IoT设备程序同源性智能检测技术综述
2023-07-06孔凯薇霍冬冬苏东楠
孔凯薇, 霍冬冬, 苏东楠, 徐 震
1北京计算机技术及应用研究所 北京 中国 100039
2中国科学院信息工程研究所 北京 中国 100093
3中国科学院大学 网络空间安全学院 北京 中国 100049
1 前言
随着5G技术的蓬勃发展, 物联网(Internet of Things, IoT)设备以其轻量化、易使用、广互联的特性, 已经被广泛应用于以智慧医疗、智慧物流、智慧工厂为代表的人类生产生活中的各个方面, 起到了越来越重要的作用[1-3]。根据有关机构的预测, 至2025年全球IoT设备的总量将达到300亿台, 并将继续呈爆炸性增长趋势[4]。然而, IoT设备的大规模部署也使得其一旦发生安全问题则容易形成群体性安全事件, 因而引来了越来越多的关注。有研究指出, 仅2021年上半年, 针对IoT设备的攻击就高达15亿次[5],涵盖敏感信息窃取[6]、构筑僵尸网络[7]以及远程恶意控制[8]等, 为他们的深度扩展应用造成了极大的负面影响。
分析IoT设备易于引发群体性安全问题的原因,一部分在于轻量化的软硬件资源条件[9]使他们自身的安全性变得越发脆弱。而另一个不容忽视的事实,则是这些受到攻击的设备大都具备相似的漏洞。为了缩短开发周期, IoT设备通常会集成不同种类的第三方库[10], 同一个组织、开发者开发也习惯使用过去自己使用过的模块。若这些复用的程序中存在可以被攻击者利用的漏洞, 那么数以万计的IoT设备将面临被攻击的危险。
许多学者都注意到了漏洞重用对IoT设备带来的严重安全威胁。例如, Cui等[11]报告了用于升级的许多固件中普遍存在由包含某些第三方库而引入的已知漏洞; 高通公司基带芯片固件漏洞(CVE-2020-11292)则间接使得全球30%智能手机的安全性受到威胁[12]。攻击同一类漏洞的恶意代码经过加壳、混淆以及架构适配后便可被轻易移植到大量的目标设备上[13-14], 使得引发大规模IoT设备攻击的成本变得越来越低, 如MIRAI以及其变种[15]。因此, 分析目标设备以获取重要程序代码的出处和来源, 将他们与已知漏洞或恶意开发者进行对应, 可指导安全人员采取更为针对性的安全加固措施, 将是提升IoT设备整体安全能力的重要手段。
同源性检测是一种对程序代码或二进制文件进行来源分析判定的技术[16-17]。通过分析重要逻辑的表现形式以及关键功能的使用方式, 该技术可以为目标程序与待匹配对象建立起关联和映射关系, 并以此确定程序的安全性。为了对不同程序的特征进行准确刻画, 传统分析方案不得不结合大量的人工干预优化, 在面对海量IoT设备程序分析时方案的实用性不高。而随着以机器学习、深度学习为代表的智能检测技术兴起, 使得其不仅支持自动化地从大量程序特征中高效获取专属于某一类程序的表示,同时在面对被混淆化的程序时仍具备较好的分析稳定性。这些因素都使得基于智能检测技术的同源性分析方案具备更好的实用性。
然而, 由于IoT设备架构以及程序的特殊性[18-19],为了达到足够的检测精度, 该项技术的应用仍面临下述问题。第一, IoT设备的部署规模庞大, 涉及到的程序软件繁多, 如何从海量设备程序中挖掘出程序的特点以提升同源性分析的效率是需要解决的难点;第二, IoT设备运行所需的基础硬件支撑环境尚未形成统一的标准共识, 架构的多样性对分析方案的跨平台适配性提出挑战[20]; 第三, IoT设备程序的获取、标记以及关键信息提取都是同源性分析顺利实施的前提。
虽然已经有研究者对程序同源性分析技术进行了梳理, 然而当前还缺乏针对IoT设备程序进行智能检测的系统性总结。孙等[21]将同源性分析技术从静态分析和动态分析角度进行了检测能力的对比总结;Haq 等[22]面向二进制文件相似性检测技术, 从应用场景、方案使用、方案实现以及其效果等方面进行总结; Kalgutkar等[23]对代码的作者归属技术进行了综述并对其涉及到的典型特征以及归属方案进行了总结。然而, 这些工作都未对IoT设备程序同源性分析进行关注。当前在该领域还缺乏结合智能检测的同源性分析技术在IoT设备上应用的系统性总结归纳。
因此, 本文将围绕IoT固件的同源性智能检测技术, 在分析和总结国内外优秀的研究成果的同时,对这些研究的效果进行评价。具体而言, 第2章将对一些背景知识, 包含IoT设备程序分类、同源性检测技术以及本文涉及到的研究成果进行整体介绍; 第3章~第5章将对IoT设备程序同源性智能检测技术成果进行介绍, 包括所使用的相关数据集以及在此基础上面向两类同源性检测目标的检测技术; 第6章针对技术现状提出了一些研究建议; 第7章对全文进行总结。
2 IoT程序与同源性检测
2.1 IoT设备程序分类
IoT设备程序的部署方式与X86系统不同, 每一个设备通常仅支持部署一个软件包, 该软件包中将集成所有运行逻辑和设备驱动代码。这类程序与通用PC等桌面计算机系统应用有以下的区别: 1)IoT设备程序应用逻辑通常可以直接通过与底层的硬件进行交互, 而通用系统的软件通常需要中间件的支持; 2)IoT设备程序在部署时一般存储在设备的Flash、ROM等非易失性存储器当中, 并被分配物理地址空间, 在执行时将会被处理器的指令寄存器直接寻址, 而通用系统的软件需要被映射到相应的虚拟内存空间后才可以被执行; 3)IoT设备程序在编译后会根据系统需求生成涵盖blob、img等多种格式的输出文件, 较通用系统的软件格式更为丰富。
在IoT设备程序分类方面, 当前已经有研究者[24]根据是否搭载操作系统将其进行分类: (1) 裸机系统程序(类别I), 这种程序不需要搭载操作系统, 通常使用C语言进行编程, 可通过直接控制物理内存的方式实现与硬件的交互, 硬件设备的软硬件能力较差; (2)基于实时操作系统(Real-Time Operation System, RTOS)的程序(类别II), 这种程序开始配合简单的微内核进行工作。虽然仍以操作物理内存为基础,但程序已经可以通过RTOS提供的硬件抽象层与底层硬件交互, 具备了模块化系统的雏形。此外, 系统在设计上重点关注中断和任务调度能力, 因此可以快速响应需求。典型的RTOS有ROS2[25]、uCOS[26]以及Contiki[27]等, 他们常搭载C/C++编写的程序; (3)基于嵌入式操作系统的程序(类别III), 基于这种程序的设备软硬件能力较强, 通常搭载Linux等系统辅助进行业务处理, 可利用内存管理单元(MMU)以实现物理-虚拟地址的映射, 具备良好的多任务处理以及资源管理能力, 可支持基于多种高级语言(如Python、Java、C++)的程序运行。
根据实际应用场景中对软件逻辑复杂程度以及处理效率的需求, 设备所搭程序(类别I/II/III)类型也将会出现差异。同时, 针对不同使用环境所开发的IoT设备程序, 其分析的关注点以及工作量也会出现些许差异。例如, 对于类别I的程序来说, 其代码交互逻辑相对直接, 所需的代码量较少, 因而同源性分析的工作量和复杂度将在一定程度上得到缓解; 而对于类别III程序而言, 软件逻辑的复杂度也会得到显著提升, 诸如类的继承嵌套、各种新编程方法的使用, 都会使得程序的分析工作变得更为繁琐, 同时也加大了同源性判定的挑战。不同类型程序的特点以及其对同源性分析的可能影响如表1所示。

表1 IoT设备程序分类Table 1 IoT Program Classification
2.2 同源性分析技术
2.2.1 IoT设备程序同源性智能检测流程
概括上来说, 典型的IoT设备程序的同源性智能检测技术包含4个主要步骤, 如图1所示。

图1 IoT设备程序同源性智能分析流程Figure 1 Process of Intelligent Homology Detection for IoT Programs
样本程序获取。在对目标IoT程序进行检测前,研究者需要获取足够数量的训练样本以生成可靠的检测模型。由于并没有权威数据集支撑IoT设备同源性检测任务, 因此很多工作在提出检测方法的同时也会对数据集来源进行介绍, 并使用自有方式进行数据收集和标注。针对不同目标, 样本程序可分为固件和源码两类, 检测任务可分为对前述三类程序的检测, 与之对应的分析方法也各有不同。
特征选择。在获取样本的基础上, 需要将原本的程序进行处理, 以数个特征的形式对程序的特点进行表征。根据不同的关注点, 所需要提取可表征程序特点的特征也各不相同, 如面向指令、函数以及逻辑的特征。不仅如此, 软件(固件和源码)和硬件(不同架构)类型的区别也使得对IoT程序特征的提取需要考虑到精度的问题。例如, 对部署在不同架构IoT设备上的同一个固件程序进行特征提取, 其获得的特征有可能出现一定的偏差。
特征表示。在获得了程序对应的特征后, 需要将其转换为便于进行数学计算的特征表示。特征表示将会使各离散的特征联系起来, 以生成对训练程序更为抽象的表达。获取特征表示的方法有很多, 典型的如借助统计学方法直接表示或利用深度学习的数据挖掘能力获得深度的数学表示。
检测判定。基于所生成的特征表示, 同源性检测任务随即展开。确定两个程序是否同源即确定程序的特征表示是否相近。确定的方法可以基于机器学习模型预测, 也可基于其他特殊的相似度计算方法。
2.2.2 同源性分析模式
同源性分析可从以下两种检测目标进行分类。第一, 从功能性角度来说, 可以将目标程序(以及其内含的漏洞)归类到某一个已知漏洞家族谱系中, 即程序的相似性分析(similarity analysis)。通过将待测程序与已知比对程序(或漏洞片段)进行对比分析, 提取诸如控制流、调用图等特征的方式, 该技术可利用特征匹配的方式对程序是否存在潜在异常进行相似性判断。在匹配过程中, 归一化的距离匹配、镜像相似性分析、特殊字符匹配以及模糊哈希相关性分析等都是常见的方法。近年来, 研究人员倾向于将机器学习技术融入相似性检测的过程中来, 以此挖掘更多可以表征程序信息, 以更高效的完成检测任务。
此外, 同源性分析工作还可以从写作风格, 即原作者归属分析(authorship analysis)的角度展开。若某一个软件或第三方库被证实存在潜在漏洞, 作为开发该程序的组织机构或个人, 他们以往开发过的软件或借助这些软件功能做二次开发的软件都应被划为重点安全检测对象。不仅如此, 将程序漏洞与其开发的组织团体以及个人进行联系的方式, 也能方便其进行后续的安全事件调查溯源和漏洞修补。在进行原作者归属判断时, 基于自然语言处理的特征维度会被广泛采用。另外, 社会学相关维度, 诸如利用专家知识并结合软件签名证书、漏洞外在表现形式以及诸多环境因素(如: 模块开发者记录、开发时间、所属组织)也将被考虑在内, 以帮助研究者进行漏洞归属的联合分析定位。
经过这些年的积累和沉淀, 不断有针对程序的同源性智能分析工作被发表出来, 表2对本文中涉及到的程序同源性智能分析技术研究进行了总结, 时间跨度在2014-2022年。概括来说, 当前绝大多数相似性检测的工作都具备跨平台的性质,也都在以ARM架构为代表的IoT设备上进行了实验验证, 不过这些工作并未更进一步的对不同设备类型(即I、II和III)设备的适应情况进行进一步讨论。而对于原作者归属工作来说, X86平台应用程序因为更易于收集, 成为了众多研究的首选对象。而这些工作在针对X86平台程序作为检测验证对象的同时, 也开始关注相关工作在IoT设备上的表现。事实上, 这些研究中有一部分采用了通用的研究方法, 因此具备移植到IoT设备上的潜力。例如, 有部分研究工作专注于面向IoT设备程序的分析, 也取得了良好的效果。

表2 现有程序同源性智能分析技术总结Table 2 Recent Homology Analysis Techniques Towards IoT Firmware
2.3 后续研究安排
在后文的介绍中, 将以章节2.1和2.2为基础对IoT设备程序同源性智能检测技术展开介绍。如图2所示, 依照检测的流程, 本文将首先介绍同源性智能检测检测时涉及到的数据来源。在此基础上,本文分别从程序相似性和创作者归属分析两个角度对同源性技术进行介绍, 包括涉及到的特征描述, 特征的表示以及如何将他们应用到检测任务,之后将会对这些技术从方案特点比较以及对I、II、III型IoT设备程序的适配性进行讨论。接着, 将针对文中所述IoT设备同源性检测技术提出综合性建议。最后, 作者将会对全文进行总结。

图2 IoT设备程序同源性智能检测Figure 2 Intelligent Homology Detection for IoT Programs
3 同源性分析数据来源介绍
研究者需要采集到足够多的训练样本以支撑同源性智能检测技术理念的实施和验证。如表3所示,本章对文中介绍文献涉及到的数据来源进行了收集,并将他们以代码/软件包库、单一工具/软件包、固件镜像三大类进行介绍。

表3 本文涉及到的数据来源Table 3 Data Resources in This Paper

表4 相似性检测方案对比Table 4 Comparisons of Approaches for Similarity Analysis
3.1 代码/软件平台
一些研究会在代码/软件包库中选取若干源代码或软件包来编译生成IoT固件镜像, 或直接对这些进行源码级别的特征提取。本文介绍研究的数据来源包括Google Code Jam以及GitHub平台。其中, 谷歌全球编程挑战赛(Google Code Jam, GCJ)是谷歌主持的一项国际性的编程竞赛。该竞赛始于2003年, 主要面向解决一些算法类的问题。由于该比赛的解题形式不限制编程语言, 并且参赛者需要提交身份信息, 因此易于收集到可以用于描述创作者归属的相关源码文件。事实上, 很多研究工作都通过采集该网站提供的程序数据形成具备作者信息的程序数据集;GitHub是一个面向开源及私有软件项目的托管平台,其基于Git提供了代码托管服务, 包括为开发者或团队提供订阅、代码片段分析等功能, 帮助其高效率、高品质地进行代码编写。由于GitHub中的程序可以被方便的下载, 且数量巨大, 例如, αDiff[28]、DeepBinDiff[29]便从中选取不同数量的项目作为训练测试数据源。
3.2 单一工具/软件包
一些研究则选取单一的工具或软件包可执行文件作为实验数据的来源, 比较典型的有Busybox、OpenSSL以及cURL、Debian软件包以及GNU软件包等。其中, Busybox是一个集成了三百多个最常用Linux命令和工具的软件, 它将许多具有共性的小版本UNIX工具结合到一个可执行文件中。由于其占用的软硬件资源比其他常用工具小, 因此Busybox常用于嵌入式Linux领域, 可以用于构建根文件系统;OpenSSL提供了一组用于安全通信软件库包, 被广泛应用在互联网的服务端、客户端上, 可确保信息在网络层秘密性传输。OpenSSL可在Windows、Linux平台下使用, 是一套跨平台的软件库包; cURL是一个利用URL语法在命令行下工作的文件传输工具,它支持文件上传和下载, 是一个综合传输工具, 支持FTP、FTPS、HTTP、HTTPS等多种通信协议;Debian是目前世界最大的非商业性Linux发行版之一, 其对应的软件包中含有文档编辑、电子商务、游戏娱乐、软件开发等软件, 可通过软件包管理器或其他软件包工具进行获得。从Debian软件包库中收集软件包进行研究的工作有αDiff[28]和SAFE[30]等;GNU软件包库提供了支撑GNU操作系统运行的各类软件包, 其内部的Coreutils、Findutils、Diffutils、Binutils被文中多个文献选取用来进行相关研究。其中, Coreutils包含Linux下的ls等常用指令; Findutils包含一系列用于查找文件的程序; Diffutils是用来更新RecyclerView的工具; Binutils是GNU下的一组二进制工具集。
3.3 厂商提供的固件镜像
除了上述公共领域获取的数据信息之外, 收集不同厂商打包好的固件镜像被认为是最为行之有效的办法。例如Genius[31]就从ATT、Verizon、Linksys、D-Link、Seiki、Polycom、TRENDnet等26个供应商处收集到涵盖IP摄像头、路由器、访问点以及第三方或开源的固件镜像。在此基础上, Gemini[32]、VulSeeker[33]等方案也继续使用了这些固件镜像。在后续的章节中, 将进一步介绍这些数据如何被相关研究所使用来实现IoT设备程序的同源性分析。
4 IoT程序相似性检测技术
相似性检测的主要参考依据是判断两个软件间所能达成的功能是否一致。在应用于漏洞检测的过程中, 若待测软件的片段与某些已知漏洞形成了“相似的功能”, 则可以认为完成了漏洞相似性判断。本章将以典型的IoT固件程序分析为目标, 对相似性智能检测过程中涉及到的关键技术依次进行介绍。具体来说, 4.1节将按不同的二进制代码粒度介绍提取的可用于进行相似性检测的原始特征, 4.2节介绍面向不同二进制代码粒度生成特征表示的方法, 4.3节介绍特征表示之间相似度的计算方法。4.4节对这些方案的特点进行总结。
4.1 可用于相似性检测的特征
在进行检测前, IoT固件需要被反汇编成二进制代码, 这种代码本质上是用来描述特定体系结构的机器代码和数据的字节流。从这个原始输入开始, 研究人员使用了许多方法来提取更高层次的信息, 将这些信息作为二进制代码的原始特征。为了提升检测能力, 一些研究还会提取两种或者三种代码粒度的原始特征。本节将分别对指令、基本块、函数等三种粒度的特征进行介绍。
4.1.1 指令级特征
指令是计算机执行某种操作的基本单位, 一条指令(汇编指令)通常由操作码和操作数两部分组成。在处理时, 研究者通常将指令或令牌(指令的操作码及操作数)转化为one-hot向量, 并以此作为它们的原始特征。为了提取指令级特征, 首先需要将所有指令或令牌组成一个词汇表, 并将词汇表的大小表示为one-hot向量的维度。例如, 假设某个指令或令牌在词汇表中的序号为x, 则它的one-hot向量的第x位为1, 其余为0。在实际应用的过程中, SAFE[30]、Kimberly Redmond等人[34]、InnerEye[35]以及SimInspector[36]都将指令转化为one-hot向量来提取指令级原始特征, DeepBinDiff[29]和Asm2Vec[37]则使用令牌来转化为one-hot向量。
4.1.2 基本块级特征
基本块由程序中顺序执行的指令序列组成, 一个基本块只存在一个入口和出口。基本块通常被使用以下方式定义: 在程序执行时, 从入口语句开始,在出口语句退出, 其中不存在跳转与分叉汇合的情况。在有分支、转移语句的情况, 将会以此为分界生成不同的基本块。根据收集到的文献, 基本块级的原始特征可分为两种: 指令的特征表示的组合以及基本块属性向量。
在基于指令特征表示的组合的研究方面, 很多研究将基本块内所有指令嵌入后生成的特征表示进行组合作为原始特征。例如, SAFE[30]和InnerEye[35]中提取指令特征表示组成的序列, DeepBinDiff[29]将基本块内所有令牌的特征表示进行汇总、运算, 运算后得到的向量作为原始特征。
在基本块级的属性向量的研究方面, Genius[31]、Gemini[32]、VulSeeker[33]、VulSeeker-Pro[38]以及Luo等人[39]选取多个基本块属性, 并统计在每个基本块中每个属性对应的值, 将这些值组合成向量作为基本块级的原始特征。选取的属性包括但不限于字符串常量数量、数字常量数量、各个类型指令的数量以及调用的数量。例如, 研究中选取了字符串常量数量、数字常量数量、算术指令数量这3个基本块属性。若某一基本块内有2个字符串常量、3个数字常量、1个算术指令, 则向量[2,3,1]便是该基本块的原始特征。
4.1.3 函数级特征
函数是实现某个特定功能的基本单元, 可以被其他程序或代码引用。函数可以由多个基本块按照一定的逻辑顺序构成。在收集到的相似性检测相关文献中, 我们发现提取的函数级原始特征包括原始字节和图两大类。对于原始字节组成的函数特征,αDiff[28]直接使用二进制代码的原始字节, 以矩阵的形式作为二进制函数的原始特征。矩阵的大小为100*100, 若函数小于10000字节, 则用0补充, 若函数大于10000字节, 则舍弃多余的代码。
在以图作为原始特征的研究中, 学者们利用工具提取了各类图作为函数级的原始特征, 包括控制流图(Control Flow Graph, CFG)、数据流图(Data Flow Graph, DFG)和函数调用图。虽然研究所使用图的类别并不固定, 但是他们都不约而同使用了CFG。例如,Genius[31]、Gemini[32]、VulSeeker-Pro[38]以及SimInspector[36]选取了CFG这一种图作为原始特征, CFG因带有函数的结构信息, 所以经过嵌入可捕获函数结构信息。基于数据流的特点, DFG也可作为原始特征捕获函数行为方面的特征, 而VulSeeker[33]则结合选取了CFG和DFG两类图进行研究。DeepBinDiff[29]添加了函数调用图来丰富CFG, 这样可捕获函数结构特征和函数上下文信息。
在后续的研究工作中, 很多研究采用了图嵌入技术获取特征表示。图嵌入输入的原始特征为函数级原始特征中的图与带有基本块特征的信息(例如基本块级原始特征、基本块的特征表示)相结合。例如, Genius[31]、Gemini[32]、VulSeeker-Pro[38]、SimInspector[36]将CFG与基本块属性向量或基本块特征表示结合, 形成了属性控制流图(Attributed Control Flow Graph, ACFG);VulSeeker[33]将CFG、DFG结合, 形成语义标签控制流图(Labeled Semantic Flow Graph, LSFG), 再附加基本块属性向量组成图嵌入的原始特征; DeepBin-Diff[29]将CFG、函数调用图结合, 形成过程间控制流图(Interprocedural Control Flow Graph, ICFG), 再附加指令特征表示组合组成图嵌入的原始特征。
4.2 面向不同代码粒度的特征表示方法
在提取了程序对应的原始特征后, 需要使用适当的表示方法对这些原始特征进行处理。通过挖掘众多特征背后的关联关系的方式形成专门的特征表示, 以此支持相似性检测。由于特征表示的精细程度与相似性检测的结果的正相关性质, 因而研究者的主要精力也主要集中在设计优秀的特征表示方案。当前, 特征表示通常通过embedding技术实现, 即将从IoT程序所提取的特征表示为一个向量, 随后对向量间的差异进行分析。
4.2.1 面向指令特征表示的研究工作
IoT设备程序二进制代码被分解后, 将会形成面向多种架构的汇编语言表示。这些汇编语言的指令之后会被进行一定的处理, 以表示为one-hot向量。这些向量被嵌入Word2vec模型中进行学习, 利用嵌入后得到的信息来表示指令的语义特征。然而, 仅依靠指令嵌入得到的特征表示是不足以进行IoT固件相似性分析的。因此, 这些研究通常将获得指令特征表示作为IoT固件相似性分析的其中一个步骤, 后续再对指令特征表示进行运算、处理来分析IoT固件之间的相似性。
Word2vec是一种通过训练学习将词转化为向量的方法。该方法支持两类典型模型: skip-gram模型和CBOW模型。skip-gram模型的输入是一个中心词,输出是最可能出现在该中心词上下文的词。而CBOW模型相反, 它将一个词语的上下文作为输入,来预测这个词语本身。skip-gram模型和CBOW模型的结构如图3所示。

图3 Skip-gram模型(左)和CBOW模型(右)结构Figure 3 Skip-gram (Left) and CBOW (Right) Models
两个模型都由输入层、隐藏层和输出层组成。每个词均可表示为长度为V的one-hot向量(V代表整个词汇表的大小), 词的one-hot向量随后会被输入至输入层。隐藏层表示为一个大小为V*N的矩阵W(N为词嵌入模型后得到的向量的维度)。隐藏层可以把V维的one-hot向量映射成为最终想要得到的N维词向量(N远远小于V)。输出层的参数是一个大小为N*V的矩阵'。经过隐藏层得到的词向量与'进行矩阵计算后重新变为V维向量。通过softmax归一化,向量的每一维将是词汇表对应的词与输入的词出现在上下文中的概率。在训练过程中, 输出还需要与样本数据进行比较, 利用损失函数进行传播来优化模型。最终, 模型训练完成后将得到了矩阵W。W的每一行代表对应词汇表中这个词嵌入模型后的词向量。
在应用于指令特征表示的研究中, 作者将指令视为词汇, 代码的基本块视为句子, 并将指令转化为向量来表示指令的语义特征。由于指令中经常使用常量、地址偏移、标签和字符串, 因此会带来out-of-vocabulary问题, 解决办法是在将指令转换为one-hot向量之前, 对指令进行预处理。有研究使用以下规则对训练数据集中的指令进行预处理: (1)常量值用0替换, 减号保留; (2)字符串字面值被替换为
4.2.2 面向基本块特征表示的研究工作
当前研究对基本块特征进行了两种表示方式的探索: 一种是将指令的特征表示组成序列嵌入长短期记忆(Long Short-Term Memory, LSTM)神经网络中;一种是将4.1.3节提到的ICFG与指令特征表示组合组成原始特征嵌入DeepWalk算法中。
4.2.2.1 利用LSTM神经网络获得基本块表示
LSTM神经网络是在循环神经网络(Recurrent Neural Network, RNN)基础上进行的一种改进, 它可以解决RNN无法处理长距离依赖的问题。解决该问题的原理是LSTM设计了记忆细胞的概念, 使得LSTM具备了选择性记忆的能力, 可以选择记忆重要的信息, 过滤掉噪声信息, 减轻信息传递的负担。
LSTM基本形式是由多个相同的时间步组成的神经网络链。链的每个时间步的结构如图4所示。其中, 输入有三个:t时刻的输入et、t-1时刻的输出以及t-1时刻的记忆细胞状态。输出有两个:t时刻的输出xt和t时刻的记忆细胞状态每个时间步由遗忘门、更新门和输出门三部分组成。

图4 LSTM网络链的时间步结构Figure 4 The Repeated Module in a Standard LSTM
(1)遗忘门:遗忘门的目的是通过Sigmoid层来决定删除上一段时间细胞状态中的哪些信息, 表示为:
(2)更新门:更新门将输入到时间步中的新信息同样通过Sigmoid层来将一些无用的信息过滤掉, 用it、表示, 其中:
通过LSTM时间步的前两个部分, 记忆细胞状态被更新为
它既包含当前时间添加的信息, 也包含一些历史信息。
(3)输出门:输出门的参数o表示为:
因此时间步在t时刻最后的输出为:
在获取基本块特征表示的研究工作中, 研究者通常利用4.2.1节的方法得到基本块内所有指令的特征表示, 再将它们组成序列, 然后依次的输入到LSTM神经网络的时间步中。代入模型, 即将指令特征表示序列的第t个向量输入到t时刻的时间步中。经过传递, 每个时间步的输出都包含了之前所有输入的指令特征表示的信息。LSTM神经网络最后一个时间步的输出即可表示整个基本块的特征。
在实际的例子中, InnerEye[35]采用的LSTM神经网络模型如图5上边所示, 指令的特征表示信息不仅在神经网络中从左至右传递, 同时从下至上传递。随着指令特征表示的输入, 经过n层迭代, 神经网络累计和传递更丰富的语义信息。在最后一个指令特征表示输入并达到最后一层时, LSTM神经网络提供了整个基本块的语义特征; SimInspector[36]采用双向LSTM(BiLSTM)神经网络, 将指令特征表示的序列分别正向、逆向两次嵌入LSTM神经网络, 如图5下边所示。在经过n层迭代后, 方案将两次嵌入最终得到的输出进行拼接, 拼接结果即可表示基本块特征。

图5 LSTM神经网络模型图[35-36]Figure 5 Structure of LSTM Neural Network[35-36]
4.2.2.2 利用DeepWalk获得基本块表示
DeepWalk算法是一种在线图嵌入学习算法, 它可以将随机游走和Word2vec两种算法相结合。首先DeepWalk利用随机游走算法在图中选取一些连续的顶点, 组成一连串随机游走的序列, 将每个序列视作一个处理单元, 序列里的每个顶点视作单词。随后利用Word2vec模型训练出表示顶点的向量。
如4.1.3节所述, 研究者们利用图嵌入技术进行特征表示提取, 通常会使用图与带有基本块特征的信息相结合作为原始特征来嵌入机器学习算法或神经网络中。例如, DeepBinDiff[29]使用ICFG进行图嵌入, 它是由调用图与每个函数的控制流图相结合的一种图。嵌入的基本块特征信息为4.1.2节提到的令牌特征表示汇总。作者将进行相似性比较函数的ICFG进行合并, 然后与基本块特征信息一同输入由DeepWalk算法改编的TADW算法中。在处理过程中,基本块被表示为图的一个顶点。方案首先在ICFG中进行随机游走, 以此产生由相互连接的基本块组成的序列。随后方案将序列作为句子, 基本块作为单词,通过套用Word2vec模型, 即可生成基本块的特征表示。此时的基本块特征表示不仅包含本身的语义信息, 还包含来自ICFG的结构信息, 表示了基本块的语义与结构特征。
4.2.3 面向函数特征表示的研究工作
4.2.3.1 基于图嵌入类神经网络
很多研究将CFG与一些其他数据结合, 作为原始特征, 嵌入到神经网络中, 得到了函数的特征表示。例如, Gemini[32]、VulSeeker[33]、SimInspector[36]以及VulSeeker-Pro[38]将由structure2vec改编的神经网络进行嵌入; Genius[31]通过谱聚类, 为图生成码本,再利用映射运算, 得到函数的特征表示。
Structure2vec神经网络是一种注重顶点之间结构关系相似性的图嵌入网络。Gemini[32]、SimInspector[36]和VulSeeker-Pro[38]都是基于该网络进行了优化改编。structure2vec网络模型工作原理如图6上边所示。研究者们将二进制函数对应的ACFG表示为,〉, 其中和E分别是中的顶点和边的集合,而中的每个顶点∊以二进制函数基本块的特征描述为向量, 记作。Structure2vec神经网络可为每个顶点∊都计算一个多维特征,是通过特定于顶点的特征根据图拓扑递归聚合得到的。每个顶点处初始化为, 并在每次迭代时更新为, 如下式所示:

图6 Structure2vec神经网络模型[32-33]Figure 6 The Structure2vec Neural Network Model[32-33]
在VulSeeker[33]中使用LSFG嵌入神经网络。由于LSFG包含了二进制函数的CFG和DFG, 因此在每次迭代时,需要考虑通过控制依赖关系指向的顶点集合C(v)以及通过数据依赖关系指向的顶点集合D(v), 如图6下边所示。而在每次迭代时,将根据下面公式进行计算:
Genius[31]通过谱聚类算法对数据集中二进制代码生成的ACFG进行无监督学习, 为ACFG生成码本。在实施过程中, 所有ACFG被分为若干个集合,每个集合中包含一个质心节点。质心节点为与所在集合中所有其他ACFG的距离最小的ACFG。所有质心节点的集合构成一个码本。最后, 方案利用VLAD编码计算ACFG与码本中每一个聚类类别的相似性距离, 并以此组合作为该ACFG的特征向量,也就是二进制函数的特征表示。
4.2.3.2 利用循环类神经网络获得函数嵌入
4.2.2.1 节提到利用LSTM神经网络可以获得基本块的嵌入来表示其特征, 有的研究表示同样可以利用该神经网络得到固件镜像的特征表示。例如,Luo等人[39]将函数内基本块的属性向量作为每一个时刻的输入嵌入LSTM网络中。方案强调在不打乱所选基本块序列顺序的情况下, 以随机的方式选择固定数量的基本块。经过实验, 最终将包括t时刻在内的前5个基本块属性向量作为该时刻的输入, 通过神经网络预测出输出t+1时刻的基本块属性向量。最终, 输出隐藏的记忆细胞状态向量作为固件镜像的嵌入, 用以表示特征。
SAFE[30]方案借助双向RNN来获得函数的特征表示。RNN是由多个结构相同的循环单元组成的链式神经网络, 适合以序列类型的数据作为输入。而双向RNN的基本思想是将输入序列向前、向后输入RNN中。在实施过程中, SAFE首先通过4.2.1的方法获得函数中所有指令的特征表示, 然后组成序列输入双向RNN中。每个指令特征向量输入到双向RNN后, 得到一个大小为μ的向量。至此, 所有可组成一个具有函数语义特征的矩阵。这个矩阵经过加权和运算与降维, 可得到一个可表示函数特征的向量。
虽然取得了一定的效果, 但文献[31-33,38-39]在提取函数/固件镜像特征表示中还存在着一定的缺陷。具体来说, 它们都选择了基本块属性向量作为原始特征进行了嵌入。这些基本块属性向量中的属性是手动选择的, 存在很大的不稳定性。同一功能的这些属性在不同平台下可能会不同, 这可能会导致检测精度较低。所以另外一些研究将原始的二进制代码或者代码的特征表示等原始数据嵌入模型中, 来生成特征表示。
4.2.3.3 利用卷积神经网络获得函数嵌入
在典型方案中, αDiff[28]将二进制函数的原始字节嵌入卷积神经网络(Convolutional Neural Networks,CNN)中, 得到了函数的特征表示。作者提出的CNN由8个卷积层、8个批处理归一化层、4个最大池化层和2个全连接层组成。整个模型采用线性整流函数ReLU作为非线性激活函数。该CNN模型以大小为100×100×1的张量T作为输入, 并输出一个64维嵌入向量(即函数特征表示)。
4.2.3.4 利用词嵌入模型获得函数嵌入
在模型优化方面, Asm2Vec[37]采用的是PV-DM模型, 该模型是Word2vec模型的拓展, 它可以联合学习每个单词和每个段落的向量表示。在每一步,PV-DM模型执行一个多类预测任务。它将当前段落映射到一个基于段落ID的向量, 并将上下文中的每个单词映射到一个基于单词ID的向量。PV-DM模型可以平均这些向量, 并通过softmax分类从词汇表中预测目标词。应用于函数特征表示的提取工作中, 将指令的操作码和操作数视为单词, 将函数视为段落。当前指令的上下文与函数的映射ID即为令牌和函数的one-hot向量, 将它们作为原始特征输入PV-DM模型, 当前指令的令牌特征表示为该模型的输出。通过训练, 不仅可以学习每个令牌的特征表示, 还可以学习函数的特征表示。
4.2.4 利用Siamese架构训练模型
很多研究将Siamese架构与机器学习模型或神经网络(以下简称“嵌入模型”)结合使用来训练参数。一般地, Siamese架构包含了两个可在顶部进行连接的嵌入模型。在模型训练的过程中, 每个嵌入模型的输入对应一个IoT设备程序, 并提取原始特征作为其输入, 并输出其特征表示。Siamese架构的最终输出是两个特征表示的余弦距离。此外, 两个嵌入模型具有相同的参数集, 这使得表示结果具备相同的比照系。整个体系结构如图7所示。
为了使相关检测技术具备一定的跨平台性质,有学者们在训练样本的选择上设计方案。例如, 他们从数据集中选择一个IoT固件, 然后提取它在不同平台下的原始特征x与x1。接着, 再从数据集中随机选择另一个IoT固件并提取其原始特征x2。然后, 将以下两组信息作为训练样本: 即标签为+1的〈x,x1〉和标签为−1的〈x,x1〉。通过很多对这种形式的信息作为训练样本, 使得同一源码在不同平台下编译的IoT固件具有相似的特征表示, 从而达到跨平台相似性检测的效果。
4.3 相似性计算方法
在获得特征表示后, 便可以利用特征表示计算二进制代码之间的相似性。典型的计算方法如下:
欧氏距离及余弦角距离:Genius[31]在得到能表示二进制代码的编码特征后, 通过LSH将编码特征投影到空间中的一个点。两个二进制代码间的相似性则是通过计算欧氏距离及余弦距离这两个经典距离度量得到。
余弦距离:文献[30,32-33,36-37]以及[38]会直接通过利用余弦距离的方式计算二进制代码之间的相似性。在得到二进制代码B1、B2的嵌入φ(B1)、φ(B2)后, 通过以下公式获得相似度。
作为一个典型的实例, VulSeeker-Pro[38]在利用余弦函数进行相似性计算后, 选取了相似度最高的M个函数, 利用仿真引擎进行函数模拟, 再选取更精确的相似度排在前N的函数。
多种距离综合计算:αDiff[28]中获取了二进制代码的三种语义特征: 函数语义特征(通过4.2.3.3节的方法获得)、函数调用语义特征、模块交互语义特征。为了计算两个二进制函数Iq和Ic的相似度, 首先得到Iq和Ic的三种语义特征; 然后再分别计算Iq和Ic的三种语义特征的距离, 得到D1(Iq,Ic)、D2(Iq,Ic)和D3(Iq,Ic); 最后将这三个距离进行综合计算, 得到的结果表示Iq和Ic的相似度。
路径相似度得分:InnerEye[35]首先利用4.2.2.1节的方法获取每个基本块的特征表示; 然后, InnerEye将查询代码组件Q的CFG分解为多条路径。对于来自Q的每一条路径, InnerEye将其与来自目标程序T的多条路径进行比较并采用以基本块为序列元素的最长公共子序列动态规划算法计算路径相似度得分;最后, 通过探索多个路径对, InnerEye可共同计算一个相似度得分, 以表示查询代码组件在目标程序中被重用的可能性。
k-hop贪婪匹配算法:DeepBinDiff[29]通过4.2.2.2节的方法, 将两个被比较的二进制代码的ICFG进行合并, 得到了图中每个基本块的嵌入。之后其利用ICFG上下文信息, 根据k-hop邻居中已经匹配的基本块特征表示计算出的相似性找到匹配的基本块。
全连接神经网络:Luo等人[39]利用两个全连接层计算二进制代码之间的相似性。具体而言, 在得到两个二进制代码的特征表示后, 他们利用ReLu激活函数与最大池化策略进行处理, 将特征表示被压平成一个矢量; 接着其利用第一个全连接层的输出计算诱导距离, 再将该诱导距离送入第二个全连接层,最终输出二进制代码之间的相似性。
4.4 方案分析
4.4.1 特点分析
基于指令级特征的方案。获取指令特征表示的优点是能够最大程度地保留二进制代码的语义信息,并将指令与指令间的依赖关系提取到特征表示中。但是仅凭获取指令特征表示无法比较程序之间的相似性, 很多研究将获取指令特征表示的方法与其他技术结合来进行IoT设备程序的同源性检测。例如,Kimberly Redmond等人[34]的方案不仅能够很好的提取指令本身的语义信息, 还能容忍跨平台架构下的语法差异。该方案采用联合学习的方法, 生成了跨体系结构的指令特征表示, 使得不同平台下的同一指令通过模型的训练都能获得等价的语义信息。
基于函数级特征的方案。提取函数特征表示的方案可分为图嵌入方案[31-33,38-39]和原始字节嵌入方案[28,37]。为了实现可扩展性和高精度, 很多研究采用了图嵌入技术, 从CFG中学习到函数的特征表示。例如, Genius[31]利用无监督学习中的谱聚类算法来为数据集中的所有ACFG训练一个码本, 再通过VLAD编码生成函数的特征表示, 但是生成码本是一个非常耗时的过程, 导致系统开销过大。为了解决相似性检测效率低下的问题, 后续的研究使用神经网络将图转化为函数的特征表示。例如, Gemini[32]、VulSeeker[33]、VulSeeker-Pro[38]将图嵌入到由Structure2vec改编的深度神经网络中, 以获得更好的检测性能以及更少的模型训练时间。另外, VulSeeker[33]还额外将DFG嵌入神经网络一同进行训练, 能够获得更加准确的函数语义信息, VulSeeker-Pro[38]在后端集成了仿真引擎, 在更少的系统开销下进一步提高了相似性计算的精度。
然而, 基于图嵌入的函数特征表示获取方案会将基本块属性向量一同进行嵌入, 这些向量信息过分依赖专家的先验知识, 选取的基本块属性稍有变化就会使函数的特征表示发生极大改变, 降低了相似性检测的准确性。αDiff[28]、Asm2Vec[37]则使用了原始字节嵌入技术, 前者将代码按字节以矩阵为单位嵌入卷积神经网络中获取函数的特征表示, 后者以二进制代码令牌(操作码和操作数)为单位嵌入PV-DM模型获取函数的特征表示。但αDiff除了深度学习算法外还利用了其他技术获取函数间、模块间的语义特征来计算相似性, Asm2Vec则不支持跨平台的相似性检测。
基于指令+基本块级特征的方案。对于获取基本块的特征表示, DeepBinDiff[29]、InnerEye[35]首先获取基本块中所有指令的特征表示, 再将其进行加工后通过机器学习、深度学习得到基本块的特征表示。提取基本块的特征表示可以获得更细粒度的代码语义信息, 因为在部分代码剽窃、漏洞传播的场景中,并不是复制了整个函数的代码, 所以提取函数的特征表示来进行相似性检测过于局限。同时, 这类型的方案在获取基本块的特征表示后, 通过其他算法还可以比较函数之间的相似性。基于上面的优势, InnerEye解决了跨架构下的代码包含检测方案, Deep-BinDiff则比InnerEye具有更高的性能, 并能提取更多的代码依赖信息。
基于指令+函数级特征的方案。SAFE[30]在相似性计算之前提取了两种特征表示, 即指令特征表示、函数特征表示。首先利用word2vec模型获取函数中所有指令的特征表示, 再将其进行加工后嵌入双向RNN中, 得到函数的特征表示。SAFE与直接利用图嵌入、原始字节嵌入的方案相比, 其没有将主观的先验知识作为嵌入信息, 有更好的准确性; 同时, 仅利用机器学习、深度学习算法就可以获得能够进行相似性比较的特征表示, 无需通过另外的算法获得其他特征, 可更加高效地完成相似性检测任务。
基于指令+基本块+函数级特征的方案。SimInspector[36]是一种特殊的图嵌入方案, 该方案共提取了三种特征表示, 分别是指令特征表示、基本块特征表示、函数特征表示。SimInspector首先采用与InnerEye[35]相似的方法提取了基本块的特征表示, 然后将这些特征表示代替基本块属性向量与CFG嵌入神经网络中获得函数的特征表示。该方案与传统图嵌入方案相比, 因为没有主观先验知识信息作为嵌入, 提高了相似性检测的准确性。同时, 最终获取的函数特征表示携带了代码的结构特征。
4.4.2 适配性分析
通过对收集的文献进行总结, 如表5所示, 绝大多数研究支持跨平台的代码相似性分析任务, 其中包括X86、ARM、MIPS架构。大多数文献在实验中使用GCC或clang编译工具对数据集进行编译后, 即可进行特征的提取以及后续工作, 因此只要能够将IoT固件通过编译器转变为汇编语言则可以进行相似性检测。GCC支持多种计算机体系结构(X86、ARM、MIPS等)芯片, 同时已在多种硬件平台上进行了适配。Clang是为C、C++、Objective-C、Objective-C++设计的非通用语法解析器。文献[28]、[36]和[38]仅使用GCC作为编译工具, 预计可支持Ⅲ类设备的相似性检测。文献[31-35]使用clang作为编译工具, 预计可支持Ⅰ类、Ⅱ类、Ⅲ类设备的相似性检测。文献[29]使用C、C++程序作为训练集, 预计也可支持Ⅰ类、Ⅱ类、Ⅲ类设备的相似性检测。

表5 相似性技术适配性Table 5 Applicability of Similarity Analysis Technology

表6 典型词汇特征Table 6 Typical Lexical Features

表7 典型句法特征Table 7 Typical Syntactic Features

表8 典型语义特征Table 8 Typical Semantic Features

表9 文献[51]所述特征Table 9 Features in Manuscript [51]
5 程序创作者分析检测技术
程序漏洞的同源性的判定除了可借助其内部结构进行相似性检测, 还可以从作者归属权(authorship attribution)的角度出发, 通过分析目标程序代码是否为同一个原作者的方式确定出他们的同源性。在软件领域, 作者归属最初的应用是在抄袭检测, 早在上世纪80年代, Oman等[54]研究人员根据各种代码组件的分析, 开始检查作者的编程风格。在漏洞同源性检测方面, 利用该技术同样可以从创作者角度快速定位其编写的漏洞程序代码(或片段)是否部署在多个待检测软件中, 以此为安全人员从作者习惯角度检查和封堵漏洞提供不同维度的参考。本文接下来将对近几年中主流研究对作者风格特征的划分以及在这些划分基础上所使用的不同处理方法进行介绍, 并将这些工作通过表10统一进行梳理。

表10 创作者归属方案对比Table 10 Comparisons of Approaches for Authorship Attribution
5.1 特征类别
特征选择是构建待判定代码与作者联系的关键,作者的编程写作习惯通常会以某种形式被嵌入到他所编写各个程序中去。因此, 将这些写作习惯逐渐的提取出来, 将有助于找出不同作者的创作风格来完成对不同作者的描述。对于一个程序代码而言, 可以从多种角度进行特征的提取和识别。当前, 许多研究都对所能提取的特征进行了仔细的研究, 结合Kalgutkar等人[23]的报告, 本节将对文献所涉及的特征类型进行介绍。
5.1.1 词汇特征
词汇特征(Lexical Features)是指直接从源文件或二进制文件中提取的若干符号(token), 通常以特殊的字符串或表示序列组成。引入这种特征的最大原因在于有研究者认为工程师在进行不同程序代码的编写时, 更倾向于(或无意识的)使用过去惯用的词汇来命名函数、变量或是其他组件。
值得注意的是, 词汇特征通常不具备特定的语言含义, 可以认为是一种更为纯粹的符号表示。因此,这种特征的使用和提取方式都较其他特征简单而直接。例如, 为了从数学角度表征词汇特征, 研究者通常结合计数的方法予以体现。不仅如此, 不与特殊语义挂钩的特性使得针对词汇特征的提取工具不仅可以在跨语言环境的基础上进行使用, 还甚少受到程序形式(如: 固件、源码)的影响。特征提取的易于实现也使得研究者可以将精力集中在同源性分析的数据处理以及算法中, 可大幅提升效率。常见的词汇特征如表6所示。
在众多的词汇特征中, 以N个符号序列作为特征(N-gram)是一种广泛采用的特征表示形式。结合Zhang等人在文献[50]的描述,N-gram即程序中连续N个条目(Item)组成的一个序列。
条目可以用以空格分隔的任意字符串表示, 且可以是任意关键字(keywords)、操作符(operators)、语句(statement)、用户定义的标识等等。例如, 设某一行程序由p1 p2 p3….pt组成, 且以空格分隔, 则经过N-gram分隔后的序列如图8所示。此外, N-gram语句分隔方法的步长也可以根据需要进行修改, 以应对不同的研究需求。

图8 N-gram策略示例Figure 8 Example of N-gram strategy
5.1.2 句法特征
句法特征(Syntactic Features)是在词汇特征基础上的一轮语义化改进。这种特征主要用于描述词汇中的各个token符号在句子中到底是如何被程序原作者组织和使用的。将这些信息作为特征的原因在于绝大多数的研究者假设工程师都有自己难以舍弃的写作习惯和方式方法, 例如更喜欢使用特殊的判断句式(如: 用switch-case替代if-else)。这种特征的表示同样可以借助于统计方法来映射作者习惯。由于句法特征难以受到函数/变量重命名等方式的影响,因此从某种程度上来说, 它比词汇特征有着更好的稳定性, 这使得其对于作者归属描绘更加具备可靠性。常见的句法特征如表7所示。
一种典型的句法特征将通过使用抽象语法树(Abstract Syntax Tree, AST)技术进行实现。文献[35]和[36]都对这种类型的特征进行了较为详细的介绍。具体来说, AST将程序代码表征为了一种树结构。程序中的各个组成成分, 例如数学操作以及变量的定义, 都会作为一个个节点(Node)被映射到树上。
典型的以fooo函数构建的AST如图9所示, 操作符(=、||)、函数调用以及if-else-return语句等都会被表征为不同类型的节点进行映射。同时, 这些节点将会根据函数实际的语句用线连接起来, 形成一种相互的关联关系。根据图9所示, 使用AST对程序进行表示的方法使得fooo函数中的各组件都被映射到了树的不同节点上, 这使得这种树能够更精确地刻画程序与所包含的组件、以及组件与组件之间的关系, 而不会被程序的布局以及注释等词汇特征所影响。

图9 fooo函数的AST构建示例Figure 9 Example of AST for Function Fooo
5.1.3 语义特征
语义特征(Semantic Features)关注代码逻辑, 旨在从逻辑控制流的角度去诠释程序运行表征的具体含义。这种特征得以使用的原因在于研究者认为作者在进行编程时, 通常会使用相似的思路去解决编程过程中遇到的问题, 这将使得其使用的代码逻辑具备较高的同质性。由于语义特征关注程序执行的运行逻辑, 因此其与待分析程序的语言形式(汇编、C), 函数/变量的名称以及布局等信息都没有关系。具体来说, 句法特征中的(if-else与switch case)理所当然被认为是不同的表述, 但是在语义特征中, 他们都表示一种选择性的语句。语义特征很好的规避了不同编程语言带来的分析挑战, 因为理论上来说作者的编程逻辑在不同语言上也应该保持一定的一致性。表8展示了语义特征所关注的典型特征。
描述语义特征的一种典型实例就是程序的控制流图(Control Flow Graph, CFG), 它主要用于表示在某一个程序执行路径中, 代码、分支语句的执行顺序。控制流图通常以有向图的形式出现, 包含顶点(vertex)和边(edge)两种成分。对于节点来说, 其通常是由某一条语句组成, 语句的粒度可以是一条指令,一个函数等; 而对于边来说, 其用于表征节点间相互调用的顺序。而数据流图(Data Flow Graph, DFG)与控制流图所包含的组分(顶点、边)相似, 但其表征了某一个数据在不同结构间的传递情况, 是一种表示数据之间依赖关系的非循环图。因此, 数据流图中顶点通常由一个操作码(opcode operation)组成, 而边指以一个操作码A作为输入被另一个操作码B使用的过程, 也可以表示被操作码A所处理的数据DataA被操作码B使用的过程, 记为A->B。
5.1.4 其他特征
除了上述从程序内容中提取的表征作者写作风格与习惯的相关特征外, 程序编写时其他相关的外部因素也同样可以用作判定原作者归属的重要因素。例如, 作者生物特征(Biographical Features)泛指通过作者的一些社会学属性去认定作者身份, 该特征通常可以作为作者归属的一个额外附加的维度进行考虑。引入他们的主要原因在于每一个软件的作者都是社会的一份子, 他可能从属于某一个机构,一个组织, 或来自于某一个特殊的地区, 有研究者认为这些与出身相关的信息也将会对代码的编写风格产生影响。根据Bayrami等人的研究[40], 典型的传记特征有作者所属地区(Region)、性别(Gender)以及编写程序时使用的特殊作者标识(Handle)等。其他的,还有程序编译时使用的编译器优化程度特征、程序配置文件特征等。
5.2 特征属性的常用表示方式
5.2.1 TF-IDF表示
词频-逆文本频率指数(Term Frequency-Inverse Document Frequency, TF-IDF)是一个广为人知的文本数据挖掘方法。该技术基于的主要观点在于某一个/或一组术语在文档中出现的频率越高, 则他们的重要性就越强, 则这些内容就更加具备代表整个文档的资格。在TF-IDF中, 通常使用如下公式的方法计算某一个术语的重要性:
其中, 在公式的一端,t表示文档中的关键术语,d表示需要分析的文档,D表示语料库中所有的文件。在公式的另一端,TF(t,d)指词频, 表示某一个给定的关键术语t在文档d中出现的频率。
IDF(t,D)指文档逆序数, 由如下公式所定义:
在等式的一端,D表示语料库中文件的总量。另一端,DF(t,D)则表示语料库中有多少文件实际包含术语t。
虽然研究者基于TF-IDF可以很容易的计算出特定特征在程序文件中的重要程度, 并可以此从一定程度上表征用户的写作风格, 但如何消除干扰项(如常见的词语、库)对特征表示的影响, 是研究者需要仔细考虑的问题。
5.2.2 深度学习表示
基于TF-IDF的表示方法事实上可以直接输入机器学习算法中进行训练, 以得到可以用于作者归属分类的模型。然而为了得到较好的分类效果, 这种直接的训练方法通常需要基于复杂且极度消耗人力的特征工程。不仅如此, 应用场景的变化对分类效果的影响所占的比重也极其巨大[55]。
作为对比, 利用深度学习模型对特征进行深度表示也已经在多个领域进行了应用[56-57]。基于深度神经网络的多层处理结构, 原本众多难以直接表征作者写作风格的离散特征将可能被更为准确的区分。不仅如此, TF-IDF与深度学习表示也可以进行结合。例如, 文献[44]即使用LSTM和GRU算法对最初的TF-IDF特征进行处理, 以此探索多样的特征表示结果。
5.3 基于不同特征属性的作者归属研究
5.3.1 基于词汇特征的方法
作为基础且常用的特征, 有关词汇特征的应用研究十分广泛。除了基础的机器学习方法之外, 深度学习以及多方法融合的技术都得到了一定的尝试,近年来的代表性研究如下。
Abuhamad 等[44]面向支持多语言原作者分析,提出融合了RNN+RF的大规模程序作者认证技术。该技术首先针对词汇特征进行关键术语提取, 接着利用TF-IDF方法排序并抽取了前30位的重要特征,再将他们输入RNN模型后, 一种新的表征作者内在身份特征的深度表示即被生成。随后研究者将该深度表示输入了随机森林分类器中, 借助该分类器提升大规模程序分类任务的效果。
另一项研究[47]关注如何使用CNN技术来进行程序原作者的归属分析。具体来说, 在区分不同作者所作程序时其利用了两种方式对程序进行表示: 一种是基于频率的表示方法, 指研究者利用TF-IDF技术对重要词汇特征进行筛查, 以确定不同程序所表征出的词汇特征的不同; 另一种是基于预测的表示方法, 研究者首先将目标程序进行分析, 以独热编码的形式编码整个程序单词库中单词, 并将其输入到对应的工具模型(如: word2vec、Glove或预先训练的模型)中以生成特殊的Word embedding表示方式。最后, 研究者通过连接型CNN(Concatenated CNN Architecture)和堆叠型CNN(Stacked CNN Architecture)架构模型, 介绍了对不同类别的表示信息在不同CNN架构下的学习方案, 并通过在不同语言环境下比较的方式对预测效果进行评估。
Gonzalez等人[48]和Kalgutkar 等人[49]的工作均面向安卓系统固件的同源性分析技术。他们的研究关注作者在开发APP时的各类编程决策, 例如开发过程中涉及的特殊类、方法以及字符串的数量。具体来说, 该工作首先对.dex文件类型的安卓固件进行解析, 根据分段信息从代码段的解析结果中提取了多种语法特征(如: 类、方法、数据结构以及与数据结构操作相关的操作码)的使用情况。随后作者将这些特征从类、方法的数量, 数组定义的统计值, 从数组操作码中包含的重要N-gram数量以及从数据结构中创建的N-gram等4个方面进行向量化, 以形成作者风格特征。
5.3.2 基于句法特征的方法
虽然词汇特征的跨平台性良好, 但其对于作者微小改动后适应性不佳。研究者在此基础上进一步开始关注句法特征, 这标志着作者归属技术逐渐从简单的关键字、布局分析向语句编写习惯进行转变,相关的研究如下。
Bogomolov等[43]面向多语言(C++、python、java)适配的目标, 在提取程序代码的抽象语法树的基础上, 以语法树节点顺序构建了程序路径, 提出基于AST不同类型节点间连接性的路径表示以及针对该路径的上下文表示, 随后该研究进一步将程序路径以出现频率进行表示, 以使其更容易的被输入到基于随机森林和神经网络的作者分类模型中来完成认定工作。
Wisse等[52]提供了一个由JacaScript编写的相当大小和质量的参考数据集, 并对其进行了标注。在此基础上, 该文献从句法角度抽取源码的抽象语法树,从中获取了三类信息, 分别为: 1)代码结构: 包含:从中记录节点列表的长度(表征函数声明中定义的参数数量和数组中初始化的元素数量), 特定节点的后代节点的数量(反应了该节点的复杂性, 例如: 函数中传递标识符、对象的多少), N-gram切分下节点使用频率最高特征; 2)表征代码布局, 例如: 缩进与空格); 3)代码风格, 即注释、命名约定和数据类型。利用这些特征, 本方案尝试对待测程序是否由某一个特定作者或给定范围内的作者所著两个目标进行验证。
5.3.3 基于词汇+句法特征的方法
除了前述基于单一类型特征的研究工作, 融合这两方面特征进行作者同样也得到了研究者的注意,较为典型的工作如下:
Caliskan-Islam等[42]针对C++程序提出了使用频率(TF)和词频逆序数(TF-IDF)描述AST节点的方式进行研究。方案将程序的词汇特征一道输入基于随机森林的作者判定模型中, 取得了不俗的检测效果。此外, 论文作者还对数十位作者的编程风格进行了数年的追踪, 以评估文中所述的基于作者风格的作者归属方法的有效性。作为较早提出使用AST句法特征作为作者风格描述分类的研究, 该工作具备一定的指导意义。
与多数文献关注于整个程序的原作者归属不同,Dauber等[41]对程序片段的作者归属问题进行了尝试性的研究。具体来说, 研究者从句子结构的角度对目标程序进行分析, 将程序转变为抽象语法树的表示。在此基础上, 作者依照Caliskan-Islam等[42]的方法统计了目标程序AST最大节点深度、AST节点相互连接的频率以及58个AST节点类型的平均深度等数据。这些数据随后以若干子树为单位被输入到随机森林算法进行训练建模, 以实现对子程序代码所属的不同作者进行区分。
Zhang等[50]同样关注词汇和句法特征所蕴含的作者风格, 对文献编程布局特点、编程风格特点、编程结构特点和编程逻辑特点进行了描述, 并分别从他们中提取了可描述作者编程偏好的特征, 例如程序中空行的数量占比、IF-ELSE语句的数量占比, For循环起始时空格的数量等数据。并结合基于字符串的连续-离散N-gram方法产生的序列频率生成表征作者的向量。进一步的, 文献在使用支持向量机模型进行作者判定时还提出引入序列最小优化算法对数据进行处理。
5.3.4 基于语义特征的方法
在词汇以及句法分析的基础上, 进一步关注作者程序逻辑的语义特征分析也是近来流行的研究方向。与前面的方式相比, 程序语义的提取对于作者写作习惯的刻画更具鲁棒性的优势。在进行此类研究时, 研究者更倾向于结合词汇以及句法特征以实现对于程序-作者对应关系的更为全面的描述, 相关的研究如下。
CPA[45]关注语义特征对原作者归属的影响, 专门针对与用户有关的函数提取了控制流图CFG和数据流图DFG。在整合这些特征的基础上形成了作者归因图(AAG), 以包括作者代码特点(如代码实现细节)、代码结构以及作者编程时的经验(内存分配习惯、特定包的使用习惯或一些特殊的资源库)在内的特征的生成了一系列表征作者代码风格的特征表述。基于这些表述, 文献同时使用狄利克雷划分算法(LDA)和K-means实现了对已知作者识别分类和对未知作者的聚类, 以此完成用户身份签名的构建。不仅如此, CPA的研究者还使用Zipr[58]和FLAIR[59]工具将目标固件中库相关、编译器相关以及用户相关的函数进行过滤, 以尽量消除无用数据对判定结果的影响。
BinEye[46]强调采用自动化执行的方式来完成针对程序二进制文件的作者归属任务, 基于深度学习网络提出了对应方案。在作者归属模型训练阶段, 其采用了三个不同的神经网络, 分别为: 1)描述语义特征的指令流序列, 这可以表述作者解决问题时特殊的编程思路; 2)从汇编语言中提取的函数调用, 如作者经常使用的一系列API, 这可以认为是一种词汇特征; 3)直接将二进制文件转换为灰度图, 并基于Oliva等的工作[60]以识别出该灰度图中有关于镜像执行结构和内容的特征。选用第三种特征的重要原因在于具备相似作者风格的镜像也可能出现相似的图像纹理。而有研究[61]指出, 这种纹理对作者风格描绘的鲁棒性在一些情况下将优于以N-gram为代表的词汇特征表示方法。在经过不同CNN网络进行学习后,所获得的作者风格表示将通过K-means聚类以及选举的方式得到作者集合, 以用来进行后续的程序作者识别。该方法不需事先得到目标程序的先验知识,可自动实现作者代码风格描述的获取。不仅如此, 文献还评估了其在对于多作者共同完成一个镜像时的多作者归属问题的效果。
Meng等[51]面向如何区分单一固件程序中的多作者归因问题, 研究了以函数为粒度或以代码组合(称为块级特征)为粒度的鉴别技术。作者倾向于证明基本块的作者归属鉴别效果优于函数粒度, 并通过实验区回答了以下两个问题: 1)块级特征可以归为单个作者的程度如何2)块级特征是否包含足够的归属信息。针对第一个问题, Meng等使用git-author[62]工具计算每行代码的作者贡献百分比向量; 针对第二个问题, 本研究增加了包含词汇特征(指令)、句法(上下文)以及语义特征(控制流、数据流)辅助作者的归属, 因此取得了一定效果, 抽取的特征如表9所示。
Alrabaee等[53]认为仅仅从基于控制图和若干高排序N-gram文本角度进行作者归属分析虽然达到了一定的效果, 但事实上这种方法难以准确表述作者的风格习惯, 这是因为分析的结果中可能混杂着由编译器产生的唯一ID或随机但唯一的函数名, 这些与作者风格无关。基于这一观点, 文献提出了基于多层结构的OBA2方案。具体而言, OBA2首先解析了程序中可能调用到的库函数, 对其重要字节序列、函数大小、关键字符串、数值等进行基于双重哈希的签名, 为这些共享库函数生成不同的标识, 并减少其对后面分析工作的影响; 其次, OBA2基于自定义的翻译库将固件中特定的汇编组合的数量表征作者的语法风格(如: mov-cmp-jnz-xor-jmp 组合使用的次数就相当于if指令的使用次数), 翻译的过程还同时考虑了直接匹配(Exact matching)和非直接匹配(Inexact matching)的情况; 同时, OBA2通过观察程序执行时寄存器的操作情况获得了寄存器流图(Register Flow Graph , RFG), 其认为这种表征同样会反应出作者的代码能力和偏好。
5.3.5 基于其他特征的方法
也有研究者从其他特征角度对作者归属工作做出了有益的尝试, 例如: Bayrami等[40]结合了文献[50]与[63]的工作, 在将从程序源码中提取的典型词汇特征指标, 如: Type–token ratio、Carroll’s Corrected TTR等称为基于内容的特征, 提出融合若干生物学维度(如: 用户登录名、地区、性别, 基于非内容的特征)的方式训练分类模型。该方案的归属分类效果在三种机器学习方法(贝叶斯、支持向量机以及随机森林)上进行了评估。
5.4 方案分析
5.4.1 特点分析
基于词汇特征的方案。由于仅需要关注程序中特殊的符号, 因此只要程序分析工具支持特定的IoT设备平台, 特征即有机会被正确提取, 这使得基于词汇特征的方法[44,47-48]具备更好的跨平台性质。然而,作为一种基础的特征集, 使用词汇特征进行原作者分析将会面临诸多挑战。具体来说, 同一个程序其词汇的布局(如: 代码行数、长度)就有可能受到不同编程IDE、代码查看器的影响, 使得这部分特征所表述的信息难以稳定; 此外, 函数/变量重命名, 重要语句的换位、混淆以及冗余添加等简单手段造成的影响也难以忽视。
基于句法特征的方案。句法方案[43,52]关注作者对词汇进行使用和处理的方式, 并把其作为判定依据。这种方式可以屏蔽部分简单修改手段, 具备更好的分析效果。然而, 句法特征由于需要识别符号的组织和使用方法, 而这些特征通常与编程语言相关。因此, 针对不同语言的特征提取工具通常难以直接混用, 这使得该技术在面对使用不同程序语言的不同架构IoT设备上遇到挑战。不仅如此, 若想隐藏作者身份, 编程人员仍然可以通过适当改变编程习惯(如:重新排序函数内语句, 变换常用的switch-case语句结构, 常用类的合并, 添加冗余代码)等方式实现。可以预见, 选择更为相关的句法特征以尽可能抵消前述不利因素, 将仍然是后续研究的重点。
基于语义特征的方案。语义特征方案[45-46,51,53]关注作者在编写程序时的运行逻辑, 而通常人的思维定式习惯是潜意识流露的, 因此理论上将比其他两类方案具备更高的抗干扰性质。但是IoT设备程序语义特征的截取涉及到动态分析技术, 通常需要对IoT设备程序进行基于模拟运行的数据捕捉。根据文献[12], 当前模拟方案可分为基于Jtag等调试用剑、全系统仿真、Hardware-in-the-loop以及固件托管等方案。这些方案仍然存在需要大量人工参与、难以全系统接口模拟、可扩展性差以及仅能针对具备HAL层的IoT固件进行分析的缺点。工具能力的限制为语义分析方案在多类型IoT设备上进行应用提出了难题。
基于多种方式融合的方案。从理论上来说, 融合多种维度特征的方案将有助于对作者从多角度进行刻画, 因此将有助于提升检测效果。然而, 这无疑将对特征的提取工作量以及工具能力提出挑战。例如作者社会学维度信息只能在特定情况下获取; 分析工具需要支持多平台、多检测模式(动态、静态)以及多软件结构(裸机系统、实时操作系统)等。此外, 由前所述, 部分特征(如词汇特征中的代码行数、长度)易受到环境影响, 在融合时也需要综合考虑, 不能盲目将他们加入, 甚至可能对模型训练的结果造成负面影响。
5.4.2 适配性分析
大多针对创作者分析技术的研究其分析对象的具体应用平台是隶属于IoT设备还是X86平台并不明确。这一部分的原因在于当前很多工作是基于源码进行分析, 并没有对可适配平台进行讨论, 而已有的针对固件镜像的工作也大多以X86平台作为先决的实验环境。当前影响面向程序原作者的检测方案效果的重要因素在于所选取的程序特征是否能尽可能准确地描绘出作者的写作风格。因此, 本节将从特征提取的角度对相关技术是否能应用到IoT设备固件上进行分析。
从面向分析对象的角度来说, 原作者分析检测方法可以分成针对源码以及针对固件两方面内容。对于面向源码的分析工作而言, 可以认为只要IoT程序可以由该种语言编写, 那么相关的工作就存在可以被移植到IoT设备平台上的可行性。根据不同类型设备系统通常使用的编写语言, 前述所介绍工作预期所能支持的设备类型如表11所示。大多数基于源码的作者归属工作(即: 文献[40]、[41]、[42]、[43]、[44]、[47]、[50]和[52])都可以支持II(C、C++)和III(Python、C++、Java)类设备, 而讨论过I类设备所支持C语言的研究较少。

表11 基于源码方案的适配性Table 11 Applicability of Source-code Oriented Schemes
对于镜像文件而言, 其反汇编后的汇编语言将于不同的架构相关, 因此不能将相应的方法直接移植到IoT设备当中去。例如, 文献[44]利用Obfuscator-LLVM[66]将其研究的源码程序编译成镜像文件, 并在此基础上进行作者归属研究, 由于Obfuscator-LLVM支持包含X86、ARM在内的多种系统架构, 因此该工作具备潜在的可扩展性; 文献[45]更是将方案直接在基于ARM、X86、MIPS等架构下的固件进行作者归属效果的评估; 文献[46]利用IDA-Pro[67]对目标镜像进行反汇编, 并使用Nucleus[68]获取编译器难以获得的控制流信息, 当前Nucleus仅支持X86与x64下的C与C++固件信息提取; 文献[48]和[49]均针对安卓程序镜像进行分析, 因此其工作直接针对于III类IoT设备; 文献[51]同样使用IDA-Pro对利用GCC进行编译的镜像进行反汇编, 同时使用Dyninst[69]获取代码。Dyninst当前支持ARM架构, 因此该工作的可移植性也值得期待; 最后, 文献[53]面向C++固件反汇编后的作者归属问题设计了方案, 其工作对II类和III类IoT系统固件的分析将有启发性作用。根据不同固件架构, 他们所能支持的设备归类分析如表12所示。
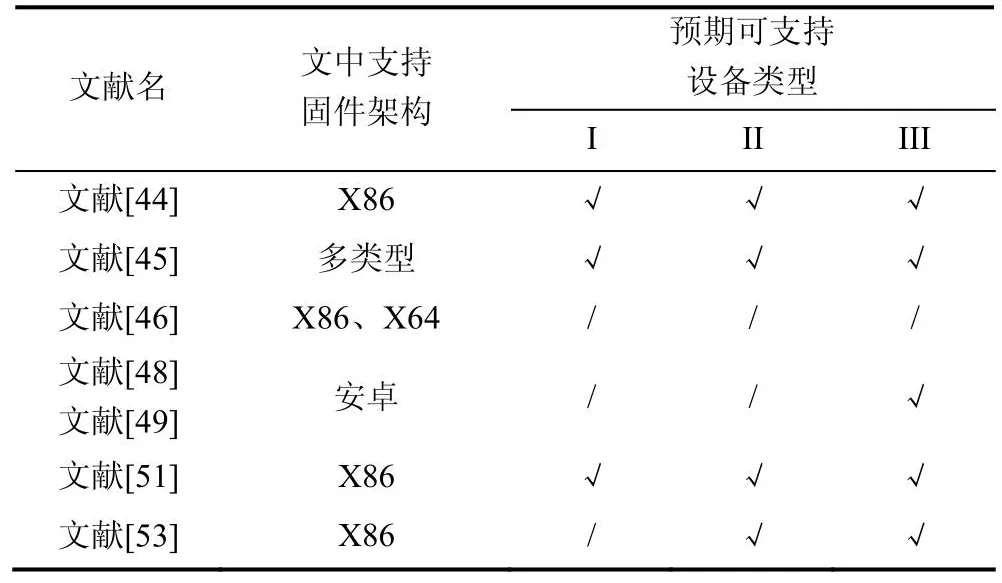
表12 面向固件二进制方案的适配性Table 12 Applicability of Binary Oriented Schemes
从以上的分析可以得知, 通过一些对应性的修改(例如测试数据集以及编译解析环境), 大多数的作者归属研究都具备移植到IoT设备上进行研究的条件。不仅如此, 有部分文献(如: 文献[45])直接声称其具备良好的跨平台特性, 可见将这些工作向IoT平台进行移植均有着一定的技术基础。
6 讨论与建议
由于 IoT设备特殊的软硬件特性, 当前大多数研究工作仍难以涵盖多类型的IoT设备。本节将面向构建通用的IoT程序同源性技术为目标, 对检测过程中所涉及到的关键技术能力展开讨论。
(1) 分析数据的收集。对于固件的相似性检测技术来说, 大多软件包(如busybox、OpenSSL以及cURL)本身就具备支持IoT设备的版本, 唯一需要注意的是他们通常需要操作系统支持, 即面向II型和III型设备程序。GNU工具集面向X86平台, 对于IoT设备而言, 搭载嵌入式Linux的III类IoT设备固件也可以使用。对于固件作者归属分析任务, 目前专门针对不同类别IoT设备的数据集还较少, 部分工作(如文献[45])也是将原适用于X86平台的C/C ++程序利用对应编译器进行编译, 利用所获得的程序进行进一步分析。事实上, 虽然当前大的代码平台(如:CGJ、GitHub)存在着大量的嵌入式程序, 但其绝对总量还是较少。
为了收集到足够数量的数据集, 满足同一个作者所著的不同IoT程序的条件, 来支持面向不同特征维度的模型训练, 还需要大量的收集和标记工作。从工作路线上来说, 研究者首先需要从典型的漏洞数据集(如: NVD、CNVD、CNNVD等)中获取不同类别漏洞的信息, 包括原程序的提供者、程序来源以及漏洞描述。随后以此为基础, 通过一定的手段(如代码平台、供应商)对应寻找相关代码并进行标注。当标注量达到一定规模后, 才可以用于实际的检测。
(2) 固件程序的解包。为了分析IoT固件文件,首先需要做的事情就是对他们进行反汇编。当前已经有诸如IDA-Pro、Dyninst等工具可以实现。然而,为了应对IoT设备多架构分析, 需要反编译工具具备良好的检测精度和广度。不仅如此, 反汇编代码的可读性也将随着不同架构模式而变化, 如何将针对源码的创作者分析研究中取得的成果应用、移植到固件环境中去, 需要进一步研究分析。在此基础上, 从汇编角度分离、区分出IoT程序中常用的库函数、系统调用以及用户编写的程序, 以进一步提升创作者分析的精度, 也需要重点关注。
(3) 特征提取。不论从固件角度分析还是从源码角度分析, 同源性分析的最终目标还是提取适合于描述作者写作风格的特征。对于作者归属技术而言,词汇特征因为仅是对标号进行一些排列组合, 因而相对而言易于提取。而句法以及语义特征的情况下,都应该基于不同的架构来分析词句之间的关联关系,这些关系的挖掘需要设计专门适用于对应IoT设备架构的软件方案来实现。特征提取方案可以分为动态以及静态分析。静态分析相对来说实现的过程较为简单, 但是其往往仅针对词汇特征较为有效。而动态分析方案因受IoT程序编程语言、生成固件形式以及设备类型的影响, 使得相关特征(例如: 语义特征)的提取难以覆盖全面。因此, 针对上述挑战进行相关数据提取工具研发, 将有利于提升语法以及语义特征提取的准确性。
(4) 分析方法。除了体量较小的I型IoT固件可能独立完成外, 其他类型固件的编写通常都不可能仅有一个作者完成, 这使得IoT固件的细粒度作者区分就显得更有意义。而当前大多数的同源性分析问题仍假设某一个程序的编写者仅由单一作者组成,仅有少量的文献对一个程序从属于多作者进行了讨论。若要深入研究, 则需要更为精确的标注数据集以及特征的支撑, 例如需要将程序片段映射到某一种漏洞或某一个作者。相比于前者, 对于后者的分析难度较大, 需要程序特征表示更为明确。因此, 为了适配IoT设备固件的运行特点, 在研究的过程中还需重点考虑不同类型固件的编写逻辑和应用场景,以从合适的粒度提取、计算能恰当描述不同作者的特征。
7 总结
由于IoT程序软件并没有固定的开发规范, 使得生态圈中充斥着各种未经授权的程序作者。他们所创作的软件的安全性和鲁棒性都难以保证。对程序同源性进行检测, 可以从一定程度上约束开发者行为, 减少恶意软件、库的传播事件。同时, 其对程序产权纠纷(如: 抄袭)也能提供一定的帮助。本文针对IoT设备程序同源性的智能分析技术展开综述, 将其从功能性和作者风格两个角度进行区分, 介绍了对应的相似性检测和创作者归属技术, 并对相关工作从数据获得、特征选取、模型训练、准确率以及主要贡献等多方面进行描述; 随后总结了这些方案对于IoT设备的有效性、局限性以及适配性。最后, 文章对同源性检测过程中的关键技术给出建议。作者希望通过本文的综述, 为研究者阐明相关工作的核心技术点, 并为后续应用研究提供参考。
