汉语复合词语素意义与整词语义整合加工的时间进程*
2023-08-04蔡文琦张向阳王小娟杨剑峰
蔡文琦 张向阳 王小娟 杨剑峰
汉语复合词语素意义与整词语义整合加工的时间进程*
蔡文琦 张向阳 王小娟 杨剑峰
(陕西师范大学心理学院, 西安 710062)
研究表明语素意义会自动激活并影响整词语义加工。但是, 汉语复合词识别中语素意义何时被激活以及如何参与并影响复合词语义整合的时间进程还缺乏清晰的认识。研究采用事件相关电位(ERP)技术, 构建了三类双字词材料: 语素意义与词义相关的透明复合词(如炽热)、语素意义与词义不相关的不透明复合词(如风流)、以及作为控制条件的单语素词汇(如伶俐), 对比考察双字词的首词素和尾词素语义参与复合词语义加工的时间进程。结果发现, 首字加工的早期(300~400 ms)和晚期(460~700 ms)都表现出语素效应, 即两类复合词要比单语素词诱发更负的波幅。在尾字加工的早期阶段(260~420 ms)不仅发现了语素效应, 还发现了语义透明度效应, 即不透明复合词比透明复合词诱发了更负的波幅。而在尾字加工的晚期(480~700 ms), 出现了反转的语素效应, 即两类复合词比单语素词诱发更正的波幅。结果表明了语素作为独立表征单元, 在早期加工阶段就得到了自动激活; 语义透明度在复合词早期加工过程发挥了重要作用, 透明复合词语素整合加工能够顺利获取整词语义, 而不透明复合词语素整合加工则会阻碍整词语义获取。
语义整合, 复合词, 语义透明度, ERP
1 引言
语义整合能够帮助人们将简单意义信息块整合为更高水平的语义信息, 形成复杂且连贯的语义表达。语素(也称词素)作为承载形态和意义的最小语言单位, 是复合词的重要组成部分。近年来, 复合词内部的语素整合加工成为了研究者广泛关注的问题(Brooks & Cid de Garcia, 2015; Fiorentino et al., 2014; Flick et al., 2018; Lee et al., 2021; Leminen et al., 2019)。例如, 研究发现, 复合词相对于单语素词需要更多的认知加工(El Yagoubi et al., 2008; Ji et al., 2011; Rastle et al., 2004)、更复杂的加工进程(Coch et al., 2012; Fiorentino et al., 2014)以及更多的脑区激活(Brooks & Cid de Garcia, 2015; Flick et al., 2018; Hsu et al., 2019)。但是对于复合词的语素意义参与激活并影响整词语义通达的时间进程还不清楚。本研究采用事件相关电位(ERP)技术, 对比考察汉语双字词的首字和尾字加工的时间进程差异, 深入揭示双字词语素意义整合加工进程。
复合词由两个及以上具有独立意义的语素所构成, 例如“微信”是由“微”和“信”两个语素整合形成的。复合词心理表征和加工机制一直是心理语言学研究广泛关注的问题。混合表征模型认为, 在心理词典中既存在语素表征, 又存在整词表征, 因此复合词的识别是语素和整词激活相互作用的结果(Libben et al., 2020; 彭聃龄等, 1999; Pollatsek et al.,2000; Taft, 2003, 2004)。例如, Taft (2003, 2004)提出,语素表征层以及整词表征层处于不同层次, 在通达整词之前都要经过语素表征层, 该表征层又称为词条层。Taft和Nguyen-Hoan (2010)基于实证研究结果, 提出了词条模型, 进一步明确提出了词条层是介于形和义的抽象连接层, 能够表征语素语义信息, 在词汇识别的早期加工阶段词条层的语素形态及语义信息均得到激活, 并且能够影响复合词的语义通达加工。上述词汇加工的认知理论模型主要是基于行为结果的证据提出, 对于复合词加工中语素如何分解和整合等加工过程还需要结合神经科学技术手段细致深入地研究。
研究者对比了英语单语素词和复合词的加工(Fiorentino & Poeppel, 2007; Gagné & Spalding, 2016; Ji et al., 2011), 结果发现了被试在两种词汇条件之间存在行为反应差异, 例如, 单语素词的书写速度快于复合词的书写速度(Gagné & Spalding, 2016), 表现出语素效应, 从而研究者认为复合词具有与单语素词不同的加工机制。具体来说, 被试在加工复合词时, 语素信息可能得到分解激活, 而单语素词仅包含一个语素, 例如玻璃, 因此无法进行分解, 只能通过整词路径获取词汇语义(Fiorentino & Poeppel, 2007; Gagné & Spalding, 2016; Ji et al., 2011)。进一步的ERP研究(Fiorentino et al., 2014)发现, 在较为早期时间窗内(275~400 ms), 英语复合词就比单语素词诱发了更负的波幅, 脑区分布在中线及右后部脑区。早期语素效应表明了被试在早期就能够意识到两类词汇的差异, 从而可能激活不同的加工通路。复合词能够进行语素分解, 并激活了语素意义信息, 进而尝试进行整合加工过程。该解释得到了脑磁图(MEG)研究的支持(Hsu et al., 2019), 该研究发现汉语复合词比汉语单语素词需要额外的脑区激活, 更多激活了左侧颞叶前部及颞叶后部脑区。
更多的研究表明, 复合词的语素意义可能独立于整词加工而被自动激活。例如, Zhou等人(1999)操纵了启动词与目标词之间的语素、词形、语义关系, 结果发现语素启动(如华丽−华贵)效应大于字形启动(如华侨−华贵)、词义启动(如医生−护士)效应。Zou等人(2019)在听觉词汇决策任务中发现共享语素条件(如火山−火箭)在前部脑区产生较大N400, 而共享词义条件(如车轮−车胎)在中后脑区产生较小N400, 从而表明汉语语素意义和整词义在神经上的加工分离。还有研究进一步发现了在复合词识别加工的早期阶段, 语素意义就得到了自动激活(Tsang & Chen, 2014; Wu et al., 2020; 赵思敏等, 2017)。例如, 赵思敏等人(2017)发现了当启动词和目标词共享语素同形同义时, 同时引发了N250和N400的变化, 结果说明了语素意义能够被自动分解并影响到目标词的早期语义通达。
语素意义在复合词加工早期就会得到自动激活, 但语素意义影响整词语义通达的加工机制还不清楚。为探讨此问题, 研究者(Brooks & Cid de Garcia, 2015; Ji et al., 2011)对比了两类复合词的加工: 整词语义与语素意义相关的透明复合词(如炽热)、以及整词语义与语素意义不相关的不透明复合词(如风流)。以往研究者分别结合启动范式(El-Bialy et al., 2013; Tsang & Chen, 2014)、语素间隔范式(Frisson et al., 2008; Ji et al., 2011)、词汇判断任务范式(Lee et al., 2021), 行为结果均发现了被试加工不透明复合词比透明复合词反应时间更长、错误率更高, 表现出复合词加工的语义透明度效应。意义计算观点认为, 透明与不透明复合词加工都需要语素的自动分解, 它们的加工差异可能在于语素意义与整词语义的整合阶段。具体来说, 透明复合词的语素语义与整合计算得到的整词意义一致, 从而促进了整词语义的通达; 而不透明复合词的语素语义与整合获得的意义存在竞争冲突, 从而阻碍了整词语义通达(El-Bialy et al., 2013; Ji et al., 2011; Tsang & Chen, 2014)。
近年来, 认知神经科学研究尝试通过对比两类复合词的神经加工差异, 来揭示语素意义整合加工的神经机制。遗憾的是, 现有拼音文字研究并没有清晰地揭示两类复合词在神经层面上的加工差异。例如, 一项MEG研究发现, 英语透明复合词及不透明复合词不存在加工时间进程上的差异(Brooks & Cid de Garcia, 2015)。使用功能性磁共振成像(fMRI)技术的研究也发现, 被试在加工波斯语透明复合词与不透明复合词时没有表现出脑区激活的差异(Momenian et al., 2021)。有研究者提出, 拼音文字属于表音文字, 语素形−义的映射关系较弱, 因此在复合词加工中, 语素更多激活了正字法结构信息, 语素意义/意义关系信息对整词语义加工的贡献较小, 从而在拼音文字研究中难以发现两类复合词的加工差异(Koester & Schiller, 2008, 2011)。
汉语独特的构词特点能够为考察复合词的语素整合提供新的可能。汉字是表义文字系统, 绝大多数汉字即为一个独立的语素, 超过80%的汉语词汇为双字复合词(Huang et al., 2011; Zhou et al., 1999)。而且, 汉字属于方块字, 汉字之间的明显分界使得语素更易被分解, 从而影响整词的语义通达加工(Tsang & Chen, 2013; Wu et al., 2017)。英语复合词大都是偏正式结构, 而汉语复合词则包含了并列式、偏正式等多种构词结构(Kuo & Anderson, 2006; Liu & McBride-Chang, 2010)。在加工并列式透明复合词时, 首、尾语素意义都可以得到激活, 当语素意义/语义特征信息与整词高度相关, 语素意义与整合计算得到的意义一致, 就会促进整词语义通达, 反之可能干扰或阻碍整词语义的通达。
有研究者尝试考察了语义透明度效应的神经加工机制。结合fMRI技术, 研究通过语义透明度效应考察语素整合加工的脑机制。如Lee等人(2021)的研究发现不透明复合词比透明复合词更多激活了左侧前额皮层, 该脑区可能反映复合词语素意义在线整合加工。但是, 也有研究者认为左侧前额皮层可能负责了语素分解过程(Gao et al., 2022; Zou et al., 2016)。另外, 还有研究认为大脑颞叶脑区(例如, 颞叶前部、颞中回后部)以及顶下脑区(例如, 角回)都可能参与了语素语义的整合加工(Boylan et al., 2017; Flick et al., 2018)。上述相关脑区的参与激活反映了复合词的语素整合可能涉及了语素分解、语素义表征通达以及语素义整合等复杂的加工过程。
使用高时间分辨率的ERP技术能够更精细地揭示复合词的语素整合加工过程。遗憾的是, 这方面的研究相对较少, 还没有清晰的研究结论。例如, 在一项听觉词汇的ERP研究中, Tsang, Zou和Tse (2022)并没有发现透明和不透明复合词的神经加工差异。而在视觉词汇的ERP研究中, Tsang和Zou (2022)发现了首、尾语素的透明度效应, 表明语素意义可能被自动激活并影响整词的语义加工, 但是该研究无法直接探讨语素语义与复合词语义的整合机制。一方面, 研究中使用混合线性模型从多变量的角度综合考察了复合词和语素水平的多个因素的影响, 通过标注方法确定的语素透明度效应反映了相对于所有语素表义的平均水平的高低差异, 并没有明确地与不透明语素进行比较。另一方面, 研究者在操纵首/尾语素与复合词的语义透明度时, 并没有同时考察另一个语素的语义透明度作用。上述方法限制导致了研究者无法直接探讨两个语素意义自动激活后如何整合并影响复合词的语义通达。
因此, 本研究克服前人研究的不足, 同时操纵两个词素的透明度, 考察汉语复合词的词素整合加工过程。实验对比了三类双字词: 透明复合词、不透明复合词与单语素词, 同时考察语素效应以及语义透明度效应。结合高时间分辨率的ERP技术, 分别考察首字和尾字诱发的ERP波幅, 深入揭示汉语复合词加工中词素意义的自动激活和整合及其影响整词语义通达的时间进程。本研究预期: (1) 被试在加工首字时可能表现出语素效应。前人的研究发现(Wu et al., 2020; 赵思敏等, 2017), 语素意义在词汇识别早期就得到了自动激活, 本研究预期语素效应也将在首字加工早期加工阶段就表现出ERP波幅的差异; (2) 被试在加工尾字时不仅会显示出语素效应显著, 还会出现语义透明度效应, 即透明复合词与不透明复合词之间存在波幅差异。具体会表现在尾字加工的早期阶段, 词素意义就得到激活, 随即首、尾词素的意义进行整合加工。透明复合词的两个词素语义相近且与整词语义相关, 词素整合加工受到意义一致的促进作用, 从而快速通达复合词语义表征。反之, 不透明复合词的语义通达中存在语义不一致的冲突, 从而干扰或阻碍整词语义的通达。而在尾词素的加工后期阶段, 由于语义透明度是一种加工属性(El-Bialy et al., 2013; Ji et al., 2011; Momenian et al., 2021), 可能在完成复合词的语义整合加工后消失, 从而在尾字加工后期不再表现出透明和不透明复合词的加工差异。
2 方法
2.1 被试
一方面基于G-Power软件进行样本量的计算, 评估一个中等大小的单因素三水平交互作用的效应量(= 0.30, Cohen, 1992), α设置为0.05, 统计检验力为0.95(Faul et al., 2009), 计算得到的样本量为31人。另一方面, 结合以往关于复合词加工研究中的样本量(吴建设等, 2020; Wu et al., 2020), 实验样本量为25~35人, 本研究设计中确定了35名被试以确保足够的统计效力。实验实际招募到在校大学生34名(19名女生), 平均年龄20.62 ± 1.04岁(19~24岁)。所有被试均为右利手, 视力或者矫正视力正常, 身体健康, 既往无神经精神系统疾患及遗传疾病。所有被试在实验之前都详细阅读了《被试知情同意书》, 并签字同意。实验结束后获得适量报酬。
2.2 设计与材料
实验采用单因素三水平(透明复合词、不透明复合词和单语素词)被试内实验设计, 每个条件包含30个汉语双音节词汇, 共90个刺激材料。透明复合词指两个词素的意义与复合词语义相同或者相近, 如“炽热”; 不透明复合词指两个词素的意义与复合词语义不同, 如“风流”; 单语素词则只具有一个整词语素, 如“伶俐”。此外, 还加入30个假词作为填充材料, 不纳入分析; 假词由两个单字组成,但是整词不能构成词汇语义, 如“仓挡”。
透明复合词和不透明复合词的划分采用7点评分(7 = 词素意义与复合词语义相关度非常高; 1 = 词素意义与复合词语义相关度非常低), 把对首词素、尾词素的得分进行求和作为整词的语义透明度(Brooks & Cid de Garcia, 2015)。15名不参与正式实验的大学生对双字复合词的语义透明度进行评定。总得分 > 7的为透明词, 总得分 ≦ 7的为不透明词, 透明词和不透明词的透明度评分存在显著差异((58)= 20.73,< 0.001)。本实验选取首、尾词素的透明度评分均 ≧ 3.5的词汇确定为并列式透明复合词, 并且首、尾词素的透明度评分不存在显著差异((58)= −0.44,0.660)。有行为研究结果显示, 词频会影响到复合词的语义透明度效应。低频复合词下的语义透明度效应大于高频复合词下的语义透明度效应(Tsai, 1994)。实验材料全部采用低频材料(平均频率为3.24/百万次)。而且, 透明复合词、不透明复合词和单语素词都匹配了词频((2, 58) = 1.65,= 0.209)、首字部件数((2, 58) = 1.06,= 0.354)、尾字部件数((2, 58) = 0.17,= 0.845)、整词部件数((2, 58) = 1.36,0.266), 首字笔画数((2, 58) = 0.45,0.643)、尾字笔画数((2, 58) = 0.16,0.856)和整词笔画数((2, 58) = 0.64,0.533)。详细的材料属性匹配见表1。

表1 实验材料的相关属性信息
注:括号中的数值为标准差。词频来自《现代汉语通用词表》(2003)。
2.3 实验程序
实验在专门的ERP实验室进行。实验过程中, 被试坐在安静的实验间, 距离电脑屏幕约60 cm。每个试次中, 首先在屏幕中央呈现500 ms的“+”注视符, 接着呈现第一个汉字800 ms, 之后是空屏200 ms, 最后呈现第二个汉字, 这时要求被试快速并准确地判断前后呈现的两个汉字是否能够构成真词。当被试判定为真词则不作任何按键反应, 第二个汉字一直呈现800 ms后消失; 当被试判定为假词做出按“F”键反应后, 第二个汉字立即消失。随后呈现空屏时间2200 ms, 之后进入下一实验试次。为了获得可靠的脑电信号, 120个刺激材料分别呈现两次。实验共分为6个部分, 每个部分包括40个试次, 其中透明复合词、不透明复合词、单语素词以及假词条件各10个试次, 每个部分的持续时间大约为3分钟, 被试完成全部实验程序需要大约18分钟。刺激的呈现和数据收集通过E-prime 3.0实现。
2.4 ERP数据记录
采用国际10-20系统扩展的64导电极帽, 以NeuroScan系统记录EEG信号。电极M1和M2分别置于左侧和右侧乳突, 同时记录双眼外侧的水平眼电(HEOG)和左眼上下眶的垂直眼电(VEOG)。在线记录的滤波带通为0.1~100 Hz, 采样频率为1000 Hz。每个电极点与头皮之间的阻抗都小于5 KΩ。数据锁时在每个汉字呈现的起始时间, 以便清晰地记录每个汉字诱发的神经反应。
2.5 数据分析
34名被试全部完成实验任务, 2名被试由于伪迹太多, 在最终数据分析中被剔除, 参与数据分析的有效被试为32名。实验中的行为按键反应是为了确保被试能够保持注意并认真完成任务, 只需要被试对25%的试次(假词条件)作出反应, 三种真词条件(透明复合词、不透明复合词和单语素词)不作任何反应, 本研究对每种真词条件下的平均错误试次进行统计并对三种条件的错误率进行单因素(透明复合词、不透明复合词和单语素词)重复测量方差分析, 当球形假设不成立时, 方差分析结果采用Greenhouse-Geisser法进行校正, 结果报告矫正后的值以及原始自由度。采用Bonferroni方法进行事后多重比较校正。
在MATLAB环境下使用EEGLAB对数据进行预处理。在预处理中, 选择双侧乳突的平均作为重新参考电极, 首先对每个被试的数据进行0.1~30 Hz的滤波, 之后将波幅超过±75 µV的波移除, 再使用独立成分分析(ICA)识别眼动和其他可能的伪迹并加以移除(Lo et al., 2019; Maurer et al., 2011; 张瑞等, 2021)。ERP数据分别选取首字、尾字刺激呈现点之前100 ms到之后700 ms的时间窗口, 分别把首字、尾字刺激点−100~0 ms 作为基线校正, 把首字、尾字刺激呈现后的700 ms 作为分析时程。随后将同一条件的脑电波进行叠加平均。
参考前人文献(Bemis & Pylkkänen, 2011; Kim &Pylkkänen, 2019; 张瑞等, 2021), 经过预处理之后,在每个电极点上对首字和尾字分别进行方差分析以确定数据分析的时间窗。首先, 计算每种条件下首字、尾字的总体平均ERPs, 以20 ms时间窗为步长计算平均波幅, 再对每个时间窗内的平均波幅的所有被试数据做单因素(透明、不透明复合词和单语素词)重复测量方差分析。然后, 在−100~700 ms范围内至少有3个步长(连续60 ms)的方差分析结果显著(< 0.05)则被确定为数据分析的时间窗。据此, 在首字诱发的ERP波幅上识别出条件差异显著的两个时间窗: 300~400 ms和460~700 ms; 在尾字加工上识别出两个时间窗: 260~420 ms和480~ 700 ms。最后, 选取3 (半球: 左/中线/右) × 3 (分区: 前/中央/后)共9个代表性电极点(左: F3, C3, P3; 中: Fz, Cz, Pz; 右: F4, C4, P4)做进一步的数据分析(Beyersmann et al., 2014; Zou et al., 2019)。在考察首字和尾字诱发的波幅条件差异时, 以每个时间窗的平均波幅为因变量, 进行3 (词汇类型: 透明复合词/不透明复合词/单语素词) × 3 (半球: 左/中线/右) × 3 (分区: 前/中央/后)的重复测量方差分析, 当球形假设不成立时, 方差分析结果采用Greenhouse- Geisser法进行校正, 结果报告校正后的值以及原始自由度。采用Bonferroni 方法进行事后多重比较校正。
3 结果
3.1 行为结果
所有32名被试都能成功地完成真假词判断任务, 被试在三种真字条件下错误地作出按键反应的平均试次仅为1.41次(2.34%)。其中, 在透明复合词条件下的平均错误试次为1.53次(2.55%), 在不透明复合词条件下的平均错误试次相对最高, 为2.31次(3.85%), 而在单语素词条件下的平均错误试次仅为0.38次(0.63%)。对三种条件的错误率进行单因素重复测量的方差分析, 结果发现词汇类型的主效应显著((2, 62) = 12.98,< 0.001, η2= 0.295), 被试在单语素词条件下的错误率要显著低于透明复合词((31) = −3.97,= 0.001, Cohen’s= −0.826)和不透明复合词((31) = −3.96,= 0.001, Cohen’s= −0.919), 在透明复合词条件下的错误反应也要略低于不透明复合词条件((31) = −2.31,= 0.083, Cohen’s= −0.500)。
3.2 ERP结果
3.2.1 首字加工
在首字下, 透明复合词、不透明复合词和单语素词条件保留的有效试次数相同, 都保留了97.91%的有效试次。对首字加工的两个时间窗(300~400 ms, 460~700 ms), 分别对平均波幅进行3 (词汇类型: 透明复合词/不透明复合词/单语素词) × 3 (半球: 左/中线/右) × 3 (分区: 前/中央/后)的重复测量方差分析。各电极点的波形图及各效应地形分布图见图1所示, 方差分析的统计结果在表2中详细列出。另外, 分区、半球主效应显著情况下的事后检验分析结果以及分区×半球交互作用显著情况下的简单效应分析后续统计结果详见网络版附表1、附表2。
(1) 300~400 ms时间窗
该时间窗内平均波幅的重复测量方差分析结果显示, 词汇类型的主效应显著, 表现为透明和不透明复合词都要比单语素词诱发更负的波幅((31)= −2.85,= 0.023, Cohen’s= −0.505;(31)= −2.50,= 0.055, Cohen’s= −0.443), 但两类复合词之间差异不显著,(31) = −0.04,= 1.000。实验结果没有发现词汇类型与分区或半球的交互作用。
首字诱发的平均波幅在头皮分布上呈现出显著的半球主效应, 表现为左侧和中线要比右侧电极点的波幅更负, 而左侧与中线上电极点的波幅之间差异不显著。而且, 半球效应与分区之间表现出显著的交互作用, 简单效应分析发现在中央脑区的半球效应显著((2, 62) = 10.99,< 0.001, η2= 0.262), 表现出左侧与中线比右侧电极诱发了更负的波幅, 而左侧与中线上的电极波幅差异不显著。而在前部脑区、后部脑区的半球效应均未达到显著((2, 62) = 3.05,= 0.054, η2= 0.090;(2, 62) = 1.38,= 0.260)。
(2) 460~700 ms时间窗
该时间窗的重复测试方差分析同样发现了显著的词汇类型主效应, 即透明和不透明复合词都要比单语素词诱发更负的波幅((31)= −4.35,< 0.001, Cohen’s= −0.784;(31)= −2.90,= 0.021, Cohen’s= −0.512), 而两类复合词之间的差异不显著,(31)= −0.56,= 1.000。与早期结果不同的是, 该时间窗发现了显著的词汇类型与分区的交互作用, 表现为中央((2, 62) = 13.19,< 0.001, η2= 0.299)和后部((2, 62) = 10.78,< 0.001, η2= 0.258)电极都发现了显著的词汇类型效应, 但在前部电极上的词汇类型效应只达到边缘显著,(2, 62) = 2.41,= 0.098, η2= 0.072。三种词汇类型在中央和后部电极上的差异模式相同, 都是透明复合词要比单语素诱发更负的波幅(中央,(31) = −5.15,< 0.001, Cohen’s= −0.933; 后部,(31)= −4.93,< 0.001, Cohen’s= −0.893), 不透明复合词也要比单语素词诱发更负的波幅(中央,(31)= −3.54,= 0.004, Cohen’s= −0.627; 后部,(31)= −3.38,= 0.006, Cohen’s= −0.600), 而两类复合词之间的差异不显著(中央,(31)= −0.56,= 1.000; 后部,(31)= −0.49,= 1.000)。
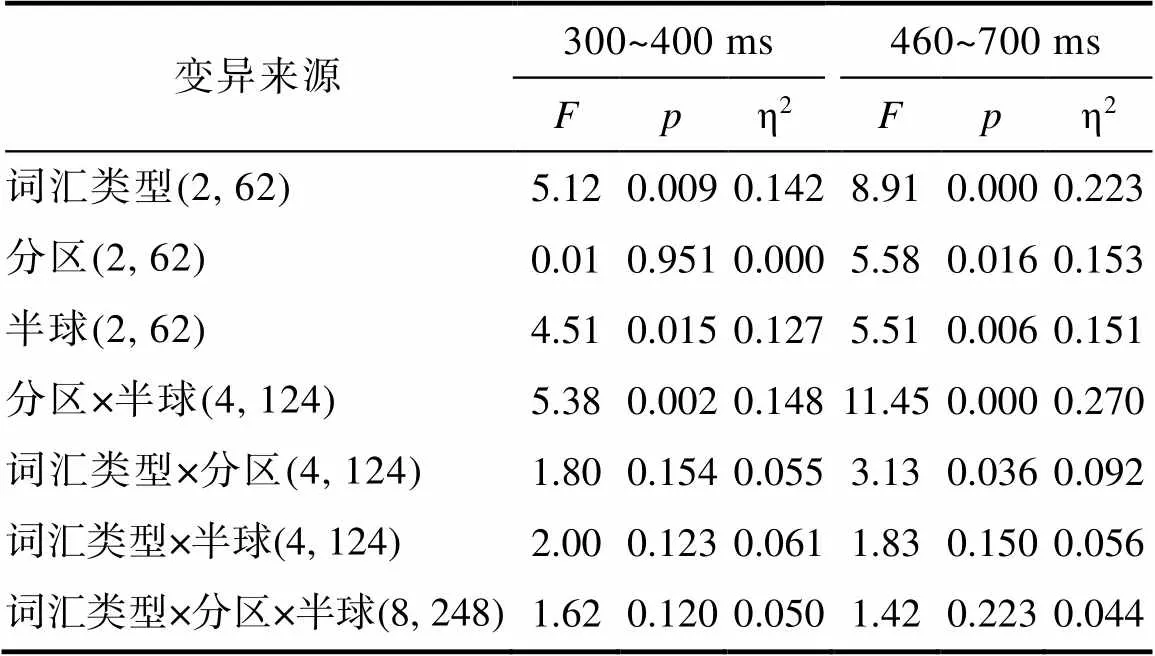
表2 首字诱发的平均波幅方差分析结果
晚期时间窗内同样发现了显著的半球主效应, 但只有左侧比中线电极的波幅更负, 而左侧与右侧、中线与右侧电极之间的差异均不显著。与早期时间窗口不同的是, 晚期时间窗口还发现了显著的分区主效应, 即前部和后部脑区比中央脑区诱发了更负的波幅, 而前部与后部脑区差异不显著。该时间窗内还发现了半球与分区的显著交互作用。晚期窗口的交互作用主要表现在中央((2, 62) = 7.21,= 0.002, η2= 0.189)和后部((2, 62) = 12.43,< 0.001, η2= 0.286)脑区的半球效应都显著。在中央脑区, 左侧和中线电极要比右侧电极的平均波幅更负, 而左侧与中线电极上的差异不显著。在后部脑区, 左侧和右侧脑区都要比中线脑区的波幅更负; 而左、右侧脑区之间的差异不显著。
3.2.2 尾字加工
在尾字下, 三种实验条件保留的有效试次也完全相同, 都保留了98.43%的有效试次。在尾字加工的两个时间窗(260~420 ms, 480~700 ms), 同样进行3 (词汇类型: 透明复合词/不透明复合词/单语素词) × 3 (半球: 左/中线/右) × 3 (分区: 前/中央/后) 的重复测量方差分析。各电极点的波形图及各效应地形分布图见图2所示, 方差分析的统计结果在表3中详细列出。另外, 分区、半球主效应显著情况下的事后检验分析结果以及分区×半球交互作用显著情况下的简单效应分析后续统计结果详见网络版附表3、附表4。

图2 A. 尾字加工中不同词汇条件诱发的平均波幅变化; B. 词汇类型主效应(上)、语素效应(中)、语义透明度效应(下)的地形分布图。
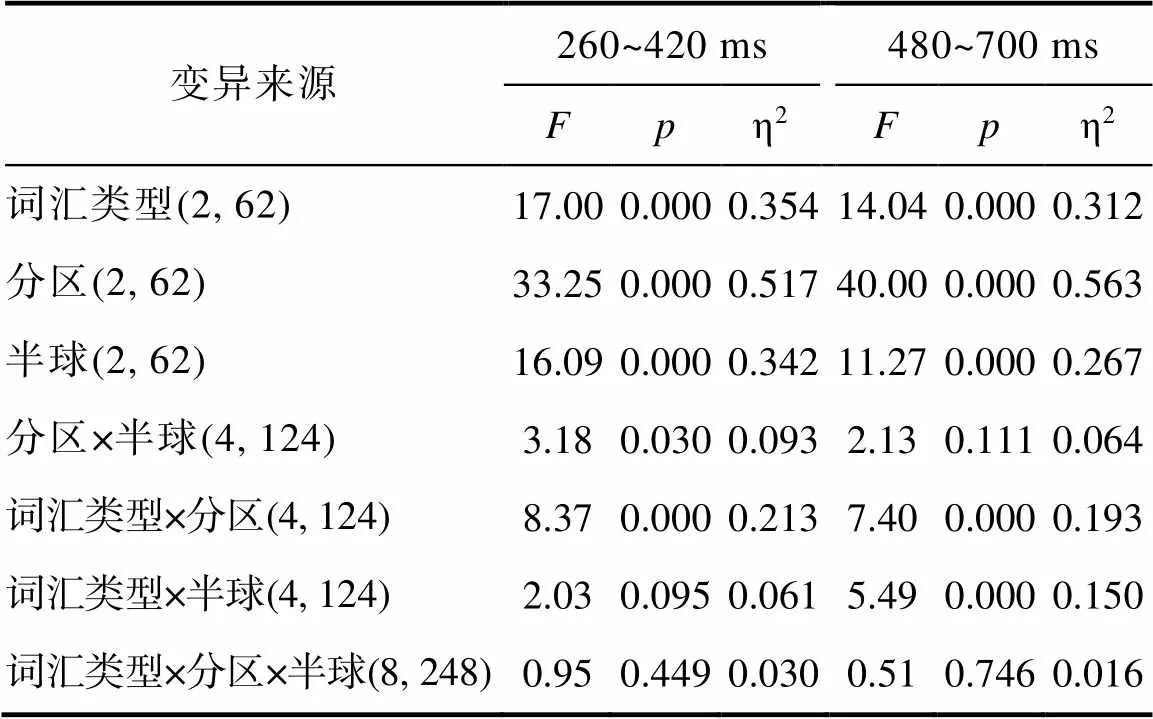
表3 尾字诱发的平均波幅方差分析结果
(1) 260~420 ms时间窗
在尾字加工的早期同样发现了显著的词汇类型主效应, 与首字的词汇类型效应相同, 都表现为透明和不透明这两类复合词要比单语素词诱发更负的波幅((31)= −3.72,= 0.002, Cohen’s= −0.670;(31)= −5.48,< 0.001, Cohen’s= −0.971), 但两类复合词之间的差异不显著,(31)= 1.61,= 0.353。
与首字加工不同的是, 尾字加工在早期窗口就发现了词汇类型与分区的显著交互作用, 而词汇类型与半球的交互作用仅达到边缘显著。进一步的简单效应分析发现, 词汇类型效应的显著性差异在前部((2, 62) = 13.74,< 0.001, η2= 0.307)和中央((2, 62) = 22.75,< 0.001, η2= 0.423)脑区表现出相同的模式, 而在后部脑区的词汇类型效应表现出另一种显著差异模式,(2, 62) = 10.80,< 0.001, η2= 0.258。在后部脑区, 结果发现了语义透明度效应, 即不透明复合词比透明复合词诱发了更负的波幅((31)= −2.72,= 0.032, Cohen’s= −0.514), 不透明复合词也比单语素词诱发了更负的波幅((31)= −4.63,< 0.001, Cohen’s= −0.824), 但透明复合词与单语素词之间差异未达到显著((31) = −2.11,= 0.128)。不同的是, 在前部和中央电极上, 两类复合词之间的差异并不显著((31) = −0.02,= 1.000;(31) = 1.95,= 0.180), 没有发现语义透明度效应, 而透明、不透明复合词都要比单语素词诱发更负的波幅(前部,(31) = −3.93,= 0.001, Cohen’s= −0.670;(31)= −4.25,= 0.001, Cohen’s= −0.754; 中央,(31)= −4.28,= 0.001, Cohen’s= −0.774;(31)= −6.49,< 0.001, Cohen’s= −1.149)。
在尾字加工的早期发现了显著的半球主效应, 表现为左侧电极比右侧和中线电极诱发的波幅更负, 而右侧与中线电极差异不显著。结果也发现了显著的分区主效应, 表现为前部分别比中央、后部脑区的波幅更负, 中央也比后部脑区的波幅更负。结果还发现了分区×半球的显著交互作用, 进一步简单效应分析发现, 在前部脑区发现的显著半球效应((2, 62) = 7.11,= 0.003, η2= 0.187)是因为左侧比中线脑区的波幅更负, 而左侧与右侧、中线与右侧脑区差异不显著。在中央脑区发现的显著半球效应((2, 62) = 14.00,< 0.001, η2= 0.311)是因为左侧比右侧和中线脑区的波幅更负, 而中线与右侧脑区差异不显著。而在后部脑区发现的显著半球效应((2, 62) = 11.26,< 0.001, η2= 0.266)是因为, 左侧比中线和右侧脑区的波幅都更负, 但中线与右侧脑区差异不显著。
(2) 480~700 ms时间窗
在尾字加工的后期时间窗口, 重复测量方差分析结果同样发现了显著的词汇类型主效应, 表现为透明复合词和不透明复合词都要比单语素词诱发了更正的波幅((31)= 4.08,= 0.001, Cohen’s= 0.722;(31)= 4.31,< 0.001, Cohen’s= 0.769), 而两类复合词之间的差异不显著,(31)= −0.13,= 1.000。
结果还发现了词汇类型×半球的交互作用显著, 词汇类型的简单效应在左侧((2, 62) = 12.50,< 0.001, η2= 0.287)、中线((2, 62) = 14.62,< 0.001, η2= 0.320)以及右侧((2, 62) = 12.92,< 0.001, η2= 0.294)电极点上都显著, 它们都表现出两类复合词之间的差异不显著(左侧,(31) = −0.42,= 1.000; 中线,(31)= −0.48,= 1.000; 右侧,(31)= 0.52,= 1.000), 而两类复合词都要比单语素词诱发更正的波幅, 只是词汇类型的差异量在不同半球上有所不同, 不透明复合词与单语素词在中线脑区((31)= 4.49,< 0.001, Cohen’s= 0.809)显著性最大, 在右侧((31) = 3.89,= 0.002, Cohen’s= 0.689)最小。
而且, 词汇类型与大脑分区之间的交互作用也显著。词汇类型的简单效应显著地表现在前部((2, 62) = 8.61,= 0.001, η2= 0.217)、中央((2, 62) = 11.66,< 0.001, η2= 0.273)和后部((2, 62) = 19.77,< 0.001, η2= 0.389)电极点上。三个分区上都发现两类复合词之间的差异不显著(前部,(31)= −1.44,= 0.481; 中央,(31)= 0.14,= 1.000; 后部,(31)= 0.80,= 1.000), 透明、不透明复合词都比单语素词诱发了更正的波幅, 只是差异量有所不同, 在后部脑区((31)= 5.20,< 0.001, Cohen’s= 0.922;(31)= 4.79,< 0.001, Cohen’s= 0.848)显著性最大, 而在前部((31)= 2.64,= 0.039, Cohen’s= 0.469;(31) = 3.67,= 0.003, Cohen’s= 0.672)最小。
尾字加工诱发的平均波幅在头皮分布上, 表现出显著的半球和分区主效应。在半球效应上, 主要是左侧比右侧的波幅更负, 也比中线波幅更负, 右侧比中线的波幅也要更负。显著的分区主效应主要表现为前部比中央和后部脑区的波幅更负, 而中央和后部电极的波幅差异不显著。
4 讨论
本研究采用ERP技术, 探讨了汉语复合词加工中词素意义整合的时间进程。结果发现在汉语双字词的首字加工中, 就表现出语素效应, 即两类复合词与单语素词之间的加工差异。而且, 在尾字加工的早期阶段就发现了两类复合词在后部电极点上的显著差异, 表现出语义透明度效应, 而在尾字加工的晚期阶段发现了反转的语素效应。研究结果揭示出汉语复合词词素意义的自动分解和整合加工的时间进程, 下面进行具体讨论:
4.1 汉语复合词识别加工中语素意义激活过程
本研究通过对比汉语复合词与单语素词的首字加工过程, 结果发现了两类复合词比单语素词诱发了更负的波幅。这与以往研究发现相一致, 都表明了在多语素词识别中语素会得到分解激活。例如, Lavric等人(2007)的一项ERP研究结果指出, 在早期时间窗口(140~260 ms)发现了语素相关−语义透明条件(如hunter−HUNT)下的神经启动效应与无语素相关−字形相关条件(如brothel−BROTH)下的神经启动效应存在显著差异。该结果说明了语素在加工早期阶段就得到了分解, 并且区别于单纯字形加工。本研究也在首字加工早期阶段, 表现出汉语复合词与单语素词之间的波幅差异。结果一方面说明了汉语语素也在早期加工阶段得到分解激活, 并作为独立表征单元加工, 而不仅仅是字形分析。另一方面, 首字发现的语素效应还可能是单纯由单字加工差异导致的, 需要在对首字更为精确地控制下才能排除这种可能, 比如字频。来自汉语歧义语素的fMRI研究结果显示, 同形异义条件在分布式脑网络中产生了显著的神经启动效应, 包括左侧颞上回、右侧枕下回等脑区(Zhao et al., 2021)。本研究结果也在全脑分布上表现出显著的语素效应, 说明了语素加工并非由单一脑区负责, 而是由众多脑区共同负责加工。
首字加工晚期同样也发现了语素效应, 但与早期电极分布模式不同的是, 晚期语素效应表现在中、后脑区。这表明了汉语语素得到激活之后, 可能在中、后部脑区得到进一步的语素意义加工, 从而影响到复合词语义通达的后续加工过程。此观点也得到了其他研究证据的支持。比如, Wu等人(2017)利用ERP技术考察汉语语素加工的神经加工过程, 结果发现了在早期加工阶段, 全脑上表现出共享语素条件与基线条件的显著波幅差异, 而在后期加工阶段发现了中、后部脑区的电极分布模式。还有研究者结合fMRI技术, 考察了德语复合词神经加工机制, 结果发现了真实存在的复合词更多激活了大脑后部的角回脑区(Forgács et al., 2012), 该脑区被认为是语义加工的重要脑区(Binder et al., 2009; Seghier, 2013)。一项法语的MEG研究结果显示, 语素加工涉及左侧颞下回、颞上回脑区的激活参与(Cavalli et al., 2016)。还有来自汉语歧义语素的fMRI研究结果显示, 双侧颞中回参与了歧义语素的意义加工(Zhao et al., 2021)。通过以上跨语言研究证据, 可以得出大脑中、后部脑区可能参与了语素意义加工。
在尾字加工中也表现出了显著的语素效应, 即两类复合词比单语素词诱发了更负的波幅。这一结果与拼音文字的行为研究(Ji et al., 2011; Rastle et al., 2004)以及ERP/MEG研究发现相一致(Coch et al., 2012; Fiorentino & Poeppel, 2007), 也与汉语研究的行为结果相一致(Yen et al., 2008; Zhou & Marslen-Wilson, 1995)。例如, Coch等人(2012)的ERP研究结果显示, 被试在阅读英语复合词时比英语单语素词汇诱发了更负的N400波幅(Coch et al., 2012)。本研究结果在尾字加工早期表现出的语素效应, 可能说明了在汉语复合词加工的早期阶段, 词素就得到了自动激活, 单语素词则无法进行分解加工, 所以表现出了两类复合词与单语素词的波幅差异。该观点也得到了来自拼音文字的研究证据支持。例如, Fiorentino和Poeppel (2007)的研究发现复合词在M350上的峰值潜伏期要显著早于单语素词, 复合词比单语素词更早的加工主要是词素意义的自动激活。研究者认为, 复合词与单语素词具有不同的加工通路, 复合词需要先进行词素分解加工, 而单语素词仅一个语素, 无法进行分解加工, 只能进行整词的语义通达加工(Coch et al., 2012; El Yagoubi et al., 2008)。
4.2 汉语语素意义影响复合词语义整合过程
本研究重要的发现是在尾字加工的相对早期(260~420 ms)阶段, 语义透明度效应显著, 表现为汉语不透明复合词比透明复合词诱发了更负的波幅。研究者认为, 这两类复合词加工都需要语素的自动分解, 它们的加工差异主要体现在语素意义的整合阶段(Brooks & Cid de Garcia, 2015)。有研究发现不透明复合词的记忆效果要好于透明复合词, 可能是因为不透明复合词检索到的整词意义与构成语素整合出来的意义之间不一致, 导致了更大程度的区别性(Han et al., 2014)。本研究在神经生理层面发现了语义透明度效应, 这一结果与前人研究结果(Lee et al., 2021; Tsang & Zou, 2022)共同说明了在汉语复合词加工中, 语义透明度能够稳健地调节词汇语义通达过程。重要的是, 本研究在尾字加工早期阶段, 就发现了不透明复合词比透明复合词激活了更负波幅, 这一结果为意义计算观点(El-Bialy et al., 2013; Ji et al., 2011; Tsang & Chen, 2014)提供了直接的神经生理证据, 表明语素意义会被自动激活并计算出整合意义, 进一步影响到复合词的整词语义通达。具体来说, 本研究采用并列式透明复合词, 其首、尾语素意义均与整词相关, 并且首语素与尾语素意义相近, 因此在首语素意义信息得到充分加工并能为后续加工提供语境信息的基础之上, 尾语素在早期加工阶段, 意义就得到了自动激活, 之后快速完成首、尾语素整合加工, 在线整合获取的意义与存储意义一致, 成功获取到心理词典中的词汇表征, 进而促进了整词语义获取。而不透明复合词中尽管语素意义得到了自动激活, 但语素整合获得的意义可能与存储意义存在冲突, 无法成功检索到复合词表征, 甚至阻碍整词意义的获取, 个体需要耗费更多认知资源来对不透明复合词进行加工, 因此不透明复合词诱发了更负的波幅。
在尾字加工的后期阶段, 透明复合词与不透明复合词之间不存在波幅差异, 语义透明度效应消失。有研究者指出, 语义透明度作为一种加工属性, 透明复合词与不透明复合词都能够进行语素分解及整合加工, 两类复合词不存在表征差异(El-Bialy et al., 2013; Ji et al., 2011; Momenian et al., 2021)。因此, 在尾字加工后期, 语义透明度效应消失, 说明了在尾字加工的后期阶段, 两类复合词已经完成了语素意义整合加工过程, 完成了复合词整词语义通达。但语素效应在尾字加工的后期阶段依然显著, 且与首字加工及尾字加工早期模式不同, 具体表现为两类复合词分别比单语素词诱发了更正的波幅。该阶段显示出来的语素效应差异可能不是反映了复合词语素意义的自动激活, 而是复合词整词语义进一步加工或者语素结构再分析。这一观点也得到了来自其他研究证据的支持。例如, 研究者使用MEG技术, 对比了英语复合词与单语素词的神经加工差异, 结果发现了在430~660 ms时间窗内, 透明复合词比单语素词更强地激活了颞上回后部, 研究者认为这可能反映的是复合词加工的延迟语义加工(Brooks & Cid de Garcia, 2015)。Kwon等人(2012)发现了大家族词比小家族词在500~700 ms时间窗内诱发了更正的波幅(Kwon et al., 2012)。还有研究者结合启动范式, 结果在450~500 ms发现了启动类型主效应, 语素相关启动条件比正字法相关启动条件诱发了更正的波幅(Beyersmann et al., 2014)。因此, 在多语素词加工的晚期阶段可能会进行广泛语义激活(Beyersmann et al., 2014; Brooks & Cid de Garcia, 2015)或者是语素结构再分析(Kim et al., 2022; Kwon et al., 2012)。
4.3 本研究理论贡献
本研究结合ERP技术, 利用汉语复合词的结构优势, 深入探究了汉语复合词语素意义与整词语义整合加工过程, 为汉语复合词的加工模型提供了神经生理证据。研究结果为Taft的词条模型提供了证据。该模型指出, 语素存在独立表征词条层, 并且在词汇识别的早期加工阶段语素形态及语义均发挥作用(Taft & Nguyen-Hoan, 2010)。本研究结果在首字加工早期就发现了语素效应, 说明语素在加工早期就得到了激活。词条模型还提出每个语素可能对应不同的词条, 这些词条涉及了语素语义表征, 因此首字后期表现出的语素效应可能反映了对语素意义的进一步加工。
研究结果还为混合表征模型(Libben et al., 2020; Pollatsek et al., 2000)提供了神经生理证据。该模型指出, 语素表征与整词表征都存在于心理词典之中, 复合词的识别是语素和整词激活相互作用的结果。本研究在尾字早期阶段表现出的语素效应, 说明了两类复合词识别过程中, 语素表征都会得到自动分解激活, 而单语素词则无法进行语素分解, 只能通过整词表征加工来获得词义。尾字加工早期出现的语义透明度效应说明了透明复合词可以通过语素整合过程从而顺利获取词义, 而不透明复合词语素整合加工则会阻碍整词语义获取, 转而直接进行了整词表征加工, 完成了语义通达。
4.4 局限与展望
本研究还存在两方面的问题需要深入探讨:
一方面, 我们发现了实验效应随着时间进程在头皮电极分布模式上的变化, 但受限于ERP技术, 对此发现的解释还需要结合高空间分辨率的fMRI进一步探讨。本研究发现了透明度效应的后部电极分布, 该结果可能反映了大脑后部区域对复合词语义整合加工的敏感性。与本研究结果一致的是, Bai等人(2008)在一项听觉复合词的研究中, 操纵了复合词语素意义一致性, 结果发现尾语素加工的语义不一致效应诱发的ERP波幅差异主要体现在后部脑区电极点, 研究者认为后部电极分布可能反映了复合词语素意义的整合加工(Bai et al., 2008)。但是, 与本研究结果不一致的是, Lee等人(2021)发现汉语复合词的语义透明度效应主要表现在左侧前额皮层。最新的一项汉语复合词研究利用功能性近红外光谱技术(fNIRS)同时结合EEG技术, 探究了汉语复合词加工的神经加工过程; 结果则是发现了左侧前额皮层, 尤其是额下回负责了语素解析加工, 而颞叶脑区则是负责了语义分析过程(Gao et al., 2022)。复合词的语素整合加工的脑机制究竟如何, 还需要结合fMRI以及经颅磁刺激(TMS)等技术, 展开深入地研究。
另一方面, 本研究在连续呈现刺激方式下深入探讨了汉语复合词内部语素语义与整词语义整合加工。连续呈现刺激方式在短语语义整合加工(Bemis & Pylkkänen, 2011; Zhang & Pylkkänen, 2015; Ziegler & Pylkkänen, 2016)研究中得到了应用, 能够很好探究语义整合加工的大脑机制。以往研究者通过对比启动词与目标词之间共享语素条件与无关条件产生的语素启动效应, 考察了汉语语素在复合词加工中的激活变化(Wu et al., 2020; 赵思敏等, 2017)。尽管结果发现在不同时间窗内语素影响了整词语义通达, 但是对于语素分解及整合过程并未得到细致地分离, 尤其是语素如何参与并影响复合词语义整合过程。本研究将连续呈现刺激方式与ERP技术相结合, 结果分别在首、尾字的加工过程中发现语素效应和语义透明度效应, 说明了汉语复合词的语素整合存在着语素分解、语素义通达以及语素义整合等复杂的加工过程。值得注意的是, 相比于同时呈现, 连续呈现方式可能加大了语素表征与整词表征加工之间的竞争。同时, 需要承认一点, 本研究的刺激呈现时间为800 ms, 首字和尾字都得到了充分加工, 这不仅使得语素意义表征得到了充分激活, 同时可能扩散激活更多的语义信息, 进而影响到整合加工。未来的研究可以通过对比不同的刺激呈现方式或者结合词汇歧义性等语言学属性来进一步展开研究, 对复合词加工过程背后的神经机制进行更加细致和深入地探讨。
5 结论
本研究结合汉语复合词的构词特点, 针对前人研究的不足, 采用ERP技术深入揭示了汉语复合词语素整合加工的时间进程。通过同时操纵和考察首、尾语素的语义透明度效应发生的时间进程, 结果发现复合词语素会被自动分解, 在首字阶段就能识别出复合词与单语素词的差异。首语素意义会被自动激活并影响尾语素的加工, 从而在尾字加工早期就表现出语素意义整合的语义透明度效应。研究结果为复合词的语素整合加工过程提供了神经生理证据。
Bai, C., Bornkessel-Schlesewsky, I., Wang, L. M., Hung, Y., C, Schlesewsky, M., & Burkhardt, P. (2008). Semantic composition engenders an N400: Evidence from Chinese compounds.(6), 695−699.
Bemis, D. K., & Pylkkänen, L. (2011). Simple composition: A magnetoencephalography investigation into the comprehension of minimal linguistic phrases.(8), 2801−2814.
Beyersmann, E., Iakimova, G., Ziegler, J. C., & Colé, P. (2014). Semantic processing during morphological priming: An ERP study., 45−55.
Binder, J. R., Desai, R. H., Graves, W. W., & Conant, L. L. (2009). Where is the semantic system? a critical review and meta-analysis of 120 functional neuroimaging studies.(12), 2767−2796.
Boylan, C., Trueswell, J. C., & Thompson-Schill, S. L. (2017). Relational vs. attributive interpretation of nominal compounds differentially engages angular gyrus and anterior temporal lobe.8−21.
Brooks, T. L., & Cid de Garcia, D. (2015). Evidence for morphological composition in compound words using MEG., 215.
Cavalli, E., Colé, P., Badier, J.-M., Zielinski, C., Chanoine, V., & Ziegler, J. C. (2016). Spatiotemporal dynamics of morphological processing in visual word recognition.(8), 1228−1242.
Chinese Linguistic Data Consortium. (2003).. Beijing, China: Tsinghua University, State Key Laboratory of Intelligent Technology and Systems, and Chinese Academy of Sciences, Institute of Automation.
Coch, D., Bares, J., & Landers, A. (2012). ERPs and morphological processing: The N400 and semantic composition.(2), 355−370.
Cohen, J. (1992). A power primer.,(1), 155−159.
El-Bialy, R., Gagné, C. L., & Spalding, T. L. (2013). Processing of English compounds is sensitive to the constituents’ semantic transparency.(1), 75−95.
El Yagoubi, R., Chiarelli, V., Mondini, S., Perrone, G., Danieli, M., & Semenza, C. (2008). Neural correlates of Italian nominal compounds and potential impact of headedness effect: An ERP study.(4), 559−581.
Faul, F., Erdfelder, E., Buchner, A., & Lang, A. G. (2009). Statistical power analyses using G*Power 3.1: Tests for correlation and regression analyses.,(4), 1149−1160.
Flick, G., Oseki, Y., Kaczmarek, A. R., Al Kaabi, M., Marantz, A., & Pylkkänen, L. (2018). Building words and phrases in the left temporal lobe.213−236
Fiorentino, R., Naito-Billen, Y., Bost, J., & Fund-Reznicek, E. (2014). Electrophysiological evidence for the morpheme- based combinatoric processing of English compounds.(1−2), 123−146.
Fiorentino, R., & Poeppel, D. (2007). Processing of compound words: An MEG study.(1), 18−19.
Forgács, B., Bohrn, I., Baudewig, J., Hofmann, M. J., Pléh, C., & Jacobs, A. M. (2012). Neural correlates of combinatorial semantic processing of literal and figurative noun noun compound words.(3), 1432−1442.
Frisson, S., Niswander-Klement, E., & Pollatsek, A. (2008). The role of semantic transparency in the processing of English compound words.(1), 87−107.
Gagné, C. L., & Spalding, T. L. (2016). Effects of morphology and semantic transparency on typing latencies in English compound and pseudocompound words.(9), 1489−1495.
Gao, F., Wang, R., Armada-da-Silva, P., Wang, M., Lu, H., Leong, C., & Yuan, Z. (2022). How the brain encodes morphological constraints during Chinese word reading: An EEG-fNIRS study.184−196.
Han, Y.-J., Huang, S., Lee, C.-Y., Kuo, W.-J., & Cheng, S. (2014). The modulation of semantic transparency on the recognition memory for two-character Chinese words.(8), 1315–1324.
Huang, H. W., Lee, C. Y., Tsai, J. L., & Tzeng, O. J. (2011). Sublexical ambiguity effect in reading Chinese disyllabic compounds.(2), 77−87.
Hsu, C.-H., Pylkkänen, L., & Lee, C.-Y. (2019). Effects of morphological complexity in left temporal cortex: An MEG study of reading Chinese disyllabic words., 168−177.
Ji, H., Gagné, C. L., & Spalding, T. L. (2011). Benefits and costs of lexical decomposition and semantic integration during the processing of transparent and opaque English compounds.(4), 406−430.
Kim, J., Kang, J., Kim, J., & Nam, K. (2022). Temporal dynamics of form and meaning in morphologically complex word processing: An ERP study on Korean inflected verbs., 101098.
Kim, S., & Pylkkänen, L. (2019). Composition of event concepts: Evidence for distinct roles for the left and right anterior temporal lobes., 18−27.
Koester, D., & Schiller, N. O. (2008). Morphological priming in overt language production: Electrophysiological evidence from Dutch.(4), 1622−1630.
Koester, D., & Schiller, N. O. (2011). The functional neuroanatomy of morphology in language production.(2), 732−741.
Kuo, L., & Anderson, R. C. (2006). Morphological awareness and learning to read: A cross-language perspective., 161−180.
Kwon, Y., Nam, K., & Lee, Y. (2012). ERP index of the morphological family size effect during word recognition.(14), 3385−3391.
Lavric, A., Clapp, A., & Rastle, K. (2007). ERP evidence of morphological analysis from orthography: A masked priming study.(5), 866−877.
Lee, H.-J., Cheng, S., Lee, C.-Y., & Kuo, W.-J. (2021). The neural basis of compound word processing revealed by varying semantic transparency and morphemic neighborhood size.104985.
Leminen, A., Smolka, E., Duñabeitia, J. A., Pliatsikas, C. (2019). Morphological processing in the brain: The good (inflection), the bad (derivation) and the ugly (compounding)., 4−44.
Libben, G., Gagné, C. L., & Dressler, W. U. (2020). The representation and processing of compounds words. In V. Pirrelli, I. Plag & W. Dressler (Eds.),(pp. 336−352). Berlin, Boston: De Gruyter Mouton.
Liu, P. D., & Mcbride-Chang, C. (2010). Morphological processing of Chinese compounds from a grammatical view.(4), 605−617.
Lo, J. C. M., McBride, C., Ho, C. S., & Maurer, U. (2019). Event-related potentials during Chinese single-character and two-character word reading in children.103589.
Maurer, U., Schulz, E., Brem, S., der Mark, S. van, Bucher, K., Martin, E., & Brandeis, D. (2011). The development of print tuning in children with dyslexia: Evidence from longitudinal ERP data supported by fMRI.(3), 714−722.
Momenian, M., Radman, N., Rafipoor, H., Barzegar, M., & Weekes, B. (2021). Compound words are decomposed regardless of semantic transparency and grammatical class: An fMRI study in Persian.103120.
Peng, D., Ding, G., Wang, C., Taft, M., & Zhu, X. (1999). The processing of Chinese reversible words——the role of morphemes in lexical access.(1), 36−46.
[彭聃龄, 丁国盛, 王春茂, Marcus Taft, 朱晓平. (1999). 汉语逆序词的加工——词素在词加工中的作用.(1), 36−46.]
Pollatsek, A., Hyönä, J., & Bertram, R. (2000). The role of morphological constituents in reading Finnish compound words.(2), 820−833.
Rastle, K., Davis, M. H., & New, B. (2004). The broth in my brother’s brothel: Morpho-orthographic segmentation in visual word recognition(6), 1090−1098.
Seghier, M. L. (2013). The angular gyrus: Multiple functions and multiple subdivisions.(1), 43−61.
Taft, M. (2003). Morphological representation as a correlation between form and meaning. In E. Assink & D. Sandra (Eds.),(pp. 113−137). Amsterdam: Kluwer.
Taft, M. (2004). Morphological decomposition and the reverse base frequency effect.(4), 745−765.
Taft, M., & Nguyen-Hoan, M. (2010). A sticky stick? The locus of morphological representation in the lexicon.(2), 277−296.
Tsai, C.-H. (1994).(Unpublished master's thesis). National Chung Cheng University, Taiwan, China.
Tsang, Y.-K., & Chen, H.-C. (2013). Early morphological processing is sensitive to morphemic meanings: Evidence from processing ambiguous morphemes.(3), 223−239.
Tsang, Y.-K., & Chen, H.-C. (2014). Activation of morphemic meanings in processing opaque words.(5), 1281−1286.
Tsang, Y. -K., & Zou, Y. (2022). An ERP megastudy of Chinese word recognition.(11), e14111.
Tsang, Y.-K., Zou, Y., & Tse, C.-Y. (2022). Semantic transparency in Chinese compound word processing: Evidence from mismatch negativity.216−223.
Wu, J., Chang, J., Qiu, Y., & Joseph, D. (2020). The temporal process of visual word recognition of Chinese compound: Behavioral and ERP evidences based on homographic morphemes.(2), 113−127.
[吴建设, 常嘉宝, 邱寅晨, Joseph, D. (2020). 汉语复合词视觉识别的时间进程: 基于同形语素的行为与ERP证据.(2), 113−127.]
Wu, Y., Duan, R., Zhao, S., & Tsang, Y.-K. (2020). Processing ambiguous morphemes in Chinese compound word recognition: Behavioral and ERP evidence.249−260.
Wu, Y., Tsang, Y.-K., Wong, A. W.-K., & Chen, H.-C. (2017). The processing of homographic morphemes in Chinese: An ERP study.(1), 102−116.
Yen, M.-H., Tsai, J.-L., Tzeng, O. J.-L., & Huang, D. L. (2008). Eye movements and parafoveal word processing in reading Chinese.(5), 1033−1045.
Zhang, L., & Pylkkänen, L. (2015). The interplay of composition and concept specificity in the left anterior temporal lobe: An MEG study., 228−240.
Zhang, R., Wang Z., Wang X., & Yang J. (2021). N170 adaptation effect of the sub-lexical phonological and semantic processing in Chinese character reading.(8), 807−820.
[张瑞, 王振华, 王小娟, 杨剑峰. (2021). 汉字识别中亚词汇语音和语义信息在N170上的神经适应.(8), 807−820.]
Zhao, S., Wu, Y., LI, T., & Guo, Q. (2017). Morpho-semantic processing in Chinese word recognition: An ERP study.(3), 296−306.
[赵思敏, 吴岩, 李天虹, 郭庆童. (2017). 词汇识别中歧义词素语义加工:ERP研究.(3), 296−306.]
Zhao, S., Wu, Y., Tsang, Y.-K., Sui, X., & Zhu, Z. (2021). Morpho-semantic analysis of ambiguous morphemes in Chinese compound word recognition: An fMRI study., 107862.
Zhou, X. L., & Marslen-Wilson, W. (1995). Morphological structure in the Chinese mental lexicon.(6), 545−600
Zhou, X. L., Marslen-Wilson, W., Taft, M., & Shu, H. (1999). Morphology, orthography, and phonology in reading Chinese compound words.(5-6), 525−565.
Ziegler, J., & Pylkkänen, L. (2016). Scalar adjectives and the temporal unfolding of semantic composition: An MEG investigation., 161−171.
Zou, L., Packard, J. L., Xia, Z., Liu, Y., & Shu, H. (2016). Neural correlates of morphological processing: Evidence from Chinese., 714.
Zou, L., Packard, J. L., Xia, Z., Liu, Y., & Shu, H. (2019). Morphological and whole-word semantic processing are distinct: Event related potentials evidence from spoken word recognition in Chinese., 133.
Time course of the integration of the morpho-semantics and the meaning of two-character Chinese compound words
CAI Wenqi, ZHANG Xiangyang, WANG Xiaojuan, YANG Jianfeng
(School of Psychology, Shaanxi Normal University, Xi’an 710062, China)
Previous studies have shown that morpho-semantic information can be activated automatically and influence the access of word meaning in compound word recognition. However, the time course underlying the morpho-semantic activation and its subsequent integration is not clear yet. In particular, little is known about how morpho-semantic information involves in word semantic integration processing.
The present study examined the time course of morpho-semantic information of the first and the second characters who participated in whole-word semantic integration processing using event-related potential (ERP) technology. We selected three types of two-character words: transparent, opaque compound words, and monomorphemic words. For the transparent words (e.g., 炽热), both two characters’ meanings (both 炽 and 热 mean hot) were identical or similar to the word meaning (炽热 means hot). As for the opaque words (e.g., 风流), the meaning of the first character (风means wind), the second character (流 means flow), and the compound word (风流 means amorousness) were completely different. The monomorphemic words (e.g., 伶俐) were materials as the control condition with two characters that cannot be split into two morphemes. Participants were instructed to complete a visual lexical decision task.
ERP results showed that the first character processing revealed the morphological effect in the early (300~400 ms) and the late (460~700 ms) time window, in which two types of compound words induced more negative amplitude than the monomorphemic words. During the second character processing, a significant semantic transparency effect was observed in the early stage (260~420 ms), that the opaque words evoked more negative-going waveform than the transparent ones. Whereas at the late phase (480~700 ms), a reversed morphological effect emerged that the two types of compound words evoked more positive amplitude than the monomorphemic words.
The present study shed light on the time course of morpho-semantic integration in Chinese compound word recognition. The results indicated that the morpho-semantic processing began at the early stage of processing the first character. The transparent morpho-semantic of the first character influences the second character’s morpho-semantic activation and subsequently facilitates the semantic access of the compound words.
semantic integration, compound word, semantic transparency, ERP
2022-06-15
* 国家自然科学基金(31671167), 中央高校基本科研业务费专项资金(GK202101010, 2021TS098), 北京师范大学中国基础教育质量监测协同创新中心研究生自主课题(BJZK-2021A3-21011)资助。
王小娟, E-mail: wangxj@snnu.edu.cn; 杨剑峰, E-mail: yangjf@snnu.edu.cn
B842
