基于频率-时间扩张密集网络的语音增强方法
2023-07-20黄翔东陈红红
黄翔东 陈红红 甘 霖
1 (天津大学电气自动化与信息工程学院 天津 300072)
2 (天津大学精密仪器与光电子工程学院 天津 300072)
语音增强是语音信号处理的重要组成部分,它旨在最大限度地去除背景噪声,提高语音信号质量和可懂度.在过去几十年中,传统的语音增强技术,例如,维纳滤波法[1]、谱减法[2]、基于子空间的方法[3]等受到了研究者们的青睐,但是这些技术在处理复杂环境下的语音信号时其效果往往不尽人意.
近年来,基于深度神经网络(deep neural network,DNN)的语音增强方法已被证实可获得比传统语音增强方法更高的性能[4-6].具体而言,该类方法的实质在于通过优化途径获得去噪后语音的短时傅里叶变换(short-time Fourier transform, STFT)幅度谱,并将之与原带噪语音的相位谱结合构造出完整的时频谱,再进行逆短时傅里叶变换(inverse short-time Fourier transform, ISTFT),即可生成增强后的语音信号.其中幅度谱优化可分为2 类途径:一类是间接方法,其致力于估计对带噪语音的STFT 幅度谱进行掩蔽操作的时频模板,如理想二值模板(ideal binary mask,IBM)[7]、理想比值模板(ideal ratio mask,IRM)[8]等;另一类是直接映射方法,借助网络优化直接求取去噪后的语音STFT 幅度谱.研究表明,间接方法比直接映射方法可在语音增强上获得更好的性能[9],故本文采用间接方法中的IRM 作为训练目标.
近年来,卷积神经网络(convolutional neural network, CNN)被广泛应用于语音增强中[10-12].文献[10]提出了第1 个全卷积语音增强网络,该网络证明了CNN 可在消耗比DNN 更少参数的情况下,获得比DNN 更优越的性能.
但需要指出,DNN 和CNN 存在共同的缺陷,即无法捕获语音信号的相邻连续时间帧之间的长依赖关系,这使其性能受到限制.为解决这一问题,研究者们在这些方法中融入了循环神经网络(recurrent neural network, RNN)、长短时记忆(long short-term memory,LSTM)网络,并取得了相应的性能提升.例如,文献[13]中提出基于RNN 的深度循环神经网络(deep recurrent neural network, DRNN),实验结果表明DRNN 的性能优于DNN.另外,文献[14]通过在编码器和解码器之间插入了双向长短时记忆(bidirectional long short-term memory, Bi-LSTM)网络,证明了获取相邻连续时间帧之间的长依赖关系可提升语音增强的性能,但代价是消耗更多网络参数.
为在不增加网络参数量的同时又可以有效捕获输入序列的长依赖关系,研究者们将时域卷积网络(temporal convolutional network, TCN)引入到语音增强中[15-18].文献[19]指出:由于TCN 由扩张卷积构成,拥有更大的感受野,从而可在不额外增加参数量的同时,获得比LSTM 更长的长期有效记忆能力.然而,以上基于TCN 的工作的缺陷在于,随着网络层数的增加,梯度消失问题变得突出,使得网络收敛速度变缓.
为解决梯度消失问题和进一步提升语音增强质量,本文将扩张卷积和密集连接网络(densely connected convolutional network, DenseNet)[20]相结合,提出频率-时间扩张密集网络(frequency-time dilated dense network, FTDDN).其特色在于:
1)在学习上下文信息方面,除了时间方向,扩张卷积同时被应用在频率方向.通过所构造的时间扩张卷积单元(time dilated convolution unit, TDCU)和频率扩张卷积单元(frequency dilated convolution unit, FDCU),本文所提网络在时频域内均可获得较大的感受野,从而能有效提取出深层语音特征,达到提升语音增强性能的目的.
2)在网络效率方面,本文中各级TDCU 和FDCU所提取的特征以密集连接的方式传递,不仅可缓解梯度消失问题,而且可避免经典信息论所指出的因级联信息处理模块数目增加而导致的信息丢失问题[21].
1 语音增强问题描述
假设含噪离散语音x(k)表示为
其中k表示时间索引,s(k)和n(k)分别表示干净语音和加性噪声.为实现语音增强从含噪语音x(k)中恢复出干净的语音估计的目的,需将x(k)进行STFT,得到时频表示:
其中
其中t∈[0,T-1],f∈[0,F-1],T和F分别是时间帧和观测频率的数量(为简化起见,后文将省略以上各时频表示的自变量t和f).随后将此时频表示的幅度谱|X|作为语音特征输入到神经网络.经过神经网络的优化,得到时频掩蔽M,并将此掩蔽M与 |X|相乘,得到增强后的语音幅度谱,最后通过对和含噪语音的相位谱 ΦX进行ISTFT 得到增强后的语音.以上过程可用式(4)描述:
其中 ℜ表示ISTFT,⊙表示矩阵对应元素相乘.
2 网络结构设计
2.1 融合扩张卷积与密集连接的模块设计
为能够充分捕获语音时频谱在频率、时间方向上的上下文信息,同时解决随着网络深度增加带来的信息丢失问题,本文将扩张卷积与密集连接结构相结合,分别设计了频率扩张密集模块(frequency dilated dense module, FDDM)和时间扩张密集模块(time dilated dense module, TDDM).
FDDM 的结构如图1 所示(图中表示卷积层的方框内第1 行数字依次表示扩张因子、卷积核大小和卷积核数量),其由 6个FDCU 卷积单元以密集连接的方式组成,其中每个FDCU 都包括2 层2D 卷积层,且每个卷积层之后都连接了1 层归一化层(batch normalization, BN)和1 个修正线性单元(rectified linear unit, ReLU).但第1 个卷积层使用普通2D 卷积,用以减少通道数;而第2 个卷积层使用频率扩张2D 卷积,其只在频率方向使用扩张因子以增大卷积核尺寸,由此增大感受野来捕获频率方向的上下文信息.

Fig.1 The structure of FDDM图1 频率扩张密集模块结构
FDDM 结构特色在于引入了密集连接结构:表现为每一级FDCU 的输入都是整个FDDM 的输入与其前面各级FDCU 输出的汇集,从而各级FDCU 的输入依次为16i×257×T,i=1,2,…,6.为保证在频率方向获得足够大的感受野,需逐级增大FDCU 的扩张因子di,将其依次设定为2i-1,i=1,2,…,6.
TDDM 则借鉴了TCN[19]的设计结构,并采用了与FDDM 类似的框架结构,如图2 所示:同样由6 个TDCU 卷积块以密集连接的方式组成,每个TDCU都包括3 部分,其中前2 部分的结构为1D 卷积层、归一化层、带参数的线性修正单元(parametric rectified linear unit, PReLU),第3 部分只有1 层单独的1D 卷积层.第1 部分采用普通1D 卷积,用以减少通道数;第2 部分使用时间扩张卷积,用以学习时间方向的上下文信息;第3 部分的单独卷积层则在输出时恢复整个TDCU 的通道.

Fig.2 The structure of TDDM图2 时间扩张密集模块结构
与FDDM 同理,TDDM 也融入了密集连接结构,表现为每一级TDCU 的输入都是整个TDDM 的输入与其前面各级TDCU 输出的汇集,从而各级TDCU的输入为128i×T,i=1,2,…,6,且其扩张因子di设定为2i-1,i=1,2,…,6.
从深层次意义上讲,正是因为图1 所示的FDDM和图2 所示的TDDM 的各层级联的FDCU 和TDCU的入口采用了密集连接,才避免了经典信息论所述及的“多处理模块级联会引起信息丢失”的现象(即信息不增性原理)[21],从而保证了特征重用,并促进信息流的传递.
2.2 总体频率-时间扩张密集网络的设计
综合以上拥有较大感受野的FDDM 和TDDM 的基本模块设计,本文提出频率-时间扩张密集网络FTDDN.
图3 展示了本文所提出的网络的框架结构,其输入时频幅度谱 |X|首先通过2 层2D 卷积层.第1 个卷积层用于增加输入特征的通道数;第2 个卷积层用于学习局部信息,并将其输出反馈给FDDM,以捕获频率方向的上下文信息和学习时间方向的局部信息.图3 中表示卷积层的方框内的第1 行数字表示卷积核大小和卷积核数量.

Fig.3 The structure of FTDDN图3 频率-时间扩张密集网络结构
FDDM 之后连接了2 层2D 卷积层和1 层1D 卷积层,其共同的作用是实现维度转换以及减少通道数,使FDDM 的输出的维度转换为128×T,并反馈至TDDM 中以学习时间方向的上下文信息.
经TDDM 处理后,其输出会送到3 个卷积单元中,前2 个卷积单元由1D 卷积层、归一化层和PReLU激活函数组成,用以聚合FDDM 和TDDM 学习到的频率、时间方向上的上下文信息,后1 个卷积单元由1D 卷积层和Sigmoid 激活函数组成,其将网络估计到的时频掩蔽模板M的维度恢复到257×T并将其值限制在[0, 1]区间内.
2.3 损失函数
图3 总体网络采用了文献[22]中提出的噪声感知多任务损失函数,即加权平均绝对误差(weighted mean absolute error,WMAE),其定义为:
3 实验设置
3.1 数据集及评价指标
实验数据集之一采用开源的VCTK 语料库[23],其训练集包括28 位说话人(14 位女性和14 位男性),测试集则包括另外2 位不同的说话人(1 位女性和1位男性).为创建含噪语音数据集,文献[23]的作者以4 种信噪比(signal-noise ratio, SNR)(15 dB,10 dB,5 dB,0 dB)向干净语音训练集添加了10 种常见环境噪声和人工制造的噪声[23],从而生成包含有11 572 个语音的含噪语音训练集;以另外4 种SNR(17.5 dB,12.5 dB,7.5 dB,2.5 dB)向干净语音测试集中添加了5 种常见环境噪声[23],从而生成包含有824 个语音的含噪语音测试集.为测试网络的泛化能力,测试集与训练集中所使用的噪声均不相同.因测试集中使用的说话人和噪声类型均与训练集不同,故也将其用作验证集以优化模型参数.为降低计算复杂度,本文将该语料库的信号采样率由48 kHz 降为16 kHz.
实验数据集之二采用LibriSpeech 语料库[24]的干净语音,其采样率为16 kHz,而噪声来源取自DEMAND 噪声库[25]和DNS Challenge 中的噪声集[26].为了构造实验所用数据集,在训练阶段,本文分别从LibriSpeech干净语音训练集和干净语音验证集中随机选取13 976 句语音和871 句语音,并采用随机选择的方式,将DEMAND 噪声库中的1 000 种噪声以10 种SNR(-7.5 dB,-6.5 dB,-4 dB,-3 dB,-1 dB,1 dB,3 dB,7 dB,-9 dB,11 dB)与这些干净语音混合,以生成含噪语音训练集和含噪语音验证集.在测试阶段,本文从LibriSpeech 干净语音测试集中随机选取740 句语音,并以4 种SNR(-5 dB,0 dB,5 dB,10 dB)向干净语音添加4 种噪声(DEMAND 噪声库:Cafter 噪声、Kitchen噪声、Meeting 噪声、Office 噪声),生成含噪语音测试集.为测试网络的泛化能力,该数据集中,测试集、验证集与训练集中的噪声不同:有水流声、汽车声等.
本文使用业内普遍接受的语音质量客观评估(perceptual evaluation of speech quality,PESQ)[27]和短时客观可懂度(short-time objective intelligibility,STOI)[28],以及主观平均意见分数——信号失真的复合测度(CSIG)、噪声失真的复合测度 (CBAK)和语音整体质量的复合测度 (COVL),作为实验结果的评价指标[29].
3.2 网络参数设置
本文所提出的FTDDN 网络的主要参数设置为:使用汉宁(Hanning)窗作为STFT 的时间窗,窗长为32 ms(帧长点数为512),帧移为16 ms(即50%重叠),由于实信号傅里叶变换具有共轭对称性,故图3输入STFT 幅度谱特征的尺寸为257×T(T取决于各条语音的长度).
在每次训练实验中,本文将设每批处理语音的条数BatchSize=4,在每批处理中,通过补零的方式使各句语音与该Batch中最长语音长度保持一致,对于超出4 s 的语音,则只取前4 s 参与训练.实验选用Adam 优化器,并以学习率0.000 2 训练网络100 次.
4 对比实验及结果分析
实验主要包括2 方面:1)开展消融实验,以探究FDDM,TDDM 内部的密集连接结构及卷积块FDCU和TDCU 的数量R对本文所提模型的语音增强性能的影响;2)分别针对3.1 节所提的2 个数据集,将本文所提模型与现有的语音增强网络做性能对比.
4.1 消融实验
为探究卷积块FDCU 和TDCU 的数量R和模块FDDM 及TDDM 中的密集连接结构对语音增强网络性能的影响,本文基于VCTK 语料库[23]进行了消融实验.为了简洁,消融实验结果仅使用PESQ 和STOI 作为客观评价指标.
图4 展示了在FDDM 和TDDM 均存在密集连接结构的情况下,不同的卷积块数量R对网络性能的影响.

Fig.4 Influence of different number of convolutional blocks R in FDDM and TDDM on network performance图4 FDDM 和TDDM 中不同卷积块数量R 对网络性能的影响
从图4 可看出,随着R的增大,网络性能逐渐提高至最高点后又开始逐渐下降.具体而言,当R从2增加到4 时,PESQ 和STOI 分别从2.89 增加到2.95和从0.938 8 增加到0.944 2;当R从4 增加到6 时,PESQ 和STOI 虽然也呈现一定程度的增加,但增速变缓,这是由于随着R的增加,网络深度增加,感受野也随之增加,使得网络学习到的上下文信息更丰富,最终提高了网络性能;而当R从6 继续增大时,可看到PESQ 变化趋势平缓、STOI 开始下降,这是因为当R继续增加时,网络深度也会加深,这导致信息丢失问题加剧,而密集连接结构的信息补充作用又无法完全解决这一问题,进而导致了网络性能退化.
表1 列出了在R=6的情况下去除TDDM 和FDDM中的密集连接结构后网络的性能变化.可发现:当分别去除TDDM 和FDDM 中的密集连接时,PESQ 从3.02 分别下降到了2.83 和2.97,STOI 从0.945 1 分别下降到了0.940 9 和0.944 7,这反映了密集连接结构的有效性,证实了该结构可通过信息补充加强特征传递和特征重用,达到增强网络性能的效果.从表1的PESQ 和STOI 的下降比例可看出,相比较而言,消融TDDM 比消融FDDM 影响更大,这是因为时间方向的上下文信息比频率方向的上下文信息更加丰富,从而间接证明了时间信息融合在提高网络性能方面更重要,但频率信息也不可忽略.

Table 1 Influence of Dense Connection on Network Performance表1 密集连接对网络性能的影响
4.2 对比实验1
针对LibriSpeech 语料库[24]在不同噪声和信噪比的情况下,将本文网络与3 种已有网络进行性能对比,这3 种网络分别是:基于LSTM 的语音增强方法、基于卷积循环网络(convolutional recurrent network,CRN)[30]的语音增强方法、基于时间卷积神经网络(temporal convolutional neural network, TCNN)[31]的语音增强方法.
表2 和表3 分别展示了对本文模型和3 种对比模型测评得到的PESQ 分数和STOI 分数,可以看出:除了5dB Meeting 噪声条件下,本文模型的STOI 分数略低于CRN 以外,在其他情况下,本文模型的PESQ分数和STOI 分数均要高于对比模型,这表明本文模型的语音增强性能更优越.

Table 2 Evaluation PESQ Scores of FTDDN and Baseline Models Using LibriSpeech Corpus表2 使用LibriSpeech 语料库对FTDDN 与基线模型的评测PESQ 分数
观察表2、表3 的数据可发现,所有模型在Cafter和Meeting 噪声条件下的语音增强性能都低于在Kitchen 和Office 噪声条件下的语音增强性能,这可归结为不同噪声源的时频谱结构造成的影响.具体解释如下:如图5 所示,Cafter 和Meeting 噪声中以人声为主,其时频谱结构与干净语音的结构非常相似,故增加了噪声与干净语音的区分难度,导致网络去噪性能下降;而Kitchen 和Office 噪声结构与干净语音结构相差很大,降低了网络从含噪语音中学习干净语音结构的难度,有助于提升去噪性能.
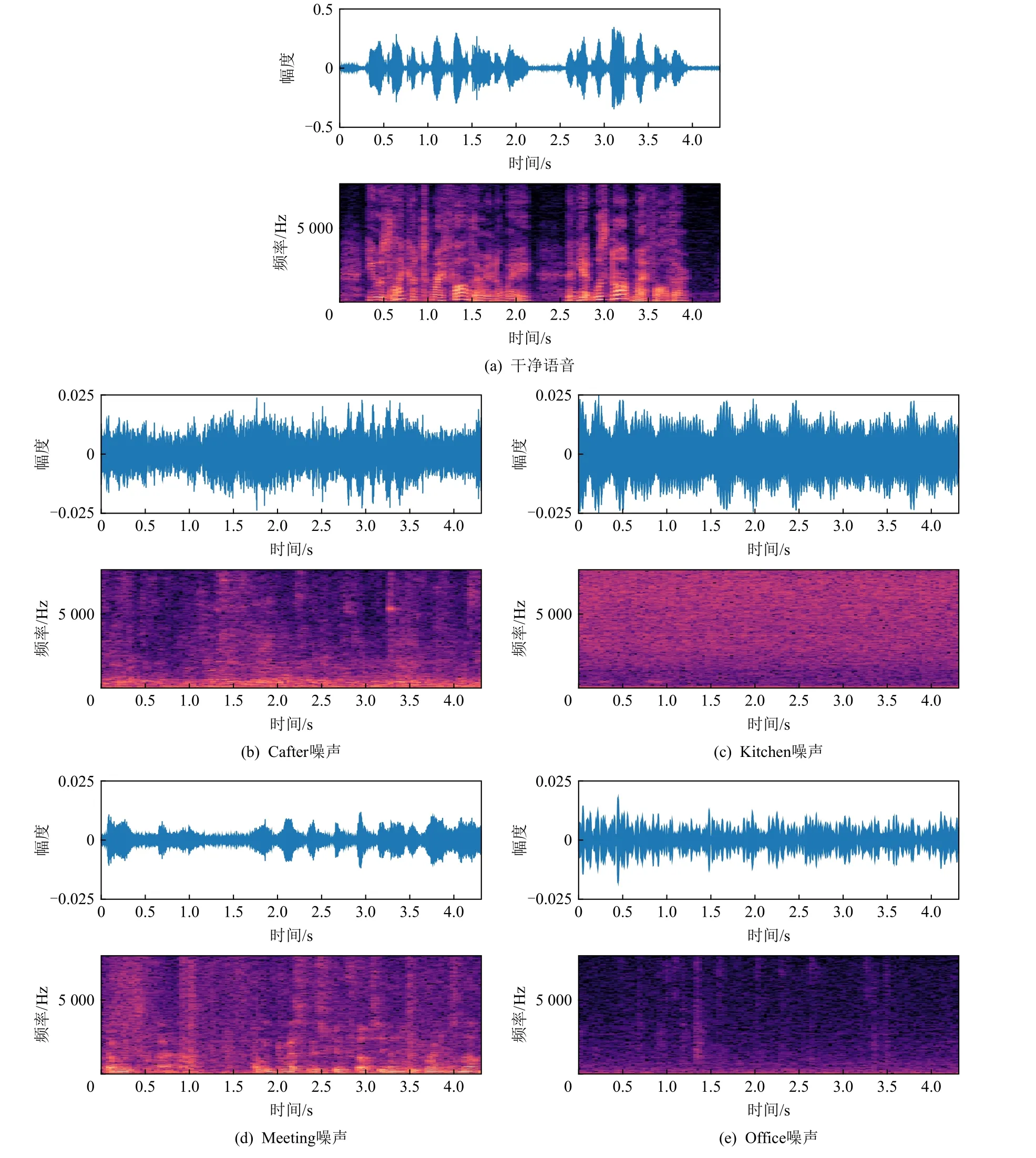
Fig.5 The time-frequency spectrograms of clean speech and different noises图5 干净语音和不同噪声的时频谱
为直观反映各对比模型与本文模型的语音增强效果,图6 展示了这些模型对 5dB Kitchen 的含噪语音增强后的结果(其加噪前后的时频谱如图6(a)(b)所示),从中可看出,图6(c)所示的LSTM 模型只是轻微地去除了噪声,只能恢复干净语音的大致结构;相比而言,图6(d)所示的CRN 模型和图6(e)所示的TCNN 模型去噪更显著,但其优势主要体现在低频区,而高频细节较为模糊;而本文提出的FTDDN 模型在去除噪声的同时,又最大限度地保留了语音信息,见图6(f).究其原因,各对比模型仅着重考虑了语音时间方向的上下文信息,而忽略了语音频率方向上下文信息间的联系,而语音的能量大部分聚集在低频部分,这导致模型对语音的高频信息关注度降低,使得增强后的语音高频信息丢失,而本文提出的FTDDN 模型给予了语音频率方向和时间方向上下文信息同等关注度,并同时学习了语音时频谱高频信息与低频信息之间的相关性和时间帧之间的依赖关系,最终得以保留完整的语音时频谱信息.需指出的是,以上实验所使用的测试集中的说话人、噪声种类以及信噪比皆与训练集和验证集中的完全不同.故表2、表3 的实验结果证实了本文模型在数据条件完全不匹配的情况下,仍可实现高性能降噪,证实了本文模型具备较高的泛化能力,可适应不同噪声条件下的复杂环境.

Fig.6 The time-frequency spectrograms of clean speech, noisy speech, and enhanced by different models图6 干净语音、含噪语音以及不同模型增强后的语音时频谱
4.3 对比实验2
将本文提出的FTDDN 模型与现有的SEGAN[32],Wave-U-Net[33],WaveCRN[34],MetricGAN[35],MB-TCN[17],NAAGN[22]模型进行性能比较.所有模型都使用VCTK语料库进行实验.从表4 列出的对比结果可以看出,本文提出的FTDDN 模型在除STOI 以外,所有指标都优于其他对比模型,这是由于SEGAN,Wave-U-Net,WaveCRN这3 个网络的输入为时域波形,而本文的FTDDN 则以时频幅度谱作为网络的输入,但时频域的信息往往比时域更加丰富、细致,从而使得网络可学习到更丰富的信息,这有利于网络性能的提升;MetricGAN,MB-TCN,NAAGN 这3 个网络虽然与本文的FTDDN 一样,都以时频幅度谱作为网络的输入,但MetricGAN 的设计是直接基于评价指标来优化网络,未专注于学习语音信号的细节信息,从而使网络性能受到限制;MB-TCN 更多关注于学习语音信号的时间方向的上下文信息,却忽略了频率方向的上下文信息的重要性;NAAGN 通过扩张卷积同时学习时间和频率方向的上下文信息,但并没有进行单独学习;而本文通过融合密集连接结构和扩张卷积将学习频率和时间方向的上下文信息分开进行,并在网络末端进行信息整合,故使网络学习到的语音信息更加细致,进而提升网络性能.特别地,可以发现NAAGN 模型的STOI 分数略高于本文所提模型,这是由于NAAGN 模型相对于本文模型额外引入了注意力门(attention gate, AG)模块,因此可进一步学习到输入样本中的更感兴趣的特征,并对其进行修剪,以保留相关的激活,从而可获得略高的STOI 分数.

Table 4 Performance Evaluation Scores of FTDDN and Baseline Models Using VCTK Corpus表4 使用VCTK 语料库对FTDDN 与基线模型的性能评测分数
5 结 论
为高质量地恢复语音信号,本文设计了频率-时间扩张密集网络(frequency-time dilated dense network,FTDDN),其包括2 个最主要的模块:FDDM 和TDDM,由于这2 个模块均融入了扩张卷积和密集连接结构,因而FTDDN 可获得较大的感受野以捕获频率方向和时间方向的上下文信息.基于LibriSpeech和VCTK 语料库与各类现有语音增强网络性能的对比实验表明:本文提出的FTDDN 网络的语音增强性能更加优越,可在有效抑制噪声的同时高质量地恢复语音,故在语音识别、文本语音转换、助听器设计、网上会议等应用中有广阔应用前景.
作者贡献声明:黄翔东完善实验方案并修改论文;陈红红提出算法思路,并负责完成实验和撰写论文;甘霖提出指导意见.
