基于Hadoop搭建高可用数据仓库的研究和实现
2023-06-21刘晓莉李满熊超秦黄刘晓娟
刘晓莉 李满 熊超 秦黄 刘晓娟

摘 要:目前,网购交易的日益增加使得电商数据量呈现疯狂增长的态势,数据量的大增需要引入数据仓库,用以支持对大容量数据的分析和处理。在数据仓库的架构设计过程中,将HDFS作为底层文件存储系统,避免因某些原因而导致的系统崩溃。该文对高可用数据仓库的应用进行深入的研究,通过搭建高可用数据数仓平台,解决Hadoop单节点故障问题,提高数据采集和存储的效率,有效解决了传统数据分析的局限性,具有一定的应用推广价值。
关键词:数据仓库;高可用;大数据;Hadoop
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2023)01-0099-03
Research and Implementation of Building High Availability Data Warehouse
Based on Hadoop
LIU Xiaoli, LI Man, XIONG Chao, QIN Huang, LIU Xiaojuan
(Guangzhou College of Technology and Business, Guangzhou 510850, China)
Abstract: At present, the growing number of online shopping transactions has led to a crazy growth of E-commerce data volume, which requires the introduction of data warehouses to support the analysis and processing of large volume data. During the architecture design of the data warehouse, HDFS is used as the underlying file storage system to avoid system crash for some reasons. This paper conducts in-depth research on the application of high availability data warehouse. By building a high availability data warehouse platform, it solves the problem of Hadoop single node failure, improves the efficiency of data collection and storage, effectively solves the limitations of traditional data analysis, and has certain application promotion value.
Keywords: data warehouse; high availability; big data; Hadoop
0 引 言
隨着信息化时代的到来,数据仓库技术逐渐受到国内外工业界和学术界的高度重视,Hadoop大数据平台可以看作迭代更新后的数据仓库系统,具有低成本、高性能、高容错和可拓展等特征。它主要实现了MapReduce计算模型和分布式文件系统HDFS功能,并且拥有许多不同特点的相关组件,这些组件为相关工程提供各种服务,逐渐形成一系列的组件系统,通常被称为Hadoop生态系统。
基于大数据仓库的决策系统可以对大容量的数据进行分析、挖掘、模型训练等。大数据的数据仓库建设能够响应灵活多变、对实时性有不同程度要求的多元化需求,除了面向DSS、BI等传统应用外,还要响应用户画像、个性化推荐、机器学习、数据分析等各种复杂的应用场景;更多的是基于非商业、开源的技术,常见的是基于Hadoop生态构建,所涉技术较为广泛、复杂,同时相对于商业产品,稳定性、服务支撑较弱,需要自己维护更多的技术框架,数据仓库模型设计更灵活,能够很好地满足电商数据平台现有的需求。
Hadoop2.x引入高可用集群的概念,一方面避免Hadoop1.x中单点故障问题导致HDFS集群不可用的情况,另一方面提高系统和应用的可能性。在Hadoop2.x引入高可用集群概念的基础上,文本将对HDFS高可用架构的搭建进行研究和实现,为后续大数据开发做好准备工作。
1 HDFS高可用架构概述
Hadoop的三大核心是分布式文件系统HDFS、分布式计算框架MapReduce以及集群资源管理器YARN。其中,HDFS是一个分布式,用于存储、管理和维护文件的系统。HDFS的组成架构包括Namenode、Datanode、客户端、Secondary Namenode,Namenode是管理所有Datanode(从节点)的主节点。它记录存储在集群(Datanode)上所有文件的元数据信息,例如存储块的位置、文件的大小、权限、层次结构等。Namenode决定是否将文件映射到Datanode上的复制块上。当Namenode不可用时,会导致整个集群暂停运作,为解决Namenode不可用的问题,利用高可用HDFS文件系统搭建Hadoop大数据数仓,而且HDFS很适合一次写入、多次读出的场景,非常适合用来做数据分析。
HDFS高可用架构在高可用集群中有两个同时运行的Namenode——Active Namenode和StandBy Namenode,如图1所示。Active Namenode负责对外提供服务,StandBy Namenode负责数据的同步。如果一个Namenode宕机,另外一个Namenode将切换为Active Namenode状态,两者之间可以通过Journalnode进程共享资源和同步数据,能够在Namenode由于某些原因崩溃不可用时自动进行故障转移,也可以是维护人员在维护期间手动进行故障转移。
保证有且仅有一个Active Namenode,如果存在两个Active Namenode,则会导致数据损坏,其中一个集群会被划分为更小的集群,每个集群都认为它是唯一活动的集群,为了避免这种情况的发生需要进行一定的防护,而Fencing是确保在特定时间内只有一个Namenode保持活动的过程。
2 高可用大数据数库平台
2.1 高可用架构的实现
2.1.1 使用仲裁日志节点
Active Namenode和StandBy Namenode通过Journal Nodes保持相互同步,其中Journal Nodes遵循环拓扑,节点彼此之间成環。Journal Nodes能在发生故障时提供容错功能,将数据信息分发到环中的其他节点中,Active Namenode负责更新Journal Nodes中的EditLog信息,StandBy Namenode读取对Journal Nodes中的EditLog更改信息。
在故障转移期间,StandBy Namenode确保自己成为新的Active Namenode之前已经从Journal Nodes中更新了元数据信息,保证当前状态与故障转移之前的状态同步。
StandBy Namenode具有集群中块位置的更新信息,能提供快速故障转移功能,Active Namenode和StandBy Namenode的IP地址对所有Datanode都是可用的,Datanode向它们发送自己的心跳和块位置信息。StandBy Namenode可感知到Active Namenode节点是否正常。如果发现异常,监控进程负责将StandBy Namenode切换为Active Namenode。
2.1.2 使用共享存储
Active Namenode和StandBy Namenode通过共享存储设备保持信息同步,Active Namenode将其名称空间中所做的修改记录记录到EditLog中。StandBy Namenode读取对这个共享存储中的EditLog所做的更改,应用到自己的名称空间中。
如果发生故障转移,StandBy Namenode使用共享存储中的EditLog更新元数据,Active Namenode使得当前的命名空间状态与之前的状态同步。HDFS高可用集群提供自动故障转移功能,协调数据,将数据的更改通知给客户端,并监视客户机的故障。
2.2 Hadoop集群配置高可用性
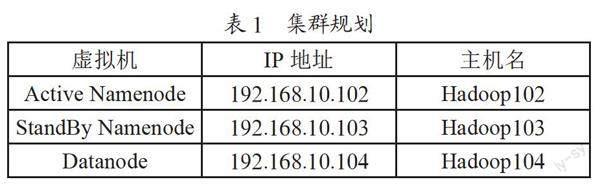
高可用的主要目的就是消除单点故障,HDFS集群规划如表1所示。
以Hadoop102为例,其基本配置信息如下:
(1)光盘映像(ISO)镜像系统:64位CentOS-7;
(2)对虚拟机命名:Hadoop102;
(3)处理器数量为1,内核数量为2;
(4)内存大小:2 048 MB;
(5)设置网卡类型:NAT模式;
(6)磁盘容量:20 GB,类型:虚拟磁盘;
(7)子网IP:192.168.10.0,网关IP:192.168.10.2。
2.2.1 HDFS-HA手动模式
在原有的Hadoop集群中,配置core-site.xml,hdfs-site.xml,分发配置好的hadoop环境到其他节点。启动HDFS-HA集群,启动journalnode服务,在nn1上进行hdfsnamenode-format格式化,在nn2和nn3上同步nn1元数据信息,启动nn2和nn3。在所有节点上启动DataNode,将nn1切换为Action。
2.2.2 HDFS-HA自动模式
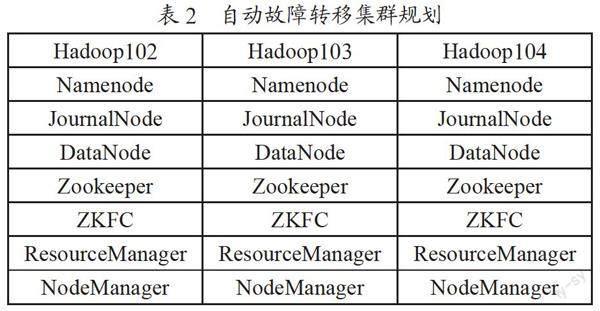
自动故障转移为HDFS部署增加了两个新组件——ZooKeeper和ZKFailover Controller(ZKFC)进程,ZooKeeper负责维护少量协调数据,通知客户端这些数据的改变以及监视客户端故障的高可用服务。Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和高效稳定的系统提供给用户。自动故障转移的集群规划如表2所示。
在原有基础上,配置hdfs-site.xml和core-site.xml文件,分别添加启用nn故障自动转移和指定zkfc要连接的zkServer地址,启动Zookeeper后,初始化HA在Zookeeper中的状态,再启动HDFS服务。
2.3 高可用节点部署及测试
在Hadoop102、Hadoop103和Hadoop104三个节点上部署Zookeeper,启动HDFS-HA集群,在各个Journalnode节点上启动,对nn1进行格式化,将nn1的元数据同步到nn2,启动nn2,能查看到Web页面显示standby,在nn1上启动Datanode,将nn1切换为Active,能查看到Web页面显示Active。
修改配置文件core-site.xml、hdfs-site.xml并添加自动故障转移,初始化Zookeeper转台,在各个Namenode节点上启动ZKFailover Controller,将Active Namenode进程杀死,断开网络,查看网页端三台Namenode的状态由standby变为active,如图2所示。
3 结 论
随着计算机技术和互联网技术的迅猛发展,预计未来5年,大数据市场将以近13%的速度增长,这是IT整体预期增速的两倍之多,充分利用大数据分析协助企业进行运营和营销的决策。而Hadoop已经被证明是解决大数据相关问题的有效工具,搭建高可用大数据数仓平台,能够解决Hadoop单节点故障问题,提高数据采集和存储的效率,既能提高信息的安全性,又能提高信息的利用效率,有效克服了传统数据分析的局限性,它可以存储和处理海量的数据,挖掘出有价值的信息,提高查询性能,给用户带来极大的便利,具有一定的参考价值。
参考文献:
[1] 邹群.一种基于Hadoop的数字图书存储系统设计方案 [J].黑龙江史志,2014(1):212.
[2] 翟永东.Hadoop分布式文件系统(HDFS)可靠性的研究与优化 [D].武汉:华中科技大学,2011.
[3] 李聪.HDFS元数据管理的高可用性优化技术研究 [D].哈尔滨:哈尔滨工业大学,2016.
[4] 宋继红,李梦楠,郝得智.基于Hadoop分布式文件系统的单点问题的研究 [J].软件工程师,2014,17(12):9-10+6.
[5] 杨帆.Hadoop平台高可用性方案的设计与实现 [D].北京:北京邮电大学,2012.
[6] 陈磊,吴晓晖.基于Hadoop的分布式集群大数据动态存储系统设计 [J].中国电子科学研究院学报,2019,14(6):593-598.
作者简介:刘晓莉(2001.04—),女,汉族,广东深圳人,本科在读,研究方向:大数据技术;李满(1966.12—),女,汉族,河南南阳人,副教授,硕士,研究方向:虚拟现实技术、人工智能;熊超(2001.02—),男,汉族,四川南部人,本科在读,研究方向:大数据开发;秦黄(2001.04—),男,汉族,广西桂林人,本科在读,研究方向:大数据存储、深度学习;刘晓娟(1990.07—),女,瑶族,广西贺州人,讲师,硕士,研究方向:大数据存储。
收稿日期:2022-09-07
基金项目:广州工商学院2022年国家级大学生创新创业训练计划立项项目(202213714006)
