基于软注意力机制的图像分类算法在缺陷检测中的应用
2023-06-22方宗昌吴四九
方宗昌 吴四九

摘 要:针对传统表面缺陷检测算法检测效率低下,难以应对复杂性检测等问题,结合深度学习和注意力机制技术,提出一种新型注意力机制算法。首先,反思卷积神经网络(CNN)与Transformer架构,重新设计高维特征提取模块;其次,改进最新注意力机制来捕获全局特征。该算法可轻松嵌入各类CNN,提升图像分类和表面缺陷检测的性能。使用该算法的ResNet网络在CIFAR-100数据集和纺织品缺陷数据集上的准确率分别达到83.22%和77.98%,优于经典注意力机制SE与最新的Fca等方法。
关键词:缺陷检测;注意力机制;卷积神经网络;图像分类
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)03-0151-04
Application of Image Classification Algorithm Based on Soft Attention Mechanism
in Defect Detection
FANG Zongchang, WU Sijiu
(Chengdu University of Information Technology, Chengdu 610225, China)
Abstract: Aiming at the problems of traditional surface defect detection algorithms, such as low detection efficiency and it has difficulty to deal with complexity detection, a new attention mechanism algorithm is proposed by combining deep learning and attention mechanism technology. First, rethink profoundly the Convolutional Neural Networks (CNN) and Transformer architecture, and redesign the high-dimensional feature extraction module; secondly, improve the latest attention mechanism to capture global features. This algorithm can easily embed various CNN, improve the performance for image classification and surface defect detection. The accuracy of the ResNet network using this algorithm on the CIFAR-100 data set and the textile defect data set reaches 83.22% and 77.98% respectively, which is superior to the classical attention mechanism SE and the latest Fca and other methods.
Keywords: defect detection; attention mechanism; Convolutional Neural Network; image classification
0 引 言
产品的表面缺陷是工业生产的常见问题和影响产品质量的重要因素,这使得工业质量检测是生产不可忽略的重要环节之一。传统人工检测具有主观性、低效率、成本高等缺点。基于机器学习的表面缺陷检测技术(Automated surface inspection, ASI)通过机器获取设备判断产品图像中是否缺陷,一定程度上解决了问题,但无法应对真实工业环境中缺陷与背景差异小、尺度变化大等复雜挑战,正在逐步被基于深度学习的机器视觉技术所取代[1]。
深度学习中的神经网络模型来自对人类大脑神经元对事物认知模式的研究,而在深度学习领域最早在自然语言处理领域取得突破,后来又发展到计算机视觉领域的注意力机制也是认知科学对人类视觉系统自发分配注意力,着重于场景中的重点目标的功能的分析结果[2]。注意力机制可被划分为考虑对全部输入做加权平均的软注意力和关注局部输入信息的硬注意力机制。它使得神经网络更加关注图像中的重要局部区域,增强了网络提取远程相关信息的能力,被认为是深度学习界的未来发展方向之一。
在图像分类模型中加入注意力机制模块已经是一种主流做法。SENet[3]将通道注意力机制引入计算机视觉领域;FcaNet[4]使用离散余弦变换DCT替换注意力机制中的全局平均池化操作;ECA-Net[5]把全连接层替换为一维卷积,促进通道间的信息交流;Coordinate Attention[6]将输入特征按水平和竖直方向分解,用于特征校准;ViT[7]系列模型用自注意力代替卷积来提取特征;MobileNet V1[8]提出了深度卷积和点卷积;Han[9]等人分析了深度卷积和自注意力背后原理的一致性;ConvNeXt[10]用深度卷积模拟自注意力,证明了卷积架构和Transformer架构同样优秀。本文基于过往的这些工作提出一种新型软注意力模块FFAM,并基于经典神经网络ResNet系列在开源图像分类数据集CIFAR-100和搜集、整理网络图片得到的纺织品缺陷数据集上获得了超越多个经典和最新的注意力机制算法的效果。
1 网络框架
1.1 注意力机制框架
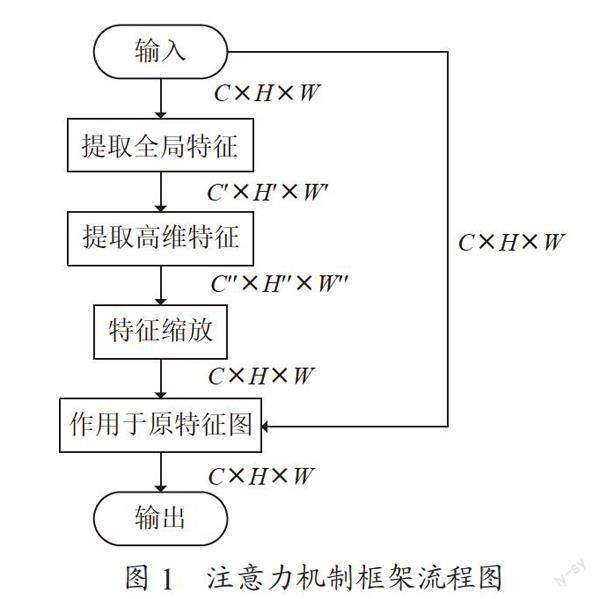
SENet及之后的CBAM、GENet、GCNet、FcaNet、ECANet、CA等一系列使用注意力机制的神经网络模块都可以用同一个流程框架模式来描述,具体为:
(1)对于输入大小为H×W×C的特征图X,通过操作A获得含有全局上下文特征而大小为H'×W'×C'的特征图X'(X'可能为多个)。
SENet通过二维全局平均池化操作获得1×1×C的特征图;CBAM同时使用二维全局平均池化和二维全局最大池化模块,将结果相加得到1×1×C的特征图;GENet经过多次将特征图的高度和宽度减半的卷积得到最小为H/8×W/8×C的特征图;GCNet将特征图X变形和降维而分别得到的C×HW大小的特征图X1与HW×1×1大小的特征图X2点乘,得到1×1×C的特征图;FcaNet从频域角度出发,用二维离散余弦变换DCT作为操作A,得到1×1×C的特征图;ECANet使用二维全局平均池化和变形操作获得1×C大小的特征图;SRM将二维全局平均池化和二维全局标准差池化的结果在通道维度上连接并使特征图变形,获得大小为1×2C的特征图;CA通过水平方向和竖直方向的两个一位全局平均池化,得到大小分别为H×1×C和1×W×C的特征图X1和特征图X2。
(2)对于含有全局上下文特征的特征图X′,用操作B作提取高维特征,得到特征图X''。这一过程通常不改变特征图大小。
SENet、CBAM、GCNet、FcaNet均使用先降维后升维的两次1×1卷积作为操作B;CA的操作类似,不同之处在于对于在第一步得到的特征图X1和X2,降维操作前合并为一个特征图,升维操作前再分割为两个;GENet多一个将特征图插值变形回原特征图X的大小的操作;ECANet则用一次大卷积核一维卷积提取特征。
(3)对于含有高维特征的特征图X'',经过操作C(通常为Sigmoid函数)将X''中的参数缩放到[0, 1]范围内,再与原特征图X相乘,进行特征缩放,抑制不重要的通道,更加关注重要的特征。
SENet、CBAM、GCNet、FcaNet、GENet、ECANet的这一过程如上文所述;CA需要同时乘以两个特征图X1''、X2'';GCNet和其模仿的ViT自注意力系列一样,将特征图X''直接与原特征图X相加。
对注意力机制的框架总结流程图如图1所示。
1.2 Transformer架构和ConvNeXt
具有自注意力机制的Transformer架构自从谷歌的ViT以来,在计算机视觉的多个领域被广泛研究与应用,似乎将取代卷积神经网络(Convolutional Neural Networks, CNN)的地位。而Han等人在《Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight》一文中通过大量实验指出,Transformer中的自注意力模块起到和CNN中深度卷积一样的作用,即逐通道的局部注意力,可以互相替换;而Transformer中进行通道间信息混合的FFN模块相当于CNN中具有升降維功能的1×1卷积。来自Facebook的团队按照这一思路设计了用上述模块模拟Transformer架构的ConvNeXt系列,作为CNN在多项指标上超过了Transformer架构中最优秀的MSRA的Swin Transform。
1.3 前馈注意力模块
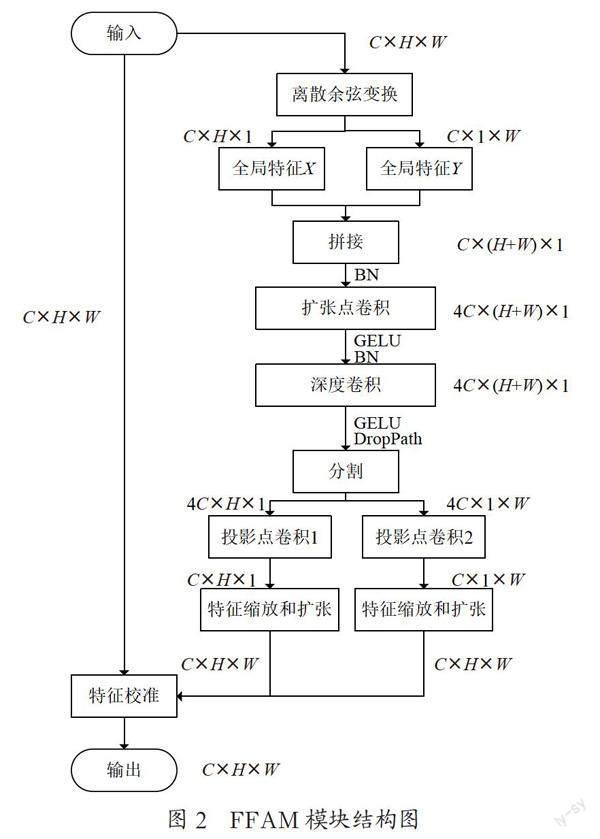
从1.1可以看出,之前的各种注意力模块在操作A上有较多探索,但在操作B上往往千篇一律。本文仿照ConvNeXt的作者,用卷积神经网络模拟Transformer架构的优点,提出了前馈注意力模块FFAM(Feed Forward Attention Module)。
本文所做的改进主要有以下几点:
(1)结合最新注意力机制方法,改造全局特征提取模块。对于1.1中被称为操作A的部分,Fca提出二维离散余弦变换DCT模块作为注意力机制模块中常用的二维全局平均池化的推广,来捕捉丰富的输入模式信息;CA使用水平方向和竖直方向的两个一维全局平均池化处理特征图,保留更多信息,增强对长条状特征的识别能力,对原始特征图做双重校准。本文结合这两种方法,改造DCT模块,生成大小分别为H×1×C和1×W×C的特征图X1和特征图X2,用于后续的高维特征提取和特征缩放。
(2)重新设计高维特征提取模块。与CNN中的注意力模块常常使用先降维后升维的两个卷积核大小为1×1的二维卷积不同,Vision Transformer中的前馈神经网络(Feed Forward Network, FFN)模块为包含两个先升维后降维的全连接层的多层感知机(Multilayer Perceptron, MLP)模块。
NIN这篇论文指出,当输入特征图大小为1×1时,MLP中的全连接层相当于CNN的1×1卷积,而卷积的通道数等同于全连接层的结点个数。因此本文用3个先升维后降维的1×1卷积来模拟Transformer架构中的FFN模块,其中一个用于升维,两个用于特征图X1和特征图X2的降维,扩张倍率均为4倍,同样使用GELU激活函数和DropPath过拟合控制方法。
CeiT提出替换FFN模块的LeFF(Locally-enhanced Feed-Forward layer)模块,在两层线性投影间加入深度卷积,带来了精度上的提升。同时由1.2可知,深度卷积能起到和自注意力机制类似的作用。本文则在升降维操作之间加入卷积核大小为1×1的深度卷积。从结果来看,最后确定的模块架构与MobileNet V2中的逆残差模块具有一定相似性,证明了优秀架构的一致性。
(3)改变基本组件顺序,减少激活函数与归一化操作数量。CNN中的卷积、激活函数和归一化操作的排列顺序通常是先进行卷积,然后做归一化,最后用激活函数,ResNet V1就采取了这一后来被称为post-activation后激活模式。但随后同一作者团队的ResNet V2提出了pre-activation的概念,选择先归一化,再用激活函数,最后再进行卷积的顺序,以增进梯度传递。采用神经网络搜索技术的Nasnet则使用先用激活函数,再进行卷积,最后做归一化的模式。IResNet含有多个卷积、激活函数和归一化的不同顺序的基本单元,在网络的不同阶段使用。PyramidNet、MobileNet V2、ShuffleNet分别以不同方式减少激活函数与归一化操作的使用数量,以避免信息损失。ConvNeXt的作者团队认为,Transformer架构成功的一部分来自它较少的激活函数与归一化操作数量。借鉴于这些工作,本文在FFAM模块中采用与Vision Transformer类似、与Nasnet相同的“归一化—卷积—激活函数”模式,并只在第一个1×1卷积和深度卷积的前后使用。
FFAM模块的结构图如图2所示。
FFAM模块可以像之前的SE、CBAM、ECA等各种模块一样轻松嵌入ResNet、MobileNet、EfficientNet等各种经典网络结构。嵌入FFAM模块的ResNet50网络的计算量从4.11 GFlops增加至4.27 GFlops,计算量仅增加3%。FFAM模块嵌入ResNet的两种基本结构单元的结构图如图3所示。
2 数据集与实验环境
2.1 数据集来源与处理
本实验所采用的数据集为来自加拿大高等研究所的开源图像分类经典数据集CIFAR-100和搜集、整理网络图片得到的纺织品缺陷数据集。
CIFAR-100数据集是Tiny Images数据集的子集,含有6万张图片,其中训练集5万张,测试集1万张。CIFAR-100数据集又分为20个超类、100个具体类别,每个具体类别有600张图片,其中训练集500张,测试集100张。CIFAR-100数据集中的超类有昆虫、爬行动物、家用电器、树木等;CIFAR-100数据集中的具体类别有海豚、向日葵、电视机、蝴蝶、火车等。
纺织品缺陷数据集中的一部分来自阿里天池大数据平台和百度飞桨深度学习平台的开源数据集,其余主要通过网络爬虫对国内外网站的爬取获得,最后经过了整理和类别平衡。纺织品缺陷数据集共计3 604张图片,包含水印、松经、纬缩、织疵等12种类别,按8:2划分训练集和测试集。具体图片数量表见表1,纺织品缺陷样本图见图4。
2.2 实验环境
本文使用PyTorch这一开源Python深度学习框架,并基于timm这一开源视觉神经网络代码库进行算法对比研究和代码撰写,首先在CIFAR-100数据集上测试和对比搭载FFAM模块与其他注意力机制模块的ResNet18网络的性能,再在纺织品缺陷检测数据集训练搭载FFAM模块的ResNet50网络的性能,并对比最新的注意力机制模块。
实验默认设置将输入图像缩放至224×224大小,数据集均值与标准差设为与ImageNet数据集相同,使用SGD梯度下降训练法做混合精度训练,动量为0.9,权重衰减量为2×10-5,每30个epoch衰减一次,学习率为0.05,批量大小为128,装载官方的預训练权重,共训练100个epoch。模型的运行环境见表2。
3 实验结果与分析
3.1 在CIFAR-100数据集上的实验
表3展现了搭载不同注意力模块的ResNet18网络在CIFAR-100数据集上的准确率对比。显而易见,搭载本文提出的FFAM模块的ResNet18网络取得了最高的准确率提升,超越经典的SE、CBAM和最新的Fca、ECA模块。同时可以看出,Fca和CA模块具有第二和第三的准确率,接下来将在纺织品缺陷数据集上对比FFAM和这两种模块的性能。
3.2 在纺织品缺陷数据集上的实验
表4的实验结果表明,FFAM模块在纺织品缺陷数据集上同样有性能优异的表现,高于新提出的Fca和CA这两种注意力机制模块,表明该模块在提升网络精度的同时具有一定的泛化能力。
4 结 论
本文分析了注意力机制模块的流程框架,借鉴各大经典注意力机制模块提出了FFAM模块,并构建了使用FFAM模块的ResNet18和ResNet50网络,用于识别CIFAR-100开源数据集和自行搭建的纺织品缺陷数据集。实验结果显示,嵌入FFAM模块的ResNet网络以更高的准确率和较少的计算量增加完成了分类任务,超过经典的SE、CBAM模块和最新的Fca、CA等模块,证明了该算法用于图像分类和缺陷检测领域的意义。该模块亦可嵌入其他卷积神经网络并用于各式计算机视觉任务中。
参考文献:
[1] 陶显,侯伟,徐德.基于深度学习的表面缺陷检测方法综述 [J].自动化学报,2021,47(5):1017-1034.
[2] 任欢,王旭光.注意力机制综述 [J].计算机应用,2021,41(S1):1-6.
[3] HU J,SHEN L,SUN G. Squeeze-and-Excitation Networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:7132-7141.
[4] QIN Z Q,ZHANG P Y,WU F,et al. Fcanet: Frequency Channel Attention Networks [C]//2021 IEEE/CVF International Conference on Computer Vision(ICCV).Montreal:IEEE,2021:763-772.
[5] WANG Q L,WU B G,ZHU P F,et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Seattle:IEEE,2020:11531-11539.
[6] HOU Q B,ZHOU D Q,FENG J S. Coordinate Attention for Efficient Mobile Network Design [J/OL].arXiv:2103.02907 [cs.CV].[2022-09-16].https://arxiv.org/abs/2103.02907.
[7] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [J/OL].arXiv:2010.11929 [cs.CV].[2022-09-16].https://arxiv.org/abs/2010.11929v1?utm_medium=email.
[8] HOWARD A G,ZHU M,CHEN B,et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications [J/OL].arXiv:1704.04861 [cs.CV].[2022-09-16].https://arxiv.org/abs/1704.04861.
[9] HAN Q,FAN Z J,DAI Q,et al. Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight [J/OL].arXiv:2106.04263 [cs.CV].[2022-09-16].https://arxiv.org/abs/2106.04263v1.
[10] LIU Z,MAO H Z,WU C-Y,et al. A Convnet for the 2020s [C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).New Orleans:IEEE,2022:11966-11976.
作者简介:方宗昌(1999—),男,汉族,山東菏泽人,硕士研究生在读,研究方向:计算机视觉;吴四九(1970—),男,汉族,四川成都人,教授,本科,研究方向:人工智能及数据挖掘、图形图像处理及应用。
收稿日期:2022-10-05
