某大口径自行加榴炮末敏弹识别模型轻量化研究
2023-07-05冯颖龙唐旭许耀峰王振明祁万龙刘爱峰刘建成
冯颖龙,唐旭,许耀峰,王振明,祁万龙,刘爱峰,刘建成
(西北机电工程研究所,陕西 咸阳 712099)
末敏弹是末端敏感弹药的简称,主要由爆炸式弹头战斗部、毫米波敏感器、红外敏感器、旋转伞、减速伞、弹载计算机等组成[1]。当末敏弹完成母弹飞行段弹道,到达目标装甲车上方后进入减速减旋弹道,母弹抛射两枚子弹。随后两枚子弹张开降落伞,绕铅锤线稳定旋转、扫描地面目标、并启爆爆炸式弹头战斗部毁伤目标[2]。单发末敏弹的毁伤概率是单发榴弹的26.7倍[3]。如果能对末敏弹的攻击进行有效反应来降低末敏弹毁伤效能,将显著提高地面装备战场生存能力。
目前国内对抗末敏弹主要方式是软对抗,即烟幕干扰、毫米波铝条箔片、隐身技术等[4]。上述方法需要从体系角度对现有装备重新设计,不符合现状。冯鹏鹏等[5]提出了反末敏弹武器系统拦截弹的方法,使用雷达发现和定位目标,指引拦截弹到达最佳炸点时,引爆拦截弹,毁伤末敏弹减速伞。该方法一方面对雷达探测能力要求较高,但传统雷达对末敏弹探测准确率不高,受干扰较大;另一方面对拦截弹要求较高,拦截弹需要接受雷达指令方可引爆,其成本较高。
研究发现末敏弹在发射后,经历了从“柱状”到“伞状”的形态变化,“伞状”形态特征较为明显。如果自行加榴炮基于低成本的视觉传感器第一时间提取伞状特征、发现伞状末敏弹,便有充足时间反应,驶离其攻击区域。尽管国内外基于深度学习的目标检测算法有较多研究,如FasterRCNN[6]、SSD[7]、Yolo-v3[8]、Yolo-v4[9]等。但是目前尚未对末敏弹伞状形态的捕获进行研究;并且上述模型参数较多,部署于嵌入式硬件平台中检测速度较慢,无法满足军事实时性需求。
通过构建末敏弹数据集,设计轻量化神经网络识别末敏弹,将该模型应用于嵌入式硬件平台上,使其在末敏弹形成有效攻击能力前及时发现末敏弹,提示自行加榴炮快速驶离其攻击范围,极大提升自行加榴炮战场生存能力。
1 基于轻量化模型的末敏弹识别算法
目前常用的神经网络模型较大,部署到嵌入式平台的推理速度较慢,无法满足工程化需求。笔者提出了基于轻量化神经网络的末敏弹识别算法。
1.1 构建数据集
伞状末敏弹数据需要在战场或者试验场拍摄获得,但因场地位于军事区域,较难获得。由于普通降落伞在打开时,形态与末敏弹张开的减速伞形态基本一致,背景都为天空,拍摄降落伞时都为地面视角,并且易于获取,故而采用普通降落伞数据等效伞状末敏弹数据。从互联网下载大量降落伞视频数据,剪辑得到不同视角、不同姿态的数据,构建“伞状”目标数据集,如图1所示。随机选择数据集中70%样本为训练集,20%样本作为测试集,10%作为验证集。数据集标签格式采用VOC格式,总计5 952幅图像数据,包含有48 192个标注框。

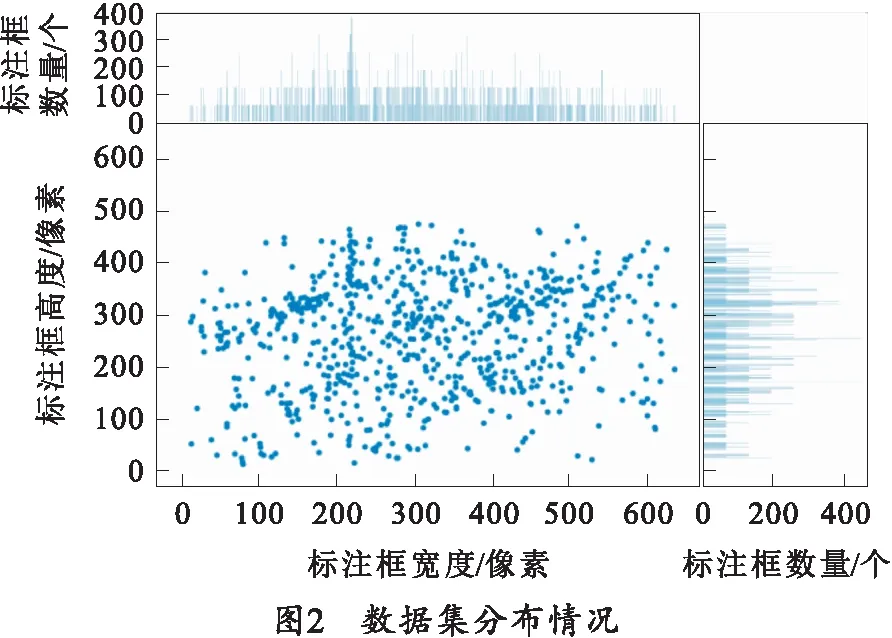
图2为数据集中目标的尺度分布情况,图中散点图横坐标为标注框宽度,纵坐标为标注框高度;散点图上方条形图为不用宽度标注框统计个数,散点图右侧条形图为不用高度标注框统计个数,从统计的标注框中可以发现,构建的数据集宽度最多集中在200 像素,高度最多集中在380 像素,总体而言标注框尺度分布较为均匀。
1.2 数据增强
为了增强数据的丰富性,融合CutMix方法和CutOut方法[10]。将图片进行规则或不规则遮挡,如图3(a)所示,然后将图3(a)中的目标信息切片,放入图3(b)中,采用Mosaic[9]方法扩充数据集,将多个图片裁剪后拼接到一张图片之中,形成新的图3(c)。为了提高目标识别中的准确率,降低背景对目标识别的干扰性,提出了背景增强的方法,一方面,将目标提取出来,贴合至不同背景图片中,如图3(d)所示;另一方面将部分背景当作空白类别,直接加入训练集中进行训练。

1.3 轻量化神经网络模型
在图像处理过程当中,卷积本身就是一种对图像特征提取的过程,笔者设计了轻量化卷积神经网络,由特征提取网络和预测网络组成。网络模型结构如图4所示。
推理过程如下:
步骤1采用MobileNetV3-small[11]的网络结构作为特征提取网络,对末敏弹图像进行特征提取,得到特征图FeatureMap1,该结构能够减少网络前向推理时间,提高网络运行速度。
步骤2对FeatureMap1特征图通过卷积、池化、激活函数、下采样等操作,得到特征图FeatureMap2。
步骤3对FeatureMap2按照图4中①②③所示操作分别提取3个不同尺度的特征图,分别为8×8×18,16×16×18,32×32×18。其中8×8、16×16、32×32为特征图大小,单位为像素,取值范围为区间[0,255]的整数;18为特征向量的维度。每个特征图有3个先验框,每个先验框包含有预测的横轴和纵轴坐标(x,y)、预测的检测框的宽高(w,h)、类别信息(class)以及类别概率共6个信息。
步骤4利用式(1)~(4)将特征图的预测信息映射到原图Img中,从而预测目标的坐标和类别。

xbox=Δx+dx,
(1)
ybox=Δy+dy,
(2)
wbox=wanchor·eΔw,
(3)
hbox=hanchor·eΔh,
(4)
式中:xbox、ybox、wbox、hbox分别为预测框中心点的横坐标、纵坐标、宽度和高度;Δx、Δy、Δw、Δh分别为预测框的偏移量、宽度与高度的缩放因子;dx、dy分别为当前网格左上方与图像左上方的偏移;wanchor、hanchor分别为先验框的宽和高。
步骤5采用两任务损失函数,分别为定位任务(Lloc)和分类任务(Lclass)损失函数,其中分类损失函数采用二数值交叉熵,使用权重系数(ξclass,ξloc)平衡两个损失函数对总损失函数(Lall):
Lall=ξlocLloc+ξclassLclass,
(5)
Lloc=1-IOU(A,B)+ρ2(Acenter,Bcenter)/c2,
(6)
式中:A为预测框;B为真实框;IOU(A,B)为预测框与真实框交并比;Acenter和Bcenter分别为预测框中心点坐标和真实框中心点坐标;ρ为A与B中心点距离;c为A与B最小包围框的对角线长度。
Lclass由两部分组成,第一部分是类别损失函数,第二部分为某一类别的概率的损失函数,
Lclass=Lclass_1+Lclass_2,
(7)
(8)
(9)

步骤6通过以上前向传播过程,预测目标的类别和位置,按照步骤5计算预测信息与真实信息的损失值,通过反向传播不断迭代调整神经权重参数,直至总损失函数值达到全局最小:
|Lall_i-Lall_i-1|≤10-6,
(10)
式中:Lall_i为第i次迭代总损失函数;Lall_i-1为第i-1次迭代总损失函数。
2 实验结果分析
2.1 硬件配置
实验软硬件平台如表1所示。

表1 软硬件平台
所有实验都在操作系统为Ubuntu 20.04的服务器运行,使用Nvidia 3080Ti的GPU训练模型;采用Android Studio开发应用程序,将量化后的模型部署到基于高通骁龙835的嵌入式平台中。
2.2 训练方法
实验中模型训练方法如下:
1)选择一部分没有目标信息的纯背景图片,令其为空白标签,加入模型训练过程中,从而提高模型对噪声背景的分辨能力,使得模型对特征提取时能够抑制背景对其干扰。
2)通过旋转、镜像对称、Mosaic等技巧扩容数据集,提高模型泛化性。
3)根据K-Means对数据集中图像标注框聚类分析,得到9个不同大小的先验框。每个先验框的宽和高分别为(90,80),(180,330),(230,150),(280,400),(300,300),(400,200),(420,300),(500,380),(600,100),将上述参数设置到模型训练文件中。
4)将训练集图片加载到GPU显存中,模型批处理大小为64,学习率为0.001,每隔10次迭代变化输入图片的尺度,提高模型对不同尺度的适应能力。
2.3 评价指标
选取推理时间、内存使用、CPU占用率来评价模型在嵌入式平台运行实时性,推理时间越小、CPU占用率越低、内存使用越小,该模型实时性越好。
选择平均准确率(Mean Average Precision,mAP)评价模型检测性能,准确率越高,模型检测能力越高。在mAP计算过程中,交并比IOU阈值设为50%,平均准确率PmAP为
(11)
式中:K为类别个数;APi为精确度和召回率曲线与X轴的积分面积。
2.4 实验结果分析
用包含4 150张图片的训练集和1 186张图片的测试集对Yolo-v3-tiny、Yolo-v4-tiny和本文模型进行训练,其中Yolo-v3-tiny和Yolo-v4-tiny加载其官方预训练模型训练,本文模型从零开始训练。
用验证集593张图片对训练后的3种模型测试,得到平均准确率PmAP。将训练后的模型量化部署于相同的嵌入式板卡中,得到3种模型的平均推理时间、CPU使用率和内存使用情况,如表2所示。

表2 本文模型与Yolo系列检测算法在嵌入式平台对比实验结果
由表2可知,对于输入608×608大小的图片,3种模型准确率均大于90%,准确率较高的原因有两个方面,该伞状目标特征较为明显,容易识别;背景为天空,背景噪声信息少且有规律。本文模型准确率相比较低的原因在于模型剪裁较多,很多有用特征的信息都被过滤掉了,但是总体都大于90%,检测结果如图5所示,实验表明,该模型准确率在实际场景中能够满足发现目标的军事需求。

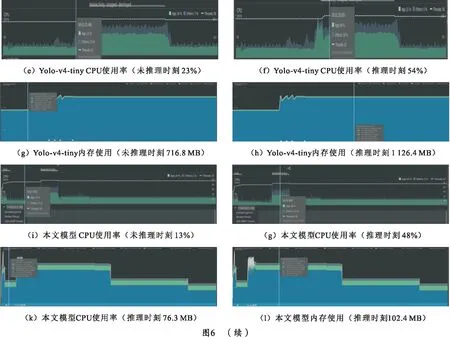
将训练好的3种模型经过量化后,分别部署于基于高通骁龙835的嵌入式开发平台上,使用Android Studio在线实时查看CPU占用率和内存使用情况,结果如图6所示。由图6可知,Yolo-v3-tiny CPU占用率从23%提高到41%,内存从409.6 MB增大至819.2 MB;Yolo-v4-tiny CPU占用率从23%提高到54%,内存从716.8 MB增大至1 126.4 MB;本文模型CPU占用率变化与上述模型相似,内存从76.3 MB升至102.4 MB。本文模型内存占用(102.4 MB)远低于Yolo系列模型(819.2 MB, 1 126.4 MB),原因在于,本文模型量化后模型参数大小为0.9 MB,在加载该模型时,模型参数较少,故而内存消耗更小。CPU占用率相差不大,是由于CPU在运行模型时,为了兼顾其他应用线程和耗电量,对该模型推理过程分配的计算能力有限,50%左右的CPU占用率已呈现出其最大占用率。
3种模型推理时间如图7所示,Yolo-v3-tiny、Yolo-v4-tiny对每一帧图像数据平均推理时间分别为129.9 ms和126.9 ms,即每秒处理7张左右图片。相比之下,本文模型平均推理时间为65.61 ms,即处理视频流频率为15 帧/s,是Yolo系列方法处理速度的2倍。


综上所述,将本文模型量化后部署于嵌入式平台,在损失3%准确率的情况下,本模型推理速度更快、内存开销更小,具有较强的边缘计算能力,能够很好地满足大口径自行加榴炮末敏弹的识别要求。
3 结束语
笔者以某大口径自行加榴炮为研究对象,针对其面对末敏弹的攻击无法有效反应、传统目标检测模型应用于嵌入式硬件平台实时性不高的问题,对末敏弹识别模型和模型轻量化进行研究。构建伞状目标(末敏弹)数据集,优化和训练模型,并部署于嵌入式板卡中。实验结果表明:设计的模型准确率为91%,相较于Yolo-v4-tiny和Yolo-v3-tiny,优化后的模型检测速度提高了7.3 帧/s,内存开销减少了716.8 MB,能够满足军事中对嵌入式板卡高实时性和低内存开销的需求,具有较高的工程应用价值。
