基于Seq2Seq模型的GRACE降尺度研究
2023-06-27吕博文
吕博文,陈 雨
(四川大学电子信息学院,成都 610065)
0 引言
随着全球人口和水需求的增加,监控全球水的储量与趋势对于水资源管理、危害分析与减灾以及粮食安全是十分有必要的,而拥有高分辨率且连续的水文数据对于预测水文气候趋势和水资源可用性至关重要[1-4]。在全球水资源总体储量中,淡水储量占比不到百分之三,而可供人开采饮用的部分中,地表水所占比重仅为0.39%,地下水量占比则达到了30.06%[5]。传统监测地下水储量变化(GWSA)的手段有很大局限性,如偏远地区测量难度大、设备维护不易等。重力恢复和气候试验(gravity recovery and climate experiment,GRACE)卫星的发射为区域水储量估算提供了一种新的手段[6]。GRACE 卫星可以获取全球重力场的微小变化,通过反演可得到陆地水储量变化,从而可以间接监测到地下水储量变化[7]。但是由于GRACE 数据本身的低空间分辨率,使得其在中、小尺度区域上的应用受到了很大限制。近年来,研究人员为了克服GRACE 数据低空间分辨率的限制,做了很多降尺度的研究,降尺度一般分为动态降尺度与统计降尺度[8],相比于动态降尺度,统计降尺度有着计算简单、误差小等优势,统计降尺度是通过获取预测因子与被预测因子的统计经验关系,将经验关系用于高分辨率的预测因子,从而得到高分辨率的被预测因子。早期的统计降尺度方法一般采用非线性回归建立预测因子与被预测因子的统计经验关系,随着计算机技术的发展,很多机器学习方法被用于GRACE 统计降尺度的研究。主要用到的方法有随机森林回归[9]、增强回归树[10]、人工神经网络(ANN)[11]等。
目前的GRACE 统计降尺度研究中,寻求的是单月的预测因子与单月GRACE 之间的经验关系,但是对于时间步长大于1情况下的关系探寻的研究很少。基于以上情况,本文采用Seq2Seq模型提取作为预测因子的气象遥感数据的时间特征,并用于预测其对应的GRACE 数据,然后结合高分辨率的气象遥感数据将美国加利福尼亚州月尺度的GRACE 数据分辨率从1°×1°提高为0.1°×0.1°,并结合实测数据验证降尺度结果,以论证该模型在GRACE降尺度上的可行性。
1 研究数据
1.1 GRACE数据
GRACE 数据是美国NASA(美国国家航空航天局)一组GRACE 卫星测量地球重力场变化的数据。通过反演算法能够解算出地球等效水高、地球冰川、地壳形变等物理量的变化。本文采用的是JPL 发布的Level-3-RL06-v04 版本的GRACE 数据集,其反映的是地球等效水高的变化量,空间分辨率为1°×1°,包含2002 年4 月到2017年6月共183个月份的数据(有缺失月份),数据下载地址为https://podaac.jpl.nasa.gov/GRACE。
1.2 气象遥感数据
本文用于模型预测的气象遥感数据有地表温度(land surface temperature, LST)、归一化植被指数(normalized difference vegetation index,NDVI)和降雨。其中LST 数据和NDVI 数据来自美国地质调查局(Geological Survey, USGS)和陆地过程分布式数据档案中心(land processes distributed active archive center, LPDAAC)发布的MODIS 数据产品。LST、NDVI 分别选用了MOD11C3、MOD13C2 产品,提供的是0.05°×0.05°的月度LST 和NDVI。降雨数据是NASA 全球降雨测量的IMERG 月度产品,其空间分辨率为0.1°×0.1°。三种数据选取的时间范围均为2002年4月到2017年6月共183个月份。
1.3 地下水数据
本文选取美国加州自然资源局开放数据门户发布的连续地下水位测量数据(https://wdl.water.ca.gov/waterdatalibrary),用作降尺度结果验证。
2 模型与方法
2.1 LSTM
对于时间序列,其特征复杂,传统的基于统计学的方法难以获取准确的时间特征。循环神经网络RNN 提供了一种全新的能提取数据时间特征的方法,但是RNN 网络在短的时间步长表现良好,而在长时间步长的训练过程中容易出现梯度消失或梯度爆炸现象[12]。Hochreiter等[13]提出的长短时记忆(long short-term memory,LSTM)网络结构克服了这方面的问题,在提取时间特征时的效果显著提高。
所有的循环神经网络都具有神经网络重复模块链的形式,在标准RNN 中,这个重复模块是一个非常简单tanh层结构,而LSTM 网络是一种特殊的RNN 网络,Hochreiter等[13]通过设计特殊的结构(见图1)取代RNN 中简单的线性神经元,来学习数据的长期依赖关系。
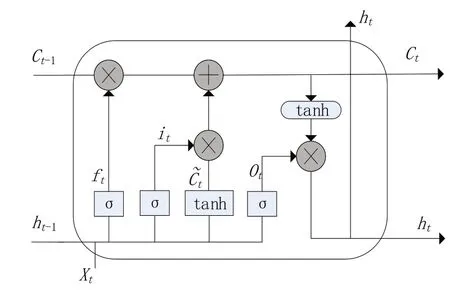
图1 LSTM Cell结构
LSTM 能学习长期依赖关系的关键在于其结构中的细胞状态Cell,它在整个网络运行过程中只会经历一些简单的线性变换,信息能更好地保留,然后通过门结构对细胞状态中的信息进行删除和添加。其中遗忘门ft决定上一时刻Ct-1中的哪些信息会被丢弃。更新门it决定向细胞状态中添加哪些信息。而输出门Ot决定的是该LSTM Cell 的最终输出,这些过程对应于以下计算公式:
其中:σ是Sigmoid 激活函数,ht-1是t-1 时刻的隐藏层权重,Ct-1是t-1 时刻的细胞状态值,W,b是不同门结构的权重与偏置。
2.2 Seq2Seq
LSTM网络虽然在长期依赖问题上比RNN做的更好,但是在处理高度非线性、时间间隔长的数据时,很难直观地获取到准确的时间序列的复杂特征。在考虑数据的时序特性时,本文的降尺度问题可以看作是多对多的序列到序列问题,因此,本文采用基于注意力机制的Seq2Seq 模型[14]来学习输入时序到输出时序的对应关系,其结构如图2所示。

图2 Seq2Seq模型结构
在模型中,编码器的主要任务是将输入序列编码为固定长度的向量表示,以捕捉输入时序的时间特征。常用的编码器结构包括RNN、CNN 等,本文的模型采用的是双向LSTM,双向LSTM 不仅能捕捉过去的信息,还能捕捉后续的信息,相比于单向LSTM 对时间特征的捕捉能力更强;解码器则是将特征解码为可变长度的输出序列,对于时间序列任务,解码器一般是单向的RNN 模型,本文的解码器采用的是结合注意力机制的单向LSTM,注意力机制会计算编码器每个时刻的输出与解码器当前时刻隐藏层状态向量的权重,从而决定当前时刻解码器的输出更注重哪个时刻的编码器输出,这就使得整个模型在长序列任务上的鲁棒性更强。
3 模型训练
3.1 数据预处理
对于LST、NDVI和降雨数据,其原始空间分辨率分别为0.05°×0.05°、0.05°×0.05°和0.1°×0.1°,本文使用最近邻重采样将这三种数据重采样至1°×1°,与GRACE 数据原始空间分辨率保持一致,另外,LST 和NDVI 数据需要再重采样一份到0.1°×0.1°的空间分辨率,与降雨数据原始分辨率保持一致,用于组成高分辨率的预测因子。由于GRACE 数据中存在缺失月份,不能直接作为时间序列使用。本文采用线性插值方法填补空缺月份数据。
由于LSTM 网络激活函数采用tanh 激活函数。tanh 激活函数可将输入从[-∞, +∞]映射到[-1,1]之间,但是当输入值很大时,其梯度几乎为0,导致使用梯度优化算法时权重更新很慢,因此还要把输入数据归一化到[-1,1]之间。
3.2 超参数设置
Seq2Seq 模型中的超参数主要有编码器、解码器里LSTM 的隐藏神经元个数和输入数据的时间步长。为了方便注意力机制的计算,一般将编码器和解码器的隐藏层神经元个数设置相同。本文采用遗传算法(genetic algorithm,GA)优化模型超参数。GA 算法是借鉴了自然进化规律而设计出的一种寻找全局最优解的模型,通过群体N代间的不断遗传、交叉、变异找到问题的最优解。实验将编码器与解码器的隐藏神经元设置为2 的4~8 次方,时间步长设置为1~12,随机产生8 个群体,通过20 代的遗传进化找到最优解,最后综合每种超参数组合下的模型评价指标(见4.1 小节)选择最优模型,实验结果表明当编码器与解码器的隐藏神经元个数为64,时间步长为12时,模型表现最佳。
3.3 模型训练
本文的研究地区为美国加利福尼亚州的15个点位,其中12 个点位(80%)的数据用作训练集,3个点位(20%)的数据用于测试,每个点位的数据都是2002 年4 月到2017 年6 月共183 个月份的数据。为了防止训练出现过拟合,本文在编码器和解码器后面都加了一层Dropout层[15],并且模型最后的输出层使用RReLU 非饱和激活函数[16]。GA 算法的实现采用了Python 分布式进化算法库(DEAP)。模型运行环境主要基于PyTorch 1.11.0版本搭建而成,Python版本为3.8,运行系统为64位Windows10系统。
4 实验结果与分析
4.1 模型评价
本文采用的模型评价标准是均方根误差RMSE、纳什系数NSE和相关系数r。
RMSE是一种估计测量方法,计算的是预测值与实际值之间的数值差异。RMSE的值域为[0, + ∞),误差越小,RMSE越小。其表达式为
NSE系数可以测量模型相对于实际数据平均值的预测能力,用来表明实际值与模型预测数据的曲线是否符合1∶1 的线性关系,可以用于对比不同模型对同一数据的拟合优度。NSE取值为负无穷至1,NSE接近1,表示模式质量好,模型可信度高;NSE接近0,表示模拟结果接近观测值的平均值水平,即总体结果可信,但过程模拟误差大;NSE远远小于0,则模型是不可信的。计算公式如下:
相关系数r是衡量向量相似度的一种方法,可以用来表示未来结果在多大程度上可被模型预测,取值范围为[-1,1],正值表示正相关,且越接近1表示越相关。其计算公式如下:
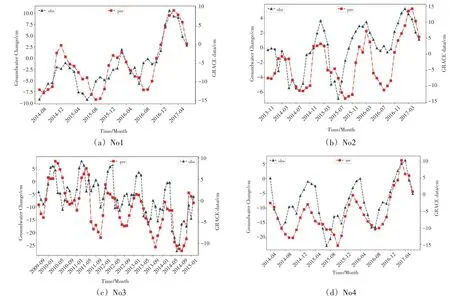
图3 实测地下水验证
在使用相同数据的情况下,本文分别训练了Seq2Seq 模型、LSTM 模型以作对比,其中LSTM 模型的超参数同样通过GA 算法进行调优,实验结果为隐藏层神经元个数为64,时间步长为6时表现最佳。训练好的模型在测试集的评价指标见表1。可以看出在三种评价指标中,Seq2Seq 模型的表现强于LSTM 模型,说明Seq2Seq 模型在时间特征的提取与利用上要优于LSTM模型。
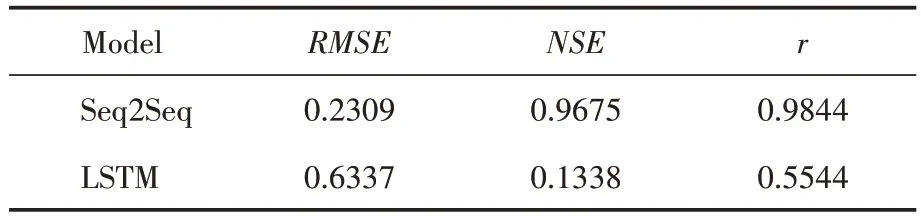
表1 模型表现
4.2 降尺度结果分析
本文使用实测地下水数据来验证GRACE 降尺度结果。首先,使用地下水数据验证GRACE降尺度结果前需要经过一定处理,根据GRACE数据的官方说明可知,GRACE 数据是减去了2005 年到2010 年平均值的,于是对应的地下水水位数据也需要经过相同的处理。本文从美国加利福尼亚州的连续地下水数据中选取了4个点位作为验证区,编号No1~No4。然后向训练好的模型输入0.1°×0.1°的由LST、NDVI 和降雨组成的输入数据,得到降尺度后的GRACE 数据,结果如图3所示。
图3 中,从左到右分别为验证区No1~No2、No3~No4,图中的实线obs 为地下水实测值,虚线pre 为降尺度后的GRACE 数据。可以看出,降尺度后的GRACE 数据与实测地下水的整体趋势基本一致,能够通过降尺度后的GRACE 数据反映地下水的变化。
通过对比计算实测地下水与降尺度后的GRACE 数据的相关系数(结果见表2),可以看出Seq2Seq模型的降尺度结果整体表现良好,相比于LSTM能捕获更多的时间特征。

表2 降尺度结果验证
5 结语
本文通过基于注意力机制的Seq2Seq模型获取LST、NDVI、降雨三种时间序列与GRACE 序列的对应关系,将美国加利福尼亚州地区2002—2017 年的GRACE 数据的空间分辨率从1°×1°提高为0.1°×0.1°。实现了一种基于时间序列映射到时间序列的降尺度方法。并且通过对比降尺度后的GRACE 数据与实测陆地水储量变化量的差异可以发现,Seq2Seq 模型捕获的时间特征相比于LSTM 模型更多,更适用于GRACE降尺度的研究。
鉴于当前研究中存在的不足,后续可以进行更深入的改进。首先是本文选用的预测因子仅为LST、NDVI和降雨,虽然有数据获取容易、降低模型复杂度等优势,但是因为没有考虑蒸散发、人为因素等对GRACE 数据的影响,降低了降尺度的准确度,在对准确度要求较高的应用中需要将这些因素考虑进去。另外由于GRACE 数据存在缺失月份,本文使用线性插值进行了补全,但是也带来了新的不确定性,这可能会丢失部分时间特征。而随着GRACE-FO卫星的升空,继续执行重力场探测任务,这意味着会有更多的训练数据,这将更有利于深度学习模型发挥自身的优势,得到更准确的预测结果。
