基于多尺度结构嵌入的图像修复方法研究
2023-07-07王海涌李海洋高雪娇
王海涌 李海洋 高雪娇
1(兰州交通大学电子与信息工程学院 甘肃 兰州 730070) 2(甘肃省人工智能与图形图像处理工程研究中心 甘肃 兰州 730070)
0 引 言
图像修复是一种利用扩散、纹理、机器学习等方法,将图像中残缺部分进行修复的技术。早期人们受到手工文物修复启发,Bertalmio等[1]提出BSCB(Bertalmio,Sapiro,Caselles,Ballester)模型,该算法利用图像缺失处周围信息及使用不同扩散策略例如转化为微分求解等对图像缺失处的信息进行补充。后来提出CDD (Curvature Driven Diffusions)模型,CDD[2]使用微分方程的同时建立图像能量函数,使函数最小化达到修复图像的目的。扩散的方法[3]进行图像修复,主要利用数学方法从完好区域向缺失区域扩散,对缺失区域进行修复。扩散方法存在修复后图像模糊不清,不能够对较大缺失图像进行修复。Barnes等[4]的PM(Patch Match)算法将图像修复问题转换为图像梯度与补丁之间的距离问题。修复中随机找到最佳匹配的Patch对缺失进行填充修复。由于PM修复过程中需要计算像素间的距离,因此修复方法对现有图像特征依赖度较高。扩散的方法对缺失较大、纹理结构复杂的图像修复效果较差。同时修复后图像存在纹理不佳、图像不清晰的问题。
为了提高修复图片质量,使修复后的图像纹理结构更加清晰,产生了基于纹理结构的缺失图像修复方法。Efros等[5]提出使用纹理特征修复图像细节区域的纹理合成方法。从图像完整区域中提取纹理信息,处理得到高分辨率纹理信息,从缺失边界向缺失区域使用高分辨率纹理信息进行修复。Criminisi等[6]从图像中提取不同区域块纹理信息,计算得到不同的优先顺序,使用最优的纹理块修复图像。但是纹理复杂的图像会出现不佳匹配,导致修复效果差。Simakov等[7]为了更好地定位和修复非静态的视觉数据,提出双向补丁相似性的方法。基于纹理的修复方法,虽然提高了细节区域修复的效果,图像纹理更符合视觉要求,但是也存在结构扭曲、图像模糊、修复后与原图不一致的问题。
近来国内外许多学者使用卷积神经网络和生成对抗网络将图像修复问题转化为高级和低级像素合成问题的研究。Xie等[8]提出将深度网络和稀疏编码结合起来的叠加稀疏去噪自动编码器对图像进行修复。该方法能修复小区域缺失,但是在大区域缺失修复上表现较差。Pathak等[9]将对抗网络应用在图像修复领域,使用卷积编码器解码器网络与生成对抗网络共同训练,实现图像像素一致,生成修复图像。但是该方法训练过程不稳定,存在修复区域缺失、生成不合理图像的问题。Iizuka等[10]提出使用扩张卷积的思想修复图像,利用破损图像与对应掩码,能够对不同大小的缺失区域进行修复,但是该方法训练时间较长,缺失较大时产生修复结果较差,修复网络结构比较深。Lin等[11]在全卷积网络模型中使用部分卷积对图像进行修复。但修复缺失部分易产生结构缺失、修复边缘痕迹明显、缺乏连贯性等问题。Yu等[12]引入两阶段的图像修复网络,结果粗修复细修复提高修复效果。Nazeri等[13]利用边缘结构和对抗网络进行图像修复。Xiong等[14]提出相似模型使用轮廓生成器结合生成对抗网络进行图像修复。轮廓生成器训练产生缺失区域的可能轮廓信息,然后图像生成器将生成的轮廓信息辅助缺失区域进行修复,生成最终结果。虽然多阶段模型在图像修复上表现出不错的效果,但是也存在一些问题。串联的结构易受到一阶段生成不合理结构信息影响;多阶段随着模型加深,图像结构信息容易被弱化遗忘,修复过程中无法生成恰当结构。
针对这些问题,本文在编码解码的生成对抗网络修复基础上提出一种嵌入结构信息的级联网络修复算法。生成网络采用由粗到细的两级级联方式,同时在生成阶段嵌入结构信息,帮助模型生成恰当的结构信息,提高粗修复阶段结构修复效果。细修复阶段使用多尺度的注意力机制提高图片修复效果。并使用WGAN-GP(improved Wasserstein Generative Adversarial Networks)鉴别器,提高模型训练过程的稳定性。
1 基础理论
1.1 生成对抗网络
Goodfellow等[15]提出了一个极小极大的双人游戏生成对抗网络GAN(Generative Adversarial Networks)。
GAN包含生成器、鉴别器两个模型。生成器(Generator)从样本中获取分布生成数据。鉴别器(Discriminator)将生成图像与真实图像输入用于判断真伪。GAN网络结构如图1所示。

图1 生成对抗网络模型
生成对抗的理想结果是生成模型生成出鉴别器无法判断来源的图片,生成器能以假乱真。训练过程中通过最大化D,最小化G,交替迭代更新当Pdata=Pz时达到最优,GAN的目标函数:

(1)
式中:x表示从真实数据Pdata获取采样值;从Pz先验分布中获取随机噪声的向量z;E表示期望。
从GAN提出以来出现了不同GAN变种,不同类型的GAN在某些方面具有突出的效果。为了改变原始GAN只能输入噪声的要求,实现特定条件图像生成,产生了CGAN[16](Conditional Generative Adversarial Networks)网络模型。为了使生成模型能够更好地衡量两个分布的散度,产生更优秀修复效果,WGAN[17](Wasserstein Generative Adversarial Networks)使用Wasserstein距离代替了JS距离,但是同样也面临着训练困难不易收敛、梯度消失等问题。为了解决模型难以训练的问题,同时使网络在训练的过程中更加稳定,并且能够加快收敛速度,提高生成质量,生成更好的样本。WGAN-GP[18]在WGAN的基础上通过施加梯度惩罚对1-Lipschitz进行限制,有效地解决了生成对抗网络模型崩溃的问题。WGAN-GP鉴别器损失函数为:
L(D)=Ex~Pdata[D(x)]-Ez~Pz[D(G(z))]-
λEx~Ppenalty[(‖▽xD(x)‖2-1)2]
(2)
式中:▽x表示求D(x)梯度惩罚。在Pdata和Pz连线上采样一点即为Ppenalty采样点。重复该采样操作得到x~Ppenalty集合。
1.2 注意力机制
在深度学习中已经有许多关于学习空间注意力的研究。Jaderberg等[19]在解决对象分类问题中首先提出空间变换网络的参数空间注意模块,用于分类。该模型使用定位模块,实现仿射变换到扭曲特征的预测。但是这个模型假定了一个全局变换,因此不适合补丁建模方面的注意力。Zhou等[20]使用外观匹配相同物体的不同视图,在新视图合成中选择哪些像素用以目标重建,用于生成判定。实验证明在相同物体的匹配生成中是有效的,但是在背景区域生成效果比较差。Dai等[21]使用空间注意力,在训练网络的过程中使用卷积的变种能够更好利用周边信息,当需要从背景中获取某些信息时,能够获取所需要特征信息,但是对于某些细节以及整体结构这些方法仍然具有局限性。
由于图像不同对细节样式要求各不相同,在修复的过程中选择合适大小的补丁较为困难。一般较大的补丁有助于保持样式的一致,较小的补丁有助于背景特征映射。使用不同大小的注意力解决单一场景的匹配限制,因此本文使用多尺度的注意力模块。为了实现缺失位置像素特征结构与缺失周围能够匹配。在卷积的过程中使用缺失部位和其周边信息进行匹配,并比较得到的每个像素的注意力得分,利用相应的得分重建具体周边信息的缺失处图像。
在周围图像中提取像素bx,y与缺失像素fx,y使用余弦相似性进行计算,修复过程中缺失位置和周围环境不断地进行移动在核为k的区域上下移动,并使用Softmax比较每个像素得分。对较高注意力得分区域进行反卷积重建,生成带有周边信息的缺失补丁。使用注意力能够获取周边更多有用信息,丰富修复过程中的结构渐变提高修复效果。通过不断计算得到注意力得分,选择最优补丁并反卷积出修复区域注意力特征图。公式为 :

(3)
式中:λ为常数。
将生成的特征图和原始特征图串联起来,用φin、φatt1×1、φatt3×3表示。将特征输入SENet (Squeeze Excitation Networks)模块,通过全连接网络fconv判断当前图像哪些细节是重要的,fSE输出表示为:
φout=fconv(fSE(〈φin,φatt1×1,φatt3×3〉))
(4)
2 网络模型与改进
为了进一步获取更多的特征信息,生成较为合适的图像,设计使用的网络模型包括修复网络和生成对抗网络。修复网络由使用嵌入结构信息和扩张卷积的粗修复网络组成,细修复网络使用多尺度注意力机制提高修复细节效果。修复时加入结构信息,扩大修复视野,关注局部细节信息提高修复效果,使生成的图像更加细腻真实。
2.1 生成器模型
将破损图像输入到网络中,在粗修复过程中经过卷积反卷积得到修复图像。粗修复在不提高模型复杂度的前提下为了获取更多信息使用扩张卷积扩大感受范围,同时使用共享的生成器生成相应结构信息,为图像修复反卷积过程提供可能结构提示。网络结构如图2所示。模型输入为H×W大小的彩色图像,通过多次卷积操作将输入图像大小变为H/4×W/4,反卷积得到粗修复结果。反卷积过程中嵌入多尺度结构信息,为修复图像提供先验条件,学习图像结构特征并预测可能出现的结构,通过特征合并避免不恰当特征对修复结果产生的影响。
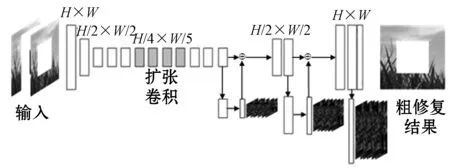
图2 粗修复模型结构
将粗修复输出作为输入,输入到细修复网络。为了提高细节修复效果,在细修复中使用多尺度文注意力机制获取周边有用信息提高修复效果。为了引入注意力模块,在细节修复的过程中使用两个并行编码结构:上层的编码器使用多尺度注意力机制学习输入图像待修复区域周边细节信息,如纹理、色彩信息。下层编码器利用扩张卷积学习破损区域的特征信息。最后将两个编码器汇集到单个解码器进行反卷积操作输出细修复结果。细修复网络结构模型如图3所示。

图3 细修复模型结构
2.2 鉴别器模型
生成对抗网络在最小化损失函数的过程中生成结果,利用鉴别器判断生成结果的真假。在对抗训练的过程中不断反馈调节,提升生成器生成效果。单鉴别器生成对抗模型虽然能够修复图像,但是也存在生成图像效果差、与原始图像不一致、模型不稳定、训练难以收敛的问题。针对这些问题本文算法在鉴别过程中使用局部与全局鉴别器,双鉴别器判别模型。局部与全局鉴别器用于判断图像的局部与整体是生成的还是真实的,并通过不断的对抗训练提高局部全局鉴别器的判别能力,生成最优的判别模型,提高图像修复效果。鉴别模型结构如图4所示。
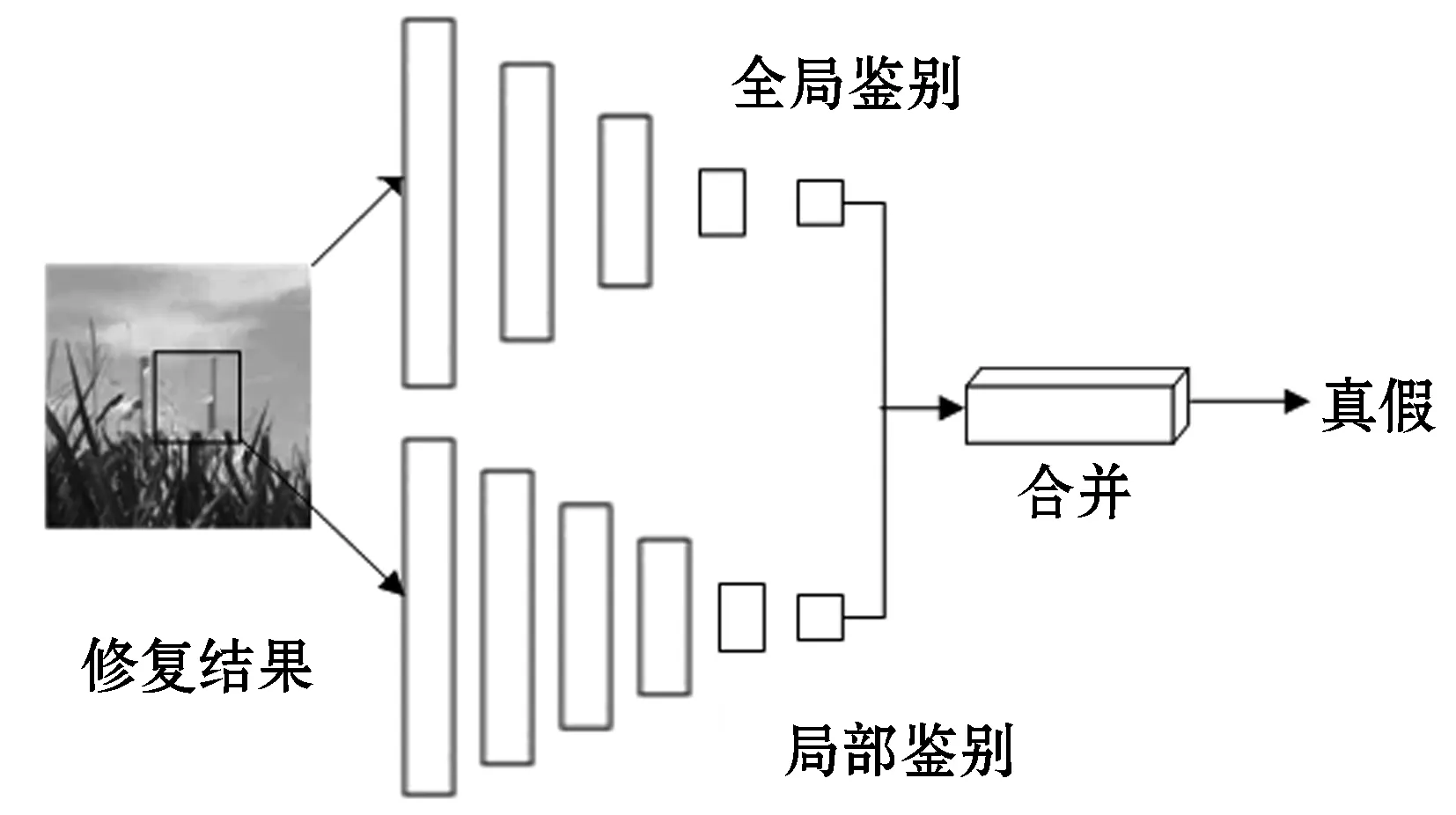
图4 鉴别器模型结构
2.3 损失函数
为了使修复模型更加稳定易于收敛,提高修复图片质量。模型损失函数由修复过程中的结构损失、重构损失和鉴别过程中对抗损失构成。在粗修复细修复过程中,生成图像与真实图像之间使用pixel-wiseL1损失。
L1=Ex∈Pdata,z∈pinput‖x-G(z)‖1
(5)
式中:x为真实数据;z为噪声数据;G(z)为生成图像。为了找到所需要的结构使用金字塔结构损失来获取结构信息,并将结构信息融合到粗修复网络中。
(6)
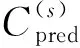
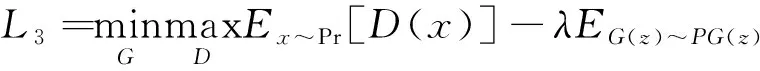
(7)
式中:Pr为真实数据;z为生成器输入;G(z)表示生成器生成数据;m=0表示缺少像素,其他位置时m=1;实验中设置λ=10;⊙表示哈达玛积。
综上,整个模型损失函数为:
L=λ1L1+λ2L2+λ3L3
(8)
在实验中不断调测试节超参数,其中λ1、λ2、λ3为不同损失因子。
3 实 验
3.1 数据集及实验环境
实验基于ubuntu 18.04下TensorFlow 1.14.0 框架、CUDNN V10.0、CUDA V10.0、单块GeForce RTX 2080Ti GPU 的环境训练网络模型。网络迭代训练1 000 000次,设置batchsize为16。实验在Places2数据集上验证模型效果,并在相同环境下测试其他方法,将修复结果进行对比。Places2是一个含有不同环境的多场景数据集,能够用在场景识别、图像描述等领域。训练前将Places2数据集中2 500 000幅256×256图片使用Places2 flist进行划分,生成训练集和验证集文件。其中训练集包含1 750 000幅图片,验证集包含750 000幅图片。实验中设置缺失最大尺寸为128×128,训练时对输入模型场景图片随机生成缺失区域,将缺失区域与原图合成缺失图像作为输入,输入到网络中进行训练。
3.2 实验结果与分析
为了验证本文算法在图像修复上的有效性,将本文方法与其他三种深度学习图像修复方法进行比较。首先验证本文修复模型的效果,对不同类型不同缺失大小图像进行修复;其次在本文实验环境下重现其他修复方法,采用相同的实验数据与步骤对比不同方法修复效果;最后使用客观评价标准对各个方法进行比较,验证本文方法有效性。为了展示本文修复算法效果,选择在不同缺失大小、不同缺失类型的缺失图像使用本文方法进行修复,修复效果如图5所示。

图5 本文模型修复结果
图5展示了Places2中选择的四个不同场景在不同区域、不同破损面积、不同破损类型的破损图像修复效果。其中:第1列为原始图像;第2列为不规则缺失图像;第3列为修复后图像,可以看出不规则边界区域能够较好地拟合整体结构;第4列为规则破损场景图像;第5列为修复结果,可以看出修复图像在整体的结构、图像完整性上有突出表现。
为了验证本文方法比其他修复方法更有效,对比的过程中重现GL[10]、 CA[12]和EG[13]等方法。采用相同的实验环境、训练数据、测试数据,对同一幅破损图像进行修复。对比修复结果比较各个修复算法的差异,如图6所示。

图6 本文模型与其他模型对比
图6是不同破损图像使用本文算法与GL、CA和EG算法的修复效果比较。其中:第1列为原图;第2列表示要修复的图像;第3列表示GL算法修复结果;第4列表示CA算法修复结果;第5列表示EG算法修复结果;第6列表示本文算法修复结果。可以看出GL不能很好地拟合边界导致边界较为明显,缺失区域内部色彩差异较为明显,修复效果比较差。CA修复填补区域出现颜色淡化与原图差别较大。EG修复结果整体较好但是还会出现缺失部位修复细节不够好。具体细节比较如图7所示。

图7 EG与本文模型对比
在不同缺失图像修复结果对比中可以看出本文方法在修复边界区域时能够与边界较好的拟合。缺失区域内部纹理结构和色彩与原图更加接近。一方面嵌入结构信息的细节修复能学习图像结构信息,提高纹理结构的一致性,同时扩张卷积获取更大的视野得到更多的边界信息;另一方面在细修复的过程中使用多尺度注意力机制。修复结果整体结构连贯同时生成的图片质量较高与原图十分接近。
为了能够更好验证本文方法的有效性,本文使用客观的评价方法对不同修复算法修复结果进行比较。图像在经过修复后会出现某些部位与原始图像不同,为了衡量修复后图像质量,使用峰值信噪比 (Peak Signal to Noise Ratio,PSNR)表示对修复结果的满意程度。PSNR越大代表失真越少,表明图像越真实,修复效果越好。SSIM是对原图与修复图像从结构、亮度、对比度三方面进行比较。SSIM数值在0至1范围,大小反映图像结构完整性,数值越大结构越优秀,修复图与原图越相似。平均L1 loss 和PSNR用于在像素级测量两幅图像之间的相似性。本文对不同的修复方法在PSNR、 SSIM和平均L1 loss进行比较,对比结果如表1所示。

表1 结构相似性对比
表1展示了本文算法与其他修复算法PSNR、 SSIM和Mean L1的对比结果。通过粗修复细修复中带有多尺度结构信息及扩展卷积的修复网络,不仅学习图像结构特征,而且扩大修复过程感受视野,获取更多的图像信息;在修复过程中使用多尺度注意力机制关注缺失区域细节信息,使生成的缺失区域图像更加真实连贯。对比结果显示本文修复方法在峰值信噪比、结构相似性、平均L1损失上分别有不同提升。本文方法了提高修复质量,修复图片更加细腻,与真实图片更加接近。
4 结 语
本文针对当前深度学习图像修复领域存在的问题,提出分阶段分步骤的图像修复方法。在修复图像过程中使用结构嵌入并结合注意力机制提高修复质量。鉴别过程中,同时使用局部与全局鉴别器进行鉴别,进一步提高模型修复图像效果,使用WGAN-GP损失提升模型收敛速度加快训练进程。最后对不同的深度学习修复方法在相同数据集上进行比较,并通过主客观评价方法验证本文算法的优越性。
