基于特征分布差异的对抗样本检测
2023-07-06俞伟平周依云杜文涛孙彦斌林昶廷
韩 蒙 , 俞伟平, 周依云, 杜文涛 孙彦斌, 林昶廷*,
1浙江大学 杭州 中国 310007*
2杭州涂鸦科技有限公司 杭州 中国 310010
3CareerBuilder 芝加哥 美国 60601
4广州大学 广州 中国 510006
5浙江君同智能科技有限责任公司 杭州中国 310051
1 引言
深度学习在多个预测任务中广泛应用, 如图像分类[1]、语言翻译[2]及语音分析[3]等。然而, 其模型的鲁棒性也备受学术界和工业界关注[4-5]。大量深度学习模型应用在高要求的关键领域中, 因此模型在应对对抗样本攻击时所具备的鲁棒性便显得尤为重要。对抗样本通常指由敌手明确设计且不易察觉的扰动输入, 用以误导某个目标深度学习模型。对抗样本会对日常生活中高要求和关键应用的安全构成严重威胁, 比如自动驾驶、监控系统[6]和生物识别验证[7]等领域。
为了降低对抗样本攻击所带来的安全性影响,诸多解决方案被学术界和工业界所提出, 但这些方案均存在相关缺陷。如对抗性训练[8]和防御性蒸馏法[9], 这两类方法都只能在模型训练期间提高模型的鲁棒性。另一类方案则利用输入转换方法的防御措施减轻恶意扰动[10]。然而, 该类方法并不能有效适应生成对抗样本变化, 同时还需要改变原始模型的训练过程。由于这些局限性, 当前学术界的研究方向主要聚焦于针对对抗样本的检测。现有的检测方法一般利用已知攻击的对抗样本, 训练与原模型分离的对抗样本检测分类器[11], 或在原模型中增加一个额外的对抗样本类别进行分类[12]。另外, 还有相关研究利用原始输入和转换后的输入之间的模型结果差异检测对抗样本。然而, 这些方法在面对不同攻击生成的对抗样本时, 其鲁棒性有限。
本文研究神经网络模型中, 其输入的原始自然样本和对抗样本在不同隐层上, 表现出的特征分布差异。基于实验结果, 确定了一种利用特征分布差异进行对抗样本检测的方法。本文的实验结果表明, 源自同一类别样本的隐层表示往往逼近于同一分布,而对抗样本的特征表示在某些层上与原始自然样本的分布则有所不同。主要原因为, 攻击者为了达到攻击效果, 对抗样本的特征表示必须至少在输出层前偏离原始自然样本的特征表示。由于每一层的特征表示都是不同层输入特征的抽象提取, 因此对抗样本可能在某一层具有不同于原始自然样本的特征表示。通过构建隐层的统计特征来捕获训练数据集中数据在确定层上的隐藏特征分布, 若隐藏特征表示与统计特征有较大偏差, 基于本文提出的方法则可以识别出对抗样本。本文的实验结果也证明了该检测方法的有效性。
1.1 相关工作
迄今为止, 已有大量工作针对模型推理期间的对抗样本检测进行研究[13-14]。其中, 对抗样本检测方法通常依据以下理论: 给定一个K类别的神经网络分类器, 原本的训练集为, 构建一个对抗样本集, 然后设计一个检测方法区分D′和D。
Gong等人[9]提出了一种二元分类器, 以高精度分离对抗样本数据和干净数据。同时本文作者还发现, 二进制分类器对对抗攻击算法较为敏感。具体来说, 在FGSM样本上训练的二进制分类器对JSMA样本不具备鲁棒性, 反之亦然。然而, 如果分类器在FGSM和JSMA的混合对抗样本上进行训练, 则分类器可以以较好的性能检测出两者。Grosse等人[15]将“攻击”类添加为模型的异常值类, 用干净和对抗性数据一起训练模型。Metzen等人[11]通过使用中间层特征作为输入数据来识别D′和D来构建检测器。检测器可以通过发现在附近类边界的特定方向上稍微偏离干净数据流中心的输入来识别对抗样本, 该类边界泛化为未知数据, 需要某些扰动规律。然而,Carlini等人[16]指出, 检测方法在识别具有强攻击的自适应敌手时效率将显著降低。为了应对这一挑战,作者提出了一种范数约束的对抗样本检测器方法,该方法保证识别潜在威胁。Lu等人[17]提出使用每个ReLu层输出的二进制阈值作为对抗样本检测器的特征, 并通过RBF-SVM分类器识别对抗样本。Lu等人[17]还表明, 即使对抗样本知道检测器, 其方法也很难被对抗样本所攻破。
Feinman[18]则通过研究对抗样本的预测置信度,提出一种贝叶斯神经网络实现对抗样本和原始干净数据的有效区分。Meng等人[19]不仅实现了对抗样本检测, 还利用了一个改型自动编码器将对抗样本移向正常样本的流形, 这对于在小扰动下正确分类对抗样本极为有效。Pang等人[20]提出训练反向交叉熵,以实现鼓励DNN通过潜在表示将对抗样本与干净数据区分开。反向交叉熵采用DNN对目标类具有较高的置信度并且在其他类上具有相似的分布。相较标准交叉熵最小化方法, 该方法实现简单, 额外计算成本更少。
1.2 本文贡献
在实验中, 本文发现当D′和D中的样本映射到神经网络隐层中的学习表示时,D′和D的样本统计特征可以被区分。神经网络模型的中间隐层捕获并抽象样本信息, 利用此信息对抗样本与干净样本则更易被区分。本文利用表示特征的Z-Score异常值补偿的统计工具, 提出基于特征分布差异的对抗样本检测框架。本文的贡献点可总结为如下几点:
· 提出了一种基于特征分布的对抗样本检测框架, 该框架分为广义对抗样本检测方法和条件对抗样本检测方法, 利用特征分布的信息可以从一个崭新的维度展开检测;
· 构建的对抗样本检测方案具备较好的检测能力, 能有效检测并区分不同攻击产生的对抗样本, 同时还能对不同类型神经网络所产生的对抗样本进行有效识别;
· 除在理论上可对特征分布及特征提取技术领域提供参考, 通过与多个当前先进算法进行对比实验, 其结果表明本文所提出的算法和框架可以利用隐层信息检测出对抗样本。
2 检测框架
如图1所示, 本文利用神经网络模型的记忆特性设计了对抗样本检测框架。神经网络模型的记忆特性是指模型的隐藏层可以全面捕获并提取数据的抽象特征信息。虽然原始干净数据D和对抗样本数据D′的统计特征很难在数据集层面上被直接区分, 但本文利用隐层的抽象特征信息区分出干净数据和对抗样本, 这也是隐层表示的统计特征差异可用作对抗样本检测方法并提高模型鲁棒性的最初动机。
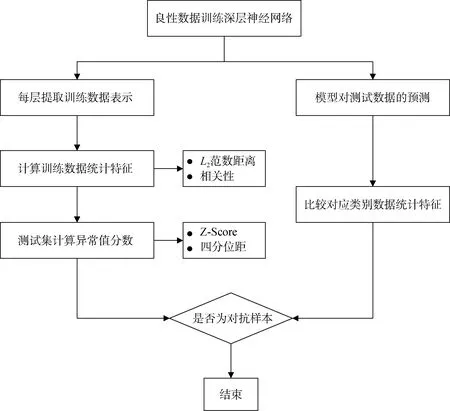
图1 对抗样本检测框架图Figure 1 Adversarial samples detection framework
本文所提出的检测框架包含两种检测对抗样本的方法: 广义对抗样本检测方法与条件对抗样本检测方法。对于这两种检测方法, 都需要先在干净的训练数据上训练深层的神经网络模型。具体地, 在广义方法中, 本文在每个隐层中提取学习到的训练数据表示, 然后计算训练数据的统计特征, 并利用它们为可能包含对抗样本的测试集计算出异常值分数;在条件方法中, 本文首先得到深层神经网络模型对测试数据的预测结果, 然后与对应类别的训练数据比较统计特征表示。另外, 本文在该框架中应用了两个统计特征, 一个是到原始数据的L2范数距离, 另一个则是与样本协方差矩阵的顶奇异向量的相关性。对于每个测试数据, 本文计算异常值分数, 如果异常分数超过某一阈值, 则判定其为对抗样本。上述两种方法均可检测出隐藏层中的对抗样本。
2.1 隐层表示的统计特征
为了使用统计特征来区分来自D的干净训练数据xi以及来自D0的对抗样本xj′, 本文假设D的隐层表示遵循正态分布, 并且在某些层上与D0隐层表示的统计特征截然不同。
在实验中, 本文发现当D和D0映射到神经网络的特征表示时,D和D0的统计特征相互分离。神经网络模型的中间层会捕获D0中的信号, 从中间层中更容易区分对抗样本。因此, 本文利用相关统计工具,如Z-Score异常值检验, 在隐层表示上检测对抗样本。在第4节中, 本文通过实验展示了如何有效地删除D0, 并防止对抗样本的潜在威胁。本文提出的框架也可以推广至任何其它深度神经网络, 且不需要过多的计算成本。对于隐层的统计特征, 本文则考虑计算训练样本的L2范数, 其与训练样本协方差矩阵的随机向量和顶奇异向量的相关性。
通过图2和图3可以发现, ResNet神经网络不同层下, 对抗样本分布与干净训练数据L2分布之间存在一定的分布差异。图2展示了数据点分布的L2范数, 即在数据层级中通过基本迭代方法BIM(Basic Iterative Method)生成的对抗样本和干净训练数据一般位于相同分布中。然而, 在隐藏层中, 模型将增强或减弱对抗性样本的信号, 使得对抗样本与干净数据分离。同样地, 如图3所示, 通过DeepFool方法所生成的对抗性样本, 在不同的表示层上具有相似的属性。在ResNet神经网络中, 两种对抗样本具有不同的分离级别。由于无法得知哪一隐层表示的统计特征最适合分离对抗样本, 为了有效识别未知攻击,因此本文在DNN的每一层中检测对抗样本。

图2 BIM对抗样本和训练数据L2分布Figure 2 L2 distribution of BIM adversarial samples and training data
传统的CNN操作可以形成迁移学习表示, 因此,本文提出的检测框架能够识别各种神经网络结构中不同类型的对抗样本。在该项工作中, 本文在框架中应用了两个统计特征: 一个是到原点的L2范数距离;另一个则是样本协方差矩阵的顶奇异向量的相关性,对于每个测试数据点, 计算异常值分数, 若分数超过阈值, 则认为该测试数据为对抗样本。
2.2 通过统计特征检测异常
首先, 本文需要计算训练数据集的统计特征。本文将训练好的模型应用于测试数据, 比较测试数据和训练数据之间的统计特征, 一些隐层的特征表示可以很好地检测对抗样本, 而一些层则无效。数值线性代数中最常用的矩阵范数则是Frobenius范数[21],其L2范数定义为:
为了得到另一个统计特征, 本文需要在每一层计算训练数据集的奇异值分解(SVD)表示。奇异值分解是一种矩阵分解方法, 其提取矩阵的抽象表示,可以删除不太重要的信息并降低矩阵维度。定义一个秩为r, 维度为m*n的矩阵A, 本文可以找到两个正交矩阵U,V和一个对角矩阵σ满足以下公式:
矩阵A的维度是m*n, 包含V的奇异向量, 这里考虑V是A的m个样本的n维空间中的最佳拟合线,矩阵A第i行在V上的投影是, 最佳拟合线最大化投影是|A∙v|2的长度平方和, 并最小化点到该线的距离平方和。A的第一个奇异向量v1, 也称为A的协方差矩阵的顶奇异向量, 定义为:
2018年, Tran等人提出了鲁棒性的统计指标[22],即ai与v1的相关性, 并实现了利用隐层表示识别深度学习模型中的后门攻击。本文参考该做法, 利用各隐层中的这些指标来检测对抗样本, 可将其定义为:
本文假设干净数据样本L2范数和表示层中第一个奇异向量的相关性服从正态分布。对抗样本D′与干净训练数据D在数据层级上位于相同的分布中,但是D′在某些隐层表示上可能是可分离的。即本文可以应用异常值检测方法, 通过学习表示的统计特征来识别D′。
一种方法是Z-Score异常值检测。在该检测过程中, 本文计算每个可能包含对抗样本测试数据的Z-Score, 若观察值Z-Score的绝对值大于3, 则被视为异常值, 在本研究中Z-Score被定义为:
这个方法遵循经验法则, 因为几乎所有(99.7%)数据的Z-Score绝对值都会在3之内。
另一个方法是四分位距IQR(Interquartile Range)规则, 本文需要获得第一四分位数Q1和第三四分位数Q3的值, 代表训练数据特定统计特征值的四分之一和四分之三。这里四分位距的值为第三四分位数减去第一四分位数后的结果, 如下所示:
计算出测试数据的统计特征值, 任何大于Q3+1.5 *IQR或小于Q1-1.5 *IQR可被认为是离群值, 即对抗样本。在本文的实验中, 这两种离群点检测方法具有相似的性能, 能够以极低的误报率识别出对抗样本D′。
2.3 分布距离
为了评估对抗样本在神经网络不同层中的敏感度, 进而选择出最佳的隐层, 本文测量两个概率分布D′和D之间的距离, 使用两个分布距离来衡量对抗样本与干净数据在不同隐层中的差异性。
本文考虑两个分布距离指标: Wasserstein距离和能量距离。Wasserstein距离是一种用来估计特征空间中两个分布之间差异性的方法, 其中单个特征之间的距离测量也称为搬土距离EMD(Earth Mover′s Distance)[23], 更具体地说, 给定两个分布,一个可以被视为在空间中充分分布的“一团土”,另一个是需要在同一空间中填充的一组“孔洞”,EMD则估算了用泥土填充孔洞所需的最小工作量。能量距离评估样本与相同或不相同维度的假设分布之间的差异[24]。
图4-图7显示了隐层表示中数据分布距离的变化。在BIM和DeepFool对抗样本中, 两个指标的结果是一致的。BIM样本在ResNet结构的开始部分和结束部分是可分离的。DeepFool样本仅在开始部分可分离。根据实验结果, 本文发现很难确定某一隐层表示最适用于对抗样本检测, 因此本文所提出的对抗样本检测框架则利用了神经网络中每一个隐层。

图5 DeepFool样本和测试数据到训练数据的EMDFigure 5 EMD from DeepFool adversarial samples and test data to training data
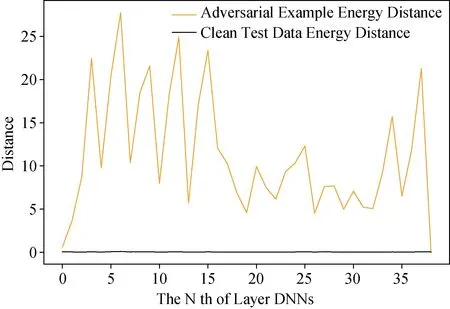
图6 BIM样本和测试数据到训练数据的能量距离Figure 6 Energy distance from BIM adversarial samples and test data to training data
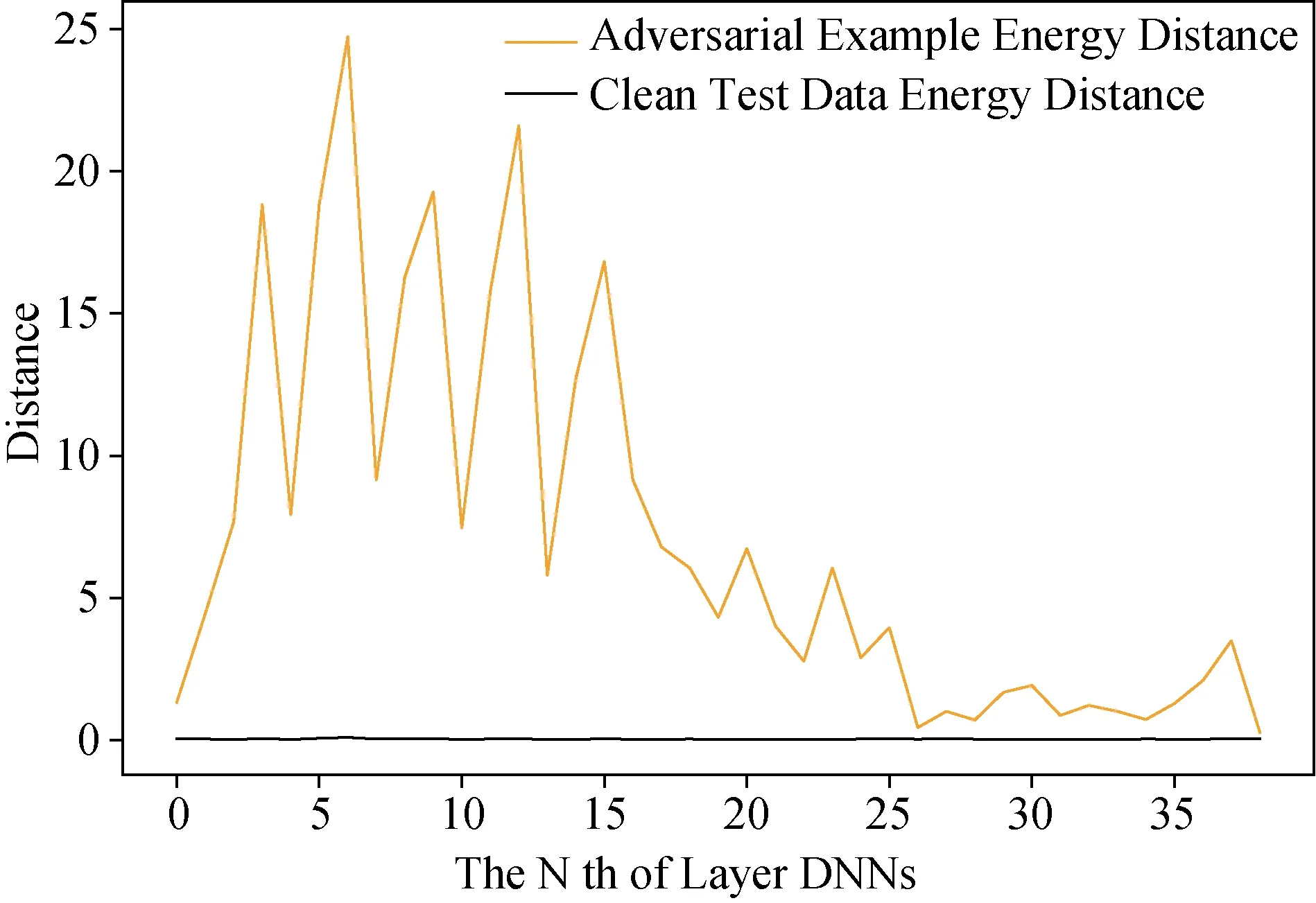
图7 DeepFool样本和测试数据到训练数据的能量距离Figure 7 Energy distance from DeepFool adversarial samples and test data to training data
3 实验
3.1 实验设置
在实验中, 本文研究了CIFAR10数据集[25]上对抗样本的特征, 在ResNet深度学习模型中测试本文的检测方法。为了生成对抗样本, 本文使用了python 3对抗样本生成工具[26]。神经网络模型中的不同层形成各种隐层表示, 通常顶部隐层被视为“高层”。实验结果表明, 防御框架在“低层”表示中能够更有效地检测对抗样本。
3.2 攻击和防御方法
本文使用三种目前最先进的对抗样本来评估检测框架: 基本迭代法(BIM)[27]、DeepFool[28]和C&W[29]。根据攻击强度级别, 可以将三个对抗样本分为: BIM-低、DeepFool-中、C&W-高。在文献[16]中, 作者表明, 通过修改C&W攻击算法中相应的代价函数, C&W方法可以打败大多数对抗性检测框架。在实验中, 本文选择32*32color CIFAR10数据集,其中包含10个类别的60000个数据观察值。本文在3块大小的ResNet神经网络上训练CIFAR数据, 分类精度达到93.42%。然后根据训练后的ResNet的梯度信息生成三种类型的对抗样本, 每种类型有1000个对抗样本。
3.3 检测框架评估
在本节中, 本文展示了基于各种统计特征和离群点检测指标的防御框架, 实验评估了广义和条件检测框架中的性能。在检测指标中, 本文利用干净训练数据集的统计特征, 然后将测试数据集统计特征与干净训练数据集中进行比较。本文还评估了将干净测试数据识别为对抗样本的假阳性案例, 并在不同的Z-Score检测方法设置下测试结果。
图8-图13展示了所提出的防御框架在神经网络每个隐藏层中的性能。一般来说, Z-Score和IQR检测方法具有相似的性能。在默认设置中, Z-Score检测器识别出偏离平均值的三个标准差的数据观察值, IQR检测器识别出高于1.5倍IQR的数据观察结果。基于扰动大小和攻击强度, 高级攻击算法生成的可检测对抗样本较少。与协方差矩阵的顶奇异向量的相关性相比,L2范数则是更好的评估统计特征。
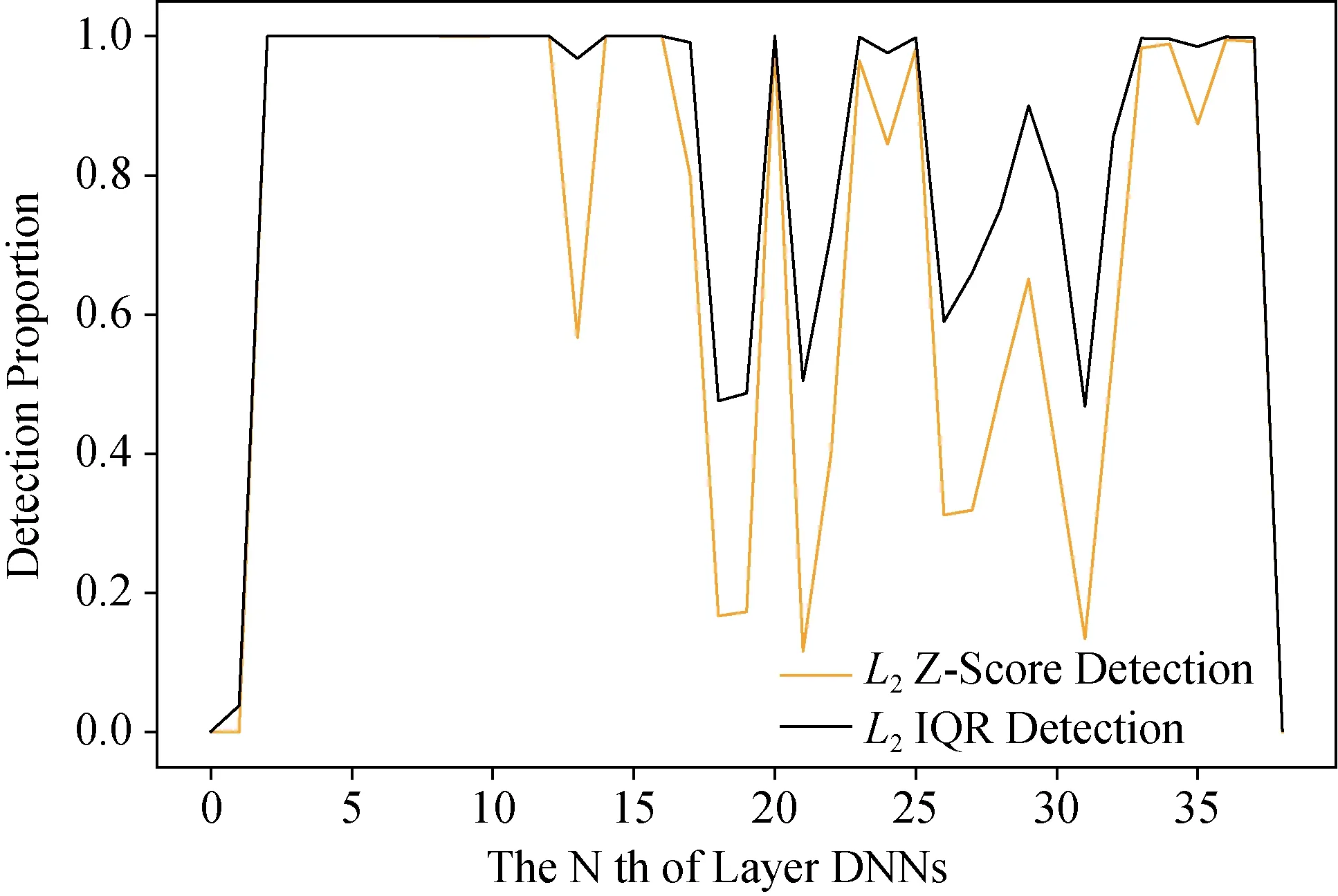
图8 ResNet不同层BIM对抗样本L2检测Figure 8 L2 detection of BIM adversarial samples on different layers of ResNet

图9 ResNet不同层BIM对抗样本顶部特征检测Figure 9 Top Eigen detection of BIM adversarial samples on different layers of ResNet

图10 ResNet不同层DeepFool对抗样本L2检测Figure 10 L2 detection of DeepFool adversarial samples on different layers of ResNet

图11 ResNet不同层DeepFool对抗样本顶部特征检测Figure 11 Top Eigen detection of DeepFool adversarial samples on different layers of ResNet

图12 ResNet不同层C&W对抗样本L2检测Figure 12 L2 detection of C&W adversarial samples on different layers of ResNet

图13 ResNet不同层C&W对抗样本顶部特征检测Figure 13 Top Eigen detection of C&W adversarial samples on different layers of ResNet
3.3.1 广义检测方法
BIM样本可以在不同的层表示中轻松检测。通过本文提出的模型可以识别所有BIM样本。DeepFool可以在“低级”特征中检测到, 但在“高级”特征中很难找到。除平坦层外, 在所有隐藏层中几乎检测不到“最强”C&W对抗样本。此外, 一些对抗样本无法在一层表示中识别, 但可以在其他层表示中检测到。聚合所有层检测结果应该是一个好的策略, 并且统计特征不会消耗太多计算能力。
除了对抗样本检测外, 误报率则是针对防御框架的另一个重要评估指标。如图14和图15所示, 除最后一层的表示外, 其他层的假阳性率极低。这表明本文需要调整检测器的参数, 并制定更严格的标准,以减轻对干净测试数据的负面影响。

图14 ResNet不同层L2检测的假阳性率Figure 14 L2 detection of false positive proportion on different layers of ResNet

图15 ResNet不同层顶部特征检测的假阳性率Figure 15 Top Eigen detection of false positive proportion on different layers of ResNet
表1展示了Z-Score检测器在2.5、3和4标准差设置下的不同性能。这意味着统计特征值大于2.5、3或4可能是对抗样本。因此, 即使有严格的标准设置, 4个标准差, Z-Score检测器仍然以非常低的假阳性率过滤出实质性对抗样本, 在两个相应的统计特征中, 从28.3%下降到6.5%, 从33.4%下降到2.3%。然而检测率并没有显著影响。BIM检测率在L2中保持不变且与顶部特征检测率一致。DeepFool的L2检测率从85.2%降到77.7%, 顶部特征检测率从76.0%降低到59.4%。比较两种静态度量的有效性,L2统计特征在对抗样本检测中更有用。顶部特征几乎不能反映C&W对抗样本的特征。

表1 不同Std标量下的 Z-Score检测精度Table 1 Z-Score detection accuracy under different Std scales
总的来说, 广义检测框架可以很好地识别未知的对抗样本, 而无需大量额外计算, 并且优于3.4中其他最先进的对抗防御模型性能。
3.3.2 条件检测方法
在条件检测框架中, 本文首先得到每个观察的预测结果, 并检测每个类别中的对抗样本。Z-Score条件检测结果如表2所示, 有意思的是, 某些类别的检测性能明显优于其他类别。船舶对抗样本易于识别, 鹿对抗样本难以识别。总体性能略低于一般检测方法。L2统计签名的性能优于顶部特征向量统计签名, 这与一般检测方法一致。
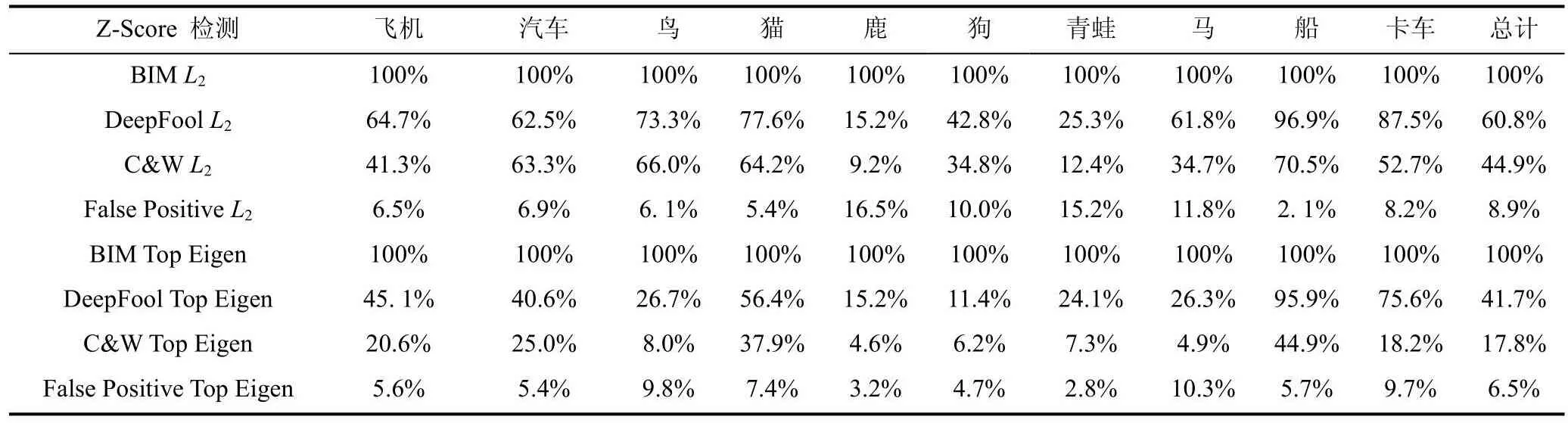
表2 Z-Score条件检测Table 2 Z-Score condition detection
如图16和图17所示, 其展示了ResNet不同层的船舶C&W对抗样本L2和顶部特征的检测结果。检测模式与一般检测方法一致, 实验结果显示: “低水平”的检测率较差, “高水平”的识别效果较好。

图16 ResNet不同层船舶C&W对抗样本L2检测Figure 16 L2 detection of ship C&W adversarial samples on different layers of ResNet

图17 ResNet不同层船舶C&W对抗样本顶部特征检测Figure 17 Top Eigen detection of ship C&W adversarial samples on different layers of ResNet
3.4 方法对比
在本小节中, 本文将提出的方法与其他最先进的对抗防御框架进行比较。文献[29]提出了一种自动架构搜索鲁棒神经网络来防御对抗性攻击。作者利用遗传算法提高了网络在每次迭代中的鲁棒性。该架构可以在对抗性样本上发展为固有的精确性。文献[30]提出了高斯数据增强方法, 以提高预测的鲁棒性。文献[31]提出了特征压缩和空间平滑来传输数据,以增强DNN对抗对抗样本的能力。
表3显示了对抗数据集上四种防御策略的预测精度。如果本文没有这些防御方法, 那么在干净的测试数据上的分类器预测是93.4%, 在对抗样本上是0.00%。注意, 与上述提出的方法相比, 本文重点关注光计算方法。因此, 本文仅利用高斯增强、空间平滑和特征压缩作为去噪变换器来消除对分类器的扰动影响。结果表明, 这些防御处理器的性能比本文提出的方法差。有趣的是, 虽然这些框架防御对于强对抗样本(C&W)更好, 但在“弱”对抗样本中表现相对较差。对于DeepFool和C&W对抗样本, 集成方法效果不佳, 空间平滑显著提高了预测精度。通过上述实验可得出结论: 各种对抗样本具有不同的属性,很难确定哪种防御方法最适合目标分类器。

表3 其他防御框架性能Table 3 Performance of other defense frameworks
4 讨论与总结
本文解释了统计特征的概念, 以及如何将其用于检测各种对抗样本。防御框架依赖于分类器每一层学习到的特征表示, 该特征表示可以提高原始信息的分类能力。当对抗样本混合在干净数据集中时,隐藏层的特征表示将统计特征放大, 本文通过离群点检测器在干净数据中分离出对抗样本。
通过实验发现, 在某些层中, 对抗样本表示的统计特征足以改变原本的分布, 从而可以利用检测方法进行检测。此外, 本文还证明在每一层中提取特征表示的必要性, 因为每一层的检测率是不同的,在某些隐藏层中无法检测到对抗样本, 但可能在其它层中识别。此外, 不同类型的对抗样本在每一层中都不具有相同的增强强度信号。一般性检测方法的性能优于条件检测方法,L2范数到原始点的距离是识别对抗样本的良好度量。
