基于级联YOLOv7的自动驾驶三维目标检测*
2023-07-31赵东宇赵树恩
赵东宇,赵树恩
(重庆交通大学机电与车辆工程学院,重庆 400074)
前言
自动驾驶周围场景的精准感知是自动驾驶系统决策规划的基础。三维目标检测主要是通过图像、点云及多维数据融合等方式获取自动驾驶周围场景静动态目标的位置、几何信息和类别信息,以实现自动驾驶车辆对行驶环境的准确认知,进而做出最优的决策规划和运动控制。
三维目标检测可以有效解决检测过程中目标遮挡、深度信息缺乏等问题,且能表征目标之间的空间关系。目前三维目标检测常用方法主要有图像、点云及多维数据融合等方法。Li 等[1]提出高效三维检测框架GS3D,通过单目相机获取的图像进行三维物体检测,基于Faster R-CNN[2]增加了方向预测分支,预测目标框和观测方向。Li 等[3]提出Stereo RCNN,采用权重共享网络提取左右图像的特征,对二维RoI 和三维模板进行相似性匹配,通过Mask RCNN[4]预测语义关键点,最后根据二维检测框和三维角点投影关系的约束来预测三维边界框。但该类方法仅以图像为输入,获取图像的颜色属性、纹理信息,依赖先验信息来设计模型,导致单目、立体视觉三维检测的精度不高,缺乏深度信息。
基于点云的目标检测通常是将点云转化为二维视图、体素或直接运用原始点云进行特征信息提取。Bewley 等[5]根据目标距离远近,运用范围条件膨胀层RCD 来连续调整卷积核膨胀率从而处理尺度变化,再采用3D R-CNN 优化3D 候选框来缓解遮挡问题。这类方法在生成二维视图时可能会忽略压缩轴上的大量信息。
李悄等[6]以SECOND[7]网络为基础,提出一种采用稀疏3D 卷积的三维目标检测方法Reinforced SECOND,将堆叠三重注意力机制引入体素特征编码网络,并设计了残差稀疏卷积中间网络,提升了模型检测速度。Hu 等[8]针对点云密度的变化,提出了一种端到端三维检测体系,通过体素质心定位三维稀疏卷积主干的体素特征,利用核密度估计和点密度位置编码器对体素特征进行聚合。张名芳等[9]运用体素占用编码点云,通过构建金字塔主网络结构传递语义信息和位置信息,利用ROI Align 层对齐不同尺度特征图,实现鸟瞰图(bird’s eye view,BEV)车辆目标检测。该类方法会受到体素比例划分的影响,在全局点云离散化过程中的信息丢失降低了细粒定位精度,掩盖了原始数据的自然不变性。
Shi 等[10]提出一种基于PointNet++[11-12]的PointRCNN 算法,运用PointNet++将场景的点云分割为前景点和背景点,自上而下生成三维候选框,结合建议框中规范化的点集坐标与全局语义特征,进行三维框回归和置信度预测。Yang 等[13]提出3D-SSD算法去除了 PointNet++中较为耗时的FP 模块和优化模块,采用一种融合欧式距离和特征距离的最远点采样法,通过结合语义信息排除大量背景点。此类方法直接处理原始点云,造成大量信息冗余,目标点云的采样策略导致了关键点周围存在较多背景点,牺牲了实时性。
基于多维数据融合的三维检测方法充分利用了图像与点云的数据优势。谢德胜等[14]提出了PointRGBNet,利用点云投影到图像生成的六维RGB 点云作为输入,让网络直接学习六维 RGB 点云特征,输出目标的三维检测结果。Wu等[15]提出了一种多模态框架SFD(sparse fuse density,SFD),利用深度图补全生成伪点云,并设计了一种高效的伪点云特征提取器,运用3D-GAF(3D grid-wise attention fusion)策略充分融合了不同类型点云的信息。徐晨等[16]提出一种基于F-PointNet[17]融合稀疏点云补全的目标检测算法,运用编码器-解码器机制构建点云补全网络,将稀疏点云补全为能够传递几何信息的密集点云,进行点云检测。张旭豪[18]设计了多尺度上下文信息聚合的深度补全算法,结合注意力机制与全局平均池化构建了编码器,基于卷积神经网络构建了解码器,实现图像边缘区域深度补全,再结合原始点云进行目标检测。该类方法所依赖的特征提取网络、二维检测算法的精度不高,对于被遮挡程度较大的目标易出现漏检。
综上,尽管有许多学者已对车辆和行人等目标进行了三维检测研究,并取得了较丰硕的成果,但仍存在以下问题:(1)在强遮挡环境下,基于图像的检测易受物体间聚集的影响,并缺乏深度信息。(2)基于原始点云的方法完整地保留了点云的原始分布信息,但在大规模点云中提取目标关键点的过程缺乏指导性,搜索范围过大,影响自动驾驶车辆对周围目标检测的实时性。
因此,为有效解决目标检测深度信息的缺乏,且在保留原始点云信息的同时减少点云全局分割的计算复杂度,进而提升对强遮挡目标的三维检测精度与实时性,本文以截体点网F-PointNet 映射策略为基础,提出一种级联YOLOv7[19]的三维目标检测模型,通过将二维检测区域纵向扩展至三维点云空间,实现对复杂环境中周围车辆和行人等交通目标的实时准确检测、定位与理解。图1所示为级联YOLOv7的三维目标检测框架。
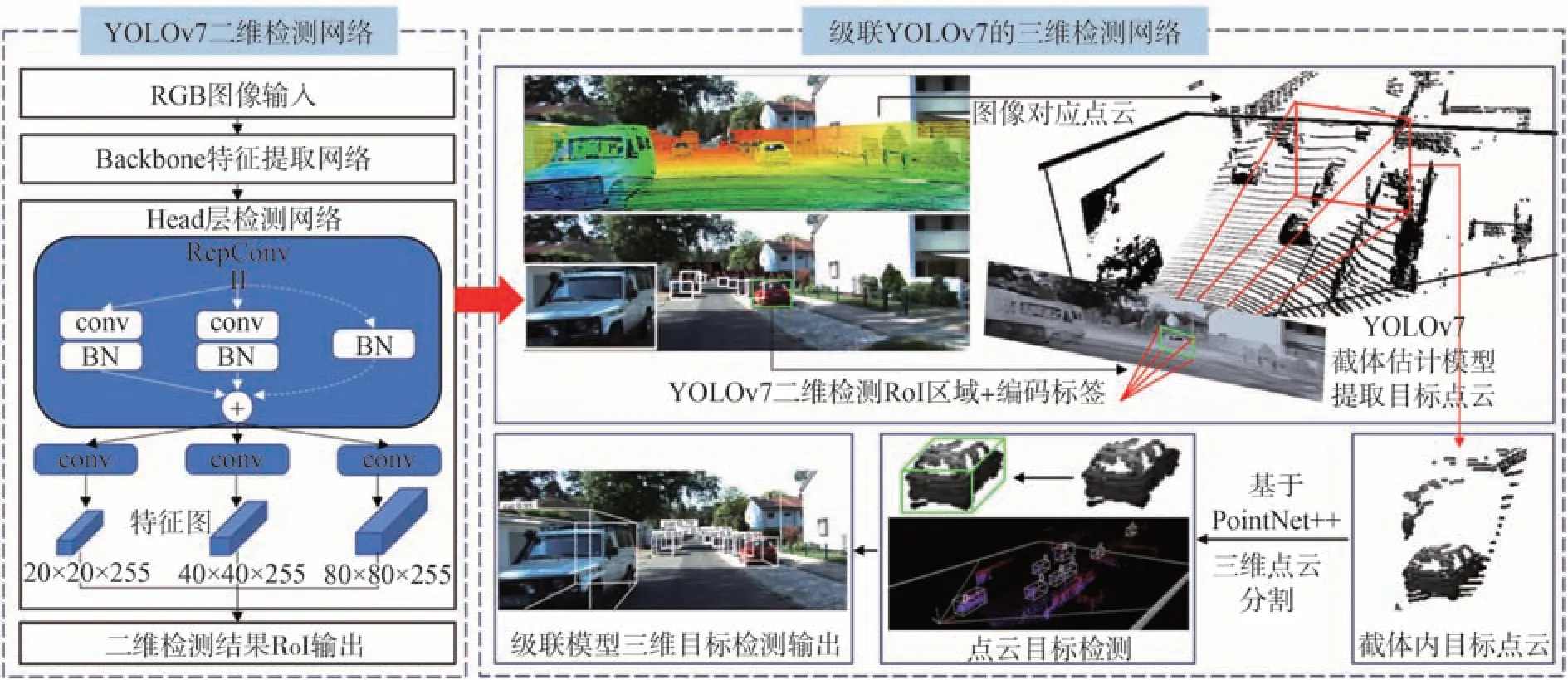
图1 级联YOLOv7的三维目标检测框架
首先运用YOLOv7 快速检测目标的二维感兴趣区域RoI和类别,进而构建YOLOv7截体估计模型以提取二维RoI 对应的目标点云。然后运用基于PointNet++的点云分割网络对截体中的目标点云进行分割,剔除背景点云。最后通过非模态三维边界估计网络,在自动驾驶场景下输出周围目标的长宽高、长宽高残差、航向角和航向角残差等信息,同时利用轻量级回归点网(light-weight regression PointNet,T-Net)修正算法,估计并修正目标的真实质心坐标,不断精确目标的三维参数。
本文的主要贡献:
(1)在复杂交通环境下,运用YOLOv7 二维检测算法对车辆、行人、骑车人进行快速检测,并在纵向上拓展YOLOv7 的检测深度,解释了二维图像中各目标之间的自然分离状态,并回归了更丰富的尺寸和航向信息。
(2)构建了一种级联YOLOv7 的三维点云目标检测模型,降低了三维检测算法PointNet++的点云搜索范围,提升了传统F-PointNet 框架的检测速度与精度。
1 基于YOLOv7的目标点云提取
1.1 二维目标感兴趣区域提取
YOLOv7 主要运用了高效聚合网络ELAN、重参数化卷积、基于级联的模型缩放等策略提取目标特征,进而在二维图像上精确提取目标感兴趣区域RoI,由Backbone 主干网络和Head 层RoI 提取网络组成。输入层将交通场景图像统一为640×640×3 大小。图2 为基于YOLOv7 的二维目标RoI 提取流程。
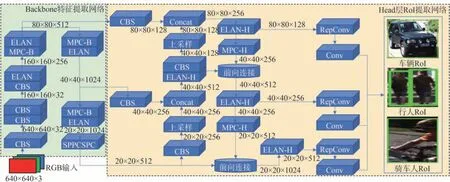
图2 基于YOLOv7的二维RoI提取流程
如图2 所示,Backbone 网络由CBS、MPC-B、ELAN、SPPCSPC 等模块连接构成。CBS 由1 个Conv层、1 个BN 层、1 个Silu 激活函数构成,提取不同尺度的图像特征。MPC-B 与MPC-H 在CBS 基础上增加最大池化分支,上分支通过最大池化进行下采样,再经过1×1 的CBS 减半图像通道数,下分支经过1×1 CBS 减半图像通道数,再连接3×3 步长为2 的CBS下采样,连接两分支得到扩展下采样结果,提高网络的目标特征提取能力。
ELAN与ELAN-H将特征图划分为两个部分,然后基于跨阶段局部网络(cross stage partial networks,CSPNet)将其合并,结合分割梯度流来使梯度流通到不同网络路径进行传播。通过切换级联和转换的步骤,将传播的梯度信息差异化,解决因梯度信息重复而造成的计算负荷大的问题,使主干网络能学习到被遮挡目标更多的特征。ELAN 有两条分支,上分支是1×1 CBS 做通道数变化,下分支连接了1 个1×1的CBS、4个3×3 CBS做特征提取,最后把4个特征整合得到最终的特征提取结果,ELAN-H 则是把每个CBS提取的特征都整合起来。SPPCSPC 模块中,SPP通过3 个不同尺度的最大池化增大感受野以处理复杂行驶环境中尺寸不同的目标,CSP 将特征分为两部分,一部分连接1×1 CBS,另一部分进行SPP 结构的处理,将计算量减半,最后运用Cat 操作将各分支各尺度的特征进行融合。
最终在Head 提取层中将所有特征输入到由BN层和Conv 层组成的RepConv 层进行特征整合,准确提取车辆、行人、骑车人等目标在图像中的RoI。
1.2 目标点云提取
为准确提取YOLOv7 所确定的目标RoI 在三维空间对应的点云,将RoI 左上、右下点坐标形成的近平面与激光雷达传感器的远平面相连接,成像为一个包含目标点云在内的截体,构建YOLOv7 截体估计模型。由于估计模型以不同传感器的信息作为输入,目标的位置存在多样性,导致截体有多种朝向。因此,通过图3(a)→图3(c)坐标转换对截体方向进行标准化,增加截体的旋转与平移不变性以加强模型对多目标检测的适应性。

图3 截体估计模型坐标转换
图3(a)→图3(b)将相机坐标系绕YC轴旋转至2.1 节中输出的目标点云质心方向;图3(b)→图3(c)将坐标中心沿ZC轴平移至目标点云的质心,相机坐标系与掩膜点云坐标系转换关系为
式中:XC、YC、ZC为相机坐标系下目标的位置;XM、YM、ZM为掩膜点云坐标系下的点云坐标;图3(a)→图3(b)旋转矩阵Rf为
式中:α、β、γ分别为绕XC、YC、ZC轴旋转角度,β为点云质心O与图像平面法线的夹角;根据KITTI 标定矩阵,取α=0,γ=0;图3(b)→图3(c)平移矩阵为
各目标相机坐标与图像坐标关系为
坐标系转换后,根据图像坐标与像素坐标换算关系,最终求得在掩膜点云坐标系下每个截体中目标点云坐标为
式中:(u,v)表示像素坐标系中通过YOLOv7 检测出的目标像素的行列值;(u0,v0)为像素坐标系中点坐标;dx、dy表示像素的物理尺寸;D*是点云深度值;fc表示相机焦距。
截体估计模型将相机坐标系与激光雷达坐标系进行了转换,统一计算了截体方向,根据二维RoI 映射的三维截体,提取像素级目标在三维空间中的点云坐标,目标点云提取结果如图4所示。

图4 目标点云提取结果
图4(a)为YOLOv7 所确定的RoI,通过该区域估计出对应的截体,图4(b)为各个截体内所有的点云,包含目标点云与背景点云。结果表明,截体估计模型能有效拓展二维RoI 维度,在大规模点云中提取目标点云,并排除目标周围大量非相关原始点云。为增加对截体中目标类别的识别精度,将二维RoI中目标的类别进行one-hot编码,使后续目标点云分割网络可以在一个特定的目标类别下进行实例分割。
2 级联YOLOv7三维目标检测算法
F-PointNet 结构主要以二维RoI 划定三维点云区域,然后运用点云分割网络进一步实现三维目标检测。在此基础上,级联YOLOv7 的三维目标检测算法架构如图5所示。

图5 级联YOLOv7的三维目标检测算法架构
图5 中级联模型的主体由目标点云提取、目标点云分割、目标三维边框检测3 部分构成。M=[(x1,y1,z1),(x2,y2,z2),…,(xM,yM,zM)]为截体中的点云集合,包含前景目标点云与其他背景点云等多种点云信息;N为经过点云分割后的目标点云集合N⊆M;D=(x,y,z,s)为每个点的特征维度,s为反射强度;k为YOLOv7 目标检测网络输出的目标类别数量。
2.1 目标点云分割
目标点云分割模块用于分割截体内部的目标点云与背景点云。以车辆、行人、骑车人的点云三维模型为数据集,通过深度学习的方式训练PointNet++网络。首先通过构建分层点集特征提取结构,运用最远点采样算法(furthest point sampling algorithm,FPS)在截体内部点云M中均匀采样M-t个中心坐标,t≠0。然后以中心点为球心,取半径为R的球形域,将整个截体点云划分为不同的局部点云,每个局部点云包括K个点,输出一组大小为(M-t)×K×(d+C')的点集,表示(M-t)×K个具有d维坐标和C'维特征的点云。最后提取各局部点云中目标的浅层特征,沿着层次结构逐步抽象出更大范围的区域,直到提取到点集的全局多尺度特征,使得PointNet++分割网络能够更精确地分割出目标点云。针对大量点云密度分布不均匀情况,通过多尺度分组(multi scale grouping,MSG)和多分辨率分组(multi resolution grouping,MRG)增加对于密集和稀疏点云特征提取的鲁棒性。
目标点云分割网络能在排除背景点云同时,输出掩膜点云坐标系下各个目标点云的坐标、目标点云质心坐标O和目标概率分数Pm,为边框检测和类型识别提供依据。目标点云分割过程如图6所示。
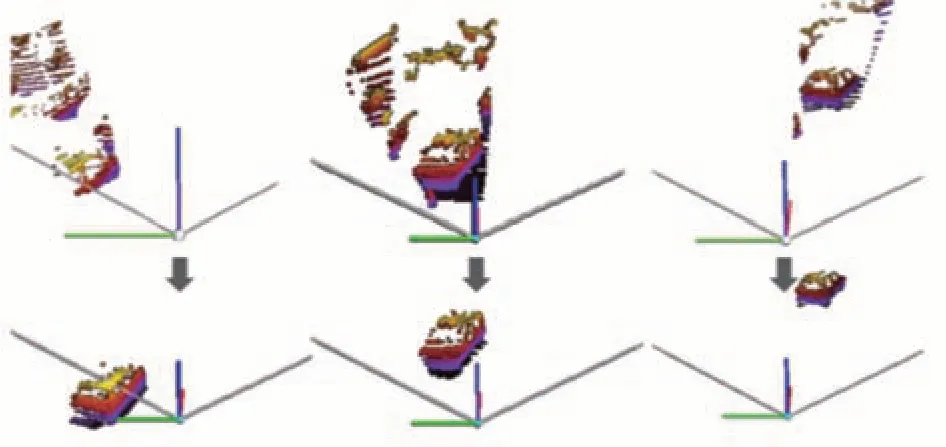
图6 目标点云分割结果
图6 表明,PoingtNet++在较小的截体内可有效提取以采样点为中心的局域特征,并正确分割出完整的目标点云。较小的截体意味着无须再进行全局点云搜索,具有较好的计算效率,充分运用原始点云的特征也可使提取的局部特征较为有效,分割出的目标点云更精确。
2.2 目标边框检测
由于车载激光雷达获得的点云均来自于目标的表面反射,目标点云质心仅根据目标表面点云所计算,因此为消除目标点云质心位置与目标内部质心之间的坐标偏差,运用T-Net 计算目标的真实质心,将掩膜点云坐标系转换为三维目标坐标系,使边框检测模块可通过目标内部质心更准确地计算目标的物理信息。T-Net结构如图7所示。

图7 轻量级回归点网T-Net
图中k为one-hot 编码的目标类别信息,将N个目标点云坐标和目标点云质心坐标O=(xM,yM,zM)作为T-Net 输入,其中O∈N。通过隐藏层神经元数量为(128,256,512)的多层感知机(multi layer perceptron,MLP)监督学习,输出目标点云质心坐标距离真实质心坐标的残差μ=(r1,r2,r3),通过α-μ,修正得到在三维目标坐标系下各点云的坐标以及真实的质心坐标,如图8所示。
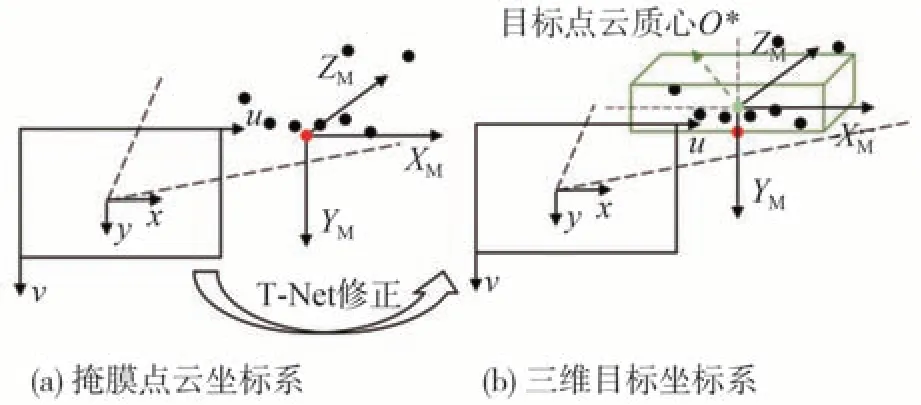
图8 T-Net坐标修正
将各点反射强度s和真实质心O*坐标共同输入基于PointNet++的非模态三维边界估计网络,如图9所示。

图9 非模态三维边界估计网络
针对已分割出的目标点云,图9 边界估计网络首先对点云集合进行单尺度分组(single scale grouping,SSG),然后通过集合抽样层(set abstraction,SA)提取不同邻域球中的点集特征,使得网络能够在远距离点云稀疏的情况下正确回归目标的三维几何边界。最终边界估计网络通过全连接层输出三维参数总量F:
式中:3为T-Net回归之后对于质心坐标O*的残差回归数;NS是不同尺寸的三维锚框个数,每个锚框有置信度P*以及边界框L、W、H的残差回归4 个维度;NH代表不同朝向的锚框,有置信度P**和航向角θ两个维度。边界预测过程中,边界估计网络预测的质心残差O3Dbox、上层T-Net 回归的质心残差μ和目标点云质心O通过O*=O3Dbox+Δμ+ΔO不断修正,更新目标真实质心O*。
级联网络的目的是获取目标的类别以及三维边界框的位置、大小和航向角。综合损失函数LD定义如下:
式中:Lm-seg为PointNet++对截体点云进行语义分割的损失;Lc1-reg为T-Net 的质心平移损失;Lc2-reg为非模态边界估计网络的质心回归损失;Lh-cls和Lh-seg为预测航向角的分类损失和分割损失;Ls-cls和Ls-seg为三维边界框尺寸的分类损失和分割损失;Lh-cls、Ls-cls使用Softmax 交叉熵损失,回归使用L1 范数损失;φ=1 和ω=10。为对三维边界框回归的参数精度进行优化,引入Lcorner角度损失,定义8 个预测角和真实角的距离损失:
3 实验结果与分析
3.1 实验设计
实验环境配置如下:级联模型程序采用python 3.6 编写,Tensorflow1.4 环境下完成训练。硬件条件:CPU 为锐龙7 5800X 8C16T,内存 为Kingston 16GB,GPU为NVIDIA Quadro RTX4000 8G。
级联模型采用COCO 预训练权重在KITTI 数据集上进行迁移学习。KITTI包含3 712帧训练集以及带有真实值的3 769帧验证集,类别包含车辆、行人、骑车人。验证模型时按照KITTI 中标注的目标截断和遮挡程度参数,将目标划分为简单、中等、困难3个级别。
训练时运用Adam 优化器;初始学习率0.001,运用指数衰减法降低学习率,每20 000 次迭代衰减50%,对于每一个样本从点云截体中抽取2 048 个点用于训练。设置batch size=24,epoch=200,边界交并比阈值为0.7。
3.2 分析对比
为验证级联模型对于目标的检测性能,选择验证集中不同遮挡程度的场景进行实验。级联模型在多个复杂行驶场景中的检测过程如图10所示。
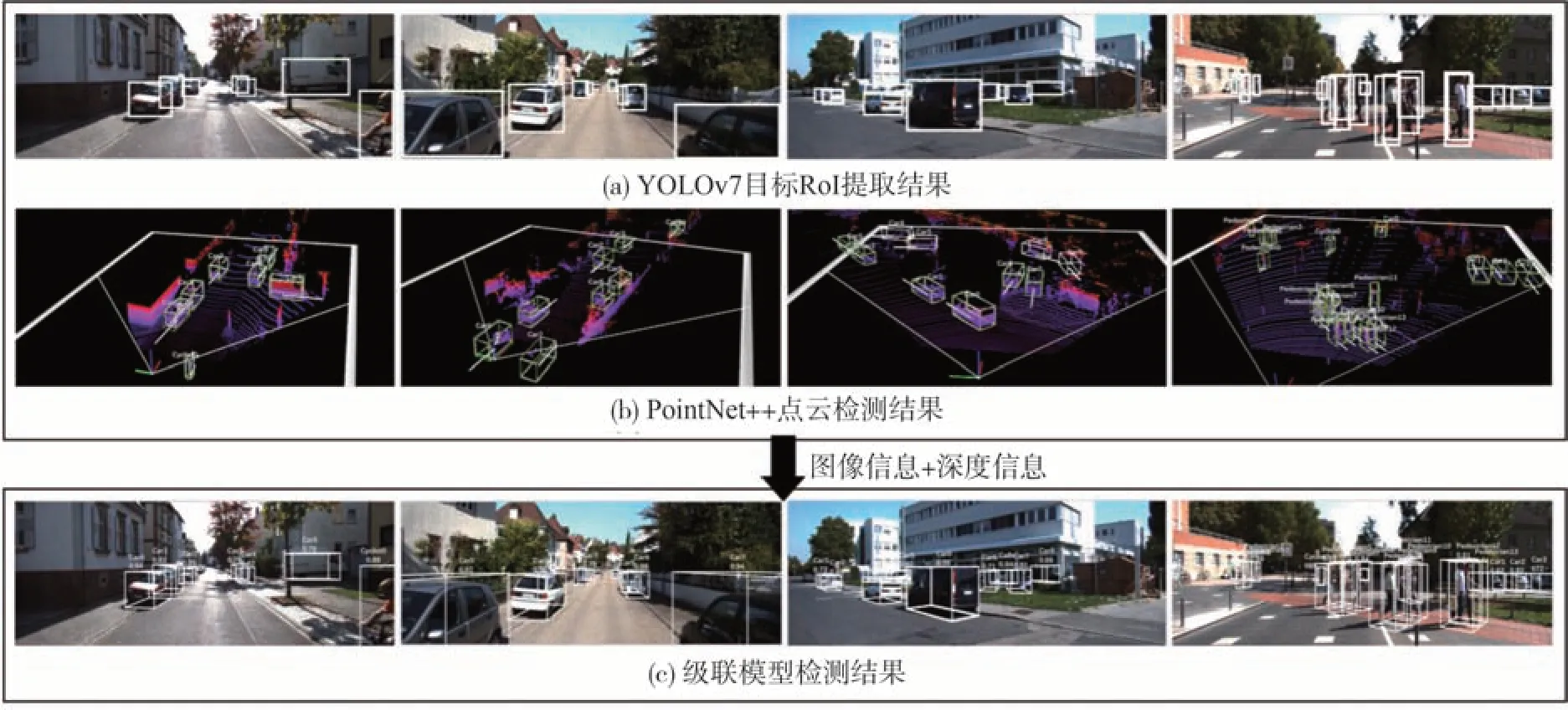
图10 级联YOLOv7三维检测模型输出过程
图10(a)是YOLOv7 目标RoI 提取结果。图10(b)是PointNet++目标点云的检测结果,下方白线为目标航向。图10(c)是级联模型融合图像与点云后最终的三维检测结果,后端输出包含航向、目标长宽高。结果表明:级联YOLOv7 后,模型检测结果非常接近真实边界。级联融合策略使检测网络具有更高的鲁棒性,对于尺度较小且被遮挡的目标,能有效检测并补充其完整几何信息,弥补了基于图像的目标检测在部分遮挡和严重遮挡工况下对目标的残缺检测劣势。
为验证级联模型相较于其他三维目标检测算法,对在复杂交通环境下被强遮挡的目标是否能进行更加实时且有效的检测并补全其信息,设定交并比(intersection over union,IoU)为级联模型优劣的评估标准,进一步计算查准率Pr-查全率Re曲线(precision-recall curve,P-R)下的包围面积可得到平均精度(average precision,AP)。
式中:NTP、NFP分别是针对当前目标真实框,IoU大于、小于阈值的数量;NFN为未检测出的目标数量。mAP则为类别AP 值的和与所检测类别个数之比。为探究模型在足够高准确率下的召回率,设置车辆IoU=0.7,行人和骑车人IoU=0.5。不同难易程度下,级联模型对于不同目标的检测结果P-R曲线如图11所示。

图11 级联模型检测结果P-R曲线
图11 中,2D 为YOLOv7 的二维RoI 提取结果。结果表明,在3 个级别中,车辆检测准确率AP 分别为97.27%、96.19%、89.97%;行 人AP 分别为87.52%、83.60%、76.53%;骑车人AP 分别为88.99%、72.87%、70.89%;简单级别中所有类别平均检测精度mAP=91.26%;中等级别mAP=84.22%;困难级别mAP=79.13%。且在设定阈值的约束下,对于验证集1242×375 尺寸的图像平均推理速度仅为0.02 s/帧(GPU),即FPS=50。
3D 为级联模型的三维检测结果,为验证级联模型的精度优势,表1 对比了多种基于不同数据类型的三维检测算法在同一数据集下的检测结果。
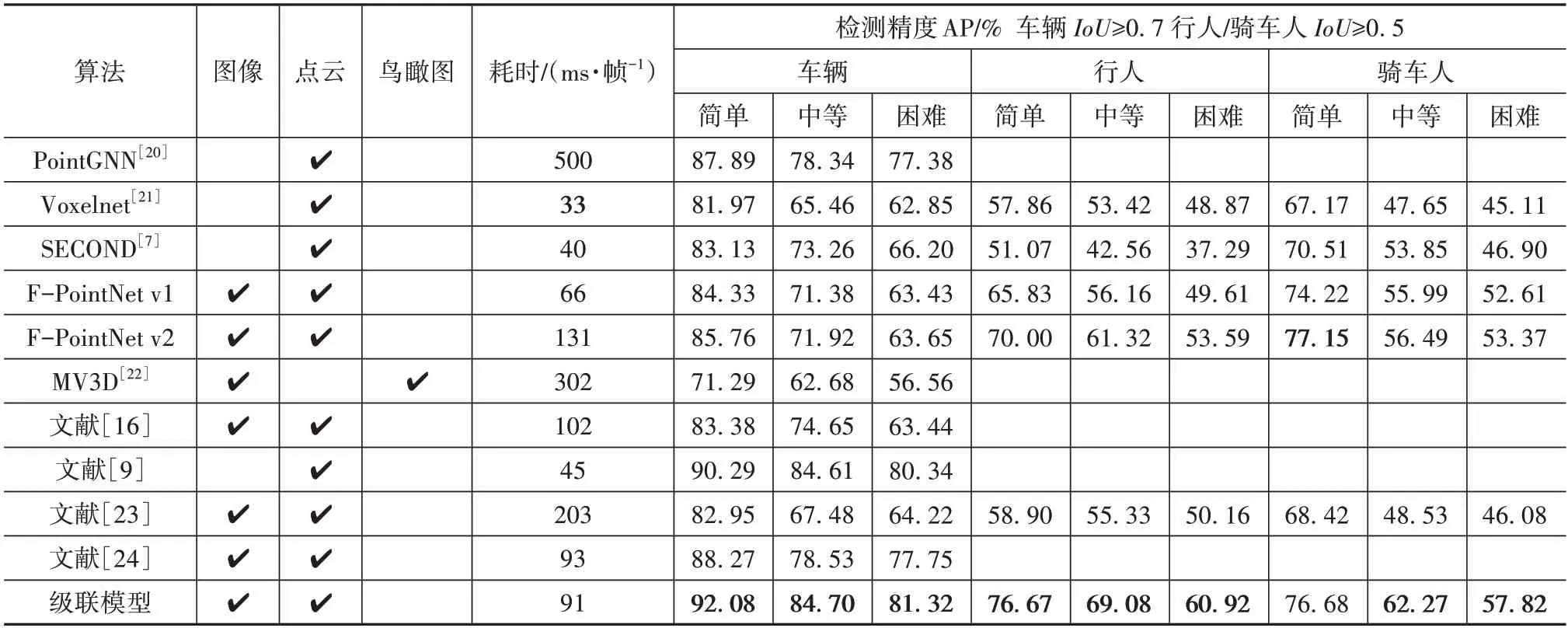
表1 不同算法在KITTI验证集中的三维检测精度
表1 结果表明,相较Point-GNN、Voxelnet、文献[9]模型等仅以点云为网络输入的算法网络,级联模型在不同复杂度的交通场景下平均检测精度提升明显;相较融合图像与点云的算法网络,级联模型精度与速度均存在优势,说明级联融合策略能够有效提高网络检测性能。相较基准网络F-PointNet v2耗时缩短了40 ms/帧,说明运用YOLOv7对周围目标进行快速检测的策略在三维检测精度足够高的情况下有效提升了算法的实时性,对于在中等、困难级别的车辆和骑车人,基准网络mAP分别为63.24%、56.87%,级联模型mAP分别为72.01%、66.68%,分别提升了8.77%,9.81%,表明模型对遮挡较严重的目标检测精度提升较好,并能准确检测其几何信息,源于YOLOv7 提升了特征提取策略,更好地提取了小尺度特征,使得PointNet++分层点集结构可以更完整提取出更多训练特征,但由于单阶段二维RoI 提取网络不存在目标锚框建议阶段,级联模型将远距离未遮挡且模糊的骑车人类别标签误识别为行人,使得NFN增大0.88%而Re降低0.47%。相较MV3D 将点云转化为鸟瞰图的算法,级联策略最大程度地保留了原始点云特征,在提升了22.42%精度的同时,实时性也优于该算法。这是因为YOLOv7截体估计模型划分的局部点云区域能够弥补处理全局点云造成的计算量庞大的劣势,GPU处理有更高的运算效率。
为确定级联模型以PointNet++为点云分割网络的有效性,表2 将不同算法作为级联模型的点云分割网络进行消融对比。
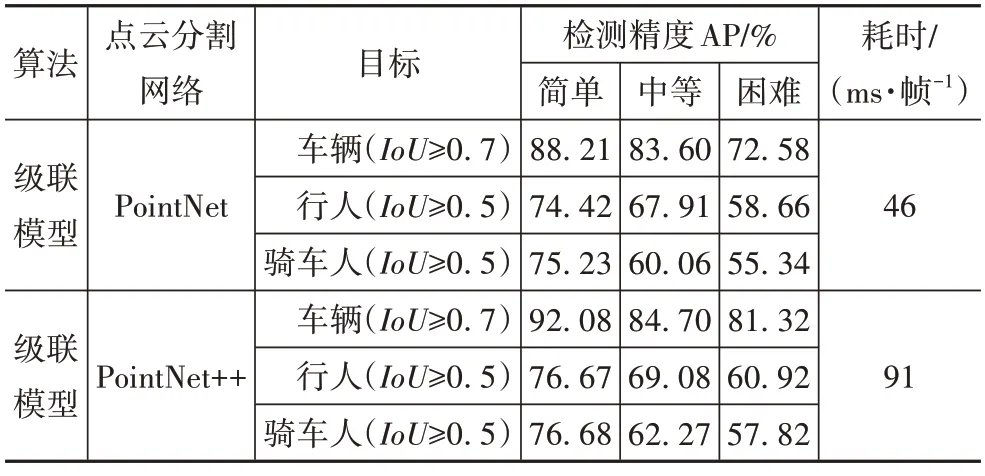
表2 级联模型在KITTI验证集中的消融对比
由表2可见,使用PointNet++作为分割网络的级联模型检测精度比使用PointNet 高,但耗时多出了45 ms/帧。这是因为PointNet++的分层点集特征提取结构使得级联模型提取到更丰富的层次特征但同时也加大了网络结构,耗时较长却获得了更多的精度收益,更有利于级联模型进行目标检测。
级联模型引入T-Net 结构学习目标坐标偏差以增加对目标位置的识别精度。为验证该结构的有效性,通过对级联模型三维检测网络中的T-Net 坐标修正模块进行消融实验以研究该结构对检测网络的影响。实验结果如表3所示。

表3 T-Net结构对模型的精度影响
由表3 可知,在所有遮挡程度下,与不引入TNet 的对照网络相比,级联模型在车辆类别的检测mAP 上增加了2.32%,行人mAP 增加了2.15%,骑车人mAP 增加了2.42%。消融结果证明,在级联模型的非模态边界估计网络中引入T-Net 结构以修正目标点云质心,能有效提高模型的三维识别精度。
为探究采用YOLOv7 作为级联模型二维RoI 提取方法的优势,通过级联不同类型的二维RoI 提取算法进行消融实验,实验结果如表4所示。

表4 二维RoI提取方法消融实验
表4 中三维分割精度指经二维RoI 提取后三维分割模型的分割精度,其中级联YOLOv7 模型相较于同类单阶段算法YOLOv5 的分割mAP 增加了2.53%,所有类别检测mAP 上升了1.8%;相较于DETR 与ConvNeXts 的分割mAP 增加了6.7%、0.83%,所有类别检测mAP 分别高出6.58%、0.71%。消融实验结果表明,级联YOLOv7 能在保持后续三维分割精度的同时降低分割耗时。
表5记录了各模型在点云鸟瞰图BEV 上的检测精度AP 以及平均航向相似度(average orientation similarity,AOS)。

表5 不同算法在KITTI验证集中的BEVAOS检测精度
由表5 可知,级联模型在中等、困难级别下,所有类别的平均检测精度mAP 较于基线网络FPointNet v2,分别获得了5.86%、6.59%的增益,可以看出,通过级联高效聚合网络ELAN,差异化二维图像之间传播的梯度信息,使级联网络能够学习到尺度更小、残缺较多的特征。
平均航向相似度AOS 通过计算预测航向角与真实航向角之间差值得出,体现模型对于目标航向的估计能力,mAOS 为AOS 值的和与所检测类别个数之比。所有遮挡程度下,对于所有类别,级联模型相较3DOP 模型,mAOS 提高了0.2%。级联模型对于行人mAOS 距Mono3D 为2.58%,这是由于级联模型不存在目标航向建议阶段,直接通过三维边界估计网络的结果计算目标航向。综合以上结果,级联YOLOv7 的三维检测模型能够在保持实时性的同时,准确检测强遮挡环境中的目标,并回归有效的目标长宽高和航向。
4 结论
结合图像与点云数据的优势,提出了一种级联YOLOv7 的三维目标检测算法,以解决目标遮挡以及原始点云搜索量过大对三维检测造成的信息残缺和实时性差的问题。通过KITTI 数据集测试结果表明,级联YOLOv7 模型充分利用了相机图像的高分辨率特性和激光雷达点云的深度信息,实现强遮挡目标几何信息和航向信息的准确检测,并降低了处理点云的运算耗时,与其它方法相比,在保证了较高准确率的同时提升了目标检测的实时性。
现实中可应用自动驾驶的场景较多,所提出的模型无法完全覆盖各场景下的静动态目标。为此,在实际应用中,应针对不同场景下的其他目标对级联模型进行训练,丰富模型可识别类型。为在保证实时性的同时尽量降低模型漏检率,下一步将在网络结构上对二维RoI 提取算法或三维分割方法进行深入挖掘,提升级联算法适配度,对于行人的航向角损失函数的选择可进一步改进。
