基于Word2Vec及TextRank算法的长文档摘要自动生成研究
2023-06-25朱玉婷刘乐辛晓乐陈珑慧康亮河
朱玉婷 刘乐 辛晓乐 陈珑慧 康亮河


基于Word2Vec及TextRank算法的长文档摘要
自动生成研究
朱玉婷,刘乐,辛晓乐,陈珑慧,康亮河
(甘肃农业大学,甘肃 兰州 730070)
摘 要:近年来,如何从大量信息中提取关键信息已成为一个急需解决的问题。针对中文专利长文档,提出一种结合Word2Vec和TextRank的专利生成算法。首先利用Python Jieba技术对中文专利文档进行分词,利用停用词典去除无意义的词;其次利用Word2Vec算法进行特征提取,并利用WordCloud对提取的关键词进行可视化展示;最后利用TextRank算法计算语句间的相似度,生成摘要候选句,根据候选句的权重生成该专利文档的摘要信息。实验表明,采用Word2Vec和TextRank生成的专利摘要质量高,概括性也强。
关键词:Jieba分词;关键词提取;Word2Vec算法;TextRank算法
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2023)04-0036-04
Research on Abstract Automatic Generation of Long Document Based on the Word2Vec + TextRank Algorithm
ZHU Yuting, LIU Le, XIN Xiaole, CHEN Longhui, KANG Lianghe
(Gansu Agricultural University, Lanzhou 730070, China)
Abstract: In recent years, how to extract critical information from large amounts of information has become a problem which needs to be solved urgently. For Chinese patent long documents, a patent generation algorithm combining Word2Vec and TextRank is proposed. Firstly, Python Jieba technology is used to segment words in Chinese patent documents, and meaningless words are removed by using the stop dictionary. Secondly, the Word2Vec algorithm is used for feature extraction, and the extracted keywords are visually displayed by WordCloud. Finally, the TextRank algorithm is used to calculate the similarity between sentences, generate abstract candidate sentences, and generate abstract information of the patent documents according to the weight of candidate sentences. Experiments show that patent abstracts generated by Word2Vec and TextRank are of high quality and have strong generalization.
Keywords: Jieba word segmentation; keyword extraction; Word2Vec algorithm; TextRank algorithm
0 引 言
21世紀,由于时代的进步与信息科技的飞速发展,大数据时代也随之来临,传统的手工编织文摘已经落后,人们获取信息的便捷度不断提高,信息量不断增加,使文本信息出现爆炸式增长。如何从大量信息中提取出重要信息还有待解决。在大量数据中提取出具有价值的信息已经成为一个重要的研究方向。自动文摘是全面反映文本信息主要内容的短文本,也具有简洁连贯的特点。自动摘要技术是计算机通过写一些算法和输入的文章自动生成摘要的技术[1],到目前为止,国外做的一些自动文本摘要技术已经取得了成果,英文文本的摘要技术也已经被提出。而中文文本提取摘要的技术上依旧不够成熟,在提取结果上依然有很大的进步空间,而国内的研究目前仍处于初级阶段,因此,根据中文的特点,制作设计出一个中文文本的自动摘要系统显得尤为重要[2]。
自动文本摘要兴起于20世纪50年代,在1958年IBM公司的Luhn[3]第一次进行了自动文本摘要的研究,宣布了这项技术的产生。刘志明[4]等利用LDA主题模型结合TextRank自动摘要方法,解决了不同文档结构及内容特征等问题对摘要结果的影响,实验表明,该方法能更为高效的获取新闻文本摘要结果。Salton[5]提出了著名的TF-IDF方法,词语的重要程度也被这个方法精确科学的评估到了,所以才能更加精确地抽取主要句子生成摘要。HU[6]等人在K-means算法的基础上进行了摘要提取。相较国外,国内从事自动文本摘要的研究相对较晚,王永成[7]等人在20世纪80年代开发了用于中文文献的自动文本摘要系统。国外学者Kchaou[8]等根据文本的相似度计算,克服了现有的CIA方法一方面集中在一个时间段产生的模型,另一方面忽视了整个开发阶段产生的各种各类的模型之间的语义相互依赖关系的问题。Li[9]等人提取关键词用到了TextRank算法,最后通过神经网络得到了关键词,并将其与点生成网络进行结合,来指导摘要生成任务的进。程园[10]等人一起制作了一个特征加权函数,在文本的训练中用到了数学回归模型,使一些冗余句子的信息被去除,进而生成关键词得到文本摘要。徐飞[11]等人利用文本结构分析等技术方法实现了中文自动摘要系统。
文章主要研究的是如何从一篇篇幅较长的专利性文本中提取出其中的关键词,使其输出文本摘要。在用一些主要的编码生成摘要时,会有目标算法与评价指标不一致以及结果与预测结果相差较大的问题出现[5],对于存在的问题,本文根据其特点,在进行文本预处理、分词以及去除停用词一系列操作之后重点使用Word2Vec和TextRank等算法计算出词频,进行关键字抽取,词云展示,生成摘要等几个妙计,获取主题的文本摘要。实验证明,本文提出的方法能够获得较好的性能提升。
1 主要算法介绍
1.1 分词和去停用词
中文分词作为自然语言处理的第一步,利用计算机将待处理的文字串进行分词、过滤处理,输出中文单词、数字及特殊字符等一系列分割好的字符串。本文采用Python 3.0自带的中文Jieba分词,基于前缀词典进行词图扫描,通过精准模式(jieba.lcut(txt,cut_all=False))将句子最精确地切开,适合本文的专利长文档。
1.2 去停用词
停用词最早发现于信息检索,Luhn在检索研究中发现有一些词出现的概率非常高,但检索效果确很差[12]。停用词是除了文本中可以表达具体含义的实词以外,用于填充结构的虚词以及一些其他没有实际意义的词。这些词很明显就不是最后要找的关键词,而且还会对下一步的特征提取产生不好的影响[13],所以要根据停用词典去除高频且毫无意义的词语。
1.3 Word2Vec算法
Word2Vec是一種产生词向量的语言模式。将所有的词向量化,以便更好地衡量词与词之间的关系,而Word2Vec作为一种编码方式,将每个词编码成向量用来体现这些词的关系。
Word2Vec主要具有两种模型,一种是CBOW模型(通过上下文窗口词向量预测中心词向量)与Skip-Gram模型(根据中心词预测窗口词向量),其主要算法流程如图1所示。
主要步骤:
(1)读取源文件(此时的源文件是已经经过分词和去停用词的文件);
(2)使用Python的第三方库,最后可以得到有关专利文本的n个候选关键词,即D={t1, t2…, t3};
(3)遍历这些候选关键词,从生成的词向量文件中抽取候选关键词的词向量表示,即WV={V1, V2,…, Vm};
(4)计算词向量距离并排序,公式:
(1)
(5)把候选关键词排名在前TopN的词汇作为文本的关键词。
1.4 TextRank算法
TextRank算法是在PageRank算法的基础上提出来的,且是一种抽取式无监督的摘要方法,把对文本的分析转化成一个网络图模式,这样就可以通过分析网络图中每个节点的权重,确定节点的重要性。把文本中每一个句子都看作一个节点,如果两个句子之间存在相似性,则这两个句子之间有一条无向有权边[14]。
句子相似度计算:
(2)
通过句子的余弦相似度方法计算可得到句子间的相似度矩阵Sn×n:
(3)
其计算公式为:
(4)
TextRank算法相当于一种排序算法,可以将专利文本分割成若干个单元,通过句子节点构建连接图[15],利用相似度,通过循环迭代计算句子的TextRank值。TextRank算法流程如图2所示。
为分割后的每个句子找到向量表示,计算出句子之间的相似度之后存放在矩阵中,然后根据相似矩阵以及网络图计算并进行排序,最终,排名最高的n个句子作为最后的摘要结果。
2 实验结果及讨论
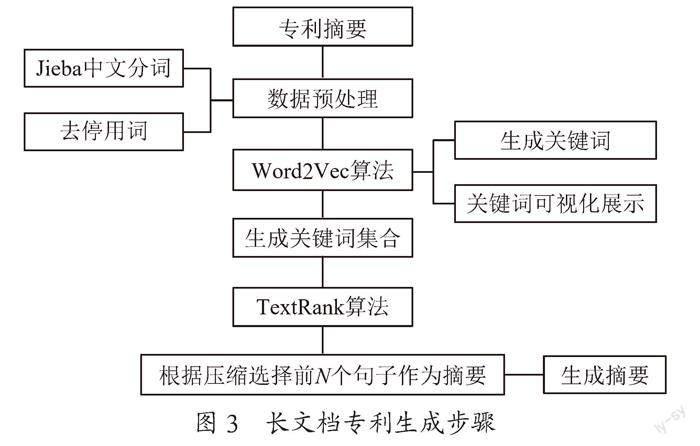
文章的设计目的是从一篇中文专利文档中抽取关键词,以农业大棚用薄膜为研究对象,对文档内容进行大致的分析。其中涉及四个步骤,首先对长文档进行分词、去停用词,其次利用Word2Vec算法提取反映文章主要内容的关键词,最后通过TextRank算法自动生成摘要,其具体的流程如图3所示。
2.1 分词和去停用词
使用Jieba库,进行分词拆分,先去掉非汉字字符,读入停用词表的文件,对每个词进行检索,去除对文本语义分词无意义的标点符号,对文本数据进行预处理,部分结果如表1所示。
2.2 Word2Vec关键字的提取
通过Word2Vec进行提取关键词,使读者一眼看出文章中的高频词,快速捕获文本信息,节约大量时间,文章共生成了254个关键词,通过Python中词云库WordCloud根据254个关键词的重要程度进行可视化展示,其最终生成的词云如图4所示。
从图4的展示结构中可以发现,本文共提取的254个关键词中,按照重要程度依次是监测、装置、相机、旋转、调节、机构、处理器、光源等关键词,由此可以推断这篇长文档是一篇关于农业大棚薄膜材质的监测装置。
2.3 TextRank生成摘要
通过Word2Vec算法对在原文中提取的关键字进行Embedding处理,TextRank算法根据Embedding值,用WordAVG表示句向量,然后根据余弦相似度计算形成一个113×113维度的相似度矩阵,根据TextRank算法提取113个摘要句,文章选取排名最前的10个摘要句构成该专利的摘要,其结果如表2所示。
从以上结果可以发现,通过TextRank算法自动生成的摘要,与该专利的原文摘要相比,篇幅较少,描述的文字也不尽相同,但较全面地概括了本文研究的目的、内容及意义,为其他专利长文档的自动生成提供了一定的借鉴及指导意义。
3 结 论
主要以农业大棚用薄膜为研究对象,以Word2Vec和TextRank算法生成摘要为例,主要从分词,去停用词,关键词提取,生成摘要四个方面对长文本进行研究,实现自动文本摘要提取。首先对文本数据进行预处理,在用Jieba库对专利文本进行分词,然后检索停用词表去除无用的停用词,然后通过Word2Vec进行提取关键词,快速捕获文本信息,用wordcloud对提取的关键词进行展示,最后通过TextRank算法生成摘要。实验结果显示,相对于传统方法而言,本文提出的基于Word2Vec和TextRank算法的自动文本摘要不易偏离主题,且适应范围广,速度快,准确度高,符合实验预期。
参考文献:
[1] 赵明辉,张玲玲,顾基发.基于网络评论文本挖掘的技术预见方法研究 [J].科技管理研究,2022,42(16):176-181.
[2] 熊谦,唐文哲.基于文本挖掘的水利工程建设管理信息化专利分析 [J].清华大学学报:自然科学版,2023,63(2):223-232.
[3] LUHN H P. The Automatic Creation of Literature Abstracts [J].IBM Journal of Research and Development,1958,2(2):159-165.
[4] 刘志明,于波,欧阳纯萍,等.基于主题的SE-TextRank情感摘要方法 [J].情报工程,2017,3(3):97-104.
[5] SALTON G,YU C T. On the Construction of Effective Vocabularies for Information Retrieval [J].ACM SIGPLAN Notices,1975,10(1):48-60.
[6] HU P,HE T T,JI D H,et al. A Study of Chinese Text Summarization Using AdaptiveClustering of Paragraphs [C]//the Fourth International Conference on Computer and Information Technology.Wuhan:IEEE,2004:1159-1164.
[7] 王永成,王晓峰.国家信息基础结构与全息检索 [J].电子出版,1997(4):57-59.
[8] KCHAOU D,BOUASSIDA N,BEN-ABDALLAH H. UML Models Change Impact Analysis Using a Text Similarity Technique [J].IET Software,2017,11(1):27-37.
[9] LI W,XIAO X Y,LYU Y J,et al. Improving Neural Abstractive Document Summarization with Structural Regularization [C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing.Brussels:Association for Computational Linguistics,2018:4078-4087.
[10] 程园,吾守尔·斯拉木,买买提依明·哈斯木.基于综合的句子特征的文本自动摘要 [J].计算机科学,2015,42(4):226-229.
[11] 徐飛,彭佳佳,刘军,杨博.基于多特征融合的TextRank新闻自动摘要模型 [J/OL].计算机系统应用:1-8[2023-01-29].https://www.cnki.net/KCMS/detail/detail.aspx?dbcode=CAPJ&dbname=CAPJLAST&filename=XTYY20221114019&v=MTkxNjlBemxxMkEwZkxUN1I3cWRaT1p1RkNEa1c3dk5KRm89UFRuU2Q3RzRITlBOcm81QlpPb0dZd2s3dkJBUzZqaDRU.
[12] 利润霖,龙昌敏,李雯芸,等.基于TextRank算法的项目标签智能化生成技术研究 [J].信息技术,2022(8):77-82.
[13] 李秀秀,陈海山.基于机器学习的新闻文本分类研究 [J].电脑编程技巧与维护,2021(12):132-135.
[14] 丁敬达,陈一帆,刘超,等.基于共词和Word2Vec加权向量的文献-主题语义匹配分析方法 [J].图书情报工作,2022,66(12):108-116.
[15] 罗婉丽,张磊.结合拓扑势与TextRank算法的关键词提取方法 [J].计算机应用与软件,2022,39(1):334-338.
作者简介:朱玉婷(2001—),女,汉族,甘肃平凉人,本科在读,研究方向:数据挖掘;刘乐(2004—),女,汉族,甘肃庆阳人,本科在读,研究方向:图像处理;辛晓乐(2000—),女,汉族,甘肃临夏人,本科在读,研究方向:机器视觉;陈珑慧(2000—),女,汉族,甘肃庆阳人,本科在读,研究方向:数据应用;康亮河(1987—),女,汉族,甘肃会宁人,助教,硕士,研究方向:人工智能算法研究。
收稿日期:2022-10-13
基金项目:甘肃省农业大学盛彤笙科技创新基金(GSAU-STS-2021-15);国家自然基金(32060437);甘肃农业大学省级大学生创新创业训练计划项目(202216018)
