融合YOLO v3与改进ReXNet的手势识别方法研究
2023-08-03魏小玉焦良葆刘子恒汤博宇
魏小玉,焦良葆,刘子恒,汤博宇,孟 琳
(南京工程学院 人工智能产业技术研究院,南京 211167)
0 引言
智能驾舱系统可显著提升汽车用户体验感,已成为汽车行业发展的重点之一。手势识别作为一种重要的人机交互方式,在智能驾舱中得到了广泛的应用。一般来说,手势识别常采用接触式和非接触式两种检测方法。基于传感器的接触式手势检测,因在智能驾舱等应用场景条件有限的情况下,难以实现以最小的驾舱成本达到同样基于计算机视觉的手势检测效果,而且会给用户带来不舒适的驾驶体验,甚至增加驾驶风险。因此在智能驾舱系统设计中采取基于计算机视觉的非接触式手势识别方法,用手部关键点定位技术进行手势约束,实现人机交互更符合应用场景。目前研究手势识别的主流网络,根据场景需求不同,算法侧重也各有不同。
多数的手势实时检测方法,研究方式重点在于直接进行手势的特征提取。而手势特征提取方法大多采用神经网络的方式,Di Wu[1]等人提出了一种用于多模态手势识别的深度动态神经网络(DDNN,deep dynamic neural networks),能够同时进行目标姿势分割和识别,检测效果良好。于此,在如何提高手势检测的整体效果,文献[2]中提出了一种采用聚合通道特征(ACF,aggregate channel feature)与双树复小波变换(DTCWT,dual-tree complex wavelet transform)的手势识别算法,以求在不同环境下都能够保持很好的识别精度。除了从选择不同算法角度,在图像处理,函数改进等方面作提升也可以达到相同的结果。KeKe Geng[3]等人提出在红外图像中采用改进的YOLO v3(you only look once v3)手势检测模型网络,较传统可见光下的数据呈现方式,可以更好地拟合人体手部姿态并减少噪声干扰。LYU Shuo[4]等人则是在改进YOLO v3和方差损失函数(SSE,sum of squared error loss)的基础上,降低Sigmoid对梯度消失的影响,来提高模型检测精度。在人体手部姿态的小目标定位分类检测中,手势特征关键点的提取精度至关重要。文献[5]中采用支持向量机(SVM,support vector machine)的方式对小目标快速计算并分类。而王婧瑶[6]等人则是提出一种基于蒙版区域的卷积神经网络(Mask R-CNN,Mask Region-based Convolutional Neural Network),与多项式平滑算法(SG,Savitzky-Golay)的手势关键点提取技术且较WANG Sen-bao[7]等提出的手部21关键点检测模型,进一步对数据进行平滑处理,有效的提升了模型检测精度。而在不输深度目标检测网络的出色表现且兼具方便嵌入小型终端使用,文献[8]中提出了构建轻量型的手势实时检测分类网络,相较于文献[9]在深层网络增加密集连接层来提高复杂环境下的实时检测效果,有效的减轻了计算量和参数量的问题。
在侧重依赖于快速且实时的基础上,本文同样采用了轻量型神经网络的方式进行手部识别检测。为进一步提高整体的检测精度,改进了ReXNet轻量型网络的网络架构及损失函数。而在考虑提高后续实验项目的拓展性与可移植性的问题上,采用先进行人体手部识别再进行关键点定位检测的方式,而非直接训练手部动作分类。实验结果表明,轻量型网络模型训练不会占用太多资源且改进后的网络有更高的检测精度,具有很强的实用性研究意义。
1 YOLO v3手部检测模型
手部识别部分方法采用YOLO v3作为手部特征提取网络。YOLO v3在YOLO前两代的基础上改进缺点,均衡了目标检测的速度和精度以及重点解决了小物体检测的问题。本文选用YOLO v3网络模型对手部特征bounding box的w、h、x、y以及置信度进行训练。模型损失函数采用均方差(MSE,mean square error)。
YOLO v3算法:
对于手部特征目标实时检测的应用要求,处理回归问题的算法模型YOLO v1,自2016年发表的论文You Only Look Once:Unified,Real-Time Object Detection后,算法也正式发布。与经典目标检测方法相比,深度神经网络特征提取能力更强,准确率更高。YOLO系列较CNN模型被称为One-Stage方法,将先生成候选框与再分类回归两步同时进行,以此大大降低了计算复杂度,加快了检测速度。根据Joseph Redmon等发布的YOLO v3算法,在COCO数据集上较YOLO v2 mAP-50的44.0%提高到57.9%,很好的提升了模型识别准确率。
YOLO v3算法通过卷积层特征提取网络,对输入特征提取输出检测结果,得到特定大小的特征图输出。算法在3种不同下采样尺度上进行,通道数为3,检测结果包括bounding box的中心位置xy,宽高wh,置信度。针对人体手部的小目标检测,在32倍下采样呈现的小尺度,大视野上,有更好的预测效果。
手部识别模型采用的MSE Loss常用在回归任务中,根据公式:
(1)
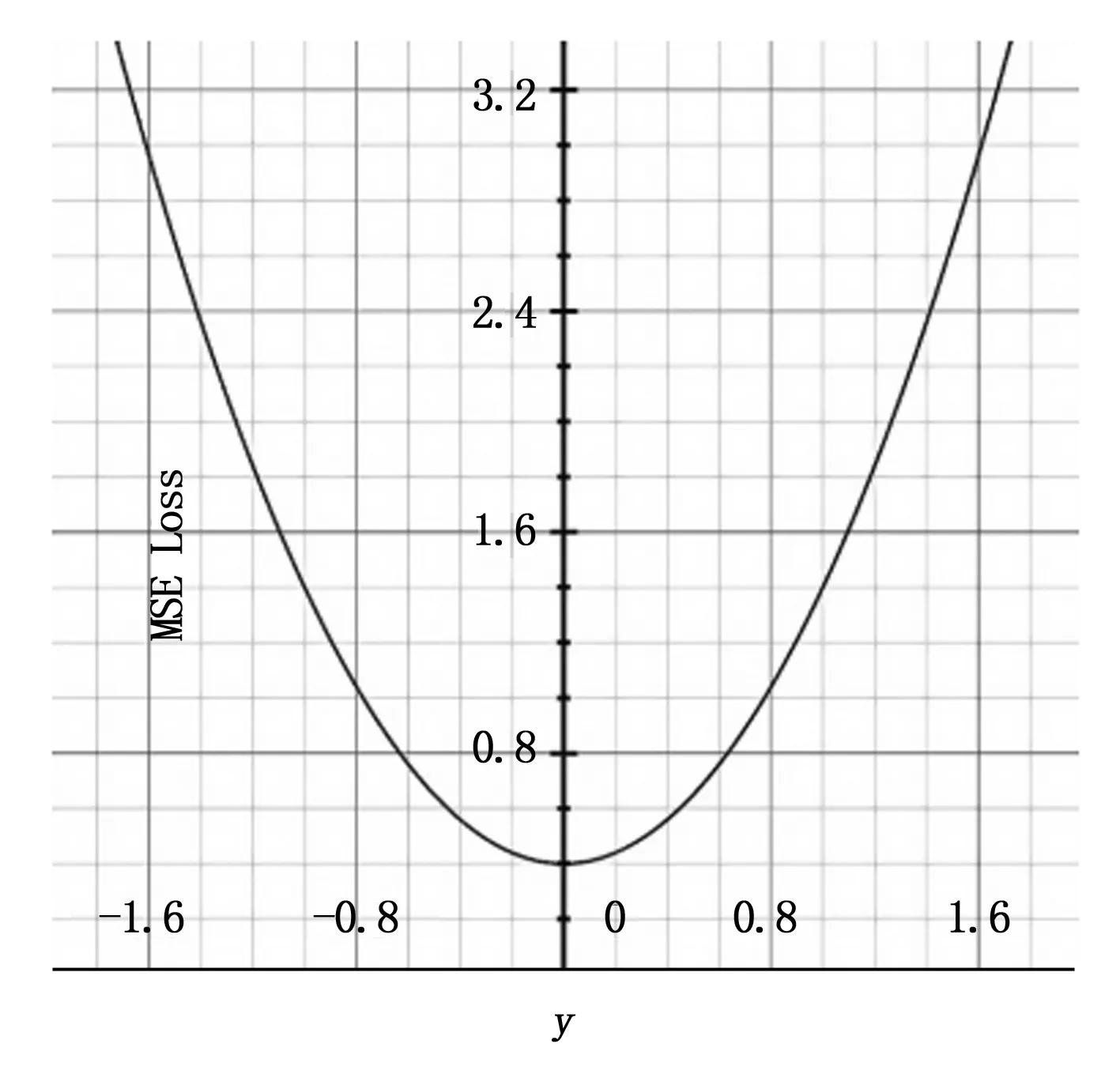
图1 MSE函数曲线图
其中,模型误差包含计算坐标误差,置信度误差和分类误差。置信度公式如下:
(2)
2 改进的ReXNet手部关键点检测模型
手部关键点代表的信息本质上不是单个的点的信息,描述的是手部这个固定区域的组合信息,表征不同关键点间的确定关系,是对手部物理空间的定位描述。通过点回归和关系回归的方式进行手部特征标注。不同于人体大目标检测手部特征的定位识别,手势姿态定义类似于人脸特征点检测和人体姿态估计的骨骼关键点检测,需要在定位出手部关键点后通过约束骨骼向量角来定义不同手势指令。
关键点检测模型采用改进ReXNet网络结构,改定位损失函数MSE Loss为平滑平均绝对误差(Huber Loss),并替换ReXNet的卷积层为Ghost Module。在采用轻量型网络的优点的同时进一步提升ReXNet网络应用于关键点检测的模型效果。
2.1 ReXNet网络架构改进
ReXNet网络的设计初衷是为了解决现有网络的特征表现瓶颈问题,网络中间层常出现因对输入特征的深度压缩,而导致输出特征的明显减少,甚至丢失特征的现象。本文在关键点检测模型上采用改进的ReXNet网络架构,实现在参数量少的情况下消除表现瓶颈问题,增强21手部骨骼点的局部关注,提升网络对关键点的识别性能及识别准确度。
2.1.1 ReXNet网络及Ghost Module
ReXNet本身是在MobileNetV2轻量化网络的基础上进行改进,以适当的调整有效减轻了现有网络的特征表现瓶颈问题。其中,倒残差结构(Inverted Residuals)、线性瓶颈(Linear Bottleneck)以及SENet(Squeeze-and-Excitation Networks)中提出的SE(Squeeze-and-Excitation)模块三部分是构成轻量化神经网络MobileNetV2的重要基础。ReXNet在结合改进的增加网络通道数,替换激活函数为Swish-1函数以及设计更多扩展层的方式来减轻网络的特征表现瓶颈问题,形成ReXNet轻量型网络的基础模型结构。
ReXNet模型在对数据的处理方式上同大多数CNN模型一样,在通过优化算法后,提高了对数据的处理能力,加快了计算效率,有效的节约了计算资源。通过提升网络模块数据秩的思路,解决尽可能完全提取图像特征不压缩的问题,贯穿轻量型神经网络的设计始终。ReXNet轻量化网络的一种关键构建块,深度可分离卷积构成的倒残差结构,其基本思想是通过分解的卷积运算符来替代完整的卷积算子,使用少量的算子及运算达到相同的计算效果。
倒残差结构能够有效的避免当常规卷积核的参数出现较多0时,即卷积核没有起到特征提取网络的作用,造成特征信息丢失的问题。利用倒残差结构能够很好地获取到更多的特征数据信息,进而提升模型的训练效果。倒残差结构在网络结构上主要采用了先升维的操作,也就是先进行扩展层的扩充,扩展倍数由扩展因子控制,此时升维卷积层的激活函数为ReLU6,主要目的是为了获取到更多的特征提取信息。接着再进行深度卷积(DW,Depthwise Convolution)的特征提取工作,此时的特征提取卷积层的激活函数为ReLU6。最后进行降维压缩的卷积处理,激活函数为线性激活函数。整体的网络结构呈现两头小,中间大的形状。这也是与残差结构很不同的一点,两者呈现的是完全相反的结构,因此称为倒残差结构。
在倒残差结构的降维卷积层中使用线性激活函数,为避免采用了常规的ReLU激活函数后,将高维信息映射到低纬空间中,进行空间维度的转换时造成的信息丢失。而线性激活函数会降低这种信息损失。在倒残差结构中,从高维映射到低维的缩减通道数,实现卷积降维的网络结构称为线性瓶颈。
可分离卷积分为空间可分离卷积和深度可分离卷积。ReXNet网络的核心卷积层即基于深度可分离卷积。深度可分离卷积将普通卷积拆分为深度卷积和逐点卷积(PW,pointwise convolution)。深度卷积通过对每一个的输入通道应用单独的卷积滤波器来执行轻量级滤波,逐点卷积通过对输入通道的线性组合构建新特征,实现对特征图的升维和降维。
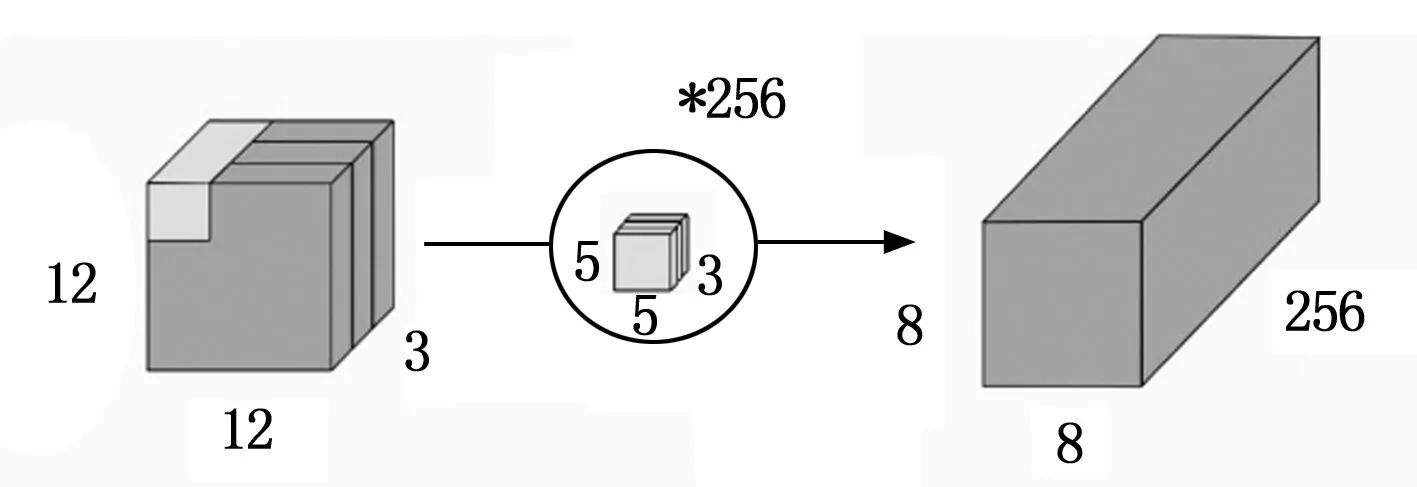
图2 标准卷积
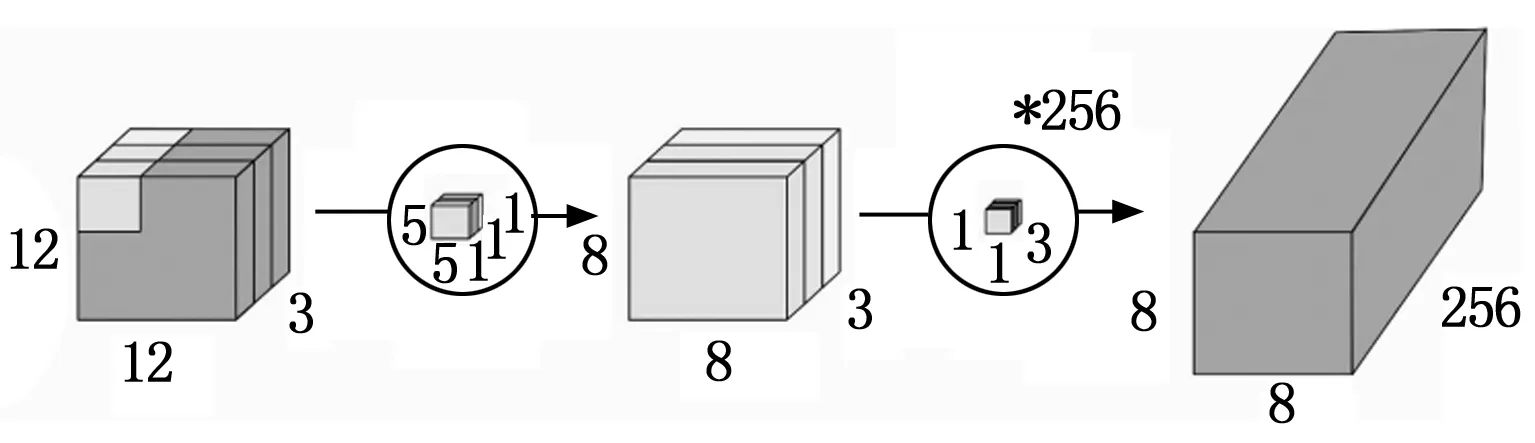
图3 深度可分离卷积
在ReXNet网络中间卷积层嵌入SE模块,以轻微的计算性能损失来提升准确率,在关键点检测模型中有很好的训练效果。SE模块作为改进模型注意力机制的常用模块,其先通过Squeeze操作从每个通道空间的角度进行特征压缩,再通过Excitation操作为每个特征通道生成独立权重,最后将每个通道的权重值与原特征图对应通道进行相乘加权,以此操作达到提升ReXNet网络通道注意力机制的效果。SE模块能够实现从含有大量冗余的信息中获取所需的重要内容,进而提升模型的整体训练精度。
Ghost Module的实质是通过减轻模型计算量来进行提升整体的训练效率。20年华为诺亚方舟实验室提出的Ghost Net新型神经网络框架,核心模块Ghost Module可以移植部署到其他CNN网络中,实现“即插即用”改进现有网络,提升实验效果。Ghost Module操作分为常规卷积过程、Ghost特征图生成以及恒等映射特征图的拼接三步,过程如下:
1)先用常规卷积得到本征特征图;
2)通过φi,jcheap operate操作得到Ghost特征图,及恒等映射得到本征特征图;
3)将第二步中的本征特征图与Ghost特征图拼接得到输出结果。
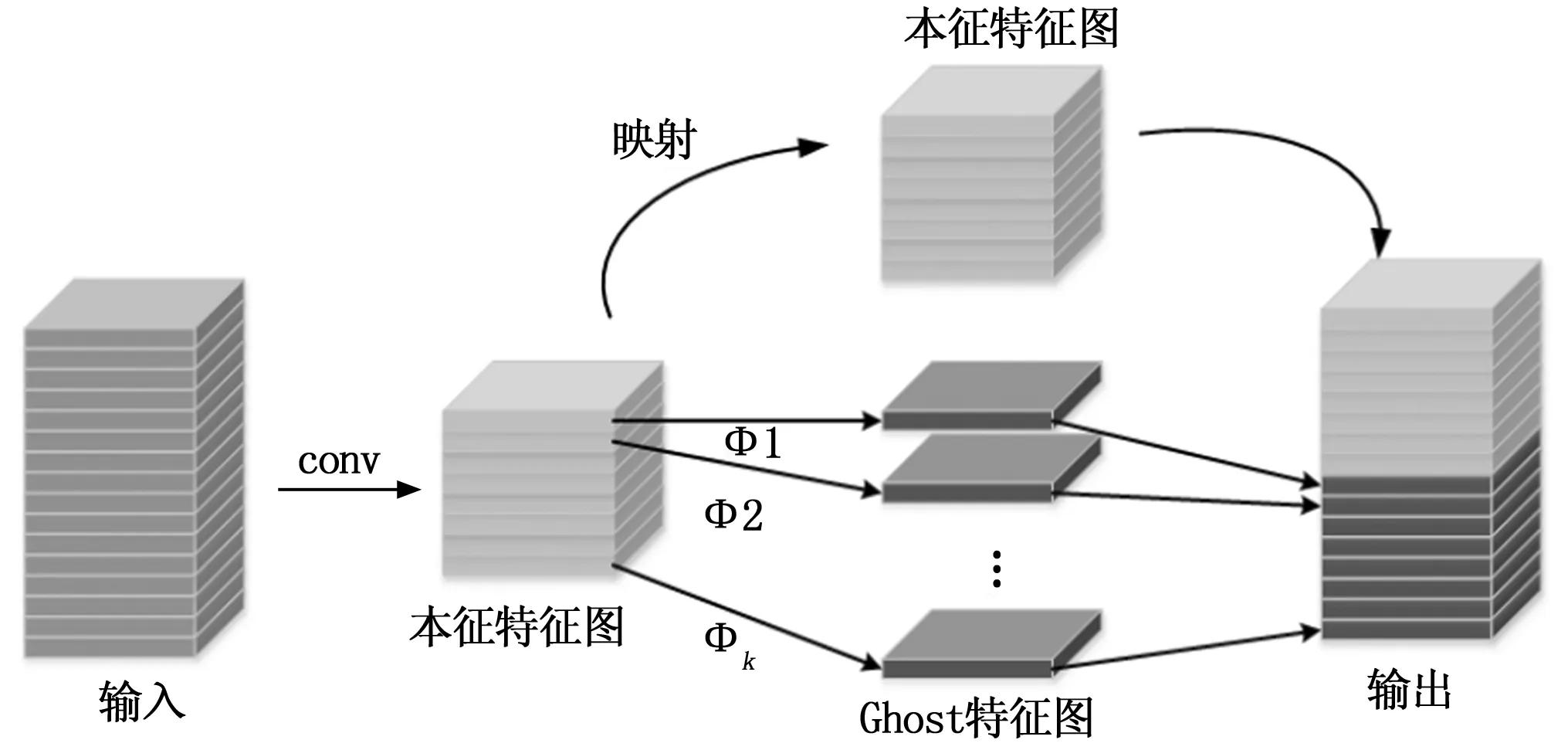
图4 The Ghost Module
2.1.2 新的ReXNet网络架构
基于以上,改进操作在结合ReXNet轻量型网络的模型结构基础上,在基于减少计算量以及兼具一定的识别准确度的基础上用Ghost Module模块对ReXNet进行网络结构的调整。基于设计的网络结构的具体实用效果,本文在通过多次实验改进网络结构的模型训练结果下,最后采用替换倒数第二层卷积为Ghost Module。相比较常规卷积,Ghost Module可以大幅度的减小计算量,改进后的网络结构如图5所示。
图5 关键点检测网络模型结构图
2.2 损失评价函数改进
在改进ReXNet网络架构后,模型适配损失函数改MSE Loss为Huber Loss。作为在处理回归问题中常用的损失函数之一,Huber loss很好的继承了MSE和MAE的优点,对于离群点抗干扰性强于MSE,Loss下降速度优于MAE,速度接近MSE。在保证模型能够准确的找到全局最优值的同时还能使其以最快的速度更新模型参数。其中,Huber loss计算公式如下:
(3)
一般采用Lδ(y,f(x))表示,衡量真实值y与预测值f(x)之间的近似程度,一般越小越好。对于Huber loss计算公式中引入的超参数δ,其不同于模型参数,需要在模型训练中根据数据收敛效果进行认人为调整。当δ趋近于0时,Huber loss会趋近于MAE,当δ趋近于∞时,Huber loss就会趋近于MSE。在实际实验过程中,因轻量型神经网络的自身优点,调整优化Huber损失函数参数,提升整体的手部关键点检测精度,并未占用太多时间资源。
3 实验设计和实验结果分析
本文以改进ReXNet轻量型网络,减少模型训练量提高检测精度为重点。实验通过YOLO v3手部检测与改进的ReXNet手势关键点定位,进而约束手部骨骼点向量角定义的不同手势后,检测手势并判断,最后达到实时检测的效果。本文实验操作流程如图6所示。
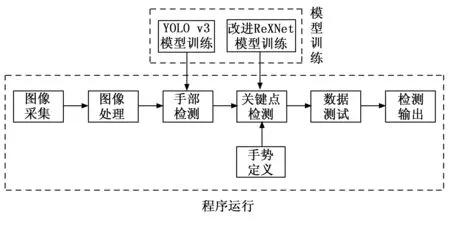
图6 实验流程图
3.1 手部检测模型训练
手部识别模型训练采用TV-Hand以及COCO-Hand的部分数据集,图像数目为32417。其中,TV-Hand选自ActionThread数据集的部分数据。
ActionThread数据集是由各种电视剧提取的人类动作图像帧组成,依据其来源于诸多电视剧,采用多角度的摄像机拍摄以及剧集中不同级别的手部遮挡,TV-Hand所用的难易样本足够均匀且场景够多。MS COCO(Microsoft Common Objects in Context)数据集是微软出资标注的公开数据集,有80个类别超50万个目标标注,本文采用其中Hand-big部分的数据集并结合TV-hand数据集进行YOLO v3手部识别模型训练。
模型训练实验数据表明,设置epoch为219,学习率为0.001时结果拟合较好。模型保存bounding box的w、h、x、y以及置信度的best loss实验结果如表1所示。

表1 best loss
如图7所示,模型训练各项收敛指标,拟合效果良好。
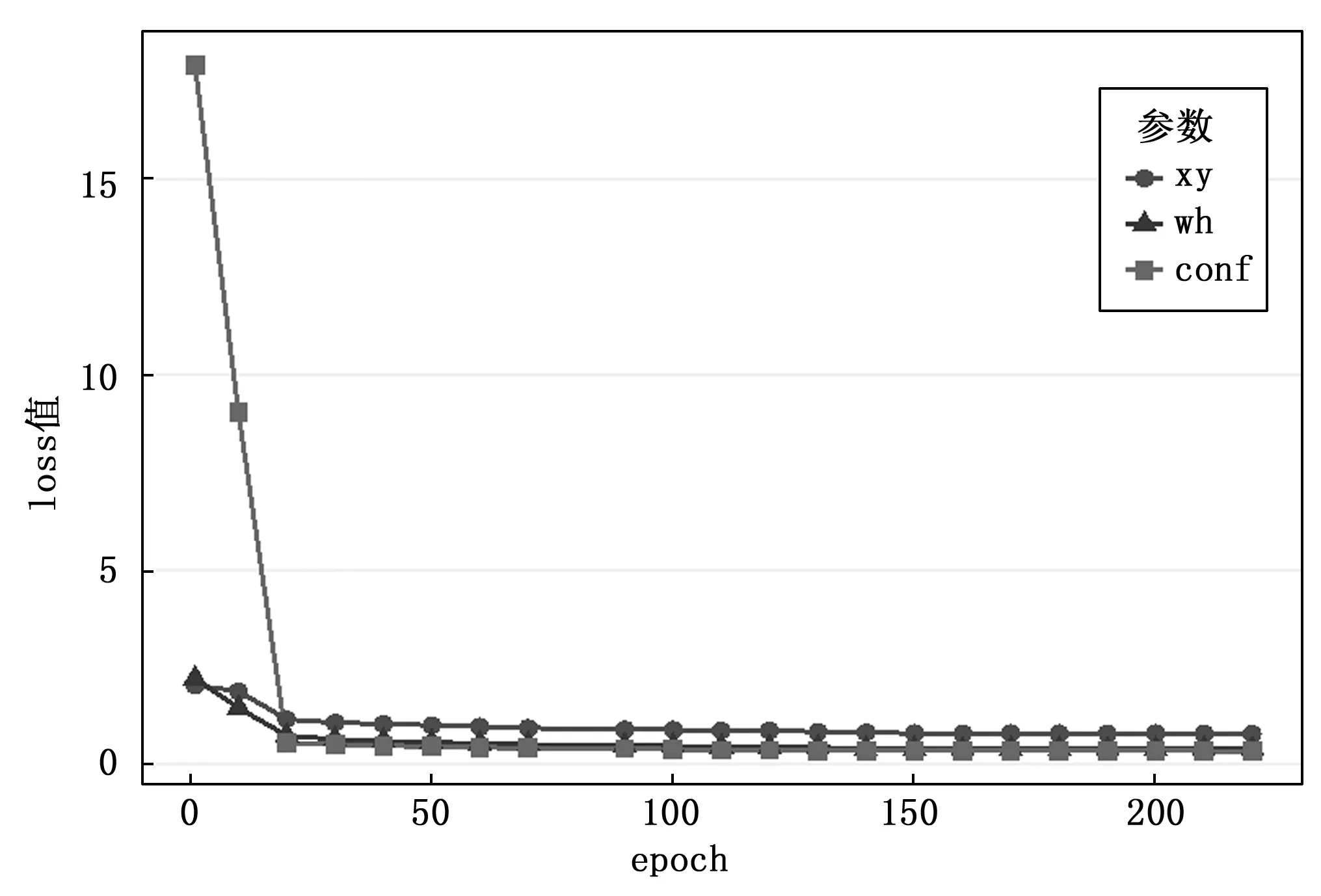
图7 Loss收敛图
3.2 关键点检测模型训练
关键点检测模型训练采用开源数据集Large-scale Multiview 3D Hand Pose Dataset及部分网络手部图片共49 060个数据样本。样本原出项目“handpose x”筛选整理部分图片合集。实验针对改进前后的网络模型,比较了训练参数的变化。
在统计训练日志loss值,绘制收敛对比图后,从图7可以清晰的看出,模型改进前后都具有很好的拟合结果。但较改进前的模型来说,优化后的模型实验效果更好。对比两次训练控制变量,设置epoch为100,学习率为0.001,batch size为10,参数一致。两轮模型训练结束保存最优loss结果如表2所示。
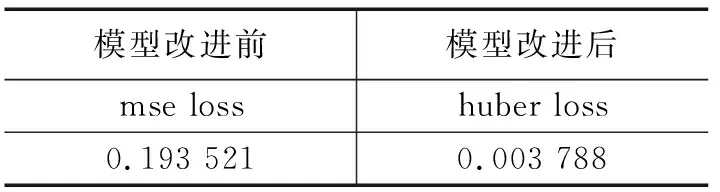
表2 最优loss对比表
如图8所示,对比改进前后关键点检测模型Loss收敛图可知,关键点损失值整体减小,拟合效果更好。
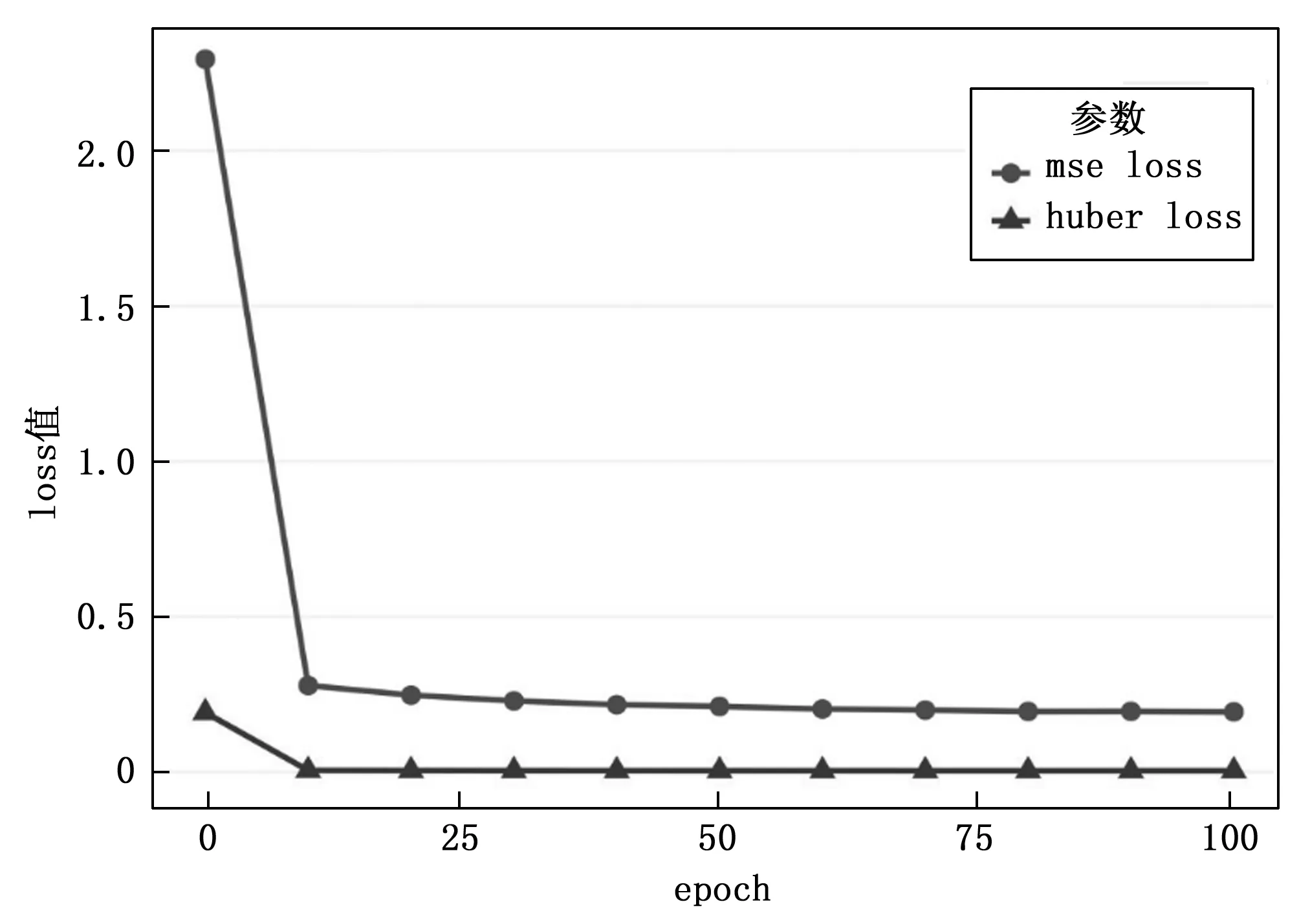
图8 Loss收敛对比图
3.3 手势定义
手势定义在基于对手部21关键点进行检测确定位置后,将同一顺序批次的关键点进行连线,标出表示当前手指。最后通过约束骨骼点间连线的二维角度定义不同手势。
手势骨骼点向量角度约束如图9所示,根据设定手指的上下关节夹角经验阈值,判断手指的弯曲程度,并定义此时手指为伸直或弯曲。约束不同手指的角度定义手势,原理简单,便于操作实现。

图9 角度约束
本实验通过角度约束,共定义了5个手势,分别为one,two,three,four,five,每种手势由5个手指弯曲角度组合定义。出于实验验证角度考虑,实验手势含义,由手指固定姿态确定。表3中数值范围为手指弯曲角度范围。
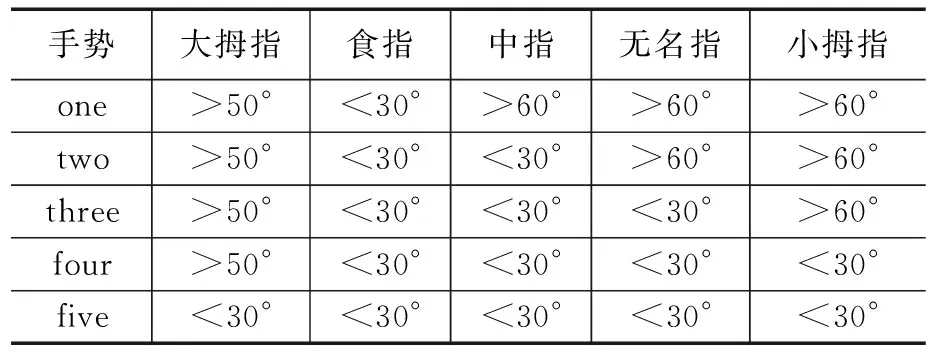
表3 手势定义
3.4 实验硬件平台及数据集设计
实验使用一块英伟达GeForce RTX 3090的显卡服务器,显存为24 GB,操作系统为32位Linux 5.4,环境搭建Pytorch1.11.0,Python3.7,opencv-python。改进前后的手势识别方法的测试样本均为RWTH(RWTH-PHOENIX-Weather multi-signer 2014)公开数据集的2 850张测试样本。RWTH数据集是一个针对手语识别的数据集,包含各种手势姿态,应用场景丰富。实验检测5种手势识别具体姿态如图10所示。
3.5 实验结果及其分析
用测试样本分别对改进前后的手势识别方法进行测试,改进后的手势识别方法在模型训练及准确度方面都有很大提升,训练识别率均可达100%。根据定义的5种不同手势,采用2 850张测试样本进行测试,测试识别率对比结果如表4所示。5种手势的平均识别准确率由改进前的93.56%提升至96.18%,整体识别准确率提升了2.62%。实验改进使得手势“two”,“three”识别准确率低于其他手势,主要原因在于测试样本的个人生活习惯不一致。大拇指与无名指和小拇指的摆放位置,与约束条件不匹配导致,存在相互误判,手势“two”误判为“three”,手势“three”误判为“two”。手势“one”,“four”,“five”在日常使用中通常较为规范,展示角度范围幅度不大,镜头识别误判率较低。
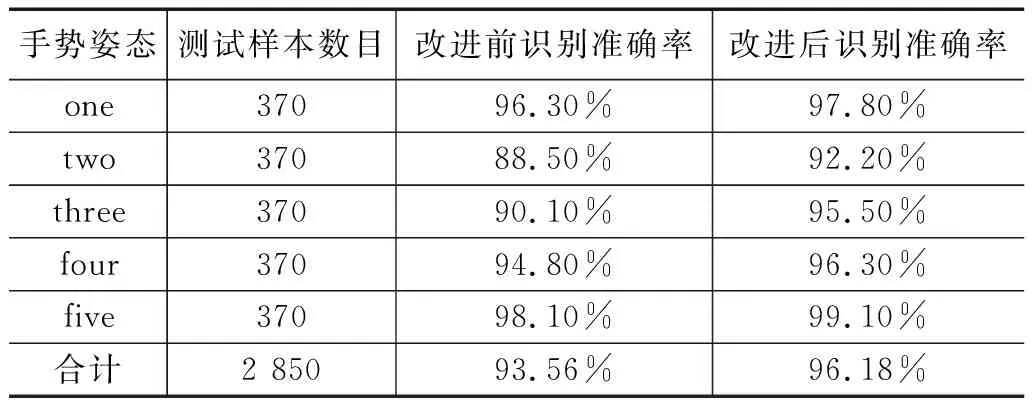
表4 测试集识别准确率对比
4 程序运行
实验运行程序调用OpenCV函数库,数据读入可使用本地图片,视频或采用硬件摄像头实时信息抓取。在经过手部识别模型检测图片,bounding box标注手部特征并进行1.1倍外扩,尽可能保证手部信息全在标定框内后,在进行图片分割。进而在改进手部关键点模型进行检测后,通过判断是否满足手势约束条件,显示设定手势,否则不显示既定手势。最后输出分类结果,检测画面还原镜头捕获比例,显示实时检测画面。
以外置摄像头检测为例,如图10所示,判断显示检测约定的5种手势。准确度高。
5 结束语
轻量型神经网络常被用于移动端或者嵌入式设备中。本文在应用于智能驾舱的人机交互手势识别中,提出了一种基于改进轻量型神经网络的手势识别方法。基于YOLO v3与改进ReXNet为基础框架,融合Ghost Module模块,有效的提高了手势识别效果,在测试样本的识别结果中表现良好,测试整体精度可达96.18%。虽然有两个手势的识别准确率相较其他手势略低,但在实时检测中,不甚有太大影响,且改进后的算法对识别精度有很大提升,模型训练不会占用太多资源,这也是轻量型神经网络的优点之一。综上总结,本文改进的手势识别方法,可以实现高精度的手势实时交互检测,在智能驾舱等应用场景中,都能够得到很好的发展,有很强的现实工程意义。
