基于聚类和高斯变异的多目标粒子群算法
2023-06-30项铁铭郑斌豪
程 兵,项铁铭,郑斌豪
(杭州电子科技大学电子信息学院,浙江 杭州 310018)
0 引 言
粒子群算法(Particle Swarm Optimization,PSO)是一种群聚智能优化算法,源于对鸟类捕食行为的研究[1]。鸟类捕食时,找到食物最简单有效的策略就是搜寻距离食物最近的区域,基于该思想衍生的多目标粒子群算法广泛应用于工程实践。例如,Sannigrahi等[2]将多目标粒子群算法应用于配电系统规划;邢小红等[3]运用多目标优化算法解决水库洪水调度问题;张玉平等[4]将多目标粒子群算法应用于斜拉桥索拉力优化分析。PSO具有结构简单、收敛速度快等特点[5],但由于多目标问题本身的复杂性,运用该算法解决多目标问题时,很难确定多目标优化问题中的局部最优个体和全局最优个体,搜索精度不高,容易陷入局部最优解[6]。为此,本文提出一种改进的多目标粒子群算法,将K-means聚类算法[7]和高斯变异算法融合到多目标粒子群算法的迭代过程中,避免算法陷入局部最优解的同时还提高了算法的局部搜索能力和精度。
1 基础理论
1.1 多目标优化问题
在科学研究和工程实践中遇到的问题大多是多目标优化问题,不仅涉及多个目标函数的优化,各优化目标之间也存在复杂的约束关系[8]。在优化部分目标的同时,往往出现其他目标遭受损失的情况,很难得到同时使每个目标达到最优的结果。所以,多目标问题并不存在一个可以满足全部目标的全局最优解,只能对所有目标进行权衡,得到相对较优的解,这些解组成了多目标优化问题的解集。
一个包含m个目标函数,n个决策变量,p个不等式约束和q个等式约束的多目标优化问题,表示如下:
(1)

1.2 标准粒子群算法
PSO中的每个粒子都代表问题的一个潜在解,粒子的适应度值用来衡量位置的好坏,粒子的速度决定了该粒子的运动方向和距离,并且速度随着个体最优值(pbest)和全局粒子的历史最优值(gbest)进行动态调整,从而实现优化。
粒子群算法的迭代公式如下:
(2)
xi(t+1)=xi(t)+vi(t+1)
(3)
式中,vi(t)和xi(t)分别表示第i个粒子在t时刻的速度和位置,w为惯性权重,用于平衡局部搜索和全局搜索,c1和c2分别表示个体最优和历史最优的学习因子,决定粒子在进化过程中向个体最优和群体最优学习的权重大小,r1和r2为加速因子,是介于[0,1]之间的随机数。
2 基于聚类和高斯变异的多目标粒子群算法
针对PSO算法的局部搜索能力不足、收敛精度不高、算法易陷入局部最优解等缺陷,本文分别从惯性参数动态变化方式、个体最优和全局最优的选取、解的多样性维护、种群的变异等方面进行改进,提出一种融合多种改进策略的多目标粒子群算法。
2.1 权重非线性变化策略
在PSO中,惯性权重w通常随着当前迭代次数T动态变化。一些改进的粒子算法采用惯性权重线性下降策略来加强算法的寻优能力,权重变化公式如下:
(4)
式中wmax和wmin分别为惯性参数w的最大值和最小值,Tmax为最大迭代次数。
但是,线性下降策略的搜索精度不高,在优化过程中,最好是一开始就着重于全局搜索,后期逐渐收敛后再着重于局部搜索,这样不仅可以提升算法的收敛速度,而且还可以提高算法的搜索精度。为此,本文提出一种惯性权重余弦递减策略,权重变化公式如下:
(5)
由式(4)和式(5)得到惯性权重随迭代次数T的变化趋势如图1所示。

图1 2种权重变化策略下,惯性权重随迭代次数T的变化曲线
从图1可以看出,和线性下降策略相比,余弦递减策略下的惯性权重w在算法搜索过程的前期和后期的下降速率更为缓慢,说明该策略下,算法在前期具有较强的全局搜索能力,在后期具有较高的局部搜索精度。
2.2 个体最优值的选取
在个体最优值选取过程中,以往的做法是将个体的当前位置与其历史最优位置进行比较,选出一个非支配解作为个体最优值。但是,在算法后期,要优化的目标数较多时,个体的当前位置与其历史最优位置往往不存在支配关系,无法直接比较,如果随机选择其中一个解作为个体最优值,反而会降低算法的性能。为此,本文在Pareto支配原则的基础上,提出更为精细的比较方法。依据Pareto支配原则进行比较,如果两者存在相互支配关系,则将其中的非支配解直接作为个体最优值,如果互相不支配,则进一步比较两者所在每一个目标函数上适应度值的大小,分别统计两者适应度值较小的次数,选择较小次数多的解作为个体最优值,避免在2个解互不支配情况下盲目选取个体最优值。
2.3 全局最优值的选取
多目标粒子群算法需要解决的一个重要问题是全局最优值的选取。本文采用拥挤距离排序的方法来确定每个粒子的全局最优解。首先,按照拥挤距离的定义,计算外部存档中每个粒子的拥挤距离,并从大到小排序;然后,将前20%的粒子单独取出,按轮盘赌法为每个粒子选取全局最优值,处在稀疏区域的粒子拥挤距离大,被选中成为粒子全局最优解的概率就大,不仅有利于算法的快速收敛,还可以保证解集分布的均匀性。
2.4 基于聚类算法的高斯变异策略
标准多目标粒子群算法很容易陷入局部最优解,导致算法早熟,收敛精度差。为了提高算法的性能,本文将K-means聚类算法和高斯变异算法融合到标准粒子群算法中。
从非支配解集中随机选取k个解作为初始聚类中心{C1,C2,…,Ck},再计算每个粒子到每个聚类中心的距离,
(6)
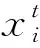
依次比较每个粒子到每个聚类中心的距离,将粒子划分到距离其最近的聚类中心所在的类中,得到k个类簇{S1,S2,…,Sk}。每次分类完成之后,重新计算聚类中心,将本类中所有粒子在各个维度上的均值作为下次分类的聚类中心,以此循环计算,直至满足算法要求。聚类中心更新计算公式如下:
(7)
式中,Cl表示第l个类中心,|Sl|表示第l个类簇中包含解的个数,xi表示第l个类簇中的第i个粒子。最终将解集分为k类,并且满足误差平方和达到最小。误差平方和(Sum of Squares for Error,SSE)的定义如下:
(8)
式中,dist(xi,Cl)表示类Sl中的第i个解到该类中心Cl的距离。
所有非支配解均经过K-means聚类后,再计算得到每个类中所有粒子的每一维度上的方差σ,以该方差为依据,为该类中的每个粒子进行变异,具体变异公式如下:
(9)
(10)
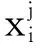
3 仿真实验与分析
在Windows 10 Intel(R) Core(TM) i7-7500U MATLAB2020a的环境下,选用ZDT2-ZDT4[10]和DTLZ1-DTLZ2[11]测试函数,分别对标准多目标粒子群算法MOPSO、基于精英策略的快速非支配排序遗传算法(NSGA-Ⅱ)[12]、基于2个局部最佳的多目标粒子群算法(2LBMOPSO)[13]、使用拥挤距离机制和突变操作保持非支配解多样性的多目标粒子群算法(MOPSO-CD)[14]、基于精英学习策略的粒子群算法(MOPSO-ELS)[15]和本文改进的多目标粒子群算法进行仿真实验。6种算法均采用相同设置,种群和外部存档规模N=100,迭代次数T=1 000,惯性权重wmax和wmin分别取2.0和0.4。分别统计每种算法在30次独立运行下求得的反转世代距离(Inverted Generational Distance,IGD)[16]、超体积(Hypervolume, HV)[17]、多样性(Diversity,DIV)[18]、空间性(Spacing,SP)[19]的均值(Mean)和标准差(Std),本文选取(1,1)和(1,1,1)两点分别作为二目标和三目标测试函数HV指标计算的参考点,其中“—”表示数据超出有效范围,实验结果如表1所示。
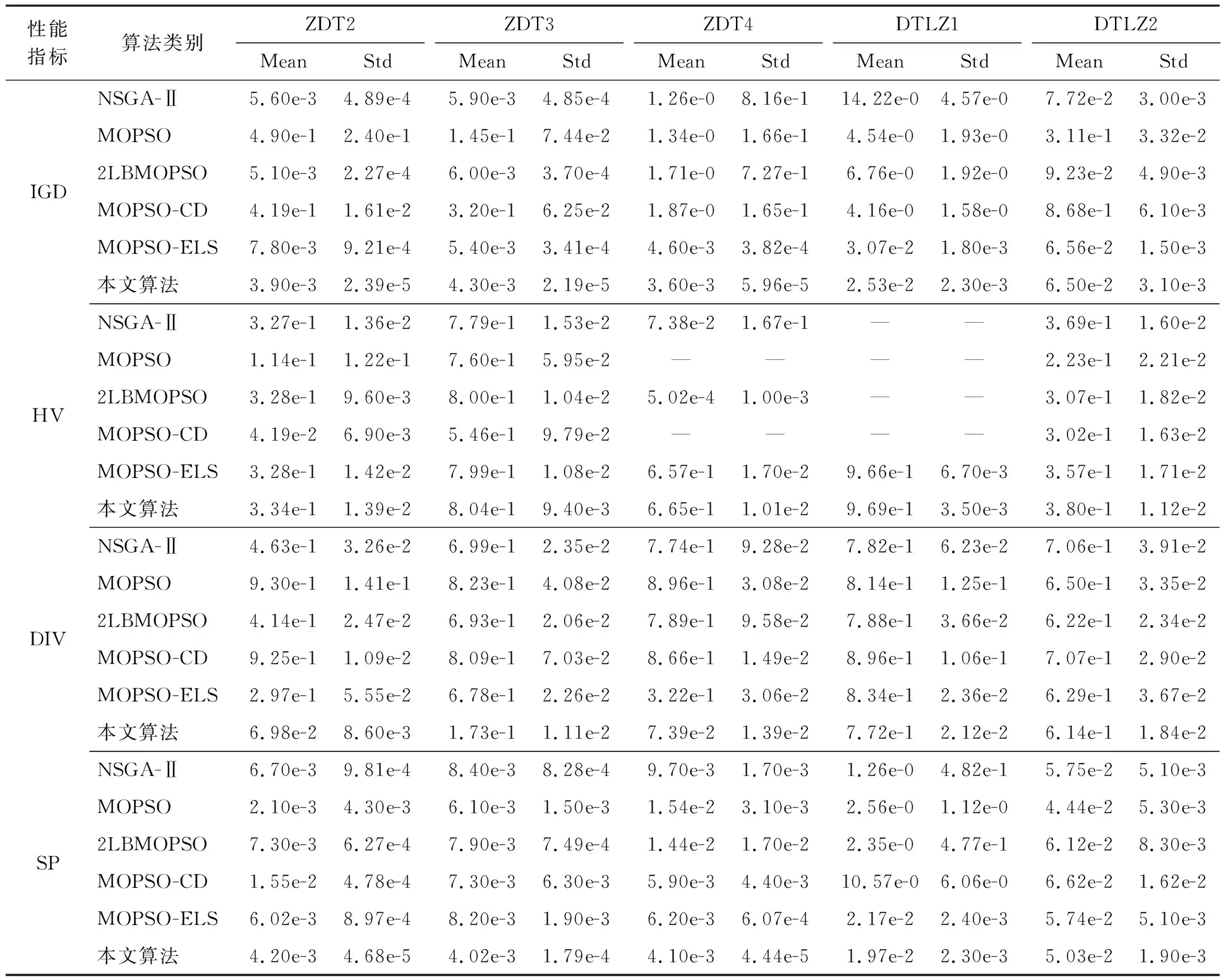
表1 不同算法的性能指标
从表1可以看出,本文算法的IGD,HV和DIV的均值比其他5种算法小,同时SP指标的均值也取得3个较好的结果,说明本文算法得到的近似Pareto前沿更收敛于真实Pareto前沿,分布也更均匀。
为了更加直观地观察非支配解集在目标空间的分布情况,分别画出6种算法得到的非支配解在目标空间的分布和真实Pareto前沿的分布。在二目标测试函数中,星形点和圆形点分别为算法得到的近似Pareto前沿和真实Pareto前沿,在三目标测试函数中算法得到的近似Pareto前沿和真实Pareto前沿分别用圆形点和透明的阴影平面或曲面表示。具体分布情况如图2—图6所示。

图2 ZDT2真实Pareto前沿和近似Pareto前沿的分布

图3 ZDT3真实Pareto前沿和近似Pareto前沿的分布
从图2—图4可以看出,在所有的ZDT系列测试函数中,本文算法得到的解集更收敛于真实的Pareto前沿,两者几乎重合。从图5—图6可以看出,在DTLZ1和DTLZ2测试函数上,其他5种算法得到的解要么完全不收敛,要么在某个区域内有大量的解聚集,解的分布较差,而本文算法得到的解的分布更均匀。从解的分布图还可以看出,NSGA-Ⅱ,MOPSO,2LBMOPSO,MOPSO-CD这4种算法在ZDT4与DTLZ1测试函数上并不收敛,将迭代次数增加到1 500次时,得到的解仍然不收敛,和迭代1 000次得到的解的收敛程度相比,没有明显变化,说明这4种算法跳出局部最优解的能力较差。
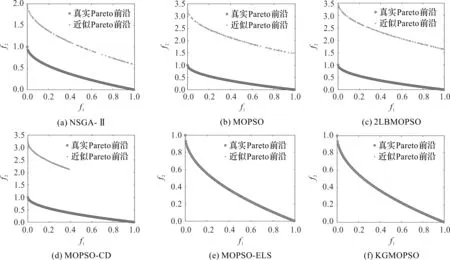
图4 ZDT4真实Pareto前沿和近似Pareto前沿的分布

图5 DTLZ1真实Pareto前沿和近似Pareto前沿的分布
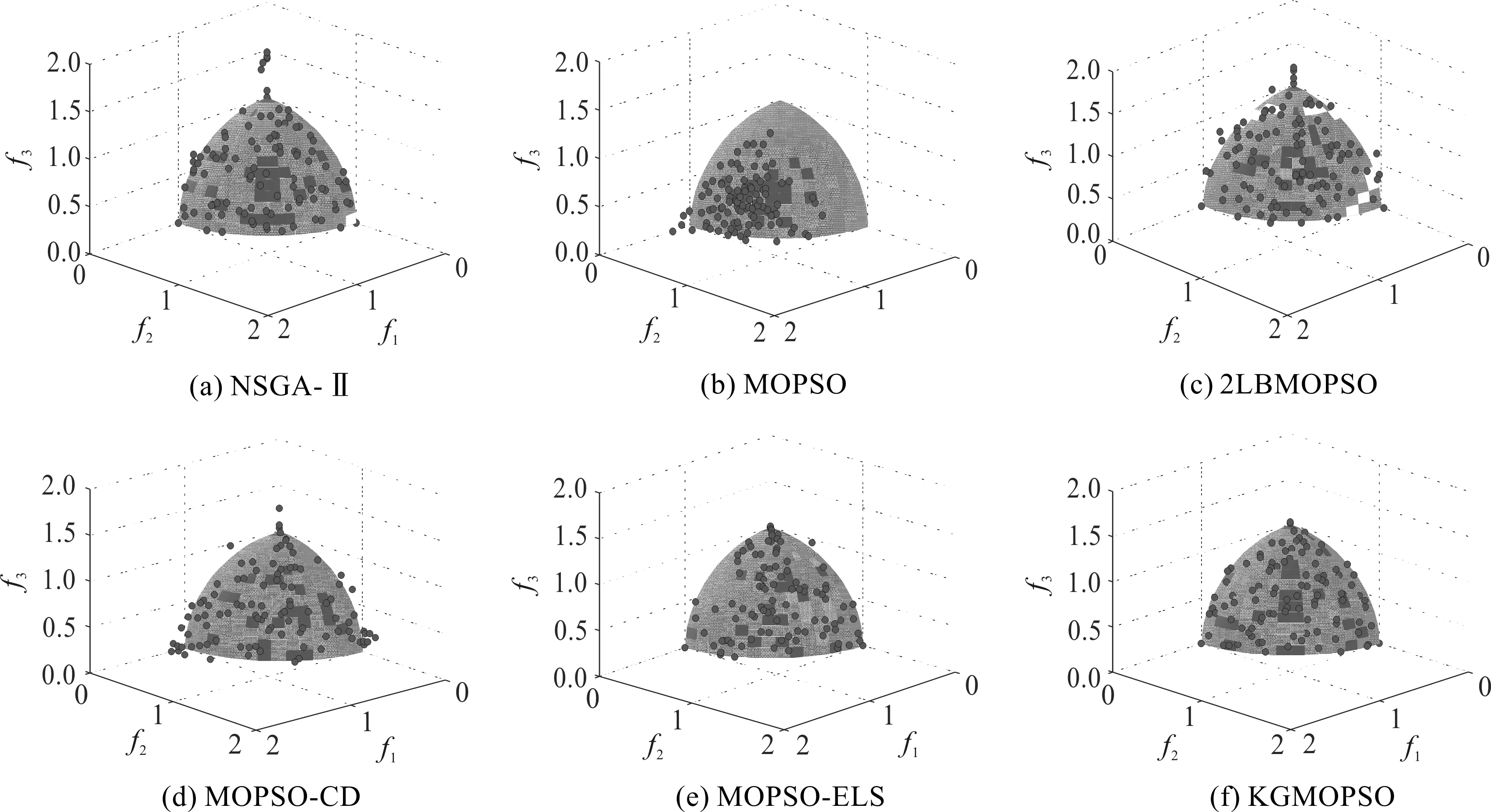
图6 DTLZ2真实Pareto前沿和近似Pareto前沿的分布
4 结束语
针对多目标优化遇到的问题,本文对标准多目标粒子群算法进行改进,提出了惯性参数余弦递减策略和基于K-means聚类算法的高斯变异策略,提升了算法的搜索精度和避免陷入局部最优解,并对Pareto支配关系进行改进,在保证良好的全局搜索能力的同时,增强了算法的局部搜索能力和搜索精度。虽然,改进算法在所有测试函数上都得到分布更收敛、更均匀的解集,但仿真实验只是针对一些特定的测试函数进行优化,目标数较少,说服力还不够,后续将进一步改进算法,以解决更多目标的优化问题。
