基于数据结构的知识图谱构建及可视化研究
2023-06-25闫艺婷黄文杰
闫艺婷 黄文杰


摘 要:知识图谱作为一种结构化的组织方式,不仅能够帮助学习者定位所需的信息,还能关联其他信息,提高学习效率。文章对构建数据结构知识图谱进行研究,主要研究内容包括通过网络爬虫技术获取和处理数据集,设计以RDF数据模型为知识图谱的建模方法,采用BiLSTM+CRF模型的知识抽取方法,最后通过图数据库进行存储和可视化,使学习者明确学习方向,也为后续该学科的应用提供数据基础。
关键词:知识图谱;数据结构;知识抽取;图数据库
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2023)04-0171-04
Knowledge Graph Construction and Visualization Research Based on Data Structure
YAN Yiting, Huang Wenjie
(Software Engineering Institute of Guangzhou, Guangzhou 510990, China)
Abstract: As a structured organization, knowledge map can not only help learners locate the information they need, but also link other information to improve learning efficiency. This paper studies the construction of data structure knowledge graph. The main research contents include acquiring and processing data sets through web crawler technology, designing a modeling method using RDF data model as knowledge graph, using the knowledge extraction method based on BiLSTM+CRF model, finally, the graph database is used for storage and visualization to make learners clear their learning direction and provide a data basis for the subsequent application of this discipline.
Keywords: Knowledge Graph; data structure; knowledge extraction; graph database
0 引 言
谷歌提出知識图谱这一概念,为全球知识领域提出了可参考价值[1],其基本形式为三元组。目前,知识图谱的研究应用主要包括通用领域和垂直领域。通用的有Google Knowledge Graph、YAGO、DBPedia[2]等。垂直领域各方面优于通用,但其构建方法为手工,且成本高[3]。
在知识图谱概念提出后,已有学者利用知识库构建各学科资源,如赵继春[4]等人构建农业在线学习知识图谱,有效提升用户在线学习体验。奥德玛[5]等学者构建中文医学知识图谱,为医学领域知识图谱构建提供参考;白文倩[6]等人在教育技术学领域为大家提供一种新型文献方法。上述对不同学科领域进行了专业描述,但不能满足计算机学科知识描述的结构化的需求。
鉴于数据结构属于计算机学科的专业基础课,其该学科的知识图谱在知识点关联查询、学科知识资源个性化推理、学科知识自动问答、辅助学习等应用中起到重要作用,已有学者在开展相关学科知识图谱的构建。但并没有公开的数据集来源,现有的知识图谱从科学性、准确性、规范化等方面仍有较大的提升。如何构建高质量的学科领域知识图谱,仍是具有挑战的课题。
文中面向数据结构学科领域,首先通过网络爬虫采集数据,并对数据进行分析处理,得到规范标准化的数据,再对数据进行知识抽取,最后将数据进行可视化显示。
1 数据来源及研究方法
1.1 数据来源
数据获取是构建知识图谱过程中最重要的环节,只有收集到正确的数据,才能构建出科学、准确、有价值的知识图谱。知识图谱的数据源一般分为三类:结构化数据、非结构化数据(如图片、视频和音频等)、半结构化数据(如JSON和XML格式的数据等)。构建数据结构学科的知识图谱,由于数据结构课程领域没有公开的数据集,所以,文中的数据将分为两类获取,其中结构化的数据获取来源自于清华大学出版社严蔚敏编写的《数据结构》一书,根据该书手工构建最原始的数据。严蔚敏教授编著的《数据结构》是多所高校用的教学教材和考研指定教材,学科领域公认度高,根据教材获取并整理的原始数据具有一定的可靠性和正确性;而非结构化数据和半结构化数据则来源于百度百科,根据原始数据网络爬虫方法从百度百科中爬取词条相关的内容信息。最终将数据整合后,加入数据集中。
1.2 研究方法
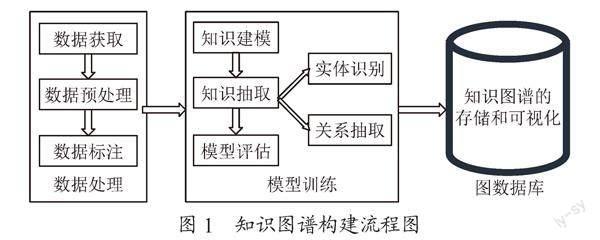
在对网络爬取的数据进行处理和标注后,进行知识图谱的建模,使用基于自然语言处理和机器学习的方法抽取知识实体,将原始数据标注后进行向量化,采用BiLSTM+CRF模型将向量化的原始数据源进行模型预训练,使用BiLSTM+CRF模型进行评估,其预测结果的精确率和召回率的调和平均数F1分数为95.3%,能够实现未标注数据的实体识别。然后,对已识别的实体进行人工的关系抽取,从而构建知识图谱。其过程主要采用BeautifulSoup库进行网页解析、Jieba库进行中文分词及NumPy库和Pandas库进行数据预处理,使用BIEOS标注策略进行数据特征标注,利用Torch机器学习框架训练模型,最后对数据进行知识抽取,模型评估合格后再使用Neo4j数据库进行知识图谱的存储和可视化,其构建流程如图1所示。
2 数据结构学科知识图谱的构建
2.1 数据处理
2.1.1 数据预处理
为了获得高质量的数据集,通过NumPy、Pandas库等,将干扰数据、停用词、重复数据等进行数据筛选并删除,数据清洗处理后的按字分行,如图2所示。
2.1.2 数据标注
数据进行特征标注处理,即采用BIEOS标注策略,将数据集以字或者标点符号作为标注单位,B-POINT表示知识点实体开始,I-POINT表示知识点实体中间位置,E-POINT表示知识点实体结束,O表示属于无关实体,S-POINT表示单个字知识点的实体,如图3所示。
通过标注处理,能够将字的特征标注出来,再进行向量化,模型训练后能够体现出向量化后的数据与特征的关系,提高实体识别的准确率。
2.2 知识图谱的知识建模
知识建模,使用一定的知识表示语言将实体规范起来,为方便知识图谱的存储,本次知识图谱的知识建模采用RDF(Resource Description Frame-work)的方法。RDF的基本組成单元三元组即S,P,O(subject(主),predicate(谓),object(宾)),例如:用一条三元组描述,线性表包括单链表(subject(线性表),predicate(包括),object(单链表))。一条三元组代表关于客观世界的逻辑描述和客观事实,多个三元组头尾相互连接就形成了一个RDF图,部分知识图谱的知识建模如表1所示。
2.3 知识抽取
对于半结构化数据和非结构化数据,需要进行知识抽取转化为三元组。知识抽取分为实体识别和关系抽取两个部分。
2.3.1 基于机器学习的实体识别
采用BiLSTM模型和CRF模型相结合,基于机器学习的实体识别,能够快速高效地构建涉及数据量较大的知识图谱。而采用BiLSTM+CRF模型其优点在于不仅可以拥有LSTM模型的特征抽取及拟合能力,并且在BiLSTM模型的基础上叠加的CRF层能够考虑到预测序列前后之间的关联性,使预测结果具有逻辑性,更加符合构建知识图谱的需求。
BiLSTM+CRF模型实现实体识别的原理是将模型预训练好后,未识别的实体通过两个循环神经网络(RNN)层生成前向和后向两个隐藏序列,由于待识别的实体在句子中分布不同,其上下文的信息也会有所不同。BiLSTM模型通过生成前向和后向两个序列,能够学习待识别的实体在句子中的上下文信息。然后,得到输出每个字向量化后的向量数值,根据其向量数值与标注特征数值相似的得分率,输出每个字对应每个标签的得分率,其得分率高的结果则表明字与标注特征的相关性大,预测出来的结果与实际结果有很大概率相同。最后,由于BiLSTM只考虑了单个字本身的标注特征,并没有考虑到最终的实体标签还会受到前后标签的影响,例如:B-POINT标签下一个标签不可能会是B-POINT,所以还会在BiLSTM模型的基础上叠加一个CRF层,通过学习标签之间的依赖关系,如:B-POINT标签与I-POINT标签相互依赖、I-POINT标签与E-POINT标签相互依赖。最后,得到具有逻辑关系的标注结果,其过程如图4所示。
通过BiLSTM+CRF算法,将得到数据结构的标注结果(数B-POINT据I-POINT结I-POINT构E-POINT),根据预测的标注结果,就可以识别出数据结构是实体。最后,根据对比实验验证,以6:2:2的比例分配训练集、测试集和验证集数据,经过10轮的训练,用F1分数对该模型的精确率和召回率进行评估,其F1分数接近95.3%,如图5所示。
经过10个Epoch的训练,验证损失和训练损失都降低到0.2%以下,而代表精确率和召回率的F1分数接近95.3%,预测出来的标注结果比较理想。最终,将未标注的数据集通过训练完成的BiLSTM+CRF模型,输出标注结果,根据标注结果确定数据中的实体,实现知识抽取中的实体识别部分。
2.3.2 关系抽取
在已经将数据集中的实体识别出来的基础上,将识别后的实体返回数据集中,从数据集中的句子确定已识别的实体关系。如果两个实体确实存在某种关系,那至少存在一个句子描述这种关系,基于这个假设,将存在两个或多个实体的句子识别出来,对其关系做进一步判断,人工从句子中抽取实体之间的关系,从而完成关系抽取。例如:数据结构包括集合、线性结构、树形结构和图图形结构,关系抽取结果为表2。
2.4 知识存储与可视化
通过数据处理和知识抽取,将原始数据集全部转化为三元组,其最终效果如图6所示。
将获取的三元组数据进行人工校对并整理,将不合理和重复的三元组进行修改或删除,整理后的三元组数据保存为csv文件,通过csv文件导入Neo4j图数据库中进行知识存储,其中实体的基本属性有知识点编号、知识点概念等级和知识点名称,关系的基本属性有关系编号和关系名称,并参考数据结构课程知识体系结构,对多个实体和实体的关系进行了补充,并添加了概念等级、函数和分类等作为实体的属性,能够更加直观的展示复杂数据中包含在其中的逻辑关系,有效帮助学习者提高学习思维,提升学习兴趣。数据结构知识图谱可视化部分是将(实体1,实体2,关系)课程知识点以三元组动态显示,通过Cypher操作语言进行Neo4j数据库进行查询和可视化,其中实体节点是以圆圈表示,实体之间的关系用箭头来连接,最终得到数据结构学科的知识图谱,其知识图谱的局部如图7所示。
其构建出来的数据结构学科知识图谱,共有235个实体,15种关系,准确率和覆盖率都达到了一定的标准,能够提供基于知识图谱的智能应用的数据基础。
3 结 论
文章从知识图谱构建的视角,以数据结构学科为计算机学科代表,详细介绍了构建数据结构学科知识图谱的步骤。设计了从三元组的知识建模,基于机器学习模型的知识抽取,并通过Neo4j图数据库实现知识图谱的存储和可视化的具体流程。解决了构建实体数量较大的知识图谱时,实体难以识别、关系难以提取的问题。并且运用图数据库,能够动态地对知识图谱进行完善。构建数据结构知识图谱,能够帮助学习者认识到数据结构学科当中各个知识点之间的关系,形成整体的知识网络,能够帮助学习者对所学知识的深入思考,同时提供能够支撑智能问答和智能搜索等智能应用的基础,也为其他的知识图谱的构建提供参考。
参考文献:
[1] 刘峤,李杨,段宏,等.知识图谱构建技术综述 [J].计算机研究与发展,2016,53(3):582-600.
[2] 杨玉基,许斌,胡家威,等.一种准确而高效的领域知识图谱构建方法 [J].软件学报,2018,29(10):2931-2947.
[3] 李艳燕,张香玲,李新,等.面向智慧教育的学科知识图谱构建与创新应用 [J].电化教育研究,2019,40(8):60-69.
[4] 赵继春,孙素芬,郭建鑫,等.农业在线学习资源知识图谱构建与推荐技术研究 [J].计算机应用与软件,2022,39(8):69-75.
[5] 奥德玛,杨云飞,穗志方,等.中文医学知识图谱CMeKG构建初探 [J].中文信息学报,2019,33(10):1-9.
[6] 白文倩,李文昊.国际教育技术学科学术群体知识图谱构建与分析 [J].中国电化教育,2013(6):31-38+66.
作者简介:闫艺婷(1994—),女,汉族,河南长葛人,教师,硕士,研究方向:自然语言处理;黄文杰(2000—),男,汉族,广东汕尾人,本科在读,研究方向:计算机应用。收稿日期:2022-09-24
