基于优化Gmapping 算法的巷道喷浆机器人建图研究
2023-07-14韩彦峰李君君肖科
韩彦峰,李君君,肖科
(重庆大学 机械与运载工程学院,重庆 400030)
煤矿的开采需要挖掘大量的巷道,这些巷道 为煤矿挖掘和煤炭运输提供了通道,巷道喷浆支护是保障巷道正常使用和安全的最有效的措施之一.随着国家煤矿工业智能化进程的推进,煤矿巷道喷浆机器人将是实现无人自主喷浆作业最好的方法之一[1].
由于环境因素的限制,矿山车辆的定位无法利用全球卫星定位系统来实现.早期煤矿多采用铺设轨道来实现车辆的移动与定位,但这种方式成本高且在巷道施工早期无法实现[2],这就要求喷浆机器人要在未知的环境中,通过自身的移动和传感器的数据来确定自己的位置同时构建环境的地图,即实现同步定位与地图构建技术[3].传统的定位与建图问题是通过机器人的运动数学模型来进行推导的,由于无法考虑传感器的测量误差、电机控制精度以及计算过程中的近似计算误差等,定位效果很差[4].考虑到机器人中的不确定性因素,Gustafsson 等[5]在概率论与数理统计的框架下对机器人定位与建图问题进行了研究,将同时定位与地图构建(Simultaneous Localization and Mapping,SLAM)问题转换成状态估计问题[6].随后许多学者利用卡尔曼滤波、扩展卡尔曼滤波等方法来进行求解,但基于扩展卡尔曼滤波的SLAM 算法计算复杂度大、精度不高[7].Kelly等[8]提出粒子滤波器算法(Rao-Blackwellised Particle Filter,RBPF),分别用粒子滤波器和扩展卡尔曼滤波器实现对机器人的位姿估计和环境路标点的位置估计[9].李帅鑫等[10]采用RBPF 算法构建机器人特征地图并命名为FastSLAM 算法.RBPF 采用运动模型作为建议分布,但由于激光雷达比里程计精度高,通过运动模型采样的粒子落在观测分布的区间较少[11],使得观测更新过程精度低.Li等[12]通过扫描匹配的方法直接从观测分布的区间进行采样,使得利用较少的粒子数获得了较高的精度,将改进后的算法用于构建栅格地图并应用到实体机器人中,形成经典的Gmapping算法.
喷浆机器人在煤矿巷道环境中精确定位与地图构建是完成喷浆作业的关键技术之一[13].Gmapping算法优化了RBPF算法存在的一些问题,在室内小场景中获得了较好的建图效果[14],但在煤矿巷道等大场景中长期运行时,后期粒子退化现象严重,粒子多样性大幅下降,建图精度降低,地图不能形成闭环.
针对粒子滤波后期出现粒子有效性和多样性缺失,经过多次迭代后丢失正确状态的粒子导致估计失败的问题,本文提出了分类回收重采样算法(Classification Recovery Resampling,CRR),该方法在抑制粒子退化时通过对低权重粒子进行修正回收,在最大程度上利用现有信息,保护粒子多样性.
1 Gmapping算法简介
Gmapping 算法是以RBPF 算法为核心的即时定位与地图构建算法[15],其运行步骤主要为状态预测、扫描匹配、采样、计算权重、自适应重采样、地图更新.其主要特点为:
1)通过扫描匹配采样过程,将激光信息引入建议分布,由于激光雷达一般比里程计精度更高,观测模型中位姿分布更集中,如图1 所示,其中p(X|Z)和p(X|X′,U)分别表示单独从里程计模型、里程计激光雷达联合模型中进行采样的位姿分布概率曲线,L(i)表示位姿分布区间.可以使用更少的粒子来表示位姿分布[16].

图1 位姿分布Fig.1 Pose distribution
2)通过自适应重采样来平衡权值退化与多样性贫化问题.在重要性采样结束后当权重差异程度参数Neff小于阈值时才重采样[17],即通过减少不必要的重采样来保护粒子多样性,只在权重退化严重时才进行重采样.
式中:N为粒子总数;为粒子归一化权重;i为粒子序号.Gmapping 算法优化了RBPF 算法存在的一些问题,在室内小场景中获得了较好的建图效果,但在大场景中长期运行时,累计重采样次数增加,后期粒子贫化现象依然严重.
2 分类回收重采样算法
2.1 算法的原理
粒子滤波器经过多次迭代后粒子集的重要性权值的方差会越来越大,最后权值只集中在少数粒子上,从而导致粒子集不能近似表示后验概率分布[18].在Gmapping 中采用重要性重采样(Importance Resampling,IR)来抑制粒子退化,但其是大量繁殖权值高的粒子,删除权值低的粒子,这又会导致粒子多样性缺失问题[19].为了能够更好地同时缓解这两个问题,本文提出了分类回收重采样算法,在改善粒子退化问题时尽可能保护粒子多样性,使算法在长期运行过程中能有效地表示后验概率分布.
2.1.1 粒子分类方案
重采样的本质就是多次复制权重大的粒子,淘汰权重小的粒子.在粒子集权重方差大于阈值时直接对粒子权重进行降序排序,利用平均权值=1/N将粒子集分为两类,复制权重值wit≥的粒子,对于权重值的粒子并不直接舍弃,在对低权重粒子进行修正后按总粒子数的一定比例进行回收.
2.1.2 大权重粒子复制方案
分类后的大权重粒子权重值都高于平均权值,属于较好的粒子,从该类粒子中直接复制产生Nb个新粒子,其中Nb=(1 -b)N,N为粒子总数,b为回收粒子占比.
首先统计大权重粒子总数D,计算权重值总和ns以及平均权重ar.
然后依次计算排序后的粒子复制次数ni,ni为大于或等于wi/ar的最小整数.根据各粒子的复制次数复制产生新的粒子集,若大权重粒子类都复制完毕还未达到Nb个,则再从最大权重粒子开始重新复制直到满足规定粒子数.
2.1.3 小权重粒子回收方案
在Gmapping 中每个粒子都携带了其特有的轨迹与地图,只因为每次估计的权重较低就直接删除并不合理,这样不仅损害了粒子多样性也浪费了之前步骤的信息.因此,本文提出将部分低权重粒子进行修正后回收,最大限度地保护粒子多样性与已有信息.
对于小权重粒子类的粒子,它的上一代粒子本身就是好粒子,误差影响使现在时刻的位姿估计产生了较大的偏差,权重较低,所以选取现在时刻大权重粒子为模板对其进行修正,将修正后的粒子回收进新粒子集.
小权重粒子在排序后的粒子集中编号为D+1~N-1,小权重粒子随机在大权重粒子集中选择模板,计算自身与模板之间的差距:
式中:X代表一个粒子,该粒子的位姿为x、y、θ;t为时间;i、j为粒子序号.再加入服从正态分布N(0,σ2)的扰动值ni-j,其中方差σ2根据模板的权值和自身与模板间差距计算.
修正后的粒子:
对回收的粒子再次进行扫描匹配,更新粒子轨迹权重Ws.从小权重粒子集中回收N-Nb个粒子放入新粒子中,维持粒子集总数不变,若小权重粒子数小于N-Nb,则循环回收直到满足N-Nb个.
2.2 算法的步骤
Gmapping算法的步骤为:
1)粒子根据权重降序排序并分类;
2)计算大权重粒子类的权重均值及复制次数;
3)复制Nb个大权重粒子;
4)修正回收N-Nb个小权重粒子,更新轨迹权重;
5)均分位姿权重.
分类回收重采样算法伪代码如表1所示.

表1 分类回收重采样算法伪代码Tab.1 Pseudo code of classification recovery resampling algorithm
3 仿真试验
3.1 基础性能测试
根据文献[20]研究结果,基于高斯分布新粒子的改进通用粒子滤波重采样算法(Particle Filter with the Improved Resampling,PF-IR)与现有算法相比更有优势.在相同条件下,分别采用Gmapping 中使用的重要性重采样(IR)算法、PF-IR 算法与本文提出的CRR 算法进行对比分析.分析过程中采用的系统模型状态方程为:
观测方程为:
式中:k为时间,以1 为周期进行采样取值;zk表示k时刻的系统观测值;wk-1和vk是均值为0,方差分别为Qk和Rk的高斯噪声,分别服从正态分布N(0,Qk)和N(0,Rk).
仿真参数设置:x0=0.1,Qk=5,Rk=1,采样周期dt=1,回收粒子比例b=20%,仿真粒子数N=10,仿真时间T=10 000.用均方根误差和状态估计误差标准差来评价2 种算法对模型跟踪定位的精度[21].均方根误差、状态估计误差标准差分别为:
式中:xk为状态实际值;为估计值;为误差均值;T为仿真时间.
CRR、PF-IR 与IR 算法对式(6)、式(7)组成的系统模型的状态估计结果,如图2 所示.为了清晰起见,图2 中只展示了后50 个时间点,由图2 可以看出,CRR 算法比PF-IR 算法、IR 算法更接近真实值.图3 和表2 对3 种算法的误差和运行时间进行了统计分析,结果表明,与PF-IR 算法和IR 算法相比,CRR 算法在一定程度上提高了跟踪精度.CRR 算法的均方根误差和状态估计误差标准差相比PF-IR 算法和IR 算法分别降低了20.2%、30.0%和32.3%、49.1%.CRR 运行时间相比PF-IR 算法和IR 算法分别增加了30.4%和47.6%.但单次总体重采样运行时间在1/10 000 s 数量级,机器人运动一段时间后才会进行一次重采样计算,这个时间远大于该数量级.因此,CRR 算法在提高跟踪定位精度的同时依然能保证算法的实时性.

表2 误差统计及运行时间分析Tab.2 Error statistics and running time analysis
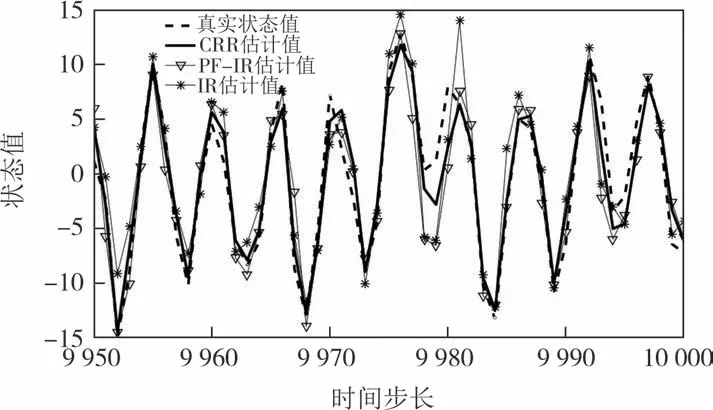
图2 CRR、PF-IR与IR算法状态估计结果Fig.2 State estimation results of CRR,PF-IR,and IR algorithms
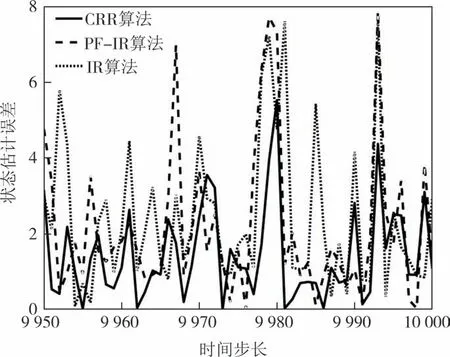
图3 CRR、PF-IR与IR算法状态估计误差对比Fig.3 Comparison of state estimation errors between CRR,PF-IR,and IR algorithms
为了验证粒子回收的必要性,去除CRR 算法中粒子回收环节进行消融试验.为了便于描述,将去除粒子回收环节后的CRR 算法称为分类重采样算法(Classified Resampling,CR).对CR 算法和CRR 算法利用上述系统的状态方程进行了跟踪定位精度对比试验,并选取后期某一时刻粒子分布状态进行了多样性对比.
CRR 与CR 算法状态估计结果如图4 所示,图5为k=9 986时粒子分布情况.由图4和图5可知,CRR算法跟踪定位精度要高于CR 算法;CR 算法的粒子大多数集中于少数状态,从而失去了粒子多样性,不利于滤波的状态估计.而CRR 在高似然区和低似然区都有一定数量的粒子分布,在一定程度上保证粒子多样性,从而提高状态估计的精度.
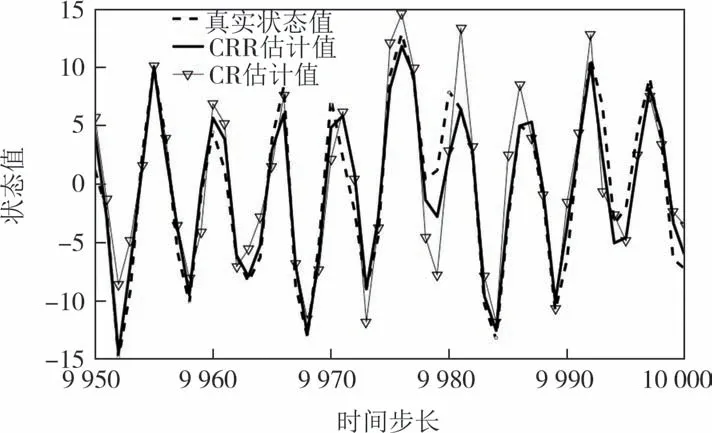
图4 CRR与CR算法状态估计结果Fig.4 CRR and CR algorithm state estimation results
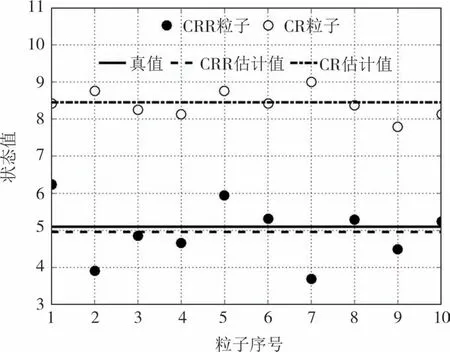
图5 k=9 986时粒子分布情况Fig.5 Particle distribution when k=9 986
3.2 地图构建测试
采用slam benchmarking*上的典型数据集ACES building(以下简称ACES)和MIT Killian Court(以下简称MIT)对算法进行测试,并利用其提供的评估工具Metric Evaluator[22]对测试结果进行定量评估.
ACES 和MIT 数据集都有典型的巷道特征.其中ACES 场景较小,整体大小为40 m × 40 m,结构简单.MIT 数据集规模较大,达到了250 m × 215 m 且结构复杂,包含多个互相形成闭环回路的长走廊,建图难度高[23].试验参数设置如表3所示.

表3 试验参数设置Tab.3 Experimental parameter setting
ACES 数据集10 个粒子的建图结果如图6 所示.机器人从A点开始,依次经过B、C、D点,再回到A点形成闭环,然后才从A点出发到达E点,再分别到达B、C、D点完成建图.可以看出使用IR 算法的Gmapping得到的地图整体形状上存在畸变,在标记1、2处存在地图重叠、分层现象,由于闭环误差较大,在3处形成了错误结构;使用PF-IR 算法的地图在整体上无明显错误,但在图中标记处闭环效果不佳,地图出现了重叠;使用CR 算法的地图一致性得不到保障,在图中标记处出现了较大程度的错位;而使用CRR 算法的地图结构正确无畸变,边界清晰、无重叠分层,很好地反映了环境真实情况.

图6 ACES数据集10个粒子的建图结果Fig.6 Mapping results for 10 particles in ACES dataset
精确的定位是构建准确地图的前提,所以定位精度的高低也能从侧面反映建图的优劣.根据数据集提供的1 279 对按时间先后排列的真实相对位姿关系,对算法的定位误差进行定量分析,如图7 所示.由图7 可知,IR 算法在序号300 处存在较大的平移误差,CR 平移误差与IR 相近;PF-IR 和CRR 算法的平移误差都有所降低,但CRR效果更好.在此次试验中旋转误差差别不大.
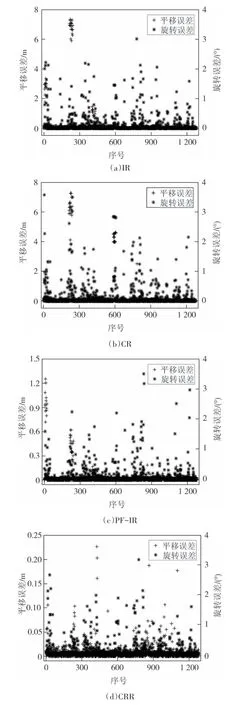
图7 ACES数据集定位误差Fig.7 Positioning error of ACES dataset
MIT 数据集60 个粒子的建图结果如图8 所示.机器人从标记点A开始,穿过标记为B的第一个回路.然后,它穿过标记为C和D的回路,完成回路E后移回标记为A和B的地方,再经过标记为F和G的两个大回路.图中矩形部分是显示地图容易出现错误的放大图.
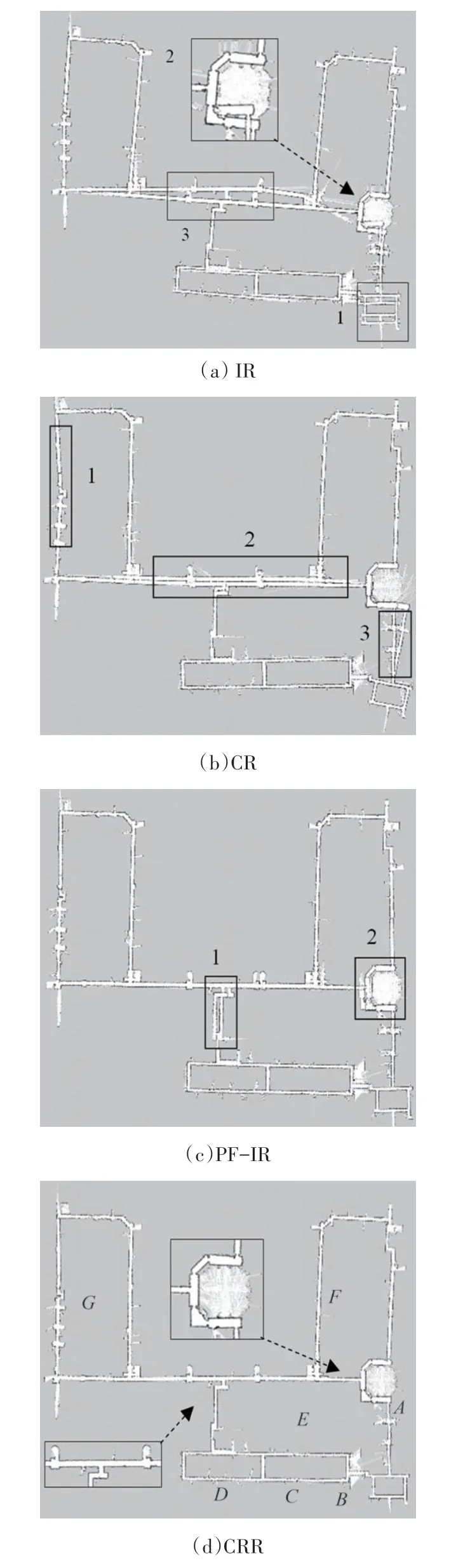
图8 MIT数据集60个粒子的建图结果Fig.8 Mapping results for 60 particles in MIT dataset
由图8 可知,使用IR 算法进行重采样的Gmapping算法的构图一致性很差,在标记点1、2处地图出现较大程度的重叠分层,在标记3 处地图结构错乱.CR 算法的效果与IR 相似,在标记1 处存在畸变,标记2、3 处形成了两处结构相同但位置不同的地图,建图未能形成闭环.PF-IR 算法较原算法效果有一定的提升,但在标记1、2 处依然存在重叠和结构等现象.使用本文算法能够在大场景获得清楚、结构正确的地图,从图8(d)放大图中能看出在易错局部也未出现分层等错误现象.
在此次试验中分别统计了各算法计算出的4 677 个定位误差,如图9 所示.由图9 可知,使用IR和CR 的Gmapping 算法定位平移误差和旋转误差都远远超过正常水平,最大误差分别达到了40 m、12°左右.使用PF-IR算法2种误差都有所降低但幅度不及CRR 算法.在此次试验中,本文算法定位误差与PF-IR 算法相比降低了一个数量级,平移误差和旋转误差始终处在较低水平.
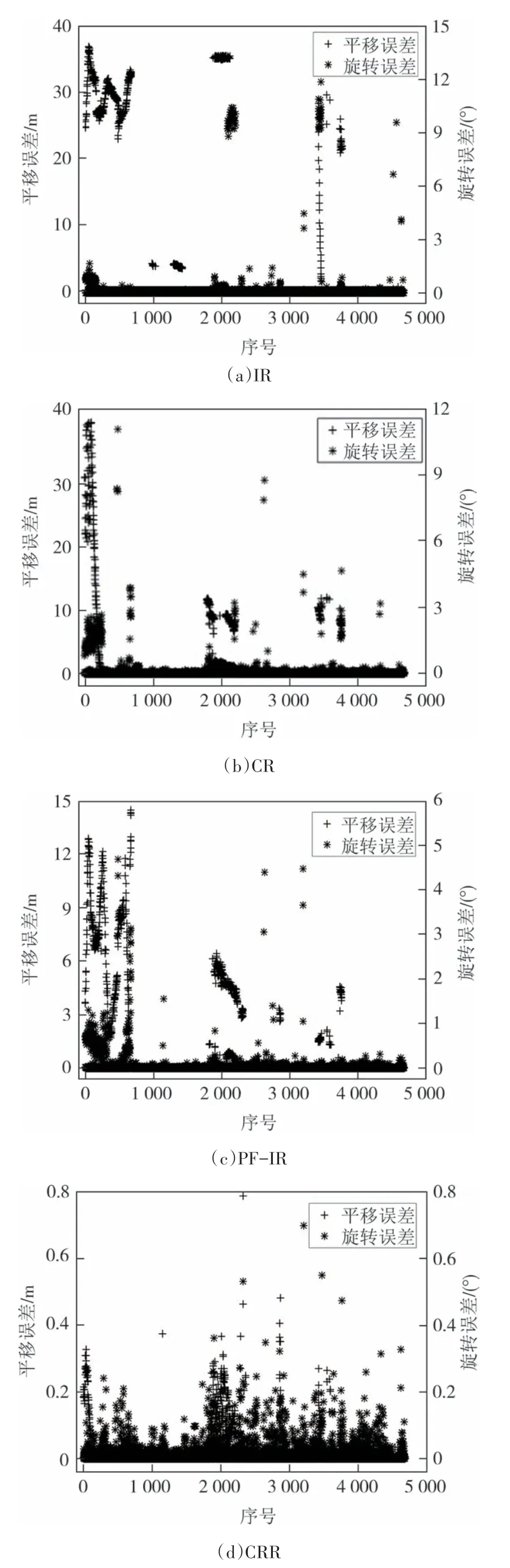
图9 MIT数据集定位误差Fig.9 Positioning error of MIT dataset
在建图后期,以位姿的x值为参考,统计了4 种算法在2 个数据集运行时的粒子分布情况,结果如图10 所示.由图10 可知,4 种算法在各自估计值处出现了不同的分布情况,由于使用IR 和CR 算法的Gmapping 区大量复制粒子,导致后期每个粒子的估计值高度相似,出现了粒子贫化现象;PF-IR 的粒子与前2 种方法相比多样性有所增加但不及CRR 算法.本文算法在复制高权重粒子时也对低权重粒子进行了修正回收,可以看出本文算法的大部分粒子也位于高似然区,但同时在低似然区也保留了一定数量的粒子,更符合粒子滤波的基本思想.
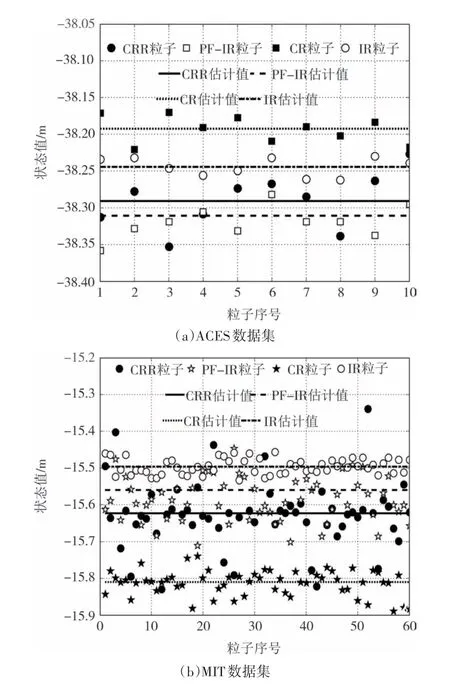
图10 粒子分布图Fig.10 Particle distribution diagram
由一维系统仿真结果可知,CRR 算法的运行时间比原算法运行时间长,所以对SLAM 的实时性进行了研究.只有当机器人走过一定的距离、旋转一定的角度或者经过一定的时间才会采样进行地图增量计算,所以存在最短采样周期.2 个数据集的建图采样周期及算法运行时间统计如表4 所示,统计了采用不同重采样算法的一次地图增量计算的最长运行时间.由表4 可知,IR 与PF-IR 算法运行时间相近,CRR 算法与IR、PF-IR 相比有所提升,但依然低于最短采样周期,在2 个数据集中CRR 运行时间分别为最短采样周期的20.36%和62.27%,能够满足建图的实时性.

表4 建图采样周期及算法运行时间统计Tab.4 Mapping sampling period and algorithm running time statistics
4 结论
为解决Gmapping 算法在巷道大场景中权值退化和粒子多样性贫化问题,本文提出了分类回收重采样算法.在粒子滤波的重采样时,针对低权重粒子并不直接删除,而是修正后按总粒子数的一定比例进行回收利用,利用现有信息,在抑制权值退化时尽量保护粒子多样性.通过试验得出了以下结论:
1)在一维系统跟踪试验中,CRR 算法相比于PF-IR、IR 算法精度分别提高了20.0%、32.3%.利用两个具有典型巷道特征的数据集ACES building、MIT Killian Court 对改进后的Gmapping 算法进行了验证,结果表明,无论在小场景还是在大场景中,相比于原始算法,都在使用相同粒子数的情况下,获得更准确、清晰的环境地图.
2)比较了3 种算法建图的定位精度和粒子分布情况.在此次试验中,本文算法的定位误差最大值比对照算法降低了一个数量级且分布更均匀;对照算法粒子分布后期高度集中在估计值附近,出现了粒子贫化现象;本文算法的粒子分布主要集中在高似然区域,同时在低似然区域保留了少量粒子,保持了较好的粒子多样性.
3)在实际建图过程中,对比了IR、PF-IR、CRR算法一次地图增量计算最大运行时间.IR 与PF-IR算法运行时间相近,CRR 算法与IR、PF-IR 相比有所提升,但依然低于最短采样周期,在2 个数据集中CRR 运行时间分别为最短采样周期的20.36%和62.27%,能够满足SLAM的实时性要求.
