猪舍氨气与二氧化碳浓度变化时序预测模型优化
2023-07-31谢秋菊马超凡王圣超刘洪贵于海明
谢秋菊 马超凡 王圣超 包 军 刘洪贵 于海明
(1.东北农业大学电气与信息学院, 哈尔滨 150030; 2.东北农业大学动物科技学院, 哈尔滨 150030;3.农业农村部生猪养殖设施工程重点实验室, 哈尔滨 150030;4.教育部北方寒区智能化繁育与养殖工程研究中心, 哈尔滨 150030)
0 引言
猪舍空气质量是影响生猪呼吸道健康的关键因素,是猪舍环境控制关注的热点之一。在生猪养殖过程中,猪呼吸产生的CO2、猪粪尿等排泄物和饲料残渣分解产生的NH3、H2S、CH4等有害气体对猪的生长、繁殖、健康造成极大危害。其中NH3与CO2的气体浓度备受关注。因为NH3是一种无色具有刺激气味的有害气体,不同浓度的NH3会对猪的呼吸系统、黏膜等造成不同程度的损伤,并且NH3排放还会造成周围环境污染[1];猪舍中的CO2浓度是衡量猪舍内空气质量状况的重要标志,它主要来自于猪的呼吸,舍内CO2浓度过高不仅会造成猪头昏和生产性能下降,更有可能对猪造成生命威胁[2]。因此,对猪舍中NH3和CO2这两种气体浓度进行监测与控制,是实现猪舍环境控制的重要任务。通过大量的现场实验得出,在猪舍内进行一系列控制,例如开启风机1 h,舍内的温湿度、气体浓度会有较明显的变化。通过对舍内气体浓度变化进行预测,可以实现猪舍环境控制设备运行状态的提前调控,从而弥补在猪舍环境实际控制过程中的环境控制效果滞后的问题。
目前,畜禽舍内有害气体浓度变化模型主要有两种,一种是基于理化统计的模型,这类模型通过对气体的产生机理或者不同影响因素进行分析构建预测模型,例如:文献[3]在多种不同空气温度和空气湿度组合下连续测量多天粪便的NH3排放构建鸡粪NH3排放模型;文献[4]通过对多种不同地板类型的猪舍的NH3排放进行检测和分析,得到不同地板类型猪舍的NH3排放系数。这些模型测量方法较复杂且受实际畜禽舍结构影响大,实用性较差。另一种是基于人工智能算法的预测模型,例如,基于支持向量回归机(Support vctor regression,SVR)、随机森林(Random forest,RF)、极限随机树(Extra tree,ET)等传统机器学习算法构建的预测模型[5-7],基于卷积神经网络(Convolutional neural networks,CNN)、GRU等深度学习算法构建的预测模型[2,8-13],将自回归模型(Autoregressive model,AR)、ARIMA等统计学习算法与机器学习算法互相结合的混合预测模型[5,14-15]。与传统理化统计模型相比,基于人工智能算法的模型具有预测精度高,可更好地提取气体浓度变化特征的优点,已成为畜禽舍气体环境控制领域研究的热点。
畜禽舍内有害气体浓度随时间不断变化,具有典型的时序序列数据的特征[9]。在众多的智能预测算法中,GRU模型不仅擅长提取时间序列中非线性长期依赖关系且训练速度较快。因此,许多学者关注GRU模型对时间序列数据的预测[16-17],同时探索将CNN、注意力机制与GRU模型相融合的混合网络模型[9],以提高时序序列数据的关键特征及信息提取能力。在时序序列数据预测神经网络模型中,超参数是影响模型性能的重要因素。然而,依据传统经验选取超参数往往较难取得良好效果。因此,学者们开始尝试使用麻雀搜索算法(Sparrow search algorithm,SSA)、粒子群优化算法(Particle swarm optimization,PSO)、灰狼优化算法(Grey wolf optimization,GWO)等优化算法进行神经网络超参数寻优[2,18-24],来提升网络模型预测性能。研究表明,通过模拟麻雀种群觅食和躲避天敌的行为而提出的麻雀搜索算法[21],其搜索精度和收敛速度均优于PSO、GWO和遗传算法(Genetic algorithm,GA),但是SSA仍然存在容易陷入局部最优的问题[23],进而导致模型预测精度低。
为了解决当前有害气体浓度预测模型存在的预测精度低的问题,本文构建基于ISSA-GRU-ARIMA的猪舍有害气体浓度预测模型,该模型使用改进麻雀搜索算法对GRU模型超参数进行寻优,以提升GRU模型非线性拟合能力,同时融合ARIMA模型对时间序列模型的残差序列信息进一步提取以提高模型预测精度。
1 材料与方法
1.1 数据来源
1.1.1猪舍结构
本文数据来源于黑龙江省哈尔滨市尚志市亚布力惊哲养殖基地(44.78°N,128.47°E)的一个妊娠母猪舍,猪舍地面是水泥漏粪地板。猪舍尺寸为19.5 m×10.5 m×2.4 m,限位栏尺寸为2.2 m×0.65 m×1 m。猪舍采用机械通风,一侧墙上安装了3个风机,风机1(fan1)和风机2(fan2)尺寸均为0.8 m×0.8 m,额定功率为0.37 kW,风机3(fan3)尺寸为1 m×1 m,额定功率为0.55 kW。舍内饲养有37头妊娠母猪,猪平均质量约为165 kg,猪舍现场如图1所示,平面结构如图2所示。

图1 猪舍现场图

图2 猪舍平面结构图
1.1.2猪舍环境监测
猪舍内安装了基于物联网系统的自动环境监测及控制器,该控制器以STM32F103VET6芯片为核心。在猪舍内设有3个环境监测点,每个监测点分别安装有温湿度、NH3质量浓度、CO2质量浓度传感器,传感器距离地面高度为1.6 m,将3个环境监测点监测数据的平均值作为舍内温湿度、NH3质量浓度、CO2质量浓度取值。舍外布置1个温湿度传感器对舍外温湿度进行实时监测,3个压差传感器分别布置在3个风机正上方,对墙上风机承受的压力差进行监测,环境数据采样时间间隔为1 min,采集到的环境数据通过Wi-Fi模块上传至物联网云平台,传感器输出信号类型均为RS-485,通信协议为Modbus,传感器具体参数如表1所示。通风速率通过持续监测风机运行时间、风机承受的压差变化以及现场实验数据拟合线性方程[25]计算得到,公式为

表1 传感器技术参数
V=(0.534 2P1+112.9)e1+(0.521 7P2+106.5)e2+
(0.626 8P3+213.6)e3
(1)
式中Pi——风机i所承受的压差,Pa,i=1,2,3
ei——风机i在1 min内运行的时间占比,%
V——猪舍风机通风速率,m3/min
猪舍投喂饲料和清理粪便均采用人工的方式,其中,喂食时间为每日08:00—08:30和14:00—14:30,清粪时间为每日08:30—09:00和14:30—15:00。
1.2 模型开发环境
本文模型开发硬件环境为Intel core i7 12700H处理器,Nvidia RTX3070显卡,Windows 11 64位操作系统。模型算法开发采用Python 3.7编程语言结合Tensorflow框架和sklearn框架。
1.3 气体浓度预测优化模型构建
本文构建以GRU模型为核心的时序数据预测模型,提取猪舍环境数据的非线性特征,然后建立改进的麻雀搜索算法对GRU模型的超参数进行优化,提升GRU模型的非线性特征拟合能力,再利用ARIMA模型的线性数据拟合能力来提取残差数据的线性特征。建立的ISSA-GRU-ARIMA模型结合了ISSA的寻优能力、GRU的非线性处理能力和ARIMA的线性处理能力,提升了模型的预测精度。将舍内温度、舍内相对湿度、舍外温度、舍外相对湿度、CO2质量浓度、NH3质量浓度、通风速率的数据序列作为ISSA-GRU-ARIMA模型输入,模型输出为2个值,分别是1 h后的CO2质量浓度和NH3质量浓度。优化模型构建过程如下:
(1)将预处理后的环境数据划分为训练集1、训练集2和测试集3部分,在训练集1上对GRU模型进行训练,然后通过ISSA算法对模型超参数进行寻优得到最优GRU模型,命名为ISSA-GRU模型。
(2)使用ISSA-GRU模型对训练集2上的气体浓度进行预测,分别得到NH3质量浓度、CO2质量浓度的观测值与预测值之间的残差序列DNH3和DCO2。
(3)以残差序列DNH3和DCO2作为数据集构建ARIMA模型,ARIMA模型可以提取DNH3和DCO2的变化规律。
(4)构建ISSA-GRU-ARIMA模型对未来时刻的有害气体浓度进行预测,在测试集上对ISSA-GRU-ARIMA模型预测精度进行测试。
1.3.1数据预处理及数据集划分
选取从2022年8月10日到9月30日共52 d的环境数据(舍内温度、舍内相对湿度、舍外温度、舍外相对湿度、CO2质量浓度、NH3质量浓度、通风速率)作为实验数据。对于传感器采集的极个别时刻的缺失值采用线性插值法进行补全;然后采取拉伊达准则对数据进行处理剔除其中的异常值,异常值被替换为相邻数据的平均值。
1 h内环境因素变化较小,因此将时间间隔为1 min的数据平均化处理为时间间隔为60 min的数据,共得到1 248组数据。为了消除量纲的差异,将数据输入模型前需要进行归一化,模型预测结果需要进行反归一化。
通过滑动窗口构建数据集,使用前3 h的数据序列对后1 h的有害气体质量浓度进行预测。将实验数据划分为训练集1、训练集2和测试集3部分,各部分占比分别是70%、20.4%和9.6%。训练集1用于ISSA-GRU模型训练,训练集2用于ISSA-GRU-ARIMA模型拟合,最后使用测试集对ISSA-GRU-ARIAM模型进行测试。
1.3.2气体质量浓度预测GRU非线性模型
猪舍环境具有时序性、非线性、相互耦合的特性[8],尤其是舍内NH3质量浓度与CO2质量浓度受多因素条件影响,因此需要构建具有较强的非线性拟合能力和最大限度地提取时序数据特征的GRU神经网络模型来预测气体质量浓度变化。本文构建的GRU神经网络模型由输入层、隐藏层和全连接层3部分组成,其结构如图3所示。

图3 GRU神经网络结构
输入层接收到舍内温度、舍内相对湿度、舍外温度、舍外相对湿度、CO2质量浓度、NH3质量浓度、通风速率时序数据,然后按照公式
(2)
式中zi——输入的环境数据
z′i——归一化后的环境数据
zmax——输入环境数据最大值
zmin——输入环境数据最小值
进行归一化,归一化后的数据直接传入隐藏层。
隐藏层由2个GRU子层组成。两个GRU子层的神经元数量分别为486和315,GRU神经网络单元使用更新门和重置门两个门来实现信息的记忆和传递[16],如图4所示。更新门zt决定当前节点的新增历史信息比例,从而可以捕捉序列数据的短期依赖关系;重置门rt决定抛弃历史信息的比例,可以更好地提取序列数据的长期依赖关系。时序序列多环境因子之间依赖关系的计算公式为
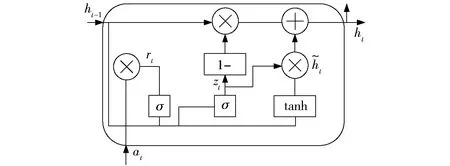
图4 GRU神经单元结构
rt=σ(Wr[ht-1,at]+br)
(3)
zt=σ(Wz[ht-1,at]+bz)
(4)
(5)
(6)
式中at——当前单元输入值
ht-1——上一神经单元状态
ht——输出状态

Wr、Wz、Wh——重置门、更新门、当前隐藏状态的权值
br、bz、bh——重置门、更新门、当前隐藏状态的偏置值
σ——sigmod激活函数
全连接层每一个结点都与GRU子层的所有结点相连,通过GRU子层学习到的特征传入全连接层。全连接层经过非线性变换提取数据之间的依赖关系并输出预测值,最后按照式(2)对输出进行反归一化,全连接层的输出为NH3质量浓度预测值和CO2质量浓度预测值。
GRU神经网络使用均方误差(MSE)作为损失函数,通过MSE计算误差后反向传播,然后通过Adam优化器根据误差不断优化权重,最终得到预测精度较高的模型。
1.3.3改进麻雀搜索算法
由于GRU预测模型的超参数众多,这些参数对网络模型的性能影响较大,因此需要对GRU网络模型超参数进行优化,以获得最佳的模型性能。SSA是一种模拟麻雀觅食和躲避天敌行为而提出的群智能优化算法[21],具有较好的全局探索能力和较快的收敛速度[22],有助于GRU预测模型对超参数进行寻优,但是SSA存在容易陷入局部最小值的问题。
混沌序列具有规律性、遍历性和随机性,将其用于搜索算法可以有效提升寻优效果,在混沌序列中,Tent序列相比常用的Logistic序列分布更加均匀且收敛速度更快;Tent混沌序列可以用于种群初始化以提高种群多样性[26],还可以对局部极值进行扰动以扩大搜索空间,从而有利于算法跳出局部最优[24];高斯分布在期望附近概率最大,引入高斯变异可以对原始解周围进行重点搜索。因此,本文使用混沌序列、高斯变异和混沌扰动对麻雀搜索算法进行改进,来提升初始解分布的均匀性及局部寻优效果,得到改进的麻雀搜索算法。在ISSA中,一只麻雀代表一组解,包含时间窗口、学习率、批数目、第1层GRU子层神经元个数和第2层GRU子层神经元个数这些需要搜索的超参数,麻雀个数代表解的个数。ISSA算法步骤如下:
(1)使用公式
(7)
式中O——粒子数量
rand(0,1)——[0,1]范围内的随机数
产生Tent混沌序列S对种群进行初始化,然后使用公式
(8)
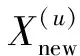
umin——解序列第u维变量的最小值
Su——混沌序列的第u维变量
umax——解序列第u维变量的最大值
将其映射到原始解空间,产生的解维度为5,个数为10。
(2)计算种群中所有个体的适应度fi,并对其进行排序,适应度是评判解优劣的指标,本实验适应度函数设置为均方误差,适应度越低表明优化算法搜索到的解越优秀。
(3)根据适应度选出发现者和捕食者,然后分别按照公式
(9)
其中α∈(0,1]ST∈[0.5,1]R2∈[0,1]
式中t——迭代次数
itermax——最大迭代次数
α——随机数
Xi,j——第i个解在第j维的位置信息
ST——预警值
R2——安全值,当R2 Q——符合正态分布的随机数 L——元素都为1的1×u的矩阵 (10) 其中 C+=CT(CCT)-1 式中XP——当前发现者最优位置 Xworst——全局最差位置 对其位置进行更新。 (4)随机选取种群中一定比例的个体作为警戒者,并按照公式 (11) 式中Xg——全局最优位置 fg——全局最佳适应度,fi>fg表示麻雀处于边缘位置且容易被天敌发现,fi=fg表示警戒者发现了敌人,需要前往安全位置 β——服从均值为0、方差为1的正态分布的随机数, 用于控制步长 K——随机数,表示麻雀移动的方向,取(-1,1) fworst——全局最差适应度 ε——无限接近0的常数,避免分母出现0 对其进行更新。 (5)在进行一轮迭代后,输出当前迭代的最小适应度,以及对应的GRU模型超参数寻优值,然后重新计算所有解的适应度fi和平均适应度favg。 (6)当fi g=x(1+N(0,1)) (12) 式中x——需要进行变异的解 N——随机数,均值为0,方差为1 g——高斯变异后的解 进行高斯变异对此解周围区域进行重点搜索,然后将变异后的解与原始解进行比较,两者之中保留最优的解。当fi≥favg时,使用公式 X′new=(X′+Xnew)/2 (13) 式中X′new——Tent混沌扰动后产生的解 X′——需要进行Tent混沌扰动的解 Xnew——使用式(7)、(8)新产生的扰动量 对此解进行Tent混沌扰动,然后将扰动后的解与原始解进行比较,两者之中保留最优的解。 (7)对种群进行更新后得到最优适应度以及最优位置。 (8)当算法达到最大迭代次数时停止算法,未达到时返回步骤(3)。 1.3.4ARIMA残差预测模型 ISSA-GRU模型的有害气体浓度预测精度虽然相比于单一GRU模型有所提升,但是通过本文实验研究发现,ISSA-GRU模型预测得到的残差序列仍然具备一定的规律,有必要对其进行进一步提取。ARIMA算法可以通过历史数据对未来值进行预测,不仅具有优秀的时间序列提取能力,更能精确反映时间序列发展规律[14],因此使用ARIMA算法对历史气体质量浓度残差序列的有价值信息进行提取和挖掘,然后对未来气体质量浓度残差值进行预测,以获得更加精确的预测值。ARIMA(p,d,q)模型是由差分运算和自回归滑动平均模型(Autoregressive moving average model,ARMA)模型组成,d指的是序列转化成平稳序列所需的差分次数;ARMA(p,q)模型是由自回归项和移动平均项组成的,p指的是自回归项阶数,q指的是移动平均项阶数,ARMA(p,q)模型为 Nt=λ+α1Nt-1+α2Nt-2+…+αpNt-p+εt+ θ1εt-1+θ2εt-2+…+θqεt-q (14) 式中Nt——残差序列中第t个值 αi——自回归项系数 θq——移动平均项系数 εt——白噪声序列中第t个值 λ——常数 ARIMA(p,d,q)模型建模步骤如下: (1)使用ISSA-GRU模型对训练集2进行预测,观测值序列与预测值序列的差值为残差序列,残差序列为ARIMA模型的输入。 (2)由于ARIMA模型的输入序列必须为平稳序列,使用单位根检验对残差时序数据的平稳性进行检验,当P<0.05拒绝原假设,该序列为平稳序列,否则该序列为非平稳序列,需要对序列进行差分直到序列平稳,方能通过平稳性检验。 (3)对差分后的序列使用Ljung_Box检验进行白噪声检验,当P<0.05拒绝原假设,该序列为非白噪声序列,否则该序列为白噪声序列,通过白噪声检验后进行下一步。 (4)使用最小赤池信息准则(Akaike information criterion,AIC)确定p和q的参数,AIC取值最小的ARIMA模型为最优模型。 (5)使用最优的ARIMA(p,d,q)模型对残差值进行预测。 采用均方根误差(RMSE)、平均绝对百分比误差(MAPE)和决定系数R2对模型的性能进行评估。 选取2022年8月10日到9月30日共52 d的预处理后环境数据作为实验数据,猪舍环境因子变化曲线如图5所示;其统计结果如表2所示。 表2 猪舍环境数据统计 图5 环境因子变化曲线 猪舍内有害气体浓度受猪舍内外温度、湿度等多环境因素的影响,构建有害气体浓度预测模型时加入外部影响因素可以使模型更加充分学习到预测目标的特征。使用Pearson’s系数分析法(P<0.05)对影响NH3质量浓度和CO2质量浓度的多环境因素进行相关性分析,如表3所示。 表3 皮尔森系数相关性分析 猪舍内NH3质量浓度与CO2质量浓度具有较强的正相关性,相关系数为0.72。猪舍内NH3质量浓度与舍内、外温度和通风速率呈负相关性,相关系数分别为-0.49、-0.58和-0.36;NH3质量浓度与舍内、外湿度具有正相关性,相关系数分别为0.26和0.21。猪舍内CO2质量浓度与舍内、外相对湿度具有正相关性,相关系数分别为0.41和0.30;CO2质量浓度与舍内、外温度和通风速率具有较强的负相关性,相关系数分别为-0.81、-0.62和-0.48。 相关性分析的结果证明了猪舍内环境因子之间具有相关性,建模时加入外部影响因素可以减少模型预测误差。因此,本文选取通风速率、舍内温度、舍内相对湿度、舍外温度、舍外相对湿度、CO2质量浓度作为NH3质量浓度的外部影响因素;选取通风速率、舍内温度、舍内相对湿度、舍外温度、舍外相对湿度、NH3质量浓度作为CO2质量浓度的外部影响因素。 在使用优化算法对超参数进行寻优之前通过预实验确定GRU子层数目。实验结果如图6所示,当GRU子层数目为1时,模型预测的RMSE分别为90.51 mg/m3和0.496 2 mg/m3;当GRU子层数增加到2时,模型预测的RMSE分别为83.15 mg/m3和0.381 mg/m3;当GRU子层数继续增加时,预测精度却下降,故本模型GRU子层数目设置为2。 图6 不同GRU层数时模型预测的均方根误差变化 使用ISSA算法对GRU神经网络的时间窗口、学习率、批数目、GRU子层1神经元个数、GRU子层2神经元个数这5个超参数进行寻优,寻优范围如表4所示。ISSA对GRU模型超参数寻优过程中优化算法种群数目设置为10,迭代次数设置为50,预警值设置为0.8,发现者比例设置为80%,警戒者比例设置为20%。ISSA算法对GRU模型的超参数优化结果如表4所示,当时间窗口值为3,学习率为0.000 6,批数目为71,两个GRU子层的神经元数目分别为486和315时模型预测精度最优。 表4 ISSA寻优参数 为了更好评估ISSA算法对GRU模型预测精度的优化,本文选取PSO算法、SSA算法和GWO算法进行对比。如图7所示。随着迭代次数的增加4种算法都逐渐收敛,ISSA算法的适应度最低(0.005 6),较PSO(0.006 2)、SSA(0.005 9)和GWO(0.006 0)3种算法的适应度分别降低9.68%、5.08%和6.67%,因此说明ISSA算法具有更高的搜索精度。 图7 4种不同算法适应度变化曲线 以训练集2为数据集,使用超参数优化后的ISSA-GRU模型对舍内NH3质量浓度、CO2质量浓度进行预测,得到的监测值与预测值的残差序列如图8所示,使用残差序列构建ARIMA模型。 图8 残差变化曲线 以NH3质量浓度残差序列为输入,对ARIMA模型输入序列的平稳性进行检验,P=8.85×10-14<0.05,该序列通过平稳性检验,NH3质量浓度残差序列为平稳序列,因此d=0。NH3质量浓度残差序列的白噪声检验P=5.44×10-4<0.05,NH3残差序列为非白噪声序列。以CO2质量浓度残差序列为输入,对ARIMA模型输入序列的平稳性进行检验,P=6.27×10-13<0.05,该序列通过平稳性检验,CO2质量浓度残差序列为平稳序列,因此d=0。CO2质量浓度残差序列的白噪声检验P=1.60×10-21<0.05,CO2质量浓度残差序列为非白噪声序列。 使用网格搜索法确定p和q的取值,当p取3且q取1时NH3质量浓度残差ARIMA预测模型AIC值最小,为447.232 2,此时ARIMA模型最优,NH3质量浓度残差最优ARIMA模型为ARIMA(3,0,1),根据相同步骤可确定CO2质量浓度残差最优ARIMA模型为ARIMA(4,0,1)。 使用测试集对模型预测精度进行测试,如图9所示,ISSA-GRU-ARIMA模型对NH3质量浓度和CO2质量浓度的预测值变化趋势与观测值变化趋势都非常接近,呈现出周期性正弦或余弦曲线波动变化。NH3质量浓度观测值变化范围为0.9~5.4 mg/m3,ISSA-GRU-ARIMA模型预测值变化范围为 0.8~5.5 mg/m3,预测值与观测值的最小误差为0 mg/m3,最大误差为1 mg/m3,平均误差为0.2 mg/m3。CO2质量浓度观测值变化范围为983.5~2 796.5 mg/m3,ISSA-GRU-ARIMA模型预测值变化范围为978.5~2 823.5 mg/m3;预测值与观测值的最小误差为1 mg/m3,最大误差为194 mg/m3,平均误差为41 mg/m3。 图9 不同模型预测值对比 2.4.1不同模型预测结果对比 为了进一步验证模型预测效果,使用CNN、GRU、SVR、RF、PSO-GRU、GWO-GRU、SSA-GRU、ISSA-GRU、ISSA-CNN、ISSA-CNN-ARIMA模型进行对比实验,与本文所提模型ISSA-GRU-ARIMA使用相同数据集,实验结果如表5所示。CNN、GRU、SVR、RF是常见基础模型,PSO-GRU、GWO-GRU、SSA-GRU是使用其他优化算法对GRU模型进行优化,ISSA-CNN、ISSA-CNN-ARIMA是使用ISSA算法和ARIMA算法对CNN进行优化。 表5 模型预测精度对比 如表5所示,本文模型ISSA-GRU-ARIMA预测精度最优,NH3质量浓度预测的RMSE、MAPE和R2分别为0.263 mg/m3、8.171%和0.928,CO2质量浓度预测的RMSE、MAPE和R2分别为55.361 mg/m3、4.633%和0.985。传统机器学习模型RF预测精度最差,NH3质量浓度预测RMSE、MAPE和R2分别为0.722 mg/m3、20.592%和0.4978,CO2质量浓度预测的RMSE和MAPE和R2分别为170.873 mg/m3、12.926%和0.859。本文模型与RF模型相比,NH3质量浓度预测RMSE和MAPE分别下降63.51%和60.31%,R2提升86.41%,CO2质量浓度预测的RMSE和MAPE分别下降67.58%和64.14%,R2提升14.65%。 ISSA-GRU模型与GRU模型相比,NH3和CO2质量浓度预测的RMSE和MAPE分别降低21.69%和20.66%,17.25%和20.25%;R2分别提升了6.87%和1.28%,说明使用ISSA算法进行寻优显著可提升GRU模型的预测精度。ISSA-GRU与PSO-GRU、GWO-GRU和SSA-GRU相比,NH3质量浓度预测的RMSE分别下降18.97%、11.57%和7.27%,CO2质量浓度预测的RMSE分别下降17.26%、17.24%和5.40%;NH3质量浓度预测的MAPE分别下降26.48%、7.64%和14.91%,CO2质量浓度预测的MAPE分别下降15.94%、14.77%和6.71%;NH3质量浓度预测的R2分别上升5.63%、2.92%和1.69%,CO2质量浓度预测的R2分别上升1.01%、1.00%和0.26%,说明ISSA相比其他优化算法拥有更优秀的寻优能力。 ISSA-GRU-ARIMA模型与ISSA-GRU相比,NH3质量浓度预测的RMSE和MAPE分别下降11.66%和12.13%,R2提升2.24%,CO2质量浓度预测的RMSE和MAPE分别下降16.08和15.99%,R2提升0.64%,由此可见,融合线性统计ARIMA方法后的ISSA-GRU-ARIMA模型,可以充分挖掘ISSA-GRU预测残差序列的有用信息,进一步提升模型预测精度。 2.4.2结果分析 近年来,对猪舍气体浓度进行预测已成为猪舍环境控制研究的关注热点,国内外学者针对畜禽舍内不同气体构建了不同的预测模型。例如,文献[7]提出的基于ANFIS的NH3质量浓度预测模型R2为0.648; 文献[9]构建的融合注意力机制和CNN网络的CNN-LSTM-AT模型,其CO2质量浓度预测的R2为0.8170;文献[27]使用不同时间间隔环境因子构建基于长短期记忆网络的CO2质量浓度预测模型,其R2分别为0.859和0.656,文献[28]使用多种机器学习模型对NH3质量浓度进行预测,梯度提升树算法取得了最好的预测效果,R2为0.402。这些模型对NH3质量浓度和CO2质量浓度预测的R2范围为0.4~0.9,本文所提出ISSA-GRU-ARIMA模型对NH3质量浓度和CO2质量浓度预测R2分别是0.928和0.985,优于上述已有研究中的模型,可为猪舍气体浓度预测及环境控制提供可行的方法。 综上,本文ISSA-GRU-ARIMA气体质量浓度预测模型预测精度较优,可用于猪舍NH3质量浓度和CO2质量浓度预测。 (1)通过ISSA算法优化GRU模型的超参数,可提升气体质量浓度预测模型的精度。ISSA-GRU模型NH3质量浓度预测的RMSE、MAPE和R2分别为0.298 mg/m3、9.301%和0.907,CO2质量浓度预测的分别为65.974 mg/m3、5.515%和0.979;与GRU(RMSE分别为0.381 mg/m3和83.151 mg/m3,MAPE分别为11.247%和6.916%,R2分别为0.849和0.967)相比,RMSE、MAPE分别降低21.69%和20.66%,17.25%和20.25%;R2分别提升6.87%和1.28%。 (2)融合统计学习ARIMA方法对ISSA-GRU模型进行优化,使得NH3质量浓度和CO2质量浓度预测的RMSE分别下降11.66%和16.08%,因此ARIMA模型对残差进行线性特征提取可以提升模型预测精度。 (3)提出的ISSA-GRU-ARIMA模型对NH3质量度和CO2质量浓度预测的R2分别为0.928和0.985,预测精度较高,预测结果可以为猪舍有害气体浓度控制提供科学依据。
1.4 模型评价指标
2 结果与分析
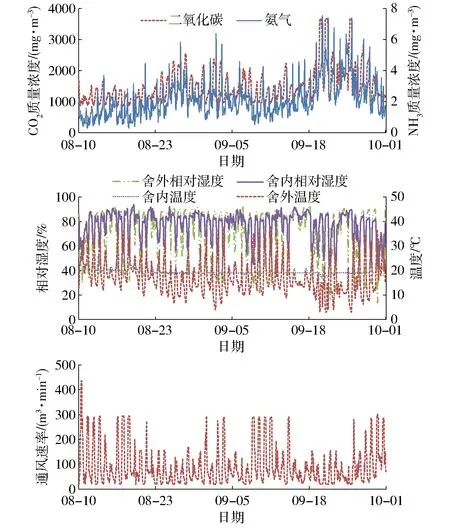
2.1 猪舍环境因子监测结果及相关性分析


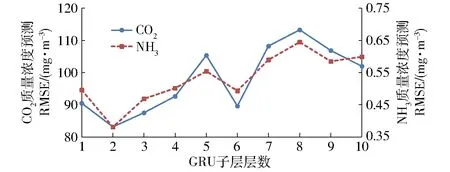
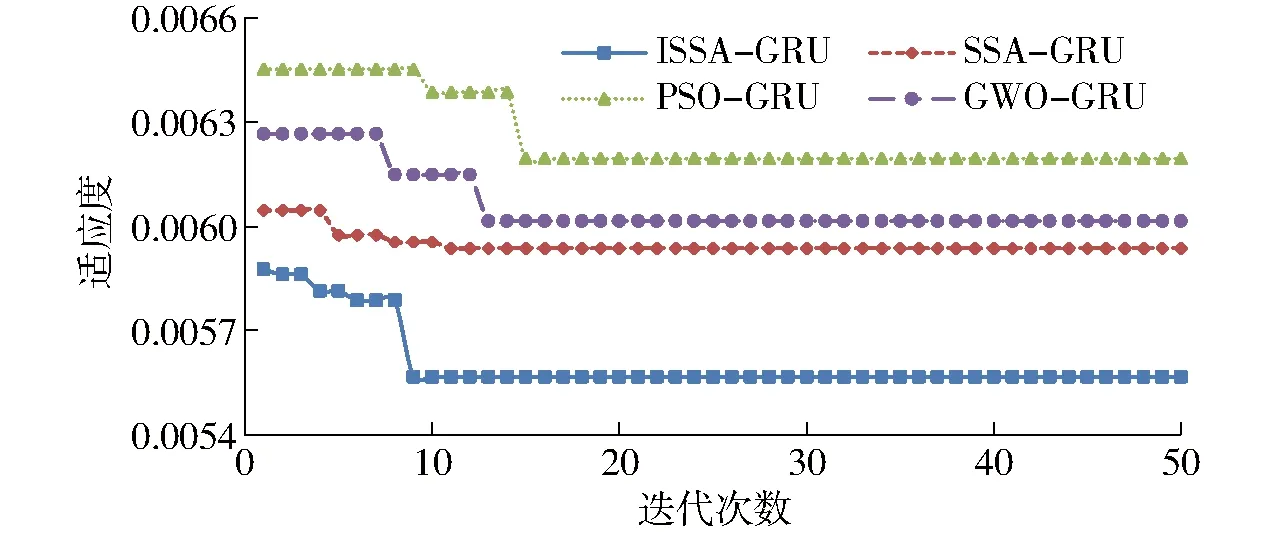
2.2 ISSA-GRU模型构建

2.3 ARIMA模型构建

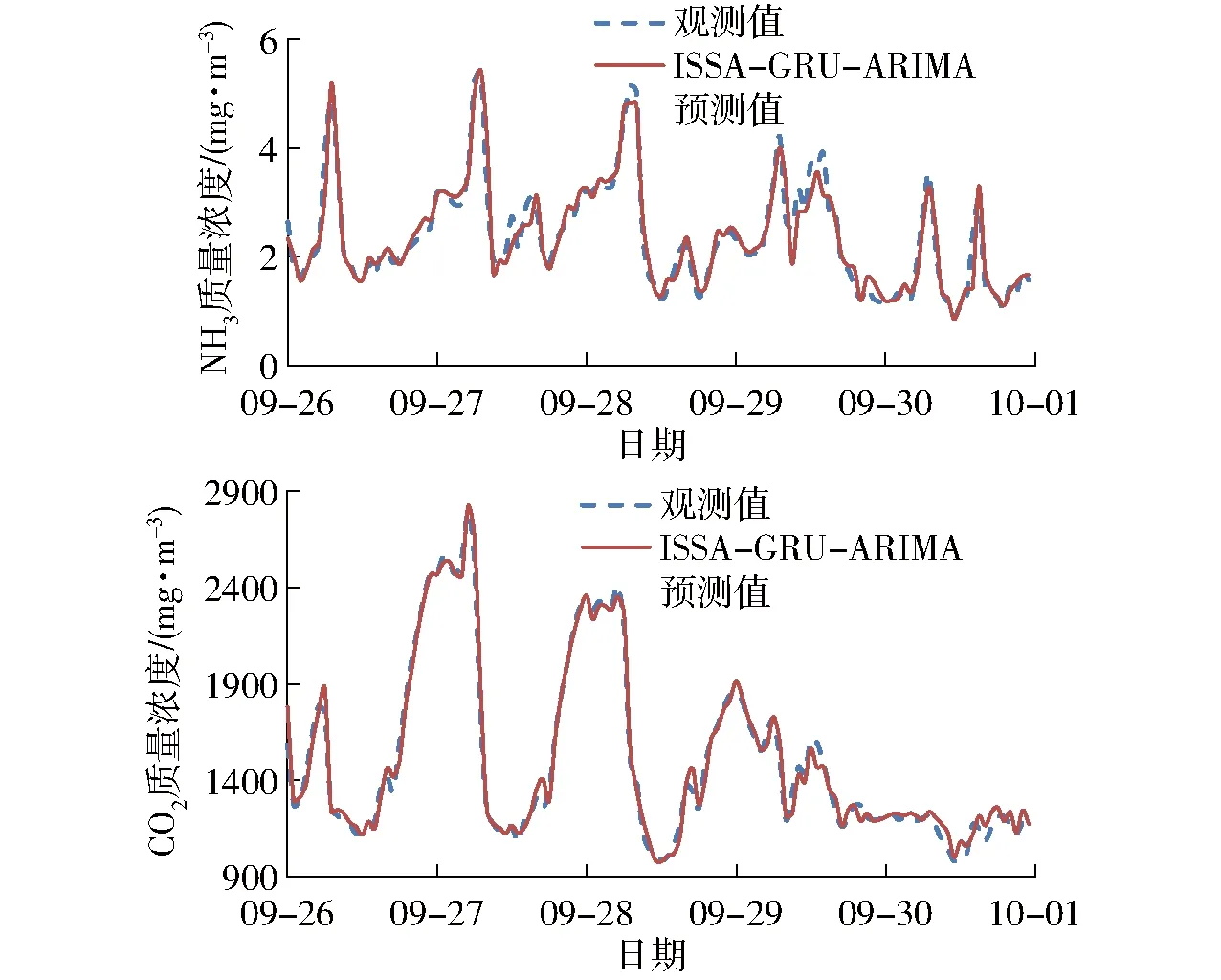
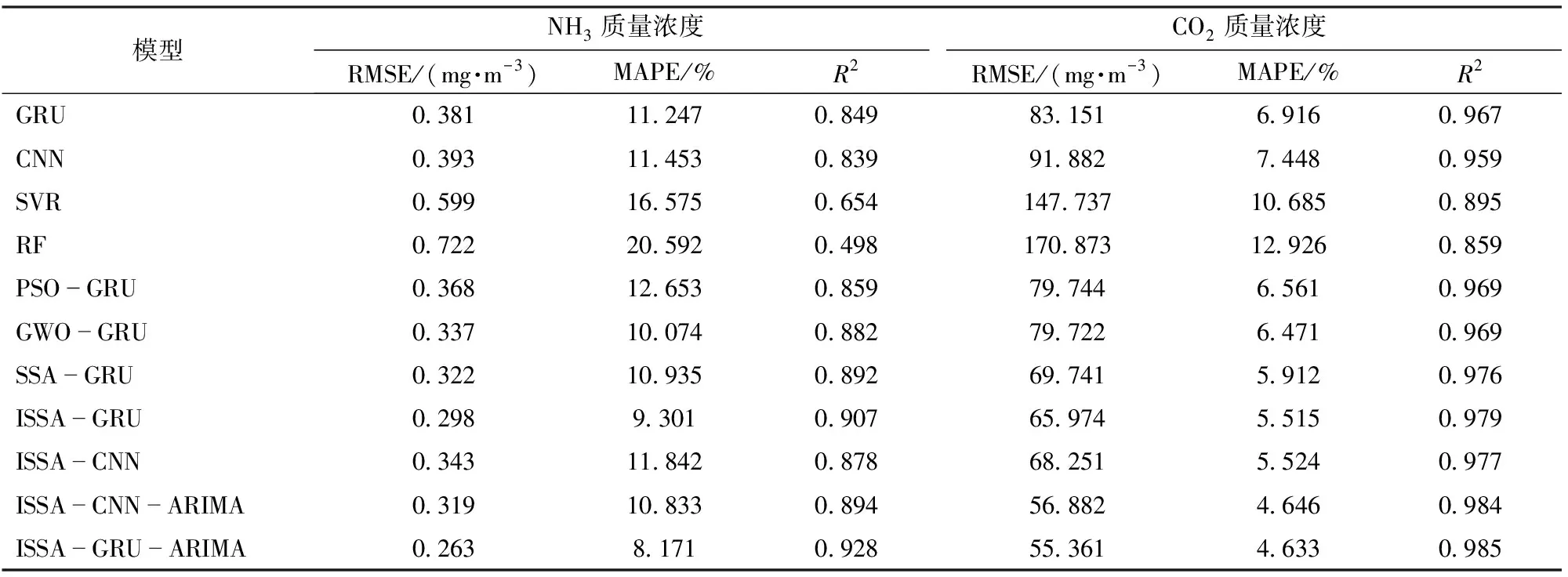
2.4 ISSA-GRU-ARIMA模型预测结果验证
3 结论
