基于字符分割和LeNet-5网络的字符验证码识别
2023-08-03张敬勋张俊虎赵宇波
张敬勋,张俊虎,赵宇波,李 辉
(1.青岛科技大学 信息科学技术学院,山东 青岛 266061;2.山东产业技术研究院,山东 青岛 250102)
0 引言
验证码存在的目的是加强网站系统安全,防止恶意攻击[1],因此网站系统中的验证码形式也种类繁多,不仅有基于文本的、基于音频的、基于视频动画的验证码,还有基于谜题的验证码等[2],而对验证码识别技术的研究是是非常关键的一部分,因为验证码的识别技术可以衡量验证码生成算法的质量,并帮助改善验证码生成算法,以达到加强网络系统安全的目的。
在验证码识别领域[3],字符型验证码[4]依旧是网站使用最多形式的验证码,因此字符型验证码的识别是一个重要的研究方向。通常,研究人员将字符识别算法的过程分为三个步骤,分别为字符定位、字符分割和字符识别[5]。而在识别字符型验证码的时,最主要的是字符分割与字符识别部分,因此单个字符的正确分割是影响字符型验证码识别准确率的关键步骤[6]。有效的分割验证码可以极大的提高字符型验证码识别的准确率。在分割方法中,传统的颜色填充分割算法[7]是利用区域填充的思想对字符进行分割的,该方法对于车牌分割[8]和字符间不粘连的验证码有着很好的分割效果,但是对于相互之间粘连的字符无法进行准确分割。垂直投影方法[9]也是一种经典的分割方法,当字符没有扭曲,倾斜等情况时,能够完成很好的分割。
在识别方法中,早期的OCR识别技术、形状上下文以及模板匹配等识别技术,仅仅只能局限在识别简单字符。而随着时间的推移,支持向量机以及卷积神经网络的出现,虽然提高了验证码识别的准确率,但是在准确率上还依然有着很大的提升空间。因此,本文提出了一种先分割后识别的验证码处理方法,此方法先将验证码图片进行分割,分割之后再使用LeNet-5神经网络对验证码图片识别。结果表明,本文方法能够很好的提升字符验证码的分割以及识别准确率。
1 字符图像预处理
1.1 图像二值化以及去噪处理
在验证码的实际识别过程中为了准确有效的对验证码进行分割,我们需要对验证码进行预处理[10],这其中包括灰度化,图片去噪,矫正以及二值化处理。首先,我们先将图片灰度化,而彩色图像转换为灰度图像时,需要计算图像中每个像素有效的亮度值[11],根据重要性及其它指标,将R,G,B三个分量以不同的权值进行加权平均。其计算公式如式(1)所示:
Y=0.299R+0.578G+0.114B
(1)
在图片灰度化之后,把图片进行去噪处理,本文选用中值滤波去噪,把验证码图像中一点的值用该点的一个邻域中各点值的中值代替,让周围的像素值接近真实值,从而消除孤立的噪声点。部分验证码经去噪处理后效果如图1所示。
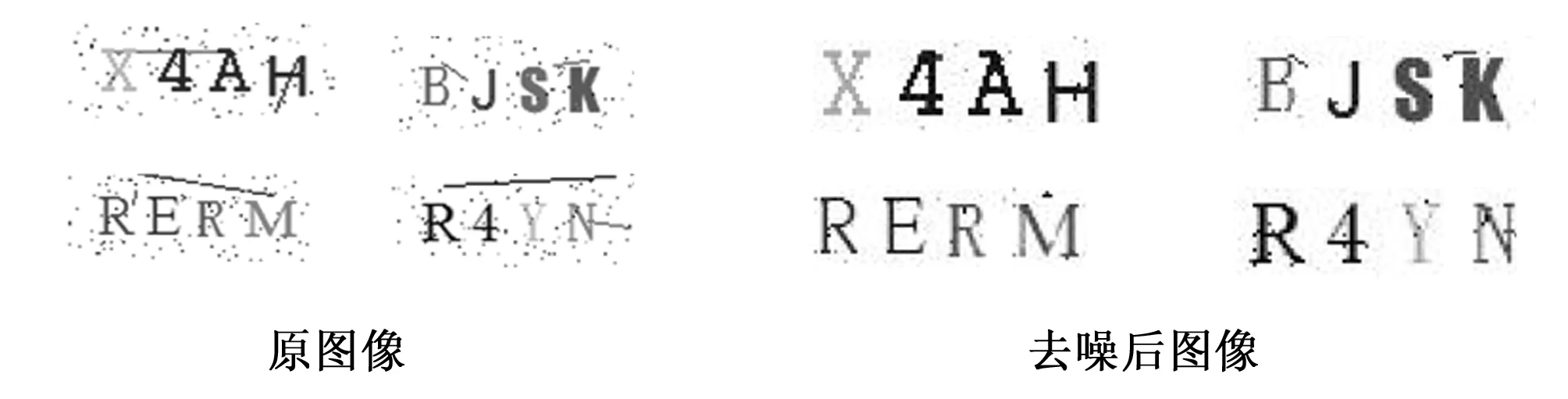
图1 部分验证码经去噪处理后效果
为了有利于进一步处理图像,使图像变得简单,而且让数据量减小,能突出字符有效信息,即突出所求目标字符的轮廓和特征,我们再对图像进行二值化处理。首先将 RGB 格式的图像转化为灰度图像,再把灰度图像进行二值化。
在图像预处理过程中,首先获得图像灰度继而使用迭代法阈值分割[12]来得到阈值,进而利用此阈值将灰度图像进行二值化,从而较为快速而且有效的来完成灰度图像的二值化。迭代法阈值分割的流程如下。
Step1:选择一个初始估计阈值T1,预设值ξ。
Step2:用T1把给定图像分割。这样做会生成两组图像:G1由所有灰度值大于T的像素组成,而G2由所有灰度值小于或等于T的像素组成。
Step3:对区域G1和G2中的所有像素计算平均灰度值μ1和μ2。
Step4:选择一个新阈值T1=T2,更新T2,T2=(μ1+μ2)/2。
Step5:重复进行Step2~Step4,直至|T2-T1|>ξ,输出T2。
部分验证码二值化结果如图2所示。

图2 部分验证码二值化结果
1.2 倾斜矫正
为了网站安全,许多网站验证码中的字符都有或多或少的倾斜字符,为了方便验证码的下一步处理,我们需要对验证码字符进行倾斜矫正。
霍夫变换(hough transform)是图像处理中识别几何形状最常用的方法[13]。用Hough变换来检测图像的边缘,确定倾斜图像边缘的直线倾斜角,通过倾斜角的旋转后,可以获得矫正后的图像。倾斜矫正具体流程为:通过Canny边缘检测算法获得字符边缘,画出最小矩阵框,然后利用Hough变换计算倾斜角度,之后进行字符旋转矫正,最后依次找出所有最小矩阵框并矫正。验证码矫正结果如图3所示。

图3 验证码矫正结果
2 字符分割
目前大多数使用的验证码依旧为四字符的验证码,因此本文研究对象依旧是四字符的验证码图像。本文针对传统颜色填充算法的缺陷和粘连字符分割存在的难点﹐对传统的颜色填充分割算法进行改进。该算法首先使用垂直投影算法来判断验证码图片包含几个字符块,以及得出每个字符块的坐标点以及字符宽度。如果字符块数量等于四,则说明字符之间没有粘连,则直接使用颜色填充算法对验证码图像进行分割,如果字符块数量不等于四,则使用颜色填充算法分割之后再根据字符块的坐标点以及字符块宽度进行二次分割。本文算法分割流程如图4所示。
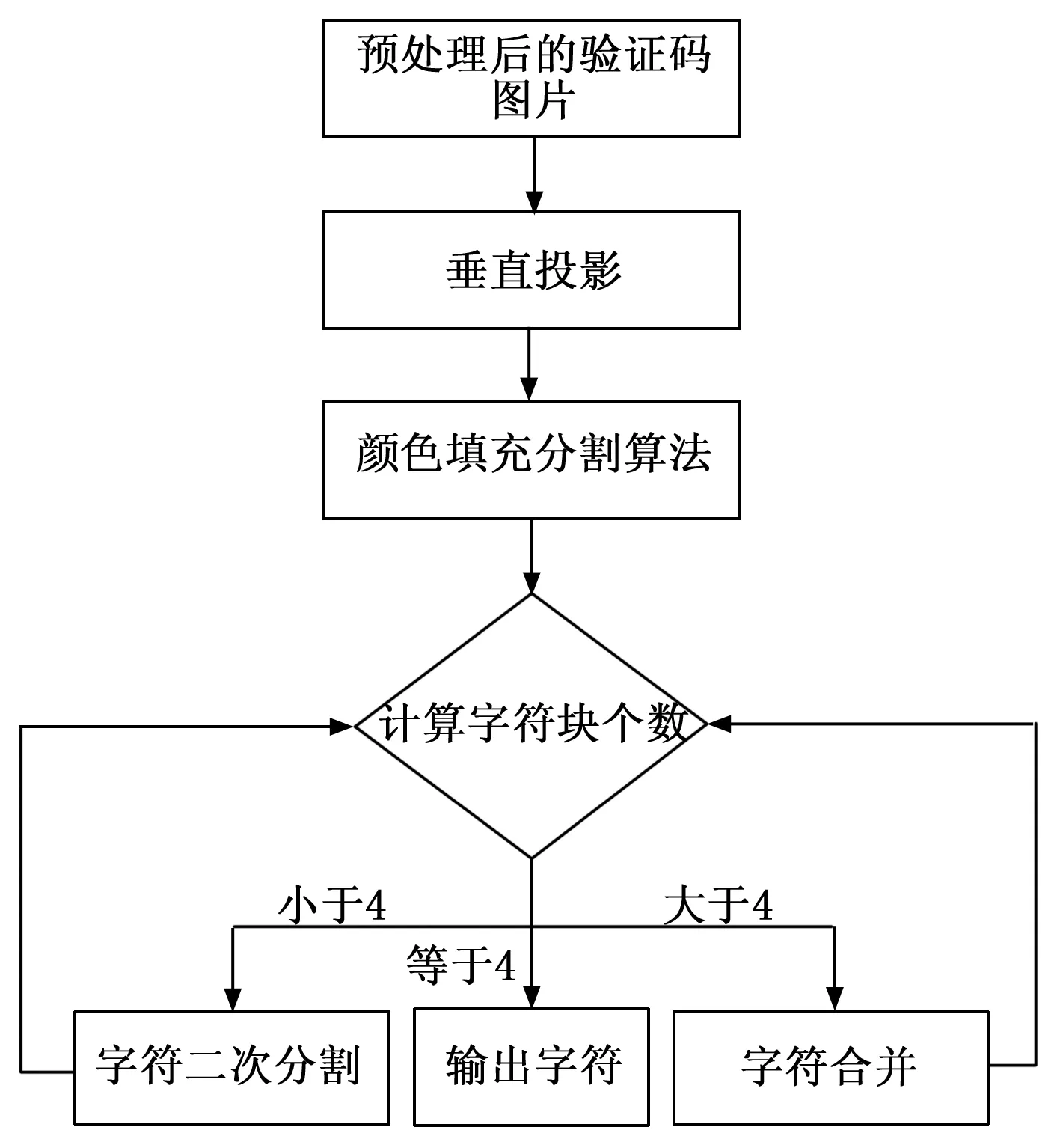
图4 字符分割流程图
2.1 垂直投影算法
垂直投影算法就是对二值化后的验证码字符图像的黑色像素个数进行竖直垂直方向上的统计。设每个像素位置(x,y)对应的坐标为f(x,y),当像素点为白色像素点时,f(x,y)=0,为黑色像素点时,f(x,y)=1。则每列像素点个数为P(x),公式如(2)所示,其中H为验证码图片高度。
(2)
从x=0开始,依次查找当P(x)=0时x的取值,当第一次查找到P(x)=0时,则记录此时的x坐标,并标记为字符的左边界;然后继续查找,当再次检测到P(x)=0时,则记录此时的x坐标,并标记为字符的右边界,以此类推,直至将字符型验证码图片检测完毕,之后将字符宽度小于2的标记为噪点并去除。部分预处理后的验证码图片的垂直投影结果如表1所示。
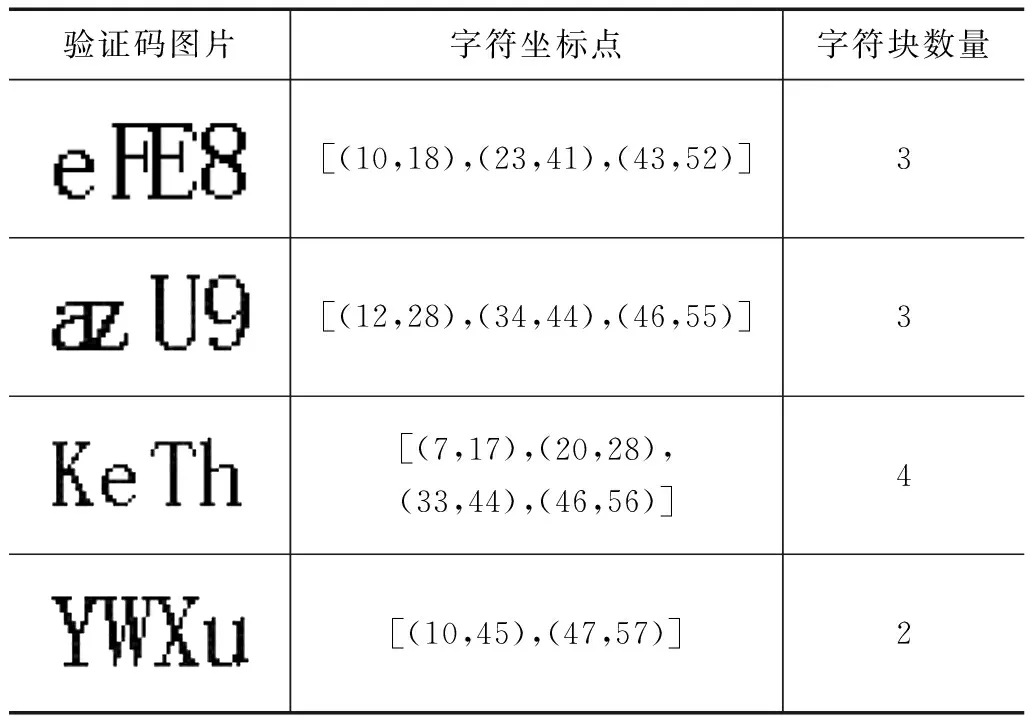
表1 部分预处理后的验证码图片垂直投影结果
对表1中的第一张图片进行可视化,可视化结果如图5所示。
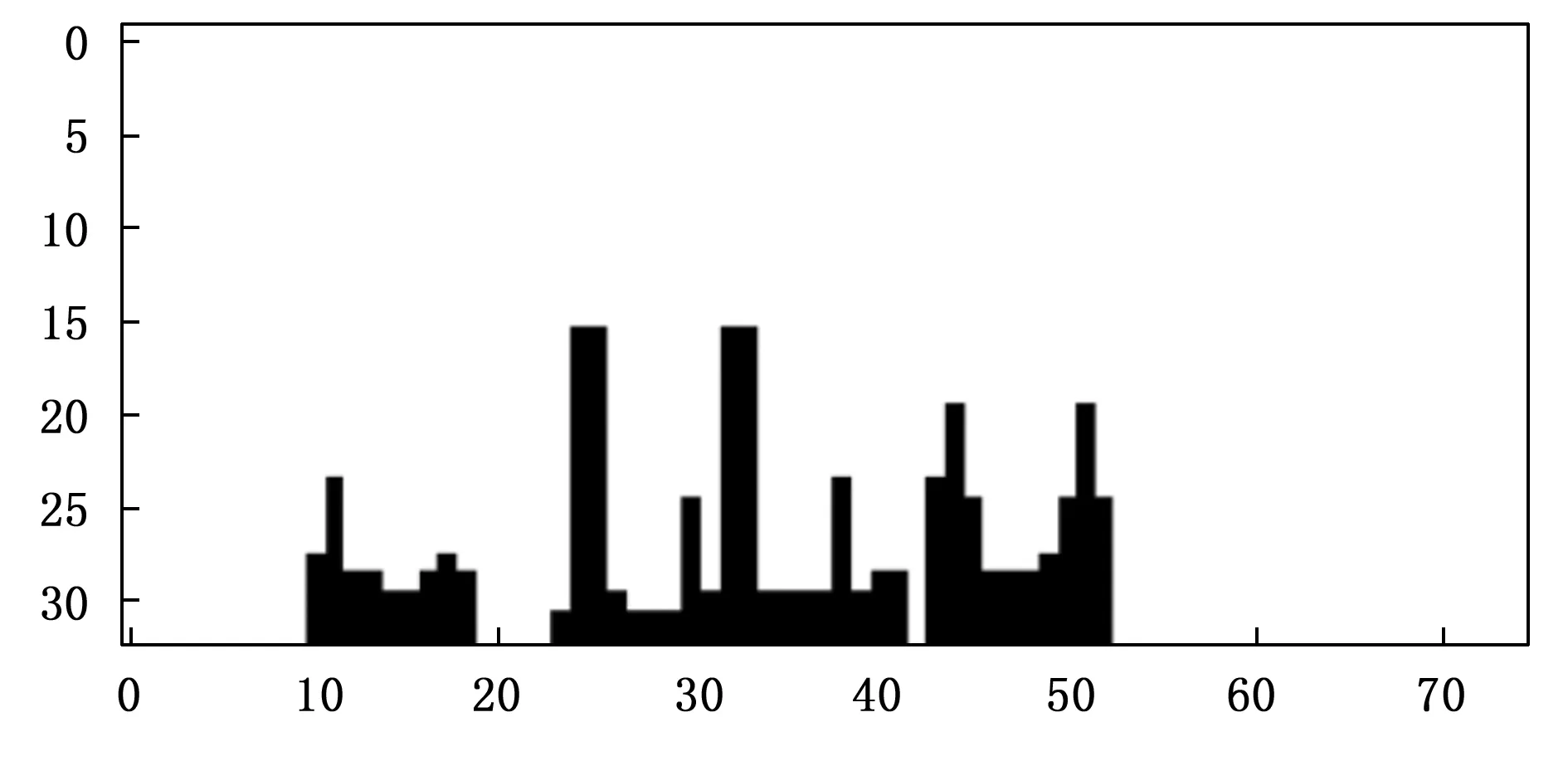
图5 垂直投影可视化图
2.2 颜色填充算法(CFS)
颜色填充分割算法(CFS,color filling segmentation algorithm),颜色填充又称为区域填充,这里的‘区域’是由像素点组成点阵形式的填充图形。一个区域由两部分组成,分别为内点和边界点,内点是指区域内部的所有像素点,在本文中是指验证码字符中的像素点,这些内部的像素点为同一个颜色。边界点是指区域外部的所有像素点,在本文中是指验证码字符之外的所有像素点,这些边界像素点为与内部像素点不同的颜色。具体的表现形式如图6所示。
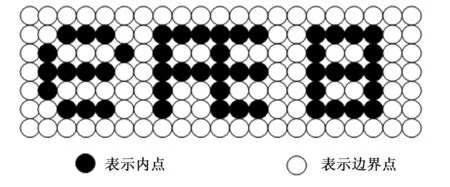
图6 像素点的表现形式
本文所使用的连通方式为八连通方式,具体表现过程为将区域内的一点标记为种子点,给种子点标记一种颜色,然后通过八向连通的方式,用该种子点的颜色遍历完区域中所有像素点的过程。因本文处理后都是二值化图片,因此该种子点也就是一个黑色像素点(像素值为 0),用其他颜色标记,然后以这个种子点为中心,使用八向连通的方式,继续找相邻的黑色像素点,找到之后就将这个点赋予为和这个种子点相同的颜色,并从找到的黑色像素点开始递归寻找其余黑色像素点直至无相邻的黑色点结束,然后均标记为与此种子点相同的颜色。通过以上的一个递归过程就可以标记出一个颜色均为黑色的区域,然后再用其它几个不同的种子点,逐渐遍历,便可找到许多面积大小不同的区域,而区域面积较小则认为是噪点区域,因此,去除噪点区域外的其他区域则是分割出来的字符。本文基于的颜色填充分割算法采用栈结构来实现。基本流程如下:
Step1:种子元素入栈。
Step2:查看栈是否非空,非空则进行Step3~Step6。
Step3:栈顶元素出栈。
Step4:将出栈元素置成要填充色。
Step5:按八向连通的方式检查与出栈元素相邻的8个元素。
Step6:在Step5检查的像素中,如果某个像素点是内部点,而且没有填充颜色,则把该像素入栈。
取出部分预处理后的验证码图片使用颜色填充算法分割,部分分割结果如表2所示。
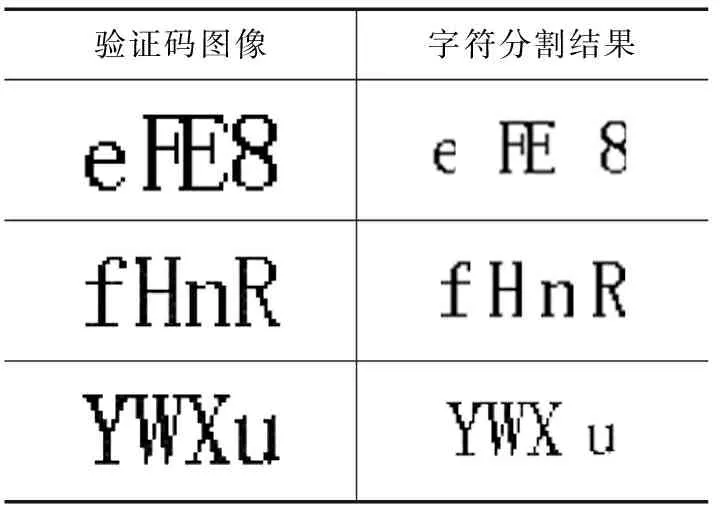
表2 颜色填充分割算法结果
2.3 字符二次分割
根据使用垂直投影算法计算出的宽度可知,使用颜色填充分割算法分割后粘连的字符要比单一字符的宽度值更大。在讨论粘连字符分割时,本文主要讨论的验证码是四个字符的验证码,因此分割后的可能会有以下情况,1)全部字符都相连,即分割后只有一个字符块,2)字符两两相连,分割后有两个字符块,3)字符部分连接,分割后有多个字符块。在以上三种情况中,我们每对字符完成一次分割,则用OCR的识别技术[14]进行一次判断,看分割出的图像是否是单个字符。直至对整个粘连字符图像处理完毕。
针对第一种情况,我们按照公式(3)对字符做出处理,因为全部字符相连,因此我们对字符做处理的结果会分出四个字符块。
(3)
其中:Wmax代表最大字符块的宽度,Wi代表每个字符块的宽度,其中W1+W2+W3+W4=Wmax,t代表对字符分割时每次移动的像素数,初始值为1。
针对第二种情况,因为分割后会有两个字符块,因此对两个字符块分别处理,然后对处理后字符进行判断,看是否分割出正确字符。分割公式如(4)所示。
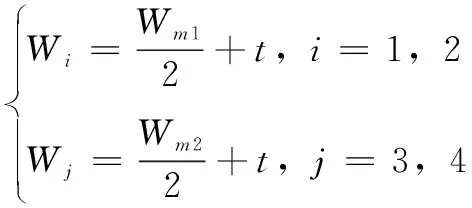
(4)
其中:Wm1代表第一个字符块的宽度,Wm2代表第二个字符块的宽度,其中W1+W2=Wm1,W3+W4=Wm2。t代表对字符分割时每次移动的像素数,初始值为1。
针对第三种情况,字符部分相连,即有可能是两个相连也有可能是三个相连,即最少有一个单个字符,我们令宽度最小的单个字符的宽度为Wmin,然后我们对粘连字符按照公式(5)进行处理,然后检查分出的是否是单个字符。

(5)
其中:Wmax代表相连字符块的宽度,Wmin代表宽度最小字符块的宽度,对于式(5)中的第一个式子,W1+W2=Wmax,对于公式(5)中的第二个式子W1+W2+W3=Wmax,t代表对字符分割时每次移动的像素数,初始值为1。
对粘连部分验证码二次分割处理以后部分验证码结果如表3所示。
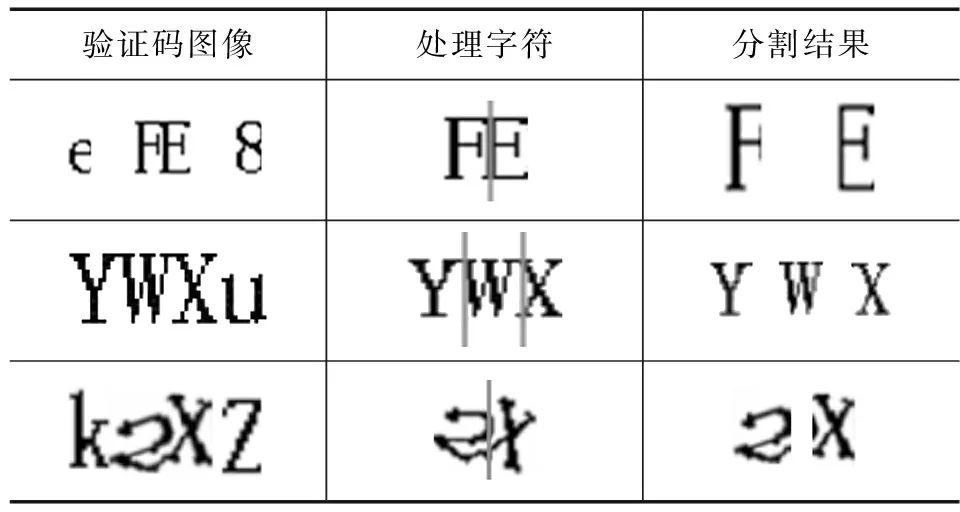
表3 部分验证码二次分割处理字符以及分割结果
2.4 字符合并
在粘连字符分割过程中,也有可能导致字符断裂,因此,我们需要对断裂字符进行合并。以下为对断裂字符处理的流程。
Step1:计算每个字符块的中线坐标为x1,x2, ,xn。
Step2:计算字符块的最小宽度Wmin和字符块数量count以及计算相邻字符块中线之间最小距离Lmin。
Step3:将Lmin与Wmin进行对比,如果Lmin小于Wmin,则将该字符块与其后相邻字符块进行合并,即更改该字符的右边界,使该字符的右边界等于其后相邻的字符右边界,之后将count减1。
Step4:重复进行步骤一到步骤三,直至垂直投影后的count≤4。
3 字符识别
随着深度学习[16]的发展,卷积神经网络(CNN)作为一种深层次的神经网络,被应用在许多领域,如目标检测[17]、图像分割和识别[18]和CAPTCHA识别[15]。而在CAPTCHA识别领域表现出了优异的性能,其性能远远优于传统的机器学习方法[19]。与传统方法相比,卷积神经网络中的卷积层有着很强的提取特征的能力,降低了人工处理的要求和复杂的预处理流程。在1998年,Lecun等[20]人在神经网络领域有了开创性工作,即提出了LeNet-5网络结构,这也正式开启了卷积神经网络时代。他首先应用于手写数字集的识别,并取得了很好的效果,之后在许多学者的改进下,又应用在车牌识别,压印字符识别等领域。
LeNet-5网络结构包括7个层,分别为一个输入层、三个卷积层、两个池化层、一个输出层。LeNet-5网络的模型结构如图7所示。
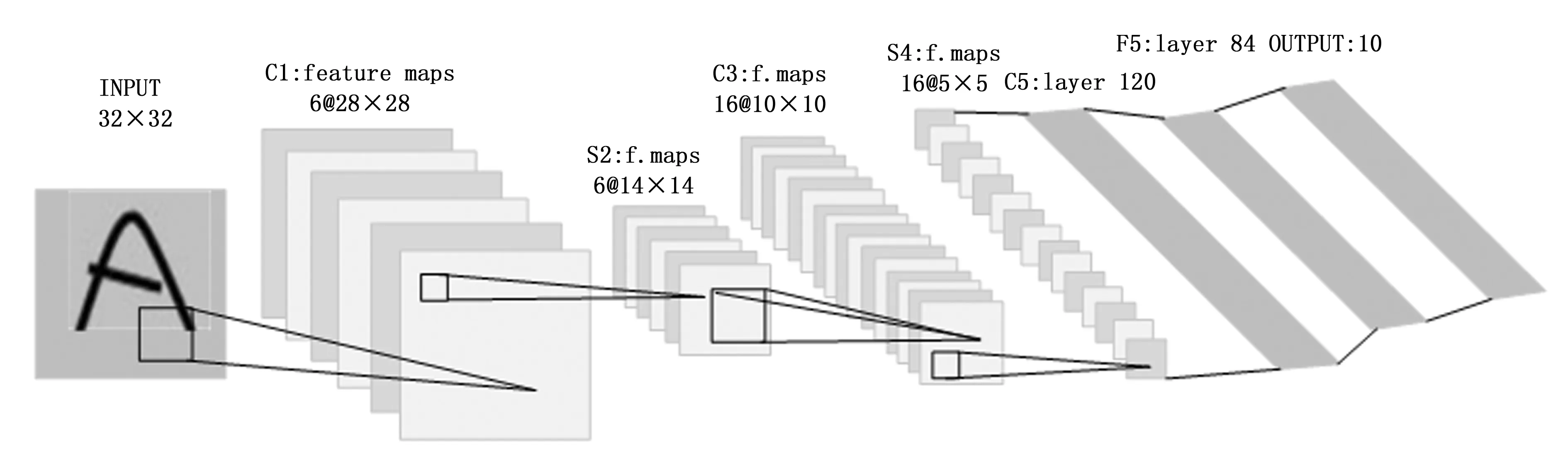
图7 LeNet-5模型结构
在图7中,C1是一个具有六个特征图的卷积层。每个特征图都由5×5的卷积核采样步长为1。特征图的大小为28×28,可以防止输入从边界溢出。C1包含156个可训练参数和122 304个连接。S2是一个具有六个特征图的14×14大小的子采样层。每个特征图中的每个单元都与C1中相应特征图的2×2邻域相连。2×2的感受野是不重叠的,因此S2中的特征图行数和列数比C1中的特征图减半。S2具有12个可训练参数和5 880个连接。C3层为卷积层,输入为S2中所有6个或几个的特征图组合,使用5×5的卷积核采样,包含6张10×10大小的特征图和1516个可训练参数以及156 000个连接;S4层为池化层,采样方式为4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid函数输出。包含16张5×5大小的特征图和32个可训练参数以及2 000个连接;C5为卷积层,输入为S4层的全部16个单元特征图,卷积核大小5×5,为包含120张1×1大小的特征图和48 120个可训练参数以及48 120个连接;F6为全连接层,计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。包含84个神经元和10 164个可训练参数;输出层采用的是径向基函数(RBF)的网络连接方式,输出为10个神经元。
RBF的计算公式如公式(6)所示:
(6)
在公式(6)中,xj为全连接层中第j个神经元;yi为输出层第i个神经元;wij为全连接层第j个神经元与输出层第i个神经元之间的权值。
因为LeNet-5网络结构最早是针对手写数字识别产生的,其10个输出神经元分别对应着0~9这10类数字,但验证码字符比手写数字更为复杂,识别难度更大,因此我们对传统的LeNet-5网络进行改进,使其能够更好的用于识别验证码字符。
由于验证码图片中包含多个字符,所以LeNet-5网络中输入层的32*32像素的大小便不能对验证码字符图片进行有效的识别,因此,我们将输入层的输入大小改为40*30像素大小,能够更好的符合字符验证码图像的长宽比,也能避免归一化为32*32大小时,而产生的过多信息丢失。
在LeNet-5网络中,C5层的训练参数数量为48 120个,占整体训练数量的80%。大大增加了训练量以及拖慢训练速度,因此将LeNet-5网络模型中的C5层去掉,改为F5全连接层,并在F5全连接层前进行扁平化处理,这样能够将模型总体的训练参数数量减少,提高了算法的运算效率。
本文设计的网络模型结构参数信息如表4所示。
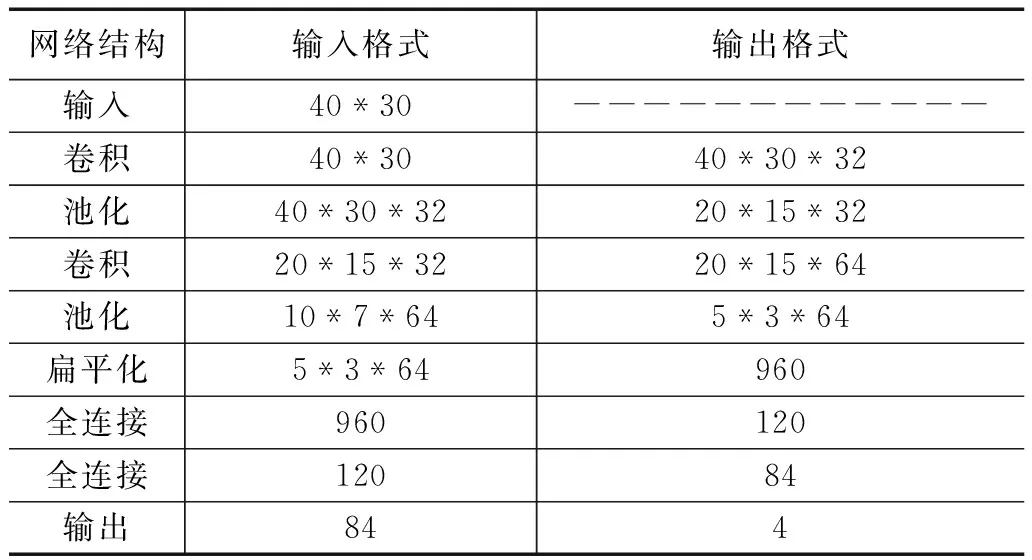
表4 卷积神经网络模型结构
本文设计的网络模型包括两个卷积层,两个池化层,和两个全连接层,其中学习率为0.001,卷积核大小为3*3,填充大小为1,步长为1,输入图片大小为40*30,识别过程如图8所示。
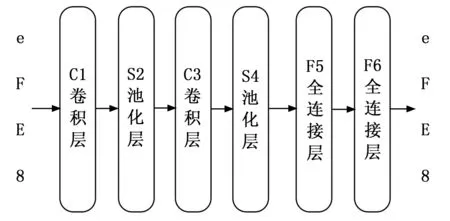
图8 LeNet-5网络识别过程
4 实验结果与分析
本文使用python语言,运行环境是在CPU上运行,是基于Intel(R)Core(TM)i5-6200U的处理器,操作系统为Windows10,编译环境为python3.7版本。
本文数据集均来自生成和网络采集,其中由Captcha库生成20 000张字符型验证码图片,网络采集2 000张字符型验证码图片,其中包括粘连字符型和非粘连字符型验证码图片。验证码图片内容包含0~9数字及A-Z的26个大小写英文字符混合。
为了验证算法的优越性,根据验证码字符是否粘连将数据集分为两类,分别为粘连字符验证码和非粘连字符验证码。每类的数据集均为11 000张验证码图片,第一类中的验证码字符为较为简单的没有粘连字符验证码;第二类中的验证码字符均为复杂的粘连字符验证码。每类验证码的字符粘连情况如表5所示。

表5 每类验证码的字符粘连情况
首先为了更好的验证本文分割算法的有效性,我们分别从两类数据集中拿出1 000张图片做分割实验,与垂直投影分割算法,颜色填充分割算法进行对比,计算字符分割算法的准确率以及分割所用时间。本文字符分割准确率公式如(6)所示:
(6)
其中:Acc代表字符分割准确率,S为字符总个数,Yi代表分割正确的字符。各种算法分割准确率以及分割时间如表6所示。
之后,我们再用卷积神经网络对字符验证码进行识别实验,将数据集按照8:1:1的比例分为训练集、测试集和验证集,然后放到卷积神经网络中。最终模型第一类验证码训练和测试的准确率与损失曲线如图9以及图10所示。第二类验证码训练和测试的准确率与损失曲线如图11以及图12所示。
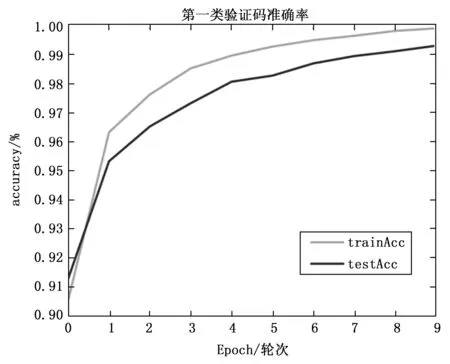
图9 第一类验证码训练的准确率
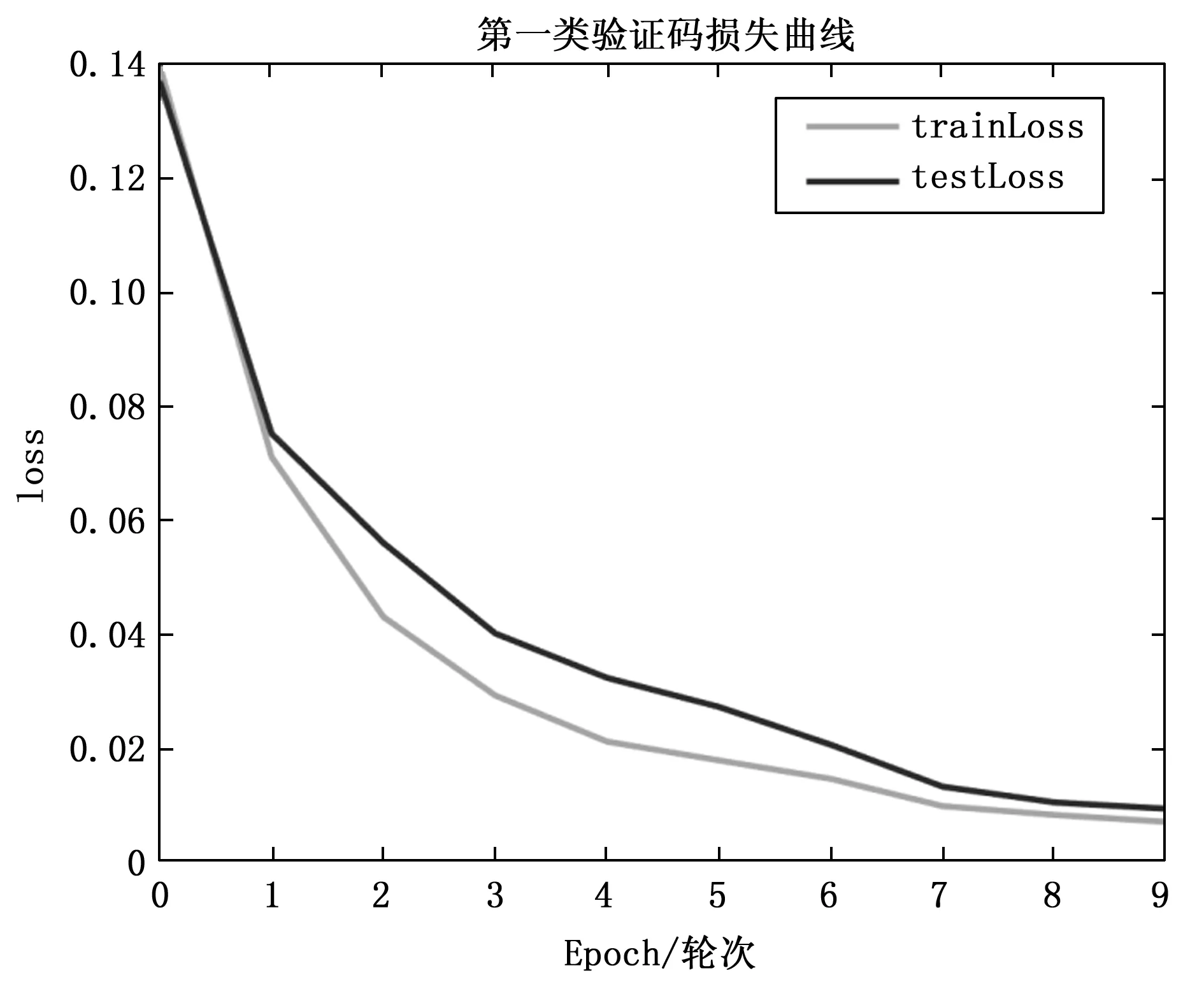
图10 第一类验证码训练的损失曲线
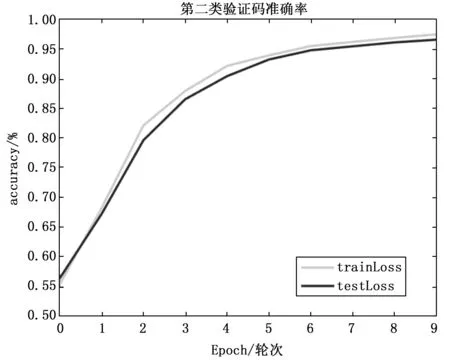
图11 第二类验证码训练的准确率
从图9、图10、图11以及图12可以看出,无论是对于第一类无粘连字符的验证码,还是对第二类有粘连字符的验证码,本文的方法都具有很好的识别效果。之后,在测试集上对两类验证码进行实验,得到结果为第一类非粘连字符验证码,识别准确率达到99.9%,对于第二类粘连字符的验证码,识别准确率可以达到97.7%。除此之外,为了进一步评估本文方法对字符验证码识别的优越性,本文与参考文献中的其它验证码识别方法进行了对比,本文实验结果和其它模型对比结果如表7所示。
从表7可以看出,无论是对于第一类简单的非粘连验证码,还是对于第二类复杂的粘连验证码,本分对验证码的处理方法均有不错的效果。其中对于第一类简单非粘连的验证码,效果有明显提升,对于第二类复杂的验证码,也比识别率最好的FRN效果要好。

表6 字符分割实验对比
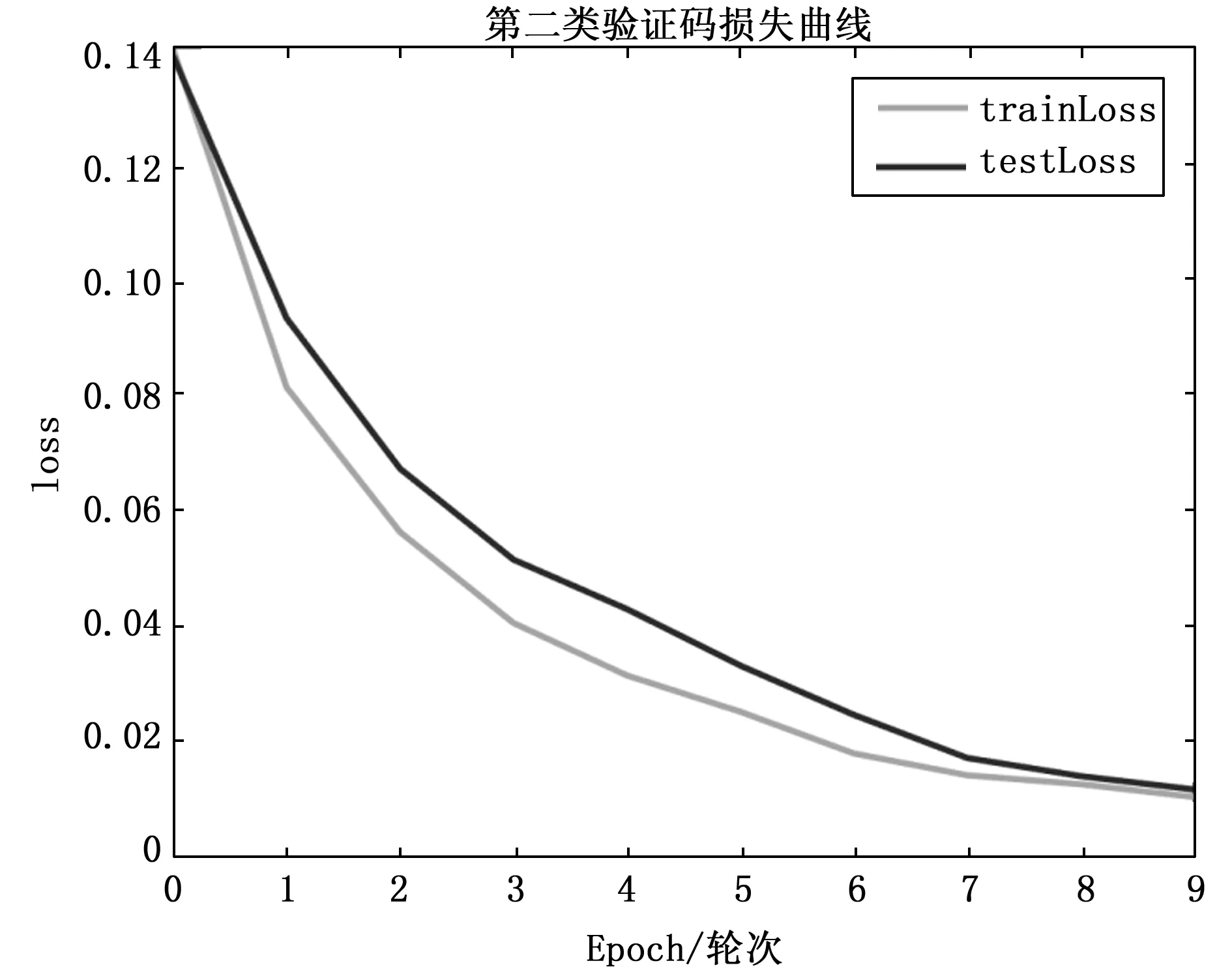
图12 第二类验证码训练的损失曲线
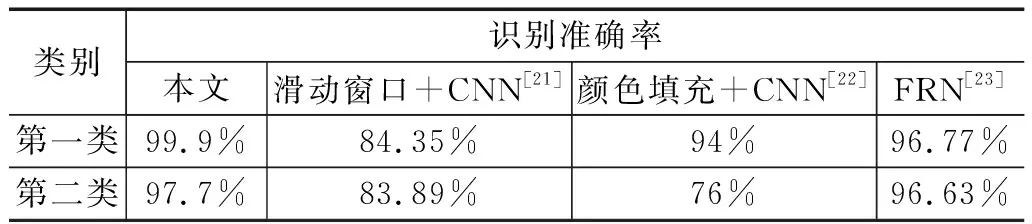
表7 各种算法识别正确率对比
5 结束语
本文针对传统颜色填充算法的缺陷和粘连字符分割存在的难点﹐对传统的颜色填充分割算法进行改进,最后再引进LeNet-5神经网络对验证码字符进行识别。实验结果表明,本文算法不仅适用于大部分非粘连字符验证码,而且还能够解决传统颜色填充算法无法处理的粘连字符分割问题,但是,对于背景较多干扰线的字符验证码,本文算法可能会出现误分割。
最后,本文在分割算法之后引入改进后的LeNet-5神经网络对验证码字符图片识别,这样极大的减少了卷积神经网络的参数,也能起到不错的字符识别效果。实验结果表明,本文提出的方法对验证码的分割和识别起到了良好的作用,提高了字符分割的准确率,也减少了卷积神经网络的参数,提高了运行速率,以及验证码识别准确率。
