基于深度学习的跨自然语言与程序语言生成任务综述
2023-07-06宋小祎张若定张梅山黎家通
宋小祎, 张若定, 张 妍, 张梅山, 黎家通
1中国科学院信息工程研究所 北京 中国100093
2中国科学院大学网络空间安全学院 北京 中国 100049
3哈尔滨工业大学(深圳) 计算与智能研究 深圳 中国 518055
1 引言
跨自然语言与程序语言(Natural languages and programming languages, NL-PL)生成任务可以分为自然语言到程序语言的生成(NL→PL)和程序语言到自然语言的生成(PL→NL)两种类型[1]。跨NL-PL生成任务是自然语言和程序语言之间的相互转换任务,与自然语言翻译任务类似, 都是一种语言到另一种语言的生成任务; 不同的是, 程序语言是按照特定语法和结构编写的可执行语言, 跨NL-PL生成任务是自然语言与可执行的高度结构化语言之间的相互转换任务, 在转换过程中需要特别考虑程序语言的语法、语义、结构等信息, 因此跨NL-PL生成任务和自然语言翻译任务相比有共性也有区别。早期的跨NL-PL生成任务研究主要采用基于模板、检索、逻辑推导和归纳的生成模型[2-3], 然而这些方法存在泛化能力差、过分依赖人工先验知识、过分依赖检索数据库质量、无法充分利用大量开源数据信息等问题。近年来, 越来越多的研究人员开始利用基于深度学习的模型来弥补跨NL-PL生成任务的不足。
NL→PL和PL→NL的代表性任务分别为基于描述信息的程序生成和注释生成任务。本文旨在以这两种典型任务为切入点, 探索和总结基于深度学习的跨NL-PL生成任务的研究方法、发展过程、能力现状和未来发展方向。
为达到上述目的, 我们首先确定code generation、program generation、generating code、generating program、comment generation、code summarization、summarizing code、commit message generation、program translation等关键词, 随后我们在IEEE Xplore Digital Library、ACM Digital Library、Springer Link Digital Library、Wiley Online Library、Science Direct Digital、Chinese Science Citation Database数据库中搜索上述关键词来检索相关论文。对于检索出的文献, 三位作者通过查看其题目、摘要和引言部分筛选与本综述主题相关的论文。一共检索到相关论文112篇, 随后在DBLP、Web of Science、知网、谷歌学术等学术论文搜索引擎查找文献被引及作者发表论文情况等, 进一步补充和筛选相关论文, 最终我们初选定相关论文120篇论文。经过两位作者重复检索、筛查确定最具代表性的高质量论文73篇(截止到2022年10月), 每年累计发表文献及本文选中文献统计结果如图1。
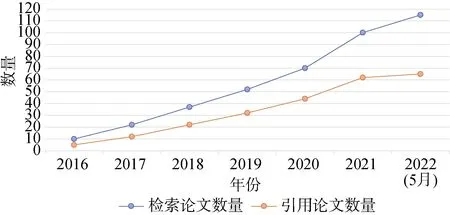
图1 检索及引用的累计相关论文数Figure 1 Cumulative number of papers retrieved and cited
通过对检索的论文进行分析, 我们发现, 近几年, ACL会议发表的相关工作最多, 共检索到25篇论文, 其中2020年之后论文20篇。另外, 与本综述相关的研究成果在ASE、ICSE等软件工程顶级会议和AAAI、NeurIPS等人工智能顶级会议中均有发表,该领域的研究者在这两类会议中都比较活跃。在代码注释方面, 来自澳大利亚蒙纳士大学的Xin Xia作为众多国内研究团队的合作者, 与来自浙江大学的Zhongxin Liu等人、北京大学的Bolin Wei、Xing Hu等人在ASE、NeurIPS、ICPC、IJCAI上发表了众多工作[4-7]; 在程序生成方面, 来自卡内基梅隆大学的学者Neubig作为合作者, 与Pengcheng Yin及奈良先端科学技术大学院大学的Yusuke Oda等人在ASE、ACL、EMNLP会议上发表了许多成果[8-11]。我们按照论文的发表源、发表源类型及等级对检索及引用的论文进行统计, 统计结果如表1, 其中发表源等级按照CCF(中国计算机学会)列表推荐的期刊等级标注。
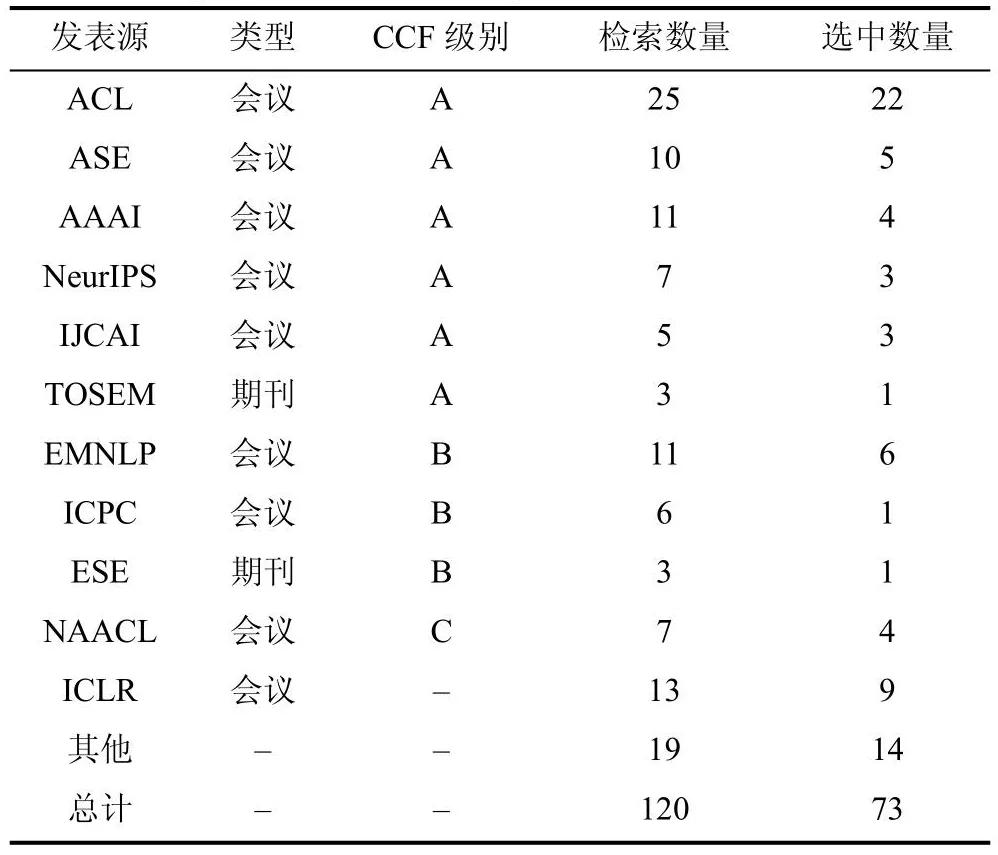
表1 按照发表源检索及选中论文统计Table 1 Statistical results searched and selected papers according to published source
目前与本综述相关的综述论文较少, Hu等人[2]对2019年之前基于深度学习技术的程序生成和程序补全成果进行了综述, 其主要关注不同输入输出形式的程序生成工作; Chen[3]等人在2020年对代码注释自动生成成果进行了综述, 该工作主要按照深度学习网络模型对注释生成文献进行分类。随着深度学习技术的发展, 越来越多成果被应用于跨NL-PL生成任务中, 在2021~2022年之间, 该领域又新发表约50篇论文, 尤其在代码表示、预训练模型设计、模型应用与安全性方面成果颇多, 本文从中选取了27篇论文进行分析。除此之外, 本文在程序代码表示方法、文献分类方法、数据集和模型效果等方面对已有文献进行了更系统地总结。
本文将从以下维度对相关论文进行总结分析:(1)基于描述信息的程序生成任务(NL→PL)和注释生成任务(PL→NL)建模、程序语言表示及深度学习核心模型 (2)两类任务基于不同程序表示方法的网络模型设计及程序语言预训练模型设计 (3)模型应用及安全性(4)数据集和模型效果 (5)未来发展方向。
2 跨NL-PL生成任务概述
2.1 任务建模
程序生成任务是典型的自然语言到程序语言生成任务(NL→PL), 通过学习一段给定的程序描述信息来自动生成具备与描述信息相匹配功能的程序。程序描述信息通常具有比较丰富的语义信息, 不同的数据集生成的程序在长度和类型方面差异较大。程序生成任务的数据集Dpg建模如下:
其中nli为自然语言撰写的程序描述信息, 是该任务的输入,ci为与nli对应的代码片段是期望的输出, 其中1≤i≤mpg,mpg为该任务数据集的标注数据数量。如图2(a)为程序生成任务常用的Django[11]数据集样例, 该数据集收集Python语言编写的Django框架代码作为ci, 使用英文编写的伪代码作为注释语句nli; CoNaLa数据集[12]收集在线编程问答论坛StackOverflow(SO)的问题标题和问题对应的解答代码片段作为nli和ci, 分别对应图2(b)中的原始注释/优化注释描述(如: 通过众包方式重新标注对应的注释内容)和代码片段部分。对数据集Dpg进行充分学习后获得最好的模型M, 最后使用M进行程序生成任务推理, 针对请求的功能描述信息nlqpg生成对应的代码cqpg即:

图2 跨NL-PL生成任务数据集示例(白色背景表示输入数据, 黑色背景表示输出数据)Figure 2 Dataset samples for generation tasks across NL-PL(white background represents input data while black background represents the output data)
注释生成任务是典型的程序语言到自然语言(PL→NL)生成任务, 目的是为一段代码自动生成通俗易懂、语义明确、格式良好的注释信息。注释生成任务通过学习源代码信息来生成相应语义的注释, 该任务和程序生成是对偶任务, 数据集Dag定义如下:
其中cj为代码片段, 是该任务的输入,nlj为与cj对应的注释是期望输出, 其中1≤j≤mag,mag为标注数据数量。常见的数据集为包含Python和Java等语言的源代码片段与注释对集合。如文献[15]采用包含Python函数级代码及注释对的数据集PCSD[16], 该集合大多数代码长度在20到60个单词之间, 注释长度在5到15个单词之间, 样例数据项如图2(c)所示,Python类Solution及其主体函数has_git的实现代码段为cj, 该类和主体函数的功能注释为nlj。由于注释生成与程序生成任务存在对偶性, 部分程序生成任务的数据集和注释生成数据集只需将输入数据和标签数据互换位置便可以共享, 如上述CoNaLa数据集就是常见的共用数据集。5.1节中我们将进一步对目前的数据集研究现状进行分析。与程序生成任务一样, 在注释生成任务中, 对数据集Dag进行充分学习后可获得基于DL的注释生成任务模型M, 部署M接受推理请求, 为请求的代码片段cqag生成对应的注释信息nlqag, 即:
2.2 程序语言表示
基于DL的跨NL-PL生成方案中, 输入或输出的代码需要表示为适用于网络模型学习的向量形式,该表示方法称为程序语言表示方法。在模型的输入侧, 程序表示应尽可能保留程序的顺序、结构、继承等信息, 从而使丰富的程序信息输入到网络模型中;在输出侧, 根据网络模型的不同, 程序可以被表示为字母、单词、程序节点等组成的序列。目前, 常见的程序语言表示方法有文本表示方法、树型表示方法及图表示方法, 样例如图3右侧所示。

图3 跨NL-PL生成任务实现方案Figure 3 Implementation scheme for generation tasks across NL-PL
文本表示方法首先将输入或输出程序中的变量名、操作符、值等按顺序提取为Token序列[13,17-20]。例如: Ling等人[13]将程序中的保留字‘int’表示为字母Token序列[i, n, t]; Iyer等人[17]则将程序语句‘return a’表示为单词Token序列[return, , a]。随后设计函数(比如: one-hot)将Token序列中的每一个字母或单词映射为向量, 在注释生成任务中, 程序文本序列将Token序列中所有向量按次序拼接, 形成程序的文本序列向量作为网络模型的输入。程序生成任务中, 通常需要经过多次迭代生成多个Token向量, 随后通过启发式搜索算法等确定最终生成的Token向量序列, 进而根据映射关系将Token向量序列转化为对应的字符Token序列。此种表示方式可保留程序的顺序、语法等信息, 但无法有效表示其结构信息。
树型表示方法将程序按特定解析规则表示为树型结构, 这些树是由许多节点和边构成的具有层次关系的集合, 树中每一个非根节点只有一个父节点,并且可以分为多个不相交的子树。以目前最常用的抽象语法树(Abstract syntax tree, AST)为例, 如图3右侧树型表示所示, AST树的每个非叶子节点表示一种语法结构例如: if、for语法, 这些非叶子节点规定了以其为父节点的下一层节点的数量、类型等, 每个节点包括两部分:类型信息以及由程序中的变量名、操作符等构成的值信息。程序的树型输入表示方法首先将程序解析为树, 之后可以分为两种模式, 一种按深度优先遍历方法序列化树中的所有节点, 然后设计函数对节点序列进行向量化表示, 形成的树型节点向量序列作为模型的输入;另一种直接将树中的节点通过映射函数映射为向量, 随后设计可以读取树向量的树型结构网络[21]进一步学习其嵌入表示。程序的树型输出表示方法则按树的生成顺序迭代输出树型程序结构的每一个节点的向量表示, 停止输出后可将已输出的向量根据向量和节点的映射关系恢复为节点, 最后根据解析规则将节点恢复为程序代码文本。树型表示方法可以有效保留程序的结构、继承等信息[22-23]。
图表示方法将程序信息首先表征为程序图。程序图由顶点和顶点之间边的集合构成, 这些边用于表示顶点之间的逻辑关系。在软件工程领域, 经典的程序图有数据流图、控制流图、函数调用图等形式,在跨NL-PL的生成任务中, 较常见的程序图为对AST树进行扩展, 增加邻居边、数据流依赖边等形成的扩展图。相较于树型表征方式, 图可以表示的信息更加丰富和灵活, 也是近些年研究的趋势。在跨NL-PL生成任务中, 图表示方法一般只用于输入端,该表示方法将输入的程序表示为图[24-25], 然后使用嵌入矩阵等映射方法将顶点和边表示为顶点向量和边向量, 随后输入到网络模型中进一步学习其顶点和边的嵌入表示获得图嵌入表示, 获得的图嵌入表示可以学习到更多程序信息。
2.3 深度学习核心模型
在跨NL-PL生成领域应用较广泛的深度学习模型包括LSTM[26](Long short-term memory)、GRU[27](Gated Recurrent Unit)、Transformer[28]及注意力机制,LSTM是改进的循环神经网络(RNN)结构单元, 其包含三个门结构, 每个门结构设有对应的权重和偏置参数, 可以控制输入和输出的数据流信息, 基于LSTM的循环神经网络可以处理时序数据并捕获数据的长距离依赖关系, 相比于原始的RNN模型可以有效解决长序列训练过程中的梯度消失和梯度爆炸问题; GRU模型在LSTM模型基础上进行改进, 使用两个门控制数据输入和输出, 可以提高数据处理效率; 注意力机制期望模型关注输入数据中更重要的部分, 因此通过计算输入数据对当前任务的权重来突出关键信息, 降低其他信息的权重, 忽略无关信息, 这样可以提高模型准确率和数据处理效率,Transformer模型采用编码器解码器结构, 核心模块为多头自注意力机制, 该机制可以从多方面关注输入数据对当前任务的影响, 使编码器更好地编码输入数据的序列和语义等信息, 使解码器更好地解码生成数据, 在编码器和解码器之间使用注意力机制,可以使解码器从编码器的输出中关注更有效的信息。另外一些学者在该领域也尝试使用卷积神经网络(Convolutional Neural Networks, CNN)模型实现跨NL-PL任务, CNN模型的核心部分为卷积核和池化操作, 卷积核用于提取文本特征, 池化层用于降低数据维度并过滤出关键特征, 该模型的数据处理速度较快, 但需要辅助设计其他算法才能有效捕获数据的长距离依赖关系。
3 基于不同程序表示方法的跨NL-PL生成网络
对搜索到的73篇文献跟踪分析, 全面梳理总结其模型设计目的、结构特征、实现方式等, 归纳这些模型的共性及特性, 我们将跨NL-PL生成网络模型抽象为三大通用组件, 分别为: 程序表示、语言处理和语言生成。其中, 程序表示单元用于表示程序信息,表示方法分类如2.2所述。语言处理组件可以分为PL处理组件和NL处理组件, 分别负责处理输入的程序语言和自然语言表示序列并提取关键特征, PL处理组件常采用基于LSTM、Transformer编码器以及图神经网络的模型处理文本、树型、图程序语言表示输入; NL处理组件常使用LSTM、Transformer编码器模型处理自然语言输入。语言生成组件用于接收捕获的特征进而生成目标信息, 该组件通常由基于注意力机制、Transformer解码器的模型构成, 根据生成内容的不同也可分为NL生成组件和PL生成组件, 由于PL生成组件需要生成比较复杂的程序代码, 因此有时还需额外加载并处理一些必要的先验知识。我们发现, 通常一个完整的生成模型只包含一个处理组件和一个生成组件, 但是在程序生成任务中, 由于需要模型独立学习先验知识或者使用无法传递信息的CNN模型等问题, 一些研究人员会另外设计一个PL处理组件, 用于处理已生成的程序或学习程序先验知识。图3展示了我们在文献中抽象出的一个通用跨NL-PL生成任务实现模型, 图中黄色数字编号代表程序生成任务实现过程, 蓝色编号对应注释生成任务实现流程。
由于语言处理组件和语言生成组件的网络设计与程序的表示模式存在较强相关性, 以下我们按照三大程序表示模式对跟踪的文献的网络结构设计理念进行分类总结。图4为本文引用文献各类型数量的堆叠面积统计图。

图4 引用文献类型统计图Figure 4 Statistical chart of cited literature types
3.1 文本程序表示与语言处理生成组件协同
基于文本表示的网络设计可以保留程序顺序信息, 一些早期的研究以及基于Transformer模型的方案常采用该设计模式。
程序生成任务方面, 早在2016年, Ling等人[13]就提出基于文本序列程序表示的LPN模型。该模型使用Bi-LSTM网络和结构注意力机制(Stru-Att)作为NL处理组件对输入的自然语言进行学习, 基于指针网络(Ptr-Net)设计PL生成组件, PL生成组件以单个程序字母Token为生成单元, 通过学习已生成单元,并不断选择程序预测器生成对应的字符级代码文本序列。预测器包括生成预测器和复制预测器, 这些预测器定义了程序生成行为, 可用于指导模型生成或复制程序Token, 可以在生成组件中作为一种先验知识强化程序文本序列生成能力; Norouzi等人[29]也提出基于程序文本表示的模型, 该模型使用BERT作为NL处理组件捕获自然语言特征, 以Transformer解码器(Trans-De)为PL生成组件, 使用目标自动编码(Target autoencoding, TAE)技术学习大量单语程序代码获取大量先验知识, 学习到的先验知识可以帮助生成组件生成程序文本序列, 已生成的程序文本序列在生成组件参与下一单元的生成。不同于LPN,该模型以单词为程序生成单元。另外, Xu等人[18]、Liu等人[20]提出的模型也是采用文本序列表示方法的程序生成方案。另外也有一些学者研究了由自然语言到程序API序列的生成工作, 该任务可看作一种特殊的程序生成任务。Gu等人[30]设计了DeepAPI模型, 该模型根据自然语言查询语句的语义生成需要调用的程序API的文本表示序列, 其NL处理组件使用GRU模型, PL生成组件使用GRU结合注意力机制模型, 注意力机制用于在生成过程中计算单个API的重要性。
注释生成任务方面, 较早基于文本表示的注释生成研究为Iyer等人[17]提出的CODE-NN模型, 该模型使用在文献[31]基础上改进的全局注意力机制[32]作为PL处理组件学习代码文本序列中每一个Token的权重, 随后使用LSTM网络作为NL生成组件学习已生成的注释单词信息和捕获的程序特征, 进而生成注释单词序列。考虑到循环神经网络无法捕获长距离依赖关系, Ahmad等人[19]基于Transformer设计基于文本表示的注释生成模型, 为了充分利用代码的位置信息, 作者结合位置编码改进Transformer编码器中的自注意力结构, 设计面向代码文本序列表示的PL处理组件, 采用Transformer解码器设计NL生成组件, 并在生成组件中加入复制注意力模块, 使模型可以复制输入的单词作为注释Token, 该模型对于自注意力模型的改进可以有效表示程序语义, 复制机制也有助于注释单词的生成。
结合多任务学习, Chen等人[33]提出同时训练两个类似的任务, 即: 代码摘要和API摘要, 希望利用API信息辅助提高代码摘要即代码注释生成性能。该模型的PL处理组件基于改进的BERT模型构建, 其在BERT模型之后加入文本上下文嵌入层来进一步捕获程序文本序列的语义信息, NL生成组件由Transformer解码器构成。在多任务学习过程中, 处理组件被两个任务共享, 生成组件进一步分为两个组件, 分别用于生成代码摘要和API序列摘要, 通常使用Transformer模型的方案中, 生成组件都由Transformer解码器构成, 并且已生成单元都在生成组件参与下一单元的生成。
根据代码变更生成提交消息可以看作一种特殊的注释生成任务, 提交消息记录了代码更改的内容、位置、目的等, 通过提交消息可以查看软件演化的过程。该类型任务中, 也有众多学者采用文本表示方法表示变更代码序列。Jiang等人[34]较早研究该类问题,他们将该问题视为神经机器翻译(Neural machine translation, NMT)问题, 模型PL处理组件和NL生成组件均使用RNN模型; 随后Liu等人[35]等人发现jiang等人[34]使用的数据集中含有约16%的噪声即重复或不重要的内容, 去掉这些噪声后, NMT方法的性能大幅下降, 但当训练集含有与测试集相似样本时, 模型可以生成高质量的提交消息, 基于上述发现, 作者设计了基于余弦相似度和BLUE-4得分的检索模型NNGen。随后jiang等人[36]也意识到训练数据集对生成的提交消息质量的影响, 因此设计使用语义分析技术对输入的代码变更进行预处理。Xu等人[18]认为已有的工作忽略了代码的结构信息, 因此提出CODISUM模型, 在PL处理组件中, 通过将变更代码文本表示序列中的标识符替换为占位符来提取代码结构, 使用双向GRU层学习代码结构信息, 使用另一个双向GRU模型学习标识符的语义信息, 随后使用注意力机制融合这两部分信息, NL生成组件采用GRU模型, 同时添加复制机制缓解生成过程中的OoV问题。Bai等人[37]提出一种联合程序代码修复和提交消息生成的新任务, 该模型以BUG代码文本表示序列为输入, NL处理组件使用Transformer编码器模型, 使用Transformer解码器作为PL生成组件生成修复代码, 随后设计带有动态注意模块(DAtt)的Transformer解码器作为另一个NL生成组件, 接收前两个组件的文本表示输出序列, 生成一段自然语言提交消息来描述修复代码的更改内容。该方法与利用师生法、多任务学习法和反向翻译方法增强的级联模型进行了对比, 证明提出的联合模型优于这些级联模型。
由于注释生成任务和程序生成任务可看成两个互逆的任务, 因此Wei等人[4]也提出一种基于程序文本表示的对偶训练模型, 通过利用程序生成和注释生成之间的互逆关系来同时提高两个任务性能。模型以Bi-LSTM作为语言处理组件分别处理程序和自然语言单词文本序列, 以注意力机制结合LSTM作为生成组件, 在损失函数中加入双正则项约束两个模型之间的对偶性。
3.2 树型程序表示与语言处理生成组件协同
由于程序语言是高度结构化的语言, 而树型程序表示被认为可以有效表示程序的结构化信息, 因此学者们提出众多树型程序表示与网络结构协同的方案, 此模式目前应用较为广泛, 且以AST树型程序表示最为常见。
以程序AST节点序列为生成单元, 众多学者引入不同的先验知识设计相应的程序生成模型。使用预定义的构造函数和语法为先验知识, Rabinovich等人[38]使用双向LSTM和改进的垂直LSTM(vertical LSTM)分别作为NL处理组件和PL生成组件, 在处理输入的NL程序描述信息之后, 通过选择构造函数递归生成PL侧AST节点序列。结合开源语法信息,Sun等人[39]提出基于语法结构的CNN方法, 模型使用多个CNN结构作为语言处理组件分别学习程序描述、已预测的语法结构、已预测的部分AST信息, 使用基于注意力机制的模块作为PL生成组件计算生成程序AST节点序列。TreeGen模型[40]在Transformer编码器(Trans-En)加入卷积层作为NL处理组件, 捕获输入的自然语言特征, 在编码器之后设计基于自注意力机制、注意力机制和树型卷积层(TreeConv)的模块作为PL处理组件用于捕获已生成程序AST节点的结构特征, 生成组件使用Transformer解码器,通过不断选择语法规则生成下一个程序AST节点。以外部语法和自定义的树构造动作为先验知识,TRANX模型[8]使用Bi-LSTM作为NL处理组件处理自然语言语句, 使用LSTM结合注意力机制模块作为PL生成组件, 通过选择树构造动作生成程序AST节点序列, 该过程通过学习语法规则保证生成的程序符合程序语法。
在程序生成过程中, 树型程序生成需要依次展开非叶子节点, 最终生成AST叶子节点序列。AST树的非叶子节点通常包含很多分支, 在上述研究中这些分支根据从左到右的深度优先遍历方式展开,然而Jiang等人[41]认为这种先序遍历展开顺序并不是最优展开顺序, 根据一些常用搭配, 如果先生成先序遍历序列中的右侧节点可能更容易生成准确的左侧节点, 因此作者设计一个基于上下文的分支选择器, 并使用强化学习对选择器进行优化, 以确定多分支节点中最优的分支扩展顺序, 将此方法应用在TRANX[8]模型中时, 获得与TRANX相比约1%的效果提升。大部分程序生成研究采用由文本序列表示的自然语言到树型表示的程序语言的生成模型,最近也有学者研究树到树的程序生成模型, Dahal等人[42]将自然语言解析为结构化的基于“成分”的解析树(Constituency-based parse tree), 随后采用结构感知的树型Transformer(Structure-aware tree transformer)模型[43]生成程序AST节点。
在注释生成任务中, 研究人员很早就注意到树型结构在程序结构表示方面的优势并设计相应的模型。Liang等人[21]使用一个改进的GRU模型即Code-GRU作为PL处理组件学习程序的AST树型表示, 使用一个RNN网络作为NL生成组件完成注释生成。考虑到相同AST结构的节点的类型可能不同,TAG模型[22]的设计考虑了AST节点类型信息, 该模型的PL处理组件由一个基于树型LSTM的模型构成,用于学习AST 节点值和类型信息, 使用基于LSTM和注意力机制的模型作为NL生成组件, 根据AST节点类型生成注释单词序列。考虑到邻居信息的重要性, Choi等人[44]提出为程序AST增加邻居边形成mAST树型表示, PL 处理组件由图卷积网络[43]和Transformer编码器构成, 用于学习mAST结构信息和代码的顺序信息。为了更好地表示程序, SiT模型[45]从AST、控制流、数据依赖三个维度表示代码的结构和语义信息, 同时设计结构引导的Transformer网络模型, 语言处理组件采用基于结构引导的自注意网络的Transformer编码器模型, 将三个维度的树型代码表示转化为邻接矩阵并进行自注意力计算捕获程序特征。
在注释生成研究中, 同时学习程序的文本及树型表示的研究众多。Wan等人[15]提出使用深度强化学习网络实现注释生成。模型使用基于LSTM的模型和基于树的LSTM作为PL处理组件, 分别处理代码文本序列和代码AST树, 设计基于注意力机制和RNN的模型作为NL生成组件结合已生成的注释信息生成下一个注释单词, 同时以评价指标结果(BLEU)指导强化学习(RL)的行动者-评论家模型, 不断优化注释生成过程。关注到复杂代码的AST树节点众多、规模庞大和语义难捕获问题, CAST模型[46]采用文本及树型程序表示方法, 采用基于递归神经网络(RvNN)的AST编码器作为一个PL处理组件, 用于对程序AST树进行层次分割, 将其划分为多个子树后捕获其结构特征, 使用Transformer的编码器作为另一个PL处理组件来捕获程序文本表示的特征, 最后使用Transformer解码器结合复制注意力机制的模型作为NL生成组件生成注释单词。CodeTransformer模型[47]联合学习程序文本序列和抽象语法树表示, 并且在模型中计算AST上的成对节点距离, 使模型在每一层都可以访问完整的树型结构, 该模型设计为注释生成模型的PL处理组件, NL生成组件由基于Transformer 解码器的模型构成。由于该方法不需要使用特定语言的先验知识, 因此作者训练了第一个代码注释的多语言模型, 即在Python、Ruby、Go、Javascript四种语言的数据集上训练获得代码注释生成网络模型。Liu等人[48]认为以前的研究中, 检索模型与生成模型各有优势, 同时充分表示变更代码的结构信息对于捕获代码语义可能很重要, 因此设计了基于AST表示和检索模块的ATOM模型, 该模型使用双向LSTM模型作为PL处理组件学习变更代码的AST表示, 使用注意力机制作为NL生成组件生成提交消息, 同时设计检索模型, 查找检索库中与目标代码更改相似的样本与对应的提交消息, 最后设计基于ConvNet的分类器对检索和生成的提交消息进行分类, 在二者中选取最合理的内容作为最终结果。该方法优于文献[18,34-36,49-50], ATOM在BLEU-4方面比最先进的模型提高30.72%。
3.3 图程序表示与语言处理生成组件协同
在我们目前为止检索分析的论文集中, 图程序表示方法在程序生成任务中不常用, 在注释生成任务中应用较多, 一个可能的原因是在程序生成任务中采用PL生成组件生成复杂图存在一定难度。但在程序生成任务中, 有学者研究学习程序图表示作为先验知识, 用于指导程序生成。Lyu等人[54]提出学习程序API依赖图信息作为先验知识, 他们首先将数据集中待预测代码片段构建为API依赖图, 并设计基于LSTM的PL处理组件学习其依赖关系, 采用另一个基于LSTM的NL处理组件学习自然语言描述信息, 生成组件使用注意力结合LSTM的模型来融合已捕获特征, 最终根据自然语言描述信息和学习到的API依赖关系生成程序文本或API依赖序列。
在注释生成任务中对输入的代码采用各种图结构进行学习, 技术相对比较成熟。早期基于检索的注释生成方法可以充分利用数据库中的相似数据信息,但是泛化能力差, 基于深度学习的方法恰好相反,因此Liu等人[24]提出将任务程序和在代码注释对数据库中检索到的相似代码构建为属性图, 并进一步建模为静态图和动态图, 使用结合GRU的混合图神经网络(Hybrid GNN)作为PL处理组件学习上述两种图信息, 最后使用基于注意力的LSTM生成组件模型, 融合图信息和检索到的注释信息生成新的注释。
考虑到在生成函数级代码注释的过程中, 与该函数在同一类级别下的其他函数可能与该函数有关联, Yu等人[69]使用基于Bi-GRU的PL处理组件捕获目标函数文本序列特征, 使用基于图注意网络(GAT)的PL处理组件捕获该函数所在类的程序图的特征,最后NL生成组件由指针网络结合GRU的模型构成,用于生成注释序列。PGNN-EK模型[76]在程序表示方面, 以程序AST树为基础, 通过添加数据流边并连接相邻的叶节点构建S-AST图, 随后将其划分为多个子图作为模型的输入, 使用GNN[80]结合LSTM的PGNN 模型作为PL处理组件来学习图嵌入表示, 同时使用CodeBERT作为另一个PL处理组件学习代码对应的API文档知识, 两部分表示融合获得最终的嵌入表示, 生成组件采用Transformer解码器, 根据最终的嵌入表示生成注释单词序列。CODESCRIBE模型[79]将AST看作图, 使用Transformer编码器和基于图神经网络的模块作为两个PL处理组件分别处理程序文本和AST图表示, 在学习程序AST图表示时,组件同时学习程序中的节点深度、父节点位置以及兄弟位置三元组信息, 这样可以更充分地学习源代码的层次语法结构和语义信息, 生成组件由Transformer解码器和衔接在其后的指针生成网络构成。表2将各类基于DL的跨NL-PL生成任务研究进行了分析和对比。

表2 基于DL的跨NL-PL生成任务方法对比Table 2 Comparison of across NL-PL generation task methods based on DL
3.4 程序表示与预训练模型协同
通过设计不同的NL-PL预训练目标和预训练模型可以使面向PL的代码预训练模型获得大量不同的代码知识, 因此许多工作基于已有模型或设计相关代码预训练模型, 对大量程序代码及注释进行预训练, 这些程序代码在输入预训练模型之前, 也需要基于不同程序表示方法进行表示, 从而使跨NL-PL生成网络模型更充分地理解输入的程序及注释信息,进而更出色地完成生成任务。表3将PL预训练方法进行了对比。

表3 PL预训练方法对比Table 3 Comparison of PL pre-training methods

表4 工业领域程序生成预训练方法对比Table 4 Comparison of pre-training methods for program generation in industrial field
CodeBERT模型[77]是2020年Feng等人提出的首个面向NL-PL双语任务的预训练模型, 它基于RoBERTa[81]模型设计, 基于文本表示方法表示程序代码, 仅使用Transformer模型的编码器结构, 结合BERT[82]的掩码语言模型(MLM) 和替换词检测(RTD)预训练目标, 以6种NL-PL对以及大量单一的PL语料作为数据集训练模型。目前该模型已被大量应用在跨NL-PL生成任务中, 如Wu等人在SiT[45]模型基础上引入了CodeBERT, CodeBERT学习的通用知识帮助SiT模型在不同评价指标上提高0.6%~3%; Zhu等人[76]使用CodeBERT学习代码的API文档知识从而获得更优秀的程序嵌入表示。
CodeT5预训练模型[1]基于T5[84]自然语言预训练模型模型设计, 使用文本表示方法表示输入数据,采用Transformer编码器和解码器结构, 该模型以掩码跨度预测(MSP)、标识符标注(IT)、掩码识别预测(MIP)三个任务为预训练目标训练基础模型, 随后使用双向对偶生成(BDG)方法同时训练程序生成和注释生成任务来增强两个生成任务效果。结合BDG的CodeT5模型获得最优效果, 与此前最优的代码摘要模型PLBART[78]相比BLEU-4值均提升约1%, 在程序生成任务上与PLBART[78]相比BLEU值提升约4%。同时作者也开发了一个结合多任务学习的CodeT5模型, 该模型使用一部分共享的模型训练多个程序语言相关任务, 可以有效减少计算消耗, 与结合BDG的CodeT5模型相比, 基于多任务学习的CodeT5模型在注释生成任务上有小幅度效果提升,但是在程序生成任务上降低了模型效果。
UniXcoder[85]是2022年提出的程序语言预训练模型, 该模型利用带有前缀适配器的掩码注意矩阵[86]作为一种训练优化方式, 控制模型的训练行为。UniXcoder将程序及其注释表示在同一个AST树中,网络模型由多个Transformer结构组成, 与上述仅采用一种Transformer编码器或解码器的模型不同, 该模型使用MLM、单项语言模型(ULM)、去噪目标(DNS)三个预训练任务分别训练仅编码器模型、仅解码器模型、编码器解码器三种模型。虽然该模型在程序生成和摘要方面一些指标无法超越CodeT5[1],但是在其他源代码相关任务上提升效果明显, 该文献在输入表示及模型训练方面为我们提供了新的思路。
考虑到仅使用文本表示的程序代码训练模型,丢失了代码结构信息的问题, Guo等人[83]提出GraphCodeBERT模型。该模型以代码的注释序列、代码文本序列以及代码数据流图为输入, 为了配合输入的数据流图, 作者在BERT模型的基础上加入一个图形导向的掩码注意力函数(Graph-guided masked attention)用于处理数据流图, 同时预训练目标除了使用MLM, 还设计了数据流边界预测(EP)和源代码与数据流节点对齐(NA), EP和NA目标用于学习程序数据流图信息。GraphCodeBERT尚未在跨NL-PL生成任务中测试, 但由于其对程序语言进行了更全面、更深入的表示, 基于GraphCodeBERT的跨NL-PL 生成任务改进方案是值得探索的研究内容。
4 跨NL-PL生成模型应用及安全性
4.1 程序生成模型应用及安全性
除学术研究外, 大型互联网公司利用其强大的计算和数据处理能力, 设计了众多针对程序生成任务的预训练模型, 并将其用于商业化目的, 这些模型在程序表示方面多采用处理效率较高的文本表示方法。与学术领域不同, 工业领域预训练模型多基于Transformer解码器模型设计。2022年6月22日,微软公司正式上线Github Copilot编程工具,该工具核心模块为Codex[14]模型, 是OpenAI团队创建的一个基于GPT模型微调的预训练语言模型,该模型使用从Github开源代码平台约159GB Python文件进行训练,微调后的模型解决程序生成问题的比例由GPT-3的0%提升到了28.8%。该工具支持Visual Studio、Visual Studio CodeNeovim 和JetBrains IDE开发环境, 可以生成Python、Java、Go等多种语言程序代码。华为公司诺亚方舟实验室联合华为云PaaS技术创新实验室在2022年设计的PANGU-CODER[89]模型采用基于Transformer解码器的自回归语言模型, 以因果关系语言模型(CLM)和掩码语言模型(MLM)为预训练目标,使用约185GB数据训练模型,其在HumanEval[14]数据集进行测试, 在较小参数规模的模型对比中,该模型效果达到了最优。该工具已集成到华为云平台的代码开发辅助工具中,可以帮助开发者在IDE中根据自然语言描述生成函数级的Python代码, 可以解析英文和汉语自然语言输入语句。目前CODEGENMONO[90]模型在参数量达到最大(6.1B)时,可以取得最优结果, 该模型是CODEGEN系列中的一种模型,由Salesforce公司设计, 使用从Github收集的约217.3GB Python代码训练完成。CODEGEN[90]系列模型基于GPT-3[87]预训练语言模型设计, 以训练下一个令牌预测(NTP)语言模型为目标, 在自然语言语料库和来自GitHub的编程语言数据上分别训练, 实现了自然语言、单语程序语言和多语程序语言模型, 分别命名为CODEGEN-NL、CODEGEN-MONO和CODEGEN-MULTI。美国纽约大学的学者Brendan Dolan-Gavitt以CODEGEN[90]模型为核心技术设计了FauxPilot[91]程序生成工具, 该工具可以在本地运行,无需上传用户数据, 不会读取开发者编写的代码或共享用户代码数据, 可以保护用户隐私。
然而, Codex和类似的工作中使用的训练样本大部分由简单的自然语言描述和代码片段组成, 其复杂度与现实编程环境差距较大, 因此来自Google的团队提出了解决竞赛类型编程问题的代码生成系统AlphaCode[88]。竞赛类编程问题通常包含一段复杂的自然语言描述和一些测试实例, 其预期输出复杂性通常较高。为解决上述问题, 作者从GitHub收集约715GB包含Java, JavaScript, PHP, Python等12种语言的源代码文件, 设计浅编码器和深度解码器结合的预训练模型学习这些数据。为筛选出最恰当的生成样本, 作者对模型输出的大量样本进行了过滤和聚类。AlphCode模型在Codeforces编程网站第1591-1623编号中的10道赛题上进行了测试, 赛题包括复杂字符串处理、贪心算法应用、递归算法应用等问题, 其排名在前54.3%, 超过约46%的真人参赛者。
程序生成成果商业化之后, 其安全性问题受到了用户的广泛关注, 目前主要包括以下三方面问题:(1)训练及生成程序可能存在安全漏洞, 比如使用弱加密函数、引入不安全第三方依赖包、存在黑客可利用的其他编程漏洞等, 如果编程人员广泛使用该工具, 则会导致错误代码传播, 后果不堪设想。(2)收集或生成的代码可能存在版权及许可问题。对于版权问题, 在Copilot发布付费版本后, 一些使用者发现该工具所生成的部分程序代码并非原创, 存在从数据集复制粘贴代码的行为, 因此使用非原创程序来谋取利益可能会导致版权问题; 对于许可问题, 由于大部分模型使用从Github平台收集的免费程序代码进行训练, 这些开源代码均遵循GPL(GNU General Public License)协议, 即允许用户免费共享和修改软件, 而互联网厂商将其用于商业化谋取利益,违反了GPL许可, 另外由于Github收集数据过程较模糊, GitHub也存在收集非GPL许可类型的程序代码的嫌疑, 甚至其可能收集用户明确声明不允许商业化的程序代码。(3)伦理道德问题。从互联网收集的数据集可能包含亵渎语言, 甚至部分存在对特殊团体的偏见。大部分模型训练和生成过程中没有对这些内容进行过滤, 可能导致生成的样本中含有不恰当的内容。
4.2 注释生成模型应用及安全性
注释生成模型在工业界应用较少, 目前比较流行的工具为GhostDoc[92]、DocFX[93]和Doxygen[94]。GhostDoc是Visual Studio工具的插件, 由SubMain公司开发, 可以帮助开发人员为C#语言的代码编写XML格式的注释文档; DocFX是微软公司开发的文档生成工具, 支持C#和VB语言, Doxygen应用较广,在OpenCV和Apollo等众多开源库中被使用。但是上述工具主要依赖于语言解析和标识符解析技术,未使用深度学习方法直接生成注释文档。
安全性方面, 注释生成模型主要面临鲁棒性安全问题。近期的研究表明[95-96], 在程序语言相关任务中, 给输入的正常样本一个微小的扰动(如: 替换训练代码中的标识符)可以很容易导致模型误判,如图5所示, 这样的模型很容易受到对抗攻击的影响。深度学习模型的鲁棒性在自然语言处理、图像识别、目标检测等领域已存在大量研究成果[97], 比较常用的提高模型鲁棒性的方法为对抗学习方法, 该方法目前也被应用于跨NL-PL生成的注释生成任务中。表5将PL对抗学习方法进行了对比。

表5 PL对抗学习方法对比Table 5 Comparison of PL adversarial learning methods
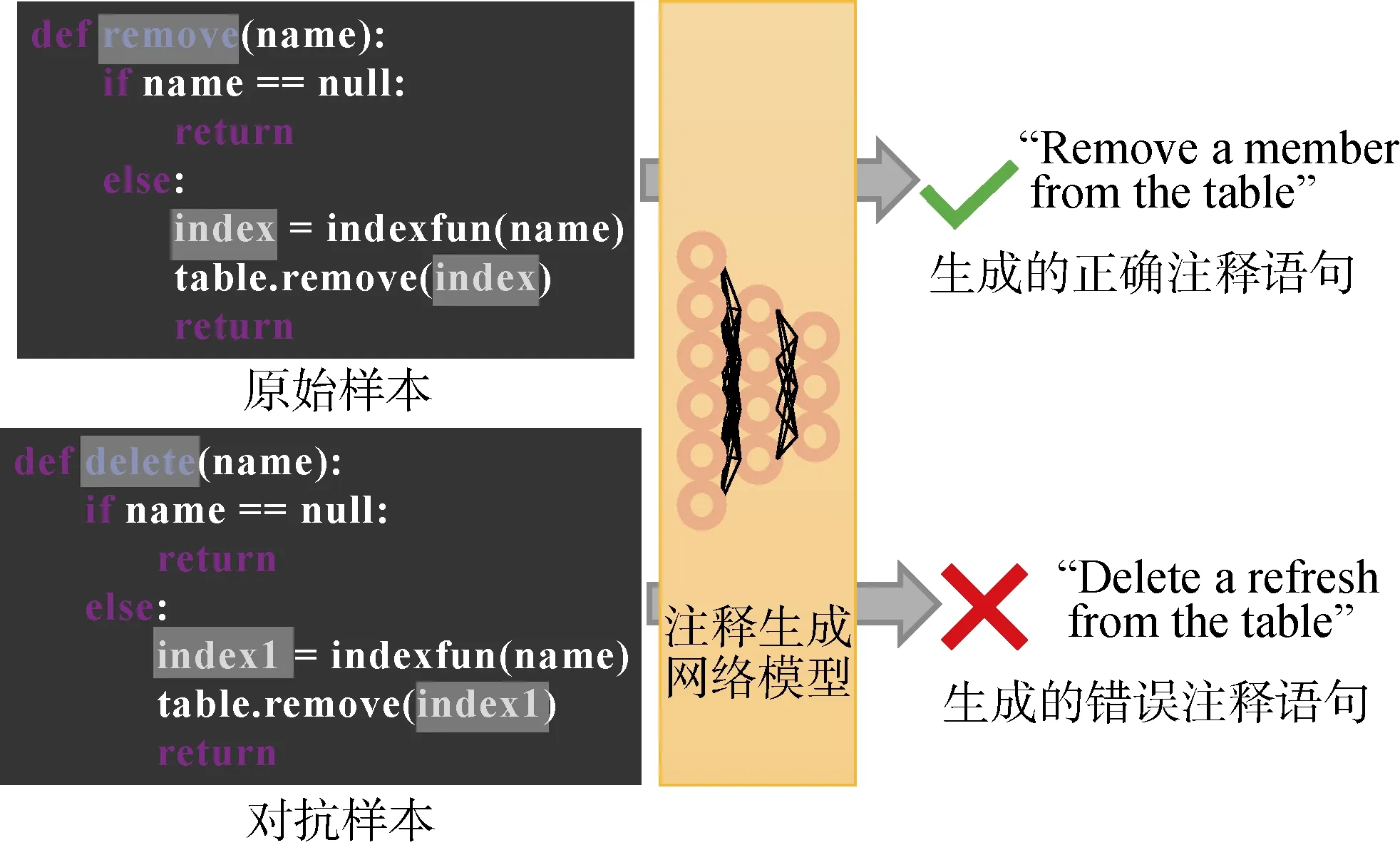
图5 对抗样本示例Figure 5 Adversarial examples
对抗学习中通常利用对抗攻击过程获取对抗样本, 随后执行对抗训练提高模型鲁棒性, 对抗攻击可分为三种方式[98]: 基于优化的方法、基于梯度的方法、基于采样的方法。与其他领域的对抗学习不同,程序语言的对抗样本必须满足程序语言的句法和语义约束。Henkel等人[99]利用梯度上升设计生成对抗样本生成模型AVERLOC, 具体的首先将程序转换为一个程序框架, 这是一个带孔的不完整的程序, 随后对于草图中的每个不同的洞, 根据梯度上升选择替换标识符, 同时还增加了额外的约束保证程序语义的准确性。该方法在Python和Java代码摘要任务上进行了广泛评估, 发现对于基于程序文本表示的注释生成模型, 经过鲁棒训练的模型比普通模型多保留了56%的原始性能。类似地, 对于基于程序树型表示的模型, 经过健壮训练的模型保留了31%的原始性能, 基于树型程序表示的代码摘要模型更容易收到对抗攻击的影响。另外对抗训练对跨语言模型迁移的影响不明确, 使用Java语言训练的鲁棒性模型应用到Python语言数据时, 对抗训练的F1值下降约3%; 但是, 在Python训练和Java评估的相反任务中, 鲁棒性训练的F1值提高约4%。
Srikant等人[100]将对抗性程序代码生成问题转化为一个有约束的组合优化问题, 他们设计出一种基于PGD(Projeccted gradient descen)的一阶优化算法,该算法可以利用程序混淆技术生成对抗样本, 具体地, 算法可以有效确定对抗样本的混淆转换位置及转换方式, 并且不受语言约束, 可以对不同语言的程序应用多重混淆转换方法。该方法在注释生成任务上进行了测试, 在数据集[70,101]上与最先进的对抗生成算法[99]相比, 攻击成功率提高3.29%~14.18%。
Zhou[102]等人提出一种专门针对代码注释生成任务的对抗样本生成方法, 该方法将对抗样本的生成转化为最大优化问题, 首先提取代码片段中的标识符构建为候选集, 随后为每一个标识符确定与其余弦相似度最近的K个标识符作为子候选集, 根据其对生成的代码注释的影响及与程序的上下文关系,从这些子候选集中的标识符中确定最佳候选标识符,最后将标识符替换为其最佳候选标识符, 从而生成对抗样本, 同时作者提出一种新的对抗训练算法即掩码训练方法, 该方法通过遮蔽部分输入程序中的标识符对注释生成模型进行对抗训练从而提高模型的鲁棒性。
除了针对注释生成任务的对抗学习方法之外,也有学者研究了其他程序语言相关的对抗学习方法及对抗样本生成方法, 这些方法虽然未直接应用于跨NL-PL生成任务, 但是我们认为这些程序对抗样本的生成方法对跨NL-PL生成领域的对抗学习研究具有重要的借鉴意义。Yefet等人[95]提出了DAMP,该方法利用梯度信息为程序生成对抗样本, DAMP会对模型的输出结果进行预测, 在保持模型权重不变的情况下, 根据梯度信息来修改输入代码, 从而生成对抗样本。Bielik[96]等人提出一种基于最大优化的对抗样本生成方法, 该方法首先将程序转化为图,利用图神经网络在不降低模型精度的情况下删除最大数量的图边, 这样可以减少代码长度进而减少生成的冗余对抗样本数量, 该方法在基于树型和图表示的代码类型生成模型上进行实验, 模型的鲁棒性提升约15%; Zhang等人[98]提出一种基于MHM(Metropolis-Hastings Modifier)采样方法的标识符重命名技术为以源代码为输入的模型生成对抗样本。通过在候选集中选择源标识符和目标标识符, 并判断接受和转换的概率决定是否进行标识符替换从而生成对抗样本。对以LSTM为主体模型的对抗训练中, 对抗样本的攻击成功率达到71.3%, 与已有方法[103]相比提高61%。
相比于工业界, 学术界人力物力资源较少, 很难大规模收集并预训练数据, 因此主要在程序表示、网络模型、优化算法、模型安全性等方面进行更深入的研究, 在程序生成任务方面, 也常通过添加额外的先验知识来提高模型的生成效果, 随着计算能力的提升, 与程序生成任务类似, 近年来注释生成领域使用预训练方法的研究颇多, 但目前用于商业化的模型相对较少。
5 跨NL-PL生成网络经典数据集与模型效果比较
5.1 经典数据集
为构建可靠有效的基于DL的跨NL-PL生成网络, 需要大规模权威性标准数据集, 我们总结在基于DL的程序生成和注释生成任务中比较常用的13个数据集, 由于两个任务的对偶性, 其中4个数据集为共用数据集, 剩余9个为任务限定数据集, 根据我们的调研其尚未应用在另一个任务中,数据集统计结果如表6。

表6 数据集对比Table 6 Comparison of datasets
如2.1节所述, 共用数据集CoNaLa[12]源自在线编程问答论坛StackOverflow, 该网站中每个编程问题包含一个简短的英文问题标题、一个详细的问题描述和众多评论者给出的答案, 这些答案通常是代码片段, CoNaLa数据集收集每个问题的英文标题和对应的Python语言编写的代码片段, 为自动收集大规模数据集, 作者定义了详细的数据集标注协议并开发了自动挖掘工具, 最终, 该数据集由手动管理的2.9K条并行数据和通过自动挖掘工具收集的600K条数据构成, 比较常用的为手动管理的2.9K数据。该数据集在程序生成任务中以摘要作为输入, 以程序片段作为输出, 在注释生成任务中相反。ATIS数据集[55]由5.4K个机票预订系统的自然语言查询语句与对应的λ演算公式组成。CoNaLa和ATIS数据集在Dahal[42]等、Jiang[41]等人的程序生成工作和Cai[22]等人的注释生成工作中均获得应用。CodeSearchNet[104]和CodeXGLUE[105]是用于预训练的多语言数据集, 包含大量单语和注释对样本, 在文献[1,77,83,85]中应用于基于DL的程序生成和注释生成任务。前者收集来自GitHub 的6种编程语言的代码及其注释, 经过预处理, 该数据集包含约200万对函数-文档对和约400万没有相关文档的函数; 后者由14个不同的数据集组成, 其中包括8个其他研究已公开的数据集, 例如CodeSearchNet[104]。CodeXGLUE数据集适用于10种不同的任务, 包括程序生成和注释生成任务。
对于仅用于程序生成任务的数据集可分为两类。一类是卡牌相关的数据集, 包括Python数据集HS[13]和Java数据集MTG[13], 这两个数据集在2016年被提出, 并在众多文献[13,38-40,54]中获得应用。HS和MTG数据集分别来自在线卡牌游戏HeartStone(HS)和Magic the Gathering(MTG), HS游戏中, 玩家持有的卡牌对应10种类型的属性如: 攻击力、生命值、稀缺性等, 每类属性对应一组不同的属性值, 基于不同的属性值集合可生成不同的Python类级别攻防技能代码。MTG则是包含10种类型属性值的Java数据集。除了卡牌相关的程序生成数据集, 也有学者创建注释语句和程序片段的数据集。E-JDT[106]为Allamanis等人从GitHub收集的588K规模的Java数据集, 该数据集样本由Javadoc中出现的注释语句和Javadoc指南中的Java代码组成。Oda等人[11]在2015年为Django Web应用程序框架创建伪代码, 得到一个包含Python语句和相应的英语伪代码的语料库, 该语料库包含约19K数据, 用于英文伪代码到Python语句的程序生成任务研究。工业界, 程序生成领域的预训练数据集通常由各企业从Github平台收集, 常用评估数据集为HumanEval[14]数据集, 该数据集由人工创建的164个问题, 及对应的Python程序函数签名、注释语句、主体和单元测试实例组成,单元测试实例即几组符合程序功能的输入输出实例,可以判断生成的程序样本能否根据给定输入获得相应的输出结果, 从而判断生成的程序代码能否编译成功以及功能是否准确, 平均每个问题约有7.7个单元测试实例。该数据集可以评估程序语言任务中语言理解、推理、算法和简单数学等多方面内容。
对于仅用于注释生成任务的数据集, Barone等人[16]、Wan等人[15]以及Hu等人[6]创建了目前使用最广泛的注释生成数据集。Barone等人[16]创建了PCSD数据集, 他们从GitHub提取一个包含函数声明、函数主体和文档字符串的并行主语料库, 并通过数据增强技术增加样本数量, 最终获得约150K个样本;同时创建由函数声明和函数体组成的纯代码语料库,规模达到160K。Wan等人[15]在Barone等人[16]创建的数据集基础上, 使用AST解析工具为108726个样本创建对应的程序AST, 在众多基于树型和图表示的方案[19,24,44,45]中获得应用。TLC数据集[6]使用Eclipse的JDT编译器将Java源代码解析为AST树,然后提取方法、方法内的API序列以及相应的Javadoc中的注释, 最终获得用于注释生成任务的API序列、代码及注释对, 文献[4,19,33,44-46]的实验中都使用了该数据集。Leclair等人[107]在2019年发布一个超过210万对Java方法和方法描述语句的Java注释对数据集。2021年Hasan等人[108]公布一个由420万个Java方法和自然语言描述组成的大型并行数据集CoDesc, 该数据集从多个已公开数据集如:CodeSearchNet[104]、DeepCom[5]等多个来源收集数据,随后作者进一步为不同来源的数据的清理制定有针对性的规则, 使其消除重复数据、XML标签等噪声。
5.2 模型效果分析
在跨NL-PL生成任务中, 常用的自动评价指标有ACCURACY、BLEU、Smoothed BLEU-4、CodeBLEU、METEOR、ROUGE和Pass@k[14]等。ACCURACY指生成的正确样本占总生成样本的比例, 该指标用于度量生成的内容是否与参考内容完全匹配。BLEU指标[109]基于Precision指标设计, 即计算在生成样本中, 与参考样本匹配的n元词组(n-gram)占生成样本中n元词组总数的比例, 用于比较生成内容与参考内容中的重合度, 根据n的不同可以分为BLEU-1/2/3/4, 分别对应一元词组、二元词组、三元词组和四元词组的重合程度, 随着n增大该指标可以进一步衡量生成文本的流畅度。目前注释生成领域常用Smoothed BLEU-4[110]作为评价指标,该指标在原来的BLEU-4计算过程中加入平滑技术,可以更有效计算较短候选句子的BLEU值。在2020年, Ren等人[111]提出CodeBLEU指标, 该指标在BLEU指标计算基础上考虑了生成代码在语法和语义方面与标签样本的匹配度。ROUGE指标[112]基于Recall指标设计, 即计算在生成样本中, 与参考样本匹配的n元词组占参考样本中n元词组总数的比例,该指标又可以细分为ROUGE-N和ROUGE-L, 其中ROUGE-N指标以n元词组为基本单元, 而ROUGE-L指标计算最长公共子序列的重合率。METEOR指标[113]计算Precision和Recall的乘积占二者加权平均数的比例, 考虑到生成内容语义方面的评价问题, 该指标使用WordNet等知识源来扩充同义词集, 同时为了反应单词顺序之间的差异引入惩罚系数, 该惩罚系数基于生成文本和参考文本的语序计算。由于METEOR指标同时考虑了Precision和Recall, 并且考虑到文本的语序, 因此可信度更高。Pass@k[14]是近年来程序生成常用评价指标, 即使训练好的模型为每个问题生成k个代码片段, 如果这些代码片段中有一个通过所有单元测试实例的检测则认为该问题可解决, 换言之, Pass@k指标用于评估模型解决问题的比例。k越大, 对于每个问题可生成的代码样本越多, 通过测试的概率通常越大,模型得分越高。由于程序生成任务最终目的为生成可以应用的程序代码, 因此程序功能是否可编译及功能是否正确是众多学者关注的问题, Pass@k指标考虑了上述问题, 因此是当前比较流行的程序生成评价指标。
由于目前自动评价指标只能反映生成样本与参考样本的表层关系, 无法区分深层语义关系, 无法判断生成内容是否冗余等, 因此也有一些人工评价方案。但是人工评价略显主观, 不确定因素较多且效率较低。人工评价方案的侧重点一般主要检测生成内容的流畅性、信息性、相关性等方面内容, 流畅性指句子是否符合语法和逻辑, 拼写是否正确; 信息性指生成内容是否包含主要信息; 相关性指生成的内容是否与目标相关, 不应该与预期生成内容相差太大。
学者们在优化基于DL的跨NL-PL生成网络过程中实现了模型效果的不断提升。结果如表7。程序生成任务早期模型准确率和BLEU值都比较低, 在HS[13]数据集上准确率均低于20%, BLEU值无法超越78%, 2016年的文献[13]的准确率和BLEU分别为6.1%和67.1%。2020年TreeGen模型的提出使得在HS数据集上的准确率和BLEU值分别达到31.8%和81.80%。2021年提出的文献[54]在F1值等其他指标上超越了TreeGen, 在准确率和BLEU值方面分别为27.3%和78.1%, 仍无法超越TreeGen。CoNaLa数据集提出时间较晚, 在2021年该数据集上模型的BLEU值从低于31%的结果[8]达到32.57%[29]。在生成代码可编译性和功能准确性方面, 文献[14,88-90]均考虑到上述问题, 采用HumanEval[14]数据集来评估程序功能可用性。在HumanEval数据集上, 相同参数量级别的情况下, PANGU-CODER结果最优, 在317M、2.6B参数量级下, 其Pass@1分别为17.07%和23.78%, 超过了Codex和AlphaCode。在6B量级的模型中, CODEGEN-MONO的Pass@1取得了最优结果26.13%。通常k可以取1, 10, 100等值, 表5仅展示k取1时的模型效果对比。
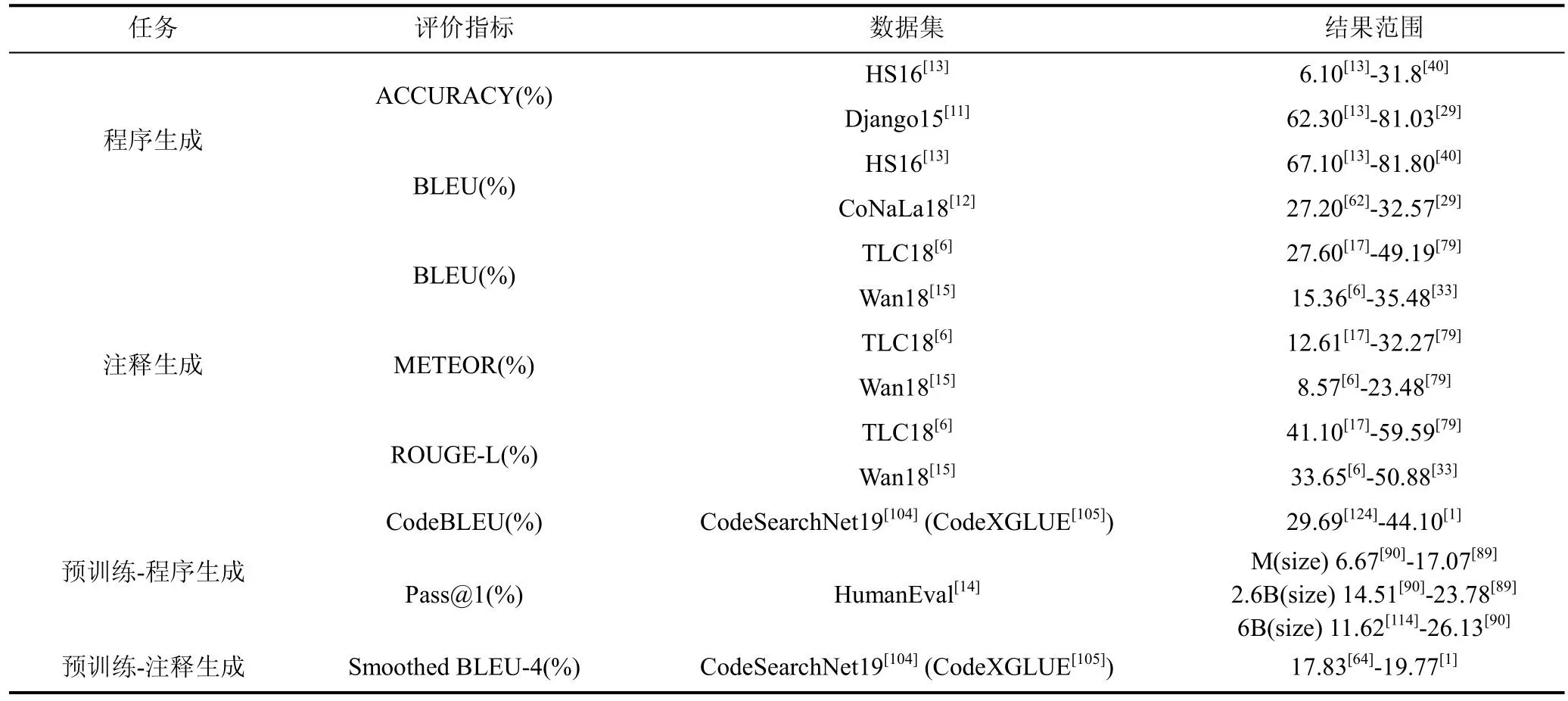
表7 基于DL的跨NL-PL生成任务实验结果的对比Table 7 Comparison of experimental results of DL-based generation tasks across NL-PL
2019年之前的注释生成成果在Java[6]数据集上的BLEU值大多低于40%[5,15,17,65]。2019年Wei等人提出的对偶模型达到42.39%, 随后文献[44]获得45.49%, CODESCRIBE[79]达到49.19%。另外,CODESCRIBE模型在METEOR和ROUGE-L指标也达到目前最优结果, 分别为32.27%和59.59%, 与2021年Choi等人[44]提出的模型相比效果均提升约5%。对于在Python[15]数据集上的实验结果, 在2020年之前, 大多文献的BLEU结果低于20%。Ahmad等人[19]在2020年提出的方案达到32.52%, 实现了较大突破, 2021年Choi等人[44]提出的模型BLEU值获得32.82%, CODESCRIBE[79]则达到35.11%, Chen等人[33]提出的模型效果超越CODESCRIBE达到35.48%, 在Python[15]数据集上METEOR和ROUGE-L值分别在文献[79]和文献[33]达到最优, 分别为23.48%和50.88%。
6 总结与展望
本文通过对众多研究工作的回顾和分析, 对基于DL的跨NL-PL程序生成和注释生成研究工作进行分类梳理, 从任务建模、代码表示及网络模型设计、模型应用及安全性、数据集及模型效果等方面进行了详细描述。在未来的研究方向方面, 我们提出以下几点思考:
6.1 小样本学习
目前, 跨NL-PL生成任务的标注数据集规模已越来越庞大, 如表6所示, 本领域数据集大小已由小于1K的数量级发展到420万条。大规模数据集虽然可以提升生成效果, 但预处理步骤复杂, 收集和标注成本尤为昂贵。解决数据收集和标注困境的一个方案是小样本学习, 小样本学习是指用少量的注释实例进行新任务学习的模式。实现小样本学习的方法众多, 由于大规模的预训练语言模型已经证明了通过微调有效学习新任务的能力[87], 因此, 涌现出许多利用预训练语言模型进行小样本学习的工作,Schick等人[115]提出模式开发训练(Pattern exploiting training, PET)范式, 该方法利用人工编写的完形填空提示符结合预训练语言模型微调方法训练小样本学习模型, 学者们在该范式的基础上提出了众多改进模型[116-117]; 另外也有一些无需使用语言模型的小样本学习的成熟方法, 包括数据增强、半监督学习、一致性训练和协同训练等。小样本学习不需要大规模标注数据, 学习成本较小, 因此建议为跨NL-PL生成任务构建小样本学习模型, 节省昂贵的数据收集和标注资源。
6.2 程序语言表示融合
程序语言的表示及对应模型的改进一直以来都是学者们的研究重点, 目前程序的表示逐渐多样化,模型结构与程序表示相辅相成, 也各有不同。Wu等人[45]通过精心构造AST、控制流、数据依赖等树型信息表示程序并设计结构引导的Transformer模型,证明多种程序表示融合可以有效提升模型的实验效果, 因此建议研究人员可以设计能够更加充分表示程序语言信息的程序表示方法, 如文本、树型和图结合的程序表示方法; 同时, 设计能够更有效捕获程序信息的生成模型, 在充分学习并捕获程序信息后,模型才能更好地生成目标内容。
6.3 自动评价指标优化
如5.2节介绍, 目前注释生成任务主要以BLEU、ROUGE、METEOR及基于这些模型改进的自动评价指标衡量模型效果。但这些指标大多只考虑输出内容与参考样本的n-gram重叠程度, 无法准确衡量生成注释在语义方面的效果[118-119]。近年来,在自然语言生成领域, 学者们针对自动评价指标无法高效、全面评价生成内容质量的问题提出众多优化方案, 包括: Vedantam等人[120]提出的基于n-gram优化的指标CIDEr; Stanchev等人[121]提出的基于文本相似性距离的指标EED; Mathur等人[122]提出的基于预训练词嵌入的指标BERTr等; 同时也有学者设计可学习的网络模型[123]用于自动评价生成任务效果。这些方法在评价生成内容的流利性、充分性、连贯性、信息量等方面分别具备计算效率高、语义理解更充分、稳健性强、评价更全面等优势。因此, 有必要将自然语言生成任务的这些评价指标或方法引入注释生成任务, 这样有助于更准确地评价跨NL-PL生成任务效果。程序生成任务目前常使用Pass@k指标, 该指标关注到了生成代码是否可用问题, 是目前比较完善的评价指标。
6.4 可解释性研究
目前对跨NL-PL生成模型的可解释性研究较少,但可解释人工智能(Explainable artificial intelligence,简称XAI)是深度学习领域研究的热点问题, 该领域的发展可以帮助研究人员更科学、更有针对性地设计跨NL-PL生成模型。因此, 跨NL-PL生成模型的可解释性研究是一个非常有前景的研究方向, 建议将自然语言处理、计算机视觉等领域的可解释性研究方法引入跨NL-PL生成模型的研究中, 用于揭示模型中的特征捕获原因、特征捕获方式、模型决策方式等部分的可解释性。
