计及机理机制的Stacking集成光伏发电预测
2023-07-26李智丁津津陈凡伍骏杰樊磊
李智, 丁津津, 陈凡, 伍骏杰, 樊磊
(1.国网安徽省电力有限公司, 合肥 230601; 2.国网安徽省电力有限公司电力科学研究院, 合肥 230601;3.安徽大学电气工程及自动化学院, 合肥 230601)
在碳中和的目标背景下,中国能源结构需加快转型速度。随着碳中和的目标提出,新能源发电逐步替代一部分火力发电[1]。中国的光伏发电产业处于高速发展阶段,截至2022年底,并网太阳能发电装机容量305.98 GW。随着光伏装机比例不断增高,弃光现象也不断发生,光伏发电消纳显得尤为重要[2]。精确地光伏功率预测在电力系统调度发挥着至关重要的作用,如何提高预测功率精度,是光伏发电预测的一大难题。
目前,工程中的光伏功率预测方法分为物理方法、统计方法和基于数据驱动算法[3-5]。其中,基于数据驱动算法的光伏功率预测是主要方法。这类方法具有建模简单、算法成熟、计算速度快等优点[6]。随着人工智能的快速发展,数据驱动方法在光伏发电预测中得到普遍应用。文献[7]针对各天气分型下的波动过程和类晴空过程,建立卷积神经网络(convolutional neural networks,CNN)和长短期记忆神经网络(long short-term memory,LSTM)的组合预测模型,兼顾了CNN和LSTM网络模型优点,预测效果较好。文献[8]采用变分模态分解将历史光伏发电功率分解成多个子模态,用LSTM分别预测光伏发电功率和误差。然而,数据驱动的预测技术完全脱离了光伏发电的内部机理,忽略了输入与输出之间的自然联系,其预测结果的可靠性受到质疑。
气象条件是影响光伏发电量必不可少的因素。由于光伏电站的发电依赖于不确定的、间歇性的太阳辐射,因此太阳能的获取和分配十分困难[9]。文献[10]以温度、辐照度等气象数据和相似日功率数据为输入变量,采用动量法优化反向传播(back propagation,BP)神经网络预测光伏功率。通常,光伏发电机理模型是时间、地点、光伏技术和当地气象条件的函数。文献[11]为探索太阳能与气象条件之间的物理关系,提出解析建模方法。文献[12]提出了一种能够适应天气变化的光伏组件温度预测模型。光伏组件的工作温度对光伏出力影响较大,环境温度、辐照度、风速作为模型的输入变量。
数据驱动模型一般依靠增加训练样本的数量来降低泛化的风险。在训练样本方面,获取全面、合格的新能源发电系统数据往往成本高昂,这缺乏适用性。在有限的样本下,要求数据驱动模型能在一定泛化误差下保证全局最优性,这对当前数据驱动模型提出了挑战[13]。基于机理模型和数据驱动联合的预测方法可以有效降低对样本数据的依赖。在数据质量和数量不理想的情况下,兼顾预测的准确性、速度和可靠性,具有较强的实用价值和广阔的应用前景。因此,通过引入基于领域知识经验,形成机理和数据联合的预测模型,可以降低机器学习的泛化风险[14]。目前,在温度预测[15]和意图识别[16]等领域已有机制和数据融合学习的探索性研究,并取得了一定的成果。光伏发电领域内,文献[17]在机理模型中对气象数据进行偏移修正,数据驱动模型中引入注意力机制削弱气象数据偏移的影响,再通过Stacking框架进行融合,实现了预测精度的提升。
基于以上条件,现提出一种Stacking模型框架下的机理模型与数据驱动模型的组合预测方法。Stacking框架可以将这两类模型结合起来使其可以并行计算预测。通过Stacking框架融合机理驱动模型和数据驱动模型的优点,进一步提高模型的泛化性能和预测精度。
1 算法理论
1.1 光伏发电机理模型
光伏发电的机理模型是根据太阳辐射和光电转换特性来预测发电量。光伏发电的机理特性模型[18]为
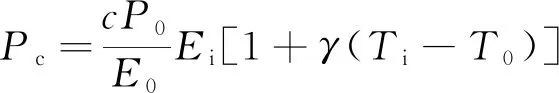
(1)
式(1)中:Pc为计算的光伏功率值;c∈[0,1]为光伏板的污垢系数,光伏板表明越洁净,c值越趋近1;T0、P0和E0分别为标准天气条件下的基准温度(25 ℃)、基准功率和基准辐照度(1 000 W/m2);γ为光伏系统的温度系数;直射辐照度Ei和光伏电池温度Ti为两种主要天气输入。
光伏电池温度可以根据周围环境温度的热传递[19]得到,公式为
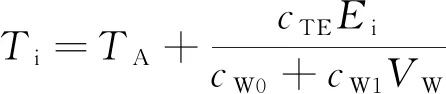
(2)
式(2)中:cTE为光伏系统吸收效率的常数因子;cW0=25 W/(m2·K)和cW1=6.84 (W/m3·s·K)分别为恒定的传热因子和对流换热因子;TA为环境温度;VW为风速。
1.2 Stacking集成框架
本文中集成了LSTM、XGBoost和光伏机理模型来构建Stacking框架[20]来预测光伏功率。Stacking模型适合于数据量大且特征维度多的数据集,是优异的光伏预测模型,其中第一层对多个模型的输出结果进行泛化,提高整体预测精度。Stacking结构如图1所示。
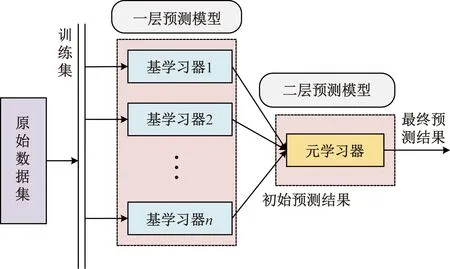
图1 Stacking集成框架Fig.1 The Stacking integration framework

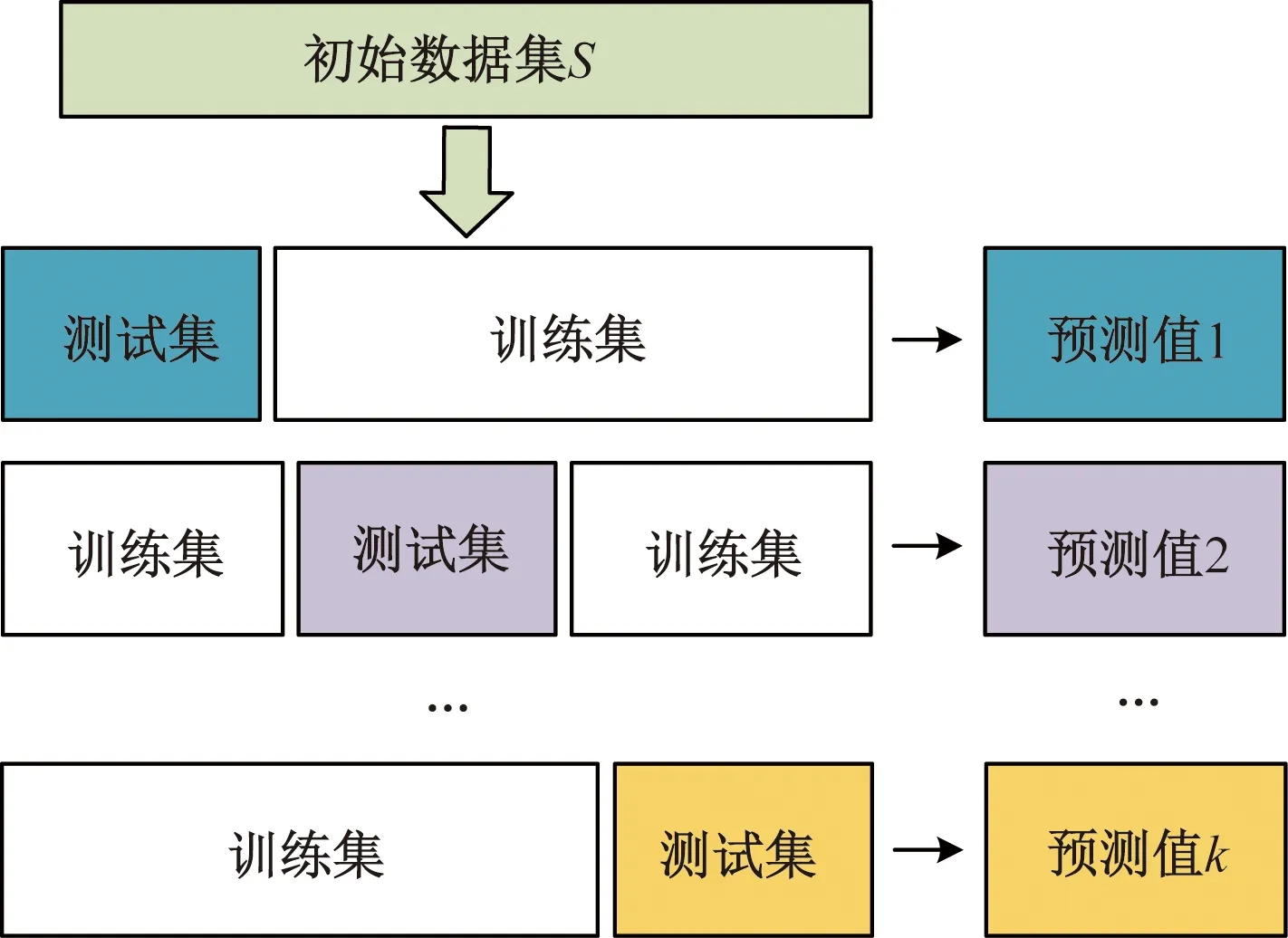
图2 一层学习器训练过程Fig.2 Training process of first-layer
1.3 基模型选取
Stacking一层基模型之间要求各个模型体现出差异化,且基模型效果越好,集成后的模型预测效果越精准。综合以上,考虑了3种不同类型的模型,分别为LSTM神经网络、XGBoost和光伏机理模型。LSTM适用于较长的时间序列,可以较好地分析时许数据间的规律,XGBoost适用于表格数据,满足光伏数据特征多的特点,同时具备LSTM没有的并行学习的能力,机理模型考虑光伏发电内部机理,降低对数据样本的过分依赖,并对数据结果进行合理约束。
由于二层学习器包含一层学习器抽取的新特征,为避免发生过拟合,二层学习器选择简单的线性回归模型(linear regression, LR)。
2 组合预测模型
2.1 流程
本项研究的实现流程包括天气归类、数据划分和预测,短期光伏功率预测流程图如图3所示。

图3 光伏功率预测流程图Fig.3 The flowchart of photovoltaic power prediction
(1)读取初始数据集,选取与光伏功率强相关特征值,剔除其中的异常值点集。随后将数据归一化处理,构成目标数据集。
(2)基于表1中的数值天气预报(numerical weather prediction,NWP)数值,将天气类型归为晴天、多云和雨天。

表1 天气分类规则
(3)依据待测天气类型,将对应气象下的数据集输入Stacking集成框架进行预测。
2.2 模型性能评价指标
通过数据能够直观反映模型的性能。采用平均绝对百分比误差(mean absolute percentage error,MAPE),均方根误差(root mean squared error,RMSE)和模型拟合系数(R2)来评价。其中,MAE值,MAPE
越小和RMSE值越小,表示模型越完美,得到的预测值更趋近真实值;R2越趋近1,表示预测结果的拟合度越趋近真实值。公式定义为

(3)

(4)

(5)
式中:yi为光伏实际发电量;y′i为光伏发电预测量;n为测试样本点。
3 算例分析
本项实验中利用安徽省某市光伏系统的气象和光伏发电量数据进行验证。实验样本集截取自2021整年,以天为单位,采集时间段为6:30—18:00,采集周期为15 min,其中包括辐照度、风速和温度等特征。
挑选3种典型天气条件下的光伏发电功率曲线对比如图4所示。曲线整体呈现峰状,表明光伏发电功率与当日太阳辐射量相关。晴天条件下,光伏功率曲线平滑,同时由于太阳辐射最强,发电量最多。多云天气下,由于云层遮蔽,影响光伏场站吸收太阳辐射,光伏发电量有所下降且具有一定波动,但由于光伏场站所在地理位置太阳辐射强,仍有较好的发电量。雨天条件下,光伏发电量较低,且波动性较强。
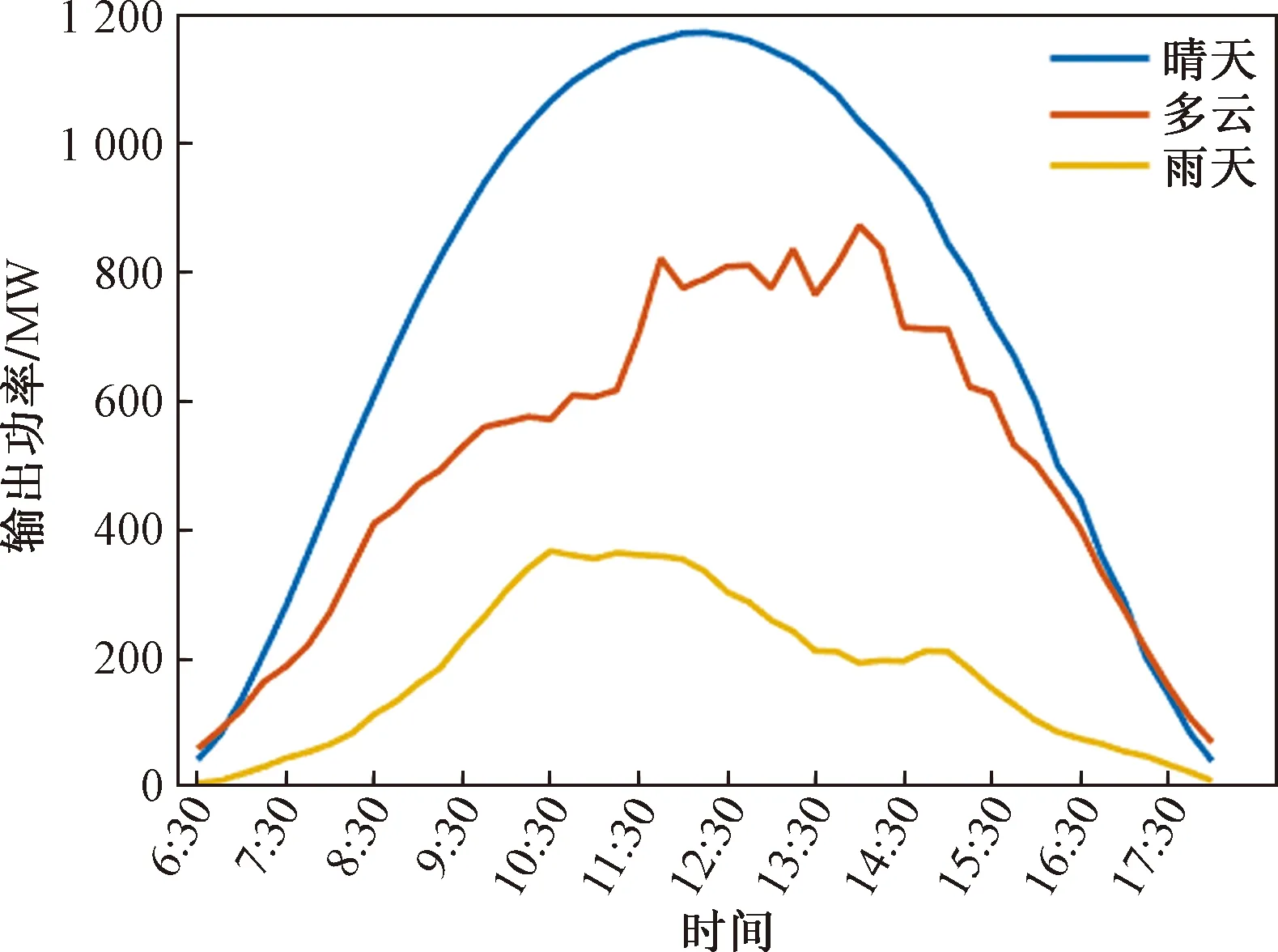
图4 典型天气下的光伏功率曲线Fig.4 Photovoltaic power curve in typical weather
将分类后的样本集输入Stacking集成框架进行预测,同时将LSTM、XGBoost和机理模型作为对比,3种天气下的预测结果对比如图5~图7所示。表2为预测指标对比。
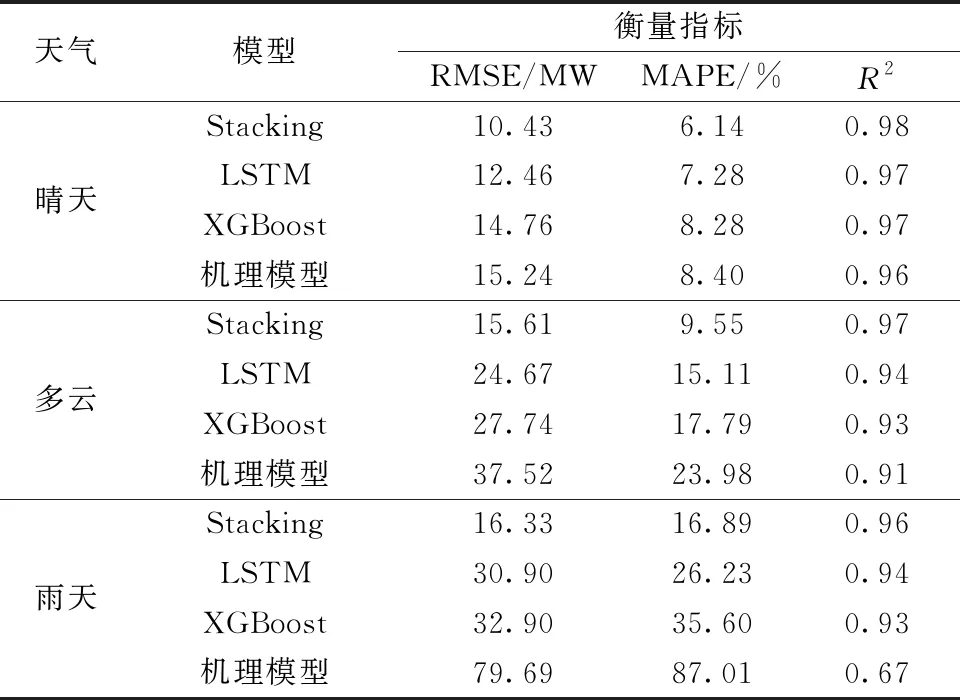
表2 不同模型的预测评价指标

图5 晴天条件预测效果对比Fig.5 Comparison of prediction of sunny conditions
图5为晴天条件下的预测结果,其曲线波动平稳,各模型均有良好的预测效果,其中Stacking的预测曲线偏差值最小。其RMSE相对于LSTM、XGBoost和机理模型降低了2.0、4.3和4.8,MAPE值分别减小了1.1、2.1和2.3。
图6为多云条件下的预测结果,光伏曲线整体仍呈现峰状,部分时段呈现锯齿状,幅值相比晴天条件下有所降低。结合表,Stacking算法仍有最好的预测表现。其RMSE值相对于LSTM、XGBoost和机理模型降低了9.0、12.1和21.9,MAPE分别减小了5.6、8.2和14.4。

图6 多云条件预测效果对比Fig.6 Comparison of prediction of cloudy conditions
图7为雨天条件下的预测结果,其曲线波动较强,发电功率与辐射相对较少。基于Stacking的预测结果更趋近于真实值,而其余3种方法的预测结果偏差较大。其RMSE值相对于LSTM、XGBoost和机理模型降低了14.6、16.6和63.4,MAPE分别减小了9.34、18.7和70.1。证明了机理模型与数据驱动算法能有效提升雨天模型的预测精度。
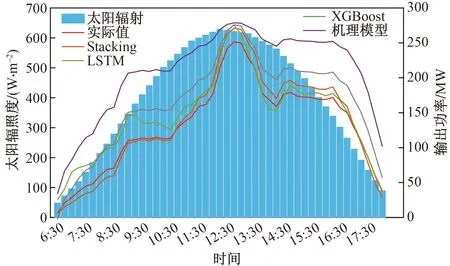
图7 雨天条件预测效果对比Fig.7 Comparison of prediction of rainy conditions
4 结论
为获取理想且可靠的光伏发电预测结果,考虑到光伏系统输入与输出间的自然联系,将机理模型与数据驱动模型进行结合。通过将机理模型嵌入Stacking框架,实现规则与经验的有机融合,可以更好地综合两种模型的优点。
通过安徽省某地区光伏数据作为实际案例进行计算,仿真结果证明,本文中设计模型有较好的预测效果。后续工作将采用更少的数据样本和更简化的机理模型,减小对数据样本质量和数量的依赖度以及建模复杂度,保证良好的预测精度和效率,并有效提升预测结果的可靠性。
