基于FPGA和多核DSP的雷达信号处理架构设计
2023-07-15郑东卫白亚莉
郑东卫 白亚莉
(1.西安电子工程研究所 西安 710100;2.西安昆仑工业(集团)有限责任公司 西安 710043)
0 引言
系统架构设计是实时信号处理系统设计中的重要组成部分。目前雷达信号处理典型硬件平台为FPGA加多核DSP。根据系统输入参数设计出合理高效的信号处理机会面临诸多问题,例如如何选择合理的处理平台,设计合理的拓扑结构,优化传输链路和数据存储空间分配等。信号处理开发设计流程如图1所示。根据信号处理任务书指标,选择相应的软件算法和硬件平台,安排相应的算法在哪个平台实现,根据实现平台设计拓扑结构,然后计算传输链路带宽分析,计算存储空间分析等,接着进行算法实现,实现完后再计算实时性是否满足指标要求。如果不满足需要调整硬件平台或硬件底层拓扑结构及系统架构。所以发挥FPGA和多核DSP的各自的最优性能,开发高效实用的系统架构是十分必要的。
1 算法分析及硬件平台选择
地面雷达信号处理算法一般包含:数字下变频、数字波束形成、脉冲压缩、动目标检测、恒虚警检测、点迹凝聚、方位俯仰测角、目标上报等环节。由于动目标检测之前这些算法需要用到大量的乘法器加法器等,这些算法适合在FPGA中实现,之后的算法需要大量的逻辑判断适合在DSP中完成。
在DSP中实现动目标检测之后的算法,DSP可以选用应用广泛的TI公司多核TMS320C6678芯片。此DSP包含8个内核,核工作速率可达1.25GHz,每个核包含存储区32KB的L1P,32KB的L1D,512KB的L2,8核共享4MB的MSMC,可外接8GByte的DDR3,支持最大5Gbps的SRIO接口[1]。虽然单个DSP功能很强大,但当FPGA送来的数据量很大时,单个DSP无法在一个相参处理时间内实时完成检测计算,就需要多片DSP并行计算完成。计算时间统计可在DSP中使用C语言库中的clock函数对各个功能的信号处理计时。需要多片DSP多个核并行处理才能完成时,需要考虑到多核并行操作有一定的效率损失,需要增加一定的冗余量。
在FPGA中实现动目标检测求模之前算法,需要根据系统参数估算所占的FPGA资源,选择合适型号的FPGA。一般选用FPGA型号主要参考内部乘法器数量,存储器数量,GTX模块数量等。
数字下变频单元主要有混频和滤波组成,所需的乘加器资源由下列公式决定:
1)使用非对称系数Fir滤波器M路数字下变频所需乘加器数为
M×N×Fs/(Fclk×D)×2+2
(1)
2)使用对称系数Fir滤波器M路数字下变频所需乘加器数为
M×N×Fs/(Fclk×D)+2
(2)
数字波束形成主要是乘累加运算,所用乘法器由公式(3)决定:
3×M×B×Fs/Fclk
(3)
数字脉冲压缩采用时域处理方式时,时域实现方式即为复数的卷积运算。一个复数的乘法运算可由4个乘法或3个乘法来实现。比较4个乘法和3个乘法的运算式可以看到,3个乘法的运算式虽然少了1个乘法,但需要5个加法,因此,四个乘法的运算式更适合FPGA运算。所需的乘加器资源如下:
1)使用非对称脉压系数B路脉压所需乘加器数:
B×N×Fs/Fclk×4+2
(4)
2)使用对称脉压系数B路脉压所需乘加器数:
B×N×Fs/Fclk×2+2
(5)
动目标检测采用FFT加窗实现,FFT所用乘法器可通过调用开发软件的IP核来得出,加窗所用乘法器数为
B×FFT×Fs/Fclk
(6)
其中:M表示通道个数;B表述波束个数;N表示Fir滤波器阶数;Fs表示输入数据率;Fclk表示工作时钟频率;D表示抽取率;FFT表示积累点数。
数字下变频所用片内存储器主要由滤波器系数长度、数据位宽和数据缓存大小决定。波束形成所用片内存储器由通道个数、波数个数、数据位宽以及数据缓存大小决定。脉冲压缩采用时域脉压时,所用片内存储器由脉压系数长度、数据位宽、数据缓存大小决定。动目标检测采用FFT加窗实现时,所用存储器由窗系数大小、数据位宽、数据缓存大小决定。
GTX模块需求数量大小由与FPGA通信传输带宽和接口数量来决定。FPGA与DSP之间采用SRIO通信,单片DSP与FPGA之间可最大支持4X的SRIO,即最大传输带宽可达20Gbps。如果单片DSP数据传输带宽不够就需要多片DSP并行处理,既可提高传输带宽又可提高处理速度。
FPGA的主要厂商有Xilinx公司、Altera公司、Lattice公司等,其中Xilinx公司的FPGA在中高端市场占有率遥遥领先,可结合自己使用习惯选择不同厂商。图2列出了Xilinx公司的Kintex-7系列的FPGA器件手册截图[2]。根据所用的乘法器数量,存储区数量及GTX数量,再结合FPGA厂家的器件手册可以选出合适的FPGA型号。
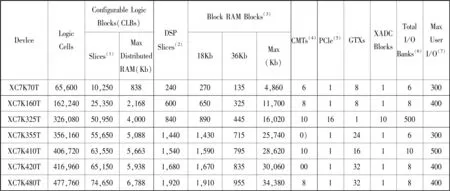
图2 Xilinx公司的Kintex-7系列FPGA资源
2 硬件底层拓扑结构
2.1 数据传输划分
每片DSP内8个核在并行处理时如何分工配合,多核DSP程序开发中两种常用的任务分配模式为主从模式和数据流模式[3]。
1)主从模式
将核0作为主核,主要用于任务分配、调度和触发,接收FPGA数据,写DDR3操作。
其它核为从核,主要用于读DDR3操作,并行处理检测数据,核间同步等。这种分配方式需要主核和从核进行频繁地消息通信。
2)数据流模式
各DSP核以流水线的方式按照数据处理的流程执行各任务。不同DSP核间有很强的数据依赖关系。这种分配方式需要考虑不同核之间的任务划分的均衡,否则任务较多的核会出现处理瓶颈。
FPGA处理完后,一个CPI内包含的处理数据有距离单元维,多普勒通道维,波束个数维的三维数据。当多核DSP程序开发按主从模式进行任务分配时,如何将这些数据分给不同DSP或不同核来完成相应的运算使计算效率和传输效率更高,现按三个维度划分来分析。
1)按多普勒通道划分
若按多普勒通道划分,将不同的多普勒通道维数据分给不同的DSP不同的核处理,每一个DSP核处理完整的距离单元维和波束维数据。若没有多普勒维恒虚警,不需要考虑多普勒维交叠。多普勒维点迹凝聚时需要汇总所有多普勒通道数据。
2)按距离单元划分
若按距离段划分,将不同的距离单元维数据分给不同的DSP不同的核处理,每一个DSP核处理完整的多普勒维和波束维数据。需要考虑在距离维恒虚警检测时片间距离段交叠,距离维点迹凝聚时需要汇总所有距离段数据。
3)按波束划分
若按波束划分,将不同的波束个数维数据分给不同的DSP不同的核处理,每一个DSP核处理完整的距离单元维和多普勒维数据。需要考虑在目标方位或俯仰测角时片间需要波束交叠,波束间凝聚需要汇总所有波束数据。
按何种方式划分,首先看不同模式积累点数,距离单元个数,波束个数这些参数哪个参数变化小,划分能兼顾各个模式,其次按某种方式划分看是否带来数据传输冗余计算复杂。当按一维划分单核还不能实时完成处理运算时,也可进行第二维的再次划分。
2.2 乒乓流水传输
前面叙述了芯片的选择及功能划分,而芯片内部链接关系及传输方式也影响系统处理效率。整个处理过程按流水方式操作,不同芯片之间,不同核之间都需要采用乒乓方式传输处理。
FPGA将数据发送到DSP的共享存储区中,由于单片DSP的共享存储区空间仅有4MB,共享存储区需要给全局变量及操作系统等留有一定的存储空间,所以给数据传输留得空间有限,FPGA需要分包给DSP发送数据,如果采用乒乓方式,需要的存储空间要翻倍。FPGA采用分包的方式通过SRIO给DSP共享存储区空间搬移数据,按乒乓方式将相邻包发到DSP的不同共享存储区。DSP主核乒乓将共享存储区中数据通过EDMA方式搬移到DSP外接的DDR3中。DDR3中也需开辟的乒乓存储空间,当一个滑窗CPI所有数据包都写入DDR3后,DSP主核给从核发送IPC中断,从核每个滑窗CPI从DDR3中乒乓读取数据到从核的L2中,从核处理完检测数据后再写入乒乓共享存储区中供主核使用。数据乒乓传输过程如图3所示。
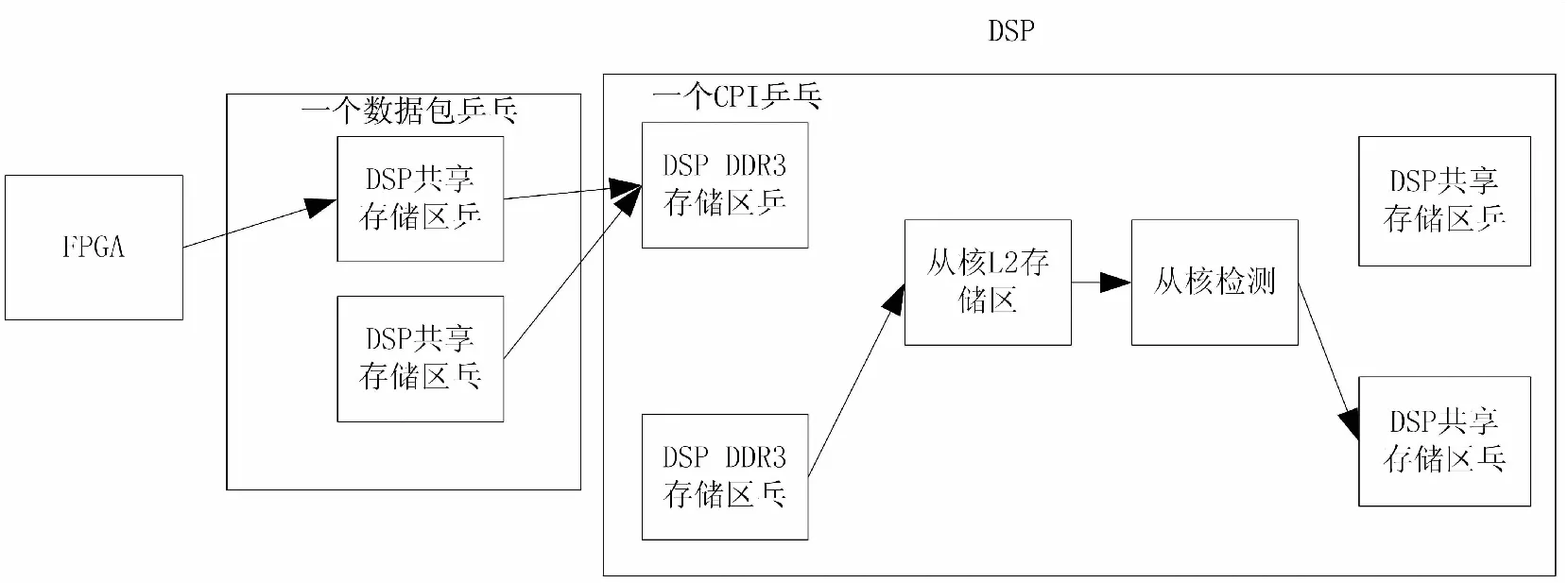
图3 数据乒乓流水架构
2.3 运算板DSP内核间通信与同步
DSP片内8个核在处理过程中存在通信和同步的问题。核间中断(IPC)与硬件信号量(Semaphore)是多核DSP内实现核间通信与同步的两种主要方式[4]。片上系统设计了核间中断的映射中断号与中断向量,通过片上中断控制器来完成内核间的同步操作。而硬件信号量则是结合了中断与查询两种方式实现核间的同步与数据传递,下面将就这两种方式分别做一概述。
核间中断专门用作处理器内部各核之间的通信与同步等操作。C6678的每个内核均可以向其他核发送中断,每个内核也都可以接收任何主控制核的中断请求操作。IPC中断的触发和接收过程设置简单,只需要操作各核的IPC中断产生寄存器(IPCGRx)和IPC中断响应寄存器(IPCARx),其中x代表核ID号0~7。将IPC中断产生寄存器的IPCG位置1即会触发相应核的IPC中断,将寄存器中SRCCn置1会清除相应的中断标志[5]。
在主核程序中初始化核间中断,当主核接收完FPGA发来的数据写入DDR3后依次触发给从核的核间中断。从核完成各自检测运算处理,通过信号量进行核间同步,同步完后由核1给核0发送核间中断。核0收到核1的核间中断后读取从核的检测数据。图4示意了主核与从核之间的核间中断。
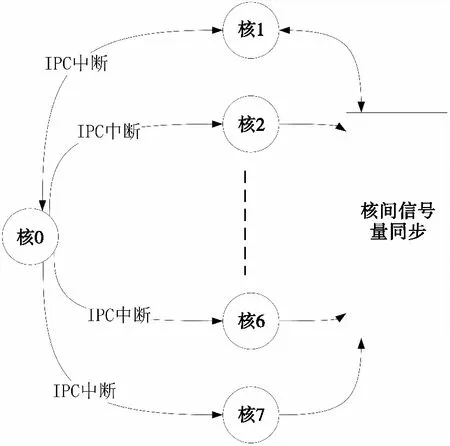
图4 多核DSP的核间中断
DSP中信号量可用于同步多核处理流程或用来避免多个DSP核同时操作某一共享资源时产生的冲突问题。利用硬件信号量可以在某一共享资源正在备占用或修改时,拒接或阻塞其他DSP核访问请求。信号量的操作主要有等待信号量CSL_semIsFree,获取信号量CSL_semAcquireDirect,释放信号量CSL_semReleaseSemaphore。这三个ARI函数可调用库函数实现[6]。
从核处理完后可采用信号量的方式完成核间同步。设置两个信号量,一个为处理信号量SEM_PROCESS_BASE_ID,一个为同步信号量SEM_SYNC_BASE_ID+DNUM。7个从核之间信号量过程如图5所示。核1在处理检测之前先获取处理信号量SEM_PROCESS_BASE_ID,处理完检测数据后再获取核1的同步信号量SEM_SYNC_BASE_ID+1,然后判断所有从核何时会全部释放各自的同步信号量SEM_SYNC_BASE_ID+DNUM,如果全部释放了说明所有从核都完成了检测处理,这时核1给主核发送核间IPC中断,如果判断没有全部释放同步信号量,则进行等待。核2~7在检测处理完后获取各自的同步信号量SEM_SYNC_BASE_ID+DNUM,然后判断核1是否释放处理信号量SEM_PROCESS_BASE_ID,如果核1释放了处理信号量,则核2~7释放各自的同步信号量SEM_SYNC_BASE_ID+DNUM,否则判断等待核1的处理信号量。
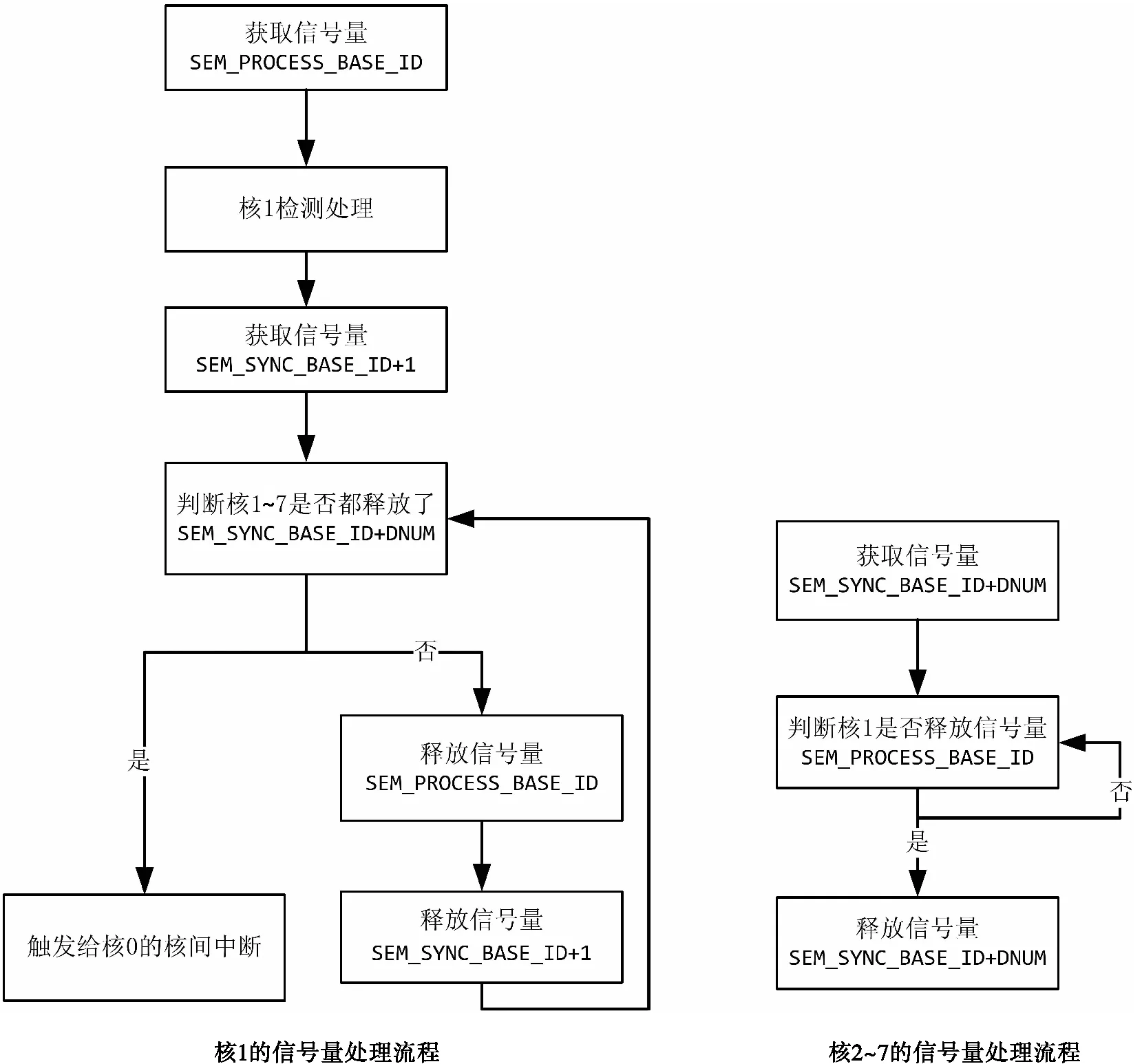
图5 信号量处理流程
3 DSP的存储空间和传输时间计算时间分析
现结合实例来分析DSP的存储空间和传输时间及计算时间。某地面雷达有1024个距离单元,16个多普勒通道,5个和波束数据,5个差波束数据,一个相参处理时间CPI为3ms。FPGA将处理后的MTD数据通过4X的SRIO送给多核DSP做后续检测处理。DSP按主从模式处理,FPGA按波束划分给DSP传输,5个和波束需要一个主核和5个从核处理,每个从核完成一个和波束的检测处理。
3.1 DSP的存储空间分析
DSP的存储空间主要包含内部L1D,L1P,L2,共享存储区,外部DDR3。在设计中为了提高代码运行效率,一般将DSP的每个核L1D,L1P全部设为cache。L2有512MB空间,分128KB空间用于堆栈存放,剩下384KB空间用于buffer缓存,主要是运算过程中临时数据缓存。共享存储区中预留512KB用于程序代码的存放,预留2MB用于接收FPGA发来的MTD数据,预留1.5MB用于程序中全局变量,数组,结构体的存放。DDR3中主要放从共享存储区中搬来的MTD数据,以及处理完的MTD模值数据,重排数据,杂波图数据,原始视频数据等。由于DSP的1个主核和5个从核共享DDR3,每个从核读取一个和波束和一个差波束数据,MTD总共存储数据为1024距离单元,16个多普勒通道,10个波束,MTD实部虚部,数据位宽32bit,如果再考虑乒乓存储,所以共计大小为20Mbit。杂波图设计为5维杂波图,数据为1024距离单元,16个多普勒通道,5个和波束,3个参差的prf,256个方位单元,数据位宽为32bit,所以共计大小为1.875Gbit。而单片DSP可外挂8GByte的DDR3,完全满足存储空间要求。
3.2 传输时间分析
FPGA按一包64个距离单元,16个多普勒通道数据搬移到DSP的共享存储区中,DSP主核收到一包数据后将共享存储区中数据搬移到DDR3中,实测每一包数据传输最大耗时Max_SRIO_Transmit_Time为9.174μs,如图6所示,图中时间单位为ns。一个滑窗CPI内需要搬移的数据为160包(每个波束分为16包,5个和波束,5个差波束,共计160包),所以DSP主核搬移一个滑窗CPI数据耗时为160×9.174μs(1467.84μs)小于一个滑窗CPI时间3000μs,所以传输时间满足要求。
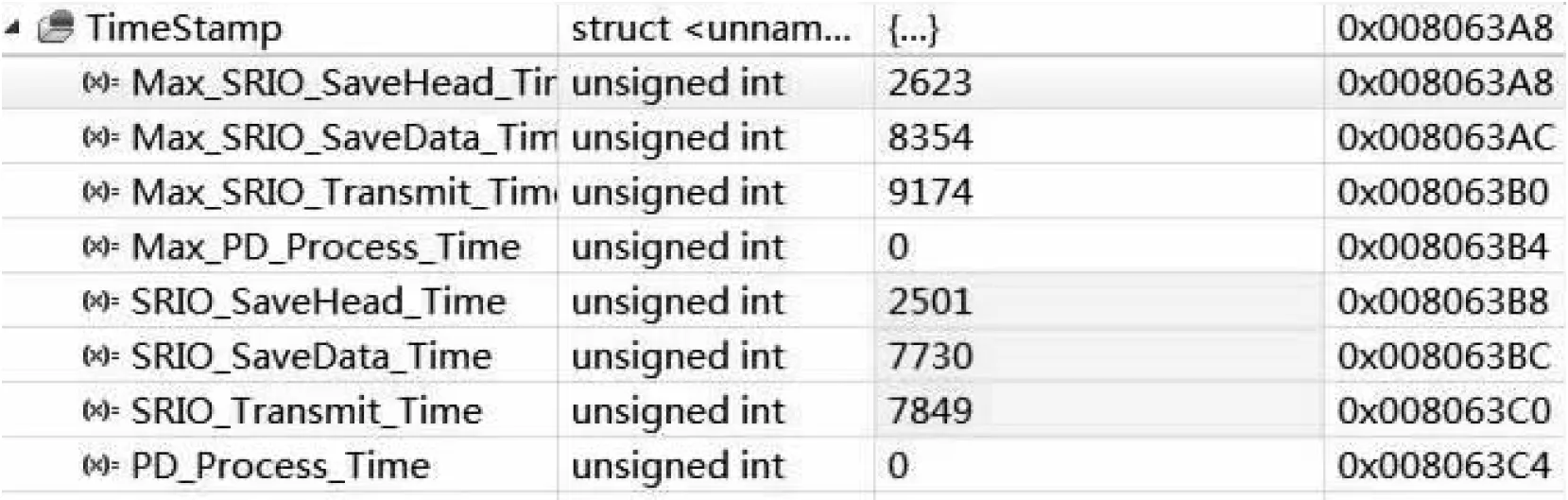
图6 DSP传输数据时间统计
3.3 计算时间分析
DSP的单个从核处理一个有效和波束的检测,实测单个波束检测运行时间如图7所示:单位为ns,恒虚警采用单元平均选大恒虚警时整个检测最大处理时间Max_PD_Process_Time为629.053μs。DSP多核并行计算5个和波束的目标检测,计算时间远小于一个滑窗CPI时间,满足系统实时性要求。
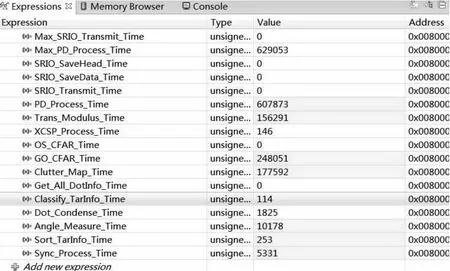
图7 单个波束DSP单核检测时间统计
由于整个检测处理过程中采用乒乓处理,每个节点最大处理时间都是一个滑窗CPI时间,所以整个信号处理过程流水会延时多个滑窗CPI时间。
4 结束语
合理的系统架构设计是雷达信号处理设计中优先考虑的问题。硬件平台设计冗余会导致系统资源浪费,成本增加。硬件平台设计小于算法实现要求时会导致部分功能不能实现,设计反复,增大了设计时间,拖延了项目进度。软件算法在已有的硬件平台上实现时如果没有规划好算法和数据流分配,会导致设计复杂,通信交互繁琐,资源竞争等问题。本文根据系统参数估算出所需的硬件资源,选择合适的硬件平台,在硬件平台上合理分配算法,结合硬件,重点讨论了多核DSP在并行运算情况下软件架构设计的相关问题。根据多核DSP硬件结构特点合理安排算法流程与资源分配,避免核间冲突与总线冲突,发挥多核DSP的最优性能。值得一提的是文中按流水处理会延时多个CPI,在后续目标点的方位测角时需要与码盘信息修正对应。系统架构设计中的其它相关问题还需在以后的工程应用中进一步探索。
