型在小规模标注数据集上的性能是否稳定;第三组为消融实验,用来验证本文模型中各个模块的有效性;第四组实验将模型应用到实体关系抽取中,以验证模型的可行性。
(1)不同PLM的对比实验。分别使用Word2Vec、BERT[36]、ERNIE、RoBERTa[37]、ALBERT[38]及本文的LISERNIE等PLM得到句子的语义表示向量,再接入BiGRU和CRF两层,实体识别结果见表6。本文提出的基于LISERNIE的识别模型效果最好,F1 值达到75.46%,相较于基于ERNIE的模型,提高了1.08%,表明为预训练模型注入领域知识能够提升实体识别效果。而ERNIE的F1值又略高于BERT,这是由于在预训练语料方面,ERNIE不仅使用百科类语料,还使用新闻资讯类、论坛对话类语料来训练模型;相比于BERT仅使用百科类语料,ERNIE可获得更好的语言表征,也进一步验证了注入外部知识有利于提高模型的语义表示能力。基于传统Word2Vec 的效果最差,可见“预训练+微调”的动态PLM比静态PLM具有更大优势。此外,从运行时间来看,各个模型相差不大,对于可以离线计算的任务而言是可接受的。
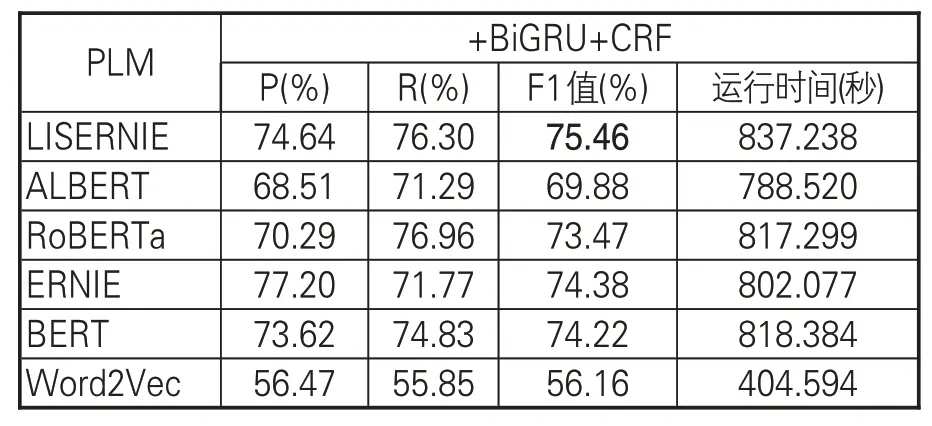
表6 不同PLM的识别效果对比
(2)不同类别的实体在不同规模语料(数据集)上的对比实验。将数据集规模划分为四分之一、三分之一、二分之一、三分之二、四分之三和全部数据集,基于LISERNIE+BiGRU+CRF的命名实体识别模型在不同规模数据集上的识别效果如图6所示。可以看到,同一个模型对不同类别实体的识别效果也有一定的差距,但总体上,实体的F1值和数据集的规模呈现一定的正相关。随着语料规模的减少,实体的识别效果下降较为平缓,说明本文模型在小规模数据集上的性能比较稳定。Person实体的F1值基本在85%以上,主要原因是对于Person这类通用命名实体,预训练阶段已经取得很好的效果,即使在标注数据很少的情况下,识别性能也不会受到很大影响。但占比较少的Document、Device、Technology和Event这4类实体识别效果都出现急剧下降情况,说明测试数据太少还是会导致深度学习模型难以有效学习,识别效果大打折扣。
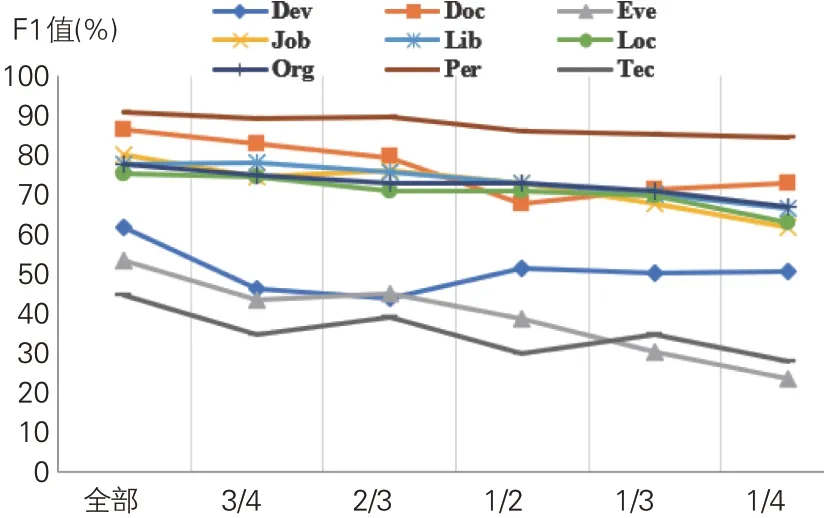
图6 不同类别实体在不同规模数据集上的实验结果
(3)消融实验。为更好地分析模型各个部分的作用,本文还进行了模型消融实验,即在原始模型基础上分别去掉BiGRU层、CRF层,以及同时去掉这两层。另外,为了检验BiGRU层的效果,还采用BiLSTM作为替换模型进行了实验。观察表7 可以看到,模型各个部分都起到了作用,模型1、2、3 的F1 值分别比本文模型低2.1%、1.19%和1.09%,说明去掉BiGRU层和CRF层的任何一层都会造成性能下降,并且同时去掉BiGRU层和CRF层,比单独去掉其中一层效果下降更加明显。比较模型2和4以及本文模型和模型5,发现用BiGRU替换BiLSTM后的效果和运行速度均有所提升。可见,相对BiLSTM模型,BiGRU 模型参数更少、网络结构更加简单,使得整个模型计算速度更快,在小数据集上的泛化效果也更好。
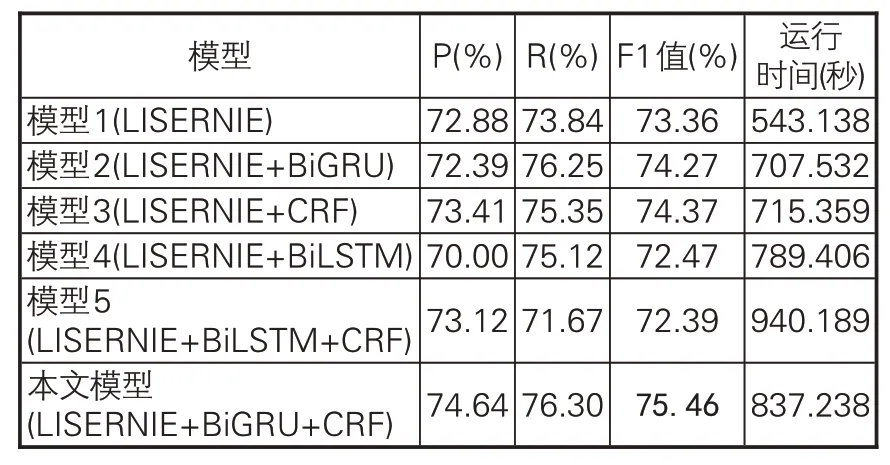
表7 不同模型的识别效果对比
(4)基于LISERNIE的实体关系抽取实验。面向开放域的关系抽取可以挣脱预定义关系的束缚,识别句子中实体与实体之间的关系,抽取出实体关系三元组。为分析LISERNIE模型对其他NLP 下游任务性能提升起到的积极作用,从LISNER数据集中随机取出166个句子,将基于LISERNIE实现的关系抽取方法和现有的CORE(Chinese Open Relation Extraction,中文开放关系抽取)[39]系统进行对比。CORE系统共抽取出22个句子中的38个三元组,经人工校对,3个正确,准确率为7.89%。本文方法共抽取出134个句子中的277个三元组,85个正确,准确率为30.69%,部分抽取结果如表8所示。
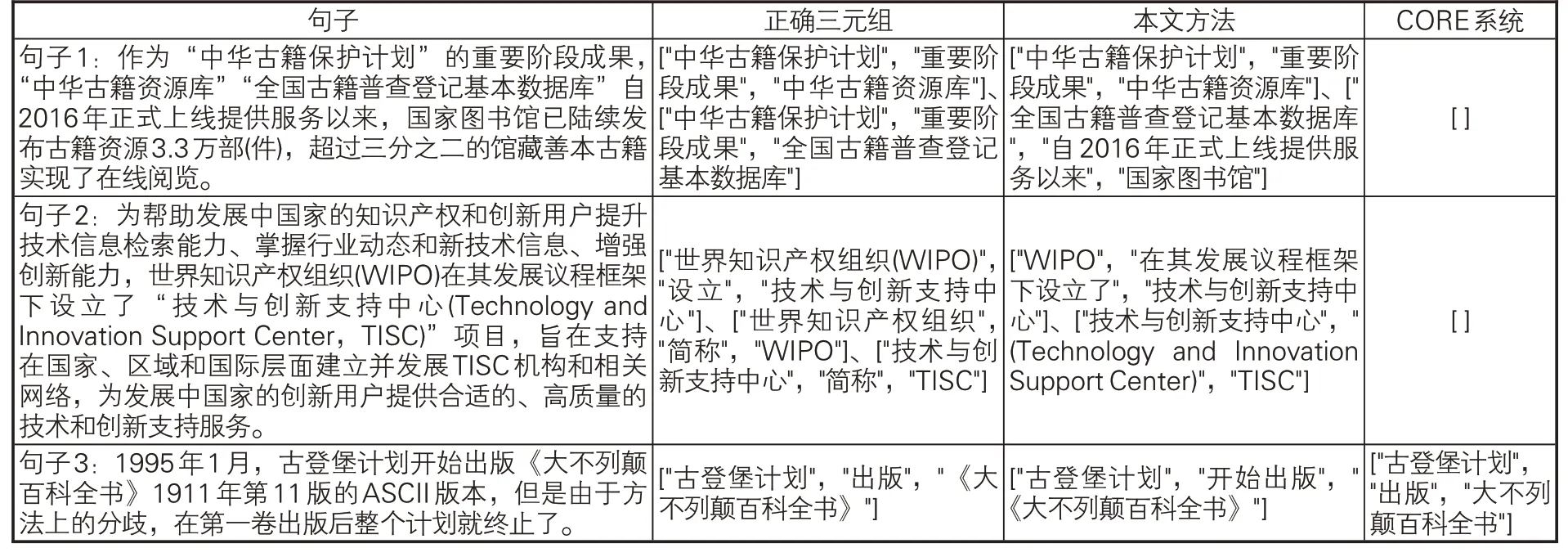
表8 抽取结果对比(部分)
CORE系统采用基于依存句法分析的关系抽取方法,只抽取由动词或名词引导的介导关系,大量有用的关系实例被过滤掉,导致准确率大大降低。本文采用流水线方法,首先基于LISERNIE+BiGRU+CRF模型对句子中的实体进行识别,接着过滤掉句中“实体数<2”的句子,最后抽取句子中实体对之间的文本作为关系。例如,句子“国家古籍保护中心在组织开展古籍数字资源发布的同时,全国古籍‘摸家底’工作也取得重要进展。”经过模型识别出一个Org实体“国家古籍保护中心”,但因为句子中的“实体数<2”,该句被过滤掉。又如,表8中的句子1经过本文模型识别出Eve实体“中华古籍保护计划”、Tec实体“中华古籍资源库”和“全国古籍普查登记基本数据库”以及Lib实体“国家图书馆”,所以实体“中华古籍保护计划”和实体“中华古籍资源库”之间的文本被抽取出来,形成三元组["中华古籍保护计划","重要阶段成果","中华古籍资源库"]。这种抽取处理简单,不受限于限定模式,准确率较CORE系统有较大的提高。
当然,本实验主要是为了验证LISERNIE+BiGRU+CRF模型在关系抽取中的可行性。实现方法仅是在Riedel等[40]假设的基础上放松抽取限制,认为如果实体对存在某种关系,那么存在该实体对的句子反映了该关系,并针对每一个实体对进行关系抽取,这样会造成大量信息冗余,降低准确率。但本文方法无需预先定义实体关系类型,只需少量标注实体的预训练语料,对于后续开展开放域的实体关系抽取研究具有一定的借鉴意义。
5 结语
针对图情领域内标注数据少、相关知识库缺失等问题,本文利用知识图谱中的实体节点及其类别层级结构,科学确定了图情领域的实体类别,并构建了一个基于领域知识注入的预训练语言模型LISERNIE。在随后开展的命名实体识别实验和开放域关系抽取实验中,相比于基线模型,本文提出的基于LISERNIE+BiGRU+CRF的命名实体识别模型能更有效地识别出实体及其关系,可以更好地支撑后续诸如知识图谱构建、问答系统、机器阅读等自然语言应用的开展。未来可关注:一是在预训练阶段,过多的知识注入可能带来噪声,造成模型损失,但注入的知识不足则对于提高模型对文本的语义理解力帮助不大,后续研究可探讨把什么样的知识以什么样的方式注入预训练模型中,使模型在下游任务上有更好的表现;二是采用流水线方法进行开放域关系抽取会产生大量冗余信息,今后可以尝试结合语义、语法信息实现实体关系的有效抽取;三是将知识驱动的人工智能和数据驱动的人工智能两种范式结合起来,是人工智能发展的必经之路[26],后续研究可以思考如何将数据和知识融合,以实现更好的效果。
