基于YOLOv5和生成对抗网络的塑料标签缺陷检测
2023-08-03庄昌乾李璟文
庄昌乾,李璟文
(1.江南大学 理学院,江苏 无锡 214122;2.江西盛泰光学有限公司,江西 新余 336600)
0 引言
自动化缺陷检测对于先进制造中产品的质量控制至关重要,现已被广泛应用于检测各种产品生产过程中的异常和缺陷[1-2]。印刷塑料标签作为一种独特的标识和质量指标,展现了商品的信息、制造商的设计理念,也代表了产品的质量。但由于生产设备参差不齐、生产工艺标准不同、操作人员误操作等外部因素,在实际制造过程中,塑料标签表面可能会出现各种类型的缺陷。一些最常见的缺陷包括异物、重影、划痕、墨点、指纹、线条缺失。这些缺陷不可避免地会影响产品的质量和外观,因此在制造过程中检测和识别这些缺陷,从而确保产品的整体质量是非常必要的。
目前,最常见的检测方法仍依赖人工筛选[3]。然而,这种方法不仅劳动强度大,而且容易受到主观因素、疲劳程度和检验员经验的影响,导致误检漏检现象频繁发生,整体准确率和效率较低。此外,另一个明显的缺点是,这种技术从根本上难以与自动化制造过程无缝衔接与兼容。
机器视觉是一种更好的缺陷检测方法,该方法依靠高速相机采集样本图像,通过算法进行图像处理,从而识别和分类各种缺陷[4-6]。目前,大多数研究都局限于基于经典图像处理方法(如振幅阈值、图像去噪与增强、图像分割和特征提取)的决策算法[6]。另一类缺陷检测依赖于基于频谱的算法,它将图像信息转换到频域(例如Gabor变换,傅里叶变换等)[7]。该方法在发现纹理特征背景下的瑕疵具有一定的优势,已应用于织物瑕疵检测。然而,由于塑料标签缺陷的复杂性,单幅图像中可能存在多个、多种缺陷,使用传统的图像处理技术对多尺度缺陷进行定位和识别具有很大的挑战性。
随着计算机视觉的快速发展,深度学习模型开始被应用于工业产品检测。到目前为止,已经有许多基于不同网络模型和算法的目标检测器用于缺陷检测[8-10]。这些检测器主要分为单阶段和双阶段检测器。其中,基于双阶段检测算法的典型模型有:Region-CNN (R-CNN)[8]、Fast Region-based CNN (Fast R-CNN)[9]、Faster Region-based CNN (Faster R-CNN)[10]。在这些方法中,涉及两个阶段(即generating candidate regions和classifying proposal regions),这通常需要较长的处理时间。另一方面,单阶段检测器只需要通过一次神经网络,并在短时间内预测所有边界框及其类别概率,因此更适合有实时需求的场景。最常见的单阶段检测器有YOLO[11-15]、SSD[16]、和CornerNet[17]。其中,YOLO是一种非常先进的目标检测器,因为它能够实时检测物体,并具有良好的精度和鲁棒性,已在许多工业场景中用于缺陷检测。例如,在文献[18]中,作者展示了一个多注意力深度学习网络,以解决纺织图像中多个和多尺度缺陷共存的问题。在文献[19]中,作者开发了一个基于YOLO-v3的端到端缺陷检测模型。在文献[20]中,作者展示了一种改进的MS-YOLOv5网络,该网络采用多流网络,旨在提高对铝表面缺陷的识别,对7种类型缺陷的总体准确率达到87.4%,且检测性能没有明显的不平衡。尽管研究人员在表面缺陷检测方面进行了大量的研究,但很少有人尝试解决工业应用中对塑料标签物瑕疵缺陷的高精度、高效率检测需求的日益增长。
此外,基于深度学习的缺陷检测技术的另一个难点在于,它们往往需要大量带注释的训练样本,而这些样本本身数量较少,或收集起来很耗时。在某些情况下,特别是在训练深度神经网络模型时,缺陷样本较少,可用的数量远远不能满足需求。缺陷样本的不足已成为各种自动化缺陷检测系统设计和部署的瓶颈。最近的一些研究尝试采用few-short learning,即从极其有限的训练样本中学习来解决这一问题[21-22]。然而,它们的性能相当有限,离实际应用还很遥远。解决缺陷样本不足的一种最直接的方法是使用数据增强方法来丰富数据集的数量和多样性,从而训练出更好的缺陷检测网络模型。
因此,在本文的工作中,为了克服现有塑料标签缺陷检测方法的局限性,并解决可用缺陷样本不足的问题,我们使用单阶段检测器(即YOLOv5)进行缺陷检测,并使用生成对抗网络(GAN,generative adversarial network)进行数据增强和缺陷样本合成。由于传统的GAN在合成缺陷图像时存在局限性,因此,我们采用了一种专门用于生成形状不规则、分布随机且尺寸不同缺陷样本的Defect-Gan,通过模拟缺陷生成(defacement)和缺陷图像重建(restoration)的过程,我们可以巧妙地利用大量的正常样本来生成具有高保真度和多样性的缺陷样本。通过使用扩增数据集训练目标检测器,并对网络的超参数进行优化,可以显著提高目标检测器的准确率和精度。此外,为了模拟该方法在实际生产中的应用场景,我们设计并定制了一台半自动的图像采集机械平台用于采集圆柱样品表面的印刷标签,以及一个自主开发的图像处理和统计分析软件。本文所开发的方法和平台可以很容易地推广并应用到其他工业质量控制和缺陷检测系统中。
1 方法
1.1 基于YOLOv5的目标检测
自2016年首次亮相以来,YOLO已经有了很大的发展和升级。即使最新的版本是YOLOv7(仍在更新中),YOLOv5仍然被认为是迄今为止最受欢迎的实时目标检测算法之一,由于其在卷积神经网络领域的最佳优化策略,它在精度、效率和识别模型等方面都优于其他目标检测算法。YOLOv5的网络结构图可分为Input、Backbone、Neck、Head四部分,如图1所示。
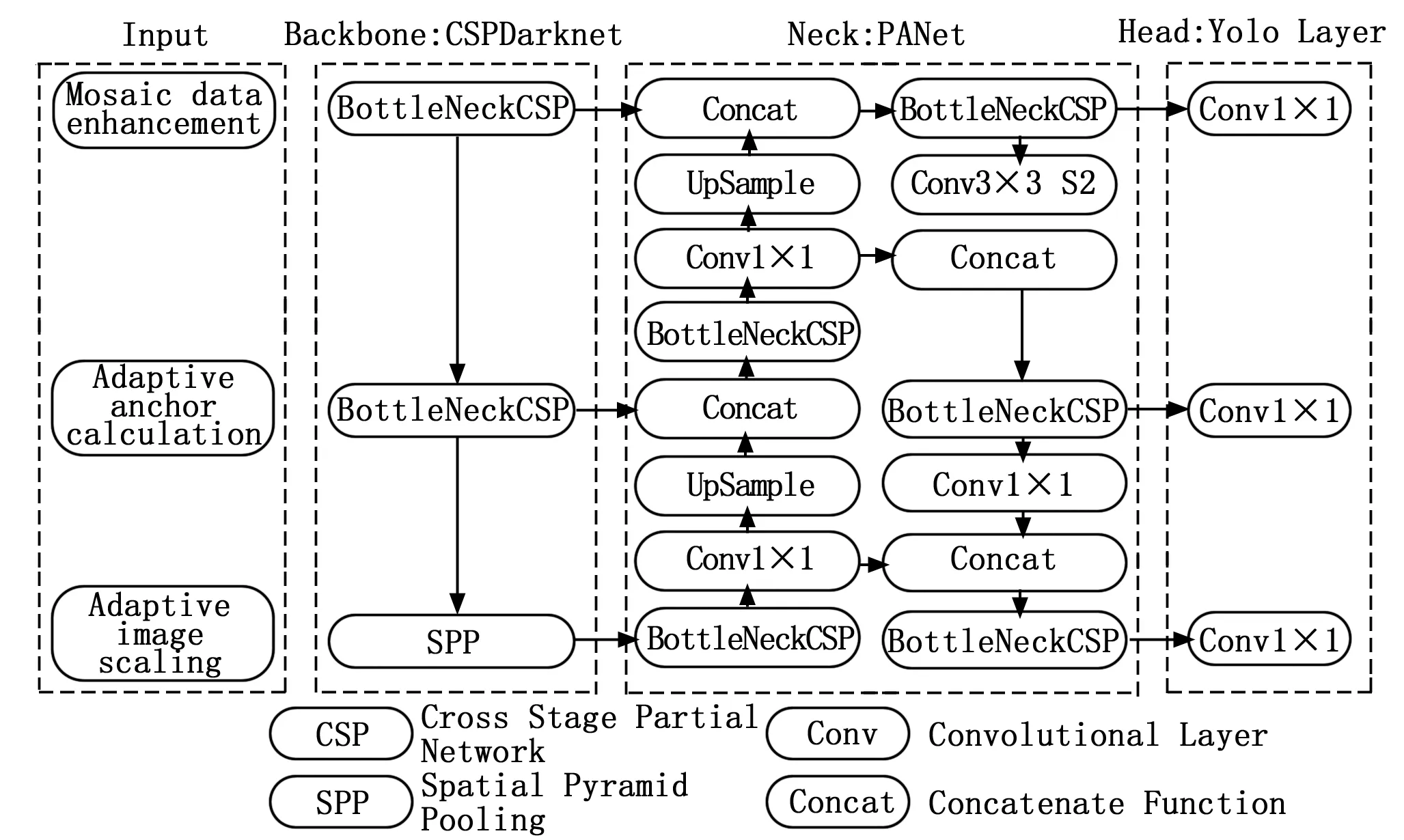
图1 YOLOv5架构
具体来说,YOLOv5的Input主要包括三种策略:马赛克数据增强(mosaic data enhancement)、自适应锚点计算(adaptive anchor calculation)和自适应图像缩放(adaptive image scaling)。首先,采用马赛克数据增强算法[23],通过翻转、裁剪、缩放等操作,对4张缺陷图片进行随机拼接,提高模型训练效率,增强网络的鲁棒性。为了适应不同的数据集,YOLOv5在输入上集成了自适应锚帧计算。因此,当使用不同的数据集进行训练时,初始锚盒的计算可以自动执行和更新。
YOLOv5的Backbone主要使用Focus结构和CSP(cross-stage particle network)结构,通过多次卷积和池化操作从输入图像中提取不同维度的特征图。采用Bottleneck CSP,将基础层的特征图分成两部分,再通过CSP进行合并,减少了计算量。最后,SPP(spatial pyramid pooling)结构从不同尺度提取特征,生成三尺度特征图,以提高检测精度[24-26]。
在Neck中,YOLOv5使用FPN(feature pyramid network)和PAN(pixel aggregation network)来融合特征层,并在三个不同尺度的特征层上实现预测。其中FPN[27]是一个自顶向下的结构,它将高层特征通过上采样和底层特征做融合得到进行预测的特征图。PAN[28]是一个自底向上的特征融合层,对FPN进行补充,并将底层的定位特征传递上去。这两种方法都有助于增强特征融合能力,增强定位的可移植性,提高检测精度。
作为最后的检测步骤,Head用于检测物体的位置和类别。在Precision中,使用GIoU作为边界框的损失函数,表示为:
(1)
(2)
式中,A、B为GT框(the ground truth box)和预测框,C为A、B的最小闭合框。IoU由预测框与GT框的交互作用定义,它代表了预测的边界框和GT在目标区域的大小。GIoU是减去C框中与A和B不重叠的面积之比得到的值。因此,GIoU越大,性能就越好。
1.2 合成数据的生成
足量的注释数据集在基于深度学习的目标检测和目标分类中至关重要。缺乏缺陷样本会导致训练过程过拟合、检测精度差、泛化能力差等问题。然而,在某些情况下,很难获得用于训练模型的足够数据集。为了解决这一问题,可以采用数据增强算法来提高网络的泛化能力。在本节中,我们展示了两种合成图像生成方法(即生成缺陷图像的传统方法和基于深度学习的Defect-GAN方法)。
生成缺陷图像最直接的方法是使用传统技术,包括几何变换(例如,旋转、翻转、平移)、颜色空间变换(例如,随机改变图像的色调、饱和度、亮度和对比度)、Kernel滤波器、随机擦除、混合图像和复制/粘贴[29]。
本工作中使用的第二种方法是使用GAN自动合成缺陷样品[30-32]。其基本思想是将两个神经网络结合起来,同时训练一个生成器来生成逼真的假图像,以及一个鉴别器来区分生成的图像和真实的图像。
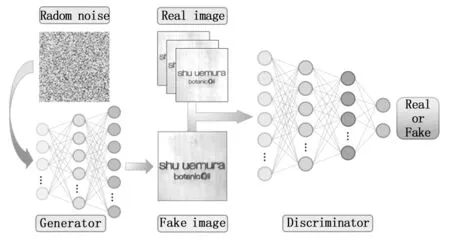
图2 GAN架构
生成器(G,generator)将一个固定长度的随机向量作为输入,并学习模拟生成原始数据集包含的缺陷样本。然后将生成的样本和原始数据集的样本输入鉴别器(D,discriminator),鉴别器学习区分合成图像和真实图像。生成器的目标是创建与原始图像尽可能相似的样本图像,从而欺骗鉴别器,使其相信合成样本是真实的。因此,生成器和鉴别器可以被认为是在进行极大极小值的博弈,其中生成器的目标是最大化鉴别器将生成的图像标记为真实样本的概率,鉴别器的目标是最小化将真实数据标记为真实样本的概率。
迄今为止,研究者已经提出了许多不同的GAN架构[33-40],用于面部表情编辑、图像修补、风格翻译、超分辨率等。其中包括用于生成人脸图像的StyleGan2[33],用于图像到图像转换任务的pix2pixGan[34],将黑白照片转换为彩色,以及用于扩大生物医学图像数据集的CycleGAN[35]。然而,这些方法在用于生成高保真缺陷样本时存在局限性。在最近的另一篇文章中,作者提出了Defect-GAN[36],它是专门为生成缺陷样本而设计的。在这个体系结构中,通过模拟缺陷生成(即在正常样本上生成缺陷)和缺陷图像重建(即将缺陷样本恢复到正常样本)的过程,我们可以巧妙地利用大量的正常样本来生成缺陷样本。Defect-Gan的结构如图3所示。
生成器采用了一个编码器-解码器帧,它首先对输入图像进行编码,步幅为4,然后将其解码为原始大小。此外,由于塑料标签上的一些缺陷通常具有复杂且不规则的形状,且具有随机变化,因此使用传统的GAN建模具有困难。为了缓解这种情况,我们采用了一种自适应噪声引入机制,该机制结合了随机性来模拟缺陷内的随机变化。有了这样的配置,我们可以生成更真实的缺陷样本,提高保真度和多样性。判别器的主要架构沿用了StarGan[37],它使用PatchGan[34]和一个分类指标来预测生成的缺陷类别来区分假样本和真实样本。
在数学上,D和G使用极小极大博弈来生成与现实图像难以区分的图像,我们采用的对抗性损失为[37]:
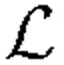
Ex,c[log(1-Dsrc(d(x,c)))]
(3)
其中:G生成一个图像d(x,c),条件是输入图像x和目标缺陷标签c,而x试图区分真实和虚假的图像。Dsrc(x)为D给出的源的概率分布。
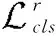
(4)
(5)
前者是对D进行优化,将真实的缺陷样本分类到目标类别,后者是对G进行优化,生成目标类别c的缺陷样本。因此,通过最小化对抗和分类损失,我们可以在目标类别中生成真实的样本图像。
1.3 模型评价指标
在本节中,我们将简要描述用于评估模型性能的指标。我们使用精度P(定义为正确分类的缺陷产品占分类器所划分的所有缺陷产品的比例)和召回率R(定义为正确分类的缺陷产品占缺陷产品数量的比例)来计算模型的平均精度(mAP,mean average precision):
(6)
式中,N表示N个分类,AP表示平均准确率,计算方法如下:

(7)
(8)
(9)
其中:TP为真正例,表示本文算法提取的缺陷与人工标注的缺陷相符合。类似的,FP为假正例,表示本文算法能提取到缺陷,而实际无缺陷;FN为假反例,表示本文算法未提取到缺陷,而实际有缺陷。此外,利用精准率-召回率曲线(PR曲线)和F1分数来评估我们的模型性能。其中PR曲线是精准率与召回率的关系图,精确率和召回率是一对相互矛盾的指标,一般来说高精准率往往意味着低召回率,反之亦然。为了获得优秀的模型,需要综合P和R,因此曲线越靠近图的右上角,说明模型的性能越好。但一般来说,算法之间的PR曲线彼此交错,很难分辨优劣,所以实际中常用F1分数来衡量。F1定义为:
(10)
2 实验装置
2.1 实验装置
现实场景中涉及塑料标签种类繁多。在我们的初步研究中,我们将主要针对印刷在圆柱表面上的半透明塑料标签。它主要有六种不同的缺陷类型,即异物、重影、划痕、墨点、线条缺失、指纹。由于基材的透明性,事实上,其中一些缺陷很难通过简单的人工检查来识别。当检查人员经过几个小时的操作后出现视觉疲劳时,情况会变得更糟。在本节中,我们首先介绍自动采集样本图像的实验设置。我们的装置主要由机械平台、光学照明、图像采集、图像处理与缺陷检测与显示五个模块组成,如图4(a~e)所示。
为了模拟真实的工业检测场景,该物体被放置在定制的机械台上,可以同时进行一维平移和360度旋转。具体地说,该物体被放置在可旋转的支架上,如图4(c)所示。当物体被传送到指定位置时,编码器提供一个基于距离的触发信号。为了用线扫描相机(Linea2,Dalsa,Canada)获得圆柱形物体上标签的清晰2D图像,物体的旋转速度和扫描速率必须完美同步。当物体到达指定位置时,旋转电机单元开始旋转圆柱形物体。同时将图像通过GigE接口发送给计算机,然后重构成展开的塑料标签二维图像,如图4(d)所示。物体旋转与相机之间的精确同步是在水平轴和垂直轴上获得可重复分辨率和相同分辨率的关键。为了保障采集的标签图像不失真,同轴度必须得到保证。最后,自主开发的图形用户界面(GUI,graphical user interface)上可对样本进行图像的自动采集、处理和统计分析,如图4(e)所示。当用户从GUI界面发出“采集图像”的请求时,平台开始旋转,并同时打开线扫光源进行照明。在界面上展示了原始图像、检测到的缺陷以及不同缺陷的实时更新和直方图。在我们的初步研究中,我们发现,即便使用半自动化的处理,采集足够的样本图像也是一个耗时的过程,当需要大量缺陷图像时,该方法仍有一定的局限性。事实上,正如我们将在下面的工作中展示的那样,通过使用数据增强,可以方便地合成缺陷图像。此外,需要说明的是,根据样品的特性和检验要求,光学照明可以采用不同的配置。特别是为了突出塑料表面的轻微划痕,可采用低角度照明。此外,通过在光源前安装偏振滤光片,我们可以避免来自反射表面的眩光。在图5中,我们展示了通常出现在塑料标签上的六种主要缺陷类型。

图4 5个模块示意图
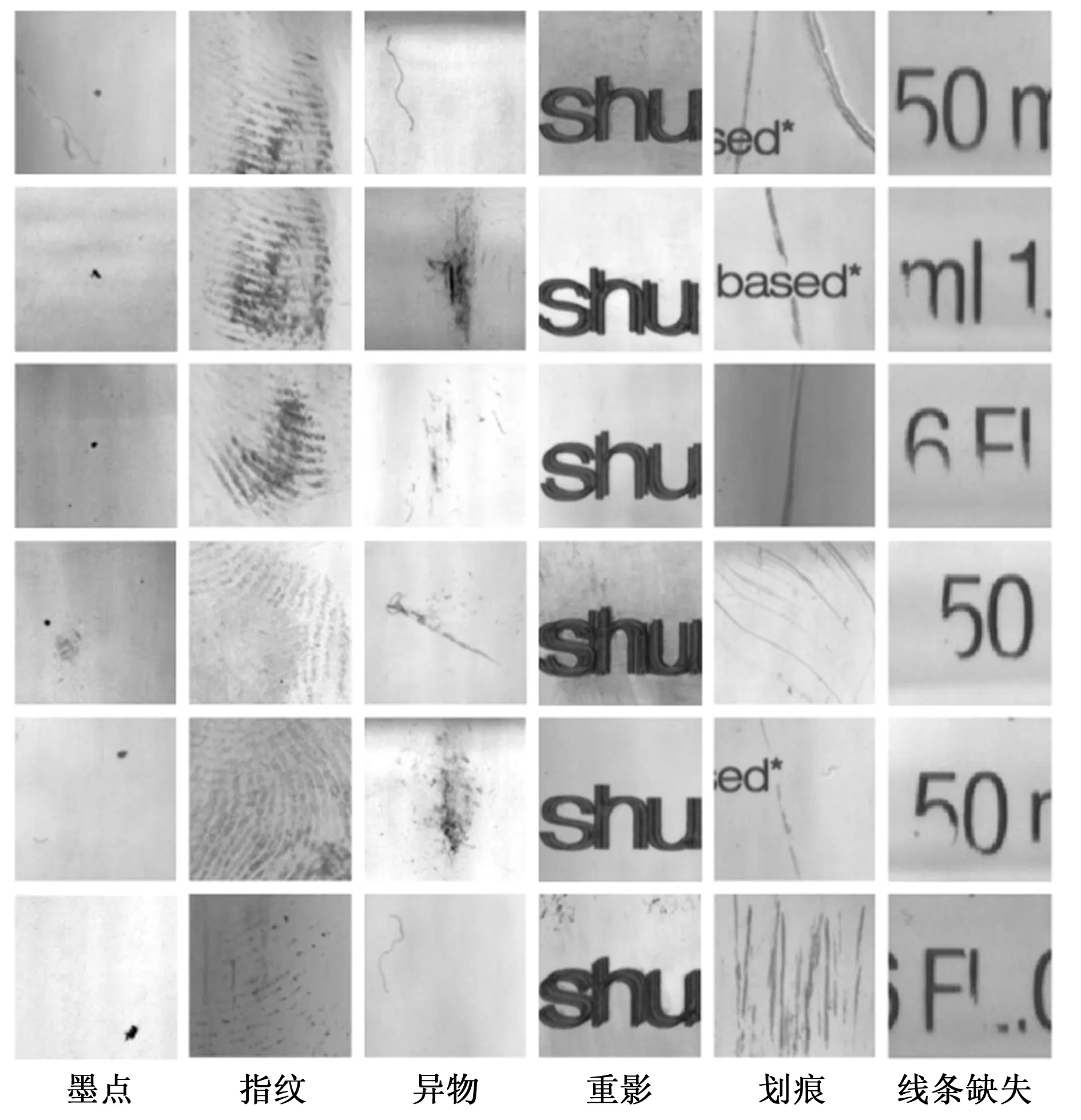
图5 塑料标签的6种主要缺陷类型
2.2 塑料标签数据集
原始数据集是使用图4所示的装置获得的343张图像(512×512像素),其中共包括6种类型的缺陷(即墨点、指纹、异物、重影、划痕和线条缺失)。考虑到样本不足,我们采用传统数据增强方法和生成对抗网络Defect-GAN进行数据增强,相应的图像和注释数量如表1所示。
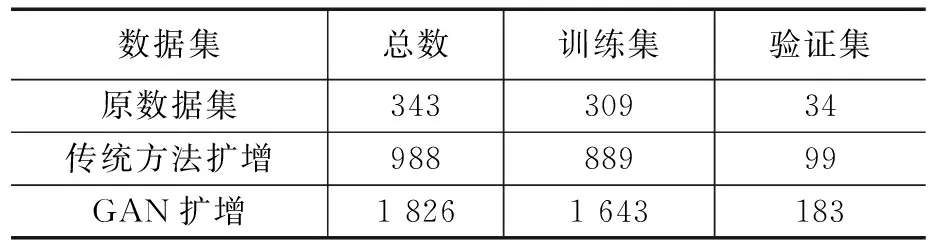
表1 每个数据集中图像和注释的数量 个
2.3 计算机环境
图像处理和分析的计算机环境定义如下:CPU,Intel(R)Core (TM)i7-11700KF@3.60GHz 8-core CPU;GPU,NVIDIA GeForce RTX3060Ti;SSD,1TB;pro-gramming languages,Python3.9;Framework,Pytorch 1.7.1;deep learning accelerator,CUDA 11.0 and CUDNN 11.1;IDE:Spider 3.9。
3 结果与讨论
在这项工作中,训练前的参数设置如下:image size:512×512;learning rate:0.001;Optimizer:stochastic gradient descent (SGD);momentum,0.937;weight decay:0.005;batch size:64;epoch:600。
为了可视化YOLOv5在数据增强后的提升,我们分别给出了原始数据集训练的YOLOv5模型,以及传统增强和GAN增强后的YOLOv5模型的度量曲线。目标检测算法利用训练损失和验证损失来判断模型是否稳定。YOLOv5的损失可以进一步分为box_loss、obj_loss和cls_loss,它们是算法进行目标预测效果的指标。如图6所示,用原始数据集训练的模型,曲线不仅不稳定,而且不收敛。相比之下,当使用增强数据集训练时,模型在100次迭代后变得稳定并且变化最小,并且在两种情况下,mAP都有很大的改进。
此外,我们还比较了不同网络模型的F1_curve和PR_curve。如图7(a~c)所示,我们绘制了F1_curve,这是一个同时考虑了模型的准确性和召回率的度量。曲线越高,模型的性能越好。我们可以看到,在所有类别的数据增强后,YOLOv5的F1_curve变得更高。为了评估目标检测器在各种阈值下的性能,我们还绘制了P_R曲线,如图7(d~f)所示。值得注意的是,我们可以看到,使用GAN增强数据集训练的YOLOv5所包围的区域比使用原始数据集和传统增强数据集训练的YOLOv5所包围的区域要大,这表明模型获得了明显的增强。

前三列是box loss,objectness loss,和classification loss。右边的两列是训练过程中的precision和recall,以及验证过程中的mAP。图6 训练和验证过程的输出
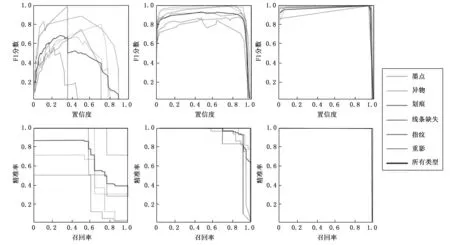
第一、第二和第三列分别对应原始数据集、传统增强后和GAN增强后的结果。图7 YOLOv5下不同数据集的F1_curve和PR_curve比较
最后,利用不同的网络模型进行实际检测分类的结果如图8所示。图中的标签显示了分类结果及其置信度分数。第一行是用原始数据集(方案1)训练的YOLOv5对每个缺陷的检测结果,第二行和第三行分别是用传统数据增强方法(方案2)和Defect-GAN生成对抗网络(方案3)训练的YOLOv5对每个标签缺陷的检测结果。从图8中可以清楚地看到,使用方案1时未发现的一些缺陷在使用方案2和方案3时可被发现。此外,对于已识别的缺陷,方案3的置信度评分普遍高于方案1和方案2,这表明分类精度有所提高。结果表明,方案3检测性能最好,几乎所有缺陷类型都能被准确识别和分类。

图8 使用原始数据集训练模型(方案1),经过传统增强(方案2)和GAN(方案3)增强后,同一数据集的实际检验和分类结果
为了使实验结果更加直观,我们在表2中列出了三个主要性能指标。可以很好地观察到,与使用原始数据集相比,使用合成图像训练模型的精度、召回率和mAP都得到了提高。当采用生成对抗网络合成的数据进行训练后,检测器的mAP已经超达到99.5%,可以满足绝大多数工业应用场景的需求。我们的实验证明,为了达到预期的性能,有足够的的数据是很重要的。此外,Defect-GAN能够生成具有高保真度和多样性的缺陷图像,从而提高目标检测器的精度。本工作的实验结果也证实了Defect-GAN在缺陷合成的保真度、多样性和可转移性方面的优越性,尤其适用于工业质量控制和缺陷检测。
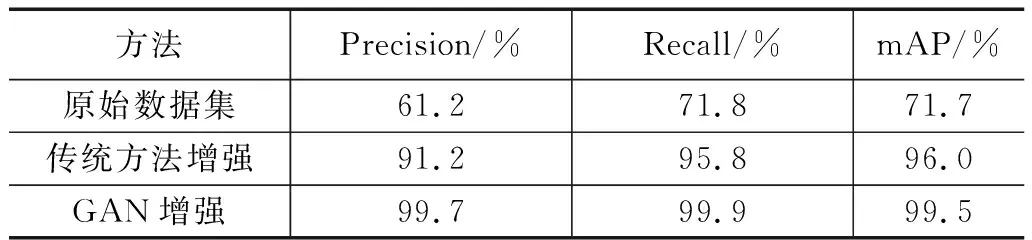
表2 方案1、2、3性能比较
此外,为了进一步验证YOLOv5在工业缺陷检测方面的优越性和适用性,我们将其性能与Faster-RCNN算法进行了比较。实验结果如图9所示。可以看出,在每个数据集的检测结果中,YOLOv5在整体性能上优于Faster RCNN。特别是在原始数据集上训练模型时,mAP从48.6%提高到71.7%,达到了23.1%的显著提高。同样,当模型使用合成数据集训练时,分别有20.6%和16.1%的改善。
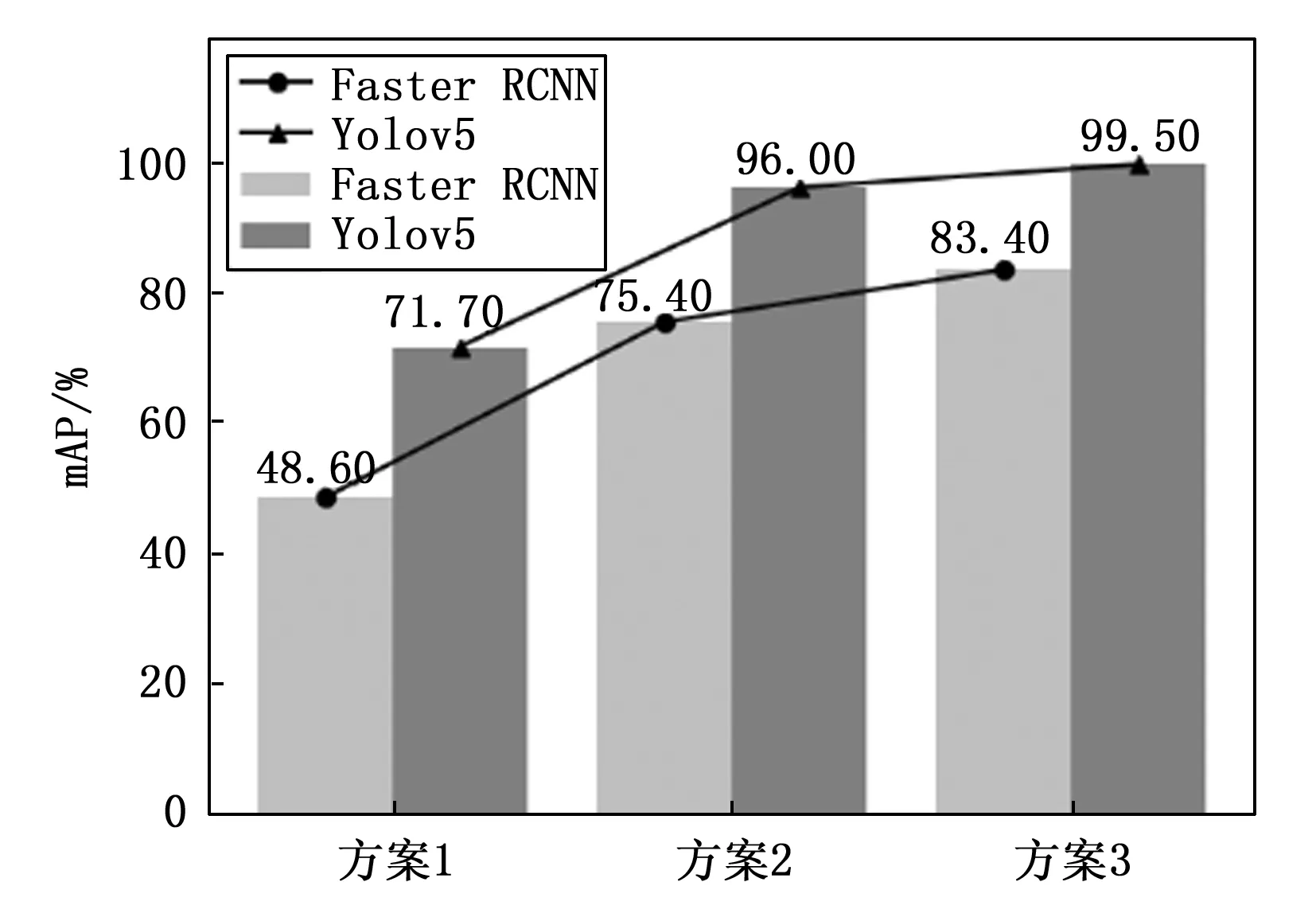
图9 使用两种不同算法(YOLOv5和Faster RCNN)时mAP对比图
4 结束语
总之,在本文中,我们研究并开发了一个用于圆柱表面塑料标签的自动检测和分类平台。我们的主要结论是,通过数据增强合成缺陷图像可以显著提高目标检测器的准确性和泛化能力。我们选择YOLOv5作为目标检测器,因为它具有良好的效率、精度和鲁棒性。针对实际中缺陷样本不足的问题,我们探究了两种数据增强方法。通过使用传统的数据增强方法和Defect-GAN网络训练模型,整体精度得到了很大的提高。所展示的数据增强方法可以合成具有良好多样性和保真度的缺陷图像,能够解决网络训练过程中样本不足的问题,从而提高预测和分类精度。我们相信合成数据的生成可以推广到数据集有限的其他场景,因此特别适用于需要实时缺陷检测和分类的工业应用。
在后续研究中,我们将继续提高超小目标检测算法的精度和泛化能力,并进一步开发复杂的集成软件,用于各种工业场景下的实时缺陷检测和质量控制。
