基于YOLOv5的改进小目标检测算法研究
2023-06-22陈富荣肖明明
陈富荣 肖明明


摘 要:文章针对小目标检测存在的可利用特征少、定位精度要求高、数据集小目标占比少、样本不均衡和小目标对象聚集等问题,提出将coordinate attention注意力嵌入YOLOv5模型。Coordinate attention注意力机制通过获取位置感知和方向感知的信息,能使YOLOv5模型更准确地识别和定位感兴趣的目标。YOLOv5改进模型采用木虱和VisDrone2019数据集开展实验验证,实验结果表明嵌入coordinate attention能有效提高YOLOv5的算法性能。
关键词:目标检测;YOLOv5;coordinate attention;注意力机制
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)03-0055-07
Research on Improved Algorithm of Small Target Detection Based on YOLOv5
CHEN Furong1, XIAO Mingming2
(1.College of Information Science and Technology, Zhongkai University of Agricultural and Engineering, Guangzhou 510225, China; 2.College of Information and Communication Engineering, Guangzhou Maritime University, Guangzhou 510725, China)
Abstract: Aiming at the problems of small target detection, such as few available features, requirement of high positioning accuracy, small proportion of small target in data set, unbalanced samples and small target aggregation, this paper proposes to embed coordinate attention into YOLOv5 model. Coordinated attention mechanism can enable YOLOv5 model to identify and locate interested targets more accurately by obtaining information of location awareness and direction awareness. The improved YOLOv5 model uses psyllid and VisDrone 2019 datasets to carry out experiments to verify, and the experimental results show that embedding coordinate attention can effectively improve the algorithm performance of YOLOv5.
Keywords: target detection; YOLOv5; coordinate attention; attention mechanism
0 引 言
随着人工智能的快速发展,目标检测算法同时也获得迅速发展。目标检测是计算机视觉的研究重点,目标检测在计算机视觉中非常重要。目标检測算法广泛应用于无人驾驶,医疗,金融等领域。目标检测算法有两个任务,一是识别出物体的位置,二是对物体进行分类。目标检测技术目前还存在较多需要改善之处,其中包含对小目标检测精确度不高。
小目标检测有两种定义,一种是基于相对尺度定义,一种是基于绝对尺度定义。基于相对尺度定义为检测目标边框面积与图像面积之比的中位数在0.08%~0.58%之间。绝对尺度是在目标绝对像素大小这一方面考虑,当前最为通用的是MS COCO数据集的定义,MS COCO数据集将小目标定义为分辨率小于32像素×32像素的目标。在目标检测中,小目标检测是难点。小目标检测的难点在于小目标可利用特征比较少,对目标的定位精度要求高,位置信息不够准确,特征的表达不完全等方面。这导致小目标检测比大目标和中目标检测更为困难。
1 国内外研究现状
1.1 国外研究现状
Kisantal[1]分析MS COCO数据集,以及Mask RCNN在这个数据集上的目标识别、分割性能表现,针对小目标图片少,即使有图片含有小目标,小目标出现得少的原因,提出在对存在小目标的图像进行过采样,以及复制小目标粘贴到不同位置的方法。Lin[2]提出的FPN结构,可以很好地结合具有高分辨率的low-level和具有丰富语义的深层网络,提高小目标的检测效果。Noh[3]提出对生成器的训练过程进行直接监督和使用空洞卷积匹配训练图像对的感受野方法,提高特征超分辨网络对小目标的超分性能。贾可心[4]提出的海面小目标检测模型,能够在压缩模型的同时,保证模型的检测速度和检测精度,达到网络轻量化的效果,并且降低了小目标的漏检率,可以有效实现对海绵小目标的检测。在DERT小目标检测困难和收敛过程缓慢的问题,Zhu[5]团队做出Deformable DETR,让注意力模块只注意到参考点附近的少量样本点,其根据Deformable convolution的思想对DETR改进。由于基于无锚框和锚框的标签分配范式将导致许多微小真实样本远离检测范围,造成检测器对小物体施加较少的关注,Xu[6]提出一种基于高斯接感受野的标签分配(RFLA)策略使用在小目标检测。Wang[7]提出一种新的度量包围框相似度的方法,用来取代IoU,解决小目标检测使用IoU,对于位置变化过于敏感的缺点。Yang[8]提出QueryDet,QueryDet使用粗略位置稀疏引导的高分辨率特征计算检测结果,粗略位置由低分辨率特征上预测小物体得到,这种新颖的查询机制有效加速基于特征金字塔的目标检测器的推理速度。
1.2 国内研究现状
窦其龙[9]针对星载合成孔径雷达图像的小目标检测,提出一种基于YOLOv5的算法。该算法优化深度学习网络,通过自适应锚点框算法重新设置锚点框大小,再嵌入GDAL模块,提高YOLOv5算法的检测速度,降低漏检率。刘闪亮[10]提出注意力特征融合结构并应用在YOLOv5s模型上,在特征图上通过注意力特征融合结构融合更多的小目标信息,并使用更浅的特征层检测目标,进一步提高原模型对小目标检测的性能。田枫[11]提出改进YOLOv5的油田场景规范化着装检测方法Cascade-YOLOv5,该算法为搭建yolo-people和yolo-dress级联的小目标检测网络,提高油田作业现场监控视频中工人安全着装小目标检测性能。奉志强[12]提出一种基于YOLOv5的无人机实时密集小目标检测算法,在保证目标检测实时性的情况下,提高无人机视角下密集小目标的检测精度。
由于小目标相对大中目标占图像像素较小,现有算法存在检测不出小目标问题,使用注意力机制,可使模型提高对小目标的检测性能。本文为在YOLOv5网络中增加CA(coordinate attention)[13]模块,分析增加CA对YOLOv5算法的检测性能的影响。
2 目标检测算法
2.1 RCNN系列目标检测算法
RCNN目标检测算法的出现,使得深度学习开始在目标检测算法发挥作用。RCNN检测物体步骤为先在图像中使用选择性搜索获取2 000个候选框,然后将每个候选框输入神经网络获得输出,然后将2 000×4 096维矩阵输入SVM分类器,之后使用非极大值抑制去除重复框再对框进行微调。但是RCNN存在以下问题,一是经过缩放处理后会使一些图片特征信息丢失,从而降低检测的准确性,不利于小目标的检测,二是在训练和预测中,RCNN的速度都非常慢。
相比于RCNN,Fast RCNN解决RCNN的两个问题,Fast Rcnn使用一个神经网络对2 000个候选框进行特征提取并分类和生成边界框,相比与RCNN的2000和候选框使用2 000个神经网络,这提高了模型训练的速度。Fast Rcnn将整张图像输入卷积神经网络,然后输出特征图,然后使用选择性搜索算法得到的候选框与特征图进行映射得到固定长度的特征向量,然后将特征向量输入一系列的全连接层得到感兴趣的特征向量,后续是通过softmax层进行分类和对边界框的回归。Faster Rcnn先将图片输入卷积神经网络,然后输出特征图,该特征图用于RPN层和全连接层共享。特征图输入RPN中,RPN中的滑动窗口在特征图上的每个像素上形成9种anchor,9种anchor又输出2×9个分类输出和输出4×9个边界框回归,然后再使用RoI池化层应用于这些对象并将这些对象变成固定大小,最后将这些特征向量输入全连接层得到感兴趣的特征向量,然后再将感兴趣的特征向量输入softmax层和线性回归层进行分类和回归。Faster不是端到端的模型,所以训练时间相较于端到端模型较慢。
2.2 YOLOv1~v4目标检测算法
YOLO网络是one-stage,其把检测变为回归问题,位置和类别是用一个网络输出,实现了流程的统一。YOLOv1检测流程为将一张多目标图像输入并将图像划分为多个网格,然后网络预测每个网格中2个预测框的定位信息和置信度,然后网格的类别预测信息使用高置信度的预测框的类别判断,对于每个类别,预测框为分类置信度低的先去除,然后重复的预测框再通过NMS去除,最后将位置和类别信息输出。其不足之处为两个物体相互靠得很近时,或者检测的物体为很小时,检测效果不好。YOLOv2在YOLOv1的基础上使用一些方法提高性能,YOLOv2添加了BN層,使用了高分辨率主干网络,使用了anchor box机制,使用全卷积网络结构,使用DarkNet19主干网络,使用K-means聚类先验框,使用更高分辨率的特征,使用多尺度训练方式。
YOLOv3使用的特征提取网络为Darknet-53,并使用了FPN特征金字塔,FPN将浅层获取位置信息与深层获取语义信息进行融合,提高网络对小目标检测的检测精度,YOLOv3有三个输出,13×13输出对大目标的检测,26×26输出对中目标的检测,52×52输出对小目标的检测,YOLOv3使用逻辑回归为每一个边界框预测一个分数。YOLOv4使用了差不多所有的检测技巧,也提出一些技巧对YOLOv3进行改进,其网络结构与传统的YOLO网络结构几乎相同,在检测速度和准确度方面有一定提高。
2.3 YOLOv5
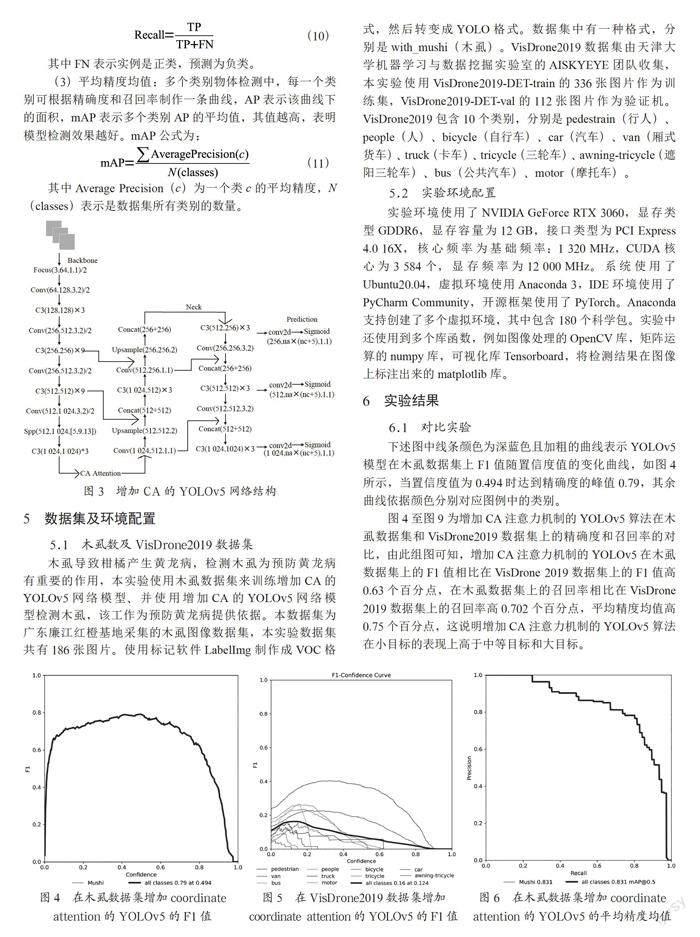
YOLOv5网络结构如图1所示,分为输入端、Backbone、Neck、Prediction四部分。
在输入端使用Mosaic数据增强。YOLOv5将自适应锚框计算功能嵌入到整个训练代码中。自适应地在每次训练时计算不同训练集的最佳锚框值。YOLOv5使用自适应图像缩放,是一个使其推理速度变快的trick。
在Backbone端,YOLO5使用了Focus结构,在Focus结构中,Focus处理608×608×3的图像成304×304×12的特征图,这在一定情况下提高特征图的操作。然后32个卷积核再将特征图变成304×304×32的特征图。YOLOv5使用了两种CSP结构,Backbone主干网络应用CSP1_X,Neck部分使用CSP2_X。CSP1_X是CSPNet变化而来,该模块由CBL模块、CONv、Resunit和Concate组成,X是指有X个这样的模块。CSP2_X也是由CSPNet网络组成,由X个Resunit和CONv组成。YOLOv5使用CSPDarknet作为特征提取网络。
在Neck端,采用SPPF结构,在特征提取上为了提高网络的感受野使用不同池化核大小的最大池化进行提取。使用FPN+PAN,借鉴了来之18年CVPR的PANet网络,FPN将高分辨率的特征图与低分辨率的特征图进行融合,自低分辨率特征图向高分辨率特征图传递强语义信息,PAN将含有强位置信息的高分辨率特征图和强语义信息的低分辨率特征图进行融合,自高分辨率特征图向低分辨率特征图传递强位置信息,通过这样做来加强网络的特征提取能力。
在输出端,YOLOv5中Bounding box的损失函数为CIoU_Loss:
(1)
(2)
而YOLOv5的NMS非极大值抑制则采用加权nms的方式。NMS的实质就是寻找局部极大值,将非极大值的元素抑制,非极大值主要用处就是用来消除冗余的检测框。如果检测的类别有N个类别,那么就要进行N次执行,因为NMS一次只处理一个类别。
3 基于YOLOv5的改进
目前已提出的注意力机制中,SE Attention[14]是SENet提出的目前最流行的注意力机制。它的通道注意力由2D全局池化来计算,它在很低的成本条件下提高了性能。
但是SE模块丢失了位置信息,而位置信息对下游的视觉任务具有非常重要的作用。之后CBAM[15]等方法使用大卷积来利用位置信息是通过减少通道数来完成,但是局部相关性只能被卷积局部捕获,对于对视觉任务很重要的长程依赖却很难解决。
在CA中,CA在通道注意力加入位置信息,让网络在大区域内进行注意力操作,同时不用产生大量的计算开销。为了减少2D全局池化形成的位置信息的丢失,两个并行的1D特征编码过程由CA将通道注意力分解而成,位置信息被有效地整合到生成的注意力图中。因为这种注意力操作能辨别坐标并且生成坐标感知的特征图,因此这方法称为坐标注意力。
相比于SE注意力和CBAM注意力,CA存在以下优势,首先,它除了获取通道的信息,还可以获取位置感知和方向感知的信息,这能让模型更精确地识别和定位感兴趣目标。然后,CA轻量而且灵活,可以很容易地插入经典模块,像MobileNetV2提出的invertd residual block和MobileNeXt提出sandglass block,是通过增强信息表示的方法来增强特征。最后,作为一个经过预训练的模型,CA在轻量化网络的基础上可以带来巨大的增益,特别是那些存在密集预测的任务。
CA模块对长程依赖和通道关系进行编码是通过精准的位置信息,和SE模块一样,分为两个步骤:坐标注意力生成和坐标信息嵌入,它的具体结构如图2所示。
CA拥有加强特征表示的能力。它可以将中间张量X=[x1,x2,…,xc]∈RC×H×W作为输入并输出Y=[ y1,y2,…,yc]由同样尺寸和有增强的表示能力的输出。
首先,在坐标信息嵌入这部分很难保存坐标信息,CA将输入特征图进行全局池化,分别在水平和垂直方向进行,这为通道注意力保留了水平和垂直方向上的长距离依赖关系。因此,第c个通道宽度为w的输出表述为:
(3)
相应的,第c通道高度为h的输出表述为:
(4)
上面的特征聚合是两个变换沿着两个空间方向进行,返回一对包含方向感知的特征图。这和其他方法由SE模块产生一个特征向量的方法不同,CA在空间的水平方向和垂直方向上获取长距离依赖关系和位置信息,这使神经网络更精确获取目标信息。
在经过全局池化后,这部分为将这两个方向上的向量进行拼接然后再进行卷积,然后再进行BN加非线性激活函数操作:
(5)
经过BN加非线性激活函数后。然后再将特征图分割开来再进行卷积操作,这里作用为在水平方向和垂直方向上对它进行关注,再进行sigmoid函数,这得到:
(6)
(7)
在这里是sigmoid激活函数。这里减少通道数经常使用适当的缩减比,这是为了降低模型的计算开销和复杂性。之后attention weight对输出和进行扩展。最后,CA block的输出可以写成:
(8)
CA注意力机制插在YOLOv5的backbone结构之后,图3为CA插入YOLOv5之后的网络结构。
4 目标检测评价指标
目标检测算法中常用的评价指标有:交并比IoU、准确率、召回率和平均准确率mAP等。下面简要介绍本文使用的几种评价指标。
(1)精确率:计算在预测的样本中,预测为正样本的正确率。精确率公式为:
(9)
其中TP表示实例为正类,预测为正类,FP表示实例为负类,预测为正类。
(2)召回率:是用来判断所有要检测的对象是否都能检测到。召回率公式为:
(10)
其中FN表示实例是正类,预测为负类。
(3)平均精度均值:多个类别物体检测中,每一个类别可根据精确度和召回率制作一条曲线,AP表示该曲线下的面积,mAP表示多个类别AP的平均值,其值越高,表明模型检测效果越好。mAP公式为:
(11)
其中Average Precision(c)为一个类c的平均精度,N(classes)表示是数据集所有类别的数量。
5 数据集及环境配置
5.1 木虱数及VisDrone2019数据集
木虱导致柑橘产生黄龙病,检测木虱为预防黄龙病有重要的作用,本实验使用木虱数据集来训练增加CA的YOLOv5网络模型、并使用增加CA的YOLOv5网络模型检测木虱,该工作为预防黄龙病提供依据。本数据集为广东廉江红橙基地采集的木虱图像数据集,本实验数据集共有186张图片。使用标记软件LabelImg制作成VOC格式,然后转变成YOLO格式。数据集中有一种格式,分别是with_mushi(木虱)。VisDrone2019数据集由天津大学机器学习与数据挖掘实验室的AISKYEYE团队收集,本实验使用VisDrone2019-DET-train的336张图片作为训练集,VisDrone2019-DET-val的112张图片作为验证机。VisDrone2019包含10个类别,分别是pedestrain(行人)、people(人)、bicycle(自行車)、car(汽车)、van(厢式货车)、truck(卡车)、tricycle(三轮车)、awning-tricycle(遮阳三轮车)、bus(公共汽车)、motor(摩托车)。
5.2 實验环境配置
实验环境使用了NVIDIA GeForce RTX 3060,显存类型GDDR6,显存容量为12 GB,接口类型为PCI Express 4.0 16X,核心频率为基础频率:1 320 MHz,CUDA核心为3 584个,显存频率为12 000 MHz。系统使用了Ubuntu20.04,虚拟环境使用Anaconda 3,IDE环境使用了PyCharm Community,开源框架使用了PyTorch。Anaconda支持创建了多个虚拟环境,其中包含180个科学包。实验中还使用到多个库函数,例如图像处理的OpenCV库,矩阵运算的numpy库,可视化库Tensorboard,将检测结果在图像上标注出来的matplotlib库。
6 实验结果
6.1 对比实验
下述图中线条颜色为深蓝色且加粗的曲线表示YOLOv5模型在木虱数据集上F1值随置信度值的变化曲线,如图4所示,当置信度值为0.494时达到精确度的峰值0.79,其余曲线依据颜色分别对应图例中的类别。
图4至图9为增加CA注意力机制的YOLOv5算法在木虱数据集和VisDrone2019数据集上的精确度和召回率的对比,由此组图可知,增加CA注意力机制的YOLOv5在木虱数据集上的F1值相比在VisDrone 2019数据集上的F1值高0.63个百分点,在木虱数据集上的召回率相比在VisDrone 2019数据集上的召回率高0.702个百分点,平均精度均值高0.75个百分点,这说明增加CA注意力机制的YOLOv5算法在小目标的表现上高于中等目标和大目标。
表1为图4至图9的实验结果总结,实验结果表明增加CA注意力机制的YOLOv5在木虱数据集上检测效果更好。
6.2 消融实验
为验证增加CA的YOLOv5算法的有效性,设置消融实验验证CA改进策略对模型性能的影响,实验考虑了CA模块,将CA模块加入原YOLOv5算法中,在同一条件下,训练300批次,图10~15为F1值,平均精确均值和召回率的实验结果图。
图10至图15分别是YOLOv5和增加CA的YOLOv5的F1值,平均精度均值,召回率的对比,在YOLOv5加入CA注意力后,使模型的F1值下降0.02个百分点,平均精度均值下降0.03个百分点,召回率提高0.01个百分点。召回率的小幅提升表明增加CA注意力之后模型对数据集中的小目标漏检率降低,能提高复杂场景下目标的检测率,如被遮挡的物体。
数据集的类别为Mushi(木虱),表2为算法中检测类别为Mushi(木虱)的检测类别实验结果对比。
由实验结果对比可知,在检测木虱类别(Mushi)中,在增加coordinate attention注意力机制后的YOLOv5在F1值下降2%的情况,平均精度均值下降3%的情况下,召回率提高1%,这表明增加CA能提高YOLOv5的检测性能。
6.3 检测结果
在图16中,左边图为YOLOv5算法检测出的木虱图像,右图像是增加CA注意力机制后YOLOv5算法检测出的木虱图像。从图像检测木虱结果上看,增加CA注意力机制后的YOLO5检测木虱图像检测出图像中右上角和右边的木虱,而YOLOv5算法没有检测出来,这表明增加CA能提高YOLOv5的检测性能。
通过上述实验结果分析可得,增加CA注意力机制对于提高YOLOv5的检测性能有作用,并且通过对比木虱数据集和VisDrone数据集可知,增加CA注意力机制在小目标上性能更好。
7 结 论
通过增加CA注意力机制,改进后的YOLOv5算法的精确度、F1值、召回率和平均精确均值都提高,但是改进后的YOLOv5算法对小目标的检测仍然存在误检问题。在未来的研究中,可以从数据集中小目标占比少、样本不均衡、网络结构方面研究,通过优化网络结构,提高数据集中小目标占比和增加小目标的训练正样本来提高YOLOv5目标检测算法的性能。
参考文献:
[1] KISANTAL M,WOJNA Z,MURAWSKI J,et al. Augmentation for small object detection [J/OL].arXiv:1902.07296 [cs.CV].(2019-02-19).https://arxiv.org/abs/1902.07296v1.
[2] LIN T Y,DOLLAR P,GIRSHICK R. Feature Pyramid Networks for Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu:IEEE,2017:936-944.
[3] NOH J,BAE W,LEE W,et al. Better to Follow,Follow to Be Better:Towards Precise Supervision of Feature Super-Resolution for Small Object Detection[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).Seoul:IEEE,2019:9724-9733.
[4] 贾可心,马正华,朱蓉,等.注意力机制改进轻量SSD模型的海面小目标检测 [J].中国图象图形学报,2022,27(4):1161-1175.
[5] ZHU X,SU W,LU L,et al. Deformable DETR:Deformable Transformers for End-to-End Object Detection [J/OL].arXiv:2010.04159 [cs.CV].(2020-10-08).https://arxiv.org/abs/2010.04159.
[6] XU C,WANG J,YANG W,et al. RFLA:Gaussian Receptive Field Based Label Assignment for Tiny Object Detection [C]//Computer Vision-ECCV 2022.Cham:Springer,2022:526-543.
[7] WANG J,XU C,YANG W,et al. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection [J/OL].arXiv:2110.13389 [cs.CV].(2021-10-26).https://arxiv.org/abs/2110.13389v2.
[8] YANG C,HUANG Z,WANG N. QueryDet:Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection [C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).IEEE:New Orleans,2022:13658-13667.
[9] 窦其龙,颜明重,朱大奇.基于YOLO-v5的星载SAR图像海洋小目标检测 [J].应用科技,2021,48(6):1-7.
[10] 刘闪亮,吴仁彪,屈景怡,等.基于A-YOLOv5s的机场小目标检测方法 [J/OL].安全与环境学报:1-8[2022-08-01].DOI:10.13637/j.issn.1009-6094.2022.0819.
[11] 田枫,贾昊鹏,刘芳.改进YOLOv5的油田作业现场安全着装小目标检测 [J].计算机系统应用,2022,31(3):159-168.
[12] 奉志强,谢志军,包正伟,等.基于改进YOLOv5的无人机实时密集小目标检测算法 [J/OL].航空学报:1-15[2022-09-01].http://kns.cnki.net/kcms/detail/11.1929.V.20220509.2316.010.html.
[13] HOU Q,ZHOU D,FENG J. Coordinate Attention for Efficient Mobile Network Design [C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville:IEEE,2021:13708-13717.
[14] HU J,SHEN L,ALBANIE S,et al. Squeeze-and-Excitation [J].Networks IEEE Transactions on Pattern Analysis and Machine Intelligence,2019,42(8):2011-2023.
[15] WOO S,PARK J,LEE J,et al. CBAM:Convolutional Block Attention Module[C]//ECCV 2018.Munich:Springer,2018:3-19.
[16] GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago:IEEE,2015:1440-1448.
[17] HE K,GKIOXARI G,DOLLAR P,et al. Mask R-CNN [C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice:IEEE,2017:2980-2988.
[18] BAI Y,ZHANG Y,DING M,et al. SOD-MTGAN:Small Object Detection via Multi-Task Generative Adversarial Network [C]//Computer Vision–ECCV 2018.Munich:Springer,2018:210–226.
[19] LI J,LIANG X,WEI Y,et al. Perceptual Generative Adversarial Networks for Small Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu:IEEE,2017:1951-1959.
[20] CHEN G,CHOI W,YU X,et al. Learning efficient object detection models with knowledge distillation [C]//NIPS'17:Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach:Curran Associates Inc.,2017:742-751.
[21] CARION N,MASSA F,SYNNAEVE G,et al. End-to-End Object Detection with Transformers [C]//Computer Vision-ECCV 2020.Cham:Springer,2020:213–229.
[22] LIN T,DOLLAR P,GIRSHICK R,et al. Feature Pyramid Networks for Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:936-994.
[23] LUC C,MINH-TAN P,SEBASTIEN L. Small Object Detection in Remote Sensing Images Based on Super-Resolution with Auxiliary Generative Adversarial Networks [J/OL].Remote Sensing,2020,12(19):3152(2020-08-25).https://doi.org/10.3390/rs12193152.
[24] HE K,ZHANG X,REN S,et al. Deep Residual Learning for Image Recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:770-778.
作者簡介:陈富荣(1995—),男,汉族,硕士研究生在读,研究方向:计算机视觉;通讯作者:肖明明(1972—),男,汉族,广东三水人,教授,博士研究生,研究方向:计算机视觉。
收稿日期:2022-10-04
