基于回访机制的无人机集群分布式协同区域搜索方法
2023-07-29文超董文瀚解武杰蔡鸣刘日
文超,董文瀚,解武杰,蔡鸣,*,刘日
1.空军工程大学 研究生院,西安 710038
2.空军工程大学 航空工程学院,西安 710038
3.空军哈尔滨飞行学院 理论训练系,哈尔滨 150000
近年来,受益于人工智能与无人系统的蓬勃发展,无人机(Unmanned Aerial Vehicle,UAV)被广泛应用于军事作战领域,而采用多架UAV以集群网络形式协同执行区域搜索、目标跟踪、饱和打击等任务正逐渐成为UAV 作战的发展趋势。其中,区域搜索任务作为UAV 集群协同作战的关键环节,能够为后续作战任务决策提供有效的全局信息支撑,得到了国内外学者的广泛关注[1-5]。
UAV 集群协同区域搜索是指UAV 成员利用机载探测设备侦察指定任务区域,并通过通信网络交互共享探测信息,从而协作完成对任务目标的捕获[6-7]。目前,诸多学者主要围绕任务环境建模与协同搜索策略2 个方面对UAV 集群协同区域搜索问题进行了广泛而深入的探究,并取得了丰硕的成果。
在任务环境建模方面,现有成果大多基于栅格化方法来构建任务环境的搜索图模型,主要包括目标分布概率图、数字信息素图及确定度图等[8-15]。Yang 等[8]为准确描述动态未知环境下传感器对目标观测信息的实时获取与更新,分别基于贝叶斯准则与D-S 证据理论构建了目标分布概率图,并借此引导集群对威胁场景下的目标进行合作定位。Khan 等[9]考虑到不确定环境下各UAV 的局部探测信息可能存在偏差,通过占用栅格合并技术对目标分布概率图进行融合,进一步增强了概率图对潜在目标的指示能力。沈东等[11]为实现集群对广域目标的协同搜索,分别定义了数字信息素的吸引和排斥属性,前者用于记录UAV 对搜索区域的访问特性,后者用于协调集群成员之间的搜索行为。吴傲等[13]通过将信息素图作为多机协同的载体,实现了集群对未知区域的高效覆盖搜索。Saadaoui 和el Boua‐nani[14]将确定度引入未知区域内离散栅格单元,借此来描述UAV 对搜索环境的认知程度,进而指导其自主搜索决策过程。彭辉等[15]在确定度图的基础上,借鉴生物细胞中荷尔蒙的扩散-传播机理,提出一种基于扩展搜索图的多UAV 协同搜索决策方法,较好地激发了多机系统的自组织性。总而言之,搜索图模型本质上都是通过建立一个二维离散栅格地图来反映UAV 对当前搜索环境的认知情况。随着任务的推进,UAV 持续探测栅格,并不断更新本机搜索图,在每个决策时刻,UAV 能够根据实时探测信息进行在线搜索决策。因此,搜索图对于引导UAV 集群遂行动态协同搜索任务具有较好的适应性。
在协同搜索策略方面,提出的方法主要包括区域分割覆盖扫描[16-20]、模型预测控制(Model Predictive Control,MPC)[21-25]和潜在博弈等[26-27]。其中,前两者的应用最为广泛。文献[16-17]首先基于Voronoi 构型划分搜索区域,然后结合概率图信息设计合理的控制律引导UAV成员收敛至各自的Voronoi 质心,从而实现对任务子区域的覆盖搜索。这种分割方法原理相对简单,但具有较高的不确定度和计算复杂度。文献[18]分别针对凸和非凸的多边形任务区域提出了基于UAV 来向均衡划分策略与凹点凸分解策略,同时采用“Z”型路径与Dubins 转弯路径来规划子区域内的覆盖扫描路径,实现了集成区域分割与路径规划的整体调用。文献[19]根据UAV 的初始位置和搜索面积将任意凸多边形区域分割为若干不同子区域,并将UAV 集群的总转弯次数作为主要指标评估分割结果,通过数值仿真证明了所提方法的有效性。
上述方法对于静态未知环境下的区域搜索问题表现出良好的适应性,但难以求解动态搜索规划问题,具有一定的现实局限性。为了提高UAV 动态决策能力,文献[21]重点研究了不确定环境下通信约束对于多UAV 协同搜索效能的影响,通过引入MPC 思想使UAV 在决策时能够充分兼顾长短期收益,有效解决了UAV 决策后期易陷入局部最优的问题。文献[22]基于MPC思想提出一种UAV 集群分布式搜索意图交互决策机制,通过定制环境更新算子与环境融合算子,实现了集群在未知威胁场景下的高效覆盖搜索。文献[24-25]为了将集群系统的大规模优化决策分解为各UAV 子系统的分布式优化决策,基于分布式模型预测控制(Distributed Model Predictive Control,DMPC)方法提出一种广泛适用的多UAV 动态搜索规划框架,通过结合滚动时域优化(Receding Horizon Optimization,RHO)与智能优化算法来迭代求解各UAV 成员的搜索路径,有效降低了问题求解维度,提高了UAV 实时在线决策能力。
综上所述,现有国内外研究虽然使UAV 集群在动态未知环境中具备了一定的协同搜索能力,但仍存有以下问题有待解决:
1)区域搜索任务中未能兼顾对地面动目标的搜索需求,仅以区域覆盖率为评价指标衡量集群协同搜索效率。
2)未针对传感器的探测性能局限可能造成的目标误判和漏检问题制定具体解决方案。
3)UAV 成员在基于传统DMPC 方法实时更新本机搜索图时,通常需要接收来自通信网络共享的它机预测状态信息或决策信息。从通信层面考虑,这种耦合更新方式会导致某UAV 成员一旦受干扰发生通信中断,通信范围内其他成员的搜索图将会不可逆地缺乏该成员的历史决策信息,进而降低集群后续协同搜索效能。
针对上述问题,论文主要开展了以下工作:
1)为实时描述未知搜索环境的变化情况,构建了环境认知图模型,并借此引导UAV 对未知任务区域进行覆盖搜索。在此基础上,通过利用动目标位置分布先验信息,进一步构建了目标分布概率图模型,用于引导UAV 搜索地面动目标。
2)为减少UAV 在搜索过程中错失动目标情况以及由传感器虚警概率导致的目标误判情况,通过定制信息素引导的回访机制,驱动UAV对全局栅格进行可控回访;为缓解由传感器探测概率导致的目标漏检问题,通过定制权系数动态切换引导的回访机制,驱动UAV 对发现可疑目标的区域进行回访复检。
3)借鉴DMPC 思想,设计了一种基于信息融合的UAV 集群分布式协同搜索决策机制,确保各UAV 成员在分布式最优决策的基础上实现对本机搜索图的独立更新,以进一步增强系统鲁棒性。
本文剩余部分的组织结构如图1 所示,共分为6 节:第1 节简要描述了UAV 集群协同区域搜索任务的典型想定,并构建了相应的任务区域栅格模型与UAV 系统状态模型;第2 节面向动态未知搜索区域,建立了综合态势信息图模型及其更新机理;第3 节重点考虑机载传感器的探测性能约束,提出了2 种区域回访机制,在此基础上,结合所建立的综合态势信息图,设计了UAV 搜索效能函数;第4 节详细介绍了基于信息融合的UAV 集群分布式协同搜索决策流程,并提出回访机制驱动的UAV 集群分布式协同搜索决策算法;第5 节进行了数值仿真实验,以验证所提回访机制、决策机制和算法的有效性;第6 节给出了结论。
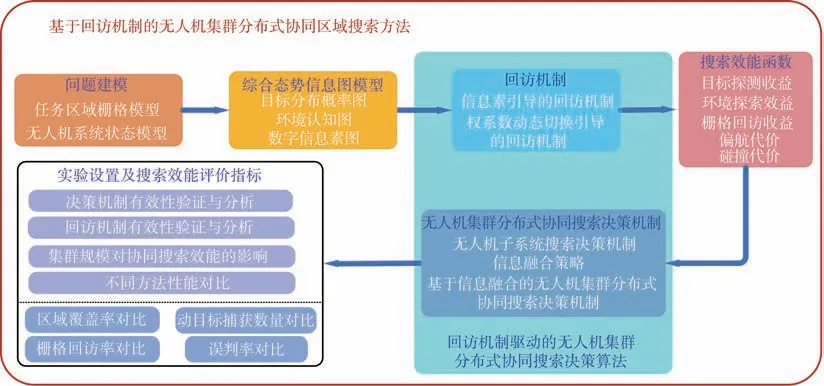
图1 论文组织结构Fig.1 Paper organization structure
1 问题建模
UAV 集群协同区域搜索任务的典型想定如图2 所示。假设某一指定的未知任务区域Ω内分布有若干动目标,现派遣Nu架(Nu≥2)UAV 组成搜索集群,利用各自携带的探测设备(激光、视觉等传感器)对Ω进行侦察,要求在捕获尽可能多的动目标的同时,实现对Ω的最大化覆盖搜索,以为指战员提供相对全面和准确的战场态势信息。
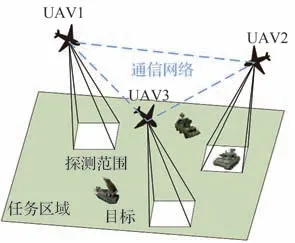
图2 无人机集群协同区域搜索任务Fig.2 UAV swarm cooperative area search mission
为保证任务顺利进行,UAV 在侦察期间应重点探测环境认知程度低、目标分布概率大的区域。同时,需要引导UAV 对指定任务子区域进行回访复检,以尽可能减少UAV 遗漏和误判目标情况。
1.1 任务区域栅格模型
为了简化UAV 搜索决策的解空间,在笛卡尔坐标系下对Lx×Ly的矩形任务区域Ω进行栅格化处理,即将其划分为若干大小为Δx×Δy的离散栅格单元,如图3 所示。则任意栅格单元的位置坐标表示为
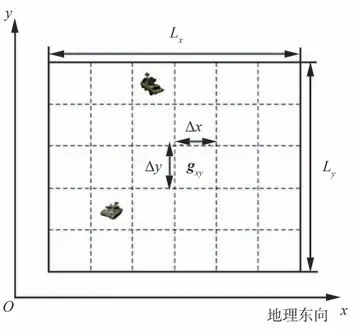
图3 任务区域栅格Fig.3 Grid mission area
1.2 UAV 系统状态模型
通常情况下,为保证传感器成像尺寸的一致性,UAV 在搜索期间一般不进行高度机动[22]。因此,为便于研究,将UAV 视为二维空间中的平动质点,记k时刻第i个UAV 的状态矢量为
式中:Pi(k)=(xi(k),yi(k))为第i个UAV 位置坐标;ψi(k)为UAV 偏航角。
则第i个UAV 的离散系统状态模型表示为
式中:v为UAV 飞行速率;Δt为时间步长;ui(k)=Δψi(t)为UAV 的决策变量,即偏航角变化量。
进而可以表示第i个UAV 的状态转移方程为
式中:f(⋅)为状态转移函数,由式(3)确定。
值得说明的是,式(3)仅描述了UAV 在相邻决策时刻的状态信息,这就意味着当前时刻的UAV 只能获取下一时刻的目标栅格位置和航向信息。然而,在实际搜索过程中,UAV 是连续机动的,因此,需要根据每步决策结果所确定的目标栅格位置,为UAV 在线规划出从当前栅格到目标栅格的飞行航迹。这涉及UAV 航迹规划领域,不是本文的研究重点,故不作详述。
鉴于上述分析,对UAV 的动作空间进行离散化处理。则第i个UAV 在k时刻有8 个可选航向,数字化表示为ψi(k)∈{0,1,2,3,4,5,6,7}。图4 展示了各个数字代表的UAV 飞行方向。考虑到UAV 本体性能约束,基于k时刻航向限定k+1 时刻UAV 的航向为:左偏航45°;直飞;右偏航45°。则有ψi(k+1)∈{ψi(k)−1,ψi(k),ψi(k)+1}mod 8,此处是数字化描述无人机在k+1 时刻的可选航向,mod8 表示对8 取余,用于约束可选航向的取值范围。
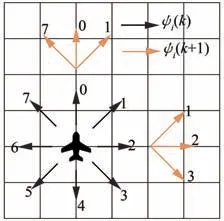
图4 无人机离散动作空间Fig.4 Discrete action space of UAV
2 综合态势信息图模型及其更新机理
本节将建立包含目标分布概率图(Target Distribution Probability Map,TDPM)、环境认知图(Environment Cognition Map,ECM)与数字信息素图(Digital Pheromone Map,DPM)在内的综合态势信息图模型及其更新机理,从而为UAV 进行实时在线搜索决策奠定基础。在综合态势信息图中,每个栅格单元均包含以下3 种属性:
式中:下标xy表示(x,y),为栅格单元坐标;k为决策时刻;pxy(k)为目标存在概率;χxy(k)为环境不确定度;ηxy(k)为信息素浓度。
2.1 目标分布概率图
在UAV 实际执行搜索任务前,动目标的大致位置分布区域通常可以借助卫星侦察等情报搜集手段来预先获取[6]。因此,为有效利用先验情报信息,引入pxy(k)∈[0,1]来描述栅格中存有动目标的概率,pxy(k)越大,表示栅格中存在动目标的概率越大。假设先验信息给定的目标预估位置为() (n=1,2,…,NT),采用式(6)所示的高斯分布初始化TDPM。
考虑到传感器在探测过程中存在噪声、遮挡等因素干扰,因此,UAV 在搜索过程中根据贝叶斯准则持续更新TDPM,数学描述为[10]
式中:pd、pf分别为传感器的探测概率和虚警概率,反映了传感器的探测性能;bxy(k)∈{0,1}为传感器对目标的探测状态,取值为1 时认为探测到目标,反之即认为未探测到目标。
2.2 环境认知图
为实时描述UAV 对未知区域的搜索认知情况,将不确定度χxy(k)∈[0,1]引入离散栅格单元。χxy(k)越小,表示UAV 对栅格内静目标信息的认知越完全。
考虑到香农熵能够有效量化不确定性信息,因此,采用静目标初始存在信息的香农熵来描述搜索环境的初始不确定度,具体为
式中:γ∈(0,1]为衰减系数,当γ=1 时,表示UAV 仅需对栅格进行一次访问便可完全确定栅格内的静目标信息;c(k+1)为截止到k+1 时刻栅格的累积搜索次数。
2.3 数字信息素图
自然界生物普遍涌现出集群协同行为,其中较为经典的是蚁群觅食,即蚂蚁个体通过跟踪自身及蚁群其他成员共同分泌的化学信息素来快速寻找和获取食物源[28]。不难看出,蚁群觅食机理与集群协同搜索过程具有高度相似性,因此,为进一步提高UAV 搜索效率,借鉴蚁群觅食机理构建DPM 为
式(10)表示采用一个Lx×Ly的信息素浓度矩阵M来数字化构建DPM。
值得说明的是,数字信息素种类较多,有吸引类、排斥类和跟踪类等,可根据具体任务需求选定。此外,由于数字信息素是对生物信息素进行的模拟,因此,数字信息素同样具备分泌、传播、挥发等仿生特性,具体可视任务需求定义。
定义数字信息素为吸引信息素,且具有分泌、传播和挥发3 种物理属性,用于引导UAV 对受访时间间隔较长的区域进行回访复检(详见3.1.1 节)。吸引信息素按照如式(11)所示的规则进行动态更新[11]:
式中:Ga,Va∈[0,1]分别为传播系数和挥发系数;二值变量Wxy∈{0,1}为信息素分泌开关因子;oxy(k+1)表示栅格自主分泌的信息素量;sxy(k+1)表示(k,k+1]时间段内相邻栅格传入的信息素总量,计算方法为
3 回访机制与搜索效能函数
3.1 回访机制
对于存有动目标的未知任务区域,UAV 进行覆盖搜索时需要着重考虑2 方面的问题:①相对于静目标,动目标存在运动至UAV 已搜索区域的可能性,增大了后续搜索过程中UAV 遗漏目标概率;② 传感器的虚警概率和探测概率造成的目标误判和漏检情况。为此,分别设计了信息素引导的回访机制和权系数动态切换引导的回访机制,以进一步提高集群协同区域搜索效能。
3.1.1 信息素引导的回访机制
为降低UAV 遗漏和误判目标概率,基于DPM 引导UAV 对受访时间间隔较长的区域进行回访复检。假设栅格前一次的受访时刻为ts,当前时刻为t,规定回访时限为τ。则信息素引导的回访机制的触发条件为
具体作用机理为:当栅格的未受访时长大于规定回访时限时,意味着UAV 需要对栅格进行回访复检。此时,打开信息素分泌开关,即设定Wxy=1,栅格将持续分泌信息素并不断传入邻近栅格,最终形成一种关于信息素浓度的梯度分布,如图5 所示。在吸引信息素作用下,UAV 将前往高信息素浓度栅格进行重搜索,从而实现对长时间未被探测栅格的回访。
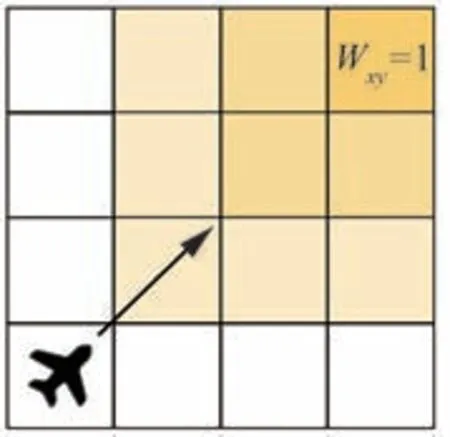
图5 信息素引导的回访机制原理Fig.5 Principle of pheromone-guided revisit mechanism
基于上述分析可知,开关因子Wxy的取值是实现由信息素引导UAV 进行回访的关键。因此,定义信息素引导的回访机制的终止条件为:一旦有UAV 对栅格进行重搜索,则关闭信息素分泌开关,即设定Wxy=0。此后,栅格内的信息素将随时间逐渐挥发,浓度随之减小,直到栅格再次满足回访机制的触发条件时,设定Wxy=1。通过定制具有周期分泌能力的吸引信息素来驱动UAV 对全局栅格进行可控回访,从而尽量减少UAV 遗漏和误判目标情况。
3.1.2 权系数动态切换引导的回访机制
为进一步缓解由传感器探测性能限制造成的目标误判和漏检问题,基于搜索效能函数(详见3.2 节)定制了权系数动态切换引导的回访机制,该机制在UAV 认为探测到可疑目标时触发。为便于阐述,记UAV 探测到可疑目标的区域为Β。权系数的动态切换规则为
具体来说,就是当UAV 探测到区域Β 中的可疑目标时,通过提高一定规划时域内目标探测收益的权系数,快速引导该UAV 或邻近UAV 重点回访Β 以便再次确认目标真伪,进而降低UAV漏检和误判目标概率。在UAV 完成回访后,切换权系数为初始值,即在决策时刻tk+q终止回访机制。
3.2 搜索效能函数
以最大化UAV 集群协同搜索效率为优化目标,同时兼顾各UAV 偏航代价与飞行安全,建立式(15)所示的UAV 搜索效能函数:
式中:Si(k)、Ui(k)分别为第i个UAV 的N步预测状态集与N步决策输入集(详见4.1 节);各优化子目标的具体定义如3.2.1~3.2.5 节所示。
3.2.1 目标探测收益
目标探测收益JD描述为UAV 搜索过程中探测到目标可能性的度量,用于引导UAV 重点搜索目标存在概率大的区域。因此,采用第i个UAV 搜索航迹所覆盖的探测区域Ri的目标存在概率累加和来定义JD为[6]
式中:ζxy(k)为UAV 对(x,y)栅格中是否存有目标的判定结果,数学描述为
其中:δp∈(0.5,1]为目标存在阈值,取δp=0.8;ζxy(k)=1 表示(x,y)栅格中存有目标,反之则表示目标不存在。
3.2.2 环境探索效益
环境探索效益JE描述为UAV 搜索过程中环境不确定性信息的减少量,用于引导UAV 探索未知环境,从而提高对静目标的发现概率。因此,基于环境不确定度的衰减量定义JE为
3.2.3 栅格回访收益
栅格回访收益JR描述为UAV 对受访时间间隔较长的栅格进行重搜索时所获得的信息素收益,用于引导UAV 重点探测高信息素浓度区域。因此,定义JR为
3.2.4 偏航代价
为减少UAV 执行任务期间的转弯油耗与飞行时间损耗,建立UAV 偏航角调整代价函数JT为
式中:N为滚动优化长度(详见4.1 节);|·|为绝对值。由式(20)可以看出,当UAV 在任意相邻决策时刻保持直飞航向时,偏航代价最小。
3.2.5 碰撞代价
机间避撞对于UAV 集群协同作业至关重要。现有方法大多采用人工势场法来实现UAV成员间的防相撞[29],借鉴其斥力势场思想,建立碰撞代价函数JC为
式中:‖·‖为欧氏距离。
4 回访机制驱动的UAV 集群分布式协同搜索决策算法
4.1 UAV 集群分布式协同搜索决策机制
MPC 方法能够使智能体在决策时充分兼顾长短期收益,因此对动态规划问题具有良好的适应性。针对UAV 集群协同区域搜索问题,基于MPC 的集中式优化求解方法虽然使UAV集群具备了良好的全局最优决策能力,但系统鲁棒性不强,且随着集群规模的扩大,由于受到中央节点的计算能力、网络通信能力等诸多方面限制,UAV 可能难以进行实时任务决策[25]。DMPC 方法能够有效解决上述问题,但其耦合更新搜索图的方式限制了集群系统鲁棒性的提升。
因此,借鉴DMPC 思想,设计了基于信息融合的UAV 集群分布式协同搜索决策机制,确保集群在分布式协同最优决策的基础上对成员态势信息图进行解耦式更新。
4.1.1 UAV 子系统搜索决策机制
为提高UAV 自主决策能力,首先基于MPC思想建立图6 所示的UAV 子系统搜索决策机制。
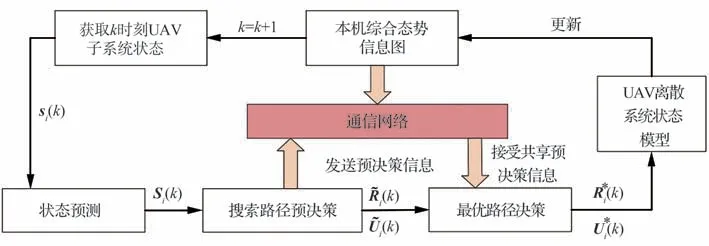
图6 无人机子系统搜索决策流程Fig.6 Search decision process for UAV subsystem
在每个决策时刻k,UAV 子系统搜索决策机制分为以下4 个步骤:
步骤1基于k时刻UAV 当前状态si(k),对未来N个时刻的子系统状态Si(k)={si(k+1|k),si(k+2|k),…,si(k+N|k)}进行预测。根据1.2 节定义的UAV 离散系统状态模型及动作空间,可将UAV 在未来N个时刻的所有可行航路点表示为一种树状结构。图7 展示了N=3 时UAV 的路径决策树。
步骤4将最优控制序列的首项作为k时刻UAV 离散系统状态模型的决策输入,从而引导UAV 探测目标栅格。同时,根据传感器探测结果更新本机综合态势信息图。直到k+1 时刻最优控制指令介入,返回步骤1。
对于第i个UAV 子系统,基于滚动优化思想建立局部有限时域滚动优化模型为
式中:Si(k)和Ui(k)分别为第i个UAV 子系统的N步预测状态集与N步决策输入集;分别为其他UAV 的N步预测状态集与N步决策输入集;Θ和Ξ分别表示UAV 的容许输入集和可行状态集。
4.1.2 信息融合策略
在UAV 利用传感器实时观测信息对本机综合态势信息图进行独立更新后,通常需要将其与其他UAV 更新后的综合态势信息图进行整合,以确保后续决策周期中UAV 能更全面准确地认知搜索环境并进行最优决策。因此,为进一步提高UAV 搜索效能,设计TDPM、ECM 和DPM 的融合规则为
4.1.3 UAV 集群分布式协同搜索决策机制
综上所述,基于信息融合的UAV 集群分布式协同搜索决策机制如图8 所示。

图8 无人机集群分布式协同搜索决策流程Fig.8 Distributed cooperative search decision process for UAV swarms
首先,各UAV 成员基于当前时刻的自身状态,分别利用MPC 决策器生成各自最优决策信息。接着,根据各自最优决策信息独立更新本机综合态势信息图。然后,通过信息融合策略将其与通信网络共享的其他UAV 的综合态势信息图进行融合计算,得到全局综合态势信息图并作为下一决策周期的本机综合态势信息图,进而实现集群的分布式协同最优决策。
4.2 回访机制驱动的UAV 集群分布式协同搜索决策算法
将回访机制引入上述决策机制,提出一种回访机制驱动的UAV 集群分布式协同搜索决策(Distributed Cooperative Search Decision with Revisit Mechanism,RM-DCSD)算法,主要流程如算法1 所示。
5 仿真实验与分析
为全面验证所提RM-DCSD 算法的有效性,基于 Windows 10(64 位),Intel Core i7-7700HQ CPU(2.8 GHz),24 GB RAM 的实验平台对图2 所示的典型协同区域搜索任务想定进行数值仿真实验。

5.1 实验参数设置
设定矩形任务区域Ω的大小为50 km×50 km,将其均匀划分为50×50 的离散栅格,则每个栅格单元大小为1 km×1 km。根据先验情报信息,假定Ω中x∈[10,40] km,y∈[12,42] km范围内分布有若干动目标,现派遣4 架同构UAV组成搜索集群对Ω执行协同搜索任务,分别将区域覆盖率和动目标捕获数量作为主要评价指标衡量集群对静目标和动目标的搜索效率。表1~表4 给出了UAV 集群初始状态信息、传感器性能参数、综合态势信息图参数以及算法参数。初始化TDPM 与ECM 分别如图9 和图10 所示。设定仿真时长为9 000 s,决策周期Td=10 s,规定回访时限τ=10Td。

表1 无人机集群初始状态信息Table 1 Initial state information of UAV swarms

表2 传感器性能参数Table 2 Parameters of sensor performance
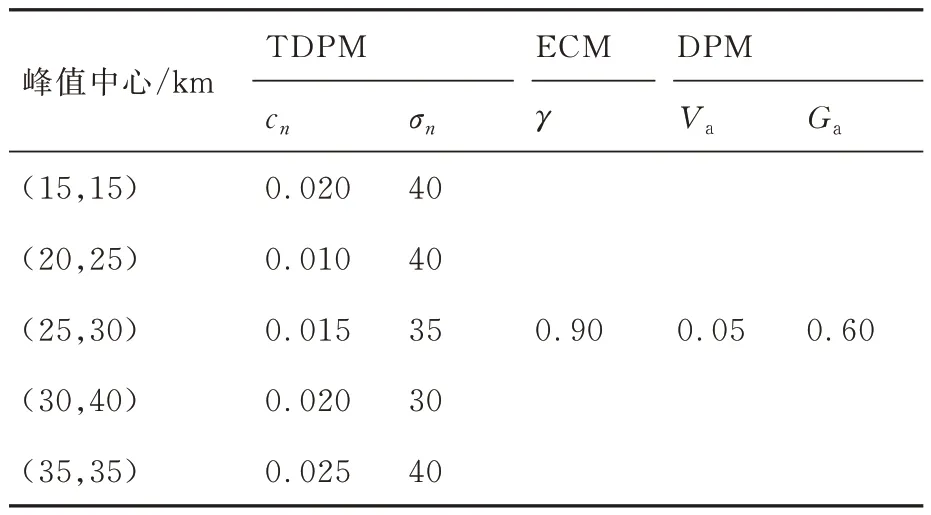
表3 综合态势信息图参数Table 3 Parameters of comprehensive situational information map

表4 RM-DSCD 算法参数Table 4 Parameters of RM-DCSD algorithm
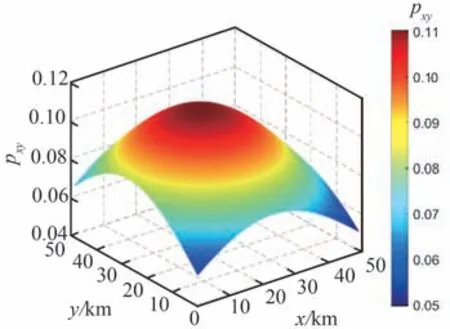
图9 初始目标概率分布Fig.9 Initial distribution of target probability

图10 初始环境不确定度分布Fig.10 Initial distribution of environmental uncertainty
5.2 协同搜索规划结果
RM-DCSD 算法的规划结果如图11 所示。图11(a)~图11(c)分别为t=2 400,4 850,9 000 s的协同搜索规划结果。
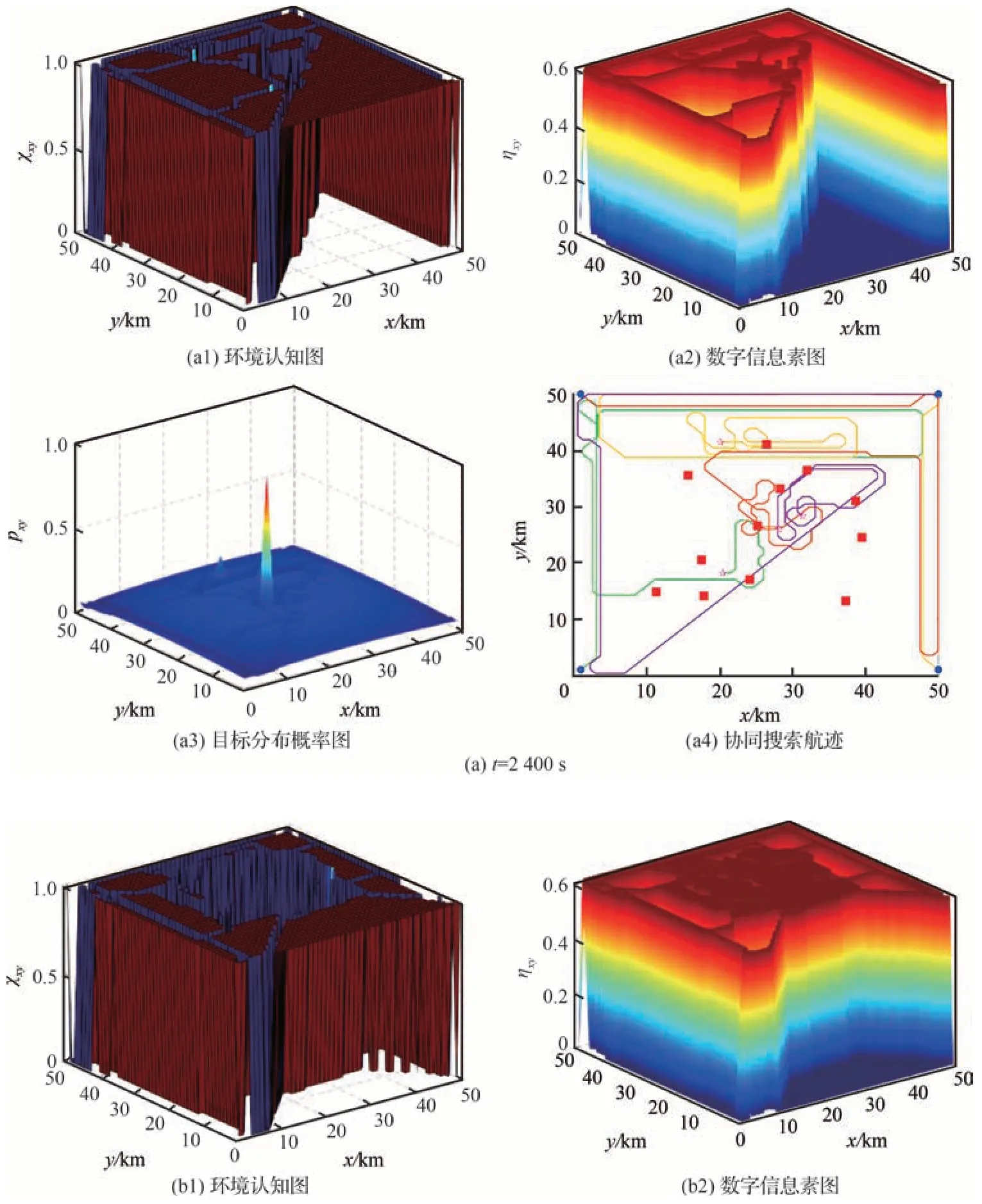
图11 协同搜索规划结果Fig.11 Results of cooperative search planning
由图11(a1)、图11(b1)和图11(c1)可知,随着任务的推进,ECM 能够持续引导UAV 集群对未知区域进行覆盖搜索,从而实现了对静目标信息的有效获取;由图11(a2)、图11(b2)和图11(c2)可知,当栅格的未受访时长大于规定回访时限时,通过打开信息素分泌开关,栅格能够持续分泌信息素并不断传入邻近栅格;由图11(a3)、图11(b3)和图11(c3)可知,通过引入动目标位置分布先验信息构建TDPM,能够有效引导UAV 对目标存在概率大的区域展开搜索,提高了UAV 对地面动目标的搜索能力。图11(a4)中UAV 搜索航迹重叠部分表明,基于DPM 定制的信息素引导的回访机制能够有效驱动UAV 对受访时间间隔较长的区域进行回访复检。此外,分析图11(a4)和图11(b4)可知,当UAV3 和UAV1 分别在(26,27)km 和(27,42)km 栅格内首次探测到可疑目标后,通过增大规划时域内目标探测收益的权系数,能够快速引导UAV3 自身以及UAV4 分别对发现可疑目标的区域进行回访,进而再次确认动目标真伪,表明了权系数动态切换引导的回访机制具有较高的合理性。综上,RM-DCSD 算法能够在引导UAV 集群对未知任务区域遂行覆盖式协同搜索的基础上,通过回访机制驱动,有效兼顾对地面动目标的搜索及捕获需求。
图12 为集群协同执行搜索任务过程中,各UAV 成员间的实时最小距离变化曲线。可以看出,机间最小距离始终保持在24 m 以上,满足UAV 集群的防碰撞要求。

图12 机间最小距离变化Fig.12 Minimum distance variation among UAVs
5.3 决策机制有效性验证与分析
为进一步验证所提出的决策机制在通信中断情况下的有效性,分别将基于信息融合的UAV 集群分布式协同搜索决策机制(记作决策机制1)与文献[24]提出的DMPC 决策机制(记作决策机制2)应用于搜索规划全过程,并独立进行30 次蒙特卡洛仿真,对比分析区域覆盖率与动目标捕获数量2 个评价指标。为确保实验数据公平可靠,在应用两种决策机制进行搜索规划时均不考虑回访机制的驱动,则令初始权系数κ3=0,其他参数设定同5.1 节。
假定搜索任务进行至2 500 s 时,UAV1 和UAV4 受干扰发生通信中断,并于6 000 s 时恢复通信。仿真结果如表5 和图13 所示。
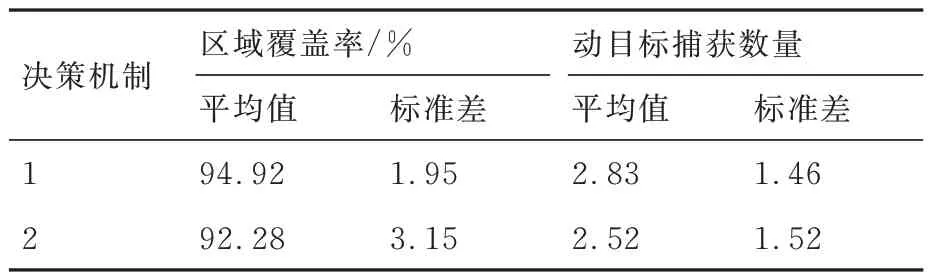
表5 评价指标的均值及标准差Table 5 Mean and standard deviation of evaluation indicators
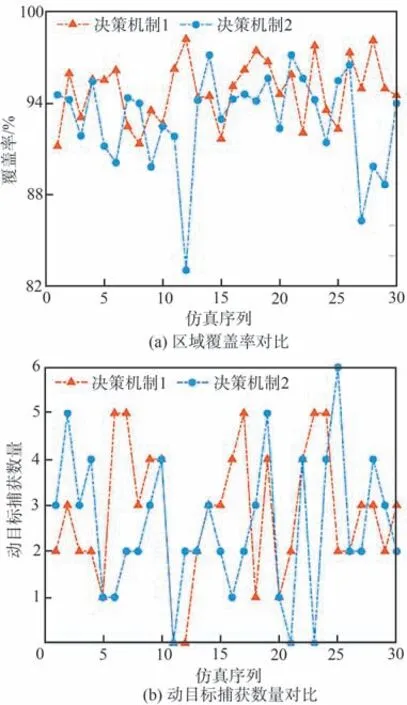
图13 2 种决策机制规划结果对比Fig.13 Comparison of planning results of two decisionmaking mechanisms
由表5 和图13 可知,决策机制1 在2 个评价指标的均值及标准差上的表现均优于决策机制2,表明在通信中断情况下,决策机制1 相比于决策机制2,具有更好的搜索规划效能与更强的稳定性。分析其原因为:UAV 集群基于决策机制1 进行协同搜索规划时,由于各成员是独立更新本机综合态势信息图的,因此,即使UAV1和UAV4 通信中断一定时间,但只要通信恢复,其他UAV 便能通过信息融合策略快速恢复UAV1 和UAV4 的历史决策信息,从而减少后续搜索过程中重复探测已知区域的情况,提高了集群对静目标的覆盖搜索效率。同理,也能通过信息融合后的全局TDPM 引导其他UAV 对UAV1 和UAV4 发现可疑目标的区域进行访问,从而完成对动目标的协同捕获。
综上所述,所提决策机制进一步增强了集群系统的鲁棒性,确保了集群即便在通信中断情况下,仍能相对稳定且高效地完成对静目标的覆盖搜索和对动目标的捕获。
5.4 回访机制有效性验证与分析
在5.3 节基础上,为进一步验证所提2 种回访机制的有效性,并分析其对集群协同搜索效能的影响,基于控制变量思想,在采用决策机制1 情况下,设置4 组回访机制标准对照实验,如表6 所示。其中,回访机制1 和回访机制2 分别表示信息素引导的回访机制和权系数动态切换引导的回访机制。针对每组实验,分别在无干扰条件下独立进行30 次蒙特卡洛仿真,每次仿真时长为6 000 s,其他参数设定同5.1 节。统计区域覆盖率、动目标捕获数量、栅格回访率和误判率4 个评价指标,结果如图14 和图15 所示。
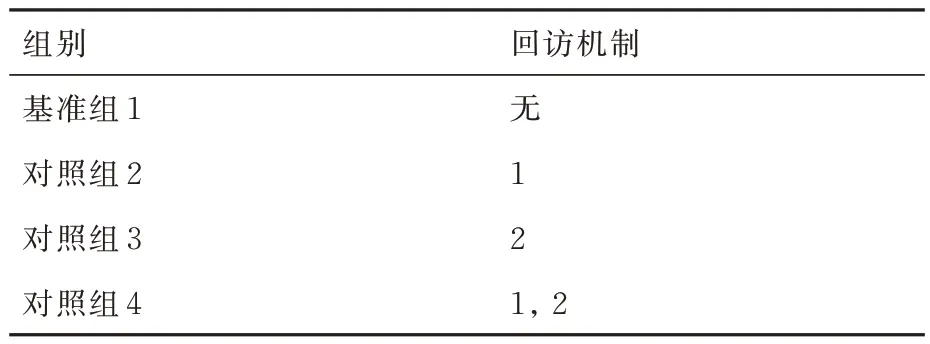
表6 回访机制有效性验证实验设置Table 6 Experimental setup for validation of revisit mechanism

图14 标准对照组实验规划结果对比Fig.14 Comparison of planning results of standard con‐trol group experiments
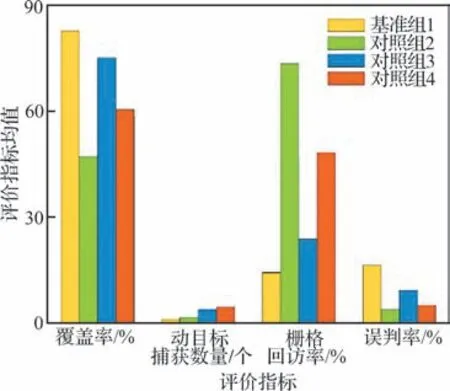
图15 评价指标均值对比Fig.15 Comparison of mean of evaluation indicators
结合图14(b)~图14(d)和图15 分析可知,对照组2 在栅格回访率、动目标捕获数量和误判率3 个评价指标上的表现均优于基准组1,表明回访机制1 能够有效驱动UAV 对全局栅格进行可控回访,从而减少UAV 遗漏目标情况,满足了动目标的搜索需求。同时也表明回访机制1 能够有效缓解因传感器虚警导致的目标误判问题,证明了所提信息素引导的回访机制的有效性。结合图14(b)、图14(d)和图15 分析可知,相比于基准组1,对照组3 具有更多的动目标捕获数量与更低的误判率,表明回访机制2 能有效引导UAV 对发现可疑目标的区域进行复检确认,在降低误判目标概率的同时,进一步提升了UAV 对动目标的捕获性能,证明了所提权系数动态切换引导的回访机制的有效性。综合分析图14 和图15 可知,对照组4 相比于其他实验组,具有更多的动目标捕获数量,且栅格回访率和误判率仅次于对照组2,表明通过2 种回访机制的联合驱动,能更好地满足UAV 集群对地面动目标的搜索需求。此外,从图14(a)和图14(c)可以看出,区域覆盖率与栅格回访率在整体上呈现出一种反比关系,表明2 种回访机制在提高了UAV 回访复检能力的同时,均会不同程度地降低对静目标的覆盖搜索效率。可以发现,回访机制1 相对于回访机制2,具有更高的栅格回访率与更低的区域覆盖率,这主要是由于前者的触发条件更为宽泛,且回访对象为全局受访时间间隔较长的已知区域。
值得说明的是,本文中2 种回访机制主要是针对协同区域搜索任务中动目标的实际搜索需求以及传感器虚警和漏检情况提出的。因此,上述分析过程中并没有将区域覆盖率作为验证回访机制有效性的评判指标,而是仅将其作为参照用于讨论2 种回访机制对静目标搜索效率产生的影响。
5.5 集群规模对协同搜索效能的影响
为定量分析集群规模对协同搜索效能的影响,分别指派由4、6、8、10、12、14 和16 架UAV 组成的搜索集群执行协同搜索任务。针对每种集群规模,分别进行30 次蒙特卡罗仿真,每次仿真时长为3 000 s,其他参数设定同5.1 节。不同规模下UAV 集群的区域覆盖率与动目标捕获数量统计结果如图16 所示。
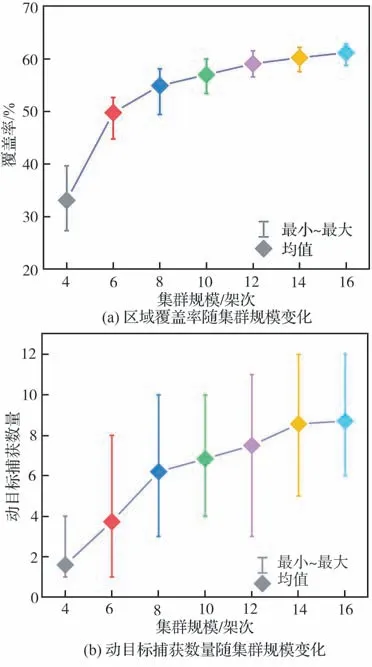
图16 不同规模下UAV 集群的协同搜索效率Fig.16 Cooperative search efficiency of UAV swarms with different scales
由图16(a)可知,随着集群规模的扩大,区域覆盖率整体呈增长趋势。可以看出,在集群规模少于12 架次时,覆盖率的增长速度较快,12 架次之后,覆盖率的增长速度明显放缓。由图16(b)可知,当集群规模少于14 架次时,动目标捕获数量随着集群规模的扩大明显增多,而当集群规模超过14 架次后,动目标捕获数量基本保持不变。
基于上述分析可知,在任务区域大小、目标数量以及搜索时长一定的情况下,不断扩大集群规模并不能持续提升集群协同搜索效能,相反,还会造成资源浪费。因此,需要根据具体任务需求确定适合当前任务场景的最佳集群规模。
考虑到论文任务需求是在保证UAV 集群捕获尽可能多的动目标的基础上,最大化覆盖搜索未知区域,因此,对于本文协同区域搜索任务想定而言,最佳集群规模为14。
5.6 不同方法性能对比
为了进一步验证所提算法的有效性,分别采用光栅式扫描方法、并排回寻式扫描方法[30]以及RM-DCSD 算法对任务区域进行搜索规划。为确保实验数据公平可靠,每种方法在相同实验平台上独立进行30 次蒙特卡罗仿真,仿真参数设定同5.1 节。统计区域覆盖率、动目标捕获数量和误判率,结果如表7 和图17 所示。
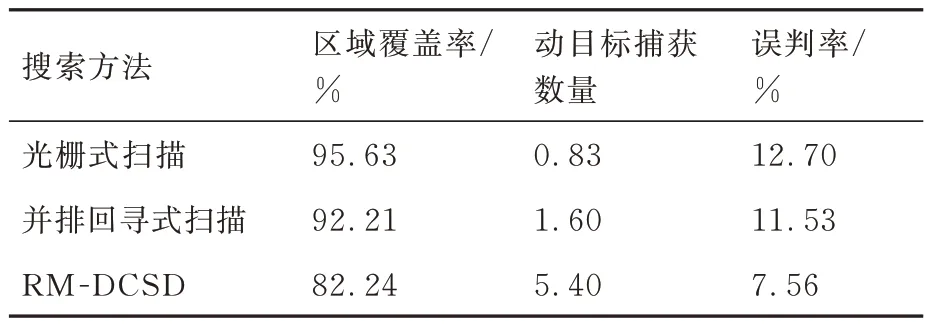
表7 评价指标均值Table 7 Mean of evaluation indicators

图17 3 种方法规划结果对比Fig.17 Comparison of planning results for three methods
由仿真结果可知,光栅式扫描方法与并排回寻式扫描方法虽然能够相对稳定且高效地完成对静目标的覆盖搜索,但两者均未有效利用先验任务信息,且受限于UAV 的初始位置分布与固定的搜索模式,难以满足动态环境下的搜索需求。其中,光栅式扫描方法引导的UAV 因回访能力不足而造成大量遗漏和误判目标情况,工程实用性较差。并排回寻式扫描方法虽然在一定程度上缓解了UAV 遗漏和误判目标问题,提高了对动目标的搜索效率,但规划过程中UAV 不能及时调整搜索航迹,回访复检效率不高,容易因传感器漏检而丢失目标,具有一定的现实局限性。相比于上述2 种对比方法,RM-DCSD 算法能够有效利用先验任务信息,从而实现UAV 实时在线自主决策,在回访机制驱动下,通过牺牲较少的覆盖搜索效率,高效引导UAV 对地面动目标进行捕获,并保证较低的误判概率。此外,对比分析5.4 节中对照组4 的实验结果可知,在任务区域大小和目标数量一定的情况下,适当延长搜索时长可以在一定程度上缓解RM-DCSD因回访机制造成的覆盖搜索效率下降的问题。
综上,所提出的RM-DCSD 算法能够有效兼顾未知任务区域内地面静目标和动目标的搜索需求,对动态未知搜索环境表现出良好的适应性。
6 结论
为提高协同区域搜索任务中UAV 集群对地面动目标的搜索效率,同时兼顾最大化覆盖搜索效能,在考虑传感器探测性能局限的基础上,提出一种回访机制驱动的UAV 集群分布式协同搜索决策算法。通过开展仿真实验,得出以下结论:
1)通过引入环境认知图,实现了UAV 集群对未知任务区域的覆盖搜索;通过引入目标分布概率图,提高了UAV 集群对动目标的搜索能力。
2)基于信息融合的UAV 集群分布式协同搜索决策机制实现了成员态势信息图的解耦式更新,进一步增强了集群系统鲁棒性。同时,通过信息融合策略确保了集群的分布式协同最优决策。
3)通过信息素引导的回访机制能够有效驱动UAV 对全局栅格进行可控回访,缓解了由于动目标的随机特性导致的UAV 遗漏目标问题以及因传感器虚警导致的目标误判问题;通过权系数动态切换引导的回访机制能够快速驱动UAV对发现可疑目标的区域进行回访复检,进一步减少了由于传感器的探测性能限制造成的目标漏检和误判情况。
4)集群规模与协同搜索效能之间呈现出一种非线性关系。因此,为避免资源浪费,在实际任务前应根据具体任务需求,通过数值仿真预先拟定合理的集群规模。
5)通过与光栅式扫描方法和并排回寻式扫描方法进行对比,表明所提出的RM-DCSD 算法能够更好地引导UAV 在动态未知环境下进行实时在线搜索决策,从而增强了UAV 对动态搜索任务的适应性。同时,在2 种回访机制的联合驱动下,能够有效缓解因传感器的性能约束造成的目标漏检和误判问题,通过牺牲较少的覆盖搜索效率,进一步提升了UAV 集群对动目标的捕获效率。
