HEVC帧内率失真优化预测模式的并行流水线硬件设计
2023-06-30林志坚丁永强杨秀芝吴林煌
林志坚 丁永强 杨秀芝 吴林煌
HEVC帧内率失真优化预测模式的并行流水线硬件设计
林志坚 丁永强 杨秀芝 吴林煌†
(福州大学 物理与信息工程学院,福建 福州 350108)
近年来,随着人们对视频数据需求的不断增加,视频的分辨率和帧率也在不断地提高,而实时视频序列的压缩编码速度往往受到帧率和分辨率的影响,分辨率和帧率越大,编码所需要的时间越长。为了实现更高分辨率和更高帧率的视频序列实时压缩编码,文中设计了一种新的帧内率失真优化预测模式的并行流水线硬件架构,该架构支持最大64×64编码树单元的帧内预测编码。首先设计了9路预测模式并行方案;然后,按照Z型扫描顺序实现以4×4块为基本处理单元的流水线硬件架构,并复用32×32预测单元的预测数据,用以代替64×64预测单元的预测数据,减少运算量;最后,基于该流水线架构,提出了一种新的哈达玛变换电路,用以实现高效的流水线处理。实验结果表明:在Altera Arria 10系列的现场可编程门阵列上,该9路模式并行架构仅占用75 kb的查找表和55 kb的寄存器资源,主频可以达到207 MHz,完成一个64×64编码树单元的预测仅需要4 096个时钟周期,最大能够支持1 080 P分辨率99 f/s全I帧的实时编码;与已有设计方案相比,文中方案能够用更小的电路面积实现更高帧率的1 080 P实时视频编码。
帧内预测;现场可编程门阵列;模式并行;高效视频编码
近年来,随着电子信息技术的发展,基于视频的数据流量呈现爆炸性增长,如视频分辨率从常用的720 P(1 280×720)增长到8 K(7 680×4 320),帧率从30 f/s增长到60 f/s乃至更高。在高质量视频的高速传输需求下,视频编码联合协作小组提出了新一代高效视频编码标准(HEVC)。相比于H.264,HEVC对高清和超高清等视频编码压缩处理有更加出色的表现[1]。在相同视频质量条件下,HEVC编码效率是H.264的两倍[2],但其编码块划分采用了更加灵活的四叉树方法,且帧内预测模式从9种增加到了35种。这增加了帧内预测率失真优化(RDO)的计算复杂度,不利于硬件实现。因此,面向硬件的帧内RDO架构设计是当前HEVC帧内预测硬件设计研究的重点。
对于HEVC帧内预测的硬件设计研究,Kim等[3]提出了通过哈达玛变换计算出的绝对变换差之和(SATD)估测最佳预测模式的方法,降低了运算的复杂度,但预测精度较低;Kalali等[4]提出了近似预测的方法,用同一组参考像素预测多行像素,减少了运算量,但电路通用性较差;Shen等[5]提出了一种基于量化变换块系数的线性RDO算法,该算法的计算复杂度相对较低,但硬件实现上难度较大;Xu等[6]提出了一种面向硬件的快速编码单元划分算法,但该算法不利于实现全流水线设计;Zhang等[7]提出了4路不同尺寸预测单元的并行预测方法,提高了运算速度,但电路结构较为复杂,且占用了较多的数字信号处理(DSP)资源;杨贺等[8]提出了对64×64预测单元和32×32预测单元进行1/4和1/2下采样的设计思想,减少了运算量和电路资源消耗,但通过下采样预测的可靠性不高,有一定的误差,且运算所需时钟周期数较多;Min等[9]提出了一种新的编码扫描顺序,用于解决编码块之间的数据依赖性,这种方法有利于进行全流水线式设计。Lu等[10]提出了一种SATD硬件计算架构,可以将各种预测模式得出的残差连续输入,实现数据的流水线处理,每个4×4预测单元仅需要4个时钟即可得出SATD值,但该架构只支持4×4预测单元的计算。
为了能用更小的电路面积实现1 080 P高帧率的实时视频编码,文中使用现场可编程门阵列(FPGA)进行设计实现,提出了一种HEVC帧内率失真优化预测模式的并行流水线硬件架构。首先,提出了9路预测模式并行方案,使预测电路在设计时能够节省运算单元、寄存器、查找表(LUT)的使用,以提高硬件利用率,同时更利于最佳预测模式选择;接着,设计高效的流水线硬件架构,采用帧内RDO数据复用策略,用4个32×32预测单元的预测数据代替64×64预测单元的预测数据,实现数据复用,以减少计算量和硬件面积;然后,设计高效的哈达玛变换架构,实现4×4和8×8的哈达玛变换功能;最后对文中设计方案和现有相关方案进行了性能比较。
1 HEVC帧内RDO原理
为了更好地利用图像空域的相关性来提高预测准确度,HEVC引入了编码树单元的概念[11],并采用四叉树的方法进行分割。在HEVC帧内预测时,其预测单元分割尺寸包括4×4、8×8、16×16、32×32和64×64[12],每个预测单元支持35个预测模式[3]。HEVC的35个帧内预测中包含0号Planar模式和用于处理平滑区域的1号直流(DC)模式,以及用于处理纹理区域的33种角度预测模式,其33个角度方向和编号如图1所示[13]。
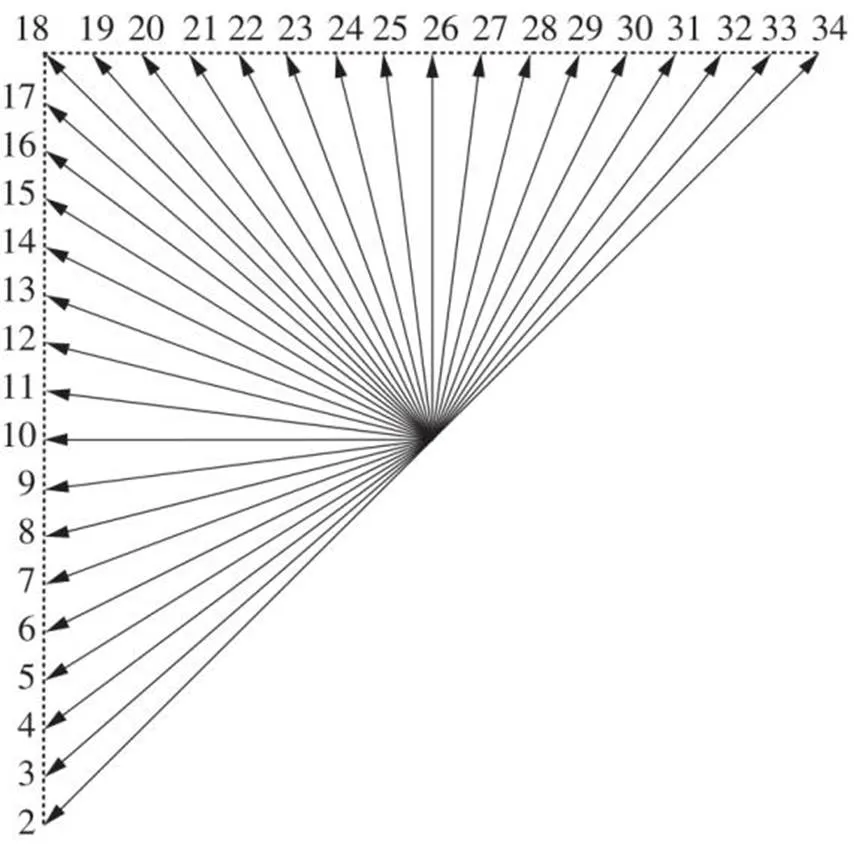
图1 帧内33个角度预测模式
HEVC在进行帧内RDO时,分为粗选和细选两个阶段。粗选是将计算的35个预测模式对应的残差进行哈达玛变换,进而计算SATD;通过较为简单但精度不高的算法计算出对应预测模式的编码代价,选出最有可能的最佳预测模式;然后参考相邻预测单元的最佳预测模式生成候选模式列表,之后进入细选阶段。在细选过程中,对候选模式列表中的各个候选预测模式进行全流程的编码,即对残差进行后续的变换量化熵编码,计算出编码的比特数,同时进行反变换反量化计算编码的失真系数,由此计算对应的预测模式的编码代价,选出编码效果最好的预测模式,作为最终的最佳预测模式。
在进行帧内RDO的硬件设计时,由于细选过程非常复杂,且存在计算回路,不利于流水线设计,往往选择只进行粗选而不进行细选,以提高硬件编码速度。
2 帧内RDO硬件设计
为了达到更高帧率的1 080 P实时视频编码设计目标,文中提出了预测模式并行和数据复用的方案,以提高硬件计算速度。为了最大化压缩设计的硬件面积,文中提出了新的硬件流水线处理架构。在该硬件架构下,为了大幅降低电路面积,文中提出了一种高效的哈达玛变换架构。该架构可以用很小的电路面积实现4×4和8×8哈达玛变换,电路在工作时,能够充分地利用运算单元。
2.1 预测模式并行设计
不同的预测模式对同一个预测块的预测精度是不同的。在计算每个预测单元的35个预测模式时,文中从模式并行的角度来提高硬件计算的吞吐量。但如果没有合理安排模式并行的策略,则会对电路面积造成极大的浪费,甚至影响计算准确度。现有的模式并行相关设计,如文献[14]采用的4路模式并行,没有针对模式并行对电路资源的使用作一些详细的分析;文献[15]采用的19路模式并行,虽然对于乘法计算采用移位相加的方式实现,节省了DSP资源,但由于模式并行度太高,为了降低整体电路面积,采用了4×4下采样的计算方法,其哈达玛变换仅支持4×4大小,计算准确度较低。
对于35个模式的并行处理,文中采用一次处理一个4×4像素块的策略,单次处理的数据量与文献[14]的一行16个像素一致,而文献[14]的4路并行处理仅能达到1 080 P分辨率30 f/s的速度,若要实现60 f/s以上的速度,则至少需要8路模式并行。不同的并行度完成所有模式的计算所需要的计算次数如表1所示。从表中可见,完成35个预测模式的8路并行需要计算5次,4路并行需要计算9次,其编码速度实际上并不能相对4路并行翻一倍,至少需要设计9路模式并行才能实现60 f/s以上的1 080 P视频编码,若要再提升编码速度,则至少需要增加3路模式的并行,相当于在9路并行的基础上增加了三分之一的电路面积。综合考虑电路面积和编码速度,选择9路模式并行设计,是平衡编码速度与电路面积的最佳选择,因此文中提出了如表2所示的9路预测模式并行的设计方案。
表1 模式并行度与计算次数的关系
Table 1 Relationship between mode parallelism and number of calculations
并行度计算次数 并行度计算次数 135 7~85 218 9~114 312 12~173 49 18~342 57 351 66
表2 模式并行方案
Table 2 Mode-parallel scheme
模式批次模式号 第1路第2路第3路第4路第5路第6路第7路第8路第9路 12345678910 2181716151413121126 318192021222324250 434333231302928271
在文中的9路模式并行方案下进行参考像素滤波时,根据不同预测块尺寸下各模式的滤波情况(如表3所示),可以让第2~7路共同使用一个滤波选择电路,从而减小滤波选择电路面积。
表3 不同尺寸预测块需要滤波的模式号
Table 3 Filtering mode required for prediction blocks with different sizes
预测块尺寸需要滤波的模式号 4×4 8×80,2,18,34 16×160,2~8,12~24,28~34 32×32及以上0,2~9,11~25,27~34
在进行角度预测时,对于第1路电路,以模式18为例(见图2),其中()为预测值,(,)为参考像素,Ref()为左侧参考像素向左上方投影并与上方参考像素拼接后得到的上方参考像素编号,由图1可知:模式18的预测方向为45°,则每个预测值都可以由参考像素直接得到,而不需要进行乘法、加法和移位计算;对于模式2和34,其预测方向与模式18的方向是垂直的,其预测值也是可以由参考像素直接得到。因此,第1路电路可以完全不使用任何计算单元。
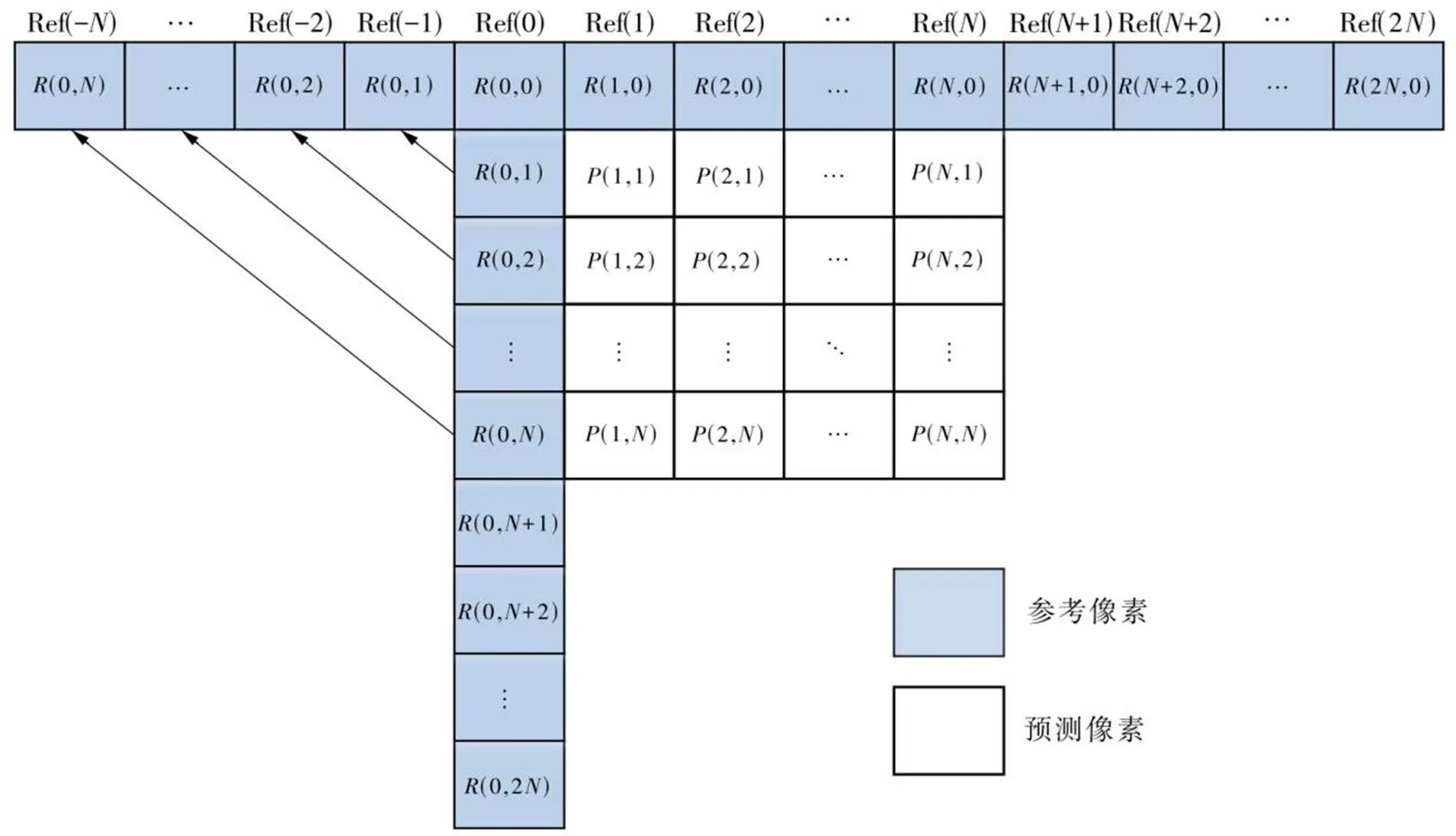
图2 模式18示例
由于角度方向对称的关系,在第2~8路电路中,每一路处理的4个预测模式所需要的计算参数都是完全一样的,因此可节省一些计算参数的寄存器占用。对于第9路电路,在计算模式10和26的角度预测时依然同第1路电路一样,可以不使用任何计算单元。
文中统计了自然情况下各预测模式的分布概率,如图3所示。其中0号Planar模式和1号DC模式的分布概率最大,角度模式的分布概率分别从模式10和26向两侧逐渐降低。因此在每一批最佳预测模式的选择上,优先选择并行电路编号较大的模式,在不同批次的选择上,优先选择后一批次的模式,以提高最佳模式选择的正确率。
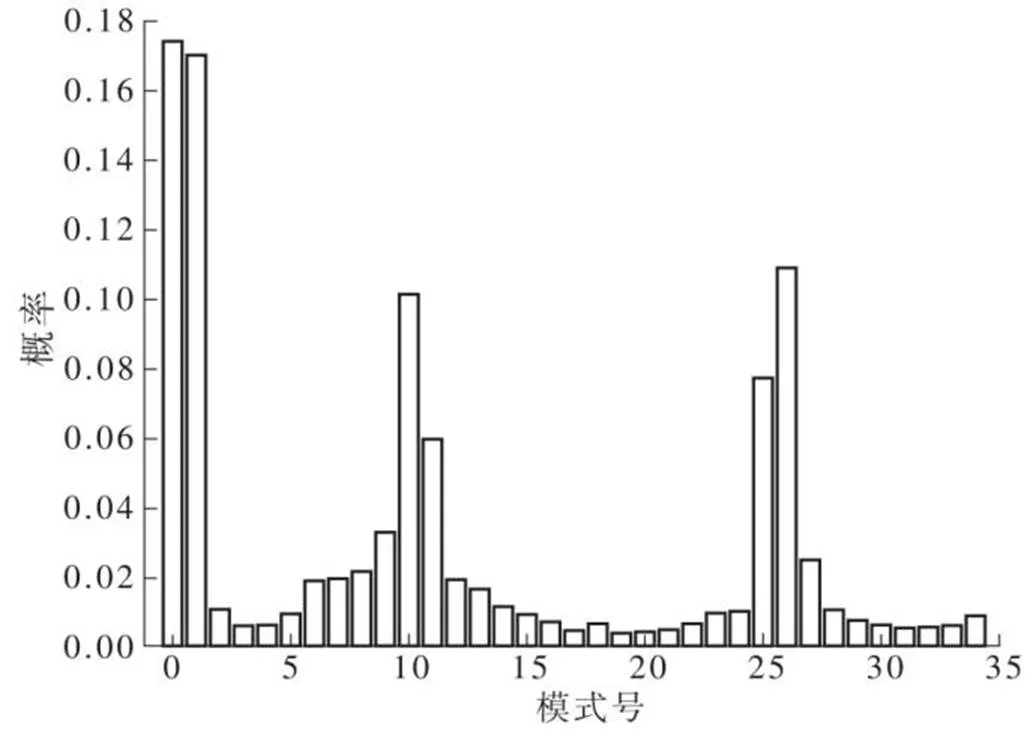
图3 各预测模式的分布概率
针对文中并行预测模式选择方案,对最佳预测模式的准确性和编码效率的影响进行测试,在全Ⅰ帧配置下,每个序列测试10帧,各个序列的测试结果如表4所示。其中率失真性能是由M33标准代码计算得出的,表示文中预测模式并行选择方案降低的率失真性能。结果表明,文中预测模式并行选择方案对率失真性能的影响很小。
表4 并行选择方案的性能测试结果
Table 4 Performance test results of parallel selection scheme
测试序列视频分辨率率失真性能/% Foreman320×2560.158 4 Blowing Bubbles384×1920.015 3 BQ Mall832×4480.001 8 Kristen and Sara1 280×7200.009 9 Four People1 280×7200.047 5 BQ Terrace1 920×1 0800.003 7 Basketball Drive1 920×1 0800.037 4 平均值 0.039 0
2.2 硬件流水线架构设计
现有设计中,文献[14]采用16点为基本处理单元的方式,即一次计算一个16×16预测块中的一行数据,这种设计方法不利于进行大小为16×16以上预测块的计算,且完成一个32×32编码树单元的计算需要大约5 787个时钟周期,这就导致该硬件架构仅能支持1 080 P分辨率30 f/s的实时编码,无法满足更高帧率的实时视频编码需求。
文中设计以满足更高帧率的实时视频编码需求为目标,提出了硬件计算以4×4小块作为基本处理单元,即将64×64的编码树单元划分成256个4×4块,并按照Z型扫描的方式进行编号。在预测模式并行上,采用9路模式并行方案。电路开始工作时,从编号为0的4×4块开始计算,在当前4×4块的4批9路模式计算完成之后,按照Z型扫描的编号顺序处理下一个4×4块。整体流水线电路框图如图4所示,主要包括参考像素获取模块、滤波模块、预测模块和哈达玛变换计算SATD模块的电路。
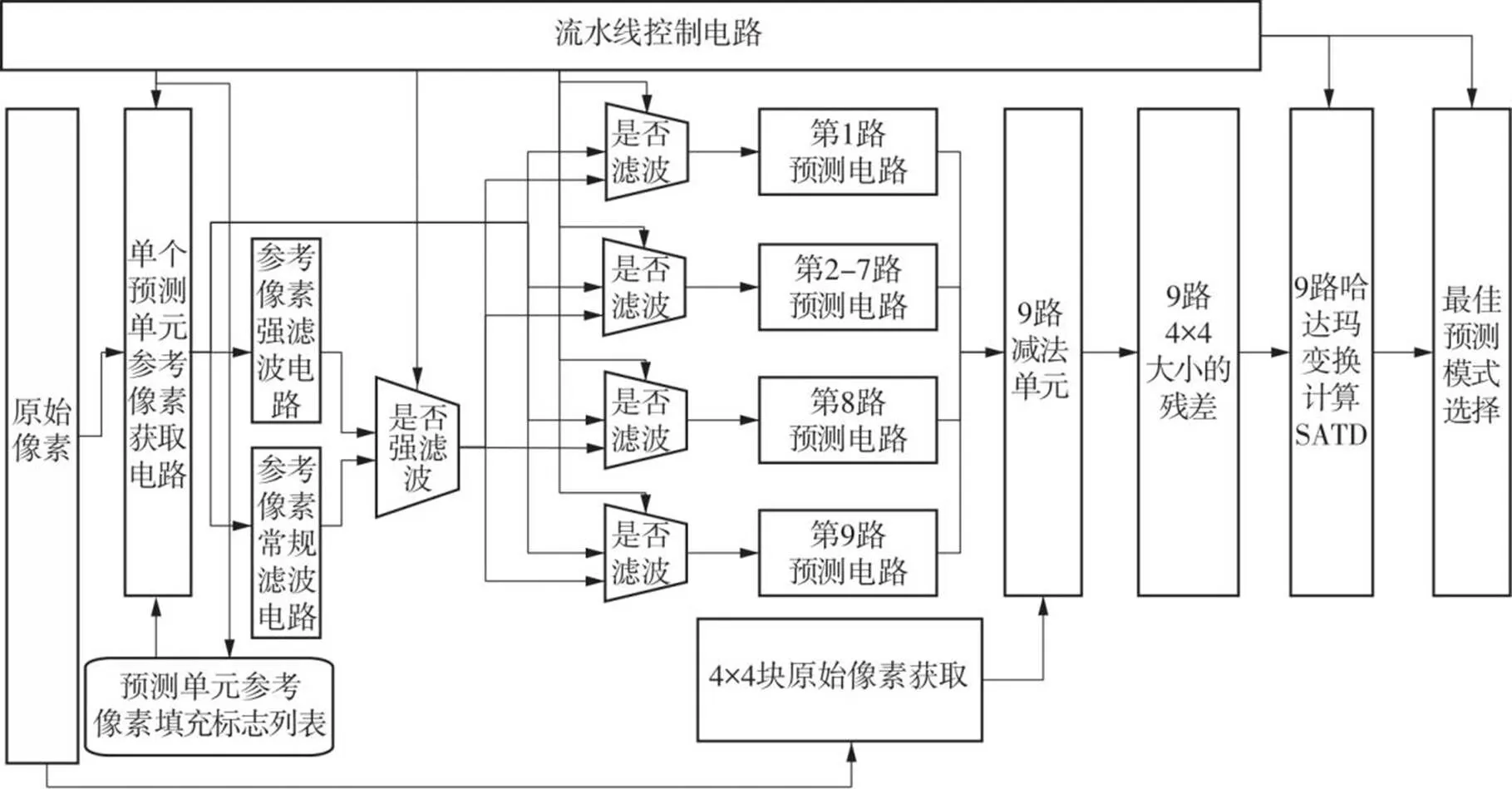
图4 流水线硬件架构
参考像素获取模块中,获取来源为原始像素。根据当前4×4块坐标以及当前预测单元的尺寸,得到当前预测单元的位置,据此获取对应的上方和左侧参考像素。对于参考像素的填充处理,事先将填充标志存入只读存储器中,然后在计算时将对应预测单元的尺寸和位置的标志读出,以此获取最终的参考像素。对于参考像素滤波模块的设计,文中先同时计算强滤波和常规滤波,然后判断当前预测单元是否需要进行强滤波,从而获取当前预测单元最终的滤波数据。前面已经分析了每一路的参考像素滤波情况,最终将9路预测电路的滤波选择电路分成4组来设计,根据模式批次和预测单元尺寸判断第1路、第2~7路、第8路和第9路的参考像素是否需要滤波。之后是进行9路预测电路的计算,得到9路4×4块的残差数据,再进行9路哈达玛变换计算SATD结果,最终选出最佳预测模式。
2.3 数据复用
在帧内RDO的过程中,需要对每一种预测块尺寸、每一个预测块进行预测计算,这在编码的过程中会占用较长的时间。文献[8]从减少计算量方面对RDO进行设计,先针对64×64和32×32预测单元向16×16预测单元进行下采样,然后按照16×16预测单元进行计算。这种处理方式虽然能够减少计算量,但降低了32×32和64×64预测单元的计算准确度。
文中统计了量化步长为12、17、22、27的预测单元划分占比,结果如表5所示。从表中可知,32×32预测单元的占比平均为23.86%,而64×64预测单元的占比仅为11.92%。在实际编码时,只有在视频信息中有较大像素面积变化较为平缓的情况下才有可能出现64×64预测单元,对于一般的视频序列,64×64预测单元极少出现。
表5 不同量化步长下不同尺寸预测单元的占比
Table 5 Proportion of prediction units with different sizes under different quantization steps
量化步长预测单元占比/% 尺寸为4×4尺寸为8×8尺寸为16×16尺寸为32×32尺寸为64×64 1217.5726.5524.7420.6010.55 1715.0824.4626.7124.169.59 2212.7522.2329.6525.699.67 2710.6221.1925.3324.9817.88 平均14.0123.6126.6123.8611.92
如果直接取消对64×64预测单元的计算,默认全部预测单元都小于64×64,则在图像平缓的场景下会降低编码器的率失真性能。因此,对于64×64预测单元的代价计算,文中提出了对32×32预测单元的预测数据进行复用,用于代替64×64预测单元的预测数据,以减少编码时间。具体来说,对于64×64预测单元,文中使用相同预测模式下4个32×32预测单元的预测值来计算其SATD值。在进行大于8×8预测单元的SATD代价计算时,是将内部每个8×8块进行哈达玛变换,然后计算绝对值之和,因此在硬件设计上计算64×64预测单元的SATD值时,只需要将4个32×32预测单元的残差进行哈达玛变换,得到的SATD缓存累加即可得到。文中提出的RDO数据复用策略具体描述如下:
{设置预测块尺寸标志为32×32
for (index=0;index<=3;index++) do
// index 为32×32预测单元索引
for (mode=0;mode<=34;mode++) do
// mode为预测模式号
计算预测值;
计算残差;
计算当前模式的SATD值;
if (index<3) then
缓存当前模式的SATD值;
else //当前为最后一个32×32预测块
将前面缓存的SATD与当前模式的SATD值相加,得到64×64预测单元的当前模式SATD值;
end
end
选出当前32×32预测单元的最佳预测模式和
代价;
if (index==3) then
//当前为最后一个32×32预测块
选出64×64预测单元的最佳模式号和代价;
end
end
得到当前编码树单元的64×64预测单元和4个32×32预测单元的最佳模式号和代价;}
在文中硬件架构下,此方法可节省256个4×4块的计算,能够节省1 024(256×4)个时钟周期。
2.4 高效的哈达玛变换架构
HEVC支持4×4和8×8的哈达玛变换,在文中硬件设计架构下,如果进行8×8的哈达玛变换,那么只有4×4残差块处于8×8块Z型扫描的1和3号位置时,才能进行一次4×8的列变换;只有当所有列变换完成之后,才能进行行变换得到哈达玛变换的最终结果。如果直接设计4×8列变换单元和8×8行变换单元,由于9路并行运算,则会需要较大的电路面积,而且列变换电路在0和2号,行变换电路在0、1、2号位置均处于空闲状态,这将极大浪费电路的利用率。为进一步提高电路利用率和降低电路面积,文中设计了高效的哈达玛变换架构,对数据进行分批计算,使变换电路能够持续进行计算。
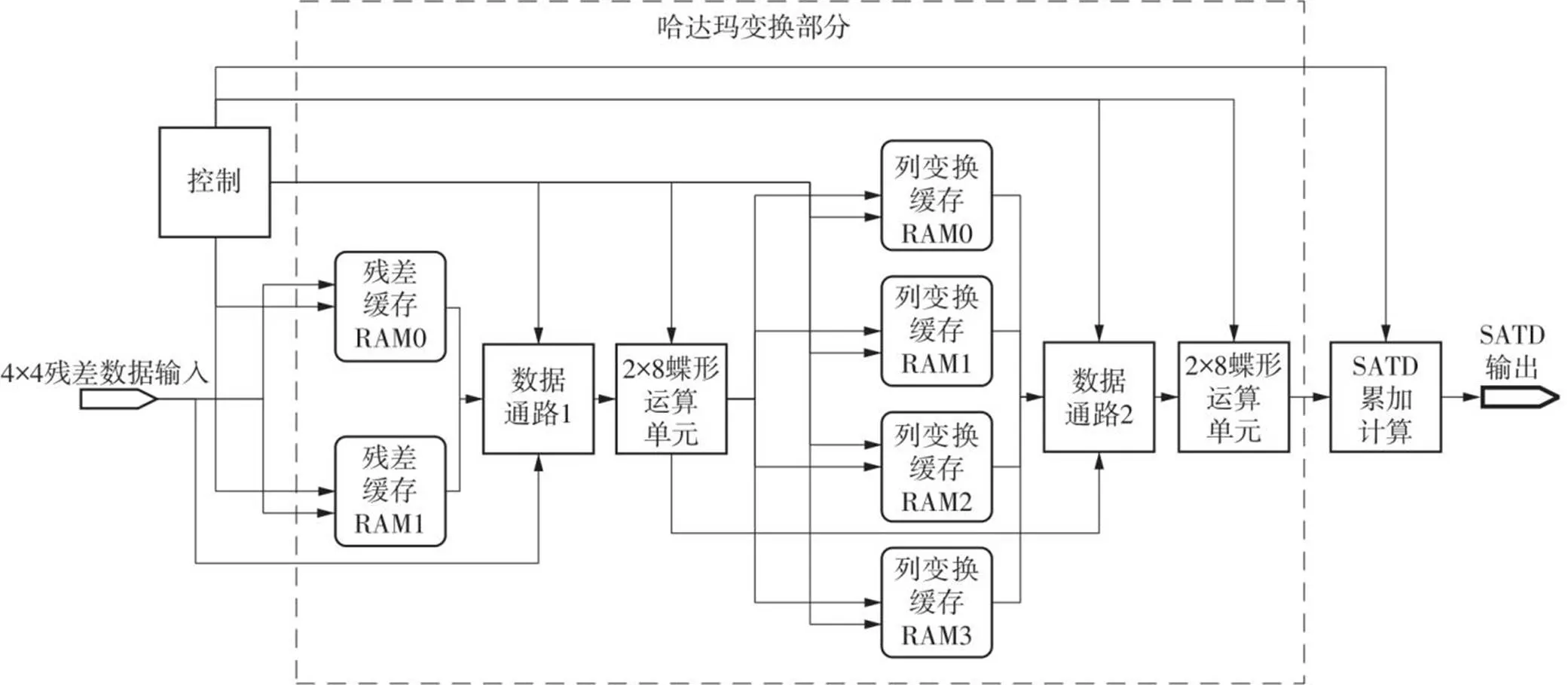
图5 哈达玛变换电路结构
图5所示为文中哈达玛变换的电路结构,其中哈达玛变换部分使用到了6个随机存取存储器(RAM)用于数据缓存,包含2个2×8蝶形运算单元,第1个蝶形运算单元用于计算列变换,第2个蝶形运算单元用于计算行变换,2个数据通路用于数据分配和转置,以实现4×4和8×8的哈达玛变换功能。
蝶形运算单元的电路结构如图6所示。当变换尺寸为4×4时,直接将输入数据通过多路复用器(MUX)输入到第2级蝶形运算单元;当变换尺寸为8×8时,输入数据进行第1级蝶形运算,之后通过MUX选择器进入到第2级蝶形运算单元。
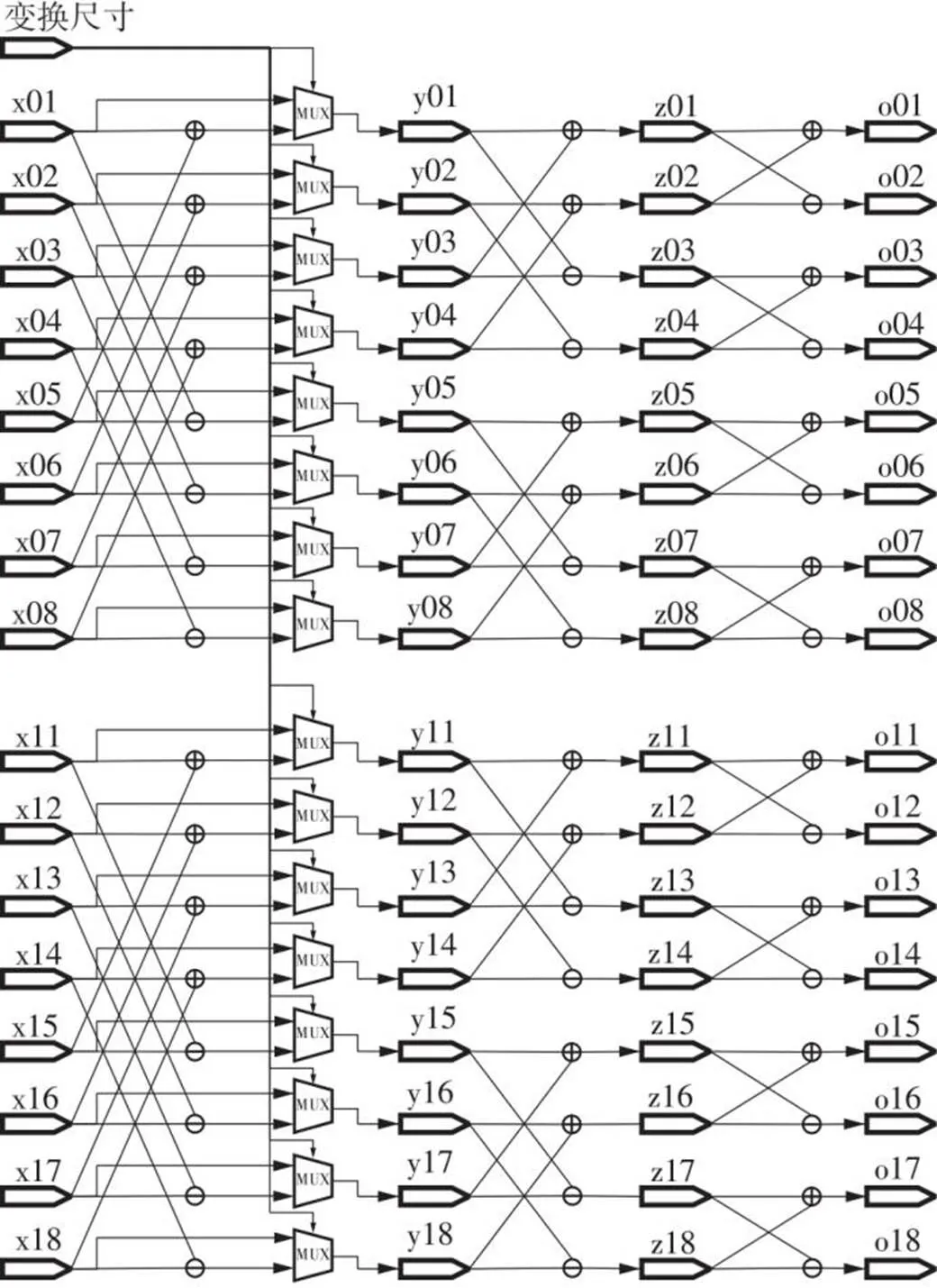
图6 2×8蝶形运算单元的电路结构
当计算的预测单元尺寸为4×4时,4×4残差数据直接经过数据通路1,将数据进行分配整理,发送到第1个2×8蝶形运算单元中实现4×4残差的列变换,之后直接经过数据通路2,将列变换数据进行转置,发送到第2个2×8蝶形运算单元中,得出整个4×4的哈达玛变换结果。
当计算的预测单元尺寸为8×8及以上时,需要进行8×8哈达玛变换,其流水线示意图如图7所示。当得到第0个残差块时,后续流水线电路处于空闲状态;当得到第1个残差块时,得到前4×8的残差数据,第1个2×8蝶形运算单元开始工作,计算第1、2行残差的列变换;当得到第2个残差块时,计算第3、4行残差的列变换;当得到第3个残差块时,得到后4×8的残差数据,计算第5、6行残差的列变换;当得到第4个残差块时,计算第7、8行残差的列变换,此时第1个8×8块完成了所有行的列变换,第2个2×8蝶形运算单元开始工作,计算列变换结果第1、2列的行变换,直到得到第7个残差块时,即可得到第1个8×8的哈达玛变换的全部结果。之后每计算完当前8×8的最后一个4×4块残差,即可得出前一个8×8块的全部变换结果。
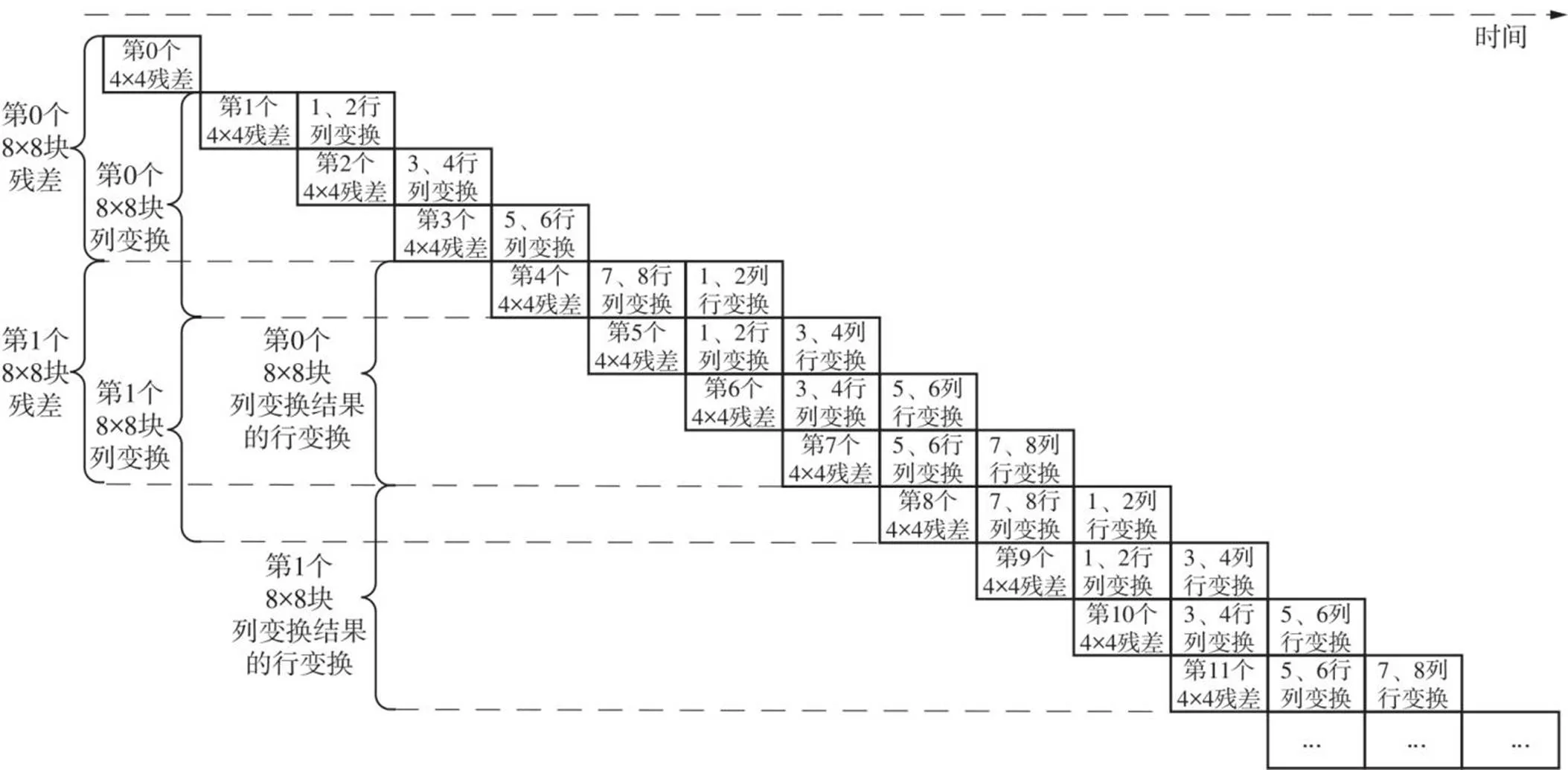
图7 8×8哈达玛变换流水线示意图
3 设计性能分析
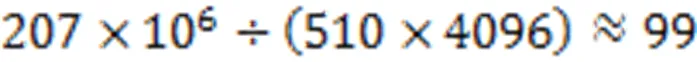
文中设计方案与已有相关设计方案的性能对比如表6所示。文献[8]设计完成一个编码树单元计算需要3万个时钟周期,这很难实现1 080 P高帧率的实时视频编码,文中设计的并行度虽然是文献[8]的9倍,但对LUT资源的使用却不足文献[8]的两倍。与文献[14]设计相比,文中设计的并行度虽然是文献[14]的两倍多,但使用的LUT资源却只增加约3 kb,寄存器资源只增加了5 kb;文中设计完成一个64×64编码树单元计算仅需要4 096个时钟周期,而文献[14]设计完成一个32×32编码树单元的计算则需要5 787个时钟周期;对于1 080 P的视频编码,文中设计能达到的帧率是文献[14]的三倍多。文献[15]设计的并行度太高,为了压缩电路面积而采用下采样的方式,只进行4×4的哈达玛变换,影响了SATD计算的准确性,且其设计的电路在FPGA上仅能达到140 MHz,其1 080 P实时视频编码帧率仅能达到30 f/s,远远低于文中方案的实时编码帧率。文献[16]设计的1 080 P实时编码帧率虽然能达到110 f/s,但使用的硬件资源为文中方案的两倍多,且最大预测块只能达到32×32。
表6 5种设计方案的性能对比
Table 6 Comparison of performance among five design schemes
硬件架构FPGA硬件平台PU大小硬件资源时钟周期数主频1 080 P帧率/(f·s-1) 查找表/kb寄存器/kb 文中方案Altera Arria 1064×64~4×475554 09620799 文献[8]方案Altera Arria 1064×64~4×4441730 000160 文献[14]方案Xilinx Virtex 632×32~4×472505 78719630 文献[15]方案Zyng ZC 70664×64~4×48428 14030 文献[16]方案Xilinx Virtex 632×32~4×4170110892219110
4 结语
HEVC视频编码虽然具有很大的压缩率,但其实现复杂度较高。文中针对HEVC的帧内RDO,基于FPGA平台,提出并实现了9路预测模式并行流水线硬件方案,设计了一个高效的哈达玛变换架构以减小电路面积。实际测试结果表明,文中设计方案完成一个64×64编码树单元的帧内RDO过程,需要约4 096个时钟周期,最大能够实现帧率为99 f/s的1 080 P实时视频编码,且综合性能均优于其他对比设计方案。
[1] 胡永健,龚文斌,刘琲贝,等.修改标志位的大容量无损HEVC信息隐藏方法[J].华南理工大学学报(自然科学版),2018,46(5):1-8.
HU Yongjian,GONG Wenbin,LIU Beibei,et al.Large-capacity lossless HEVC information hiding method by modifying flag bits [J].Journal of South China University of Technology (Natural Science Edition),2018,46(5):1-8.
[2] 朱秀昌,李欣,陈杰.新一代视频编码标准:HEVC[J].南京邮电大学学报(自然科学版),2013,33(3):1-11.
ZHU Xiuchang,LI Xin,CHEN Jie.New generation of video encoding standards:HEVC[J].Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition),2013,33(3):1-11.
[3] KIM Y,JUN D S,JUNG S,et al.A fast intra-prediction method in HEVC using rate-distortion estimation based on Hadamard transform[J].ETRI Journal,2013,35(2):270-280.
[4] KALALI E,HAMZAOGLU I.An approximate HEVC intra angular prediction hardware[J].IEEE Access,2019,8:2599-2607.
[5] SHEN W,FAN Y,HUANG L,et al.A hardware-friendly method for rate-distortion optimization of HEVC intra coding[C]∥ Proceedings of 2014 International Symposium on VLSI Design,Automation and Test.Hsinchu:IEEE,2014:1-4.
[6] XU Y,HUANG X.Hardware-oriented fast CU size and prediction mode decision algorithm for HEVC intra prediction[C]∥ Proceedings of 2019 IEEE the 5th International Conference for Convergence in Technology.Bombay:IEEE,2019:1-5.
[7] ZHANG Y,LU C.Efficient algorithm adaptations and fully parallel hardware architecture of H.265/HEVC intra encoder[J].IEEE Transactions on Circuits and Systems for Video Technology,2018,29(11):3415-3429.
[8] 杨贺,杨秀芝,陈建.一种新的基于FPGA的HEVC帧内预测硬件结构[J].福州大学学报(自然科学版),2020,48(3):318-324.
YANG He,YANG Xiuzhi,CHEN Jian.A new hardware structure of HEVC intra prediction based on FPGA [J].Journal of Fuzhou University(Natural Science Edition),2020,48(3):318-324.
[9] MIN B,XU Z,CHEUNG R C C.A fully pipelined hardware architecture for intra prediction of HEVC[J].IEEE Transactions on Circuits and Systems for Video Technology,2016,27(12):2702-2713.
[10] LU W,YU N,NAN J,et al.A hardware structure of HEVC intra prediction[C]∥ Proceedings of 2015 the 2nd International Conference on Information Science and Control Engineering.Shanghai:IEEE,2015:555-559.
[11] CHEN W,HE Q,LI S,et al.Parallel implementation of H.265 intra-frame coding based on FPGA heterogeneous platform[C]∥ Proceedings of 2020 IEEE the 22nd International Conference on High Performance Computing and Communications;IEEE the 18th International Conference on Smart City;IEEE the 6th International Conference on Data Science and Systems.Yanuca Island:IEEE,2020:736-743.
[12] WANG M,WEI H,FANG Y,et al.Fast mode selection algorithm for HEVC intra encoder[C]∥ Proceedings of 2018 IEEE International Conference on Automation,Electronics and Electrical Engineering.Shenyang:IEEE,2018:169-172.
[13] TARIQ J,IJAZ A,ARMGHAN A,et al.HEVC’s intra mode process expedited using Histogram of oriented gradients[J].Journal of Visual Communication and Image Representation,2022,88:103594/1-10.
[14] 杨秀芝,赵敏,施隆照,等.面向硬件的帧内预测模式选择快速算法与实现[J].计算机辅助设计与图形学学报,2019,31(1):158-164.
YANG Xiuzhi,ZHAO Min,SHI Longzhao,et al.Research and implementation of fast algorithm for intra prediction mode selection oriented to hardware[J].Journal of Computer-Aided Design & Computer Graphics,2019,31(1):158-164.
[15] ATAPATTU S,LIYANAGE N,MENUKA N,et al.Real time all intra HEVC HD encoder on FPGA[C]∥ Proceedings of 2016 IEEE the 27th International Conference on Application-specific Systems,Architectures and Processors.London:IEEE,2016:191-195.
[16] AMISH F,BOURENNANE E.Fully pipelined real time hardware solution for high efficiency video coding (HEVC) intra prediction[J].Journal of Systems Architecture,2016,64:133-147.
Parallel Pipeline Hardware Design of Intra Rate-Distortion Optimization Prediction Mode in HEVC
(College of Physics and Information Engineering,Fuzhou University,Fuzhou 350108,Fujian,China)
In recent years, the resolution and frame rate of video have been continuously improved to meet people’s increasing demand for video data. However, the compression encoding speed of real-time video sequence is often restricted by frame rate and resolution. The higher the frame rate and resolution are, the longer the encoding time will be. In order to achieve real-time compression encode for video sequences with higher resolution and frame rate, this paper designed a new parallel pipeline hardware architecture of intra rate-distortion optimization prediction mode, which supports intra prediction coding of up to 64×64 coding tree unit. Firstly, a parallel scheme with 9-way prediction mode was designed. Secondly, a pipeline hardware architecture was implemented based on a 4×4 block as the basic processing unit in a Z-shaped scanning order, and the prediction data of 32×32 prediction units were reused to replace the prediction data of 64×64 prediction units so as to reduce the amount of calculation. Lastly, a new Hadamard transform circuit was proposed based on this pipelined architecture for efficient pipelined processing. The experimental results show that: on the Altera Arria 10 series field programmable gate array, the 9-way mode parallel architecture only occupies 75 kb look up table and 55 kb register resources, the main frequency can reach 207 MHz, and it only takes 4 096 clocks cycles to complete a 64×64 coding tree unit prediction and can support real-time encoding of 1 080 P resolution 99 f/s full I-frame at most. Compared with the existing design scheme, the scheme designed in this paper can realize higher frame rate 1 080 P real time video encoding with smaller circuit area.
intra prediction;field programmable gate array;mode in parallel;high efficiency video coding
Supported by the General Program of the National Natural Science Foundation of China(61871132,62171135)
10.12141/j.issn.1000-565X.220612
2022⁃09⁃20
国家自然科学基金面上项目(61871132,62171135);福建省高等学校科技创新团队项目(产业化专项,500190)
林志坚(1984-),男,博士,副教授,主要从事视频编码、FPGA设计研究。E-mail:zlin@fzu.edu.cn
吴林煌(1984-),男,博士,副研究员,主要从事视频编码、计算机视觉研究。E-mail:wlh173@163.com
TP391.41
1000-565X(2023)05-0095-09
