科技文献自动分类研究*
——以医学类和农学类学位论文为例
2023-08-03谢庆恒
谢庆恒
(国家图书馆,北京 100081)
1 引言
当前,我国智慧图书馆建设的理论与实践研究方兴未艾,文献分类是图书馆赖以生存的重要基础,是智慧图书馆建设中的重要一环。面对图书馆智慧化发展的新需求,国家图书馆于2020年提出建设“1+3+N”的“全国智慧图书馆体系”建设总架构[1]。随后,《国家图书馆“十四五”发展规划》中明确提出推进文献信息智能化加工与编目,并对文献自动分类工作做出了具体要求和部署[2]。科技文献是指报道科技领域原创实证研究与理论研究的文献。按载体性质可划分为印刷型、缩微型、数字型、实物型;按出版形式可划分为科技图书、科技期刊、专利文献、会议文献、科技报告、政府出版物、学位论文、标准文献、产品资料等[3]。学位论文尤其是博士学位论文是一类重要的科技文献,同时也是图书馆的特色馆藏,具有重要的开发和利用价值。实现以学位论文为典型代表的科技文献的自动化标引是推动落实《国家图书馆“十四五”发展规划》的客观要求和重要举措。近年来,我国博士教育事业蓬勃发展,博士毕业生从2011年的50289人逐年增长到2020年的66176人,年均增长3.1%[4],学位论文数量的稳定增长客观上对学位论文的标引效率提出了更高要求,现有传统人工文献标引工作效率低下的弊端逐渐显现,而现有技术条件下标引效率难以提升[5],亟需利用现代信息技术革新标引方式,重构标引流程,实现学位论文等科技文献标引的自动化和智慧化。因此,开展科技文献标引自动化研究,在应对科技文献数量高增长现状、满足提高科技文献标引效率客观需求、加快推动智慧图书馆建设实践方面具有积极意义。
2 相关研究
文本自动分类是自然语言处理领域的经典问题,一般包括文本特征表示、分类器选择与训练、分类结果评价与反馈等过程,相关研究可追溯到20世纪50年代。从分类方法来看,主要经历了基于专家规则到基于统计特征学习[6],再到传统机器学习[7-9]与深度学习神经网络[10-13]的发展历程。深度学习方法出现以前,文本分类大都是浅层次的特征提取,对于文本背后的语义、结构、序列和上下文理解不够,因此分类效果不够理想。近年来,随着深度学习技术的快速发展,特别是2018年Google推出BERT模型以来[14],文本分类效果得到显著改善,之后又出现GPT2、XLnet等改进模型,使得效果得到进一步提升。从研究对象上来看,深度学习技术的出现和应用,有效拓展了文本分类的应用场景,主要包括网络舆情分析[15]、情感分析[16]、问答系统[17]、金融[18]、新闻传播[19]等行业应用。可以说,深度学习技术在推动提升政府管理能力、营造健康网络环境、助力行业良性发展等方面发挥了重要作用,是现代经济社会健康发展不可或缺的重要科技力量。
相较于轰轰烈烈的行业应用研究,科技文献自动分类得到的关注相对较少。笔者在中国知网以篇名“科技文献”包含“分类”检索出中文文献9篇。其中比较有代表性的有檀林[20]等利用科技文献的毗邻文所属的类这一信息,结合科技文献的内容提出了一种协调迭代的科技文献分类方法,效果比传统方法有所改进。白小明[21]等基于SVM和KNN算法研究设计了科技文献自动分类方法,分类性能较好。周丽红[22]等用PredictiveApriori关联算法构建基于关联规则的科技文献分类方法,取得了较好效果。谢红玲[23]等基于深度学习模型,比较了简单RNN、LSTM和GRU模型对科技文献的分类效果,结果表明三者均对未去停用词的科技文献分类效果较好,其中LSTM模型效果最好。张智雄[24]等运用层次分类思想设计和实现了一个基于多层分类器集群的科技文献自动分类引擎系统,并重点解决了科技文献自动分类引擎建设中的高质量数据获取、多层次分类器构建、处理流程优化和开放接口调用等4个关键问题。而学位论文的自动分类研究则更少,仅有1篇[25],且发表时间较早。可见,深度学习模型应用在科技文献自动分类领域是完全可行的,同时也可以看到这方面应用目前不多,仍需加强推广。学位论文是一类重要的科技文献,开展学位论文的自动分类研究是拓宽深度学习研究领域,解决人工分类效率低下难题的重要尝试。因此,笔者基于BERT构建学位论文自动分类模型,以《中国图书馆分类法》R类(医学类)和S类(农学类)学位论文为例,通过实验验证模型在实际分类中的效果,以期为科技文献自动分类的实际应用提供一定参考。
3 研究方法与数据处理
3.1 模型构建
BERT[14]是Google团队于2018年提出的基于Transformer[26]衍生出的双向自编码表征模型,在11种经典自然语言处理测试中取得理想表现,具有里程碑意义。如图1a所示,该模型采用Transformer的Encoder模块,从前后两个方向获取文本特征表示。其中X1,X2,…,XN表示输入字符,经过多层(笔者采用12层)双向Transformer训练后生成相应的向量表示T1,T2,…,TN。其中,Transformer采用Encoder-Decoder结构,摒弃了传统的CNN和RNN,采用Self-Attention机制获取字词之间的依赖关系,使得模型输出的文本语义表示能够刻画语言的本质。BERT仅采用Transformer的Encoder部分,文本输入由字嵌入(token embedding)、句嵌入(segment embedding)和位置嵌入(position embedding)3部分相加构成,每句话用CLS和SEP作为开头和结尾的标记。BERT中文预训练使用字典文件,该文件包含标记符与汉字,且都被统一赋予唯一编号。字嵌入通过查找字典获取编号;句嵌入则表示属于哪个句子,一般用0表示上句,1表示下句;位置嵌入则采用模型动态学习获取。BERT预训练主要包括遮挡语言模型(masked language model,MLM)和下一句预测(next sentence prediction,NSP)两个任务。BERT下游任务主要是使用预训练阶段的词向量完成诸如情感分析、句子关系判断、问答任务、命名实体识别等任务,即所谓的微调(fine-tunning)。BERT输出已完成封装,对于情感分析等单句分类任务,可以直接输入单个句子,将[CLS]的输出直接输入到分类器进行分类;对于句子关系判断任务,需要用[SEP]分隔两个句子输入模型中,然后同样仅需将[CLS]的输出送到分类器进行分类,比较常见的是采用Softmax分类器(见图1b)。
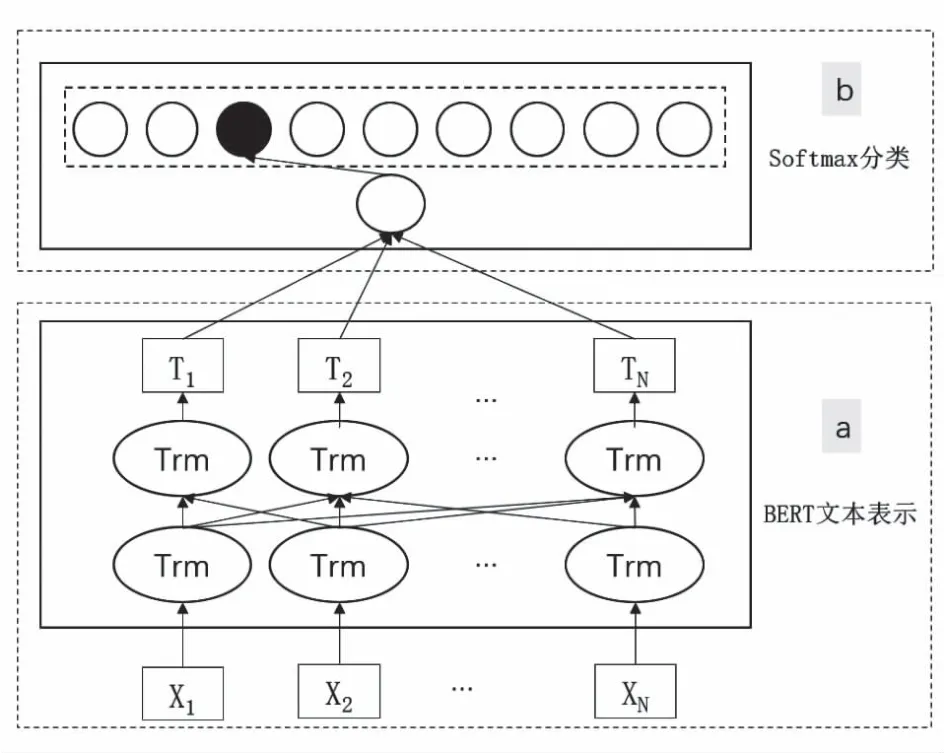
图1 BERT模型结构
3.2 数据处理
笔者的数据采集来自万方中国学位论文全文数据库①。以中图法分类号R、S一级类下的四至五级类目为检索项,分别采集到近些年来论文数据260995条和137885条,每条数据包含题名、摘要和类号,类号细分到四至五级,如四级类号R737.1、S332,五级类号R811.1、S881.2,数据样例如图2所示。

图2 数据样例
经过清洗、去重、删除等操作得到无重复的高质量数据R类目1123类199451条和S类目1321类135184条,其中相当数量的类号下文献数量不足10条。为消除训练数据由于分布不均带来的影响,笔者制定了分类训练样本的类目筛选规则,具体如下(以S类处理为例,R类做类似处理):
(1)以1321个深层级类目为起点,自下而上进行各类目下文献的统计筛选工作;
(2)若某个类目下的文献数量大于等于300,则将该类目直接列入最终类目列表;
(3)若某个类目下的文献数量小于300,则将该类目下的文献合并到其上级类目;
(4)若合并后的类目层级小于四级,则将该类目舍弃,否则,统计合并后的类目下文献数量,若小于300,则重复步骤(3);
(5)若合并后类目下的文献数量不小于300,则将该类目列入最终列表。
整个筛选流程如图3所示,下面以S661和S662为例对上述筛选规则加以解释说明。S661类目下共有S661.1-S661.9共7类2168篇文献,其中S661.1和S661.2文献数量均大于300,按照上述规则将这两个类目直接列入最终类目。S661.3-S661.9各类目的文献数据则均小于300,故将各个类目下的文献合并到上级类目S661,得到S661类目文献146篇,数量依然小于300,此时,重复步骤(3)再向上合并到S661(三级类目),类目层级小于四级,满足条件(4),故舍弃。类似地,S662类目下共有S662.1-S662.9共6类1043篇文献,其中S662.1包含文献528篇,按照规则直接列入最终类目列表。S662.2-S662.9各类目因文献数量均小于300故将其合并到上级类目S662中,得到文献515篇,数量大于300且类目层级为四级,满足条件(5),所以将S662列入最终类目列表,最终得到表1所示的结果。共得到S类目135类共计108762条数据,再按照8∶1∶1分别将各类随机分成训练集、验证集和测试集。同样地,得到R类目129类共计169495条数据,再按照8∶1∶1分别将各类随机分成训练集(135643条)、验证集(16897条)和测试集(16955条)。二者共同组成本文数据集。
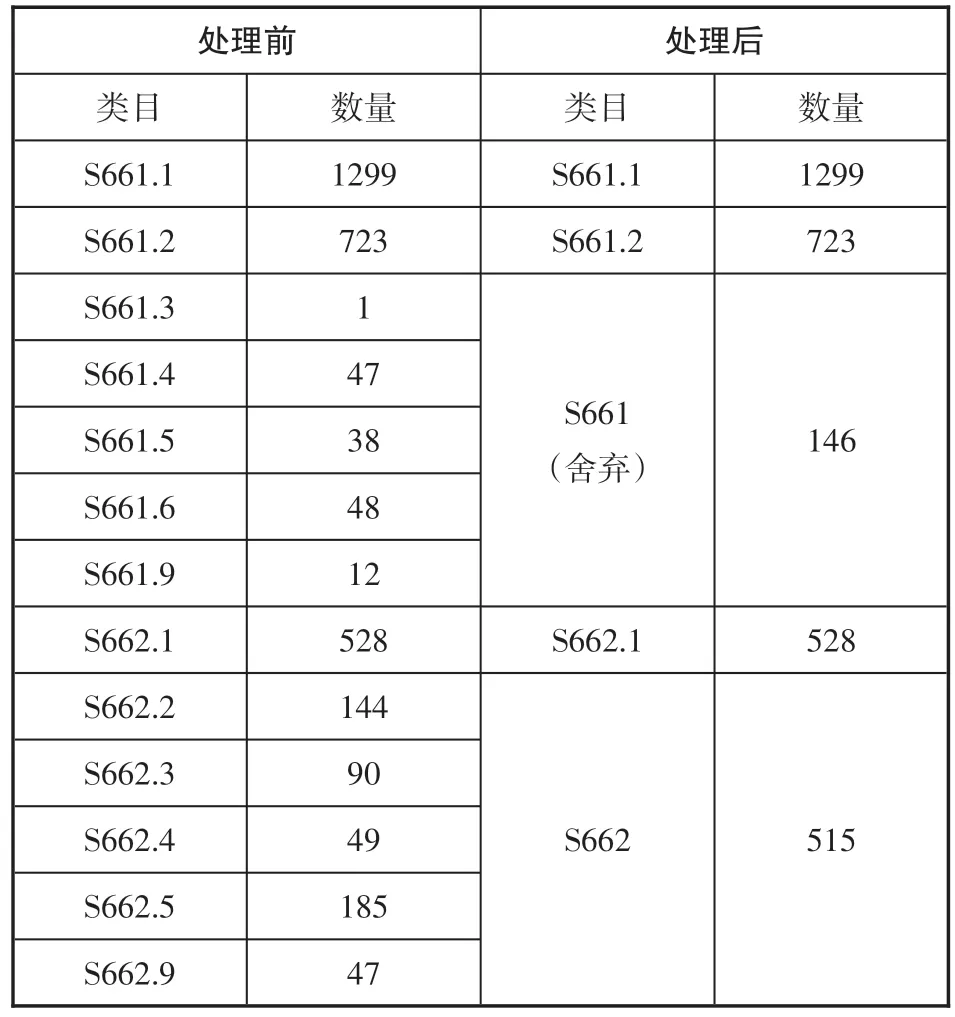
表1 S661和S662下级类目及文献数量
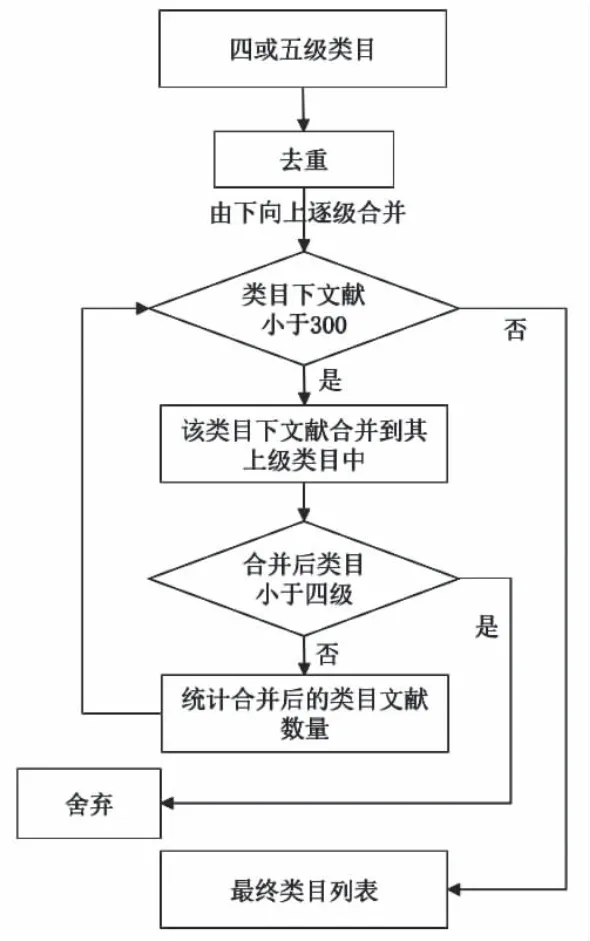
图3 类目筛选处理流程
4 实验过程及结果
4.1 实验环境
由于Pytorch在易用性与速度方面较优,因此笔者采用Pytorch搭建深度学习框架,实验环境如表2所示。
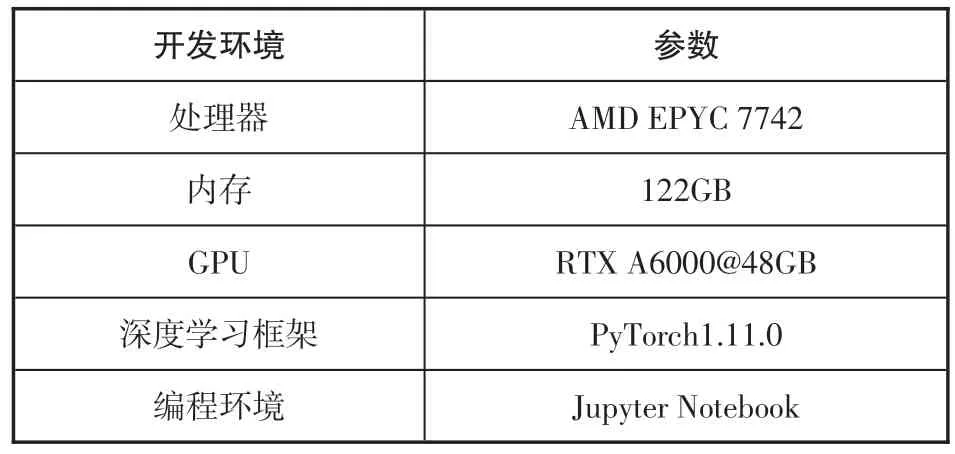
表2 实验环境
4.2 评价标准
采用经典的精确率(P)、召回率(R)、F1值作为模型分类结果评价依据。其中P表示预测为正样本中实际为正样本的比率,反映的是模型查准的能力;R表示实际为正样本中预测为正样本的比率,反映的是模型查全的能力;F1值综合平衡了二者信息,计算公式为:F1=(2×P×R)/(P+R)。
4.3 结果分析
4.3.1 基线模型对比
为了检验模型的分类效果,基线模型采用经典模型Word2Vec和FastText。为提高检验效率,训练语料采用前文预处理数据集中的题名数据部分。模型的基本设置如下:
(1)Word2Vec:使用Jieba分词工具将每个句子进行切词并转换为二维list形式,基于已有的Word2Vec[27]词向量生成词向量再取各词的平均向量作为句子的向量表示。模型参数设置为学习率0.01,训练轮次epoch为3,批次大小为128,dropout率为0.5,采用交叉熵计算损失并通过随机梯度下降法更新模型权重。
(2)FastText:使用已有的FastText[28]中文词向量生成词向量,其他与(1)一致。
(3)BERT:采用Google发布的预训练好的中文模型“BERT-Base,Chinese”生成词向量,取模型输出结果中的“pooler_output”层作为句子向量表示,模型学习率设置为5e-5,epoch为3,批次大小128,dropout率为0.5,损失函数仍采用交叉熵计算方法,通过随机梯度下降法更新模型权重计算出分类结果(见表3)。
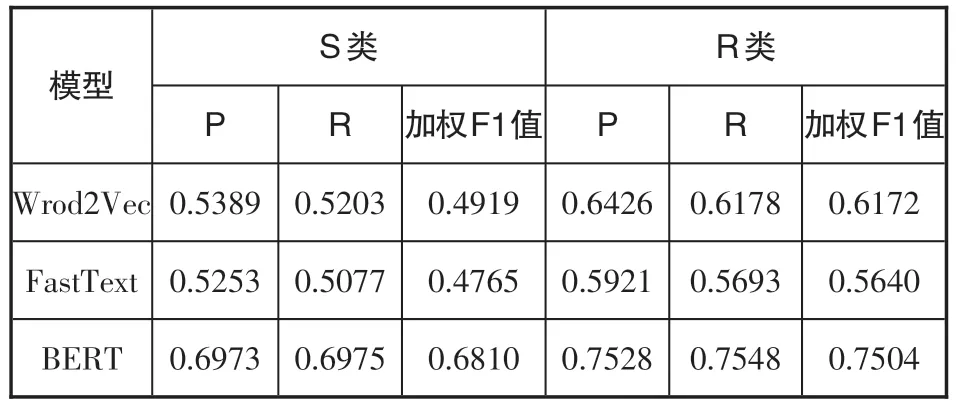
表3 基于题名的模型分类结果
从表3可以看出,在两个类别上BERT模型的F1值均高于传统的Word2Vec和FastText模型,S类分别高出18.91和20.45个百分点,R类分别高出13.32和18.64个百分点,可见BERT模型凭借良好的特征抽取能力保证了其分类效果好于传统模型。因此,笔者选用BERT作为分类模型。
4.3.2 BERT模型结果
训练语料采用前文预处理的数据集的摘要数据部分。参数设置如下:输入层采用Google发布的预训练好的中文模型“BERT-Base,Chinese”,该模型采用12层Transformer,隐藏层的维度为768,Multi-Head-Attention的参数为12,激活函数为Relu,模型总参数大小为110 MB。模型训练参数批次大小(batch_size)设置为40,学习率5e-5,最大序列长度(pad_size)为400,优化器为Adam,dropout率为0.5,训练轮次epoch为2。采用随机梯度下降法对模型权重进行更新(见表4)。
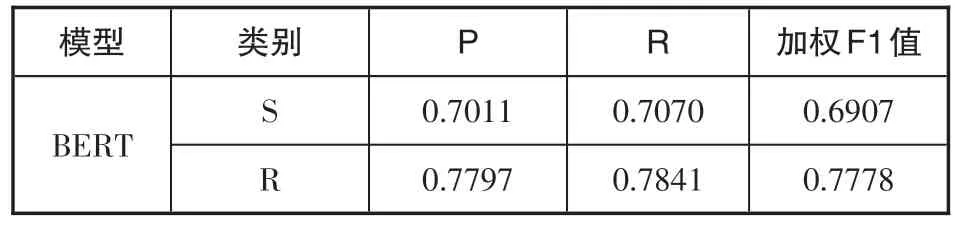
表4 基于摘要的模型分类结果
结合表3和表4可以看出,S类上基于摘要的BERT模型F1值比基于题名的要高出约1个百分点,R类则高出约两个百分点,表明基于摘要数据的分类效果好于基于题名数据。题名是学位论文内容的直观表达,是学位论文最直观的标签。摘要则能较全面地反映学位论文的内容,是学位论文的精简版。可见摘要对论文内容的表达更为详尽,对论文主题的揭示更加充分。同时也表明BERT能够提取出摘要中的文本特征,能够较好识别摘要中的详细信息。
具体来看,R、S类别中F1值提升占比分别为23.26%和62.22%。把S类F1值按照不同变化程度分为8组,分别为{>0.2,[0.1,0.2],[0.06,0.1),(0,0.06),0,[-0.1,0),[-0.2,-0.1),<-0.2},并以此为X值,将对应分组内的基于题名的分类F1值均值(以下简称前值)作为Y值绘制直方图(见图4)。可以看出,在提升20%以上分段内的前值为0.35,随后逐渐递增,到0分段时达到最大值0.89,之后再逐步降低到降低20%以上的分段内的0.51,整体上呈倒U型分布,即在前值较小的样本上F1值变化幅度较为剧烈,而前值较大的样本上F1值变化较为温和。
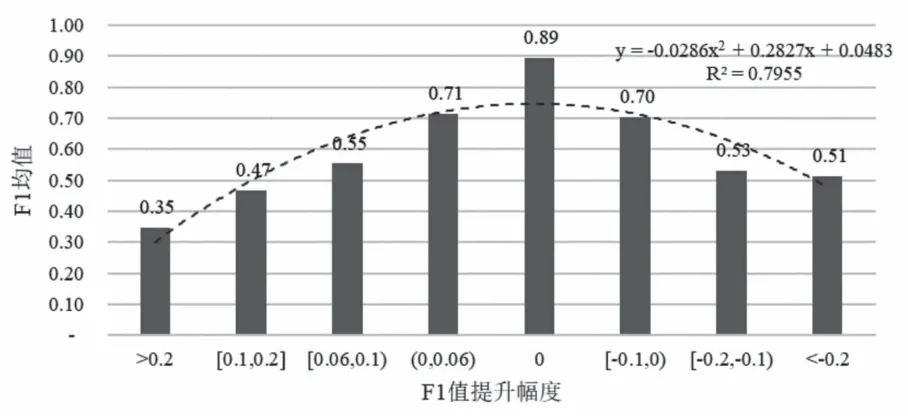
图4 S类(农学类)F1值变化分布情况
通过对各分组内样本文本信息的分析,可以按F1值变化的不同情况将样本分为双显性主题(Title Strength-Abstract Strength,简称TSAS型)、题名隐性摘要显性主题(Title Weakness-Abstract Strength,简称TWAS型)和题名显性摘要隐性主题(Title Strength-Abstract Weakness,简称TSAW型)等3大类型,类似的情形也出现在R类别上。
(1)TSAS型(双显性主题)。指的是题名或摘要中主题词比较明显,二者均能明显体现分类主题。如F1值变化幅度不大的S664.1类(核桃)和R736.4类(垂体腺瘤),二者大多数样本的题名和摘要中都一次或多次出现对应主题词,使模型从题名和摘要中都能轻易提取到对应主题的信息特征,从而提高分类效果。因此,该类型样本基于题名和摘要得到的分类效果相差不明显,表现为F1值变化较为温和。
例1:
2001#$a大别山山核桃遗传多样性及经济性状分析
330##$a大别山山核桃主要分布在安徽大别山区,分析大别山山核桃天然种群遗传多样性及经济性状,旨在更好地保护和合理地开发大别山山核桃资源,从而进一步开展引种试验和示范推广,推进我省山核桃产业转型升级。本文选取自然分布区内的13个种群,运用方差分析、聚类分析、ISSR标记等方法分析了4个坚果经济性状、11个营养物质含量、6个表形性状。获得结果如下……
解析:题名中出现“山核桃”这一主题词,特别是摘要中也多次出现,使得模型从题名和摘要中都能轻易地提取到文本“山核桃”这一主要特征信息,从而提高分类准确率,二者的分类效果也无差别(F1值均为89.41%)。
例2:
2001#$a垂体腺瘤生物学特性的相关因素研究
330##$a本课题通过研究垂体腺瘤的临床和影像学资料;内分泌功能(P R L、GH、ACTH、T S H、F S H、LH)及肿瘤相关抗体(p16、FGF R-4、c-erbB-2、CD44、Ⅳ型胶原)在细胞中的表达,以探讨影响垂体腺瘤增殖、侵袭和预后等生物学特性的相关因素……分析临床资料与垂体腺瘤增殖性和侵袭性的关系……结果:所有95例垂体腺瘤病例中无内分泌功能性腺瘤48例……
解析:题名中出现“垂体腺瘤”这一关键词,在摘要中也多次出现,模型从题名和摘要中都能轻易提取出“垂体腺瘤”这一主题信息,从而提高分类效果,二者分类效果相同(F1值均为88.57%)。
(2)TWAS型(题名隐性摘要显性主题)。指的是题名或摘要中难以轻易识别出主题内容,尤其是通过题名难以提炼出主题信息,模型需要通过对摘要信息的详细“阅读”获取论文主题再进行分类判断,这种情况下基于摘要的分类效果往往要好于基于题名的分类效果,表现为F1值提升幅度较大。
例3:
2001#$a甘蓝型油菜开花时间的遗传及株高和开花时间的Q TL定位
330##$a甘蓝型油菜是中国重要的油料作物,是中国食用植物油的主要来源。株高和开花时间是当前油菜育种的两个重要性状,适当的降低株高和缩短开花时间,对于提高油菜抗倒伏性和早熟性,推动油菜机械化收获,促进油菜产业发展具有战略意义……
解析:题名中主题词“甘蓝型油菜”直观地揭示了论文研究主题为“油菜”,很容易将其分类到S634.3(蔬菜园艺类)。但从摘要内容来看,论文研究主题是作为油料作物的油菜,而非蔬菜类的小白菜,应分入S565.4(油料作物类)。油料作物这一信息只能从摘要内容中识别。因此,基于摘要的分类效果(F1值76.73%)好于基于题名(F1值73.15%)。
例4:
2001#$a经缝牵引成骨术前后颧骨体积的测量及体外细胞模型的构建研究
330##$a面中部骨骼发育不全严重影响患儿的身心健康,目前临床上主要应用正颌外科截骨/植骨术、正畸治疗、截骨成骨术、经缝牵引成骨术(Tr a ns-sutu r a l D ist r a c tion Ost e og e n e sis,T S D O)治疗此种……T S D O通过对患者面部骨缝进行持续牵引从而促进面部骨骼重塑,……综上,面缝具有哪些不同于颅缝的特性、如何在体外构建T S D O的面缝细胞力学模型均亟待阐明。故本研究目的为首次从体积测量的角度全面证实T S D O可促进面部新骨形成(颧骨)……
解析:题名中主题词“成骨术”直观地揭示了论文研究主题为“外科手术”,很容易将其分类到R687.3(骨骼手术)。但从摘要内容来看,论文研究主题是面部骨骼的外科手术,具有一定的专指性,应分入R782.2(口腔颌面部整形外科学),而这一信息主要来自摘要内容。因此,基于摘要的分类效果(F1值75.52%)好于基于题名(F1值71.01%)。
(3)TSAW型(题名显性摘要隐性主题)。指的是题名中主题比较明确,但在摘要中由于背景介绍、表达方式等对主题内容的表达造成了一定的干扰,对题名主题进行了一定的隐匿。在这种情况下,基于摘要的分类效果反而不如基于题名的理想。
例5:
2001#$a联合地基L i DA R与无人机L i DA R的白桦蓄积量反演研究
330##$a森林蓄积量是描述森林生态系统功能和生产力的重要物理指标……如何快速准确地获取森林蓄积量,成为近年来森林资源质量动态监测和林业可持续发展的关键。森林蓄积量的基本单元是每棵活立木的材积……本文以河北省承德市塞罕坝森林公园内的人工白桦林和张家口市老虎沟村的天然白桦林作为研究对象,联合地基L i DA R和无人机L i DA R数据完成了白桦样地森林蓄积量的反演研究。具体研究内容如下……
解析:题名中“白桦”直观揭示了论文研究对象为“白桦”。而摘要中开篇主要讲述森林蓄积量的指标意义及测度反演方法,在一大段论述后提出研究主题“白桦”,给模型提取“白桦”这一研究主题造成严重干扰,很容易误分到S758.5(森林蓄积量),而不是正确的分类S792.153(白桦)中。因此,基于摘要的分类效果(F1值32.56%)反而比基于题名的(F1值59.63%)差。
例6:
2001#$a ETV治疗CHB患者肝细胞癌发生率及预测因子的研究
330##$a目的:对接受恩替卡韦(Entecavir,ETV)治疗的慢性乙型肝炎(Chronic Hepatitis B viral hepatitis,CHB)患者原发性肝细胞癌(Hepatocellular Carcinoma,HCC)的发生率及预测因子的研究,探讨ETV治疗慢性乙型肝炎患者对HCC发生率的影响。方法:……结论:……对于年龄大于50岁的男性患者,尤其是HBeAg阴性慢性乙型肝炎患者,应定期加强监测,尽早发现肝癌,从而改善患者预后。
解析:题名中的“肝细胞癌”这一主题词能够清晰明了地揭示论文主题,容易给出正确的分类号R735.7(肝癌)。而摘要开篇“乙型肝炎”对“肝癌”的特征识别造成了一定干扰,易误分到病毒性肝类R512.6。因此,基于摘要的分类效果(F1值84.16%)不如基于题名的效果(F1值87.28%)理想。
从模型原理上来看,如图1所示,主要有两大部分影响模型分类效果。一个是文本表示部分。文本表示主要是通过词向量模型对待分类文本进行向量化表征以提取文本信息,包括静态和动态两种。一般而言,动态词向量(如笔者采用的BERT模型)能综合文本上下文、语法、词性等信息,对文本信息的提取能力较强,因此采用动态词向量有助于提高模型分类效果。另一个是分类器部分。分类器是将文本向量按照一定的规则进行归类,一般采用神经网络模型,比如本文模型就采用经典的Softmax神经网络分类器,它能通过交叉损失熵的反向传播不断迭代更新神经网络参数,使模型朝着损失最小的方向演化,以提高分类效果。
在本研究模型结果分析中可以发现,BERT对文本信息的提取能力优于静态模型Word2Vec和FastText,是模型分类效果优良的重要保证。TSAS型(双显性主题)中,不管是题名还是摘要,BERT都能成功准确提取主题信息,尤其是在TWAS型(题名隐性摘要显性主题)中,BERT能抓取到题名中遗漏的重要信息。分类器主要进行的是监督分类,因此文本标签质量就显得十分重要。文本标签的混乱会对模型分类效果造成较大影响,特别是同类文本被贴上不同标签时,会给分类器带来很大“困惑”。比如前文提到的“油菜”这一主题,有的被分到S634.3,有的被分到S565.4,这样分类器在进行交叉熵反向传播更新参数时会出现混乱,难以找到最优值,导致分类效果不够理想。
5 结论与建议
5.1 结论
文献分类是图书馆学、情报学领域的经典课题,传统的人工文献分类方法在文献数量暴增的当下已不太适用,深度学习技术的快速发展使得文献的自动分类成为可能。笔者构建BERT分类模型,以医学类和农学类学位论文为例,分别基于题名和摘要数据对科技文献的自动分类展开了探讨。结果显示,在两大类别上基于摘要数据的分类效果整体上均好于基于题名,摘要数据集上医学类和农学类F1值分别达到77.78%和69.07%,相应高于题名数据集上的75.04%和68.10%。从具体样本来看,按照F1值变化的不同情况将样本分为TSAS型(双显性主题)、TWAS型(题名隐性摘要显性主题)和TSAW型(题名显性摘要隐性主题)。在TSAS型上基于摘要的分类提升效果不太明显,同时也彰显训练样本分类质量的重要性。TWAS型中摘要的详细表达给模型分类效果带来较大提升,说明模型训练样本承载详细信息的重要性。TSAW型中由于写作方式等问题给模型提取信息造成了一定的干扰,出现了信息冗余,导致基于摘要的分类效果不如基于题名的效果,说明论文写作的规范性对模型分类效果具有重要影响。
5.2 建议
鉴于训练样本分类质量、写作方式和样本承载信息量对模型分类效果的重要影响,笔者从以下3个方面提出相应建议,以期提高学位论文等科技文献的自动分类效果。
(1)夯实数据质量
数据是模型进行自动分类的重要基础,是模型分类结果的决定性因素。训练样本的数据质量决定了模型分类器参数的更新方向,直接影响分类效果。应通过人工审核、校验等过程提高训练语料的分类数据质量,尽量避免同类样本被误分到不同类目的现象发生。
(2)规范写作方式
直入主题的写作方式便于模型对主题特征的提取。论文作者在写作摘要时应当开门见山、直截了当地表达论文主题思想,尽量避免背景介绍、内容综述铺垫过多而造成的对主题信息的干扰甚至淹没。可以适当精简背景分析和对主题来龙去脉的介绍,而把重点放在论文主题相关内容的描述和解析上。
(3)拓宽信息来源
题名、摘要、关键词、引言、结论等都是学位论文的重要组成部分,是论文主题的主要信息点。这些部分均难以单独全面、充分地揭示论文主题。因此,需要将这些信息点融合起来,通过不同信息源之间的互补来弥补单一信息源揭示不够全面、充分的缺陷,从而达到提高分类质量的目的。
注释:
① 万方中国学位论文全文数据库.https://c.wanfangdata.com.cn/thesis.
