基于轻量型卷积神经网络的马铃薯种薯芽眼检测算法
2023-07-14王相友吴海涛刘书玮杨笑难刘为龙
黄 杰,王相友 ,吴海涛,刘书玮,杨笑难,刘为龙
(山东理工大学农业工程与食品科学学院,淄博 255000)
0 引言
马铃薯是全球第四大粮食农作物,栽培范围遍布全世界[1-3]。全球疫情期间,欧美国家马铃薯的产量走低,马铃薯市场需求缺口扩大。2018—2019 年中国马铃薯种植面积分别为7.18×106、7.14×106、7.21×106hm2[4]。然而,马铃薯种薯播种前的切块工作,仍以人工切块为主,存在机械化程度低、人工成本高、劳动强度大等问题。为了解决这一系列问题,国内外许多研究机构、科研院所已经开始研究自动化切块设备[5-9],但大多数研究成果没有考虑芽眼的位置,直接对其进行加工,造成了极大的浪费。因此研究一种能够在切块装置上快速、准确、实时完成芽眼识别任务的算法极为重要。
国内外研究人员针对芽眼识别的研究,主要使用传统图像处理方式。李玉华等[10]提出一种基于色彩饱和度三维几何特征的马铃薯种薯芽眼识别方法,芽眼识别准确率为91.4%。孟令军[7]通过提取HSV 色彩空间中马铃薯种薯的色彩饱和度图像,获取到马铃薯芽眼位置,试验结果表明,色彩饱和度提取马铃薯芽眼可行。JI 等[11]使用K-means 聚类方法对马铃薯进行分割,提取发芽马铃薯信息,最终采用建立的模型准确率达到了84.62%。YANG 等[12]在灰度图上使用Canny 边缘检测器,获得分割掩码,完成马铃薯芽眼的检测。结果表明,该方法的检测精度为89.28%。以上研究方法都能较好地识别马铃薯芽眼,但其应用场景单一、鲁棒性差,不能在复杂环境中完成检测任务。
随着智能时代的到来,以机器学习为代表的深度学习技术被广泛应用于农业的目标识别任务中。李就好等[13]提出一种改进Faster R-CN 的田间苦瓜叶部病害检测算法,结果表明,检测苦瓜叶部病害的平均精度值为78.5%,检测时间为0.322 s。陈柯屹等[14]使用改进型Faster RCNN 识别田间棉花顶芽,试验结果表明,该方法平均检测精度值为98.1%,识别速度为10.3 帧/s。梁喜凤等[15]使用改进Mask R-CNN 模型去识别番茄侧枝修剪点,试验结果表明,修剪点平均识别准确率为82.9%,检测时间为0.319 s。LEE 等[16]使用Mask R-CNN 方法,检测马铃薯,试验结果表明平均检测精度为90.08%。XI 等[17]基于混沌优化的K-means 算法实现了马铃薯种薯芽眼的快速分割,试验结果表明,所提算法检测单幅图像时间为1.109 s。
以上使用R-CNN[18]为代表的二阶段算法,其检测精度高,但检测速度相对较慢。而以SSD[19]、YOLO[20-23]为代表的一阶段目标检测算法,相比二阶检测算法在速度上存在优势。张兆国等[24]提出了一种采用改进YOLOv4模型检测复杂环境下马铃薯的目标检测算法,其平均识别率为91.4%,识别速度为23.01 帧/s。王相友等[25]提出了一种基于改进YOLOv4 模型的马铃薯中土块石块检测方法,利用通道剪枝算法对模型进行剪枝处理,其模型存储空间为20.75 MB,检测速度为78.49 帧/s。孙俊等[26]提出一种快速精准识别棚内草莓的改进YOLOv4-Tiny模型,使用GhostNetV1 作为主干网络,并修改注意力机制,提升识别小目标的性能,其模型权重大小为4.68 MB,平均识别精度为92.62%。WANG 等[27]提出一种基于YOLO框架的新型轻量型小物体检测框架,试验结果表明,枯木检测精度为89.11%,模型权重大小为7.6 MB。ZENG等[28]提出一种基于改进YOLO 的轻量型番茄实时检测方法,试验结构表明,平均检测帧率为26.5 帧/s,检测精度达到93%。
上述以一阶段检测算法为代表的YOLO 目标检测模型,在检测速度和检测精度上具有较好的效果,同时在此框架下修改的网络结构又能降低模型权重大小,利于部署在不同的移动设备上。鉴于此,本研究在YOLOv4的基础上,提出一种基于轻量型卷积神经网络的马铃薯种薯芽眼检测模型,该目标检测模型替换改进前的CSPDarkNet-53 主干为GhostNetV2 轻量级网络,大幅度减轻模型计算量;其次修改颈部的标准卷积为深度可分离卷积,进一步降低计算量,同时丰富目标的语义信息提升小目标物体的检测能力;最后更改边界框回归损失函数为SIoU 回归损失函数,提升芽眼检测模型的收敛速度和整体检测性能,为快速、准确完成小目标物体芽眼识别任务提供基础。
1 材料与方法
1.1 数据采集
本次试验数据采集于自制试验台,同时自制的试验台也用于芽眼检测。该试验台主要由三部分组成,分别是便携式笔记本电脑、顶部和底部摄像头以及透明输送带,如图1 所示。其中便携式笔记本电脑主要用于前向推理,顶部和底部摄像头主要负责收集马铃薯和芽眼的顶部及底部数据,透明输送带主要帮助底部摄像头获取马铃薯的底部芽眼信息和传输马铃薯到达下一个工序位。

图1 数据采集试验台Fig.1 Data acquisition test bench
该试验台中的摄像头型号为WH-L2140.K214L,分辨率为1920×1 080 像素,速率为60 帧/s。在自然光照条件下拍摄马铃薯。拍摄时,底部摄像头和顶部摄像头同时工作,在同一时刻获取马铃薯底部和顶部的芽眼信息。选取200 个带有芽眼的马铃薯,品种为中暑2 号。为了更加有效地利用每个马铃薯,将每个马铃薯按照横正、竖正、横反、竖反的顺序放在试验台上进行数据采集,如图2 所示。共计采样800 次,收集1 600 张从顶部和底部拍摄的马铃薯图像。

图2 马铃薯摆放顺序Fig.2 The order of the potatoes
1.2 数据处理
首先将采集到的1 600 张原始图片使用LabelImg 工具进行标注,标注内容为马铃薯和芽眼两个类别,其中马铃薯设置为potato,芽眼设置为bud。由于检测环境相对固定,不需要增加额外的噪音提升模型的泛化能力,由此将已经标注好的每张图片使用python 脚本程序对图像进行简单的数据增强处理,包括2 次随机翻转、2 次随机旋转,共生成6 400 张带有标签的马铃薯种薯图像。最后将数据增强后的图像按照8:1:1 的比例随机分为训练集(5 120 幅)、验证集(640 幅)以及测试集(640 幅),用于之后的模型训练和测试任务。
1.3 芽眼检测算法
1.3.1 改进YOLOv4 主干网络
YOLOv4[20]主干网络主要参考CSPNet[29]网络结构,和YOLOv3 中的DarkNet[21]网络结构,形成现在的CSPDarkNet-53 主干特征提取网络,其中53 代表有53 次标准卷积操作。相比于其他YOLO 系类[22-23],YOLOv4 主干网络结构较清晰,简单明了,易于修改,为不同场景的目标检测任务提供研究基础。YOLOv6、YOLOv7 主干网络前向推理时,参数多,计算量大,不合适用于边缘设备实时检测需求和储存要求。GhostNet 模型是北京华为诺亚方舟实验室提出的一种轻量型卷积神经网络[30],其核心思想是使用Ghost 模块代替标准卷积达到降低模型计算量的目的,具体工作过程如图3 所示。
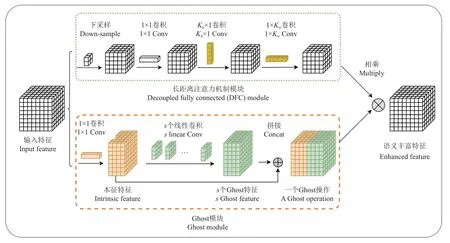
图3 Ghost 模块和长注意力机制模块Fig.3 Ghost module and decoupled fully connected module
首先,对输入特征X,使用1×1标准卷积生成少量的本征特征Y′:
式中 ⊙表示卷积操作;X∈RH·W·C表示输入特征,H、W、C分别为输入特征的长、宽和通道数;F′∈RC·K·K·C′,其中K·K表示标准卷积核的大小,这里K取1,Y′∈RH·W·C′表示输出的少量本征特征,C′<C。
其次,使用线性卷积(深度卷积)对本征特征进行特征信息提取,生成s个Ghost 特征Y′′:
最后,将本征特征与Ghost 特征拼接,产生一个与使用标准卷积通道数相同的特征图Y:
式中Y∈RH·W·C表示输出特征图(一个Ghost 模块操作),C=SC′。
经过上面3 个步骤,Ghost 模块的计算量与标准卷积之比为
由结果可知,Ghost 模块的浮点数计算量大约是标准卷积的1/s。
在GhostNetv2中作者提出一种长距离注意力机制(DF C)模块[31],用于进一步捕获空间语义信息,其前向推理过程如图3 所示。首先使用1×1标准卷积生成特征图,接着分别使用大小为Kh×1,和1×Kw的卷积核提取空间语义信息。相比普通注意力机制的复杂度O(H2W2),该方法的复杂度为O(KhHW+KwHW),最后将Ghost 模型生成的特征与使用DFC 机制生成的特征逐元素相乘得到语义更加丰富的特征,且不改变输出特征维度。
另外,GhostNetV2 中的Ghostbottleneck 是由Ghost模块和DFC 模块共同组成的一个逆残差瓶颈结构,如图4 所示。图4a 为Stride=1 时GhostNetV2bottleneck(G2-bneck)结构。该结构首先使用一个Ghost 模块和DFC模块对输入特征进行特征提取,并扩充特征信息,然后使用逐元素相乘的方式丰富语义信息,接着将其传入下一个Ghost 模块进行通道压缩,最后将原始输入特征与压缩特征进行拼接,完成一个G2-bneck 操作。

图4 GhostNetV2bottleneck(G2-bneck)模块和decoupled fully connected(DFC)模块Fig.4 GhostNetV2bottleneck(G2-bneck) module and decoupled fully connected(DFC) module
当Stride=2 时,在逐元素相乘和第二个Ghost 模块之间插入一个深度卷积模块(DW),对特征的宽高进行压缩,完成下采样操作,同时在右分支使用一个深度卷积和一个1×1 的标准卷积,确保主干分支在相同尺度下完成拼接操作。
经过试验发现[31],在获取空间语义信息时,直接使用DFC 模块将会额外增加计算成本,因此先使用下采样,得到较小特征图,再进行一系列便宜卷积操作,最后使用Sigmoid 函数将注意力值限制在(0,1)范围内,实现加速推理,如图4c 所示。
1.3.2 颈部深度可分离模块
YOLOv4 的颈部网络(PANet)使用标准卷积方式获取主干中的特征信息。此种操作会进一步增加计算成本,因此,本研究使用MobileNetV1[32]中的深度可分离卷积模块(如图5 所示)代替原先的标准卷积达到减小模型整体运算量和进一步提升小目标检测能力的目的。可分离卷积计算量为:
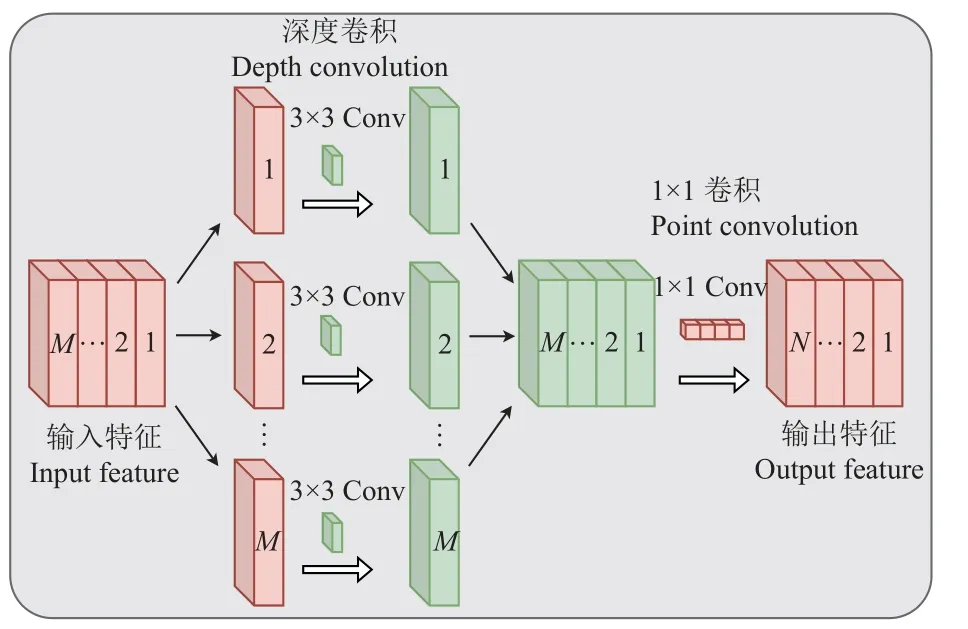
图5 深度可分离卷积计算过程Fig.5 Depthwise separable convolution calculation procedure
式中DH、DW为特征图长宽尺寸,M、N分别为特征图输入、输出通道数,DK为卷积核大小,一般取3。由此可知,深度可分离卷积的计算成本比标准卷积少8~9 倍。
1.3.3 改进后芽眼检测模型
改进的芽眼检测模型主要由部分GhostNetV2 网络结构和深度可分离卷积模块组成。如图6 所示,带有黑色虚线外框的模块和主干网络为修改位置。模型前向推理时,首先将尺寸为416 × 416 × 3 的图像在通道数上进行扩张,接着使用16 个G2-bneck 模块(如表1 所示)进行特征提取,其次提取主干G2-bneck 模块中的4、10、15 层特征信息与YOLOv4 的颈部网络相连,经过使用深度可分离卷积模块修改的特征金字塔结构(颈部网络),进一步加强改进YOLOv4 网络的特征提取能力,且减少计算量。最后从颈部分出3 个特征层,使用3 种不同尺度的检测头完成目标检测任务。

表1 改进后芽眼检测模型的主干网络Table 1 The backbone network of the improved bud eye detection model

图6 改进后芽眼检测模型Fig.6 Improved bud eye detection model
1.3.4 边界框回归损失函数
边界框回归损失函数是目标检测损失函数的重要组成部分,良好的定义将为目标检测模型带来显著的提升。YOLOv4 目标检测模型使用CIoU 作为回归损失函数(LCIoU),其定义为[33]
式中Su的值如图7 所示。

图7 真实框和预测框的交集及并集面积Fig.7 The intersection and concatenation areas of ground truth box and prediction box
除CIoU 边界框回归损失函数外,还有一系列基于加法的损失函数,如GIoU[34]、DIoU[33]、EIoU[35],都遵循以下范式:
式中 Ri为惩罚项。
以上回归损失函数都依赖于边界框回归指标的聚合,如预测框和真实框的距离、重叠区域和纵横比。而预测框在训练过程中难免存在方向不确定(“四处游荡”)的情况,导致收敛速度慢和效率低下。由此使用一种考虑了角度、距离、形状的回归损失函数(SCYLLA-IoU,SIoU[36])替换CIoU 损失函数,提升模型的收敛速度和整体检测能力。
其中,角度代价描Λ 述中心点连线(如图7 所示)与x-y轴之间的最小角度,定义如下:
当中心点连线与x轴或y轴对齐时,Λ=0;当中心点连线与x轴为45°时,Λ=1。
其中,距离代价Δ 描述中心点之间的距离,其代价与角度正相关,定义为
其中,形状代价Ω描述边界框之间的大小差异,定义为
最后,综合角度代价、距离代价、形状代价,定义回归损失函数为
1.3.5 试验平台及评价指标
本研究使用的算力资源来自中科视拓科技有限公司的线上服务器(AutoDL)。处理器(CPU)型号为AMD EPYC 7 642 48-Core Processor,运行内存容量为80 GB,固态硬盘(SDD)容量为50 GB,内核个数为24 个,显卡(GPU)型号为Nvidia GeForce RTX 3 090,显存为24 GB,系统环境为Ubuntu 20.04,搭建Python3.8 的编程语言和Pytorch1.10.0 的深度学习框架及CUDA11.3 的并行计算框架。
模型训练参数设置:单机单卡,使用VOC07+12 数据作为预训练数据集。输入尺寸为416 × 416,每批次样本数量为16,多线性进程为8,优化器为Adam(adaptive moment estimation),训练次数(epoch)为200 轮,学习率下降方式使用余弦退火cos(cosine annealing),为防止过拟合设置权重衰减为0,初始学习率为0.001,权重衰减系数为0.000 5,动量因子为0.937,使用Mosaic、Mixup 数据增强方式。
为了准确评估模型的性能,本研究采用以下指标进行性能评估:所有类别的平均准确率(mean average precision,mAP),平均精度(average precision,AP),准确率(precision,P),召回率(recall,R),F1得分,权重大小,检测时间及参数量。其中,F1表示准确率(P)和召回率(R)的调和平均数,最大值为1,最小值为0,得分越大,模型整体性能越好。参数量以卷积块大小与输出特征尺度之间的乘积为标准,权重大小为总Loss 值最小时保存的参数,检测时间为便携式笔记本电脑CPU 上的前向推理时间,其电脑型号为联想拯救者Y7000P,CPU型号为12th Gen Intel(R)Core(TM)i5-12500H,GPU型号为NVIDIA GeForce RTX 3 050 Ti Laptop。
2 结果与分析
2.1 改进模型试验结果
2.1.1 不同主干网络试验结果
本试验以改进YOLOv4 目标检测模型为基础,更换不同的主干网络,如MobileNetV1、MobileNetV2、MobileNetV3、GhostNetV1。在不改变除主干以外参数的情况下,训练目标检测模型。将得到的参数进行分析比较,验证改进目标检测模型的可行性。由表2 可知,使用GhostNetV2 模型作为YOLOv4 的主干特征提取网络时,其参数量为12.04 M,检测精度(mAP)为89.13%,检测单张图片的时间为0.148 s,芽眼和马铃薯的F1得分分别为0.80、0.99。相比改进前使用CSPDarkNet-53 的主干网络,改进后主干网络参数量约为原来的1/3,检测精度提升1.85 个百分点,检测时间减少0.279 s,芽眼得分略高于改进前主干。另外与其他轻量型主干网络Mobile-NetV1、MobileNetV2、MobileNetV3、GhostNetV1 相比,GhostNetV2 检测精度分别提升0.75、2.67、4.17、1.89个百分点,芽眼的F1值分别提升0.06、0.07、0.12、0.08。模型参数量相比MobileNetV1 减少1.65 M,相比MobileNetV2、MobileNetV3、GhostNetV1 不存在优势,但也能满足模型部署需求。检测时间与其它轻量型主干网络基本一致。

表2 不同主干网络对比Table 2 Comparison of different backbone networks
整体而言,以GhostNetV2 网络作为YOLOv4 主干特征提取网络时,其模型在检测时间、模型参数量上明显优于改进前YOLOv4 主干网络,在检测精度上也能高于其他轻量型主干网络。故选用GhostNetV2 网络作为主干,提高检测精度的同时也能满足实时检测和模型部署需求。
2.1.2 不同回归损失函数试验结果
改进前YOLOv4 目标检测模型使用CIoU 作为边界框回归损失函数,其在训练过程中有较强的拟合能力,但在训练过程中不可避免地存在预测框方向漂浮不定的情况,导致收敛速度慢,影响模型整体检测性能。由此本试验在改进后YOLOv4 目标检测模型基础上,更换多种边界框回归损失函数,从mAP、AP、P、R、F1得分的角度,分析比较不同损失函数对模型整体性能的影响。由表3 可知,SIoU 回归损失函数的检测精度相比没有使用方向代价的回归损失函数,在检测芽眼时有更高的准确率。根据试验结果可知,SIoU 的检测精度相比GIoU、CIoU、DIoU、EIoU 分别提升2.97、4.33、2.38、3.18 个百分点。由于SIoU 考虑了预测框的方向,在训练的过程中可以引导锚框移到目标框最近的轴上,减小损失的总自由度,提升模型的整体性能。图8 展示了不同回归损失函数训练时的收敛情况,相比GIoU、CIoU、DIoU、EIoU,SIoU 回归损失函数收敛速度更快,多次训练后,损失值也更低。
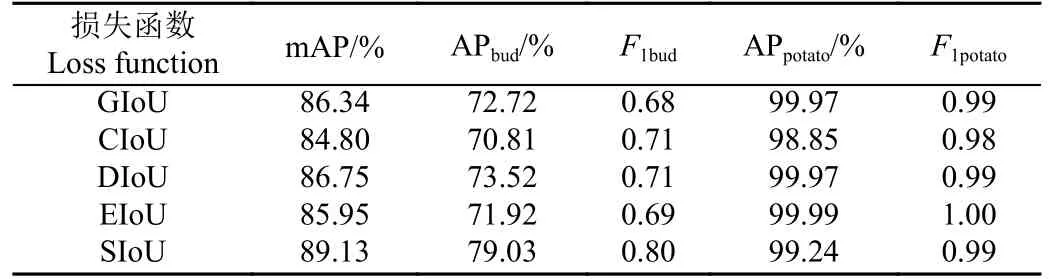
表3 不同损失函数对比Table 3 Comparison of different loss functions
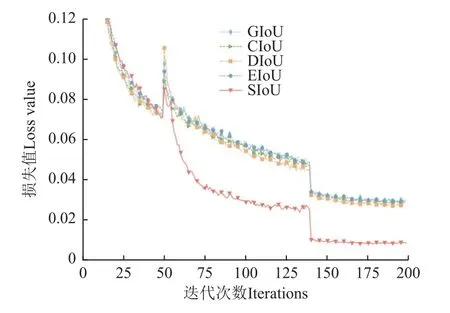
图8 不同损失函数收敛情况Fig.8 Different loss function convergence
2.1.3 YOLOv4 改进前后试验结果
改进前YOLOv4 主干特征提取网络使用CSPDarkNet-53,颈部金字塔结构使用标准卷积,回归损失函数使用CIoU。改进后YOLOv4 主干使用GhostNetV2,用于减少模型参数量,同时具备较高的检测精度,如表2 所示;颈部金字塔结构中的标准卷积替换成深度可分离卷积,进一步降低模型参数,同时也可以丰富图像语义信息,利于提取小目标信息;回归损失函数使用SIoU,提升模型整体检测性能和加快收敛速度。图9 展示了改进前和改进后YOLOv4 芽眼识别结果,从图中可以发现,在检测小目标芽眼时,改进前YOLOv4 出现较多漏检情况,而改进后YOLOv4 能够检测大部分芽眼位置。另外从表4中可以发现,改进后YOLOv4 的参数量约是改进前的1/5,检测芽眼时的精度相较改进前提升了0.56 个百分点,在笔记本电脑上的前向推理时间也从原来的0.474 s 降低至0.148 s,减少了0.326 s。
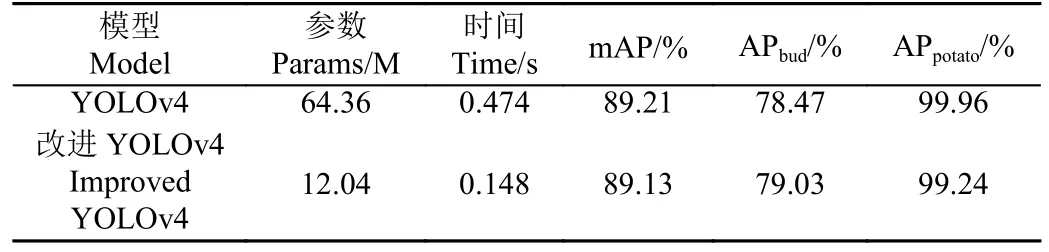
表4 改进前后模型试验结果Table 4 Test results of the model before and after improvement

图9 改进前后模型检测结果Fig.9 Model detection results before and after improvement
综上所述,改进后的目标检测模型在检测芽眼小目标物体时有较高的检测精度,同时也具有较少的推理参数,为模型部署提供研究基础。
2.2 消融试验
在模型主体网络结构中,由表2 的试验结果可以发现,使用GhostNetV2 网络结构作为改进后YOLOv4 的主干特征提取网络有较好的检测性能。本试验在不改变GhostNetV2 主干网络内部结构的基础上,比较改进前YOLOv4 颈部网络结构和改进后颈部网络使用深度可分离卷积模块之间的区别。从表5 的结果可以看出,使用深度可分离卷积模块后,模型的参数量大幅降低,约为原先的1/4 倍,更加利于移动设备或者边缘设备的部署。在预测层中,由表3 的试验结果可以看出,当使用具有角度代价的SIoU 作为回归损失函数时,其整体检测性能达到最优,同时收敛速度也相较GIoU、CIoU、DIoU、EIoU 快。本次试验结合主干特征提取网络(GhostNetV2)、颈部深度可分离卷积模块(DW)以及回归损失函数(SIoU)观测模型的权重值、平均精度值以及检测时间。从表5 中可以看出,当使用SIoU 回归损失函数后,其平均检测精度有明显提升,相较于使用CIoU 回归损失函数,提高了4.33 个百分点。

表5 颈部和预测层及主干注意力机制消融试验Table 5 Neck and prediction layer and backbone attention mechanism ablation test
另外,本试验在改进后YOLOv4 的基础上,还对主干特征提取网络GhostNetV2 中的注意力机制分布情况进行了测试,如表5 所示。当完全不使用注意力机制(A1)时,改进后YOLOv4 的平均精度值只有85.96%;当完全使用注意力机制(A2)时,其平均精度值提升至86.87%,同时模型的权重大小上升10.23 MB;当部分使用注意力机制(A3,其分布情况如表1 所示)时,其平均精度值为89.13%,相比不使用注意力机制,检测精度提升4.83个百分点。
综上所述,使用主干特征提取网络(GhostNetV2)加上深度可分离卷积模块(DW)加上回归损失函数(SIoU)加上在GhostNetV2 中部分使用注意力机制组成的芽眼检测模型,整体性能达到最优,其平均检测精度值为89.13%,检测时间为0.148 s,模型权重大小为46.40 MB。
2.3 不同目标检测算法识别试验
本试验使用自制试验台(如图1 所示)收集50 张马铃薯种薯图像作为测试集。在训练参数、训练数据集相同的情况下,将测试集数据使用SSD、Faster-RCNN、EifficientDet、CenterNet、YOLOv7、YOLOv4 及改进后YOLOv4 目标检测模型进行前向推理。观察各个检测模型的参数量、便携式笔记本电脑CPU 检测时间、芽眼F1得分和马铃薯F1得分以及mAP 值。由表6 可知,本研究改进YOLOv4 目标检测模型平均精度值(mAP)为89.13%,与SSD、Faster-RCNN、EifficientDet、CenterNet、YOLOv7 相比,分别提升23.26、27.45、10.51、18.09、2.13 个百分点,与改进前YOLOv4 相比,检测精度基本一致;在模型参数量上面,改进后检测模型相比上述6种目标检测模型,占有明显优势,仅为12.04 M;在检测时间上面,改进后模型在笔记本电脑CPU 上检测单张图像的时间为0.148 s,相比前6 种检测模型,分别减少0.007、6.754、1.891、1.745、0.422、0.326 s。

表6 不同目标检测算法芽眼识别结果对比Table 6 Comparison of bud eye recognition results of different target detection algorithms
另外,为了更加清楚地观察检测效果,分别从上述6 种目标检测算法中,随机选出5 张预测结果。如图10所示,使用SSD、YOLOv4、YOLOv7、CenterNet、EifficientDet 算法检测芽眼时,存在漏检情况,图中用箭头标出。值得注意的是CenterNet 不能识别马铃薯。使用Faster-RCNN 及改进YOLOv4 目标检测算法时,可以识别出大部分芽眼,但Faster-RCNN 使用笔记本电脑CPU检测单张图片的时间不能满足实时检测需求。综上所述,基于YOLOv4 改进的轻量型芽眼检测模型在检测时间、精度及参模型参数量和权重大小方面都具有较好的表现能力,能够满足小目标芽眼检测需求和更加利于模型部署。

图10 不同目标检测算法识别马铃薯和芽眼的结果Fig.10 The results of different object detection algorithms to identify potato and eye
3 结论
为了在试验台上快速、准确地完成芽眼识别任务,本文提出一种基于轻量型卷积神经网络的芽眼检测算法,主要结论如下:
1)使用轻量型主干网络GhostNetV2 代替YOLOv4的主干网络CSPDarkNet-53,明显减少网络参数量,约为改进前的1/3,检测时间减少0.279 s,相比CSPDarkNet-53、MobileNetV1、MobileNetV2、MobileNetV3、GhostNetV1
主干网络,平均检测精度分别高出1.85、0.75、2.67、4.17、1.89 个百分点。
2)使用SIoU 回归损失函数代替CIoU 回归损失函数,提高模型的整体检测精度,相比GIoU、CIoU、DIoU、EIoU 回归损失函数,检测精度分别高出2.97、4.33、2.38、3.18 个百分点。
3)本文所提轻量型目标检测算法,可以有效识别芽眼和马铃薯的位置,平均检测精度为89.13%,检测时间为0.148 s,相比SSD、Faster-RCNN、EifficientDet、Center-Net、YOLOv7 目标检测模型,平均精度值分别高出23.26、27.45、10.51、18.09、2.13 个百分点,检测时间分别减少0.007、6.754、1.891、1.745、0.422 s,模型参数量上占有明显优势,仅为12.04 M。由检测结果可知,改进后轻量型芽眼检测模型能够满足小目标芽眼检测需求和利于模型部署,为该类研究提供技术支撑。
