基于FPGA并行加速的脉冲神经网络在线学习硬件结构的设计与实现
2023-06-30刘怡俊曹宇叶武剑林子琦
刘怡俊 曹宇 叶武剑† 林子琦
基于FPGA并行加速的脉冲神经网络在线学习硬件结构的设计与实现
刘怡俊1曹宇2叶武剑1†林子琦2
(1. 广东工业大学 集成电路学院,广东 广州 510006;2. 广东工业大学 信息工程学院,广东 广州 510006)
当前,基于数字电路的脉冲神经网络硬件设计,在学习功能方面的突触并行性不高,导致硬件整体延时较大,在一定程度上限制了脉冲神经网络模型在线学习的速度。针对上述问题,文中提出了一种基于FPGA并行加速的高效脉冲神经网络在线学习硬件结构,通过神经元和突触的双并行设计对模型的训练与推理过程进行加速。首先,设计具有并行脉冲传递功能和并行脉冲时间依赖可塑性学习功能的突触结构;然后,搭建输入编码层和赢家通吃结构的学习层,并优化赢家通吃网络的侧向抑制的实现,形成规模为784~400的脉冲神经网络模型。实验结果表明:在MNIST数据集上,使用该硬件结构的脉冲神经网络模型训练一幅图像需要的时间为1.61 ms、能耗约为3.18 mJ,推理一幅图像需要的时间为1.19 ms、能耗约为2.37 mJ,识别MNIST测试集样本的准确率可达87.51%;在文中设计的硬件框架下,突触并行结构能使训练速度提升38%以上,硬件能耗降低约24.1%,有助于促进边缘智能计算设备及技术的发展。
神经网络;学习算法;加速;并行结构
脉冲神经网络(SNN)作为第三代人工神经网络,能通过神经元产生脉冲来传递信息,具有稀疏性和事件驱动特性。因此,相比于传统的人工神经网络(ANN),SNN的工作方式更加接近生物神经网络的感知和处理模式,仅需要较少的计算资源和网络层数据通信,使得能耗需求大大降低。
近年来,基于CPU和GPU的Brain/Brain 2[1]、CARLsim 4[2]等软件的出现,使得SNN的模拟仿真得以实现,但它们存在并行度低、能耗高以及不适应脉冲稀疏性等问题。硬件加速SNN的优势在于适应事件驱动、并行性高,可以加快处理速度,使用硬件数字电路构建的SNN在处理速度上往往是软件SNN的数百倍以上。因此,越来越多的研究人员投入到神经形态硬件设计领域的研究工作中[3],基于专用集成电路(ASIC)和现场可编程门阵列(FPGA)等硬件结构的神经形态平台相继被提出。相较于ASIC,FPGA设计具有可编程、成本低、设计周期短的特点,又能兼顾快速性和低功耗特性。因此,大多神经形态平台采用FPGA进行设计,并对基于神经元模型[4-5]、可塑性突触模型[6-8]、推理计算结构[9-10]以及低功耗设计[11]的FPGA设计进行了较好的优化。
在线学习能实现SNN模型的在线训练与权值的实时更新,因而也逐渐被整合到神经形态硬件平台中。相关硬件电路的实现可减少网络延迟,最小化功率[8],所以在线学习模块也成为智能物联网边缘设备[12]的必备模块之一。SNN训练方法包括反向传播有监督学习(STBP)、脉冲时间依赖塑性(STDP)无监督学习、ANN-SNN权值迁移等。STDP学习规则是一种受生物学原理启发的神经网络学习方法,文献[13]中的SNN模型与理论是STDP规则无监督训练SNN的经典应用之一,该方法是通过构建赢家通吃(WTA)结构的SNN完成图像学习和识别的任务。基于WAT结构的SNN模型[13]如图1所示,输入编码层全连接到兴奋层的每一个神经元,两层之间的连接权值使用STDP规则进行训练,兴奋层每个神经元向后连接一个抑制神经元,通过这个神经元来抑制兴奋层的其他神经元,形成竞争关系。这种情况下优先被激活的一个或几个神经元,将会在后面的竞争中具有优势,从而持续响应。
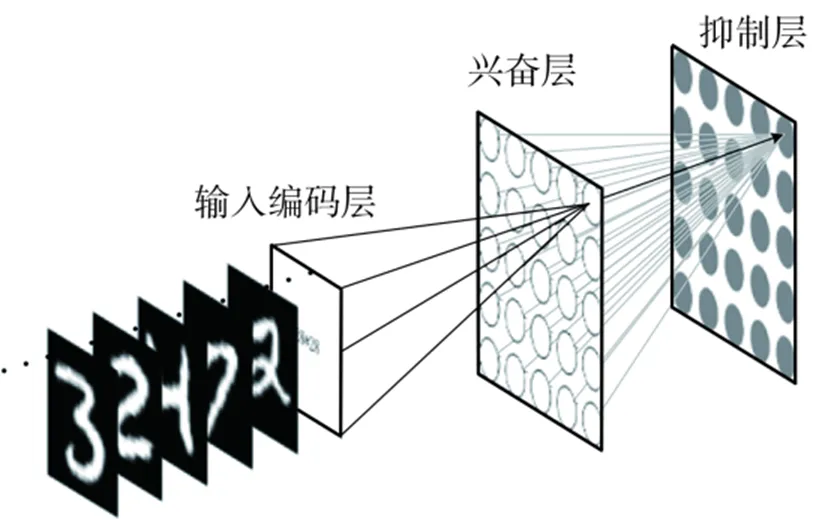
图1 SNN模型
STDP学习算法仅涉及突触前、后神经元的局部脉冲时间差,非常适合硬件实现[14]。近些年逐渐出现了许多使用STDP规则进行SNN在线训练的硬件数字电路设计工作,它们都是通过图1所示的网络来验证硬件的在线学习功能。Wang等[11]实现的SNN在线学习加速器,采用近似乘法器来降低功耗,但相同任务量下其训练时间与推理时间较长,未能真正达到降低能耗的效果。Li等[3]提出了一种具有自适应的时钟/事件驱动计算方案,实现了快速节能的SNN在线学习处理器,每幅MNIST数据集图像的平均推理用时为3.15 ms,能耗为5.04 mJ;训练用时为16.30 ms,能耗为26.32 mJ。Wu等[8]提出了基于快速收敛CORDIC算法的STDP规则,并实现了在线学习SNN的硬件设计,处理每幅图像用时为6.10 ms。Guo等[15]比较了欧拉方法和3阶Runge-Kutta(RK3)方法实现数字化神经元的不同,RK3方法虽然需要比较多的硬件资源,但训练速度相比于欧拉方法有较为明显的提升。为了实现高效的SNN在线学习硬件,文献[3,8,14-15]进行了SNN数字电路实现方法、事件驱动方法等方面的研究。然而,在突触的脉冲传递功能和学习算法的并行方面,以往工作尚缺乏比较好的设计或方案。突触是SNN的重要结构之一,以往对脉冲传递和学习等突触功能的设计通常是串行输入、并行输出,对SNN的处理速度尤其是对训练过程的处理速度依旧有比较大的限制。
针对这些问题,文中提出了一种可扩展的高效SNN在线学习硬件结构。首先,文中结合突触功能和SNN事件驱动特性设计出一种高度并行的突触结构,根据前、后膜脉冲产生的并行情况设计突触处理和计算的并行,并设计了相适应的并行STDP算法硬件结构,以加快SNN的推理和在线学习速度;然后,提出了一种既符合脉冲稀疏性,又有利于并行处理的脉冲数据形式,统一突触前后的脉冲表示方法,使硬件结构具有扩展潜力;最后,为了节约硬件资源,文中提出了一种WTA结构的侧向抑制实现方法,以简化WTA结构,进而有利于在硬件上的部署与实现。
1 硬件结构与并行设计
为了实现SNN的快速学习与推理,文中设计了一个基于FPGA的神经形态硬件加速平台,其内部逻辑结构如图2所示。在FPGA中,使用泊松编码的方法构造并行的输入编码层,产生的脉冲传送到并行突触结构的权重存储块矩阵;将并行的各路权重求和,送入并行神经元计算结构;神经元更新完成后神经元计算结构将产生的脉冲送入并行突触结构的STDP计算矩阵,与此同时输入编码层产生的脉冲也会送入STDP计算矩阵,依据这些从突触前后膜送来的脉冲实现突触的可塑性,完成SNN学习;控制器控制以上过程有序进行,并且通过串行数据接口完成请求图像输入和SNN运行信息回传的功能;外部存储接口用于获取、保存神经元参数以及突触权重;前端服务程序是一个控制台程序,配合硬件完成SNN的学习与推理过程,完成硬件SNN的调试。
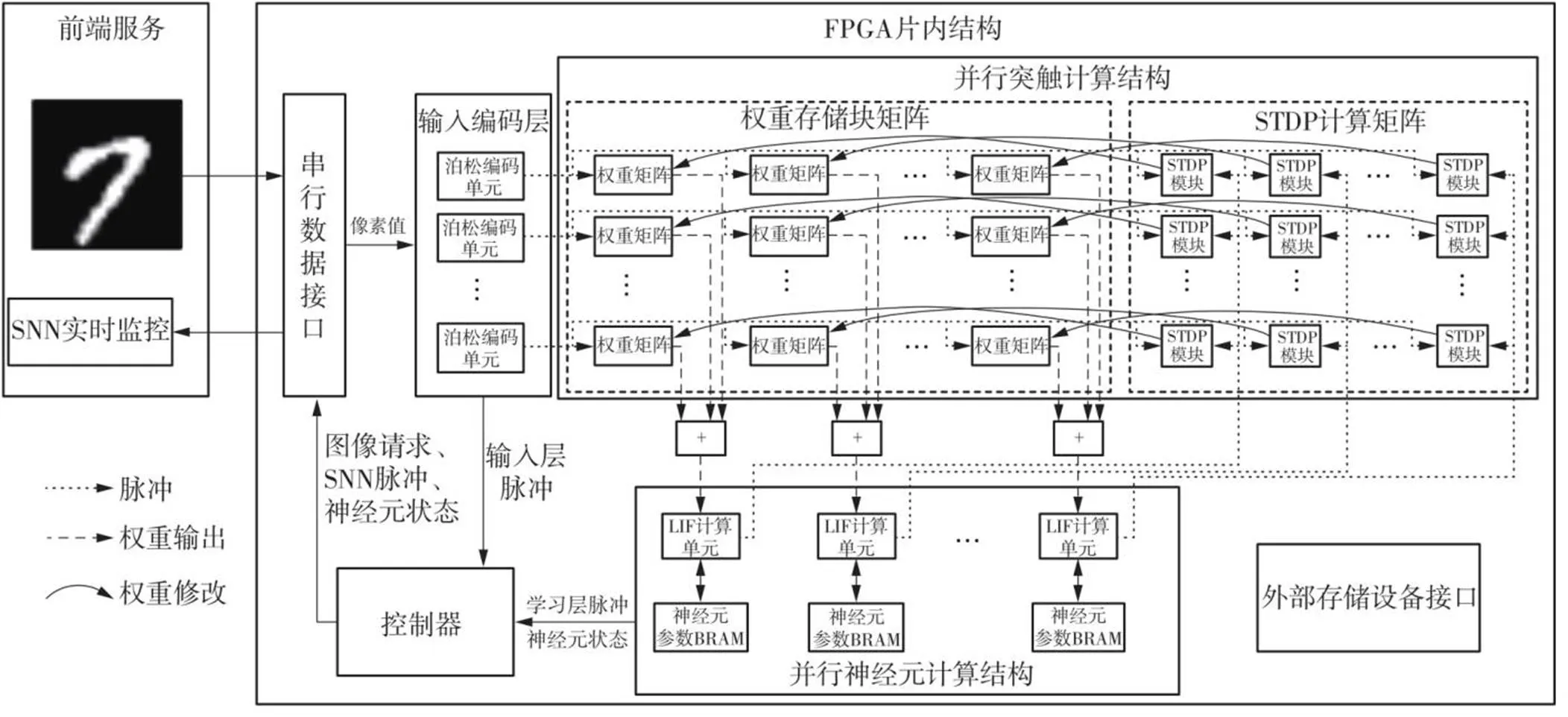
图2 基于FPFA的神经形态硬件平台逻辑框图
1.1 神经元硬件形态
1.1.1神经元并行计算模块
使用FPGA实现SNN脉冲神经元的方案是通过一个计算核心去更新一个神经元状态参数存储块,即将一个物理神经元复用到多个逻辑神经元,再将多个复用结构并行,如图3所示。
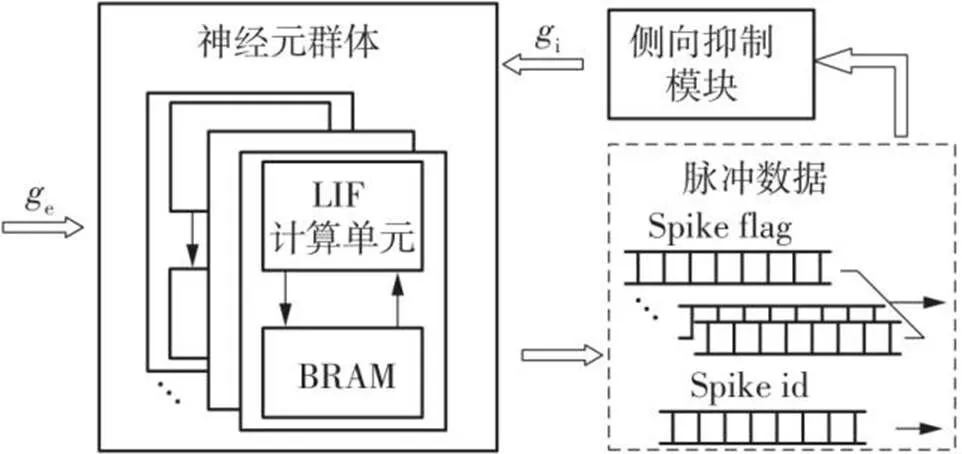
图3 神经元计算核心并行结构
文中实现的神经元动力学模型是泄漏-积分-发放(LIF)模型。LIF模型是一种兼顾生物神经元特性和计算复杂度的模型,文中采用欧拉方法对LIF神经元模型进行离散化处理,设计LIF计算单元。在计算单元完成膜电位计算后,将膜电位与神经元阈值进行比较,判断是否发出脉冲。在图3中,输入神经元群体的e表示神经元计算核心接收的来自突触的权重累加和,i表示神经元接收到的抑制作用。文中在实现WTA结构的SNN时,对WTA网络的侧向抑制功能进行了简化,见图3中的侧向抑制模块。
文中将图3所示的结构作为学习层神经元,输出脉冲数据由脉冲标志(Spike flag)和脉冲序号(Spike id)两部分组成,脉冲标志的位数与神经元计算单元的并行数相同。工作时,一层内的多个计算核心同步更新存储块内的神经元状态,当计算核心检测到有脉冲输出时,与计算核心相对应的标志位设置为1,其余无脉冲的标志位设置为0,同时输出该神经元在片内块随机存取存储(BRAM)块中的存储序号作为脉冲id。这样,不但可以满足脉冲的稀疏性,还能够适应硬件结构的并行性。
1.1.2输入编码
输入层的主要功能是将输入到脉冲神经网络的信息编码成脉冲,文中采用泊松编码方法。对输入数据进行编码,需要随机数生成器,文中使用线性反馈移位寄存器(LFSR)单元产生随机数,将输入的像素数据作为脉冲泊松编码的频率。参考神经元计算核心的并行结构,文中将输入编码层设计成并行结构,输出如图3中所示的脉冲数据。
1.2 并行突触结构
设计具有在线学习功能的硬件SNN结构,突触设计需要包含权重累加和STDP权重修改两个功能。结合图3中的脉冲表示方法,文中将逻辑框图2中的并行突触计算结构设计成图4所示的电路结构。

图4 并行STDP突触结构
1.2.1突触并行设计
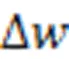
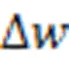
这种设计符合事件驱动的特点,提高了运行速度。相比于传统的依据突触后膜神经元计算单元的并行数量分块存储权重,文中的设计提高了并行程度,并且适应了并行神经元核心生成的自然脉冲表现形式,不需要对脉冲形式进行解析,同时设计出相适应的STDP算法并行结构,大大加快了硬件学习时的处理速度。
1.2.2突触功能设计
图5所示为文中设计的权重累加结构,在权重BRAM中,w表示前膜神经元传递到后膜神经元的权重值。假设突触前膜神经元有个,突触后膜神经元有个,将前膜相同的权重存放在连续的一片存储空间中,形成图5中的存储形式。当前膜神经元的脉冲输入到突触时,读取出权重w0~w(-1)与累加缓存中对应位置的数值相加,再将结果保存到累加缓存中,直到每一个周期神经元更新完成后,将累加缓存中的累加结果输出并将其清0,完成前、后膜神经元间的脉冲传递。
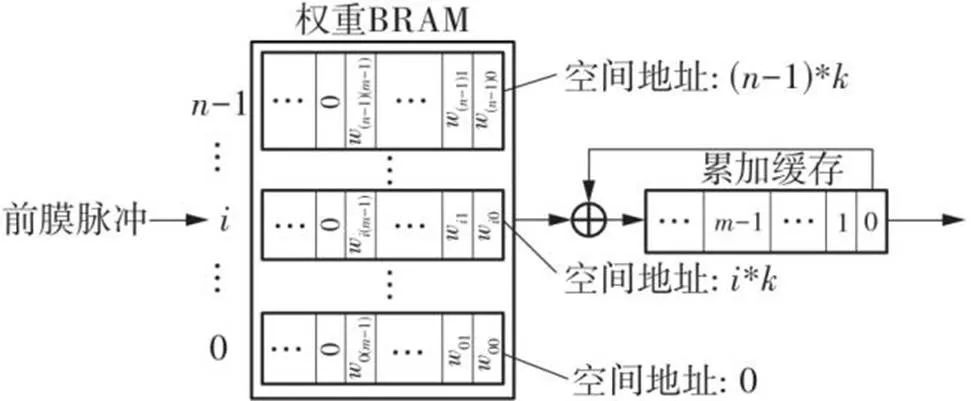
图5 突触权重累加结构
文中使用数字电路完成了基于三相脉冲的STDP[16]规则的设计,用于训练SNN,STDP模块的结构如图6所示。每个突触都需要两个指数衰减的轨迹变量(、)来衡量前、后膜神经元的放电时间差。
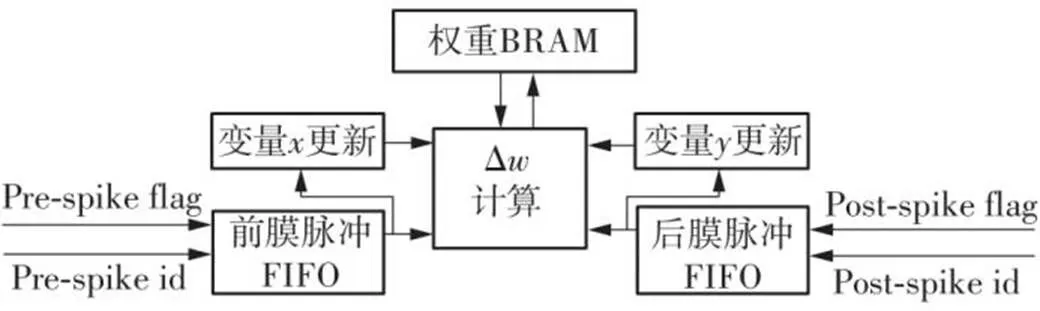
图6 STDP模块的结构
文中设计了轨迹变量更新模块,即图4和图6中的变量更新和变量更新,每当前膜脉冲到达时,突触前轨迹变量被设置为1,无脉冲到达时按照指数规则衰减。同理,突触后轨迹变量在突触后膜神经元被激活时被设置为1,否则按照指数规则衰减。文中使用欧拉方法实现STDP规则,即轨迹变量的差分计算公式为

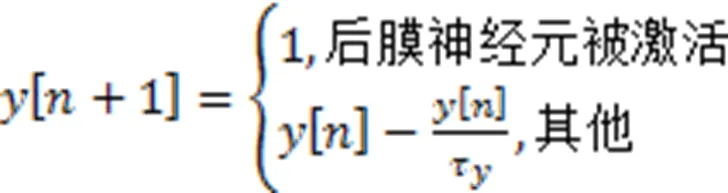
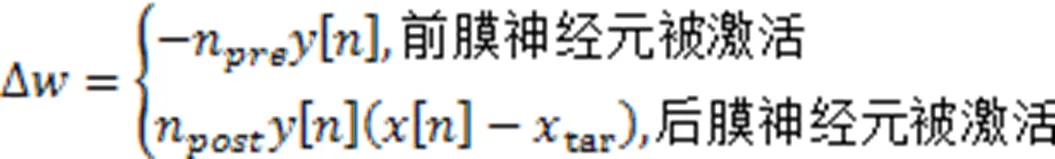
硬件运行时,SNN依据突触前、后膜脉冲情况进行突触训练,轨迹变量以及权重的变化过程如图7所示。可以看出,后膜脉冲作用时,需要依据上一次前、后膜神经元放电的时间,脉冲形成后-前-后或者前-后-后的形式,称为基于三相脉冲的STDP学习规则。
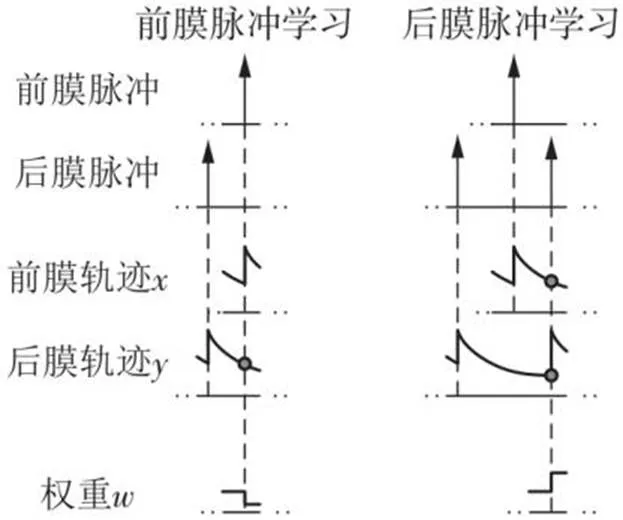
图7 STDP规则学习过程
1.3 改进的WTA网络侧向抑制
文中使用WTA结构的SNN作为学习层,其结构如图8(a)所示。在WTA网络中,每个抑制性神经元必然会跟随输入的兴奋性神经元响应,且对每一个兴奋性神经元产生的抑制作用是相同的,抑制神经元的功能仅仅是向同层传递一个抑制作用。为了简化结构、降低能耗,文献[8]使用抑制性突触代替抑制性神经元,形成图8(b)所示的结构。为更大程度地减少计算时间和硬件资源的消耗,文中提出了一种针对WTA结构的侧向抑制的实现方法,即不是构造抑制性神经元和突触连接结构,而是利用一般性规律设计侧向抑制,达到去掉抑制层神经元实体,保留抑制作用的目的。
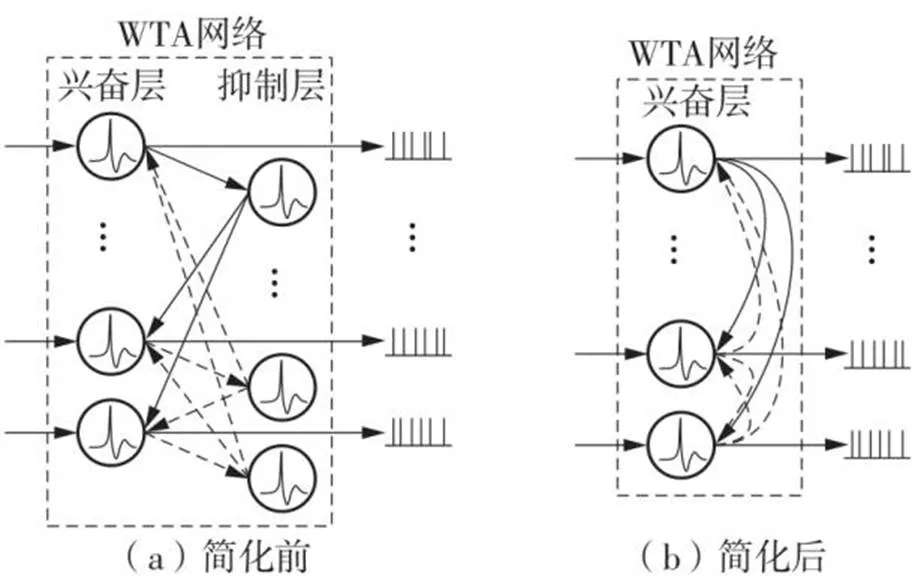
图8 脉冲神经网络结构
在每个抑制性神经元具有相同突触延时的情况下,抑制层的功能可以抽象为:在某一个时间窗口,统计兴奋层的脉冲数目,然后往回作用到兴奋层,产生脉冲的神经元接收到的抑制作用强度将比未产生脉冲的神经元少一个单位,如兴奋层在某一时刻产生的脉冲数目为2,那么当这两个脉冲作用到兴奋层时,产生脉冲的两个神经元将接收到1个单位抑制作用,而其余神经元将收到2个单位的抑制作用,文中将兴奋层→抑制层→兴奋层的脉冲传输过程的延时设为1个时间单位,即文中所描述SNN的一个工作周期。
1.4 高效的时序流程
为了使文中设计的各个部分协调运行,从而高效地实现SNN的功能,文中提出了时间线上不同任务过程并发的设计原则:若处理过程中两个任务不需要访问一个存储块,则它们的功能就可以同时运行,而无需相互等待。例如,编码层生成脉冲与神经元状态更新这两个任务,在神经元和输入编码产生脉冲时,可以依据前膜送来的脉冲进行权重累加,而无需等待所有神经元更新后再进行权重累加。
文中设计了如图9所示的时间线并行执行过程。SNN每个周期的工作任务有:脉冲产生(包括输入编码、神经元状态更新)、权重累加、突触输出以及STDP计算。权重累加是根据突触前神经元的激活情况累加权重值,权重输出是突触将每个周期脉冲的权重累加结果输出给突触后膜神经元。STDP计算就是根据输入的脉冲进行学习的过程。
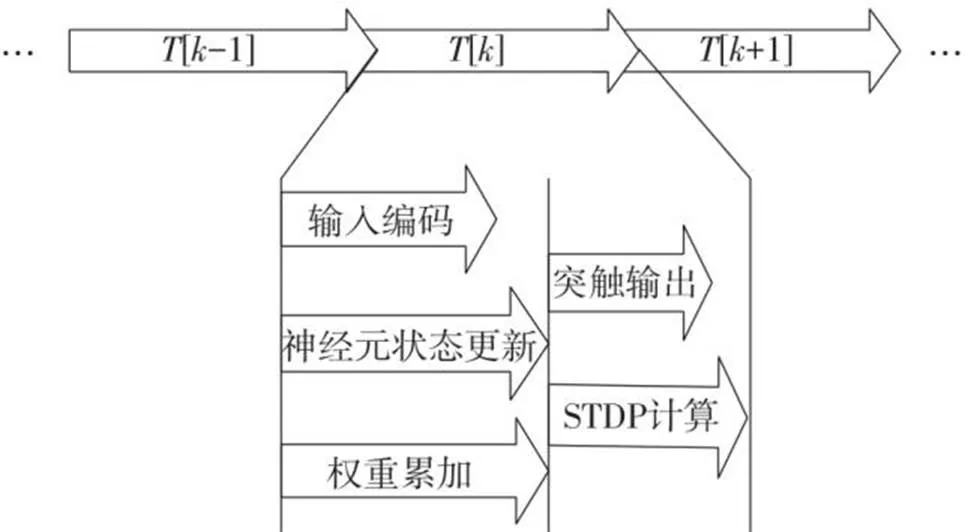
图9 并行处理进程
2 测试与结果分析
为了分析文中所提出的硬件结构的性能,笔者在Xilinx的Kintex-7系列XC7K325T设备上实现784×400的WTA网络,突触规模为784×400,采用16位定点数的形式存储在片内BRAM,系统时钟为200 MHz。然后,使用MNIST训练集对SNN模型进行在线训练,通过训练后学习层神经元的输入权重、识别MNIST测试集的准确率等分析文中的SNN在线学习硬件的性能,以验证文中设计方案的可行性。文中统计了SNN硬件结构学习6万幅图像样本花费的时间、输入层产生的脉冲总量,并且计算出处理每幅图像花费的平均时间、输入脉冲的平均处理速度,结合Vivado软件综合、实现后提供的片上总功耗,计算出处理每幅图像的硬件能耗。分析突触处理输入脉冲的并行程度的改变对这些性能指标的影响,反映出文中的并行设计对硬件在线学习的加速效果。
2.1 在线训练效果
在实验中,每幅图像样本送入后,SNN将运行500 ms,其中前350 ms内,编码层根据图像像素进行编码生成脉冲,经突触传向后层神经元;后150 ms内,将编码层的输入频率变为0,不加外部干预,让整个SNN模型自然恢复。将样本图像0~255的灰度值转换为编码层0~63.75 Hz的脉冲发放率,若激活的兴奋性神经元总数少于5,则将输入层的发放率相应增加0~30 Hz,重新运行一次SNN。通过收集运行过程中的数据,可以得到图10所示的SNN硬件运行情况。
如图10所示,输入标签为2的MNIST样本图像,可以得到SNN的编码层、学习层的脉冲情况。学习层仅有固定的一个或几个神经元在重复激活,说明文中设计的侧向抑制功能正常。
完成硬件设计后,整个实验包括训练、神经元赋值、测试3个过程[13]。在训练过程中,将MNIST训练集所有图像依次传入硬件SNN中,使硬件学习输入的特征。神经元赋值过程是:在训练完成后,再次输入1万幅MNIST训练集图像,通过图2中的前端服务,统计学习层神经元对不同标签的响应的脉冲数,脉冲数最大的标签即为对应神经元识别的类。经过赋值过程后,每个神经元都会识别一类输入,在测试时,输入MNIST测试集数据,在前端服务统计每一类的神经元脉冲总数,脉冲数最多的类即为模型对输入的预测结果。
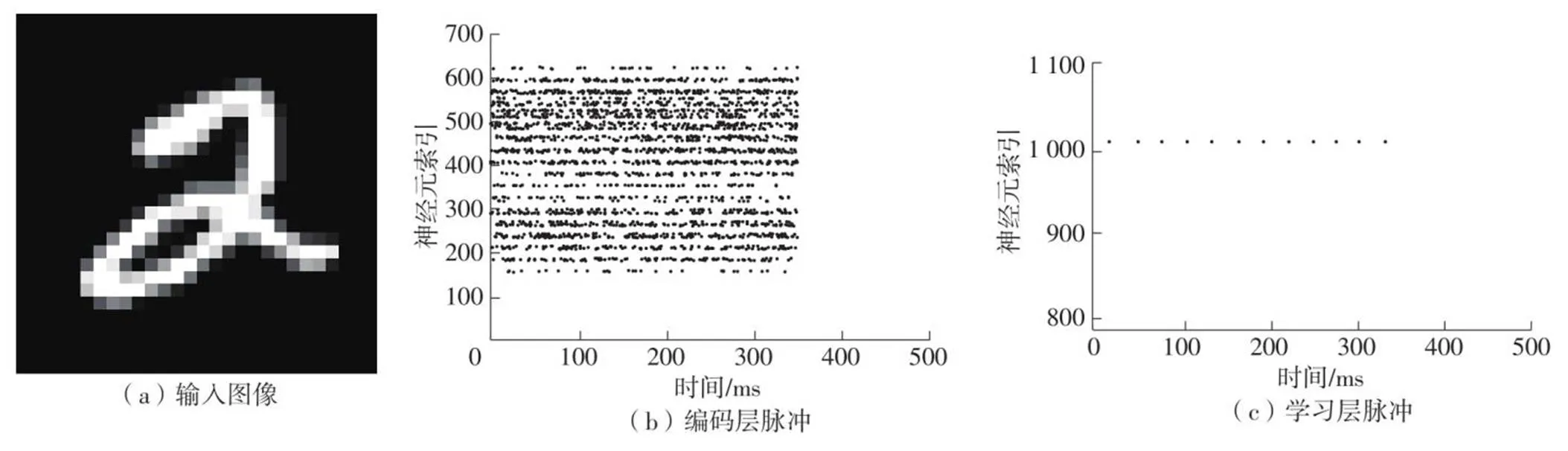
图10 SNN硬件运行情况
训练前、后学习层神经元的输入权重如图11所示。学习层的每个神经元与输入编码层都是全连接,因此每个神经元都有784(28×28)个输入权值,文中按照所连接的编码层神经元顺序将权重值排列成28×28的矩阵,并转换成灰度图像,最后将不同神经元的输入权重图排布成图11所示的形式。在图11中亮度越高的点表示传递给学习层神经元的权重越高,连接度越强。训练前,初始权重是随机生成的,因此图中没有表现出任何规律;训练后,每个神经元的输入权重会出现数字特征,这说明每个神经元都习得了输入图像的一些特征。在进行任务识别时,各个神经元会对具有相应特征的输入图像产生响应,从而实现对手写数字的识别。

图11 学习层神经元输入权重
训练后,SNN模型识别MNIST测试集数据的准确率可达87.51%,略高于相同规模下文献[13]中的87.0%。
以上结果证明,文中实现的SNN硬件结构整体运行情况协调有序,可完成SNN在线学习任务,设计的侧向抑制功能和并行突触结构对输入脉冲进行并行处理的方法并不会影响SNN的学习效果。
2.2 硬件性能测试结果分析
在SNN功能测试的基础之上,对文中的SNN硬件结构的加速特性进行分析。文献[10,15]研究发现,改变神经元计算核心的并行数量可以使SNN硬件的处理速度受到影响。文中主要分析突触的并行设计处理对SNN硬件的处理速度、能耗等性能的影响。结合图2,文中将突触对前膜神经元输入的处理并行路数称为突触前膜并行数;突触对后膜神经元返回脉冲的处理路数称为突触后膜并行数,也等于神经元计算核心并行数量。这个并行结构是文中设计的核心要点,对SNN的脉冲处理具有加速的效果。
文中实现的WTA网络结构,学习层神经元的脉冲发放率比较低,因此改变突触后膜并行数不能直接反映文中设计的加速效果。因而,文中固定后膜并行数量为8,改变前膜并行数量开展实验,其中并行情况2×8表示突触前膜并行数量为2,突触后膜并行数量为8。
2.2.1资源利用率分析
使用Xilinx Vivado软件综合和实现后,统计了不同并行程度时SNN硬件中逻辑资源(查找表LUT、寄存器LUTRAM、触发器FF等)、BRAM等资源消耗情况,结果如表1所示。设计时,采用生成语句块来扩展突触结构的并行,获得的资源消耗随着前膜并行数量的增加整体上呈现线性增加趋势。
从表1可知,除了BRAM的需求较高外,其他硬件资源的消耗总体上均保持在比较低的水平,而BRAM的资源消耗主要是用于权重存储。在增加并行程度的情况下,受限于XC7K325T设备的片上BRAM数量,本研究只能实现313 600(784×400)个16位定点权重值的突触结构,因而后续的实验数据均是在训练网络规模为784×400的WTA网络下获得的。
表1 SNN硬件的资源使用
Table 1 Resource usage of SNN hardware
并行情况使用数量使用率/%片上总功耗/W LUTLUTRAMFFBRAMLUTLUTRAMFFBRAM 1×821 33591526 323266.010.471.436.4659.781.322 2×826 43694631 685282.012.971.487.7763.371.636 4×836 5361 01840 690314.017.931.599.9870.561.986 8×856 8421 27962 547379.527.892.0015.3585.282.906
2.2.2平台加速性能分析
使用MNIST数据集训练SNN时,SNN硬件的处理速度及能耗如表2所示。训练用时是输入训练集图像后训练SNN所用时间总和,没有包含串口的传入图像和脉冲等数据的回传时间。输入脉冲数量是编码层对所有训练集数据产生的脉冲总数。脉冲事件处理速度等于输入脉冲数量除以训练用时。单幅图像处理时间等于训练用时除以样本图像数。处理能耗是片上总功耗乘以图像处理时间。这些数据可以反映出SNN训练架构的性能。
从表2可以看出,对于在线学习任务,突触前膜并行数量从1变为2时,硬件结构处理脉冲事件的速度有明显的提升,每幅图像的处理时间可减少38%左右,处理能耗降低约24.1%。这说明文中的并行设计相比于传统的突触输入串行处理,硬件处理脉冲事件的速度有一个质的飞跃,也反映了文中设计的意义所在。随着突触前并行程度继续提高,硬件处理速度有所提升,但能耗也在增加。因此,需要考虑硬件处理速度与能耗之间的折衷问题。在本次MNIST训练实验中,最低能耗出现在突触前膜输入并行数为2时,但并行数为4时单幅图像处理时间有所减少,且能耗的增加程度比较小,这在实际应用中是值得考虑的。总体上来说,在学习MNIST数据集时,文中提出的SNN并行训练结构每秒钟处理的脉冲数量级约为106,每幅图像样本在硬件结构中的训练用时在2 ms以内。
2.3 与现有硬件结构性能的比较分析
文中通过简化抑制层的实现、增加脉冲传递和学习过程的并行处理等方面的设计,提高了SNN硬件的学习处理速度。在此基础上,将文中硬件的整体性能与文献[3,11,15]中的硬件结构性能进行比较,结果如表3所示。可以看出,文中设计的硬件结构在处理速度和能耗方面有着比较明显的优势。文献[11]搭建的平台较为特殊,其编码层产生脉冲是在计算机端进行的,通过串口将脉冲传入到学习层,存在较大的传输延时,处理速度方面文中仅作为参考,但其在近似乘法器简化计算降低功耗方面的工作依然非常有参考意义。文献[3]设计的结构模块化思想较清晰,直观来看比较具有通用性,但作为数字电路设计其思路有些复杂。与文献[3]结构相比,文中设计的SNN硬件结构更为简单、高效,脉冲传递和并行处理的效率更高,在处理速度与能耗方面均有较为明显的优势:训练(在线学习)过程处理速度(单幅图像处理时间)是文献[3]结构的10倍左右,但能耗仅是0.12倍;推理过程的处理速度为文献[3]结构的2.65倍,能耗也仅是0.47倍。与文献[15]相比,文中的设计增加了前膜脉冲输入的并行处理结构和并行的STDP处理结构,因此能耗上相对略高,训练与推理过程每幅图像的能耗均为文献[15]的1.3倍左右,但处理速度却均是20倍以上。文中侧向抑制的实现方式没有抑制神经元更新方面的工作,也给文中设计的提速带来一定的优势。
表2 学习MNIST数据集的加速情况
Table 2 Acceleration of learning MNIST datasets
任务并行情况样本数/104训练用时/s输入脉冲数量脉冲事件处理速度单幅图像处理时间/ms单幅图像处理能耗/mJ准确率/% 在线学习1×86179.623152 777 357850 544.52.9943.95886.80 2×86110.189150 372 0471 364 673.81.8363.00487.41 4×8696.291150 255 9761 560 436.31.6053.18186.92 8×8690.802146 492 9961 613 323.41.5134.39887.51 推理1×8119.59626 248 9571 339 505.81.9602.59186.80 2×8112.91420 794 1151 610 199.31.2912.11387.41 4×8111.94125 913 6462 170 140.31.1942.36786.92 8×8111.71425 262 7902 156 632.21.1713.40487.51
表3 4种硬件的性能比较(学习MNIST数据集)
Table 3 Performance comparison among four hardwares (learning MNIST dataset)
硬件结构系统时钟/MHz数据格式学习算法FPGA设备神经元模型神经元总数突触数量单幅图像处理时间/ms单幅图像处理能耗/mJ准确率/% 在线学习推理在线学习推理 文献[11]1208位固定STDPVirtex 6LIF1 591638 20816 800.008 400.001 330.001 120.0089.10 文献[3]10016位浮点STDPVirtex 7LIF98488 40016.303.1526.325.0485.28 文献[15]1008位固定STDPVirtex 7LIF1 184313 60034.0028.002.431.7389.70 文中设计20016位固定STDPKintex 7LIF1 184313 6001.611.193.182.3787.51
因使用FPGA芯片资源限制了文中SNN的规模,故文中设计的硬件结构识别测试样本的准确率略低,但能达到目前主流水平[13]。依据表2及文献[13]中软件实现的理论分析结果,在资源相同的情况下,可以预测文中设计的硬件结构在同样规模的网络下,将能获得相近于其他SNN硬件学习平台的识别效果,同时在处理速度方面也能保持优势。
3 结论
文中设计了一种快速高能效的SNN在线学习的数字电路并行方案,提出了一种高度并行的突触结构,突触前、后神经元脉冲采用相同的表示形式,使结构具有可扩展性;为省略WAT网络的抑制层,提出了一种实现侧向抑制的简化方案,节约了硬件资源开销,并达到了与抑制层神经元相同的效果。实验结果表明,文中提出的突触并行结构对每幅图像的处理时间可减少38%左右,使用文中提出的结构搭建规模为784×400的WTA网络实验平台,训练一幅MNIST图像样本的时间约为1.61 ms,需要能耗约3.18 mJ。文中设计的硬件SNN处理速度相比于传统的软件框架有百倍甚至千倍量级的提升,相比于同等条件下的硬件实现,处理速度和功耗也有明显的优势。
受限于芯片资源,文中未进行更大规模神经网络结构的测试与研究,这将是今后进行改进的方向,做出多芯片扩展方面的设计或者权重片外存储的在线学习硬件神经形态加速器,以更加灵活地实现更大规模和更深度的SNN。
[1] STIMBERG M,BRETTE R,GOODMAN D F M.Brian 2,an intuitive and efficient neural simulator[J].Elife,2019,8:e47314/1-10.
[2] CHOU T S,KASHYAP H J,XING J,et al.CARLsim 4:an open source library for large scale,biologically detailed spiking neural network simulation using heterogeneous clusters[C]∥ Proceedings of 2018 International Joint Conference on Neural Networks.Rio de Janeiro:IEEE,2018:1158-1165.
[3] LI S,ZHANG Z,MAO R,et al.A fast and energy-efficient SNN processor with adaptive clock/event-driven computation scheme and online learning[J].IEEE Transactions on Circuits and Systems I:Regular Papers,2021,68(4):1543-1552.
[4] SOLEIMANI H,AHMADI A,BAVANDPOUR M.Biologically inspired spiking neurons:piecewise linear models and digital implementation[J].IEEE Transactions on Circuits and Systems I:Regular Papers,2012,59(12):2991-3004.
[5] HEIDARPUR M,AHMADI A,AHMADI M,et al.CORDIC-SNN:on-FPGA STDP learning with Izhikevich neurons[J].IEEE Transactions on Circuits and Systems I:Regular Papers,2019,66(7):2651-2661.
[6] JOKAR E,SOLEIMANI H.Digital multiplierless realization of a calcium-based plasticity model[J].IEEE Transactions on Circuits and Systems Ⅱ:Express Briefs,2017,64(7):832-836.
[7] QUINTANA F M,PEREZ-PEÑA F,GALINDO P L.Bio-plausible digital implementation of a reward modulated STDP synapse[J].Neural Computing and Applications,2022,34:15649-15660.
[8] WU J,ZHAN Y,PENG Z,et al.Efficient design of spiking neural network with STDP learning based on fast CORDIC[J].IEEE Transactions on Circuits and Systems I:Regular Papers,2021,68(6):2522-2534.
[9] WAN L,LUO Y,SONG S,et al.Efficient neuron architecture for FPGA-based spiking neural networks[C]∥ Proceedings of 2016 the 27th Irish Signals and Systems Conference.Londonderry:IEEE,2016:1-6.
[10] LIU Y,CHEN Y,YE W,et al.FPGA-NHAP:a general FPGA-based neuromorphic hardware acceleration platform with high speed and low power[J].IEEE Transactions on Circuits and Systems I:Regular Papers,2022,69(6):2553-2566.
[11] WANG Q,LI Y,SHAO B,et al.Energy efficient parallel neuromorphic architectures with approximate arithmetic on FPGA [J].Neurocomputing,2017,221:146-158.
[12] HE Z,SHI C,WANG T,et al.A low-cost FPGA implementation of spiking extreme learning machine with on-chip reward-modulated STDP learning[J].IEEE Transactions on Circuits and Systems Ⅱ:Express Briefs,2022,69(3):1657-1661.
[13] DIEHL P U,COOK M.Unsupervised learning of digit recognition using spike-timing-dependent plasticity[J].Frontiers in Computational Neuroscience,2015,9:99/1-9.
[14] VIGNERON A,MARTINET J.A critical survey of STDP in spiking neural networks for pattern recognition[C]∥ Proceedings of 2020 International Joint Conference on Neural Networks.Glasgow:IEEE,2020:1-9.
[15] GUO W,YANTIR H E,FOUDA M E,et al.Toward the optimal design and FPGA implementation of spiking neural networks[J].IEEE Transactions on Neural Networks and Learning Systems,2021,33(8):3988-4002.
[16] MORRISON A,AERTSEN A,DIESMANN M.Spike-timing-dependent plasticity in balanced random networks[J].Neural Computation,2007,19(6):1437-1467.
Design and Implementation of Hardware Structure for Online Learning of Spiking Neural Networks Based on FPGA Parallel Acceleration
1212
(1. School of Integrated Circuits,Guangdong University of Technology,Guangzhou 510006,Guangdong,China;2. School of Information Engineering,Guangdong University of Technology,Guangzhou 510006,Guangdong,China)
Currently, the hardware design of spiking neural networks based on digital circuits has a low synaptic parallel nature in terms of learning function, leading to a large overall hardware delay, which limits the speed of online learning of spiking neural network models to some extent. To address the above problems, this paper proposed an efficient spiking neural network online learning hardware architecture based on FPGA parallel acceleration, which accelerates the training and inference process of the model through the dual parallel design of neurons and synapses. Firstly, a synaptic structure with parallel spike delivery function and parallel spike time-dependent plasticity learning function was designed; then, the learning layers of input encoding layer and winner-take-all structure were built, and the implementation of lateral inhibition of the winner-take-all network was optimized, forming an impulsive neural network model with a scale of 784~400. The experiments show, the hardware has a training speed of 1.61 ms/image and an energy consumption of about 3.18 mJ/image for the SNN model and an inference speed of 1.19 ms/image and an energy consumption of about 2.37 mJ/image on the MNIST dataset, with an accuracy rate of 87.51%. Based on the hardware framework designed in this paper, the synaptic parallel structure can improve the training speed by more than 38%, and reduce the hardware energy consumption by about 24.1%, which can help to promote the development of edge intelligent computing devices and technologies.
neural network;learning algorithm;acceleration;parallel architecture
Supported by the Key-Area R&D Program of Guangdong Province (2018B030338001,2018B010115002)
10.12141/j.issn.1000-565X.220623
2022⁃09⁃27
广东省重点领域研发计划项目(2018B030338001,2018B010115002);广州市基础研究计划基础与应用基础研究项目(202201010595);广东省教育厅创新人才项目;广东工业大学“青年百人计划”项目(220413548)
刘怡俊(1977-),男,博士,教授,博士生导师,主要从事集成电路设计、类脑计算机、深度学习研究。E-mail:yjliu@gdut.edu.cn
叶武剑(1987-),男,博士,讲师,主要从事类脑计算机、深度学习应用研究。E-mail:yewjian@gdut.edu.cn
TP389.1
1000-565X(2023)05-0104-10
