基于粒子群算法的科技创新数据检索系统设计
2023-07-25马芳平李林郭金婷柳玉兰徐镭梦
马芳平,李林,郭金婷,柳玉兰,徐镭梦
(国能大渡河流域水电开发有限公司,四川成都 610095)
随着信息化社会的进步,数字文献信息资源的管理和检索方法有了很大的改进,但在检索时会出现数据检索不安全、数据检索效率低的问题,导致数据资源共享出现了严重的“数据孤岛”情况。因此,建立一套完整的科技创新数据检索体系是十分必要的。有研究人员提出深度学习驱动的跨模态数据检索方法,建立了基于深度学习的多模式信息检索模型,在该模型上,结合深度学习的强大学习与表达能力,采用多标记相似度测量与建模训练技术,实现科技创新数据的检索[1];还有研究人员提出基于哈希算法的异构多模态数据检索研究方法,通过对图像和文字的语义建模,以保证在模式中的语义一致性。采用CCA 算法融合文字与图像的语义,产生最大关联矩阵,实现对科技创新数据的检索[2]。然而,上述方法受到原始数据集冗余信息和噪声影响,导致检索结果不精准。为此,提出了基于粒子群算法的科技创新数据检索系统设计。
1 系统硬件结构设计
基于粒子群算法的科技创新数据检索系统硬件结构如图1 所示。

图1 系统硬件结构
由图1 可知,该系统硬件结构是由四个部分组成的,分别是语义查询系统内核、语义全文检索系统内核、语义定义与注册系统、综合检索系统。基于本体论的语义搜索可以准确地对数据进行搜索,而基于语义的全文搜索系统则可以为整个搜索库提供一个具体的关键词[3]。该结构建立在一个统一的全文检索系统之上,包括索引、中文分词、搜索模式等。以粒子群算法为基础的综合检索系统,也能给使用者提供一个较为便捷的查询和展示界面[4]。
1.1 检索引擎
在检索服务器方面,按照所建立的索引库及整个系统的特征进行检索,并给出了相应的逻辑结构,如图2 所示。

图2 检索引擎
在解析过程中,根据代理服务器的查询请求,对查询请求进行分词处理,得到一系列关键字,然后根据这些关键字之间的逻辑关系,得到一条查询语句[5];采用哈希方法,将索引库中的索引关键词指派到各自的检索查询器中,根据搜索语句的关键词,在索引库中进行检索,产生对应的文档链接,再根据关键词之间的逻辑联系,将相关结果和查询的相关性一同传送至最后的循环[6]。
1.2 检索数据存储模块
检索数据存储模块通过预定义的协作策略,实现系统各功能模块的调用,并进行数据交互,实现协同工作[7]。该模块所用的工具是一个动态的数据存储模块,其结构如图3 所示。

图3 检索数据存储模块
检索数据存储模块是可移动的,外部硬盘的引进使储存于存储器装置中的主机装置变得更小巧、更便于携带。该存储器装置有两个存储区域,其中区域1 用来记忆储存资料,外部装置不可访问该区域;区域2 用来储存已加密的安全数据的,外部装置可访问该区域,并且加密的安全数据是区域1 中数据的加密版本[8-10]。
1.3 关联导航模块
关联导航模块如图4 所示。
图4 关联导航模块
在相关联导航模块中有3~5 个关键词和一个长的单词,通过首页、内页的宣传链接来判定这些词是否为热门词汇[11]。如果导航中的导航模块以长字开头,重点突出,且在关键词排行榜中有更多的内页,那么网站的排名将会更好,百度主页的速度也会更快,快速提升了科技创新数据检索速度[12]。
2 系统软件部分设计
2.1 基于粒子群算法的数据分词处理
由于词串是在通道中传送的,通道中存在噪声干扰,使词串失去了边界标志变为汉字串。为此,提出了基于粒子群算法的数据分词研究。数据分词流程如图5 所示。
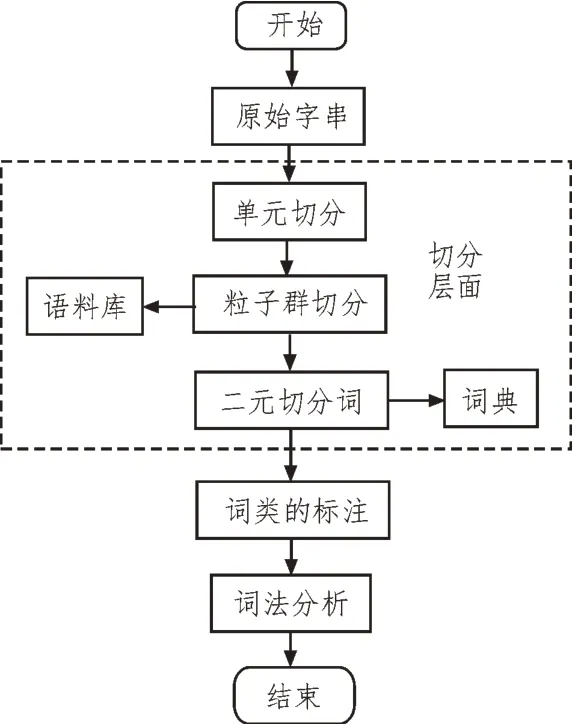
图5 基于粒子群算法的数据分词流程
在词典的基础上,找到所有可能出现的词,并构造一个有向无回圈的分词[13]。每一字与图表中的一条有向边对应,并将其分配到相应的长度(权重)。在此基础上,采用粒子群算法计算从起始到结束的最短路径,并将其输出作为分词的结果[14]。
粒子群求解过程为:设粒子群算法的种群规模为m,连续演化的时间为t,该时间段内的活动量可表示为:
式中,η(t,ai)表示粒子ai在连续演化的时间内的适应值。
如果粒子在连续演化时间内被选择参加飞行,则新的自适应分词表达式为:
式中,ϕ表示可调参数。
当粒子活动量较小时,新的自适应分词值较小,在随后的时间里,优先参加飞行,这会强迫系统的熵值增大[15]。群体中的弱小粒子具有更大的可供选择的可能性,使得求解空间中的探索区域和最佳粒子的驻留时间大大增加,改善算法的局部搜索性能,同时也避免了大规模的粒子聚集,保证了群体的多样性。该方法将待优化的各向异性作为最优参数,并对其进行了速度、位置的修正,使其在最优解空间内进行最优解计算。
2.2 检索流程设计
综合上述基于粒子群算法的数据分词处理过程,设计的检索流程如下所示:
步骤一:以各个粒子的位置矢量为控制参量,求出各个粒子的适配值,随机地对粒子的动态和行为进行初始化,决定最大可容许的重复次数,并将链接指向网页[16]。通过优化二元函数,寻找最优粒子并对其编码,评估链接最终价值。按照链接价值依次排序链接,并将相应的地址存入待搜索队列之中,由此确定粒子的最优位置。
步骤二:利用数据分词处理结果完成了对系统中的所有技术创新资料的分词,并在后台进行;
步骤三:当用户输入待检索的关键词后,由数据分词处理步骤分词处理关键词,由此产生对应的分词矢量;
步骤四:确定各个粒子的全局最优位置,并对文档特征矢量表中的全部记录进行了相关分析;
步骤五:根据相关程度进行分类,最终回归到相应的用户文件集中,实现了数据的检索。
3 实 验
3.1 科技创新数据源导入
由于技术创新的数据来源是外部资料,因此在进行研究时必须将数据来源的基本参数引入其中。图6 中显示了科技创新数据源的输入过程。

图6 科技创新数据源导入实现流程
由图6 可知,在该设计模式下,使用者将数据来源的参数信息填入到视图层次,并以URL 的形式传送至模型层。通过调用Controller 功能来获得URL,将分析结果作为返回的数值传递到模型层中。模型层根据返回值的判别结果,通过适当的加载量对数据进行分析。
3.2 评价标准
采用的评价标准是数据检索中的经典指标,即查准率和查全率,其公式分别为:
3.3 实验结果与分析
基于评价标准,分别使用深度学习驱动的跨模态数据检索、基于哈希算法的异构多模态数据检索和基于粒子群算法的检索系统,对比分析检索查准率和查全率,如图7 所示。
由图7 可知,使用深度学习驱动的检索方法查准率最高为77%,查全率最高为70%;使用基于哈希算法的数据检索方法,查准率最高为80%,查全率最高为77%;使用基于粒子群算法的检索系统,检索查准率和查全率均较高,其中查准率最高为96%,查全率最高为97%,均高于另两种方法。这是由于文中设计的检索系统,通过基于粒子群算法的数据分词处理步骤,能够改善数据干扰问题,提高查准率和查全率。
4 结束语
设计的基于粒子群算法的科技创新数据检索系统,通过粒子群算法对分词进行实时加权,通过在线调整,使系统具有自适应性,使得检索结果更加精准。经过对上述系统的分析,该系统真正地突破了以往的技术创新数据的限制,实现了对中心数据库数据的快速更新。
